Nicht zurückschrecken wegen der Länge. Mein Problem ist vermutlich
relativ trivial, aber ich muss ertmal etwas drumherum erklären.
Ich möchte in MatLab eine Sprachanalyse/Sprachsynthese machen. Das ganze
arbeitet übrigends frameweise. Ich lese also beispielsweise 4s vom
Mikrofon mit 44,1 kHz ein und habe damit 4*44100 Samples. Diese werden
in Frames mit fester Framegröße eingeteilt, beispielsweise 160 Samples
sind 1 Frame. Am Ende der Analyse habe ich pro Frame noch max. 40
Triplets (Amplitude, Phase, Frequenz). Aus diesen muss ich wieder einen
Frame generieren. Dazu laufen diese zunächst durch einen Peak-Matching
Algorithmus, welcher frequenzabhängig die Peaks des aktuellen Frames mit
denen des nachfolgenden Frames "matched". Sinn des Matching ist es die
Frequenz-Tracks frameübergreifend zu betrachten, damit die Übergänge
zwischen den Frames weicher klingen.
Soviel zur Vorgeschichte. In der Synthese muss ich nun die Amplituden
des Frames und die Phasen des Frames durch vorgegebene Formeln
interpolieren (bei der Interpolierung werden auch die Werte des
nachfolgenden Frames berücksichtigt, was durch das Peak-Matching
vorbereitet wurde).
Logischerweise muss die Länge eines Syntheseframes mit der Länge eines
Analyseframes übereinstimmen. Wäre die Framegröße also 160, dann müsste
ich aus den max. 40 Triplets 160 Samplewerte machen (die beispielsweise
in eine Wave-Datei geschrieben werden können).
Dies soll durch die Erzeugung von Sinuswellen in Framelänge geschehen,
welche dann aufsummiert werden. Ich muss also für jeden einzelnen der
max. 40 Peaks eine Sinuswelle mit genau 160 Werten erzeugen. Diese max.
40 Wellen werden dann aufsummiert, sodass am Ende nur eine einzige
(resultierende) Welle mit 160 Werten übrig bleibt. Diese gehen in den
Output und das Ganze beginnt von vorn für den nächsten Frame.
Die Interpolation sieht so aus (dieser Codeausschnitt ist vor der
eigentlichen Problemstelle, dient also nur um das Nachfolgende zu
verstehen): 1 | for j = 0:length(synthframe(:,1))-1
| 2 | out_int(j+1,1) = interpolate_amp(synthframe(j+1,1),matchframe(j+1,1),length(synthframe(:,1)),j);
| 3 | out_int(j+1,2) = interpolate_pha(synthframe(j+1,2),matchframe(j+1,2),synthframe(j+1,3),matchframe(j+1,3),length(synthframe(:,1)),j);
| 4 | end;
| 5 | output = [output;out_int];
|
interpolate_amp ist die Amplitudeninterpolationsfunktion und
interpolate_pha eben die Phasenint.-Fkt. Relevant für das Problem ist
eigentlich nur die Phaseninterpolation:
PHI(t) = PHI + w(t) + alpha(M)*t^2 + beta(M)*t^3
alpha und beta sind zwei spezielle Faktoren, die u.a. noch Komponenten
des nachfolgenden Frames erhalten. Wichtig ist hier nur, dass die
Phasenfunktion eben auch die Frequenz und die Phase enthält.
Das Problem ist nun die Erzeugung der Sinuswelle. Das geschicht
folgendermaßen: 1 | for j = 1:length(output(:,1))
| 2 | oooo = [];
| 3 | oooo = output(j,1)*cos((0:(2*pi)/(framesize-1):2*pi)+output(j,2));
| 4 | waveform = [waveform;oooo];
| 5 | end;
| 6 | finalwave = sum(waveform);
| 7 | wave = [wave;finalwave];
|
Die Formel zur Erzeugung der Sinuswelle ist wie folgt vorgegeben:
s(n) = A(n) * cos[PHI(n)]
Wie in dem Ausschnitt zu sehen habe ich noch den Ausdruck
(0:(2*pi)/(framesize-1):2*pi)
in die cos()-Funktion eingefügt damit ich eben die richtige Anzahl an
Samples als Ergebnis erhalte. Und ich denke deshalb funktioniert die
Synthese nicht richtig.
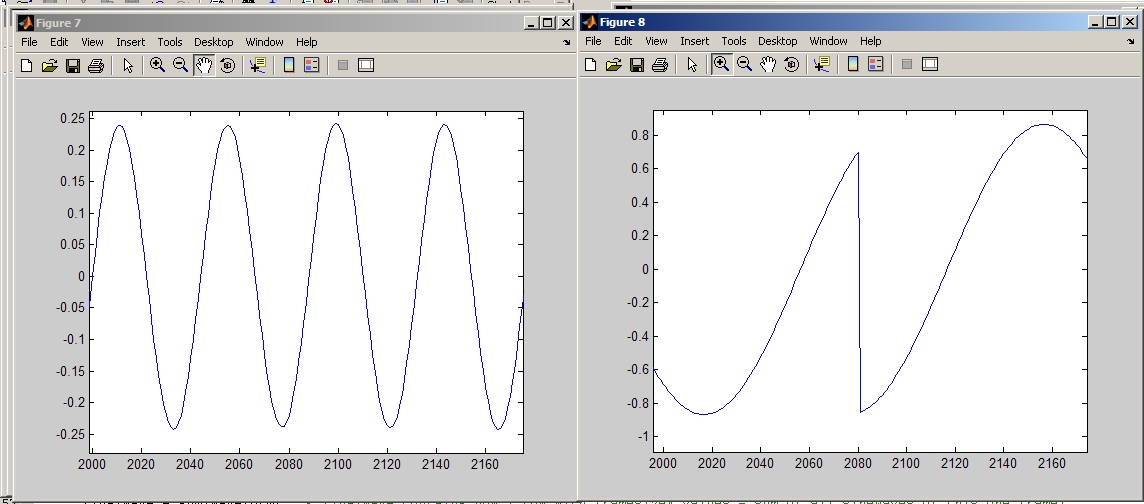
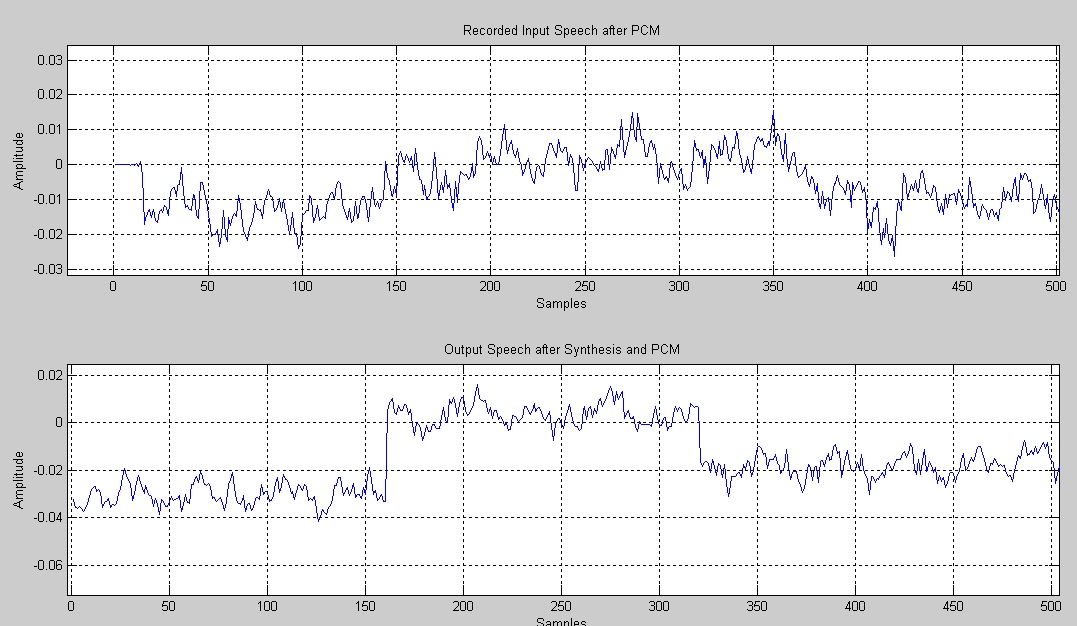
Im Anhang sind zwei Diagramme enthalten. Das linke ist die Aufnahme, das
rechte die Synthese. Das Signal selbst ist ein 1kHz-Sinus bei einer
Abtastung mit 44,1kHz. Wie man ansatzweise erkennen kann beträgt die
Periodendauer ca. 44 Samples (entspricht 44/44100 s bzw. 1002 Hz) im
linken Diagramm. Im rechten hingegen beträgt sie 160 Samples (bzw. 275
Hz). Die Frequenz meiner erzeugten Wellen ist also fast nur ein Viertel
so groß wie die ursprüngliche Frequenz. Jede erzeugte Cosinuswelle hat
also eine Dauer von 160 Samples und eine entsprechende
Phasenverschiebung.
