Hallo, ich möchte gerne eine selektive Signalzuweisung in einem FPGA umsetzen. Hierzu frage ich mich, welche Lösung am geschicktesten ist und hätte gerne eure Meinung dazu. signal addr : std_logic_vector (11 downto 0); signal data_x : std_logic_vector (15 downto 0); signal REG1 : std_logic_vector (15 downto 0); signal REG2 : std_logic_vector (15 downto 0); signal REG3 : std_logic_vector (15 downto 0); 1. with addr select data <= data_x when "000000000000" or "000000000001" or "000000000010" ... "101000100000" (Syntax so nicht korrekt, nur zur kürzeren Schreibweise hier fürs Forum) REG1 when "101000100001", REG2 when "101000100010", REG3 when "101000100011", (others =>'0') when others; 2. data <= data_x when (ADDR>="000000000000" and ADDR<= "101000100000") else REG1 when ADDR="101000100001" else REG2 when ADDR="101000100010" else REG3 when ADDR="101000100011" else (others =>'0') when others; Aus Fall 2 folgt eine priorisierte sequentielle Decodierung welche ich so nicht haben möchte. Um jedoch Schreibarbeit zu sparen suche ich nach einer ähnlichen Lösung wie in Fall 2 dargestellt. Andernfalls müsse ich für jede Adresse die Zuweisung explizit angeben. Oder gibt es noch weitere elegante Lösungen?
Angehängte Dateien:
-

TechSchem.gif
10 KB
{kind=link}
> Aus Fall 2 folgt eine priorisierte sequentielle Decodierung welche ich > so nicht haben möchte. Nein. Weil du ausschliesslich Abhängigkeiten von ADDR drin hast (und zudem keinerlei Bereichsüberlappungen) wird das von der Synthese nicht priorisiert. Das ist ein ganz einfacher Mux. Hier einmal ein kleines Beispiel:
1 | library IEEE; |
2 | use IEEE.STD_LOGIC_1164.ALL; |
3 | use IEEE.NUMERIC_STD.ALL; |
4 | |
5 | entity Mux is |
6 | Port ( out1 : out STD_LOGIC; |
7 | out2 : out STD_LOGIC; |
8 | out3 : out STD_LOGIC; |
9 | in1 : in STD_LOGIC; |
10 | in2 : in STD_LOGIC; |
11 | in3 : in STD_LOGIC; |
12 | sel : in STD_LOGIC_VECTOR (2 downto 0)); |
13 | end Mux; |
14 | |
15 | architecture Behavioral of Mux is |
16 | |
17 | begin
|
18 | process (in1,in2,in3,sel) begin |
