Ich verwende den arm-elf-gcc mit WinARM.
Ich verwende den AT91SAM7A3, ein ARM7 ohne Floating-Point Unit. D.h.
gleitkommaberechnungen müssen sowieso emuliert werden.
Im Tutorial hier:
http://www.mikrocontroller.net/articles/ARM-elf-GCC-Tutorial
wird behauptet, doubles werden mit 64 bit gespeichert, so wie es auch
IEEE-754 (http://de.wikipedia.org/wiki/IEEE_754) vorsieht.
Leider musste ich nun feststellen, dass double-variablen nur einem float
entsprechen. Das ist für mich ein großes Problem, weil die Berechnungen
mit float durch Rundungsfehler unbrauchbar werden.
Hat jemand schon diese Erfahrungen gemacht?
Kann man dem Compiler irgendwie mitteilen, dass er doubles richtig
umsetzen soll?
lg, Karl
>...>Hat jemand schon diese Erfahrungen gemacht?>...
Nein.
Randnotiz: mein WinARM-Projekt liegt auf Eis und das so lange, wie
Codesourcery in CS G++ lite das "fertig vorgekaut" bereitstellt, was ich
in meinen Entwicklungen benötige. Ehedem war die Toolchain in WinARM
etwas besonderes (v.a. keine Cygwin-Abhängigkeiten, syscalls nicht fest
"verdrahtet"). Das findet man inzwischen aber auch woanders. Falls
möglich also auf Codesourcery CS G++ lite oder alternativ Yagarto oder
DevkitARM umsteigen. Die sind moderner und werden besser gepflegt.
Danke Jörg für deine rasche Antwort.
So wie du es getestet hast, komme ich genau auch auf deinen Output.
Ich kenn das nm-tool aber nicht...
Nun, ich habe einen Digitalen Filter implementiert. Der ist mit double
stabil, und mit float instabil.
Obwohl ich ihn mit double kompiliert habe, entspricht die ausgegebene
Zahlenfolge der wie mit float - exakt!
Diesen Eindruck hatte ich schon mal, aber da habe ich es nicht näher
untersucht.
Jetzt hab ich ein Testprogramm geschrieben.
Das bestätigt jedoch, dass double 64 bit hat.
Sehr seltsam, anscheinend habe ich in meiner Filter-Implementierung
irgendwo etwas übersehen...
Hier die Ausgabe des Testprogramms:
Precision Test Program of floating point numbers:
Karl Zeilhofer schrieb:> Sehr seltsam, anscheinend habe ich in meiner Filter-Implementierung> irgendwo etwas übersehen...
Wer Floating point Arithmetik naiv anwendet, wird immer wieder derartige
Effekte erleben. Floating Point ist kein Allheilmittel für alles und
jedes und erfordert extreme Sorgfalt.
Lies mal das hier
http://docs.sun.com/source/806-3568/ncg_goldberg.html
Wenn du willst konstruier ich dir auch ein Beispiel, welches obwohl alle
Eingangszahlen exakt in Floating Point repräsentiert werden können (also
keine Rundungsfehler bei den Ausgangswerten) und ein und dasselbe
Verfahren symetrisch benutzt wird (einmal wird aus a b ausgerechnet,
einmal aus b a, wobei exakt der gleiche Code benutzt wird),
widersprüchliche Ergebnisse liefert :-) Floating Point ist manchmal
nicht die Lösung, sondern das Problem.
Karl heinz, danke für den Link.
Hab grad nicht die Zeit für dieses ausfühliche Dokument.
Mir ist sehr wohl bewusst, was bei Gleitkommazahlen passiert.
Mit
> Sehr seltsam, anscheinend habe ich in meiner Filter-Implementierung> irgendwo etwas übersehen...
hab ich gemeint, dass ich beim kompilieren was übersehen haben muss.
So war es auch. Denn für den PC kompiliert erhielt ich unterschiedliche
Ergebnisse für float und double - auf dem ARM auf einmal nicht.
Da ich aber nur ein typedef geändert habe, wurden die files die diese
Definition verwenden nicht neu kompiliert. Ein "clear all" hat geholfen.
Das war heute sowas wie eine selbsterfüllende Prophezeiung, da ich mir
schon mal eingebildet habe, dass der arm-elf-gcc double wie float
implementiert. Etwas peinlich, aber was solls.
