Urban B. schrieb:> (der User muss nicht selbst eine Datenbank anlegen)
Das kann auch die Installationsroutine erledigen.
> wenn SQLite eingesetzt wird, kann> Part-DB z.B. vor jedem Datenbankupdate selbstständig ein Backup der DB> anlegen.
PHP kann doch ein Shell-Skript, bzw. das Windows-Äquivalent dazu
starten, oder nicht?
> Versteh mich nicht falsch - ich will nicht MySQL schlechtmachen oder so.
Mir geht es nicht um MySQL - hätten wir SQLite, dann wäre meine
Argumentation gegenüber MySQL dieselbe -, sondern um den Testaufwand.
Wir unterstützen zwei Betriebssysteme und wenn wir dann auch noch zwei
Datenbanken unterstützen, dann muß - wenn man es solide machen will -
schon der vierfache Testaufwand betrieben werden.
Wie gründlich man als Entwickler sowas dann letztlich macht, wirst du
selbst wissen. Mein innerer Schweinehund hat mich meistens davor
bewahrt, das auch nur annähernd gründlich genug zu tun und die Quittung
kam dann mit ziemlicher Sicherheit hinterher.
Markus Müller schrieb:> Ich habe das mit der Datensicherung der MySQL DB in EleLa relativ leicht> gelöst:> - Man wählt die Sicherungsdatei aus, die ist eine SQLite Datenbank
Warum sicherst du in eine SQLite DB?
Ich habe in einem Rails-Projekt recht gute Erfahrungen mit dem
Dump-Programm von MySQL gemacht. Das kickt man an und schon hat man eine
Textdatei, die alle Daten enthält, mit der man eine leere DB befüllen
kann und das Anlegen einer leeren DB kann man per Skript machen, das aus
der Installationsroutine angekickt wird.
Uhu Uhuhu schrieb:> PHP kann doch ein Shell-Skript, bzw. das Windows-Äquivalent dazu> starten, oder nicht?Uhu Uhuhu schrieb:> Ich habe in einem Rails-Projekt recht gute Erfahrungen mit dem> Dump-Programm von MySQL gemacht. Das kickt man an und schon hat man eine> Textdatei, die alle Daten enthält, mit der man eine leere DB befüllen> kann und das Anlegen einer leeren DB kann man per Skript machen, das aus> der Installationsroutine angekickt wird.
Ja, genau so hatten wir es schonmal eingebaut, das funktioniert auch
wunderbar solange man genügend Rechte hat, so ein Skriptauszuführen. Unser Ziel ist es aber, dass Part-DB weitgehendst auch
auf einem einfachen Webspace läuft - und da ist dann häufig nix mehr mit
Skripte ausführen, weil exec() vom Hoster gesperrt ist.
Urban B. schrieb:> OK damit weiss ich jetzt dass Windows da auch Slashes haben will, und> nicht Backslashes. Ich habe die start_session.php nochmals angepasst,> jetzt müsste es eigentlich für Linux und Windows korrekt funktionieren.> Die neue Version ist schon im SVN, einfach schnell updaten lassen.
Jo hab das update gemacht wie du sagtest,mit der aus der svn.
Also es läuft super. Fehler hinsichtlich dessen habe ich keine mehr.
Damit währe glaube ich mal diese Punkt abgehakt,oder.
Was is denn sonst noch so auf der Bug-list oder wie man das jetzt
nennt?.
Marco tom Suden schrieb:> Damit währe glaube ich mal diese Punkt abgehakt,oder.
Jup, die Pfad-Konstanten sollten somit (hoffentlich) auf allen Systemen
funktionieren.
Marco tom Suden schrieb:> Was is denn sonst noch so auf der Bug-list oder wie man das jetzt> nennt?.
Nun, da sind noch einige Sachen. Zum richtig Testen ist es eigentlich
noch zu früh denke ich. Eine ToDo-Liste gibts noch in der
Quellcode-Dokumentation (nicht alle Punkte betreffen aber die Version
0.3.0 - einige können noch länger warten, z.B. die System-Updates und
die Benutzerverwaltung).
Wenn du in der config.php die Einstellung "developer_mode" auf "true"
stellst, kommt ein neuer Menüpunkt "Entwickler-Werkzeuge" zum Vorschein,
dort drin ist dann der Link zur Quellcode-Dokumentation.
Wichtig wäre mir in nächster Zeit mal jemand der sich mit Datenbanken
etwas besser auskennt, da einige kompliziertere Abfragen noch nicht
genau das machen was sie sollten :-)
>z.B. dass es AUTOINCREMENT anstatt AUTO_INCREMENT heisst
Bei SQLite deklariere ich das Feld nur als "INTEGER NOT NULL PRIMARY
KEY" und es ist automatisch ein Autoincrement-Feld.
EleLa merkt sich den CREATE TABLE Code als SQLite Syntax. Dazu habe ich
eine Routine geschrieben "ChgQueryCreateSQL()", die biegt alles um auf
MySQL und PostgreSQL. Feldtypen, AutoIncrement und Indize.
Wichtig ist, dass Felder mit der gleichen Funktion auch den gleichen
Name haben, wie "ID" "Bezeichnung" "Beschreibung" "AendDatum" um die
globalen Funktionen besser nutzen zu können.
>Also werden nur die Backups als SQLite abgespeichert, oder kann man auch>direkt von Anfang an mit SQLite arbeiten?
EleLa kann SQLite, MySQL und PostgreSQL. Nach dem ersten Setup wird man
in der Regel mit SQLite beginnen um mal rein schnuppern zu können ob
einem überhaupt das Programm gefällt und es sind auch schon einige
Datensätze (Widerstände) vorhanden.
Jederzeit kann man auf MySQL oder PostgreSQL wechseln.
Wenn man in EleLa nur die Verbindungsdaten des MySQL Servers eingibt, so
kann EleLa mit einem Tastenklick eine neue Datenbank samt aller Tabellen
automatisch anlegen (der MySQL-User muss natürlich die Rechte haben).
Ein Import der bestehenden SQLite Daten in MySQL und man hat innerhalb
weniger Sekunden MySQL als Server.
Mit EleLa ist der Wechsel der Datenbank ein Kinderspiel und alles
Menügeführt.
Markus Müller schrieb:> EleLa merkt sich den CREATE TABLE Code als SQLite Syntax. Dazu habe ich> eine Routine geschrieben "ChgQueryCreateSQL()", die biegt alles um auf> MySQL und PostgreSQL. Feldtypen, AutoIncrement und Indize.
So ähnlich habe ich mir das auch vorgestellt. Da Part-DB bis jetzt nur
MySQL unterstützte, sind alle Updatebefehle auch in MySQL Syntax
gespeichert. Nun habe ich in der Updateroutine einfach mal ein
rudimentärer "Konverter" eingebaut, der eben z.B: ein "AUTO_INCREMENT"
automatisch durch ein "AUTOINCREMENT" ersetzt, oder sowas wie
"ENGINE=InnoDB" entfernt.
Ich habe auch festgestellt dass mit SQLite das hier nicht funktioniert:
1
INSERT INTO tabelle SET key=value
Das hier funktionier hingegen bei SQLite und MySQL:
1
INSERT INTO tabelle (key) VALUES (value)
Schlussendlich müssen wir Entwickler uns einfach darauf einigen, dass
immer die zweite Variante verwendet wird. Das sollte eigentlich kein
Problem sein, an andere Code-Guidelines halten wir uns ja auch.
Und wenn wirklich mal eine fehlerhafte Datenbankabfrage in ein Release
kommt - davon geht die Welt auch nicht unter. Ausser der Fehler passiert
beim Datenbankupdate und es existiert kein Backup - dieses Problem
hätten wir aber bei SQLite sicher nicht, und wenn wir dein System für
das Backup einer MySQL Datenbank auch noch einbauen, existiert das
Problem auch bei MySQL nicht mehr.
Markus Müller schrieb:> EleLa kann SQLite, MySQL und PostgreSQL. Nach dem ersten Setup wird man> in der Regel mit SQLite beginnen um mal rein schnuppern zu können ob> einem überhaupt das Programm gefällt
Genau sowas finde ich für Einsteiger sehr wichtig, darum "kämpfe" ich ja
auch für die Unterstützung von Part-DB für SQLite :-)
Auch der Installer, den es bisher noch nicht gab, finde ich wichtig. Ich
bin mir ziemlich sicher, dass schon viele Leute Part-DB runtergeladen
haben, dann aber mit dem Einrichten überfordert waren und es aufgegeben
haben. Das ist natürlich schade, denn mit einem benutzerfreundlichem
Installer und SQLite-Datenbank lässt sich das weitgehendst verhindern.
Dass man auch einfach zwischen verschiedenen Datenbanken wechseln kann,
ist für den Anfang sicher nicht notwendig. Später, wenn wir mehr Zeit
für solche Sachen haben, könnte man natürlich immernoch einen
"Konverter" einbauen. Momentan haben wir aber wichtigere Sachen zu tun
:-)
EDIT:
Ich habe in unseren "Issues" gleich mal einen Link eingefügt zur
Beschreibung der Datenbanksicherung von Markus:
https://code.google.com/p/part-db/issues/detail?id=3
>Später, wenn wir mehr Zeit für solche Sachen haben
Ja, klar. War bei mir am Anfang auch nicht drin und kam erst später.
Macht erst mal weiter mit eurem Projekt und bringt das auf einen guten
Stand.
Irgend wann einmal, wenn PartDB gut läuft können wir auch mal dran gehen
und EleLa/PartDB von der Datenstruktur her angleichen, dann wäre EleLa
und PartDB mit dem gleichen Datenbestand nutzbar. Ein Front-End für
Lokal und eines Internettauglich :-)
Im moment sind die noch zu verschieden, hier die EleLa-DB:
http://www.mmvisual.de/Hilfe/EleLa/TutorialDB/TutDB.htm
Habe grad mal alles durch gegangen,als ich bei Zeige/Statistik an kam,
dauerte es erst ne weile bis überhaupt was angezeigt wurde.
Zuerst war es ne art Fehlermeldung, wo was von Time-out 30 sec etc
stand.
Nach dem 2 Versuch öffnete sich die Seite wie sie soll, jedoch fiel mir
sofort das Karo mit (?) ins Auge. Das sicherlich das € darstellen
soll,was glaub ich mal an der Kodierung UTF-8 / ANSI liegt.
Demnach habe ich in der config.php unten diese Auskommentierte Zeile
wieder Aktiv gemacht:
$manual_config['money_format']['de_DE'] = '%!n Euro';
Naja dementsprechend wird nun statt dem Karo (Euro) ausgegeben.
Nach Änderung dieser Zeile in:
$manual_config['money_format']['de_DE'] = '%!n €'
war das Karo wieder da,logisch da die config.php in ANSI Kodiert ist,
als ich sie jedoch in UTF-8 Kodiert hab war das € Zeichen da.
Wie es sicherlich soll.
Ich weis grad nicht,ob das bei euch auch so ist.
Daher dachte ich ich schreib euch das einfach mal.
Daß ein unbedarfter User mit MySQL zurecht kommt, ist letztendlich eine
Frage der Anleitung, nach der er das macht. Er muß ja nicht im Einzelnen
verstehen, was da passiert, aber so lange er ein Kochrezept an die Hand
bekommt, nach dem er nur Schritt für Schritt vorgehen muß, dann wird er
diese Klippe nehmen. Und wenn man ihn zusätzlich noch mit Skripten
versorgt, die ihn vor Tippfehlern bewahren, dann ist das ganz prima.
Nur ohne, oder mit einer Doku, die in Rudimenten über diverse Threads,
Quelltexte, Readmes etc. pp. verstreut ist, wird das natürlich nix.
Marco tom Suden schrieb:> Habe grad mal alles durch gegangen,als ich bei Zeige/Statistik an kam,> dauerte es erst ne weile bis überhaupt was angezeigt wurde.
Das ist eine Baustelle, wo mal einer mit mehr Datenbankkenntnissen ran
muss :-) Momentan habe ich dort noch improvisiert, es werden Sachen mit
PHP berechnet, die man (mit genügend Kenntnissen^^) auch mit SQL machen
könnte, damit würde es gleich viel schneller gehen.
Marco tom Suden schrieb:> Nach dem 2 Versuch öffnete sich die Seite wie sie soll, jedoch fiel mir> sofort das Karo mit (?) ins Auge. Das sicherlich das € darstellen> soll,was glaub ich mal an der Kodierung UTF-8 / ANSI liegt.
Ja, das ist auch ein Problem von mir, weil ich da den Durchblick noch
nicht habe mit den verschiedenen Kodierungen :-( In der Konfiguration
kannst du übrigens noch den Zeichensatz ändern, bringt das auch nichts
wenn du den auf "ISO-8859-1" stellst?
In den *.tmpl Dateien sind bisher auch alle ä, ö, ü ganz normal
gschrieben, und nicht in HTML-Schreibweise (ä). Bei mir
funktioniert das zwar, ich weiss aber nicht inwiefern das auch mit
anderen Systemen kompatibel ist, bzw. ob sich das mit dem Ändern des
Zeichensatzes lösen lässt.
Udo, hast du hier vielleicht den Durchblick und kannst mir mit ein paar
Sätzen mal einen kurzen Crashkurs geben? :-D
Ich finde die Schreibweise ä mühsam und würde sie gerne vermeiden
wenn es geht.
Markus Müller schrieb:> Irgend wann einmal, wenn PartDB gut läuft können wir auch mal dran gehen> und EleLa/PartDB von der Datenstruktur her angleichen, dann wäre EleLa> und PartDB mit dem gleichen Datenbestand nutzbar. Ein Front-End für> Lokal und eines Internettauglich :-)> Im moment sind die noch zu verschieden, hier die EleLa-DB:> http://www.mmvisual.de/Hilfe/EleLa/TutorialDB/TutDB.htm
Uiuiui, da hat sich ja schon richtig was ergeben bei dir :-D Gegen deine
DB sieht unsere ja grad mickrig aus :-D
Also falls das mal was werden würde mit dem Angleichen von
Part-DB/EleLa, dann sicher erst in ferner Zukunft. Unsere nächsten Ziele
sind erstmal die Version 0.3.0 stabil zu machen. Dann arbeiten wir auf
die Version 1.0.0 hin, wo nochmal sehr viel getan werden muss: es soll
eine Benutzerverwaltung und ein automatisches System-Update geben.
Die Arbeit geht uns erstmal also nicht aus :-)
Uhu Uhuhu schrieb:> Daß ein unbedarfter User mit MySQL zurecht kommt, ist letztendlich eine> Frage der Anleitung, nach der er das macht.
Ja stimmt schon auch. Aber dann müssen wir wieder zwei verschiedene
Anleitungen schreiben, eine für Windows und eine für Linux. Ist also
auch doppelter Aufwand.
Naja - ich werde mir in den nächsten paar Wochen das Thema SQLite
nochmal genauer anschauen und ausführlichere Tests machen. Dann kann man
besser abschätzen wieviel Mehraufwand es wirklich bedeutet. Bis jetzt
habe ich aber den Eindruck, mit ein paar SQL Guidelines kriegen wir das
sehr gut in den Griff.
Urban B. schrieb:> Ja, das ist auch ein Problem von mir, weil ich da den Durchblick noch> nicht habe mit den verschiedenen Kodierungen :-( In der Konfiguration> kannst du übrigens noch den Zeichensatz ändern, bringt das auch nichts> wenn du den auf "ISO-8859-1" stellst?
Ja das geht auch, meinte nur wenn man das auf utf-8 hat geht's nicht.
Mit ISO-8859-1 geht's auch mit auskommentierter Zeile.
Unter utf-8 jedoch nicht.
Wenn du nichts dagegen hast,würde mir gern mal die ganze
Konstruktion,etwas genauer ansehen,vtl Find ich ja ne Lösung dafür ;-).
Marco tom Suden schrieb:> Ja das geht auch, meinte nur wenn man das auf utf-8 hat geht's nicht.> Mit ISO-8859-1 geht's auch mit auskommentierter Zeile.>> Unter utf-8 jedoch nicht.>> Wenn du nichts dagegen hast,würde mir gern mal die ganze> Konstruktion,etwas genauer ansehen,vtl Find ich ja ne Lösung dafür ;-).
Ach so, dann ist doch alles gut? :-)
Genau für diesen Fall gibts doch die Möglichkeit, den Zeichensatz zu
ändern.
Meine Vermutung ist, dass Zeichen wie ä halt immer funktionieren,
unabhängig vom Zeichensatz. Verwendet man aber ganz normale Zeichen wie
ä, ö, ü, so muss man dem Browser halt mitteilen wie er die Zeichen
interpretieren soll. Ist aber nur eine Vermutung von mir, da ich
eigentlich mit Webseiten-Entwicklung nicht viel am Hut habe.