19 | case to_integer(unsigned(sel)) is |
20 | when 2#000# to 2#011# => out1 <= in1; |
21 | when 2#101# => out1 <= in2; |
22 | when 2#110# => out1 <= in3; |
23 | when others => out1 <= '0'; |
24 | end case; |
25 | end process; |
26 | |
27 | with sel select |
28 | out2 <= in1 when "0--", -- Aufpassen: das funktioniert mit der Synthese, |
29 | in2 when "101", -- gibt aber mit der Simulation Probleme, |
30 | in3 when "110", -- denn '-' ist ein definierter Wert wie '0' oder '1' |
31 | '0' when others; |
32 | |
33 | out3 <= in1 when sel>="000" and sel<="011" else |
34 | in2 when sel="101" else |
35 | in3 when sel="110" else |
36 | '0'; |
37 | end Behavioral; |
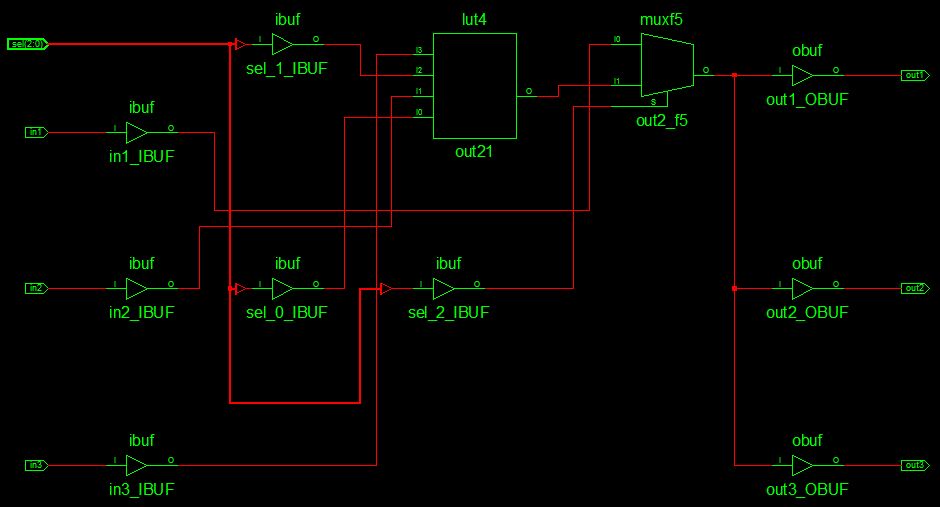
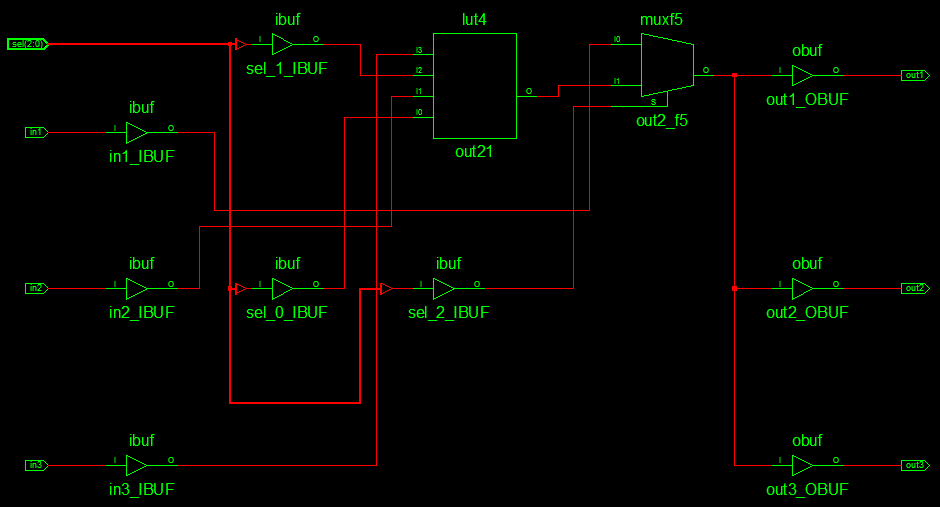
Und das Ergebnis? Obwohl die Synthese im RTL-Schaltplan noch Unterschiede bringt, wird letztlich für alle 3 Ausgänge das selbe erzeugt (siehe Technologie Schematic).
Lothar Miller schrieb: > Und das Ergebnis? > Obwohl die Synthese im RTL-Schaltplan noch Unterschiede bringt, wird > letztlich für alle 3 Ausgänge das selbe erzeugt (siehe Technologie > Schematic). Vielen Dank für den Hinweis und des guten Beispiels. Sehr Interessant auch, dass das Endresultat durch die verschiedenen Schreibweisen nicht beeinträchtigt wird. Ich habe mich jetzt zu folgender Schreibweise entschieden:
1 | with to_integer(unsigned(DSP_ADDR)) select |
2 | data <= data_x when 6#000# to 16#A20#, |
3 | REG1 when 16#A21#, |
4 | REG2 when 16#A22#, |
5 | REG3 when 16#A23#, |
6 | (others => '0') when others; |
Mit welchem Programm hast du denn das Schematic erzeugt?
Mit Xilinx ISE 12 --> Synthesize --> View Technology Schematic
bloede Frage: Was macht das statement mit den 6#ABC# denn?
1 | data <= data_x when 6#000# to 16#A20#, |
> 6#ABC#
Das wäre ein Fehler, aber es heißt zum Glück 6#000#
Das ist eine 0 zur Basis 6 ;-)
2#1001# = 10#9# = 9
2#1111# = 10#15# = 16#F# = 15
korrekt. Hier hatte sich ein Tippfehler eingeschlichen. Korrekterweise sollte es 16#000# anstatt 6#000# heißen. In diesem Fall wäre das Ergebnis wie bereits erwähnt das gleiche.