Auf dein angesprochenes künstliches Problem bin ich aber neugierig.
Kannst du einen Code oder so posten?
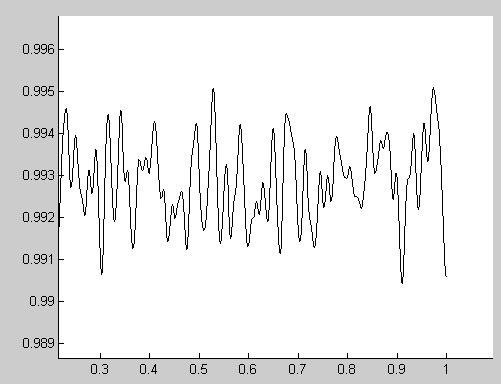
Im Bild sieht man die "eingeschwungene Sprungantwort" des von mir
implementierten Tiefpassfilters, der mit 2kHz Samplerate läuft und auf
50Hz Grenzfrequenz ausgelegt wurde, also Omega_c = pi/20. Entworfen mit
analogem Butterworth, 5. Ordnung und Bilinearer Transformation. Grausam,
was Rundungsfehler anrichten können. Der Filter wird auf einmal zum
Rauschgenerator.
Fixkommaberechnung (bzw. Ganzzahl-) kann aber vom Prinzip her auch nicht
besser sein als Gleitkomma, oder?
Ich sehe es als das beste an, das uns für numerischer Probleme zur
Verfügung steht, aber trotzdem hat alles seine Grenzen - und wenn die
Mantisse noch so viele Bits hat.
lg, Karl
Karl Zeilhofer schrieb:> Fixkommaberechnung (bzw. Ganzzahl-) kann aber vom Prinzip her auch nicht> besser sein als Gleitkomma, oder?
Das kommt auf den benötigten Wertebereich an. Prinzipiell kann ein
64bit-Fixkommawert bis ca. 3 signifikante Dezimalstellen mehr haben als
ein IEEE-754-double. Ausserdem kann auf 32bit-Architekturen meist auch
recht problemlos mit 128bit-Integern gearbeitet werden, das gibt dann
nochmal erheblich mehr Stellen.
Andreas
Karl Zeilhofer schrieb:> Auf dein angesprochenes künstliches Problem bin ich aber neugierig.> Kannst du einen Code oder so posten?
:-)
Das hab ich vor Jahren mal in comp.lang.c++ gepostet
1
For another example (taken from "Geometric and Solid Modeling, Christoph Hoffmann" )
2
3
4
Consider implementing a test of whether two points in the plane
5
are equal. Specifically assume that the point u is the intersection
6
of the pair of lines (L1,L2), and that the point v is the intersection
7
of the lines (L3,L4). The line equations are the input to the following
8
algorithm:
Also zu deutsch:
Wir wollen wissen ob 2 Punkte identisch sind. Die beiden Punkte
definieren sich dadurch, dass sie die Schnittpunkte von jeweils 2
Geraden sind.
L1 und L2 definieren Punkt A
L3 und L4 definieren Punkt B
und wir wollen wissen, ob A identisch ist zu B (natürlich mit einem
kleinen erlaubten Epsilon, wir sond ja brave Floating Point
Programmierer)
1
1. Compute the coordinates of u.
2
2. By substituting into the line equations L3 and L4, conclude that
3
u == v if both L3(u) and L4(u) are smaller then some tolerance.
Dazu benutzen wir dieses Verfahren:
Für jeden Punkt auf einer Geraden gilt: Seine Koordinaten eingesetzt in
die Geradengleichung ergeben 0 (natürlich erlauben wir eine kleine
Toleranz, wann kommt bei einer Berechnung schon exakt 0 raus, wenn 0
rauskommen sollte)
Wir machen daher:
Berechne den Schnittpunkt A und setze ihn in L3 und L4 ein.
Punkt B wird gar nicht berechnet. Es ist aber klar dass A identisch zum
nicht berechneten B sein muss, wenn A sowohl auf L3 als auch auf L4
liegt. Denn es gibt immer nur 1 Punkt, der gleichzeitig auf 2 Geraden
liegen kann, nämlich den Schnittpunkt der beiden Geraden.