Vielleicht sollte man in der Installationsroutine eine Erkennung des
Betriebssystems einbauen. Wird Windows verwendet, soll der Zeichensatz
automatisch auf ISO-8859 gesetzt werden, ansonsten auf utf-8.
Urban B. schrieb:> Ach so, dann ist doch alles gut? :-)> Genau für diesen Fall gibts doch die Möglichkeit, den Zeichensatz zu> ändern.
Ja aber mir ist grade aber aufgefallen das andere texte wie der Button
(Einstellungen übernehmen) plötzlich unter ISO Merkwürdige Zeichen
enthalten.
Wenn man die config.php dann aber wieder in utf konvertiert ist alles
easy,und sauber.
Da gibts aber sicherlich ne Lösung für.
Ich versuche grad der Statistik bei zu bringen die Daten aus der
Database direct aus zu lesen,vtl läuft es dann schneller.
Zu dem Kodierung's Konstrukt,fällt mir sicher auch was ein ;-)
Die Zeichen in der DB sollten immer UTF-8 sein, denn wenn man mal einen
Server-Umzug von Windows <> Linux macht, dann sollte der eine Export
beim anderen Import immer gehen.
Zum zweiten ist UTF-8 unter Linux Standard.
Mit htmlentities() sollte das ganze dann auch korrekt gewandelt werden.
>Uiuiui, da hat sich ja schon richtig was ergeben bei dir :-D
Bei meiner Versino 0.x war das auch noch so. ;-)
Um so mehr PartDB nutzen um so mehr Anforderungen und entsprechend
Tabellen/Felder wird es geben.
Foreign Key's nutze ich nicht, denn SQLite kann das nicht. Wird alles im
Programm geprüft.
Markus Müller schrieb:> Foreign Key's nutze ich nicht, denn SQLite kann das nicht. Wird alles im> Programm geprüft.
Grad die Foreign Keys muessen vom Datenbanksystem ueberprueft werden.
Die Integritaet der Datenbank wird ja schliesslich hauptsaechlich von
fehlerhaften Referenzen in andere Tabellen bedroht.
Die Ueberpruefung der referenziellen Integritaet muss unbedingt vom DB
System gemacht werden. Dazu muessen die Foreign Keys natuerlich in den
Schemadefinitionen definiert werden. Das wird vermutlich eine ganze
Menge Fehler aufbringen, weil ein INSERT dann schlicht nicht moeglich
ist, wenn es den Key, auf den verwiesen wird, noch nicht gibt. In dem
Fall muss man dann die Statements im PHP Code umstellen.
Viele Gruesse
Christoph
Markus Müller schrieb:> Die Zeichen in der DB sollten immer UTF-8 sein, denn wenn man mal einen> Server-Umzug von Windows <> Linux macht, dann sollte der eine Export> beim anderen Import immer gehen.
Ja, das macht Sinn. Ist bei Part-DB auch standardmässig auf UTF-8
gesetzt, kann jedoch geändert werden. Theoretisch könnte man diese
Möglichkeit vielleicht auch noch rauswerfen, also dass es immer mit
UTF-8 arbeitet, da dies ja jeder MySQL Server unterstützen sollte.
Markus Müller schrieb:> Foreign Key's nutze ich nicht, denn SQLite kann das nicht.
Sicher? http://www.sqlite.org/foreignkeys.html
Stimmt, jetzt kann SQLite das. Ab der Version 3.6.19.
Ich nutze schon viel länger SQLite und damals konnte SQLite das nicht.
Wenn Du jetzt SQLite mit Foreign Keys unter Linux nutzt, dann musst Du
auch sicherstellen, dass die DLL libsqlite.so auch wirklich eine
aktuelle ist. Ältere Linux-Distris haben zum Teil nicht die neueste
libsqlite mit dabei. Ich meine sogar, als ich vor einem halben Jahr mal
Debian in eine VBox installiert habe, dass dort auch nur eine
V3.6.irgendwas dabei war und nicht mal eine 3.7.x.
Bei mir überprüft EleLa die Konsistenz der Daten und ich zeige auch
entsprechende Fehlermeldungen. Wenn das nur die DB macht, dann kommen
kryptische Meldungen auf den Bildschirm und das ist immer schwierig zu
handeln. Foreign Keys sind nur für den Notfall da, falls man mal ein Bug
in der Programmierung drin hat, um die Daten zu schützen.
EleLa macht auch alles mit UTF-8, da das Standard der
Programmierumgebung Lazarus ist. Damit wäre schon mal der erste
Meilenstein für das Zusammenspiel gelegt ;-)
Bei MySQL lege ich die DB immer mit dem Code an:
1
CREATE DATABASE IF NOT EXISTS <######> DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci
Also hier unter Ubuntu 12.10 ist SQLite 3.7.13 in den offiziellen
Paketquellen. Wie es auf den gängigen Webservern aussieht, weiss ich
aber nicht.
Part-DB hat eigentlich eh schon "relativ hohe" Anforderungen an die
PHP-Version (mind. 5.3), da sollte die hohe Anforderung bei SQLite auch
nicht mehr so schlimm sein. Obwohl man meinen würde, dass heute PHP5
Standard ist, musste ich meinen Webhoster anfragen ob Sie mir PHP 5.3
installieren könnten. Die haben immer noch PHP4, und per Webfromular
kann man es auf 5.2 aktualisieren lassen. Mit einer persönlichen Anfrage
aktualisieren sie aber auch auf 5.3.
Alternativ könnte man immernoch im Installer schreiben:
Entweder SQLite >= 3.6.19, oder dann MySQL.
Obwohl auch in Part-DB seit der Version 0.3.0 die Beziehungen sehr genau
"von Hand" überprüft werden, ist die Überprüfung durch das
Datenbanksystem per Foreign Keys doch nochmal ein Plus an Sicherheit.
Das werde ich noch einbauen müssen, bis jetzt werden nämlich auch bei
MySQL keine Foreign Keys verwendet...
@Markus
Habe ich das eigentlich richtig verstanden, dass bei SQLite die Indizes
innerhalb der ganzen Datenbank eindeutig sein müssen, bei MySQL aber nur
innerhalb einer Tabelle?
Nein, bei mir sich die Indizes nur innerhalb der Tabelle eindeutig. Das
geht so wie ich oben gezeigt habe.
Aber, wenn man bei SQLite den letzten Datensatz (z.B. ID = 15) löscht,
dann ist der letzte ID = 14. Wenn man nun einen neuen Datensatz anlegt,
so erhält der wieder 15. Bei MySQL würde der Datensatz die ID = 16
erhalten. SQLite ist schon eine wirklich einfache Datenbank, SQLite ist
fast wie ein Müllschlucker und frisst alles.
Besonders musst Du auf Datums und Zeitfelder aufpassen und die besser
als Float Felder abfragen und selbst in das gewünschte Anzeigeformat
wandeln, damit habe ich ständig Probleme. Das Datumsfeld als Float
abzufragen macht bei MySQL keine Probleme.
Die SQLite Version kannst Du mit dem SQL Befehl einfach auslesen:
SELECT sqlite_version() AS Vers
Markus Müller schrieb:> Nein, bei mir sich die Indizes nur innerhalb der Tabelle eindeutig. Das> geht so wie ich oben gezeigt habe.
Hmm okay, dann muss ich mir das nochmal anschauen...Ich bekam immer eine
Fehlermeldung (blabla...already exists...blabla) wenn ein gleichnamiger
Index bereits in einer anderen Tabelle vorhanden war.
Momentan habe ich aber für sowas keine Zeit. Ab Freitag kanns dann
wieder richtig weitergehen :-)
Vermutlich muss nur der Name des Indizes eindeutig sein, den also so
z.B. benennen:
TabellenName_FeldName_IX
Probiere das mal.
PS: Index oder Primary key? Nicht dass wir jetzt da was durcheinander
bringen.
Bei sieht das z.B so aus:
CREATE TABLE IF NOT EXISTS bauteil (
ID INTEGER NOT NULL PRIMARY KEY,
: :
AendDatum DATETIME);
CREATE TABLE IF NOT EXISTS bauteillager (
ID INTEGER NOT NULL PRIMARY KEY,
: :
AendDatum DATETIME);
Hinterher erzeuge ich die Indizes.
Markus Müller schrieb:> Vermutlich muss nur der Name des Indizes eindeutig sein, den also so> z.B. benennen:> TabellenName_FeldName_IX
Ja, genau das meine ich. Es gibt bei uns verschiedene Tabellen, die
gleichnamige Spalten haben. Also eine Spalte "A" in Tabelle 1, und eine
Spalte "A" in Tabelle 2. Bei beiden ist diese Spalte A auch ein Index
(nicht Primary Key) und heisst ebenfalls "A". Und da bekomme ich bei
SQLite eine Fehlermeldung dass so ein Index schon existiert, bei MySQL
hingegen funktioniert es. Daher kam die Vermutung, dass die Namen der
Indizes bei MySQL nur innerhalb einer Tabelle eindeutig sein müssen, bei
SQLite jedoch innerhalb der ganzen Datenbank.
Aber ein "Tabellenname_" vor die Index-Namen zu setzten ist natürlich
kein Problem, werde ich dann vermutlich so einbauen.
Als nächstes (wenn ich wieder Zeit habe) werden aber erstmal überall
Transaktionen eingebaut, damit im Fehlerfall immer ein Rollback
durchgeführt werden kann. Und dann den Installer noch etwas ergänzen,
die Importfunktionen wieder zum laufen bringen, einige kleine Bugs
beheben usw usw... :-)
mfg
Transaktionen machen die DB auch schneller, da erst mal nichts auf die
Disk geschrieben wird.
Wenn Du fragen zu SQL Befehlen hast kannst Du mir auch eine PN
schreiben.
Ich kann Dir auch Teile von EleLa schicken, damit Du siehst wie ich z.B.
"ChgQueryCreateSQL()" mache oder Felder im Update hinzufüge.
Ist halt Lazarus/Pascal und Du müsstest das umschreiben auf PHP.
Markus Müller schrieb:> Transaktionen machen die DB auch schneller, da erst mal nichts auf die> Disk geschrieben wird.
Aber beim COMMIT wird synchron geschrieben, was den
Geschwindigkeitsvorteil wieder relativiert.
Transaktionen dienen der Datenkonsistenz und nicht der Geschwindigkeit.
Erst wenn alle SQL-Aktionen innerhalb einer Transaktion fehlerfrei
ausgeführt wurden, dann erfolgt das COMMIT und die Datenbank schreibt
die Daten endgültig auf Platte. Wenn man Geschwindigkeit herausholen
möchte, dann per Indices, Keys, Cache etc. SQLite ist zwar nett, aber
nur für Einzelplatzsysteme wirklich sinnvoll. Erstmal ist MySQL zu
bedienen, danach kann man ja auch andere Systeme unterstützen. Die Idee,
SQLite als Backup zu nutzen, finde ich interessant.
Markus Müller schrieb:> Wenn Du fragen zu SQL Befehlen hast kannst Du mir auch eine PN> schreiben.> Ich kann Dir auch Teile von EleLa schicken, damit Du siehst wie ich z.B.> "ChgQueryCreateSQL()" mache oder Felder im Update hinzufüge.
Danke für das Angebot, ich werde darauf zurückkommen wenn ich soweit bin
und Hilfe brauchen könnte.
> Ist halt Lazarus/Pascal und Du müsstest das umschreiben auf PHP.
Das ist kein Problem, ich habe auch mal Pascal programmiert :-)
Udo Neist schrieb:> SQLite ist zwar nett, aber> nur für Einzelplatzsysteme wirklich sinnvoll.
Und genau das wird für viele Benutzer schon genügen, da sie zu Hause
Part-DB nur auf einem einzigen Computer benutzen ;-)
Udo Neist schrieb:> Erstmal ist MySQL zu> bedienen, danach kann man ja auch andere Systeme unterstützen.
Jup, erstmal hat MySQL schon Priorität. Wenn es aber kein grosser
Aufwand ist, kann ich SQLite auch schon in die Version 0.3.0 einbauen.
Übrigens habe ich gerade noch das Auslesen der SVN-Revision mit einem
PDO Objekt gelöst, funktioniert wunderbar :-) Wird in nächster Zeit mal
noch ins SVN hochgeladen...
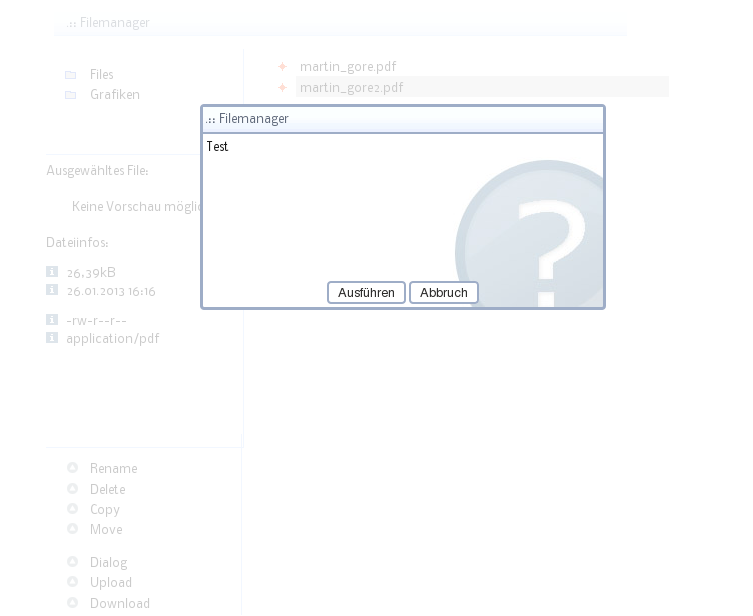
Der Filemanager nimmt so langsam Formen an. Ich habe heute am
Dialogsystem gearbeitet. Damit ihr euch schon mal ein Bild davon machen
könnt, habe ich zwei Screenshots angehängt.
Das ganze basiert auf zwei Javascript-Klassen mit eigenem Namensraum.
Derzeit fehlt noch die Anbindung der Dialogbuttons an frei definierbare
Funktionen innerhalb der DOM-Klasse. Das Aussehen der Elemente ist in
CSS-Dateien definiert. Im Moment erbt der Dialog noch ein Element der
Webseite, wird aber noch korrigiert. Der PHP-Unterbau benötigt eine
fileIO-Klasse.
Sieht doch schonmal ganz gut aus!
Vielleicht könnte man ja den Bereich "Ausgawähltes File / Dateiinfos"
noch auf die rechte Seite nehmen, dann ist es auch besser für
Bildschirme mit niedriger Auflösung (z.B. 1366x768) geeignet. Die blöden
Netbooks haben einfach eine viel zu niedrige vertikale Auflösung...
Ach ja, falls das noch nicht geplant ist: Ganz oben wäre noch eine
Navigations-Zeile sinnvoll, damit man sieht in welchem Ordner man sich
gerade befindet. Also sowas in der Art:
1
media / footprints / TQFP
Wobei natürlich jedes dieser Elemente ein Link sein könnte um zum
jeweiligen Ordner navigieren zu können.
Bin auf jeden Fall schonmal gespannt auf den fertigen Dateimanager :-)
Urban B. schrieb:> Sieht doch schonmal ganz gut aus!
Danke :-)
> Vielleicht könnte man ja den Bereich "Ausgawähltes File / Dateiinfos"> noch auf die rechte Seite nehmen, dann ist es auch besser für> Bildschirme mit niedriger Auflösung (z.B. 1366x768) geeignet. Die blöden> Netbooks haben einfach eine viel zu niedrige vertikale Auflösung...
Dank CSS lassen sich die 4 Blöcke (Ordner, Dateiinfo, Commands und
Explorer) frei verschieben. Nur die IDs sind fest vergeben.
> Ach ja, falls das noch nicht geplant ist: Ganz oben wäre noch eine> Navigations-Zeile sinnvoll, damit man sieht in welchem Ordner man sich> gerade befindet. Also sowas in der Art:>
1
media / footprints / TQFP
> Wobei natürlich jedes dieser Elemente ein Link sein könnte um zum> jeweiligen Ordner navigieren zu können.
Breadcrumb-Navigation? Existiert schon auf der globalen Ebene der
Webseite und wäre für den Dateimanager recht einfach zu adaptieren. Die
Navigation enthält aber keine Links. Werde ich mal für die nächste Runde
umsetzen.