So wie ich das mache kommt also nicht das gewünschte Resultat raus. Wie
kann ich die cos()-Funktion unter diesen Rahmenbedingungen in MatLab
richtig nutzen um die gewünschten Werte zu erzeugen?
Dann noch eine kleine Frage: Die Phaseninterpolierungsfunktion oben ist
eine Funktion in der Zeitbasis, in die cos()-Funktion setze ich also
eine gesampelte Version dieser Formel ein. Ist es korrekt t durch n (n =
0..S-1; S = Länge des Syntheseframes) zu ersetzen? Die gesampelte
Variante der Phasenfunktion ist:
pha_int = phase+freq*n+alpha*n^2+beta*n^3;
pha_int ist 1 Amplitudenwert für das aktuelle Sample, n entspricht also
jeweils der Samplenummer.
Man könnte mein Problem auch kürzer formulieren:
Wie erzeuge ich in MatLab eine Sinusfunktion mit beliebiger Frequenz und
Amplitude mit einer definierbaren Ergebnisarraygröße, ohne dabei mit
Skalierung der Arraygröße und der Frequenz durcheinander zu kommen?
Aha, das war die Frage.
Das geht so:
sinus=amplitude*sin((0:(Ergebnisarraygroesse-1))*2*pi*frequenz/abtastfre
quenz+phase)
Die Abtastfrequnz hattest Du nicht erwähnt, die spielt natürlich ne
Rolle, phase ist der Phasenoffset des Sinus zum Fenster.
Cheers
Detlef
btw:
(1)
>>waveform = [waveform;oooo];
nicht tun, Strukturen mit variabler Länge machen Matlab scripts sehr
langsam. Zu Anfang ein array passender Länge anlegen.
(2) 'for' Schleifen sind in 99% aller Fälle unnötig, siehe oben und sind
langsam.
Cheers
Detlef
Aah, Frequency Tracking nach McAulay & co? Wenn du Interesse bzw.
immernoch Schwierigkeiten hast kann ich dir mit MATLAB Code unter die
Arme greifen - allerdings angepasst an ein etwas anderes Problem. Bei
Interesse schreib mir eine Mail - die findest du im Link meines
Accounts.
Detlef _a wrote:
> Die Abtastfrequnz hattest Du nicht erwähnt
Ganz oben: 44100Hz.
> 2) 'for' Schleifen sind in 99% aller Fälle unnötig, siehe oben und sind
> langsam.
Recht hat er. Wenigstens initialisieren (foo = zeros(sizeX, sizeY,
...)), dann sind auch for-Schleifen erträglich schnell (mit dem Vorteil
der imho intuitiveren Lesbarkeit).
Cheers!
>>Detlef _a wrote:
>>> Die Abtastfrequnz hattest Du nicht erwähnt
>>
>> Ganz oben: 44100Hz.
Aha, das hatte ich nicht wahrgenommen. Vermutlich deshalb, weil ich nach
dem Satz:
>>Mein Problem ist vermutlich relativ trivial, aber ich muss ertmal etwas
>>drumherum erklären.
schlagartig die Lust zum Weiterlesen verloren hatte ;-)
Kommst Du Mittwoch mal wieder zum Biertrinken mit, würde mich freuen !?
Cheers
Detlef
Detlef _a wrote:
> Aha, das war die Frage.
>
> Das geht so:
> sinus=amplitude*sin((0:(Ergebnisarraygroesse-1))*2*pi*frequenz/>abtastfr
equenz+phase)
>
Vielen Dank, genau das hat mir erstmal weitergeholfen. Ich hab das
folgendermaßen eingebaut: 1 | output = [];
| 2 | out_int = [];
| 3 | waveform = [];
| 4 | finalwave = [];
| 5 | for j = 0:length(synthframe(:,1))-1
| 6 | out_int(j+1,1) = interpolate_amp(synthframe(j+1,1),matchframe(j+1,1),length(synthframe(:,1)),j);
| 7 | out_int(j+1,2:framesize+1) = interpolate_pha(synthframe(j+1,2),matchframe(j+1,2),synthframe(j+1,3),matchframe(j+1,3),length(synthframe(:,1)),j,Fs);
| 8 | out_int(j+1,3) = synthframe(j+1,3);
| 9 | end;
| 10 | output = [output;out_int];
| 11 | for j = 1:length(output(:,1))
| 12 | oooo = [];
| 13 | oooo = output(j,1)*cos((0:(framesize-1))*2*pi*output(j,3)/Fs+output(j,2:framesize+1));
| 14 | waveform = [waveform;oooo];
| 15 | end;
| 16 | finalwave = sum(waveform);
| 17 | wave = [wave;finalwave];
|
Dazu noch die Phaseninterpolierungsfunktion: 1 | function pha_int = interpolate_pha(phase,phase2,freq,freq2,S,n,F)
| 2 | freq = 2*pi*freq;
| 3 | freq2 = 2*pi*freq2;
| 4 | M = round((1/(2*pi))*((phase+freq*S-phase2)+(freq2-freq)*(S/2)));
| 5 | alpha = (3/(S^2))*(phase2-phase-freq*S+2*pi*M)-(1/S)*(freq2-freq);
| 6 | beta = (-2/(S^3))*(phase2-phase-freq*S+2*pi*M)+(1/(S^2))*(freq2-freq);
| 7 | pha_int = [];
| 8 | for i = 1:S
| 9 | pha_int = [pha_int,phase+alpha*(i/F)^2+beta*(i/F)^3];
| 10 | end;
|
Wie im Bild zu sehen ist stimmt die Frequenz jetzt. Und tatsächlich kann
man jetzt auch die synthetisierte Stimme halbwegs verstehen. Vorher
verstand man Worte nicht, jetzt kann man die Worte verstehen (auch wenn
es zugegebener Maßen noch sehr grottig klingt; da läuft also noch nicht
alles so wie es soll).
Die Stimme klingt noch relativ metallisch und verzerrt, was daran liegt,
dass die synthetisierten Wellen rechteckförmig sind.
Siehe auch Bilder:
http://www.worldofevanescence.de/martin/matlab/basically_working_01.jpg
http://www.worldofevanescence.de/martin/matlab/basically_working_02.jpg
Ich nehme an die Interpolationen laufen noch nicht so wie sie eigentlich
sollen. Besonders bei der Phase bin ich mir noch unsicher. Die
Phaseninterpolationsformel lautet ja:
Die Frequenz wäre damit ja im Cosinus enthalten. Den Frequenzteil (w*t)
hab ich jetzt weggelassen, damit ich die Frequenz separat von der
Funktion im Cosinus einfügen kann (wie oben). Damit hab ich doch jetzt
das t unterschlagen, richtig?