Anstelle B explizit auszurechnen, genügt es also nachzusehen, ob A
dieser Schnittpunkt wäre. Ausgedrückt dadurch, das A auf L3 als auch auf
L4 liegen muss.
Clever Trick! Denn um einen Punkt in eine Geradengleichung einzusetzen
muss man nicht viel rechnen. Für einen Schnittpunkt muss man aber
vergleichsweise aufwändig rumrechnen. So gesehen wäre dieses Verfahren
viel einfacher!
1
Intuitively, this algorithm ought to be equivalent to a second version in
2
which the roles of u and v are reversed. Lets see if this is true.
3
4
5
(Hint: a1 denotes 'a' with a subcscript of 1)
6
7
8
1. The intersectoin (ux, uy) of the lines
9
10
11
a1*x + b1*y + c1 = 0
12
a2*x + b2*y + c2 = 0
13
14
15
is computed as:
16
17
18
D = a1*b2 - a2*b1
19
ux = (b1*c2 - b2*c1) / D
20
uy = (a2*c1 - a1*c2) / D
21
22
23
2. The point (ux,uy) is assumed to lie on the line a*x + b*y + c = 0
24
if the distance is small; that is if
25
|a * ux + b * uy + c| < eps * sqrt(a*a + b*b)
26
27
28
We assume eps to be 1E-10, a reasonable bound for double precision. We
29
ask whether u and v are incident using 2 different methods:
Jetzt fragen wir uns:
Wenn wir A ausrechnen und in L3 / L4 einsetzen UND da kommt raus, dass A
auf L3 / L4 liegt, dann müsste doch eigentlich auch die Umkehrung
gelten: Ich kann B ausrechnen und in L1 / L2 einsetzen. Muss das gleiche
rauskommen!
Denn wenn A gleich B ist, dann darf es keine Rolle spielen, ob ich über
A teste oder ob ich über B teste.
1
a. Compute the coordinates of u;
2
conclude that u == v iff u is on both L3 and L4.
3
b. Compute the coordinates of v;
4
conclude that u == v iff v is on both L1 and L2.
probiern wirs praktisch aus:
Man nehme 4 Geraden:
1
The line coefficients follow. Since pow(2,-23) ~ 1E-7, they differ
2
from 1 and 0 by amounts that are several orders of magnitude larger
These coefficients can be represented *exactly* in double precision.
Man beachte: Die Koeffizienten der Geradengleichungen sind so gewählt,
dass sie (die Koeffizienten) exakt darstellbar sind. Da ist also keine
Rundung im Spiel!
1
The coordinates of the points are now computed to be
2
3
4
u = ( 1.0, 1.0 )
5
v = ( 1.000030517578125, 1.000030517578125)
6
7
8
They are both exact.
und daqs sind die Koordinaten der jeweiligen Schnittpunkte A und B.
Genaue Analyse zeigt, dass beide bis auf die letzte Kommastelle stimmen
1
Moreover since ai*ai + bi*bi is aproximately between
2
1 and 2, the evaluation of the line equations after substituting the point
3
coordinates yields an error that can be compared directly with eps. We
4
obtain the values
5
6
7
L3(u) ~ -3E-5 > eps
8
L4(u) ~ -3E-5 > eps
9
10
11
from which we conclude that u connot be incident to v, since it is too
12
far from the lines L3, L4 whose intersection is v.
Punkt A in L3/L4 eingesetzt zeigt, dass der Punkt fast, aber nicht genau
genug auf L3 bzw L4 liegt. Die Schlussfolgerung daher: A liegt nicht auf
L3/L4, A ist daher nicht identisch zum Schnittpunkt L3/L4 (also B)
1
But we also obtain
2
3
4
L1(v) = 0 < eps
5
L2(v) ~ -7E-12 < eps
6
7
8
from which we must conclude that v is incident to u, since it lies
9
extremely close to both lines.
Aber aus Sicht von B sieht das ganz anders aus!
B liegt exakt auf L1 und nahe genug aus L2, sodas wir das nach als
'liegt drauf' akzeptieren. AUs Sicht von B liegt B auf L1/L2 so dass
sich hier gemäss Algorithmus ergibt: A ist identisch zu B
1
Therefore, although they ask the same geometric question, the two
2
computations yield contradictory results.