> Bin auf jeden Fall schonmal gespannt auf den fertigen Dateimanager :-)
:-)
Udo Neist schrieb:> Dank CSS lassen sich die 4 Blöcke (Ordner, Dateiinfo, Commands und> Explorer) frei verschieben. Nur die IDs sind fest vergeben.
OK super!
Udo Neist schrieb:> Breadcrumb-Navigation?
Lol, wusste gar nicht dass das so heisst xD Aber ja, laut Wikipedia ist
das genau das was ich meinte :-) Halt wie in Nautilus, Windows Explorer
usw.
Sind eigentlich die beiden Ordner links oben auf dem Screenshot
aufklappbare Menüs wo dann die ganze Verzeichnisstruktur ersichtlich
ist?
Urban B. schrieb:>> Breadcrumb-Navigation?>> Lol, wusste gar nicht dass das so heisst xD Aber ja, laut Wikipedia ist> das genau das was ich meinte :-) Halt wie in Nautilus, Windows Explorer> usw.>> Sind eigentlich die beiden Ordner links oben auf dem Screenshot> aufklappbare Menüs wo dann die ganze Verzeichnisstruktur ersichtlich> ist?
In meinem Beispiel sind das zwei fest vergebene Verzeichnisse, die
unterhalb eines gemeinsamen Verzeichnisses liegen. Ausserhalb dieser
Verzeichnisse kann der Filemanager nicht zugreifen.
Natürlich lassen sich diese Verzeichnisse auch ändern. Entsprechend dem
Einsatzzweck muss man die Konfiguration und Suchfunktion anpassen. Ich
habe mal die Dateisuchfunktion rauskopiert, damit man mal eine
Vorstellung davon hat.
Udo Neist schrieb:> In meinem Beispiel sind das zwei fest vergebene Verzeichnisse, die> unterhalb eines gemeinsamen Verzeichnisses liegen. Ausserhalb dieser> Verzeichnisse kann der Filemanager nicht zugreifen.
Jup, ich denke schlussendlich soll der Benutzer die Verzeichnisse
"img/footprints/", "/img/iclogos/" und "media/" im Dateibrowser zur
Verfügung haben. In "img/..." darf er aber nur Leserechte haben, da die
dort enthaltenen Dateien von Part-DB verwaltet werden, also auch Updates
bekommen. Fummelt der Benutzer da drin rum, gibts nur ein Chaos.
Für die Dateien des Benutzers ist der Ordner "media/" vorhanden, dort
kann er tun und lassen was er möchte. Part-DB hingegen wird dort keine
Dateien ablegen.
Möchte ein Benutzer z.B. die Footprint-Bilder auf eine andere Art und
Weise sortiert haben, so muss er unseren Footprint-Ordner nach media/
kopieren und dort nach seinen Wünschen organisieren.
Urban B. schrieb:> Udo Neist schrieb:>> In meinem Beispiel sind das zwei fest vergebene Verzeichnisse, die>> unterhalb eines gemeinsamen Verzeichnisses liegen. Ausserhalb dieser>> Verzeichnisse kann der Filemanager nicht zugreifen.>> Jup, ich denke schlussendlich soll der Benutzer die Verzeichnisse> "img/footprints/", "/img/iclogos/" und "media/" im Dateibrowser zur> Verfügung haben. In "img/..." darf er aber nur Leserechte haben, da die> dort enthaltenen Dateien von Part-DB verwaltet werden, also auch Updates> bekommen. Fummelt der Benutzer da drin rum, gibts nur ein Chaos.
Ich kann ja den Filemanager soweit ergänzen, dass er neben den
Verzeichnisnamen auch Rechte verwaltet. Wäre also sowas wie:
1
$dir[0]['dir']="img/footprints/";
2
$dir[0]['name']="Footprints";
3
$dir[0]['type']="image";
4
$dir[0]['mode']="ro";
5
$dir[1]['dir']="img/iclogos/"
6
$dir[1]['name']="IC Logos";
7
$dir[1]['type']="image";
8
$dir[1]['mode']="ro";
9
$dir[2]['dir']="media/"
10
$dir[2]['name']="Media";
11
$dir[2]['type']="";
12
$dir[2]['mode']="rw";
>> Für die Dateien des Benutzers ist der Ordner "media/" vorhanden, dort> kann er tun und lassen was er möchte. Part-DB hingegen wird dort keine> Dateien ablegen.>> Möchte ein Benutzer z.B. die Footprint-Bilder auf eine andere Art und> Weise sortiert haben, so muss er unseren Footprint-Ordner nach media/> kopieren und dort nach seinen Wünschen organisieren.
Jupp. Ich werde zwar erst einmal nur einzelne Dateien verwalten können,
aber wenn das klappt, dann ist es auch kein Problem, mehrere Dateien zu
bearbeiten. Es bleibt nur zu überlegen, ob auch Verzeichnisse bearbeitet
werden dürfen oder ob die Struktur einmal festgelegt wird.
Wenn der Filemanager in der jetzigen Form fertig ist, werde ich ihn ins
Part-DB-Repo rüberziehen, damit wir den zusammen weiter entwickeln
können. Die Software steht unter CC-BY-SA 3.0-Lizenz.
Udo Neist schrieb:> Ich kann ja den Filemanager soweit ergänzen, dass er neben den> Verzeichnisnamen auch Rechte verwaltet. Wäre also sowas wie:> [...]
Das wäre super! Dann kann er auch ganz einfach angepasst werden wenn mal
noch neue Verzeichnisse hinzukommen.
Udo Neist schrieb:> Jupp. Ich werde zwar erst einmal nur einzelne Dateien verwalten können,> aber wenn das klappt, dann ist es auch kein Problem, mehrere Dateien zu> bearbeiten. Es bleibt nur zu überlegen, ob auch Verzeichnisse bearbeitet> werden dürfen oder ob die Struktur einmal festgelegt wird.
Was meinst du mit "Verzeichnisse bearbeiten"? Umbenennen, Kopieren, neue
Verzeichnisse erstellen? Das sollte natürlich in "media/" schon möglich
sein, sonst muss der Benutzer ja all seine Dateien in einen Topf werfen.
Oder eben das ganze Verzeichnis "img/footprints" (rekursiv) nach
"media/footprints" kopieren sollte auch möglich sein.
Erstmal ist aber wichtig dass man Dateien hochladen und hochgeladene
Dateien auswählen kann, die man dann den Bauteilen zuordnen kann...
Ich bin grad die Updateschritte auf die DB-Version 13 nochmal am
anpassen. Es werden noch diverse Änderungen vorgenommen: Umstellung auf
InnoDB, zusätzliche TIMESTAMP-Spalten, und - sehr wichtig - es werden
Foreign Keys hinzugefügt.
Es gibt aber immernoch einen Updateschritt, der nicht funktioniert. Ich
wäre froh wenn mir hier jemand helfen könnte, da meine SQL-Fähigkeiten
begrenzt sind ;-)
Es geht um folgendes:
Bisher (bis DBv12) war es erlaubt, einem Bauteil eine Bestellnummer
und/oder ein Preis zuzuordnen, ohne einen Lieferanten anzugeben. All
diese Daten befanden sich in der Tabelle "parts". Jetzt ist dies aber
nicht mehr erlaubt.
Für Bauteile, die keinen Lieferanten, jedoch eine Bestellnummer und/oder
ein Preis besitzen, wird einfach ein Lieferant "Unbekannt" erzeugt:
1
INSERT IGNORE INTO `suppliers` (name, parent_id) VALUES ('Unbekannt', NULL)
Dann soll die ID von diesem (evtl. neuen) Lieferanten allen Bauteilen
zugeordnet werden, die noch keinen Lieferanten (parts.id_supplier == 0),
jedoch eine Bestellnummer (parts.supplierpartnr != '') und/oder einen
Preis (preise.price > 0) haben. Mein Versuch sieht so aus:
1
UPDATE `parts` SET parts.id_supplier = (SELECT `id` FROM `suppliers` WHERE name='Unbekannt') WHERE (parts.id_supplier = 0) AND ((preise.price > 0) OR (parts.supplierpartnr != ''))
Ich glaube, man sieht was der Befehl machen sollte. Allerdings muss da
wohl noch ein JOIN rein, damit genau der Preis geholt wird, der zum
jeweiligen Bauteil gehört. Die Tabelle "preise" wird über die Spalte
"part_id" mit einem Bauteil verknüpft. Dabei kann es aber auch Bauteile
geben, die keinen Eintrag in der Tabelle "preise" haben! Mehr als ein
Eintrag kann (sollte...) aber nicht existieren.
Ausserdem, wenn es jetzt mehrere Lieferanten mit Namen "Unbekannt" gäbe,
sollte es trotzdem funktionieren (einfach einer dieser Lieferanten
nehmen, egal welcher). Ich bin mir nicht sicher wie sich da mein Befehl
verhalten würde...
Ist sicher nur eine Kleinigkeit für jemanden der was davon versteht :-)
Wäre super wenn mir da jemand helfen könnte, dann würde wenigstens mal
das Datenbankupdate funktionieren.
Falls mehr Infos gebraucht werden, einfach melden.
mfg
na, nur nicht alle auf einmal! :-D
Ich hätte auch gleich schon das zweite "Problem":
Bevor die Foreign Keys hinzugefügt werden, sollen alle Datenbankeinträge
mit einer "toten" parent_id auf die oberste Ebene gesetzt werden, also
parent_id = NULL setzen. Ansonsten ist die Gefahr eines Fehlschlages
beim Update zu hoch, weil es sein könnte dass es in der Spalte
'parent_id' IDs gibt, die nicht (mehr) existieren (sollte zwar
theoretisch nicht vorkommen - habe aber auch schon merkwürdige Dinge in
meiner Datenbank gesehen)
Pseudo-Code für die Tabelle "categories":
1
UPDATE `categories` SET parent_id=NULL WHERE (parent_id existiert nicht in categories.id)
Für die anderen Tabellen kann ich das Ding natürlich auch selber
anpassen.
mfg
Kann mir denn wirklich keiner helfen? ;-)
Ich habe noch diverse andere Sachen gemacht, die ich gerne wiedermal ins
SVN laden würde, aber ohne das Datenbankupdate funktionieren die
nicht...
Wenn sich keiner meldet, frage ich dann halt mal in einem MySQL Forum
nach... Die Updateschritte sollten halt wirklich wasserdicht sein, und
das krieg ich mit meinen MySQL-Fähigkeiten nicht hin :-(
Die Tabelle mit PHP auf machen und mit einer Schleife durchlaufen?
Es muss ja nicht unbedingt ein SQL Script sein, komplexere Teile können
auch per PHP bearbeitet werden.
Markus Müller schrieb:> Die Tabelle mit PHP auf machen und mit einer Schleife durchlaufen?> Es muss ja nicht unbedingt ein SQL Script sein, komplexere Teile können> auch per PHP bearbeitet werden.
Nein es sollte wenn möglich schon direkt per MySQL Queries erledigt
werden, da das bisherige Updatesystem so aufgebaut ist dass nur MySQL
Befehle abgearbeitet werden können. Ausserdem sollten die genannten
Operationen ja problemlos mit MySQL lösbar sein, es liegt nur an meinem
begrenzen Fähigkeiten dass ich es nicht hinkriege ;-)
Ich weiß das jetzt auch nicht auswendig und müsste in der Doku
nachlesen. Ich habe das zumindest in meinen Updates so gelöst um die
Unterschiede der SQL Syntax korrekt behandeln zu können.
Damit habe ich sogar die Möglichkeit gleiche Updates mehrfach aus zu
führen, da erst geprüft wird ob z.B. das Feld nicht doch schon existiert
und dann erst angelegt wird. Bei einem reinen SQL Script ist das viel
schwieriger.
Markus Müller schrieb:> Damit habe ich sogar die Möglichkeit gleiche Updates mehrfach aus zu> führen, da erst geprüft wird ob z.B. das Feld nicht doch schon existiert> und dann erst angelegt wird. Bei einem reinen SQL Script ist das viel> schwieriger.
Jup, das war bisher tatsächlich ein Problem. Ich habe jetzt aber einen
Zähler eingebaut, der sich merkt bei welchem Updateschritt ein Abbruch
stattfand. So kann beim nächsten Versuch wieder an der gleichen Position
weitergemacht werden. Beim Update von v12 auf v13 ist das auch dringend
notwendig, da wird so viel an der DB verändert... ;-)
Das ganze Updatesystem soll später aber sowieso nochmal überarbeitet
werden, da wir auch Systemupdates unterstützen möchten. Bisher wird nur
die Datenbank an die neue Systemversion angepasst nachdem der Benutzer
das System selbst aktualisiert hat.
OK also ich habs nochmal selbst probiert, und ich glaube sogar ich habs
hingekriegt :-) Bei den Tests die ich durchgeführt habe, stimmte das
Ergebnis jedenfalls...
Ich habe jetzt mal alle Änderungen ins SVN hochgeladen (r594).
Achtung! Es wird jetzt wieder eine Datenbank der Version 12
vorausgesetzt, da ich den Schritt von v12 auf v13 verändert habe! Eine
DB v12 liegt ja nach wie vor im "development" Ordner.
Die Online Demo wird nun in nächster Zeit vermutlich auch nicht mehr
richtig funktionieren, da muss auch erstmal wieder eine frische DB
geladen werden...
So, vielleicht kriege ich nun sogar auch noch die anderen
Datenbankprobleme hin, die in der Doxygen Doku noch aufgelistet sind ;-)
mfg
P.S.
Falls es bei euch Probleme geben sollte beim DB-Update, bitte melden,
vielleicht ist ja doch noch ein Wurm drin ;-)
Urban B. schrieb:>> Die Online Demo wird nun in nächster Zeit vermutlich auch nicht mehr> richtig funktionieren, da muss auch erstmal wieder eine frische DB> geladen werden...>
Leuft ;-)
>> P.S.> Falls es bei euch Probleme geben sollte beim DB-Update, bitte melden,> vielleicht ist ja doch noch ein Wurm drin ;-)
Jap aus irgendeinen Grund, wird der Datenbank Zeichensatz bei mir auf
schwedisch gestellt für die umbenannten Tabellen.
Was noch nett ist das neuerdings erst nach dem kompletten Update die DB
Rev. geändert wird so kann man das auch selber grade biegen und dann das
script nochmal durchlaufen lassen.
K. J. schrieb:> Leuft ;-)
Super, danke! :-)
K. J. schrieb:> Jap aus irgendeinen Grund, wird der Datenbank Zeichensatz bei mir auf> schwedisch gestellt für die umbenannten Tabellen.
Hmm dann musst du dir wohl noch eine schwedische Tastatur besorgen ;-)
Ne im Ernst, ich bin mir noch unsicher was die Befehle "CHARSET=..." und
"COLLATE=..." genau bringen. Vorher haben wir ja eine Tabelle so
erzeugt:
1
DROP TABLE IF EXISTS `categories`;
2
CREATE TABLE IF NOT EXISTS `categories` (
3
`id` int(11) NOT NULL AUTO_INCREMENT,
4
`name` mediumtext COLLATE utf8_unicode_ci NOT NULL,
Hier wird ja der Zeichensatz auf utf8_unicode_ci gesetzt. Aber was, wenn
jemand einen anderen Zeichensatz haben möchte (auf Windows?) ? Oder wird
das niemand wollen? ;-) Über die Konfiguration lässt sich ja jetzt der
Zeichensatz des PDO setzen. Dieser Zeichensatz sollte dann eigentlich ja
auch beim Anlegen neuer Tabellen verwendet werden nehme ich mal an. So
ist halt der Zeichensatz nicht mehr hardgecoded, sondern der Benutzer
kann ihn selber wählen. Aber ob das wirklich Sinn macht... Sollte man
besser den Zeichensatz wieder auf utf8 hardcoden und die
Konfigurationsmöglichkeit rauswerfen?
Und dann gibts da noch das "COLLATE=...". Hier bin ich mir auch nicht
sicher. Wird da nicht standardmässig utf8 verwendet, wenn die Tabelle
sowieso den utf8-Zeichensatz verwendet? Oder muss das wirklich noch
separat angegeben werden?
Die blöden Zeichensätze bereiten mir echt Kopfschmerzen... :-(
K. J. schrieb:> Was noch nett ist das neuerdings erst nach dem kompletten Update die DB> Rev. geändert wird so kann man das auch selber grade biegen und dann das> script nochmal durchlaufen lassen.
Jup, wenn ein Update fehlschlägt wird die aktuelle Position in der
config.php abgelegt, damit beim nächsten Versuch wieder an der gleichen
Position weitergemacht werden kann. Vorher war es echt mühsam wenn mal
ein Update fehlgeschlagen hat... ;-)
Markus Müller schrieb:> Foreign Key's benötigen InnoDB.