Detlef _a wrote:
>btw:
>(1)
>>>waveform = [waveform;oooo];
>nicht tun, Strukturen mit variabler Länge machen Matlab scripts sehr
>langsam. Zu Anfang ein array passender Länge anlegen.
>(2) 'for' Schleifen sind in 99% aller Fälle unnötig, siehe oben und sind
>langsam.
>
>Cheers
>Detlef
Danke für den Hinweis. Ich hätte nicht gedacht, dass das einen
Unterschied macht. Ich bin noch nicht dazu gekommen das umzusetzen,
probier ich dann später aus (mir gehts erstmal nur um die
Funktionalität; um die Performance kümmere ich mich am Ende).
T. H. wrote:
> Aah, Frequency Tracking nach McAulay & co? Wenn du Interesse bzw.
> immernoch Schwierigkeiten hast kann ich dir mit MATLAB Code unter die
> Arme greifen - allerdings angepasst an ein etwas anderes Problem. Bei
> Interesse schreib mir eine Mail - die findest du im Link meines
> Accounts.
Genau darum geht es. ;)
Mail ist gesendet.
Hallo Martin,
ich antworte mal hier im Forum auf deine Mail - ist sonst unfair anderen
gegenüber.
Martin Förster wrote:
> Was versteht man unter einem pitchadaptiven Hammingfenster und wozu dient
> es? Ich nehme stark an, dass es wohl unter Umständen noch etwas die
> Datenmenge bei der Analyse reduzieren kann. Momentan arbeite ich mit einem
> Hammingfenster fester Länge. Wenn dem so ist, ist das Fenster also nicht
> essentiell für den Algorithmus.
Ich habe das Paper gerade nochmal überflogen: So wie ich das sehe geht
es hier speziell um die Restriktion durch die Formel 20 im Paper und um
eine Fensterlänge von 2 1/2 mal dem Pitch des Signals. Essentiell ist
das in erster Näherung nicht, vor allem wenn man sich vorerst auf
stimmenhafte (voiced) Sprache beschränkt. In meiner Applikation (für
Musik) habe ich immer mit einer festen Analyselänge gearbeitet.
> Ich versuche gerade herauszufinden warum die synthetisierte Sprache so
> rechteckförmig ist. Wenn ich das hinbekomme sollte das die
> Verständlichkeit deutlich besser werden. Entweder stimmt da etwas noch
> nicht mit den ganzen Schleifen und der Funktion oder beim Peak-Matching
> komme komische Werte raus. Seltsamerweise tritt dieser Stufenbildung nur
> bei Sprache auf, jedoch nicht wenn ich einen einfachen Sinus als
> Eingangssignal nehme (obwohl dieser auch etwas kratzig klingt, was
> vermutlich noch an den Phasensprüngen liegen mag).
Ich kann dir nur empfehlen erstmal mit einfachen Signalen zu arbeiten.
Zum Beispiel mit drei überlagerten Sinussen, meinetwegen mit 200, 400
und 1000Hz. Dadurch werden Ergebnisse nachvollziehbar, du kannst Phasen,
Frequenzen und Tracking-Ergebnisse leicht nachvollziehen. Zudem verkürzt
sich in jedem Fall die Rechenzeit.
> Die Frequenz wäre damit ja im Cosinus enthalten. Den Frequenzteil (w*t)
> hab ich jetzt weggelassen, damit ich die Frequenz separat von der
> Funktion im Cosinus einfügen kann (wie oben). Damit hab ich doch jetzt
> das t unterschlagen, richtig?
Mit dem hier bin ich nicht glücklich: 1 | for i = 1:S
| 2 | pha_int = [pha_int,phase+alpha*(i/F)^2+beta*(i/F)^3];
| 3 | end;
|
Wie du schon schreibst, ist die Phase
phi(t) = phase + omega * t + alpha * t² + beta * t³
omega * t kann man schon weglassen, wenn man es bei der Synthese
berücksichtigt. Die Frage ist nur: Warum?
1 | for j = 0:length(synthframe(:,1))-1
| 2 | out_int(j+1,1) = interpolate_amp(synthframe(j+1,1),matchframe(j+1,1),length(synthframe(:,1)),j);
| 3 | out_int(j+1,2:framesize+1) = interpolate_pha(synthframe(j+1,2),matchframe(j+1,2),synthframe(j+1,3),matchframe(j+1,3),length(synthframe(:,1)),j,Fs);
| 4 | out_int(j+1,3) = synthframe(j+1,3);
| 5 | end;
|
Vllt hab ich gerade einen Knick in der Optik, aber warum ist deine
Amplitude nicht abhängig von der Zeit (Skalar) aber sehr wohl die Phase
(Vektor)?
Zum Schluss: Etwas mehr Kommentare in den Quelltexten wäre schön. :^)
Ede wrote:
> Kommst Du Mittwoch mal wieder zum Biertrinken mit, würde mich freuen !?
Auf jeden Fall!
Edit geht leider nicht. Nachtrag:
Wenn du Zeit hast guck mal hier rein, das Schema von McAulay wird
genutzt und etwas modifiziert:
http://elvera.nue.tu-berlin.de/files/0937Lajmi2003.pdf (S. 119)
http://www.alice-dsl.net/sound-inside/downloads/TH2008.pdf (S. 52)
T. H. wrote:
> Wie du schon schreibst, ist die Phase
>
> phi(t) = phase + omega * t + alpha * t² + beta * t³
>
> omega * t kann man schon weglassen, wenn man es bei der Synthese
> berücksichtigt. Die Frage ist nur: Warum?
Sorry, ich war da grad etwas verwirrt. Das omega*t hab ich in der
Phasenformel weggelassen, da diese ja nun direkt im cos-Argument stehen.
Die Anzahl der Samples (0:..) entspricht dabei dem t und das
2*pi*Frequenz entspricht ja dem Omega. Von daher passt das schon so wie
es sein soll.
T. H. wrote:
> Vllt hab ich gerade einen Knick in der Optik, aber warum ist deine
> Amplitude nicht abhängig von der Zeit (Skalar) aber sehr wohl die Phase
> (Vektor)?
Du hast da keinen Knick in der Otik. ;) Was ich da geschrieben habe ist
natürlich Murks. Richtig heißt es nun so: 1 | for j = 0:length(synthframe(:,1))-1 % !!! 0 to 255 == 1 to 256 in real!
| 2 | out_int(j+1,1) = interpolate_amp(synthframe(j+1,1),matchframe(j+1,1),length(synthframe(:,1)),j);
| 3 | out_int(j+1,2) = interpolate_pha(synthframe(j+1,2),matchframe(j+1,2),synthframe(j+1,3),matchframe(j+1,3),length(synthframe(:,1)),j,Fs);
| 4 | out_int(j+1,3) = synthframe(j+1,3);
| 5 | end;
| 6 | output = [output;out_int];
| 7 | for j = 1:length(output(:,1))
| 8 | oooo = [];
| 9 | oooo = output(j,1)*cos((0:(framesize-1))*2*pi*output(j,3)/Fs+output(j,2));
| 10 | waveform = [waveform;oooo];
| 11 | end; % waveform: rows = samples in frame; columns = sinuswave with framesize*values
| 12 | finalwave = sum(waveform); % finalwave contains now 1 row with framesize* values = sum of all sinewaves of this one frame!
| 13 | w = triang(length(finalwave(1,:))); % triangular window
| 14 | finalwave = finalwave.*w';
| 15 | wave = [wave;finalwave]; % summed sinewaves of all frames are stacked in rows
|
Macht ja auch keinen Sinn so wie es vorher war. Die Zeitabhängigkeit
kommt ja über die Cosinusfunktion für jedes der Samplepaare.