Hallo, mit Interesse hab ich diesen (doch etwas älteren) Beitrag gelesen, da wir im Moment ein ähnliches Problem haben. Lothar Miller schrieb: >> Aus Fall 2 folgt eine priorisierte sequentielle Decodierung welche ich >> so nicht haben möchte. > Nein. > Weil du ausschliesslich Abhängigkeiten von ADDR drin hast (und zudem > keinerlei Bereichsüberlappungen) wird das von der Synthese nicht > priorisiert. Das ist ein ganz einfacher Mux. Gilt das auch für (im Rahmen) beliebig viele Eingangskombinationen, oder nur für soviele, wie im FPGA halt in eine LUT passen? In deinem Beispiel hast du ja nur 4 Kombinationen. Was passiert, wenn zwar die Abhängigkeit von nur einem Signal bleibt, es sehr viele Eingangskombinationen werden, dann müssen im FPGA ja viele LUTs hintereinander geschalten werden. Hat dann immer noch jede Kombination die gleiche Priorität, unabhängig von der Art der Beschreibung? Ich frage, weil wir im Moment das Problem auf einem Spartan3 haben, dass das asynchrone, parallele Interface zu einem Microcontroller plötzlich Timing Probleme (teilweise falsche gelesene Werte) verursacht, nachdem es zuvor problemlos gelaufen ist. Wir haben eine Register-Bank im FPGA, die über die Zeit natürlich immer wächst, laufend kommen neue Features und Debug-Sachen dazu, die die Kombinatorik immer komplexer machen. (Ich erklär es mir so, dass der Mux im FPGA mit jedem zusätzlichen Register "tiefer" wird und somit das Timing zum Ausgang verschlechtert). Danke für eure Einschätzung, lg Harry
Harry schrieb: > Was passiert, wenn zwar die Abhängigkeit von nur einem Signal bleibt, es > sehr viele Eingangskombinationen werden, dann müssen im FPGA ja viele > LUTs hintereinander geschalten werden. Hat dann immer noch jede > Kombination die gleiche Priorität, unabhängig von der Art der > Beschreibung? Eine LUT ergibt, wenn sie hintereinender geschaltet wird einfach nur eine größere LUT. > (Ich erklär es mir so, dass der Mux im FPGA mit jedem zusätzlichen > Register "tiefer" wird und somit das Timing zum Ausgang verschlechtert). Es kommt darauf an, wie stark die Pfade ineinander verschachtelt und ausgdekodiert sind. > Ich frage, weil wir im Moment das Problem auf einem Spartan3 haben, dass > das asynchrone, parallele Interface zu einem Microcontroller plötzlich > Timing Probleme (teilweise falsche gelesene Werte) verursacht, nachdem > es zuvor problemlos gelaufen ist. Das kannst du doch einfach nachlesen: wenn der uC die Daten liest, solange die noch nicht stabil sind, dann musst du Waitstates einfügen oder schneller werden. Aber offenbar hast du diesbezüglich keine Constraints angegeben. Denn sonst würde dir die Toolchain schon was sagen, wenns knapp wird... Die allermeisten Probleme kommen bei asynchronen Zugriffen aus dieser Ecke: http://www.lothar-miller.de/s9y/categories/35-Einsynchronisieren
Hi Lothar, vielen Dank für deine rasche Antwort. Ok, dann ist das mit den mehreren Eingängen also geklärt. Und, du hast Recht, bei den Timing Constraints haben wir noch Nachholbedarf. Wir haben schon welche, aber anscheinend greifen sie nicht richtig. Ich muss mir die nochmal genauer anschauen, mich verwirrt der UCF Syntax immer wieder aufs Neue... und dem Constraints Editor von Xilinx vertrau ich auch nicht so ganz. Danke auch für den informativen Link, Thema Metastabilität ist immer interessant :-) Nur ist es schwierig, bei dem asynchronen EMIF, Sachen einzusynchronisieren, denn nach den empfohlenen zwei FF-Stufen ist der Microcontroller schon wieder mit anderen Dingen beschäftigt. Aber das schau ich mir auch nochmal genauer an. lg Harry
Harry schrieb: > bei dem asynchronen EMIF, Sachen > einzusynchronisieren Dort reicht es eigentlich, wenn man /RD und /WR einsychronisiert (siehe Link, ab Seite 29). Ggf. muß der Controller wait-states einlegen. Duke [1] http://www.pldworld.com/_xilinx/html/training/10_fpga_dsgn_tech.pdf
Du brauchst vor allem die Adresse so frueh wie moeglich. Das musst du am Controller halt einstellen. Damit kannst du den 'read' sauschnell hinbekommen. Und wie du ja bemerkt hast: Je mehr Register im FPGA, desto langsamer wird der 'read'...
Beim Lesen muss eigentlich gar nichts registriert sein, wenn das Lesen nicht Auswirkungen auf das gelesene Register hat (z.B. ein Interruptflag löscht). Und beim Schreiben dürfen die Daten ruhig verzögert abgelegt werden, sie müssen nur schon dort sein, wenn gleich danach wieder von der selben Adresse gelesen wird...
Super, danke für eure Inputs! Werde weitere Tests in der Richtung machen. (Langsam gleitet die Diskussion in offtopic ab, deshalb werde ich gegebenenfalls weitere Fragen extra posten!) Danke an alle, lg
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.