Ja, deshalb werden zu Beginn des Updates alle Tabellen auf InnoDB
umgestellt:
1
ALTER TABLE `categories` ENGINE=InnoDB
Aber das hat mit dem Zeichensatz eigentlich ja nichts zu tun, oder?
Übrigens ist mir grad noch ein schlimmer Fehler im DB Update
aufgefallen, es waren plötzlich alle Einkaufsinformationen doppelt
vorhanden :-) Ist jetzt aber gefixt (r596).
Kann man eigentlich in Google Code nicht einzelne Verzeichnisse aus dem
Changelog rausnehmen? Die Änderungen an der Doxygen Doku nerven extrem
in der Änderungsliste, die wirklich wichtigen Änderungen gehen so total
unter...
Übrigens, ich habe jetzt mal ein Dokuwiki in Part-DB mit eingebaut. Wer
möchte, kann gerne daran arbeiten :-)
Und dann habe ich noch diverse Sachen gefixt: Man kann nun endlich nach
Lieferanten und Bestellnummern suchen, die Statistik wird jetzt viel
schneller geladen (Preisberechnung per MySQL statt PHP) und die
Footprint-Bilder Auflistung habe ich umgebaut. Beim Aufrufen von Tools
-> Footprints werden nun nicht mehr die über tausend Bilder geladen
(sehr mühsam bei langsamen PCs). Wer es trotzdem wieder haben möchte,
kann es in der Konfiguration ändern.
mfg
K. J. schrieb:> Jap aus irgendeinen Grund, wird der Datenbank Zeichensatz bei mir auf> schwedisch gestellt für die umbenannten Tabellen.
Ich habe mal die CHARSET=... und COLLATE=... wieder hinzugefügt (r598),
könntest du nochmal eine DB v12 laden und schauen obs nun klappt?
Ausserdem gibts jetzt ein paar neue Sachen in Part-DB 0.3.0:
1
- Export für gesuchte Teile, Baugruppen und zu bestellende Teile
2
- Eigene Exportformate können ziemlich einfach in der config.php definiert werden
3
- Baugruppen können zum Bestellen vorgemerkt werden (damit tauchen Sie in der Liste der zu bestellenden Teile auf - war ziemlich tricky, vielleicht gibts da noch Bugs...)
4
- Obsolete Einkaufsinformationen werden in den Tabellen nicht mehr angezeigt
So langsam aber sicher wird die ganze Sache ziemlich kompliziert ;-) Die
Einkaufsinformationen und Preisinformationen machen es einem nicht
leicht, aber ich denke der Aufwand lohnt sich. Wenn man das selbe
Bauteil mal bei diesem, mal bei einem anderen Lieferanten bestellt, muss
das halt auch irgendwie gescheit verwalten können...
Gute Nacht! :-)
Urban B. schrieb:> K. J. schrieb:>> Jap aus irgendeinen Grund, wird der Datenbank Zeichensatz bei mir auf>> schwedisch gestellt für die umbenannten Tabellen.>> Ich habe mal die CHARSET=... und COLLATE=... wieder hinzugefügt (r598),> könntest du nochmal eine DB v12 laden und schauen obs nun klappt?>
Supi geht.
An dieser Stelle einfach mal ein Lob an Urban für seine Arbeit :-)
Ich hänge derzeit an den AJAX-Routinen für den IE (hab nur den 8er)
fest. JScript ist halt nicht Javascript und das nervt tierisch :(
K. J. schrieb:> Supi geht.
OK dann lassen wir das mal so :-)
Ich habe mich jetzt übrigens mal noch ein bisschen mit dem Thema
Zeichensätze beschäftigt, da ich damit immernoch Mühe hatte. Einerseits
haben wir ja den HTTP Zeichensatz (im HTML Header), und andererseits den
Zeichensatz der Datenbank.
Die Kommunikation mit der Datenbank können wir wohl auf UTF-8 hardcoden
denke ich (mit "SET NAMES utf8"). Jeder (einigermassen aktuelle) MySQL
Server sollte UTF-8 unterstützen, so können Probleme und
Missverständnisse vermieden werden. Übrigens habe ich heute
herausgefunden dass der Befehl "SET NAMES utf8" bisher gar nicht
funktioniert hat, in der nächsten Revision die ich hochlade,
funktioniert es dann aber.
Eventuell könnte es aber bei einigen Benutzern zur falschen Darstellung
von Umlauten führen. In früheren Versionen von Part-DB wurden die Daten
wohl in "latin1" in der Datenbank abgelegt. Die Backups davon werden bei
mir nun aber als UTF-8 interpretiert und somit die Umlaute falsch
dargestellt. Ich bin mir aber nicht sicher ob das nur bei alten Backups
passiert, oder obs auch im normalen Betrieb dann plötzlich passiert
(beim Update auf eine neue Version von Part-DB)...Im schlimmsten Fall
müssten die Benutzer dann ihre latin1-Datenbank nach UTF-8 konvertieren.
Ist zwar irgendwie blöde, aber wenn man jetzt einfach was "bastelt" wird
uns das Problem auf immer und ewig verfolgen ;-)
Und dann zum HTTP-Zeichensatz. Der gibt eigentlich dem Browser ja nur
bekannt, wie die Daten codiert sind. Da gibt es einmal die (ich nenne
sie mal) "dynamischen" Daten, die z.B. von der Datenbank kommen, die
erhalten wir immer in UTF-8 und werden auch so ausgegeben. Und dann
gibts noch die "statischen" Daten, die hardgecoded (in *.php oder
*.tmpl) sind. Die sind ja auch alle in UTF-8 codiert. Teilweise gibts
Umlaute noch in HTML-Schreibweise, die könnten wir aber auch noch durch
Umlaute (im Klartext) ersetzen. Es ist also immer alles UTF-8, somit
könnten wir doch den HTTP-Zeichensatz auch auf UTF-8 hardcoden, oder?
Wenn jetzt ein Windows Server eingesetzt wird, sind ja die Dateien von
Part-DB immernoch UTF-8 und es müsste weiterhin funktionieren schätze
ich. Oder liefert ein Apache Server auf Windows etwa latin1 Ausgaben,
auch wenn die PHP/TMPL Dateien UTF-8 codiert sind? Das bin ich mir nicht
so ganz sicher...
Zusammengefasst würde ich also sagen: Wir könnten alles auf UTF-8
hardcoden und es sollte tzotzdem auf allen Server-Systemen richtig
funktionieren. Einzig bei der Bearbeitung der PHP/TMPL Dateien unter
Windows muss man darauf aufpassen, dass die Dateien auch wieder UTF-8
codiert gespeichert werden. Aber das sollte ja jeder ernstzunehmende
Code-Editor beherrschen.
K. J. schrieb:> Aso hab mich mal ans Wiki gemacht,
Super! :-)
Uhu hat sich ja diesbezüglich auch mal gemeldet, vielleicht müsstest du
mit ihm mal besprechen ob/was/wie/wann er auch noch an der Doku
arbeitet.
> ich weis nur nicht ob ein einfaches> Coppy der Seiten reicht damit sie übernommen werden.
mmh ich verstehe die Frage nicht ganz. Also grundsätzlich solltest du im
DokuWiki einfach Änderungen machen und dann die Dateien ins SVN
hochladen können. Man sieht ja in der Online-Demo dass das bereits
geklappt hat.
Übrigens habe ich nur mal ein paar grobe Einstellungen gemacht im
DokuWiki. Vielleicht gäbe es noch ein paar andere Sachen die man ändern
könnte. z.B. macht es nicht viel Sinn dass der Benutzer schlussendlich
auch die Möglichkeit hat, Änderungen an der Doku durchzuführen (sieht
irgendwie komisch aus wenn man die Doku einer Software selbst verändern
kann). Da könnte man sicher noch ein bisschen was anpassen...
Udo Neist schrieb:> An dieser Stelle einfach mal ein Lob an Urban für seine Arbeit :-)
Vielen Dank :-)
Ja, werd mich drum kümmern werde auch mal schauen ob wir das ganze nicht
mal etwas abspecken können alleine die Sprachfiles sind son eine ganze
menge die wir nicht brauchen, denke DE und EN werden reichen, das
gleiche für die doxigen doku die ist sowas von aufgebläht.
K. J. schrieb:> Ja, werd mich drum kümmern werde auch mal schauen ob wir das ganze nicht> mal etwas abspecken können alleine die Sprachfiles sind son eine ganze> menge die wir nicht brauchen, denke DE und EN werden reichen,
Jup, gute Idee.
K. J. schrieb:> das gleiche für die doxigen doku die ist sowas von aufgebläht.
Ja es sind halt sehr viele Dateien, aber viel weglassen kann man da
nicht denke ich. Ausserdem kriegt der Endanwender die Doxygen-Doku
nicht, die ist nur für Entwickler. Der ganze Ordner "development" kommt
schlussendlich nicht in die Download-Archive, deshalb habe ich die
Doxygen Doku auch von "documentation" nach "development" verschoben.
Was ich aber schön finden würde, wäre wenn man die Änderungen im Ordner
"doxygen" im Changelog in Google Code irgendwie ausblenden könnte. Aber
ich vermute mal das ist nicht möglich (?)...
@ Marco tom Suden (falls du noch mitliest)
Wenn du auf deinem Windows Server den HTTP Zeichensatz auf "UTF-8"
einstellst, werden dann die Umlaute richtig dargestellt (nicht bei den
Daten schauen die aus der Datenbank kommen, sondern bei statischen
Inhalten, z.B. die Tabellenüberschrift "Datenblätter")?
Urban B. schrieb:> z.B. macht es nicht viel Sinn dass der Benutzer schlussendlich> auch die Möglichkeit hat, Änderungen an der Doku durchzuführen (sieht> irgendwie komisch aus wenn man die Doku einer Software selbst verändern> kann).
Das sehe ich nicht ganz so. Wenn die Doku schlecht ist - MS ist in
dieser Disziplin ganz große Klasse! - ist es mehr als wünschenswert, daß
man als Nutzer z.B. leeres Stroh eliminieren, verkorkste Übersetzungen,
oder Formulierungen reparieren kann...
Dokuwiki ist genau dafür ganz prima geeignet: man kann neue Versionen
einspeisen und private Änderungen notfalls mit Hilfe der diff-Funktion
finden und übernehmen, falls sinnvoll.
Aber es ist durchaus sinnvoll, die Änderbarkeit an einen speziellen
Wiki-Login zu koppeln, daß nicht aus Versehen Änderungen gemacht werden.
Der Username muß natürlich bekannt gemacht werden.
Uhu Uhuhu schrieb:> Aber es ist durchaus sinnvoll, die Änderbarkeit an einen speziellen> Wiki-Login zu koppeln, daß nicht aus Versehen Änderungen gemacht werden.> Der Username muß natürlich bekannt gemacht werden.
Ja, so ähnlich hätte ich mir das auch vorgestellt. Also dass
standardmässig die Editier-Buttons nicht sichtbar sind (die meisten
Anwender werden die nicht brauchen), aber mit der Möglichkeit, dass man
eben doch was verändern kann wenn man möchte (z.B. wir Entwickler
brauchen das ja). Sei es ein Login, oder evtl. auch in der Konfiguration
von Part-DB eine Option wie "Änderungen in der Dokumentation zulassen".
Wie gesagt, ich habe mich nicht grossartig mit DokuWiki beschäftigt. Ich
habs einfach mal in Part-DB eingefügt und ein paar grundlegende
Einstellungen getätigt, so dass wir mal eine Grundlage für die Doku
haben. Ihr dürft daran gerne noch Einstellungen verändern usw.
Uhu Uhuhu schrieb:> Udo Neist schrieb:>> JScript ist halt nicht Javascript und das nervt tierisch :(>> Tja, das ist das Echo des Browserkrieges.
Problem ist gelöst. Ajax funktioniert jetzt auch mit dem IE8. Jetzt muss
ich erstmal einen Schönheitsfehler im Bezug auf die Testseite beheben,
dann kommen die Kommandos hinzu. Ich habe mir überlegt, dass ich die
Verzeichnisse per Konfiguration von Änderungen ausnehmen kann (jetziges
Verhalten). Alternativ würde man per Einfachklick das Verzeichnis zum
Bearbeiten markieren und ein weiterer Klick würde das Verzeichnis
öffnen. Neue Ordner können nur dann erstellt werden, wenn eine weitere
Konfigurationsoption dies freischaltet. Schließlich soll nicht jeder an
der bestehenden Struktur was ändern können, eventuell neu erstellte
Verzeichnisse würde vom System u.U. auch gar nicht berücksichtigt
werden.
Ne, derzeit haben wir kein Release-Fahrplan. Nach meinem Wissen gibt es
derzeit drei Baustellen:
1) Umstellung des Codes auf Modul-/Klassenbasis
2) Neuer Filemanager
3) Dokumentation im Form eines Wikis
Ich vermute mal, dass wir irgendwo bei 90% sind. Am eigentlichen Code
arbeitet derzeit nur Urban und ich bin am Filemanager dran. Nach der
Veröffentlichung der Version 0.3 soll die Kommunikation zwischen
Anwendung und Server auf Ajax umgestellt werden und somit die veraltete
Frame-Variante komplett ersetzen.
Für den produktiven Betrieb ist die 0.2.x vorgesehen.
Grüße
Udo
So, die Importfunktionen sollten nun (r606) auch funktionieren. Falls
noch jemand Bugs findet, bitte melden :-)
Ihr glaubt gar nicht, wie froh ich bin dass wir nun Transaktionen
verwenden können :-D Eine Funktion, die die Werte aus dem Import-Text
auf Gültigkeit überprüft, wurde so zum Kinderspiel. Einfach alles normal
importieren, aber am Schluss ein Rollback statt einem Commit ausführen
:-)
Ausserdem habe ich den Code-Styleguide vom Google-Code Wiki in die
Doxygen-Doku verschoben. So gibts schlussendlich nur zwei
Nachschlagewerke: Die Doxygen Doku für Entwickler, und das DokuWiki für
Anwender (und beide Nachschlagewerke sind natürlich auch online auf der
Demo-Seite verfügbar).
So braucht es das Google Code Wiki gar nicht mehr.
Den Code-Styleguide sollte demnächst dann unter
http://partdb.grautier.com/uneistkami89/development/doxygen/html/styleguide.html
erreichbar sein.
Gespeichert ist die Seite übrigens unter
"development/doxygen/related_pages/". Man kann sehr schön eigene Seiten
in die Doxygen Doku aufnehmen, die sich dann auch ins Menü integrieren.
Wie man das genau macht, kann man in den in diesem Ordner vorhandenen
Dateien nachschauen.
Ich wäre nun übrigens langsam für den Dateimanager bereit, wie sieht die
Lage bei dir aus, Udo? :-)
mfg
Urban B. schrieb:> Ich wäre nun übrigens langsam für den Dateimanager bereit, wie sieht die> Lage bei dir aus, Udo? :-)
Ich wollte heute einige der Kommandos fertig machen, damit der
Filemanager zumindest mit den Basisfunktionen auch nutzbar ist. Vorerst
halt nur für Dateien, das mit den Verzeichnissen kommt später noch dazu.
Den Upload-Teil werde ich die Tage dann integrieren.
Aktueller Stand Filemanager:
- Befehle funktionieren, sind aber auf Dateien beschränkt
- Alle Meldungen über einen modalen Dialog (Formulare, Meldungen)
- Fehlermeldungen des Webservers werden als Statusmeldung direkt im
entsprechenden Block angezeigt (kein Dialog)
- (Access-)Token als Absicherung für die Kommandos, da man auf den
HTTP-Referrer nicht bauen kann
- Vorschau von Grafiken
- Mimetyp-Grafiken für alle anderen Files (optional)
- Anpassen des Designs über CSS. Nur wenige Elemente sind in den
Templates fest über Style-Regeln definiert.
Basis sind XMLHttpRequests und JSON auf Seite von Javascript. Die
Javascript-Klassen haben einen eigenen Namespace.
ToDo:
- Verzeichnisfunktionen einführen
- Fehlermeldungen des Webservers als modaler Dialog
Die aktuelle Version werde ich die Tage von den Eigenheiten meiner
Webseite befreien und erstmal in den Development-Ordner kopieren. Eine
Minidoku füge ich hinzu.
Grüße
Udo
Edit:
Es fehlt noch der Upload-Teil. Hab mich erstmal auf meinen eigenen Code
konzentriert ;-)
Super, dann geht die Version 0.3.0 nun ja endlich langsam in die
Endphase über :-)
Also ich bin auch noch nicht ganz fertig, aber es sind jetzt
hauptsächlich nur noch Kleinigkeiten die noch fehlen. Und beim Testen
werden dann sicher auch noch einige Bugs auftauchen...