Ich hab jetzt auch schon die Dreiecksfensterung am Ende eingefügt.
T. H. wrote:
> Ich kann dir nur empfehlen erstmal mit einfachen Signalen zu arbeiten.
> Zum Beispiel mit drei überlagerten Sinussen, meinetwegen mit 200, 400
> und 1000Hz. Dadurch werden Ergebnisse nachvollziehbar, du kannst Phasen,
> Frequenzen und Tracking-Ergebnisse leicht nachvollziehen. Zudem verkürzt
> sich in jedem Fall die Rechenzeit.
Ok, hab ich gemacht. Zunächst mit einem 1 kHz Sinus und dann mit drei
überlagerten Sinussen.
http://www.worldofevanescence.de/martin/matlab/6_sinus.jpg
http://www.worldofevanescence.de/martin/matlab/testsignal.jpg
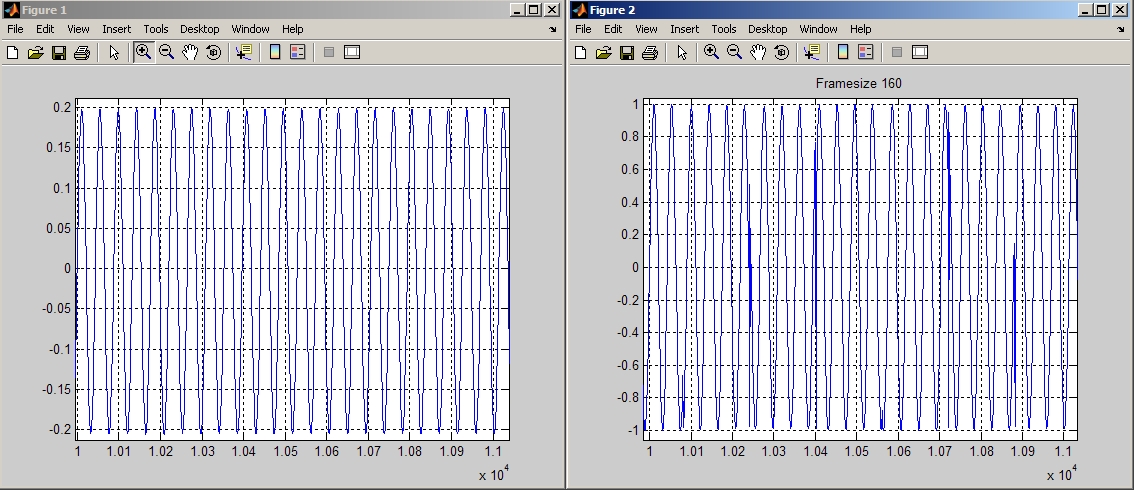
Auf beiden Bildern sind jeweils mind. 2 Frames dargestellt. Die Signale
werden nun nicht mehr eckig synthetisiert, sondern so wie sie sein
sollen. Durch die Dreiecksfensterung am Ende ist die synthetisierte
Funktion natürlich dreiecksförmig. Sieht etwas seltsam aus, klingt aber
ziemlich gut. Ich habe jetzt keine Probleme mehr die Originalstimme zu
erkennen. Selbst die Betonung bleibt erhalten (also man kann anhand der
synthetisierten Stimme problemlos den Sprecher unterscheiden). Ein paar
Soundartefakte/anomalien (oder wie man das nennen will) sind zwar
enthalten und natürlich klingt es etwas synthetisiert, aber im Prinzip
funktioniert es zufriedenstellend. :D
Im nachfolgenden Bild ist ein Wort dargestellt (links original, rechts
synthetisiert):
http://www.worldofevanescence.de/martin/matlab/6.jpg
Ist nicht perfekt, aber schon recht gut (nach meinem Verständnis).
Zumindest macht das Script nun weitestgehend was es soll.
T. H. wrote:
> Zum Schluss: Etwas mehr Kommentare in den Quelltexten wäre schön. :^)
Ok, ich hatte sie bis jetzt immer bewusst rausgelöscht beim Posten, weil
ich sie eher verwirrend fand. Stimmt natürlich, ohne Kommentare ist Code
schwer nachvollziehbar. Man sieht das selbst nicht so wenn man drin
steckt.
Ich hab gerade an der Stelle im Script bestimmt schon zig mal etwas
verändert und rauskommentiert, ich muss jetzt erstmal das ganze Script
überfliegen und alles Unnötige entfernen.
T. H. wrote:
> Edit geht leider nicht. Nachtrag:
>
> Wenn du Zeit hast guck mal hier rein, das Schema von McAulay wird
> genutzt und etwas modifiziert:
>
> http://elvera.nue.tu-berlin.de/files/0937Lajmi2003.pdf (S. 119)
> http://www.alice-dsl.net/sound-inside/downloads/TH2008.pdf (S. 52)
Danke für die Links. Ich habs mal kurz überflogen und es klingt
interessant. Momentan ändere ich aber erstmal nichts. Unser Projektthema
lautet ja eigentlich, dass wir den McAulay-Algorithmus in einen FPGA
reinbekommen sollen. Das MatLab-Modell dient dazu nur zum Verständnis
und natürlich der Simulation des Algorithmus. Soviel Zeit haben wir auch
nicht mehr. Wenn wir den Algorithmus so in der Form in den FPGA bekommen
wäre das schon sehr gut. Wenn am Ende noch Zeit bleibt werden wir
schauen wie man den Algorithmus (qualitativ) noch verbessern kann, aber
so wie es jetzt ist, ist es erstmal ausreichend.
Na wunderbar! :^)
Stell doch mal ein oder zwei Beispiele (Original & Synthese) hier rein -
das würde mich interessieren.
Cheers!
T. H. wrote:
> Na wunderbar! :^)
>
> Stell doch mal ein oder zwei Beispiele (Original & Synthese) hier rein -
> das würde mich interessieren.
>
> Cheers!
Ok. In der nachfolgenden Zip-Datei sind 4 Soundaufnahmen enthalten (2
mal ich selbst, einmal eine Frauenstimme aus einem Hörbuch, 1 mal
Rockmusik). Die Rockmusik klingt, wie erwartet, relativ scheiße. Aber
für sowas war der Algorithmus ja ursprünglich auch nicht vorgesehen.
Dennoch versteht man noch die Gesangsstimme. :)
http://www.worldofevanescence.de/martin/matlab/sound_examples.zip
Ich hab noch eine Frage zur Darstellung. Und zwar möchte ich das
Eingangssignal (Original) und das synthetisierte Ausgangssignal im Zeit-
und Frequenzbereich darstellen, sodass man problemlos die Unterschiede
sehen kann. Welche Darstellungsformen sind dafür am besten geeignet?
Den Zeitbereich kann ich, wie man weiter oben sehen kann, problemlos
darstellen. Auch der Frequenzbereich geht. Nur hab ich dann eben zwei
separate Diagramme für ein Signal. Außerdem kommt beim Frequenzbereich
noch das Problem hinzu, dass ich für jeden Frame eine Linie habe.