Was denn nun? Sind A und B gleich oder sind sie es nicht?
Aus Sicht von A sind sie nicht gleich
Aus Sicht von B sind sie gleich
Ein Widerspruch!
1
So what can one do about this.
2
Clearly: Don't use that algorithm. One could choose to do:
3
4
5
1. Compute the coordinates of u and v, by intersecting the
6
respective lines.
7
2. If the euclidian distance between u and v is smaller then eps,
8
decide u == v;
9
otherwise decide u != v
10
11
12
(Note that this computation is more 'expensive' then the previous one.
13
This time both points and an euclidian distance needs to be computed.
14
In the previous algorithm only one point is computed and the testing
15
does not involve a square root.)
16
17
18
This method is symetric, but it does not exhibit transitivity.
19
Specifically, we choose 3 points u, v and w such that u is incident
20
to v, v is incident to w, *but* u is not incident to w. We assume an
21
eps of 1E-10
22
23
24
u = ( 0, 0 ) v = ( 0, 0.8E-10) w = ( 0, 1.6E-10 )
25
26
27
Clearly the distance between the adjacent pairs is less then eps, but
28
the distance between u and w is greater then eps. So what is the correct
29
answer? Are all those points equal or are they not?
Nettes Beispiel!
@Andreas: 128 Bit Integer, die der Kompiler direkt unterstützt, ohne
Rechen-Funktionen/-Makros?? Wie geht das? long long int ist nämlich als
64 Bit Integer definiert (beim arm-elf-gcc).
@Martin Thomas: Das mit Code Sourcery ist mir ganz was neues.
Das muss ich mir bei Zeiten mal zu gemüte führen.
Worin genau bestehen die Vorteile? Wenn eine Toolchain mal läuft, bin
ich doch schon glücklich. Brauch ich da ständige Updates, wo ich wieder
vieles umkrempeln muss (oder ist das nicht der Fall)?
lg, Karl
Karl Zeilhofer schrieb:>...> @Martin Thomas: Das mit Code Sourcery ist mir ganz was neues.> Das muss ich mir bei Zeiten mal zu gemüte führen.> Worin genau bestehen die Vorteile?
Der m.M. nach größte Vorteil ist, dass die Leute von Codesourcery sehr
gut über die GNU Toolchain Bescheid wissen. Wenn man sich die
Änderungshistorie der Quellcodes für GNU binutils und GNU GCC anschaut,
tauchen sehr oft die Namen von Codesourcery Mitarbeitern auf. Verwundert
wenig, da m.W. CS von ARM dafür bezahlt wird, sich um die GNU Tools zu
kümmern. Falls nötig, kann man sich bei CS auch Support kaufen. Etwas
kostenlosen Support gibt es auch in einem Forum bei Codesourcery. Die
GNU Toolchain hinter Crossworks ist meines Wissens auch die Fassung von
CS. Bei einigen Anbietern findet man auch Beispielcode, der mit der CS
Toolchain getestet wurde (z.B. TI/LMI)
Nennenswerte technische Vorteile im Vergleich zu anderen vokompilierten
Toolchains für MS Windows Hosts kenne ich keine mehr. Vor Jahren war die
Unterstützung von ARMv7/thumb2/Cortex-M3 nur bei Codesourcery zu haben,
inzwischen ist diese aber auch in den offiziellen GNU Quellcodes
enthalten. Nachdem auch Yagarto nun für arm-eabi Target gebaut wird,
gibt es auch "unter der Haube" keine mir bekannten nenneswerten
Unterschiede mehr dazu. DevkitARM enthält noch ein paar zusätzliche
Dateien für die Eigenentwicklung von Anwendungen für Spielkonsolen (z.B.
GBA), diese Dateien kann man aber auch bei anderen Toolchains
nachrüsten. Pflege des GNUARM Packets ist meines Wissens inzwischen
eingestellt. WinARM liegt wie oben geschrieben auf Eis. Andere GNU
Packete habe ich nie genutzt.
Nachteil ist, das Codesourcery manchmal etwas hinterherhinkt mit der
Lite-Version (kommerzielle Version ist mglw. aktueller - kenne ich aber
nicht). Habe als Begründung gelesen, dass man bei CS viele eigene
Testläufte durchführt, bevor man ein Packet freigibt. Wahrscheinlich
(=Spekulation) will man aber einfach lieber ein Packet mit Support
verkaufen und bietet als Anreiz dafür häufigere Aktualisierung als bei
dem kostenlosen Lite Packet. Yagarto und DevkitARM sind manchmal mit
aktuellerem Quellcode erstellt.