Ich wollte dich aber schon lange mal noch was ganz anderes fragen. Du
hast ja mal das Skript "svn.sh" erstellt, das ich mittlerweile übrigens
in "tools.sh" umbenannt habe (habe noch eine neue Funktion hinzugefügt,
die nichts mit SVN zu tun hat). Ein Teil dieser Funktionen sind übrigens
nun auch sehr bequem über Part-DB unter "Entwickler-Werkzeuge"
erreichbar. Ich bin einfach zu faul um jedesmal ein Terminal aufzumachen
;-)
Meine Frage bezieht sich aber auf das Commiten. Du hast ja dort den
Parameter "--force" mit eingebaut. Ich frage mich aber ein bisschen, ob
das geschickt ist. Einerseits werden doch so eventuelle Änderungen im
Repository, die seit dem letzten Update gemacht wurden, einfach
überschrieben, oder? Und andererseits habe ich gelesen dass dann die
Ignore-Dateien auch nicht mehr ignoriert werden (verwende ich für den
Debug-Log und config.php). Zweiteres ist nicht schlimm, aber ersteres
könnte zu Problemen führen wenn man nicht aufpasst.
Ich selber benutze einen grafischen SVN Client der sich in Nautilus
integriert. Bei jedem Commiten überfliege ich alle geänderten Dateien
nochmal um zu prüfen, ob auch wirklich genau das hochgeladen wird, was
hochgeladen werden soll. Und falls meine lokale Kopie nicht mehr aktuell
ist, bekomme ich eine Fehlermeldung weil ich kein "--force" verwende. So
werde ich gezwungen, erst mal ein Update durchzuführen und es wird
sichergestellt dass ich keine Dateien aus Versehen überschreibe.
Ich habe das leider auch schon bei anderen Projekten erlebt (git) dass
Leute einfach mal drauflos committen und Änderungen von Anderen wieder
(aus Versehen) rückgängig machen. Das ist extrem mühsam...
Meine Frage wäre also: Sollten wir da nicht besser das "--force"
entfernen, um unbeabsichtigte Änderungen zu vermeiden?
mfg
Das "--force" bezieht sich ja nur auf "svn add" und durchsucht rekursiv
alle Verzeichnisse. Mit "--no-ignore" würdest du gesperrte Dateien
hinzfügen, so lese ich zumindest die Doku. Zudem fehlt da eh noch der
Befehl "svn resolve --accept working *" (oder ne Variante), um Konflikte
zu lösen. Das Script ist noch lange nicht perfekt und sollte ja auch
erstmal nur die Arbeit in meinem Branch erleichtern. Es ist halt nicht
für Mehrbenutzer-Repos ausgelegt und darf jederzeit angepasst werden :-)
Udo Neist schrieb:> Das "--force" bezieht sich ja nur auf "svn add"
Ups, da habe ich wohl nicht richtig hingeschaut^^ Sorry, ich dachte das
war beim "commit" ;-) Beim "add" sollte das dann ja tatsächlich nicht so
wild sein...
Udo Neist schrieb:> Mit "--no-ignore" würdest du gesperrte Dateien> hinzfügen, so lese ich zumindest die Doku.
Jo nach Doku würde ich das auch sagen, wenn ich aber diverse Meldungen
in Foren richtig verstanden habe, tut es das eben nicht. Ich habs
allerdings nie selber ausprobiert, das Committen mit der Konsole ist mir
etwas ungeheuer. Ich setze da lieber auf hübsche Klicki Bunti GUIs, dann
kommt auch das richtige bei raus :-D
Aber dann hat sich das ja auch mehr oder weniger erledigt. Ich wollte
nur sichergehen dass man (die, die es verwenden) mit dem Skript keine
unbeabsichtigten Sachen im Repo überschreibt.
Das nächste Mal schaue ich mir den Code etwas genauer an bevor ich hier
nachfrage, versprochen! :-D
...wie still es doch sein kann in diesem Thread :-)
Ich habe vor ein paar Wochen noch ein neues (grosses...) Projekt
angefangen, daher ist Part-DB in letzter Zeit leider etwas auf der
Strecke geblieben. Dieses Wochenende versuche ich aber wieder daran zu
arbeiten :-)
@Udo, siehts bei dir (bzw. beim Dateimanager) ähnlich aus oder bist du
in der Zwischenzeit weiter gekommen?
mfg
Urban
Leider nein :( Wird wohl noch bis Ende April oder Mitte Mai dauern, bis
ich wieder mehr Zeit habe. Im Moment raubt mir die Vertretung eines
Kollegen etwas die Zeit. Wie es im Juni aussieht, weiß ich auch noch
nicht. Da steht bei uns eine Reakkreditierung an. Ich versuch zumindest
mal den Uploader zu integrieren, damit wenigstens diese Baustelle im
Dateimanager geschlossen werden kann.
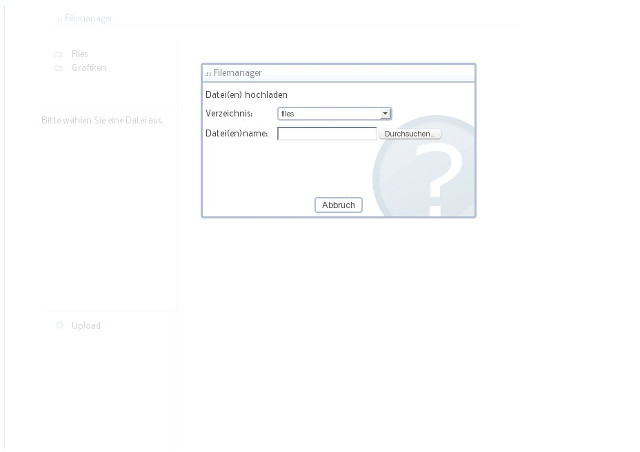
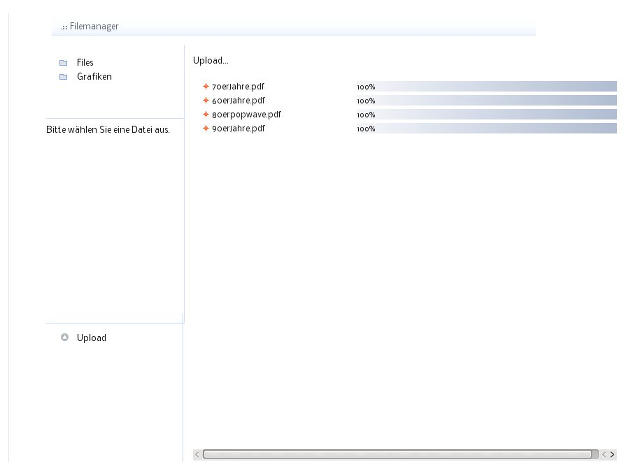
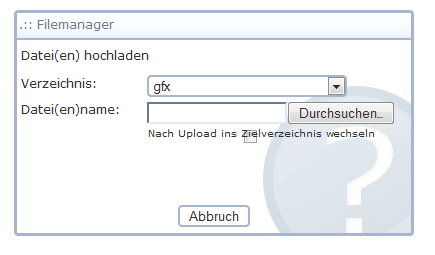
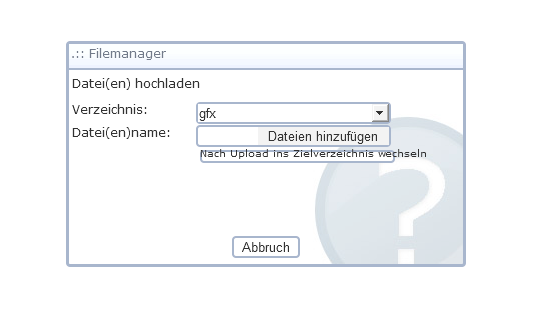
So, habe einen einfachen Uploader integriert. Es wird kein Flash oder
ähnliches verwendet. Nur der Browser sollte möglichst aktuell sein. Es
fehlt nur noch die Option, nach dem Upload direkt ins Zielverzeichnis zu
wechseln.
Ok super, also wenn der Uploader schon funktionsfähig ist, kannst du ihn
ja mal ins SVN hochladen.
Wenn der Uploader einen Haufen Dateien braucht, wäre es vielleicht
sinnvoll wenn wir ihm ein eigenes Verzeichnis spendieren, also im
Hauptverzeichnis einen Unterordner "filemanager/" o.ä. (anstatt
JS-Dateien in "javascript/", CSS in "templates/" usw.)
Das Wechseln nach 5s in das Zielverzeichnis funktioniert jetzt auch. Ob
das auch bei fehlgeschlagenen Uploads funktioniert, kann ich noch nicht
beurteilen, da es nur sporadisch auftritt.
Die Installation in ein eigenes Verzeichnis wäre mir auch lieber, da der
Filemanager ja absichtlich als Add-On/Modul für ein CMS oder ähnliches
gedacht ist. Javascript und CSS müssen eingebunden, die
Grafikverzeichnisse verlinkt werden. Ansonsten sollte es ziemlich
pflegeleicht sein. Ich werde vielleicht morgen mal die aktuelle Version
ins Repo einbinden. In die jetzige Version der Part-DB kann man
allerdings nur das Aufrufen per Popup-Window nutzen. Eigentlich ist es
für die Nutzung innerhalb eines DIV-Elements auf der Hauptseite
vorgesehen. Es wird ein Fenster mit mindestens 600px Breite gebraucht.
Nächstes Feature: Interner Viewer ähnlich eines Dialogs
Unterstützt werden PDF und Images. PDF wird vom jeweiligen Plugin
angezeigt, die Images werden bei Übergröße über CSS skaliert. Letzteres
ist kein ideales Verhalten, aber sollte bei jedem Browser funktionieren.
Kleinere Bilder füllen den Viewer nicht aus. Dieser wird nicht
angepasst. Wäre noch was für die ToDo-Liste. Vielleicht unterstütze ich
später auch noch Videos oder anderes per object-Tag.
Ich habe den Filemanager mit Kommentaren versehen und ein paar kleinere
Anpassungen für Part-DB gemacht. Wie man den Filemanager in einen
Webseite einbaut, kann man in der Datei vlib_filemanager.html sehen.
dom.css und filemanager.css dabei nicht vergessen!
Aktuelle Version ist in der Revision 613 enthalten.
ToDo:
- Viewer soll auch Text-Dateien anzeigen können, dabei soll
Syntax-Highlightning unterstützt werden.
- Hauptverzeichnis für Dateioperationen wird in filemanager.php bzw.
conf.php definiert, aber kann dort noch nicht gesperrt werden. Geht
derzeit nur über eine interne Variable in filemanager.js.
- README ändern, da es nicht mehr aktuell ist.
- Doxygenkompatible Kommentare, kann auch jemand vom Part-DB-Projekt
übernehmen ;-)
Ich habe mir das mal angeschaut aber ich blicke noch nicht so richtig
durch :-(
Wie würde man den Filemanager später z.B. in "edit_part_info.php" (bzw.
dem *.tmpl davon) einbinden?
Die Bedienung stelle ich mir etwa so vor (Bsp. "edit_part_info.php"):
- Der Benutzer klickt unter Dateianhänge/Dateiname auf den Button "..."
- Der Filemanager öffnet sich in einem neuen Fenster (Popup)
- Falls nötig, kann der Benutzer die Datei erst noch hochladen
- Der Benutzer wählt die entsprechende Datei aus und klickt auf "OK"
- Der Filemanager schliesst sich und der Pfad zur gewählten Datei wird
automatisch in das Textfeld "Dateiname / URL" in "edit_part_info.php"
geschrieben.
Wie man das so hinkriegt weiss ich aber leider nicht... ;-)
mfg
Dachte ich mir schon, dass dazu noch Fragen sind :-) Ich werde noch eine
Testseite machen, auf dem der Aufruf für den Upload-Teil gezeigt wird.
Erst wenn die dann so läuft wie angedacht, würde ich den Filemanager in
Part-DB einbauen.
Im Grunde besteht der Uploadmanager nur aus einem Dialogfenster und
einem zweiten Element für die Anzeige des Uploads selbst. Innerhalb der
gleichen Seite wäre es ein
1
onclick="filemanager.command('upload');"
auf einem entsprechenden Button. Für den Aufruf in einem Popup muss man
mehr machen. Erstmal ein onclick-Event, das ein neues Fenster erzeugt.
In dem Fenster wird dann der komplette Filemanager aufgebaut, aber die
normalen Funktionen wären abgeschaltet, d.h. das Element links oben mit
den Verzeichnissen wäre abgeschaltet.
Okay dann warte ich diesbezüglich noch ab :-)
Momentan habe ich noch ein anderes Problem. Unter "Zu bestellende Teile"
werden nun ja jeweils zu jedem Bauteil alle verfügbaren
Einkaufsinformationen angezeigt, jeweils mit einem Radiobutton um
auszuwählen, welchen Artikel man nun genau bestellen möchte. Anhand
dieser Auswahl wird dann übrigens der Gesamtpreis der Bestellung
berechnet, und auch für den Bestelllisten-Export ist diese wichtig.
Das Problem ist nun aber, dass die Radiobuttons etwas höher sind als der
Text alleine, und das führt bei mehreren Einkaufsinformationen zu einer
Verschiebung in der Höhe (zwischen den verschiedenen Spalten). Siehe
angehängtes Bild.
Ich habe keine gescheite Idee, wie man die Zeilen jeweils aufeinander
ausrichten könnte. Die einzige Idee war, dass man für jede
Einkaufsinformation eine eigene Zeile macht, und die dann mit "rowspan"
zusammenfasst wo sie nicht gebraucht werden. Allerdings würde das extrem
viel Aufwand bedeuten, vieles verkomplizieren und neue Probleme mit sich
ziehen.
Hat jemand eine gute Idee wie man das machen könnte?
Nachtrag:
Das Beispiel im Anhang ist natürlich ziemlich übertrieben. Bei 2 oder 3
Einkaufsinformationen ist dieses Problem erst leicht ersichtlich.
Trotzdem ist es unschön und sollte wenn möglich verbessert werden :-)
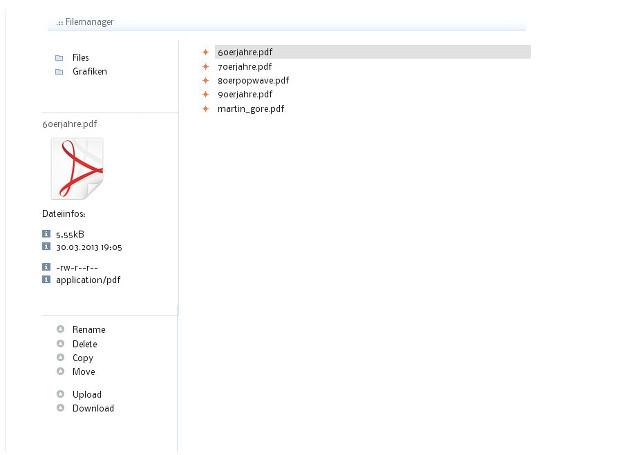
Auf http://phpbookworm.singollo.de/project/part-db/index.html ist der
Filemanager in zwei Modi zu sehen:
- Innerhalb eines DIV-Elements
- In einem Popup-Fenster
Ausprobieren ist ausdrücklich erlaubt. Fehlerberichte wären sehr
hilfreich, um den Filemanager fertig zu bekommen.
ToDo:
- Breadcrumb-Anzeige der Verzeichnisstruktur hinzufügen.
- README ändern, da es nicht mehr aktuell ist.
- Doxygenkompatible Kommentare, kann auch jemand vom Part-DB-Projekt
übernehmen ;-)
Udo Neist schrieb:> Warum ausgerechnet Radio-Buttons? Select mit allen Infos wäre passender.
Daran habe ich auch schon gedacht. Irgendwie finde ich es aber mit
Radiobuttons übersichtlicher, weil man direkt auf einen Blick alle
Möglichkeiten sieht. So sieht man halt sehr schnell, welche Teile man
bei welchen Lieferanten bekommt und kann so entscheiden, wo man
bestellen möchte.
Wenn ich z.B. 10 zu bestellende Teile habe, müsste ich bei Comboboxen
erst bei jedem einzelnen Teil schauen (klicken, schauen, anwählen), ob
es das bei z.B. Conrad gibt. Bei Radiobuttons sieht man auf einen Blick
- "aha, 3 der Teile gibts bei Reichelt, aber alle 10 gibts bei Conrad,
also bestelle ich alle 10 bei Conrad"
- oder "aha, 5 gibts bei Reichelt und Conrad, die anderen 5 gibts nur
bei Conrad, ich muss also sowieso bei beiden Lieferanten bestellen,
markiere also bei den 5 Teilen wo ich wählen kann jeweils den
Lieferanten mit dem tieferen Preis".