Ich weiß, dass man solche Darstellungen beispielsweise mit dem
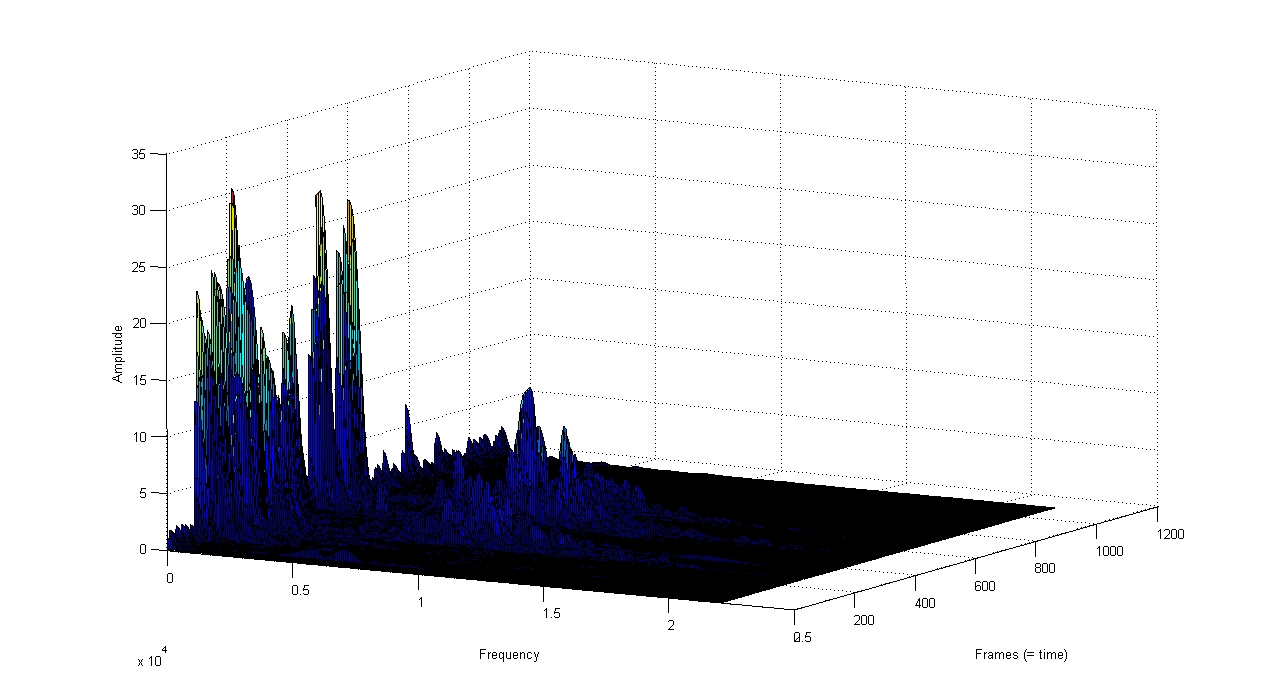
surf-Befehl als 3D-Diagramm darstellen kann. Nur irgendwie krieg ich das
nicht so richtig hin. Es funktioniert zwar, dass ich die Amplituden aus
der FFT über die Frames (entspräche dem Zeitbereich) und die Frequenz
hinweg (Frequenzbereich) mit surf darstellen kann, aber das was
rauskommt sieht relativ dunkel aus, sodass ich nah hinneinzoomen muss.
Das kann man dann aber nicht in ein Dokument einfügen. (siehe Anhang)
Ich hab auch ein wenig probiert das mit der Farbpalette ansehlicher zu
machen, nur irgendwie wird das auch nicht besser.
Gibt es noch eine bessere/sinnvollere Darstellungsform oder wie kann ich
den surf-Befehl so anwenden, dass das Ergebnis auch irgendwie verwendbar
in einem Schreibprogramm ist?
Danke für die Beispiele. Es hört sich zwar nicht so gut an wie ich
erwartet habe, aber man versteht es. Die Tage habe ich ein wenig weiter
geforscht und bin hierauf gestoßen. Das sieht auch interessant aus.
http://mtg.upf.edu/files/publications/CMJ-1990-xserra.pdf
Martin F. wrote:
> Den Zeitbereich kann ich, wie man weiter oben sehen kann, problemlos
> darstellen. Auch der Frequenzbereich geht. Nur hab ich dann eben zwei
> separate Diagramme für ein Signal.
Zeitbereich ist klar:
foo = rand(100, 1);
bar = rand(100, 1);
plot(foo);
hold on;
plot(bar, 'r');
hold off;
Für den Frequenzbereich kannst du durchaus mit surf arbeiten...
> Es funktioniert zwar, dass ich die Amplituden aus
> der FFT über die Frames (entspräche dem Zeitbereich) und die Frequenz
> hinweg (Frequenzbereich) mit surf darstellen kann, aber das was
> rauskommt sieht relativ dunkel aus, sodass ich nah hinneinzoomen muss.
> Das kann man dann aber nicht in ein Dokument einfügen.
Allerdings sollte man das drübergelegte Netz ausstellen. Wenn es zwei in
einem sein sollen kannst du ein wenig mit der Transparenz jonglieren.
Damit es übersichtlicher wird würde ich es monochrom machen
(hell/dunkel, evtl. unterschiedliche color maps). Eine andere Variante
ist, zwei separate Plots mit spectrogram zu erstellen (hier ein wenig
mit der Auflösung spielen).
Keine Ahnung mit welcher MATLAB Version du arbeitest, meine hat Probleme
mit dem Export von Oberflächenplots. Vektorgrafik sieht wirklich übel
aus. Abhilfe schafft
print -dbmp -r300 'file.bmp'
Cheers!
Meiner Meinung nach ist eine Darstellung eines Spektrogramms als
zweidimensionale Grafik viel anschaulicher. Die x-Achse entspricht dabei
der Zeit, die y-Achse der Frequenz und die Intensität ist farbcodiert.
Samplitude kann das beispielsweise auch sehr schön in Echtzeit, Audacity
kann es in einer Audiospur offline. Wie man das in Matlab macht, weiß
ich aber nicht.
Grüße,
Peter
Sorry für die lange Sendepause, hatte erstmal viel zu tun.
Das mit den Darstellung hab ich noch nicht hinbekommen. Vielleicht hab
ich mich auch etwas missverständlich ausgedrückt.
Ich habe nun nach der FFT ein Array mit 257 Zeilen (entspricht dem
halben Spektrum der 512er FFT) und N Spalten. N ist hierbei die Anzahl
der Frames die ich bearbeite. Somit sind die Spalten/Frames meine
Zeitbasis (1. Dimension), die Zeilen meine Frequenzbasis (2. Dimension)
und die Amplitudenwerte meine 3. Dimension. Dargestellt werden soll das
in 2D.
Ein Beispiel von dem was ich meine findet man unter:
http://cnx.org/content/m0505/latest/spectrum8.png
(ohne die untere blaue Grafik)
Welchen Befehl muss ich dafür ansetzen? surf scheint mir hierfür nicht
geeignet zu sein; plot ebenso wenig. Im Prinzip muss ich doch einfach
nur eine x-Achse mit N Werten und eine y-Achse mit 257 Werten haben, in
welche ich dann das Array scheibchenweise reinlege und die
Amplitudenwerte einfärbe. Mache ich den Spaß in zwei separaten Grafiken,
einmal Original und einmal Synthese, dann müsste das ja eine sehr
anschauliche Darstellung sein, wo man beides vergleichen kann.
> Eine andere Variante
> ist, zwei separate Plots mit spectrogram zu erstellen (hier ein wenig
> mit der Auflösung spielen).
spectrogram scheint es nicht direkt als Befehl zu geben.
spectrogram wäre genau das was du brauchst. Allerdings ist diese
Funktion Bestandteil der Signal Processing Toolbox. Wenn du die nicht
hast siehts schlecht aus. In diesem Fall musst du dir das selber bauen.
Hier würde ich z.B. surf verwenden - LineStyle auf none (in
graph3d) damit das Gitter verschwindet, azimuth auf 0 und elevation
auf 90 (in axis - view). Oder man macht sich das Leben leichter und
verwendet image (Skalierung beachten!).