> Wenn eine Toolchain mal läuft, bin> ich doch schon glücklich.
Ist ja auch o.k. Ich kenne einige, die an alten Toolchain-Versionen
festhalten. Manchmal weil man Anwendungen damit ausgiebig getestet hat
und nicht nochmal von Neuem testen mag. Manchmal einfach weil man
glaubt, alle Fehler in einer alten Version zu kennen und weiss, wie man
sie umgehen kann. Falls es aber hart auf hart kommt, wird man kaum auf
Unterstützung für eine alte Version hoffen dürfen, weder bei den
Kommerziellen noch bei "der Community".
> Brauch ich da ständige Updates, wo ich wieder> vieles umkrempeln muss (oder ist das nicht der Fall)?
Ständige Updates braucht man sicher nicht aber auch nicht zu lange
hinterherhängen, sonst gibt es umso mehr Verdruss, falls man updaten
muss, z.B. weil ein verwendeter Core nur von einer neuen Version der
Tools untersützt wird. Ich hatte aber nach Updates von CS G++ lite seit
vielen Versionen keine Probleme. Es kann aber durchaus sein, dass Fehler
im Quellcode erst dann auffallen, wenn nach einem Update eine neuere
Compilerversion mit besserer Optimierung genutzt wird. Häufig ist dann
z.B. ein fehlendes volatile Ursache für ein Fehlverhalten. Man kann das
dann nicht der neuen Version anlasten und viel "Umkrempeln" muss man für
die Korrektur solcher Fehler nicht.
Falls man älteren Quellcode für arm-elf hat, kann es beim Update auf
eine arm-eabi Toolchain vorkommen, dass die Attribute für ISRs nicht wie
erwartet funktionieren. Diese Attribute sind ohnehin für viel Verdruss
verantwortwortlich. APCS-Frame Compiler switch hat bei mir und Leuten,
die mich gefrage haben bisher geholften, um auch Code mit diesen
Attributen zum Laufen zu bringen. Ob das immer hilft, weiss ich nicht.
Mittel der Wahl z.B. bei ARM7TDMI ist m.M. auf die Attribute zu
verzichten und einen Assembler-Wrapper für IRQs zu verwenden. Kosten ein
paar Zyklen aber verhindert mehr als ein paar graue Haare. Atmel zeigt
in seien Beispielcodes ja, wie man dass für AT91SAM7 mit ARM7TDMI und
AIC implementieren kann. Falls man das schon so gemacht hat, ist beim
Toolchain-Update diesbezüglich kein Problem zu erwarten.
Hoffe, dieser längliche Text hilft etwas weiter.
Karl Zeilhofer schrieb:> @Andreas: 128 Bit Integer, die der Kompiler direkt unterstützt, ohne> Rechen-Funktionen/-Makros?? Wie geht das? long long int ist nämlich als> 64 Bit Integer definiert (beim arm-elf-gcc).
Bloss weil ein Compiler keinen Datentyp für 128 Bits hat musst du nicht
zwangsläufig drauf verzichten. Kann man sich programmieren. Und wenn man
C++ verwendet, dann merkt man das hinterher nicht einmal, jedenfalls
nicht im Quelltext. So richtig brandschnell ist das ohne 128-Bit
Maschine natürlich nicht.
Karl Zeilhofer schrieb:> @Andreas: 128 Bit Integer, die der Kompiler direkt unterstützt, ohne> Rechen-Funktionen/-Makros?? Wie geht das? long long int ist nämlich als> 64 Bit Integer definiert (beim arm-elf-gcc).
Aus kleineren Datentypen selbst bauen. Addition und Subtraktion sind
trivial, Multiplikation erfordert geringfügig mehr nachdenken, einzig
Division wird ein bisschen kniffliger, aber auch noch überschaubar.
Einfach mal an das in der Schule praktizierte schriftliche Rechnen
zurückdenken.
Grössere Fliesskomma-Typen von Hand zu bauen ist dagegen deutlich
komplizierter.
Andreas