Und dann kommt dann manchmal auch noch der Mindestmengenzuschlag hinzu,
den man berücksichtigen muss...
kurz gesagt: Radiobuttons halte ich für übersichtlicher (klar, wenn
jedes Teil 10 verschiedene Einkaufsinformationen hat, wirds auch
unübersichtlich. Aber ich schätze mal die meisten Benutzer von Part-DB
werden maximal 3 Einkaufsinformationen pro Bauteil haben).
Theoretisch könnte man aber auch beide Varianten implementieren, und die
Wahl dem Benutzer überlassen. Ist eigentlich auch ganz einfach, so wie
die Tabellen jetzt aufgebaut sind (Spalten in der config.php definiert).
Warum dann nicht alle Elemente mit einem identischen height-Wert
ausstatten? Entweder Listen oder DIV/P-Elemente verwenden. Ist bisschen
Fummelarbeit, zugegeben, aber die praktikabelste Lösung.
Funktioniert das dann auch ziemlich
browser-/schriftarten-/betriebssystemunabhängig?
Und sollte man das am besten gleich in CSS machen?
Bin leider in HTML/CSS nicht wirklich fit...ein Beispiel wäre super :-)
Entweder du nimmst bei jedem Element das Inline-Verfahren
1
style="height=1.5em;"
oder du definierst das im CSS
1
eklist{height: 1.5em;}
und bindest das dann als
1
class="eklist"
ein. Im Template muss das dann nur einmal pro Spalte an der richtigen
Stelle der Schleife eingetragen werden. Steht da nur ein BR-Tag, dann
mach mal daraus ein DIV-Element.
PS: Die Höhe hab ich einfach mal beispielsweise genommen. Kommt auf das
Radio-Element an, wie hoch das dann tatsächlich ist. "em" ist eine
relative Größe.
Das scheint zu funktionieren, zumindest im IE und im FF (Win7/Ubuntu)
siehts nun so aus wie es soll.
Dann kann ich das ja endlich mal abhaken...
Wenn ich mich nicht täusche, ist nun etwa alles, was ich für die Version
0.3.0 vorgesehen habe, eingebaut. Ich wäre froh, wenn ein paar Leute nun
langsam mit dem Testen beginnen würden, es gibt sicher noch viele Bugs
und Sachen die ich vergessen habe :-)
Vom geplanten Systemupdate sind halt schon ein paar Fragmente in der
aktuellen Version drin, die kann man ignorieren, die kommen nicht in die
v0.3.0. Aber der Filemanager kommt natürlich rein, der ist aber noch
nicht fertig.
Ich würde mich sehr über Rückmeldungen aller Art (Bugs, Vorschläge,
Bemerkungen) freuen!
Noch nicht wirklich ausgiebig getestet sind übrigens der Installer und
die Import/Exportfunktionen, hier ist also das Testen besonders wichtig.
Ich habe die komplette Testsuite mit dem aktuellen Stand des
Filemanagers reinkopiert. Ist recht groß das ganze, da es neben GeShi
auch noch die vlibTemplate-Engine drin hat. Letztere ist eigentlich
überflüssig, aber ich wollte die Testsuite nicht extra umschreiben.
Die beiden Dateien index.html und popup.html zeigen, wie man den
Filemanager in eine Seite integriert.
Revision 615 steht zur Verfügung.
ToDo:
- Globale Rechte und Benutzerrechte integrieren. Einerseits werden
Standardrechte zu definieren sein, andererseits soll die Token-Abfrage
zu einem Rechtesystem erweitert werden.
- Doxygenkompatible Kommentare, kann auch jemand vom Part-DB-Projekt
übernehmen ;-)
- Aktualisierung von http://weinbauer73.myparts.info/ (Test-Branch)
Udo Neist schrieb:> Ausprobieren ist ausdrücklich erlaubt. Fehlerberichte wären sehr> hilfreich, um den Filemanager fertig zu bekommen.
Gefällt mir schon gut.
Kleinigkeiten hätte ich allerdings:
Obwohl ich bereits im Filemanager einen Unterordner ausgewählt habe bzw
mich darin befinde, muss ich im Uploader den Unterordner erneut
auswählen.
Im IE 9 funktioniert leider weder "Filemanager (gleiche Seite)" noch
"Filemanager (per Popup)" (Popup geht zwar auf, aber es wird kein Inhalt
angezeigt)
Beim FF und Opera gibts kleinere Schönheitsfehler, siehe Anhang.
mfg Pyro
Mit dem erneuten Auswählen im Uploadmanager hab ich erstmal so gemacht.
Kann ich ja noch so umbauen, dass das angezeigte Unterverzeichnis als
Vorauswahl dient.
Im FF habe ich eigentlich keine Darstellungsfehler, hatte das mit der
19er und jetzigen 20er so entwickelt. Mit Opera, Chrome und dem IE (nur
bis IE 8, da nur XP) hab ich es noch nicht probiert, aber ich kann mich
die Tage mal ransetzen.
Ein Fehler hab ich schon gefunden. Ältere Browser verstehen den Mime-Typ
"application/javascript" nicht, sondern die nie standardisierte Version
"text/javascript". Warum der IE 8 dann immer noch das dom-Objekt nicht
findet, konnte ich heute morgen noch nicht klären.
Ich hab dem IE8 zumindest schon mal die Anzeige im gleichen Fenster
beigebracht. Bis auf den Darstellungsfehler und dem fehlenden Support
für den Multifileupload von HTML5 läuft es. Eigentlich wollte ich das
unabhängig von Flash oder Java halten, um nicht irgendwelchen
IT-Restriktionen zu wider zu laufen :(
Hallo,
erstmal vielen Dank für PartDB. Das ist eine tolle Sache und hilft
ungemein. Ich habe eine kleine Ergänzung für den Import von Bauteilen
bei einer Baugruppe gemacht, so dass man nun die Bauteile nicht nur über
die ID sondern auch über den Bauteilnamen importieren kann. Vielleicht
ist das ganze ja auch für andere hilfreich. Der Patch gegenüber dem
branch uneist_kami89 hängt an.
Viele Grüße,
Christoph
Hallo Christoph,
Danke für den Patch, das ist keine schlechte Idee. Ich habe ihn kurz
angeschaut und werde ihn dann gleich übernehmen (mit ein paar
Anpassungen - z.B. wenn es zu einem Namen mehrere exakt gleichnamige
Bauteile gibt, soll der Vorgang abgebrochen werden weil das Ergebnis
nicht eindeutig ist).
Momentan bin ich mich übrigens grad selbst am bestrafen ;-)
Als ich die Klasse "File" und die davon abhängigen Klassen erstellte,
war mir bereits bewusst dass "File" ein nicht sehr geschickter Name ist,
bin aber grad auf keine bessere Idee gekommen. Danach ist es leider in
Vergessenheit geraten... Nun bin ich dabei, den Namen "File" durch
"Attachement" zu ersetzen, diese neue Bezeichung ist viel
aussagekräftiger und zutreffender. Man kann sich ja etwa vorstellen
wieviel Arbeit das gibt... Und nein, automatisches copy&replace geht
nicht, da "File" auch in anderen Zusammenhängen verwendet wird ;-)
Ich werde dann schon bald diese zwei Änderungen ins Repository
hochladen. Dann muss man auf jeden Fall wieder eine Datenbank der
Version 12 laden, da auch die Tabelle "files" in "attachements"
umbenannt wird.
mfg
Hallo,
es freut mich, dass du die Funktion einbaust. Dadurch, dass in meinem
Fall die Namen eindeutig sind, habe ich nicht dran gedacht, da auf
Mehrdeutigkeit zu testen.
Von Klassennamen, mit denen man sich ein Bein stellt, kann ich auch ein
Lied singen (ich verdiene meine Brötchen als Softwareentwickler). Da
hilft dann einfach nur Augen zu und durch :)
Im Moment ist bei mir das Datenschema Version 13. Heißt dass, dass ich
erst ein Downgrade machen muss, bevor ich dann die neue Version mit den
zwei Änderungen verwenden kann?
Viele Grüße,
Christoph
So, die Änderungen sind nun im Repository (r616).
Ich habe vorher gar nicht gesehen, dass im Patch das Suchen des
entsprechenden Bauteiles in "build_deviceparts_import_template_loop()"
geschah, das ist irgendwie nicht so passend weil diese Funktion nur für
das Erzeugen eines Template-Loops (also für die Ausgabe) verantwortlich
ist. Die eigentliche Import-Funktion braucht die Suchfunktion allerdings
auch, daher habe ich sie nun in eine eigene Funktion
"match_devicepart_names_to_ids()" ausgelagert. Scheint soweit zu
funktionieren, wenns Probleme gibt bitte melden :-)
Christoph Emonds schrieb:> Von Klassennamen, mit denen man sich ein Bein stellt, kann ich auch ein> Lied singen (ich verdiene meine Brötchen als Softwareentwickler).
Ja, das glaube ich :-)
Ich bin zwar bei solchen Sachen ein Perfektionist, habe aber das Problem
dass mir manchmal keine passenden Namen einfallen. Das war mir auch
bewusst als ich die Klasse "File" getauft habe, daher stand das schon
von Anfang an auf meiner (virtuellen :-) ToDo-Liste. Die virtuelle
ToDo-Liste ist aber leider auch nicht von Datenverlust befreit :-D
Christoph Emonds schrieb:> Im Moment ist bei mir das Datenschema Version 13. Heißt dass, dass ich> erst ein Downgrade machen muss, bevor ich dann die neue Version mit den> zwei Änderungen verwenden kann?
Ja, die Entwicklung findet momentan im Branch "uneist_kami89" statt, und
die aktuelle Version ist noch nicht für den produktiven Einsatz gedacht.
Heisst also, ich passe die Datenbankstruktur ab und zu wieder an, ohne
ein entsprechendes Update rauszugeben. Stattdessen muss wieder eine alte
Datenbank geladen werden, sonst läuft Part-DB nicht mehr korrekt.
Ein Downgrade auf v12 gibt es nicht. Ich hoffe, du setzt Part-DB 0.3.0
nicht schon produktiv ein? ;-)
mfg
Vielleicht sollte man sich ein Deutsch-Englisch-Wörterbuch neben den PC
legen, um passende englische Wörter zu finden? ;-)
PS: Mittlerweile hab ich auch Win7 in einer virtuellen Umgebung. So kann
ich dann auch in meinem Kurzurlaub um den 1. Mai den Filemanager weiter
entwickeln.
Hmmm... Angenommen ich würde gerne die Datenbankstruktur meines
"Testsystems" migrieren, kann ich mir die dafür nötigen Änderungen aus
den Commit messages zusammensuchen und selber ein Änderungsskript
erstellen? Hast du denn schon eine Idee, wann ein neues Release kommt?
Hatte mich da wohl von dem RC1 auf der Startseite dazu verleiten lassen,
die Version schon einzusetzen.
Vielen Dank schonmal :)
Viele Grüße,
Christoph
> Hatte mich da wohl von dem RC1 auf der Startseite dazu verleiten lassen,> die Version schon einzusetzen.
Naja...Wir entwickeln ja laufend im Repository, und momentan arbeiten
wir auf die 0.3.0 RC1 hin. 0.3.0 Ist also quasi das Ziel, nicht der
momentane Stand. Wenn die RC1 fertig ist, wird sie als Downloadpaket
angeboten. Solange wir kein fertiges Paket anbieten, ist es noch nicht
für Endanwender bestimmt.
Mir scheint, vielen Leuten ist nicht klar bewusst dass das Repository
grundsätzlich nur für die Entwickler gedacht ist. Für den Endanwender
stricken wir dann Archive, die man (ohne SVN Client) runterladen kann.
> Hmmm... Angenommen ich würde gerne die Datenbankstruktur meines> "Testsystems" migrieren, kann ich mir die dafür nötigen Änderungen aus> den Commit messages zusammensuchen und selber ein Änderungsskript> erstellen?
Also zurück zur v12 migrieren wäre ein riesen Aufwand, bzw. u.U. gar
nicht mehr möglich weil dort gewisse Funktionen noch nicht zur Verfügung
standen. Wenn es dir nichts ausmacht wäre es einfacher, wenn du deine
Datenbank von nun an jeweils selber aktualisierst, bis dann die RC1
offiziell fertig ist. Bis dahin sollte es eigentlich fast keine
Änderungen mehr geben (hoffe ich mal ;-).
Die Datenbankupdates sind in der updates/db_update_steps.php
aufgelistet.
Im Commit von r616 siehst du, was du alles ändern müsstest, damit du
deine Datenbank mit der Version 0.3.0 weiterverwenden könntest.
Wenn es nur eine handvoll Artikel sind, würde ich aber eher eine leere
DB v12 nehmen und die Bauteile von Hand übertragen. Halt mit den
Einschränkungen von v12, die z.B. nur einen einzigen Lieferanten pro
Bauteil unterstützt.
> Hast du denn schon eine Idee, wann ein neues Release kommt?
Das ist schwierig zu sagen. Sobald Udo den Dateimanager fertig hat,
können wir ausgiebig mit dem Testen anfangen und dann schon bald einen
ersten Release Kandidaten rausgeben. Ausser die 80/20-Regel macht uns
noch einen Strich durch die Rechnung :-)
Hallo,
mir war schon bewußt, dass das 0.3.0 Repository nicht stabil ist, aber
ich bin halt eher davon ausgegangen, dass sich das weniger auf die
Datenbank als vielmehr auf das Frontend bezieht. Ich hatte mir zuerst ja
auch die 0.2.2 installiert, aber später dann geupgradet, weil ich ja
noch die Änderungen bzgl. des Bauteileimports machen wollte. Da sich ja
schon einiges im Vergleich zur 0.2.2 getan hat, hielt ich es für
sinnvoll, das ganze dann in der aktuellen Version zu machen.
Das ganze ist aber auch kein Problem. Ich bastel mir jetzt einfach immer
wenn es noch Änderungen am Datenbankschema gibt ein Updateskript und
pass das ganze dann bei mir an. Solange solche Änderungen in den
Commitmessages stehen, geht das schon :-)
Auf jeden Fall vielen Dank für das Tool und eure Arbeit.
Viele Grüße,
Christoph
Christoph Emonds schrieb:> Solange solche Änderungen in den> Commitmessages stehen, geht das schon :-)
Jup, das werden sie. Sollten aber wie gesagt nicht mehr häufig
vorkommen.
Christoph Emonds schrieb:> Auf jeden Fall vielen Dank für das Tool und eure Arbeit.
Gerne doch :-)
@K.J. falls du mitliest:
In der Online Demo sollte man nun auch wiedermal eine Datenbank der
Version 12 einspielen. Ausserdem, wäre es vielleicht möglich Doxygen auf
dem Server zu installieren? Ich habe nun nämlich die Doxygen Doku aus
dem Branch entfernt, weil die stört in den Commits einfach zu stark, die
wirklich wichtigen Änderungen gehen dabei unter. Wer sie braucht, kann
sie ja ganz einfach selber erstellen, das Doxyfile ist ja vorhanden.
Wenn nun auf dem Demo Server Doxygen auch installiert wäre, könnte man
ab und zu mal in den Entwicklerwerkzeugen auf "Doxygen Doku
aktualisieren" (o.ä.) klicken, dann steht auch diese Doku wieder online
zur Verfügung. Noch komfortabler wäre natürlich, wenn sie jeweils nach
dem auschecken der aktuellen SVN Revision gleich automatisch erstellt
werden würde, muss aber nicht unbedingt sein.
Gruss
Urban
hi,
erstmal danke für das tolle System, es ist sehr hilfreich!