Die Funktion für das Spektrogramm heißt specgram, farbige 2D-Darstellung
geht mit pcolor (das macht sogar intern genau das was T.H. "von Hand"
beschrieben hat).
1 | help specgram
| 2 |
| 3 | SPECGRAM Spectrogram using a Short-Time Fourier Transform (STFT).
| 4 | SPECGRAM has been replaced by SPECTROGRAM. SPECGRAM still works but
| 5 | may be removed in the future. Use SPECTROGRAM instead. Type help
| 6 | SPECTROGRAM for details.
|
Andreas Schwarz wrote:
> ... farbige 2D-Darstellung geht mit pcolor ...
Nett, kannte ich noch nicht.
Vielen Dank. Specgram scheint genau das zu sein was ich suche. Werde ich
dann gleich mal testen.
Es hat sich nun aber ein anderes Problem aufgetan. Wie in einem Beitrag
weiter oben zu sehen wird aus einem Sinus wieder ein Sinus (siehe auch
http://www.worldofevanescence.de/martin/matlab/6_sinus.jpg), jedoch
wegen der Dreiecksfensterung hat man sozusagen eine Art dreieckige
Einhüllende mit drin. Zum Vergleich auch noch ein Rechtsignal:
http://www.worldofevanescence.de/martin/matlab/int_recht.jpg
Für die Verständlichkeit von Sprache ist das (in der Konstellation) gut,
da man die Frameübergange quasi mit dem Holzhammer Richtung Null zwingt
und somit keine Sprünge drin hat. Schlecht ist das natürlich in Bezug
auf die Gesamtqualität (durch die Dreiecksfensterung hat man natürlich
gewisse Rausch/Nachhalleffekte) und die Funktionalität des Algorithmus',
da die Interpolationsformeln nach McAulay eigentlich glatte Übergänge
ermöglichen sollten, ohne dass man hinterher diese mit dem Holzhammer
"glättet".
Unser Betreuer meinte jedenfalls, dass wir das so nicht richtig haben.
Mal unabhängig davon habe ich noch zwei andere Varianten getestet:
(zuvor kommt das Peak-Picking)
Variante 1: 1 | wave = zeros(fftsize,length(spec(1,:))); %spec contains the peaks with zeros
| 2 | for i = 1:length(spec(1,:))
| 3 | wave(:,i) = real(ifft(spec(:,i),fftsize));
| 4 | end; %sine wave generation via IFFT
| 5 | output = [];
| 6 | output(1:framesize,1) = wave(1:framesize,1); % first frame (without overlap)
| 7 | for i = 1:length(wave(1,:))-1
| 8 | wavetemp = zeros(framesize,1);
| 9 | for j = 1:framesize
| 10 | wavetemp(j,1) = (wave(j+framesize,i)*(framesize-j)/framesize)+(wave(j,i+1)*j/framesize); %overlap of frames and application of triangular window
| 11 | end;
| 12 | output = [output;wavetemp];
| 13 | end;
| 14 | output = [output;wave(framesize+1:2*framesize,length(wave(1,:)))]; %last frame without overlap
|
Das ganze mit 512er FFT und 256er Framegröße. Diese Idee, dass
Dreiecksfenster so anzuwenden, hab ich von ein paar Kommilitonen. Nur
das Resultat klingt sehr schlecht. Dafür wird aber ein Sinussignal
perfekt synthetisiert. Etwas komplexeres, wie ein Rechteck, jedoch total
verhunzt (siehe angehängtes Bild im nächsten Beitrag).
Variante 2: 1 | for i = length(spec(:,1))+1:fftsize
| 2 | spec(i,1) = 0;
| 3 | end; %zero padding for ifft
| 4 |
| 5 | wave = zeros(fftsize,length(spec(1,:)));
| 6 | waveform = zeros(framesize,length(spec(1,:)));
| 7 | w = triang(framesize);
| 8 |
| 9 | for i = 1:length(spec(1,:))
| 10 | for j=1:length(spec(:,i))
| 11 | wave(:,i) = real(ifft(spec(:,i),fftsize));
| 12 | end;
| 13 | waveform(:,i) = wave(1:framesize,i).*w; %only framesize samples are taken
| 14 | end;
| 15 | output = [];
| 16 | for i = 0:length(waveform(1,:))-1
| 17 | for j = 1:length(waveform(:,i+1))
| 18 | output(i*framesize+j,1) = waveform(j,i+1);
| 19 | end;
| 20 | end;
|
Variante 2 mit 160er Framegröße und 512er FFT. Diese Variante produziert
exakt das selbe wie die ursprüngliche Interpolierungsgeschichte, nur mit
weniger Codezeilen.
Dass von der ifft nur die ersten 160 Realwerte genommen werden ist ok,
da die Amplituden am Ende wieder auf 1 normalisiert werden (die ersten
160 Realteile sind amplitudenmäßig zu klein; die Proportionen zwischen
ihnen sind aber mit dem Originalsignal identisch, sodass dies durch die
Normalisierung wieder ausgeglichen wird).
Irgendwo muss bei mir ein fundamentaler Denkfehler drin sein. Die
Interpolierung sollte ohne separates Dreiecksfenster auskommen, da sie,
laut der Formel im Artikel, ein solches bereits enthält. Somit hab ich
die Interpolierung fehlerhaft umgesetzt. Variante 1 sollte theoretisch
auch funktionieren, versagt aber bei allem was komplexer als ein Sinus
ist. Variante 2 ist im Prinzip eine kürzere Form der Interpolierung;
benötigt aber auch das Holzhammer-Dreiecksfenster.
Mittlerweile gehen mir auch die Ideen aus, wo in meinem Ansatz jetzt der
Fehler ist. Dass Variante 2 verständlich klingt ist klar, nur formal
gesehen ist sie fehlerhaft. Hat Jemand eine Idee was ich noch probieren
könnte oder wo der Fehler zu suchen ist?
Irgendwie will der Dateianhang heut nicht so recht.
Neue Erkenntnis: Lasse ich bei der ursprgl. Interpolation vom Anfang die
Dreiecksfensterung weg, so kommt sowas wie im Anhang raus.
Es sieht so aus als wären die Amplitudenniveaus bei manchen
Frameübergängen unterschiedlich. Das sollte dank der Interpolierung
eigentlich nicht passieren. Durch die Dreiecksfensterung wird der Fehler
verschleiert, aber die Folgen nicht ganz beseitigt. Wenn ich das
wegbekomme, dann sollte die Sprache deutlich besser klingen.
Moin moin!
Hab den Code mal überflogen. Das hier
1 | for i = length(spec(:,1))+1:fftsize
| 2 | spec(i,1) = 0;
| 3 | end; %zero padding for ifft
|
geht so nicht. Jedenfalls macht es nicht das was du scheinbar denkst. Du
bringst in das Spektrum eine Asymmetrie rein, dein rücktransformiertes
Ergebniss wird imaginär (und erklärt, warum du nur den Realteil
verwenden willst). Ich denke nicht, dass das dein Ziel war.
http://www.mikrocontroller.net/attachment/50846/a01.jpg
Das sieht mir stark nach einem Phasenfehler aus, der unsymmetrisch ist
(der Offset scheint nicht gleich zu sein - kann aber durchaus sein,
dass er es doch ist und die Unsymmetrie im Zeitbereich durch die
Akkumulation der Einzelwellen kommt).
Soweit erstmal, wenn ich etwas mehr Muße habe dann gucke ich mir den
Code mal genau an. :^P
Cheers!
T. H. schrieb:
> Moin moin!
>
> Hab den Code mal überflogen. Das hier
>
> 1 | > for i = length(spec(:,1))+1:fftsize
| 2 | > spec(i,1) = 0;
| 3 | > end; %zero padding for ifft
| 4 | >
|
>
> geht so nicht. Jedenfalls macht es nicht das was du scheinbar denkst. Du
> bringst in das Spektrum eine Asymmetrie rein, dein rücktransformiertes
> Ergebniss wird imaginär (und erklärt, warum du nur den Realteil
> verwenden willst). Ich denke nicht, dass das dein Ziel war.
Du hast Recht. Die Stelle ist murks, hatte aber keine Bedeutung, weil
vor dem Peak Picking: 1 | spec = zeros(fftsize,(fix(size(pla,1)/framesize)));
|
Ich hatte in dem Script viel rumeditiert und vergessen den Teil
rauszulöschen.
Andreas Schwarz schrieb:
> Die Funktion für das Spektrogramm heißt specgram, farbige 2D-Darstellung
> geht mit pcolor (das macht sogar intern genau das was T.H. "von Hand"
> beschrieben hat).
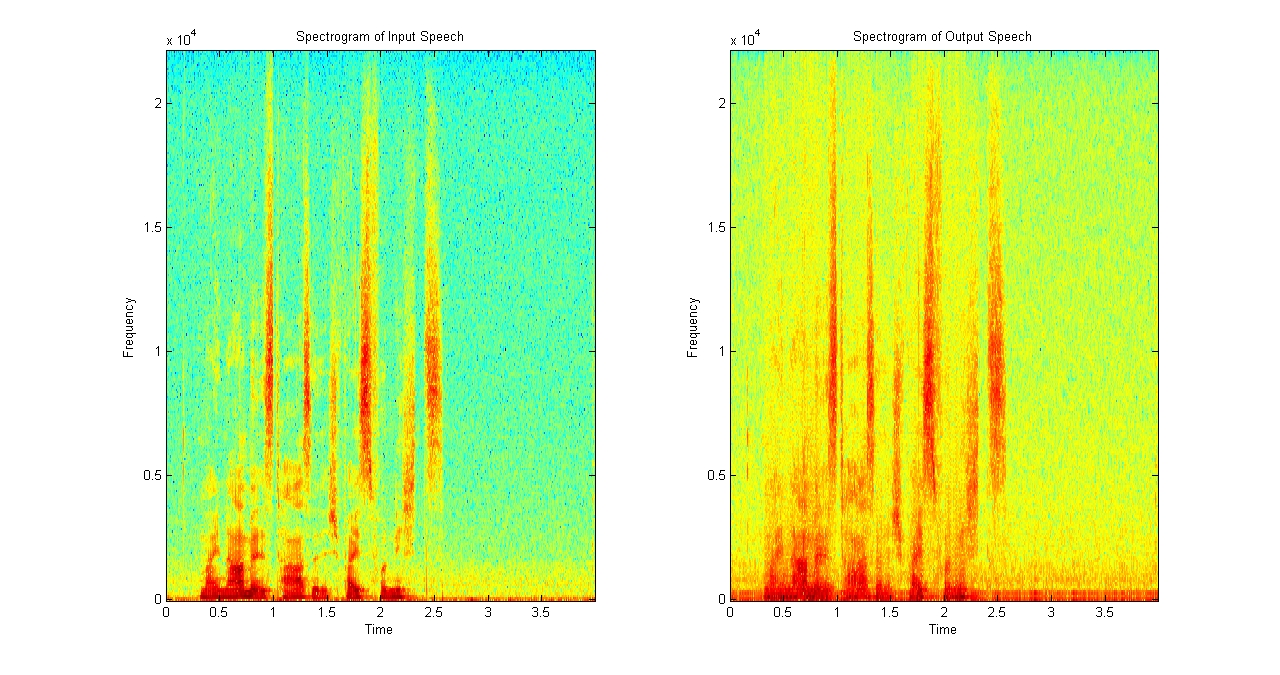
Nochmal vielen Dank. specgram hat wunderbar funktioniert (siehe Anhang).
Der Code dafür: 1 | figure(1)
| 2 | subplot(1,2,1)
| 3 | specgram(inputspeech,fftsize,Fs,hamming(fftsize))
| 4 | title('Spectrogram of Input Speech');
| 5 | subplot(1,2,2)
| 6 | specgram(outputspeech,fftsize,Fs,hamming(fftsize))
| 7 | title('Spectrogram of Output Speech');
|
Das ist übrigens das Spektrum mit Dreiecksfensterung.
Ohne Dreiecksfensterung siehts so aus:
http://www.worldofevanescence.de/martin/matlab/spectrogram_speech_ow_160-512.jpg
Wenn man das mal in Hinblick auf den Ausschnitt in a01.jpg betrachtet,
so werden durch den Sprung sehr viele Harmonische hervorgerufen.
Logisch, idealisiert betrachtet ist er ein Rechteck.
Ich hab jetzt herausgefunden wo der Fehler lag: Ich hab die FFT-Fenster
nicht halb übereinander geschoben. Dummer Denkfehler, aber so ist es
nunmal.
Und zwar muss man das FFT-Fenster bei der STFT immer nur
(beispielsweise) um einen halben Frame verschieben. Dadurch überlappt
man die Frames sozusagen übereinander. Schiebt man das dann durch die
IFFT, muss man die Frames am Ende wieder richtig zusammensetzen.
Ich möchte an der Stelle nicht den ganzen Code reintelllen oder
reinkopieren, aber hier die wirklich wichtigen Stellen:
Fensterung und Short Time Fourier Transform: 1 | fftsize = 512;
| 2 | ffthsize= 257;
| 3 | framesize = 256;
| 4 | hfsize = framesize/2;
| 5 | frametotal = fix((n*Fs)/framesize); %only framecount in real time!
| 6 | framecount = fix((length(pla)-framesize)/hfsize)+1;
| 7 | window = hamming(framesize);%0.011636*hamming(framesize);
| 8 | my_spec = [];
| 9 | for i = 0:(framecount-1)
| 10 | frame = pla((i*hfsize+1):(i*hfsize+framesize)).*window; % extracts one frame of input and multiplies it with Hamming window
| 11 | my_spec = [my_spec,(fft(frame,fftsize))]; % calculation of the STFT
| 12 | end;
| 13 | spectrum = my_spec(1:(fftsize/2)+1,1:framecount); % FFT spectrum is mirrored; only one half is needed
| 14 | real_spec = real(spectrum); % separates real parts
| 15 | imag_spec = imag(spectrum); % separates imaginary parts
| 16 | amp = sqrt(real_spec.*real_spec+imag_spec.*imag_spec); % amplitude calculation
| 17 | phase = atan2(imag_spec,real_spec); % phase calculation
| 18 | freq = [];
| 19 | freqcount= 1;
| 20 | for i = 0:(Fs/2)/(fftsize/2):(Fs/2) % generation of the frequencies
| 21 | freq = [freq;i,freqcount];
| 22 | freqcount = freqcount+1;
| 23 | end;
|
Danach kommt das Peak-Picking. Lässt man es weg, erhöht sich die
Qualität maßgeblich (das Ganze arbeitet dann als quasi-Loopback).
Hier werden die Frames wieder zusammengesetzt: 1 | wave = zeros(fftsize,framecount);
| 2 | for i=1:framecount %framecounter
| 3 | wave(:,i) = real(ifft(spec(:,i),fftsize));
| 4 | end;
| 5 | waveform = [];
| 6 | for i=1:hfsize % first half frame
| 7 | temp = wave(i,1);
| 8 | waveform = [waveform;temp];
| 9 | end;
| 10 | for i=1:framecount-1 % all frames except first and last half frame
| 11 | temp2 = [];
| 12 | for j=1:hfsize
| 13 | temp = (wave(j+hfsize,i)*(hfsize - j)/hfsize) + (wave(j,i+1)*j/hfsize);
| 14 | temp2 = [temp2;temp];
| 15 | end;
| 16 | waveform = [waveform;temp2];
| 17 | end;
| 18 | for i=(hfsize+1):framesize % last half frame
| 19 | temp = wave(j,1);
| 20 | waveform = [waveform;temp];
| 21 | end;
| 22 | while length(waveform) < length(pla)
| 23 | waveform = [waveform;0];
| 24 | end;
| 25 | soundsc(waveform,Fs);
| 26 | waveform = waveform./max(waveform);
| 27 | wavwrite(waveform,Fs,'synthetic_wave');
|
Der Trick beim Zusammensetzen ist, dass ich die Hälften richtig
überlagern muss.