Ich glaube ich habe einen Bug gefunden: Wenn ich einem Bauteil ein
falsches Bild hochgeladen habe und zum ausbessern ein anderes Bild
hochlade, hat das Bauteil gar kein Bild mehr und jeder weitere Versuch
funktioniert nicht. Aber hochgeladen wird das Bild, also es ist immer im
img/ Verzeichnis. (Habe auch probiert das Bild direkt im Dateisystem zu
löschen, es wird einfach beim hochladen neu erstellt aber im Bauteil
wird kein Bild angezeigt).
c,Ya Chris.
also aktuell ist keine demo funktionsfähig oder sehe ich das falsch. bin
heute mal wieder hierher gekommen um mich etwas über den weiteren
verlauf zu informieren. meine SVN 512er läuft immernoch stabil mit
einigen bugs die aber eher nebensächlich sind. ansonsten ist die partdb
hier im volleinsatz zu unseren Kardex Lagerschränken.
wollte gerade mal die weinbauer demo testen was sich so getan hat bisher
aber dort geht gar nix. weder mit ie noch chrome. anscheinend ist da was
am template falsch wodurch mir das neuerstellen von artikeln verwährt
bleibt.
wäre schön wenn man da extern wieder bisl testen könnte und entsprechend
beid er fehlersuche hilft. Ich habe auch paar bugs in der issue list auf
google eingetragen. ob diese noch in der neuesten vorhanden sind kann
ich aber aufgrund der oben genannten probleme gerade nicht sagen.
gruß kirkdis.
PS: wie schon vor nem halben jahr erwähnt kann ich auch gerne am wiki
und anleitungen zur partdb mithelfen allerdings bräuchte ich da mal ne
neue version zum testen
Hi, ich beuchte mittlerweile mal Hilfe (am besten einer der Entwickler),
zum Thema GPL neuerdings trudelt hier ne menge Post ein, der Part-DB
betreffend mag sich jemand mit mir per Mail in Verbindung setzen.
Danke
hallo kirkdis,
Also momentan gibts nur einen aktiven Branch, das ist der
"uneist_kami89". Der sollte lauffähig sein, in der Online-Demo muss nur
noch eine neue Datenbank eingespielt werden dann läufts dort auch
wieder.
Die anderen Branches sind veraltet, da gibts nichts Interessantes mehr.
Hilfe bei der Doku können wir bestens gebrauchen, dazu gibts im
genannten Branch extra ein DokuWiki das noch auf einen Freiwilligen
Helfer wartet :-)
@K.J.
hast eine PN bekommen.
mfg
Danke ist mir wohl irgendwie entgangen, gibt noch das Typische umlaut
Problem aber da kümmer ich mich gleich noch drum.
@kami installiere auch grade doxigen mal sehn ob ich das hinbekomme weil
mein Server recht restriktiv ist mit fremd Programme ausführen.
Meine Demo funktioniert derzeit gar nicht, da sie einen Stand ausserhalb
unseres SVN-Repos repräsentiert. Ich werde mal die Demo auf den Stand
des Repos updaten und auch mal den Filemanager weiter schreiben. Gerade
das Thema Javascript ist ja nicht ohne, weil fast jeder Browser seine
Eigenheiten hat und man sich oft stundenlang die passende Doku zusammen
suchen muss. Vorallem die unterschiedlichen IEs sind grauslich!
Javascript-Entwickler sind gerne willkommen :)
Wenn bei mir auf der Arbeit die Akkreditierung im Juni gelaufen ist,
dann dürfte ich auch wieder mehr Zeit (und Nerven) für die Entwicklung
haben.
Grüße
Udo
Udo Neist schrieb:> Vorallem die unterschiedlichen IEs sind grauslich!>> Javascript-Entwickler sind gerne willkommen :)>>> Grüße> Udo
Tu dir das nicht an alles unter 7/8 ist für die Reste Tonne und ziemlich
unbeherrschbar, bau ne abfrage rein das der User updaten muss, der
filemanager ist momentan ja nicht zwingent damit die Part-DB leuft.
Doxigen scheint zu laufen auf der DEMO.
Den IE 6 und älter sind bei mir nicht auf der Liste. Warum soll ich mit
den JS (nicht zu verwechseln mit Javascript; M$ wollte keine Lizenzen
kaufen, daher diese Variante der ECMA-Scriptfamilie) unterstützen? Erst
mit IE 7 näherte sich M$ an Javascript an, wobei da selbst im IE 10 noch
Differenzen zum Quasi-Standard der Gecko/Webkit-Systeme bestehen.
Leider ist mir durch eine kleine Unachtsamkeit mein Raid mit den
virtualisierten Windoofs (XP und 7) "abgeraucht", muss beides morgen neu
installieren. Zum Glück hab ich aber noch ein XP auf dem Notebook ;-)
K. J. schrieb:> gibt noch das Typische umlaut> Problem aber da kümmer ich mich gleich noch drum.
Ja, das leidige Problem mit den Umlauten... ;-)
Das Problem liegt aber höchstwahrscheinlich nicht an deiner
Installation, sondern an meiner Datenbank.
Wenn ich mich nicht täusche, liegt das Problem genau genommen an älteren
Versionen von Part-DB. Wenn man da nämlich ISO-8859-1 als HTTP
Zeichensatz verwendet hat, dann wurden die ISO-8859-1-codierten Zeichen
als UTF-8 codierte Zeichen an die MySQL Datenbank übergeben. Beim MySQL
connect ist nämlich kein Zeichensatz angegeben, also müsste automatisch
UTF-8 verwendet werden.
Das würde dann also bedeuten, dass alle Benutzer, die den HTTP
Zeichensatz auf ISO-8859-1 stehen haben, nun falsch codierte Zeichen in
ihrer Datenbank haben. Solange man zum Decodieren auch wieder ISO-8859-1
verwendet, fällt das natürlich nicht auf. Jetzt (v0.3.0) kann man
allerdings den Zeichensatz nicht mehr wählen (weils nichts bringt), und
die falsch codierten Zeichen in der Datenbank äussern sich in Form von
kryptographischen Zeichen auf der Webseite.
Man könnte natürlich weiterhin den Zeichensatz auf ISO-8859-1 stellen,
dann fällt das Problem nicht auf, aber das behebt nicht die Ursache
sondern nur das Symptom.
Die Frage ist jetzt allerdings, wie wir das Problem lösen, ohne dass die
Benutzer all ihre Umlaute von Hand austauschen müssen. Vielleicht würde
es ein MySQL Befehl im Datenbankupdate tun, das alle falsch codierten
Umlaute durch richtig codierte Umlaute ersetzt. Muss mal schauen ob das
funktioniert...
Dabei muss ich aber noch anmerken, dass das alles nur Vermutungen sind.
Ich habe nicht so wirklich viel Erfahrung mit dieser Problematik, ich
habe einfach mal versucht das Phänomen mit logischen Schlussfolgerungen
nachzuvollziehen ;-D
K. J. schrieb:> Doxigen scheint zu laufen auf der DEMO.
Wunderbar!
mfg
mysql und Zeichenkodierung ist schon seit Jahren ein echtes Problem.
Evtl. kann man da mit ein paar manuellen Konvertieroutinen Abhilfe
schaffen, letztendlich muß die Kodierung von der Datenbank über php und
dem Webserver bis zum Browser konsistent sein :-/
Grüße
b.r
Okay also ich habe gerade gemerkt dass meine Testdatenbank-Datei im SVN
schon fehlerhaft ist, daher werden die Umlaute dann auch nach dem Import
noch falsch dargestellt. Ich habe die Datei nun korrigiert und werde sie
mit dem nächsten Commit hochladen.
Irgendwie kommen die falsch codierten Werte ziemlich sicher von einem
Bug in einer früheren Version von Part-DB. In der Zwischenzeit habe ich
aber mindestens einmal meine Datenbank exportiert und wieder Importiert
(Umzug des Servers), durch den Import/Export konnten meine Daten aber
ev. noch zusätzlich beschädigt worden sein. Denn mich macht etwas
stutzig, dass in meiner Datenbank ein 'ä' ganze 4 Bytes belegt, das kann
also nicht nur durch ein falsch codiertes Zeichen entstanden sein. Da
muss mindestens zweimal nacheinander etwas schiefgelaufen sein.
Dieser spezielle Fall lässt sich vermutlich nur durch Textersetzung
korrigieren. Allerdings frage ich mich, ob noch mehr Leute von diesem
Problem betroffen sind.
Hat jemand noch eine Datenbank, die mit einer Part-DB <= 0.2.2 betrieben
wird und noch nie exportiert/importiert wurde?
Falls ja, würde mich interessieren, wie dort die Umlaute abgespeichert
werden. Werden sie in phpMyAdmin korrekt angezeigt? Falls nicht, kann
man sich den Hex-Code anschauen, z.B. damit:
1
SELECT HEX(`name`) FROM categories WHERE ID = 5
Das Umlaute-Problem ist sicher relativ leicht zu lösen. Viel schwieriger
ist es aber, rauszufinden, wie die Datenbanken unserer Nutzer überhaupt
aussehen ;-)
mfg
Eventuell ist in meinem Testbranch noch eine alte Version vorhanden.
PS: Ich habe zwar am Filemanager weiter gearbeitet, kann aber leider
keine Fortschritte beim IE vermelden. Bis einschliesslich IE9 fehlt mir
FormData(), um einen verbesserten Uploader fertig zu stellen. Da muss
ich wohl oder übel auf Flash oder die alte Methode zurück greifen :(
Wobei Flash ja nicht überall zu finden wäre.
Udo Neist schrieb:> Eventuell ist in meinem Testbranch noch eine alte Version vorhanden.
OK wäre super wenn du da bei Gelegenheit mal nachschauen könntest :-)
Udo Neist schrieb:> PS: Ich habe zwar am Filemanager weiter gearbeitet, kann aber leider> keine Fortschritte beim IE vermelden. Bis einschliesslich IE9 fehlt mir> FormData(), um einen verbesserten Uploader fertig zu stellen. Da muss> ich wohl oder übel auf Flash oder die alte Methode zurück greifen :(> Wobei Flash ja nicht überall zu finden wäre.
Hmm also das klingt, als ob es noch etwas länger dauern wird (?).
Theoretisch könnten wir sonst ja auch nochmal den simplen Upload-Button
wie bisher verwenden bis der neue Dateimanager fertig ist. Dann könnten
wir den ersten Release Kandidat der Version 0.3.0 schon sehr bald zum
Download anbieten, und du kannst dir für den neuen Uploader problemlos
die Zeit nehmen, die du brauchst.
Arbeiten kann man ja auch mit dem alten Uploader, bisher ging das
schliesslich auch :-)
Falls niemand etwas dagegen hat, würde ich mich dann mal ums
Fertigstellen der 0.3.0 RC1 kümmern. Das Problem mit der
Zeichencodierung hätte dann jetzt erstmal höchste Priorität, denn das
muss noch vor dem Release behoben werden.
@kami das ist Definitiv ein Datenbank Problem das bekommen wir nicht im
griff 4-Byte für umlaute hat was mit dem Zeichensatz zu tun.
Du hast div. Möglichkeiten den Zeichensatz einzustellen, im Mysql, PHP
und im Script selber, zuletzt noch im Backup, und das sind alles User
Probleme.
Das ist ziemlich unhändelbar die meisten CMS geben das auch nur vor fürs
Script und um den Rest muss sich der User kümmern.
Das einzige was mir so einfallen würde ist die Sonderzeichen vor der
Weitergabe in die DB umzuwandeln und beim Rausholen nochmal, aber das
wehre ziemlich unnötiger Overhead, im Normalfall gibt man seine Backups
nicht weiter.
Also ich habe mal einen Test gemacht. Neue Datenbank angelegt, Struktur
mit dem SQL Skript aus v0.2.2 erzeugt und meine Part-DB 0.2.2 mit dieser
Datenbank verknüpft. Dann eine neue Kategorie 'ä' angelegt und in
phpMyAdmin den Bytecode davon angeschaut.
Das Zeichen 'ä' sollte dem Bytecode 0xC3 0xA4 (UTF-8) bzw. 0xE4
(ISO-8859-1) entsprechen.
Ergebnis mit HTTP Zeichensatz UTF-8: 0xC3 0x83 0xC2 0xA4
Ergebnis mit HTTP Zeichensatz ISO-8859-1: 0xC3 0xA4
Erklärung:
Bei ISO-8859-1 wird das 'ä' als 0xE4 von PHP entgegengenommen und MySQL
übergeben. Da für die Übertragung kein Zeichensatz vereinbart wurde,
beginnt hier ein Glücksspiel. In meinem Fall geht MySQL wohl davon aus,
dass es ISO-8859-1 codiert ist. Intern arbeitet MySQL aber mit UTF-8,
also wird das Zeichen nach UTF-8 konvertiert und als 0xC3 0xA4 in der
Datenbank abgelegt. In diesem Fall wird das Zeichen also richtig codiert
in der Datenbank abgelegt.
Bei UTF-8 wird das 'ä' als 0xC3 0xA4 von PHP entgegengenommen und MySQL
übergeben. MySQL nimmt aber wieder an es sei ISO-8859-1. 0xC3 entspricht
dann 'Ã', 0xA4 entspricht '¤'. Beide Zeichen werden dann wieder
(unnötigerweise!) nach UTF-8 konvertiert. 'Ã' ergibt dann 0xC3 0xA4, '¤'
entspricht 0xC2 0xA4.
Zusammengefasst kann man also sagen, dass zwei Fehler das Problem
verursachen:
- Beim Verbindungsaufbau mit dem MySQL Server wird kein Zeichensatz
vereinbart. Es ist reine Glückssache, dass der richtige Zeichensatz
verwendet wird
- Der Benutzer kann in Part-DB den HTTP Zeichensatz selber einstellen.
Wählt er den falschen, gibts ein Durcheinander.
Lösungsvorschlag:
- Für die MySQL-Verbindung wird IMMER UTF-8 verwendet (hardcoded). Das
ist in der aktuellen Entwicklerversion bereits so gemacht.
- Der HTTP Zeichensatz wird IMMER auf UTF-8 eingestellt (hardcoded), der
Benutzer kann es nicht ändern. Was er nicht ändern kann, kann er nicht
falsch machen ;-) Ausserdem wäre hier m.M.n. ISO-8859-1 sowieso falsch,
weil unsere PHP/TMPL Dateien ja auch UTF8-codiert sind.
Machen wir diese Umstellung, wird es Benutzer geben die nach dem Update
auf 0.3.0 das gleiche Problem haben wie ich. Lösen könnte man es mit
Search&Replace in der Datenbank.
Ich werde mal schauen wie die "4-Byte-Codes" der wichtigsten paar
Zeichen (Umlaute und noch ein paar Sonderzeichen) lauten und ein
entsprechender Search&Replace Befehl ins Datenbankupdate einbauen.
Man könnte beim Update einfach einen Dump der Datenbank machen, den mit
Recode auf UTF-8 trimmen und wieder einspielen. 100% sicher ist das
Verfahren nicht, aber immerhin besser als das Scannen aller Daten und
halbmanuell das ändern. Beim Einlesen "--default_character_set utf8"
nicht vergessen, damit MySQL nicht wieder was falsch macht ;-)
Dump:
mysql --default_character_set utf8 -uUSER -pPASS DATABASE <dump
Weitere Optionen können hilfreich sein, z.B.
--add-drop-table
--hex-blob
--create-options
--extended-insert
Wobei einige Optionen bereits mit per Default gesetzt sind (siehe auch
--opt).
Udo Neist schrieb:> mysqldump
Können wir leider nicht verwenden weil das bei den meisten Hostern nicht
läuft ;-)
Part-DB sollte möglichst ohne exec() auskommen sonst kann man es auf
einem normalen Webspace nicht mehr verwenden...
Das Ersetzen mit dem MySQL Befehl "REPLACE()" habe ich grad getestet,
funktioniert zumindest bei meiner fehlerhaften Datenbank super. Ist
sicher nicht sehr elegant, aber allemal besser als gar nichts
unternehmen ;-)
Hallo,
ich hab da ein Problem mit part-db beim Webhoster Strato. Anscheinend
stimmen die Links nicht. Beim Aufruf der Startseite bekomme ich folgende
Meldungen:
The requested URL /mnt/webj/c0/03/5587203/htdocs/part-db/navigation.php
was not found on this server.
Nach meinem Verständnis ist der Teil "/mnt/webj/c0/03/5587203/htdocs"
der Pfad auf dem Server, jedoch nicht die richtige URL von außen.
Versuchsweise habe ich in "start_session.php" folgende Zeile angepasst:
define('BASE_RELATIVE', './');
Danach konnte ich auf part-db zugreifen. Allerdings denke ich mal das
dass nicht so ganz der richtige Weg ist. Hat da einer von euch einen
Tipp ?
Gruß
Dirk
So, habe grad nochmal ein Update hochgeladen (r619), da sind noch ein
paar wichtige Änderungen drin. Unter anderem auch eine Migration der
alten config.php in das neue Format, damit man die Einstellungen nicht
nochmal tätigen muss.