Ich versuch das mal so zu visualisieren:
Eingangssignal Zeitbasis:
|----|----|----|----|
Ein Frame entspricht 4 x '-'. Das FFT-Fenster ist ebenso groß, wird aber
nur um eine halbe Framegröße weitergeschoben. Somit sieht es so aus:
|----|----|----|----| Zeitsignal
I II III IV Nummerierung der Zeitframes
|....|....|....|....| FFT-Frames (ungerade Indizes)
|....|....|....|....| FFT-Frames (gerade Indizes)
1 3 5 7 Nummerierung der FFT-Frames
2 4 6 8
Da ich eine 512er-FFT anwende, brauche ich nur die Werte 1:257. Das ist
das komplette Spektrum.
Nach dem Peak-Picking habe ich einen solchen Frame mit 257 Frequenzen
(falls durch Peak-Picking nicht Null gesetzt). Der wird in die
512er-IFFT geschoben. Die gibt 512 komplexe Werte raus. Davon betrachte
ich nur die Realteile und die Werte 1:256 (dies liegt in der Annahme,
dass die Eingangssignale der FFT periodisch kontinuierlich sind;
dementsprechend auch die Ausgangswerte der IFFT). Die Frames werden
halbframeweise zusammengesetzt. Jeder Halbframe besteht so aus 2
Komponenten, welche beide mit einer Flanke eines Dreiecksfensters
multipliziert werden. Der erste und der letzte halbe Frame können
natürlich nicht optimal zusammengesetzt werden.
Somit ergeben sich die Zeitframes wie folgt (.1 und .2 bedeuten
erste/zweite Hälfte des Frames):
I.1 = 1.1
I.2 = 1.2 + 2.1
II.1 = 2.2 + 3.1
II.2 = 3.2 + 4.1
...
Klingt verwirrend, aber wenn man sich das mal auf einem Blatt Papier
aufmalt und ein Glas Wein dazu trinkt, dann haut das hin. :)
Ich hab hier nochmal ein paar Soundbeispiele:
http://www.worldofevanescence.de/martin/matlab/sound_examples_2.zip
Die Qualität ist sehr gut, wenn auch nicht perfekt. Sprache ist fast so
gut wie das Original; Musik klingt etwas arm (logisch, wenn man das
Peak-Picking hat), aber dennoch überraschend gut verständlich. Mit etwas
Mühe liese sich das ganze System sicher noch optimieren, aber für unsere
Zwecke ist das absolut ausreichend.
Ich hab auch noch ein paar Graphen mit angefügt.
Auf jeden Fall nochmal ein großes Danke für die Hilfe hier. :D
Servus Martin!
Ich hatte ganz verpennt nochmal den Code zu beaugapfeln. Aber du hast es
ja offensichtlich mit eigenem Hirnschmalz sehr gut hinbekommen. Den
Handstand mit den Realanteilen der iFFT finde ich zwar etwas ulkig, aber
nun gut. ;^)
Ich dachte die überlappende DFT (STFT) war klar. :^D Btw: hier kann
man sicher noch an der Fensterform drehen. Man kann z.B. spektral
günstige Fenster so konstruieren, sodass sich diese bei einer
überlappenden Addition - wie beim Dreieck - neutral verhalten. Das
Verfahren MDCT (oder MDST) macht das z.B. so von Hause aus.
Sei's drum! Die Tracks hören sich wirklich gut an! In den Anhang habe
ich mal ein Vergleich meines Ergebnisses mit FTR gelegt. Hier ging es um
die Rekonstruktion ganzer weggefallener (null Information) Blöcke mit je
21ms Länge.
Cheers!
Mhh, das mit den Realteilen ist so ein Ding. Wie würde man es denn
richtigerweise machen? Ich hatte da echt eine ganze Weile drüber
nachgedacht, aber am Ende stellte sich das als funktionierend heraus.
Ich hatte das auch mathematisch betrachtet. Nimmt man die
Definitionsformel der inversen DFT, so kann man durch Umformung und
Behalten der Realteile an einer Stelle auf die Interpolierungsformeln
vom Paper kommen.
Das mit den überlappenden Fenstern ist halt echt ein dämlicher Fehler.
Aber scheinbar ist dieses Verfahren so selbsterklärend, dass in der
Literatur nicht wirklich detailiert darauf eingegangen wird. Wenn man
sich vorher noch nicht mit sowas beschäftigt hat, liegt das nicht immer
gleich auf der Hand. :P
Dein Beispiel klingt auch sehr interessant. Ich hätte nicht erwartet,
dass man solche Fehler so gut kompensieren kann.
Martin F. schrieb:
> Mhh, das mit den Realteilen ist so ein Ding. Wie würde man es denn
> richtigerweise machen?
Wenn ich dich recht verstanden habe hast du nur die erste Hälfte des
Spektrums invers transformiert? Wenn man nur eine Hälfte vom Spektrum
mitschleifen möchte dann kann man beispielsweise das Spektrum vor der
inversen Transformation an der Niquistfrequenz konjugiert spiegeln:
1 | sig = sin(0:2*pi/1023:2*pi);
| 2 | spec = fft(sig);
| 3 | recsig = ifft([spec(1:513) fliplr(conj(spec(2:512)))]);
| 4 | plot(sig); hold on; plot(recsig, 'r');
|
Vllt habe ich auch was falsch verstanden. 8^)
> Wenn ich dich recht verstanden habe hast du nur die erste Hälfte des
> Spektrums invers transformiert?
Jein. Ja, ich nehme nur die eine Hälfte des Spektrums. Aber nach dem
Peak-Picking ist dieses nicht mehr so wie es vorher war (also die
Amplituden einiger Frequenzen sind auf Null gestzt). Da kann ja
naturgemäß schon nicht mehr exakt das Gleiche rauskommen.
Deinen Code könnte man auch so schreiben: 1 | sig = sin(0:2*pi/1023:2*pi);
| 2 | sig = sig';
| 3 | spec = fft(sig);
| 4 | recsig = ifft(spec);
| 5 | plot(sig); hold on; plot(recsig, 'r');
|
Also im Prinzip: Signal->FFT->IFFT->Signal
So wie ich das mache, sieht das so aus: 1 | sig = sin(0:2*pi/1023:2*pi);
| 2 | sig = sig';
| 3 | spec = fft(sig,2048);
| 4 | spec = spec';
| 5 | respec = spec(1:1025);
| 6 | respec(1025:2048) = 0;
| 7 | recsig = real(ifft(respec,2048));
| 8 | e = 2*(recsig(1:1024)+fliplr(recsig(1025:2048)));
| 9 | plot(sig); hold on; plot(e, 'r');
|
Am Ende muss ich mit 2 multiplizieren, damit die Amplituden passen. Das
mache ich in meinem Script jedoch nicht. Allerdings muss ich sagen, dass
ich das dort ja auch anders mache, weil ich ja überlappende Fenster
habe. Ein Framestück setzt sich dann immer aus zwei Teilen zusammen. Am
Ende passt es ebend. Ich wüsste jetzt nicht so recht wie ich dein
Beispiel auf mein Script übertragen könnte.
Ist ja auch nicht so wichtig, es funktioniert ja so. ;)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}