Übrigens war bisher ja der PayPal-Link tot, weil Jacobs PayPal-Konto
nicht mehr erreichbar ist. Nach Absprache mit K.J. geht der Link nun
(zumindest vorläufig) auf mein PayPal Konto. Falls tatsächlich Spenden
getätigt werden, werde ich es sammeln und bei Erreichen eines
nennenswertes Betrages hier bekanntgeben um das weitere Vorgehen
abzuklären.
Vermutlich werde ich schon bald den aktuellen Entwickler-Branch in den
Trunk mergen, und dann ein Paket für die 0.3.0 RC1 zum Download
anbieten.
mfg
Urban B. schrieb:> Übrigens war bisher ja der PayPal-Link tot, weil Jacobs PayPal-Konto> nicht mehr erreichbar ist. Nach Absprache mit K.J. geht der Link nun> (zumindest vorläufig) auf mein PayPal Konto. Falls tatsächlich Spenden> getätigt werden, werde ich es sammeln und bei Erreichen eines> nennenswertes Betrages hier bekanntgeben um das weitere Vorgehen> abzuklären.
Jup passt, Paypal ist manchmal recht kompliziert wen das Konto aus
Sicherheitsgründe dicht ist, da kein Geld drauf war tue ich mir das
nicht an.
Will ungerne deren Datenbank mit den geforderten Sachen füttern, die
haben echt komische Forderungen.
>> Vermutlich werde ich schon bald den aktuellen Entwickler-Branch in den> Trunk mergen, und dann ein Paket für die 0.3.0 RC1 zum Download> anbieten.>> mfg
Das Paket muss ich glaube ich erstellen b.z.w. Uploaden, glaub das kann
ich nur als einziger.
p.s. Hab die Doku für die GPL Geschichte angefangen, leider ist das
ganze recht kompliziert die GPLv2 ist nicht wirklich einfach zu
verstehen.
So hab jetzt mal die print Anweisungen eingefügt und bekomme folgende
Ausgabe:
BASE = "/mnt/webj/c0/03/5587203/htdocs/part-db"
DOCUMENT_ROOT = "/home/strato/http/premium/rid/72/03/5587203/htdocs"
BASE_RELATIVE = "/mnt/webj/c0/03/5587203/htdocs/part-db/"
DIRECTORY_SEPARATOR = "/"
Dirk B. schrieb:> So hab jetzt mal die print Anweisungen eingefügt und bekomme folgende> Ausgabe:>> BASE = "/mnt/webj/c0/03/5587203/htdocs/part-db"> DOCUMENT_ROOT = "/home/strato/http/premium/rid/72/03/5587203/htdocs"> BASE_RELATIVE = "/mnt/webj/c0/03/5587203/htdocs/part-db/"> DIRECTORY_SEPARATOR = "/"
Du hast da zwei unterschiedliche angaben des Pfades, das kann nicht
sein.
Base_relative müsste auch anders sein nämlich der Relative Pfad der URL
also wahrscheinlich "part-db/"
Ich habe keine Ahnung was Strato da hinter den Kulissen macht, aber die
Ausgaben stammen direkt von meinem Webspace bei Strato :-(
Naja, zur Not kann ich immer noch den Pfad manuell im Source anpassen.
> Das Paket muss ich glaube ich erstellen b.z.w. Uploaden, glaub das kann> ich nur als einziger.
OK wenn es dann soweit ist melde ich mich einfach bei dir.
> p.s. Hab die Doku für die GPL Geschichte angefangen, leider ist das> ganze recht kompliziert die GPLv2 ist nicht wirklich einfach zu> verstehen.
Hehe ja das glaube ich ;-) Ich kenne mich da leider auch zu wenig aus,
müsste mich auch erst genauer informieren was da alles geregelt wird...
Dirk B. schrieb:> BASE = "/mnt/webj/c0/03/5587203/htdocs/part-db"> DOCUMENT_ROOT = "/home/strato/http/premium/rid/72/03/5587203/htdocs"> BASE_RELATIVE = "/mnt/webj/c0/03/5587203/htdocs/part-db/"> DIRECTORY_SEPARATOR = "/"
Das ist ja wirklich eine komische Sache, mit solch unterschiedlichen
Pfaden vom Server kommt Part-DB nicht zurecht. Ich habe mal ein bisschen
im Internet nachgeschaut und bin auf das hier gekommen:
http://www.strato-faq.de/artikel.html?sessionID=4ca68360450406176b63d8a14b819b56&id=10
Aber selbst diese Beschreibung passt nicht zu deinen Pfaden, da dort
deine Domain ja nicht enthalten ist. Weiss der Geier, was Strato hier
für Spielchen treibt ;-)
Ich denke mal das ist für uns Entwickler unmöglich, die korrekten Pfade
zu bekommen, vermutlich wirds also auf das hier rauslaufen:
Dirk B. schrieb:> Naja, zur Not kann ich immer noch den Pfad manuell im Source anpassen.
Ja das geht natürlich, wird dann aber bei jedem Update wieder
überschrieben. Ansonsten könnte ich noch eine Funktion einbauen, die es
explizit erlaubt, die Pfade manuell zu setzen, und die dann auch bei
einem Update nicht überschrieben werden. Werde mal schauen was man da
machen kann.
Rein für die Webseite sind die Pfade nicht so kritisch, also wenn die
Seite richtig angezeigt wird passt das schon. Allerdings kann es
Probleme geben bei den Pfaden zu Footprint-Bilder oder Dateianhängen.
Denn bevor ein Pfad zu einer Datei in der Datenbank abgelegt wird, wird
ein Replace druchgeführt, der den BASE Pfad durch "%BASE%" ersetzt. So
gibt es keine Probleme wenn man Part-DB auf einem anderen Server (mit
anderem BASE Pfad) installiert, alle Pfade in der Datenbank
funktionieren dann immernoch weil eben der absolute Pfad dort nicht
abgelegt wird. Wenn du jetzt bei der manuellen Definition der Pfade was
falsches eingibst, könnte es unter Umständen sein dass diese
Textersetzung nicht mehr funktioniert.
Allerdings wäre auch dieses Problem schnell wieder lösbar, du müsstest
dann bei einem Server-Umzug halt manuell in der Datenbank alle
Basis-Pfade noch durch "%BASE%" ersetzten, dann läufts wieder. Wichtig
ist einfach dass du das weisst, sonst ärgerst du dich nach einem Umzug
über die nicht mehr funktionierenden Dateipfade...
mfg
Eine Möglichkeit zum manuellen Setzen wäre natürlich sehr gut.
Zu den Footprints hätte ich sowieso noch eine Frage. Wenn ich z.B. ein
TQFP64 Gehäuse anlegen möchte, wie muss ich das mit den neuen Footprint
Bildern denn machen ?
Wie wäre es mit folgenden Code? Wenn BASE und BASE_RELATIVE auf das
gleiche Verzeichnis zeigen, dann wird "./" als Pfad zurückgegeben,
ansonsten einen aus DOCUMENT_ROOT zusammengebauten (altes Verhalten).
Ob es auf allen Strato-Hosts funktionieren wird, bezweifel ich.
Vielleicht setzt Strato ein BIND oder nen Link auf das Verzeichnis und
schiebt dem Apachen was anderes unter? Ziemlich merkwürdiges Setup.
b.r schrieb
> Zum Ausprobieren gibt es momentan zwei Demo-Seiten:> http://partdb.grautier.com/ ("offiziell")
leider funktioniert die Demo zur Zeit nicht
Dirk B. schrieb:> Zu den Footprints hätte ich sowieso noch eine Frage. Wenn ich z.B. ein> TQFP64 Gehäuse anlegen möchte, wie muss ich das mit den neuen Footprint> Bildern denn machen ?
Nun, das ist momentan ein bisschen blöd...Eigentlich war dafür der neue
Filemanager gedacht. Also man hätte dann den neuen Footprint angelegt
und mit dem Filemanager das passende Bild dazu ausgewählt. Da der
Filemanager aber noch fehlt, müsste man theoretisch den Dateipfad des
entsprechenden Bildes in das Textfeld "Bild:" eintippen (bzw. per
Copy&Paste aus der Footprintbilder-Übersicht).
Es gibt momentan nur einen Workaround der das etwas einfacher macht. Man
kann statt dem Dateipfad einfach z.B. "DIP28" eintippen und so
übernehmen. Weil das Bild dann aber nicht gefunden wird, taucht der
Eintrag dann unter "Footprints mit fehlerhaften Dateinamen" auf, inkl.
Vorschlägen für Dateipfade die ein "DIP28" beinhalten. Dort kann man das
passende dann anwählen und übernehmen.
In der Version 0.2.2 läuft es momentan ja auch nicht anders...
Sobald der neue Filemanager kommt, ist das Problem dann aber auch
beseitigt. Man könnte ja z.B. auch mit dem Zuweisen der Bilder noch
warten und das dann erst später machen wenn der Filemanager fertig ist.
Demo Tester schrieb:> leider funktioniert die Demo zur Zeit nicht
Huch, @K.J. hat mein Update von gestern vielleicht die config.php
zerschossen?
K. J. schrieb:> Urban B. schrieb:>> Huch, @K.J. hat mein Update von gestern vielleicht die config.php>> zerschossen?>> Jup scheinbar ;-)
Hmm ja jetzt habe ich den Fehler gesehen ;-)
Passiert dann wohl bei allen, die schon die 0.3.0 verwendeten.
Macht aber nix, beim Upgrade von der 0.2.2 auf die 0.3.0 oder wenn noch
gar keine config.php vorhanden ist sollte alles funktionieren.
Ich habe jetzt eben noch eine Versionsnummer für die config.php
eingeführt. So kann man im Falle eines Formatwechsels (wie von 0.2.2 auf
0.3.0) die alte config.php aufs neue Format updaten. Steht in der
config.php noch keine Version drin, geht das System davon aus dass es
sich um Part-DB 0.2.2 handelt, was jetzt natürlich nicht stimmt wenn man
bereits Version 0.3.0 benutzt hat weils bisher diese Versionsnummer noch
nicht gab.
Also ich habe mal einen STRATO workaround in start_session.php eingebaut
(r620). Zusätzlich gibt es jetzt auch die Möglichkeit die Pfade ganz
manuell zu setzen in der config.php, falls es noch andere so komische
Server gibt.
@Dirk B.
kannst du mal schauen ob der workaround so funktioniert?
Eine Sache war mir noch bei den Lieferanten aufgefallen. Wenn man dort
eine Webseite angibt ist der Link über dem Eingabefeld zusammengesetzt
aus der Part-db URL und der Lieferanten URL. Das funktioniert natürlich
nicht.
Aus "www.digikey.de" wird z.B. "http:/www.xyz.de/part-db/www.digikey.de
Gruß
Dirk
So heute nen Barcode Scanner bestellt, das einzige was mir für mein
Lager fehlt, also werde ich mich mal dran machen das Sinnvoll
umzusetzen.
Hab extra einen Bestellt der CDC kann, so kann man den einfach als
Tastatur nutzen und man spart sich den ganzen API Krams.
Demo Tester schrieb:> leider funktioniert die Demo zur Zeit nicht
Funktionert wieder. Hab aber einen kleinen Fehler gefunden. Preise
müssen mit einem Punkt eingegeben werden. Ein Komma wird nicht
akzeptiert.
Respekt für die Arbeit
Ich habe auf der Arbeit auch einen Laserbarcodescanner, der über die
alte DIN-Tastaturbuchse bzw. PS/2 läuft. Auch einige neuere USB-Scanner
kann man als USB-HID direkt nutzen.
Dirk B. schrieb:> Eine Sache war mir noch bei den Lieferanten aufgefallen. Wenn man dort> eine Webseite angibt ist der Link über dem Eingabefeld zusammengesetzt> aus der Part-db URL und der Lieferanten URL. Das funktioniert natürlich> nicht.
Ah ja, liegt nur am fehlenden http://, werde das noch einbauen dass es
automatisch vor das www gesetzt wird wenn der Benutzer es weglässt. Ist
dann im nächsten Commit von mir drin.
K. J. schrieb:> So heute nen Barcode Scanner bestellt, das einzige was mir für mein> Lager fehlt, also werde ich mich mal dran machen das Sinnvoll> umzusetzen.
Daran habe ich auch schon lange gedacht dass wir das mal noch einbauen
müssen, super dass du dich da grad drum kümmerst :-)
Jo mich nervt das schon länger, vor alledem ist es wesentlich einfacher
bei der Teile Entnahme und co. ;-)
Meine Private ToDo liste sagt grade:
- Barcodescanner
- Labeldrucker
Hab mir mal etwas Gedanken gemacht, ich hätte gerne den Namen mit auf
dem Barcode, am besten hört sich bis jetzt CODE128 an als Barcode.
Der Aufbau wehre dann <Bauteielnamen>-<PartID><ENT> so weit ich das
jetzt raus gelesen habe ist der auch problemlos per Termoverfahren in
kleinen Dimensionen Druckbar, das kleinste bei mir wehre 66x12mm, da
passen einige Zeichen drauf.
wobei ich grade nicht weis ob der Barcode Scanner sowas wie ENTER
selbständig ausführen kann soll wohl gehen ansonsten müste mann das dem
Barcode mitgeben bei CODE128 geht das.
Schön wäre auch wenn man für jede Einkaufsinformation auch noch einen
Barcode abspeichern könnte, und zwar den vom Lieferanten. So könnte man
z.B. beim Einbuchen von bestellten Teilen den Barcode auf der Verpackung
kurz scannen und dann noch die Stückzahl eingeben. Das würde das Suchen
des Bauteiles ersparen.
Wobei es natürlich auch andere Varianten gäbe für diese Aufgabe, z.B.
ist ja noch ein "pending orders" geplant, damit könnte man eine
Bestellung mit einem Klick einbuchen. Das setzt aber natürlich voraus
dass man auch jede getätigte Bestellung in Part-DB eingibt...
Das würde gehen wen die Strichcodes der Hersteller die Bestellnummern
sind bei Reichelt z.b. ist das nicht so, da ist es wahrscheinlich
irgendeine Lagernummer.
Es gibt eine PDF-Klasse mit Barcode-Support. Mit dem passenden Drucker
hat man direkt entsprechende Etiketten. Ich habe sowas für einen Dymo
Labelwriter 320 bzw. 400 mal umgesetzt (allerdings nur unter Linux und
Cups als Printerserver).
Ja an sowas dachte ich mit PHP eine Print-bare PDF erstellen und dann
direkt drucken, es gibt zwar Barcode Tools für Server aber das sind
externe Programme und dadrauf würde ich gerne verzichten.
Das grobe PHP-Script hab ich fast fertig, ist recht einfach warte jetzt
auf den Scanner hinzukommt das ich das auch gerne am Tablett nutzen
möchte so brauche ich im Lager keinen PC, leider breuchten wir dazu
endlich mal ein Mobile Template.
Und diese ganzen Templates krams verstehe ich momentan nicht
ansatzweise.
K. J. schrieb:> Das würde gehen wen die Strichcodes der Hersteller die Bestellnummern> sind bei Reichelt z.b. ist das nicht so, da ist es wahrscheinlich> irgendeine Lagernummer.
Jo, man müsste den Barcode auf der Verpackung erstmal in Part-DB
registrieren, also einer Einkaufsinformation zuordnen...
Ganz einfach um nur mal den Scanner zu testen.
http://grautier.com/partdb/barcode.php
Der Barcode bei mir besteht aus <Bauteielname><Trenzeichen><pid>,
z.b. <MAX1181><-><84>
Die pid-0 die in der DB ja nicht vorkommen kann, nehme ich für Options:
Ausbuchen-0
Einbuchen-0
Loeschen-0
...
So kann ich über Barcodes die Options aufrufen um mit dem zweiten Scan
dann das Bauteile der PartDB Hinzuzufügen, Entfernen, Löschen...
Die Überlegung wehre noch ein Dritter Scan, z.b. für die Anzahl, oder
Löschbestätigung die frage wehre ob es nicht zuviel Overhead wehre
dreimal Scannen ist schon recht viel was Sagt ihr ?
K. J. schrieb:> Die Überlegung wehre noch ein Dritter Scan, z.b. für die Anzahl, oder> Löschbestätigung die frage wehre ob es nicht zuviel Overhead wehre> dreimal Scannen ist schon recht viel was Sagt ihr ?
Also wenn man es so macht, dass einmal gescannte Optionen und
Stückzahlen gespeichert werden, entsteht ja kein unnötiger Overhead.
Also z.B. so:
- Option "Ausbuchen" scannen
- Stückzahl "3" scannen
- Bauteil 1 scannen --> 3 Stück werden abgebucht
- Bauteil 2 scannen --> 3 Stück werden abgebucht
- Stückzahl "1" scannen
- Bauteil 3 scannen --> 1 Stück wird abgebucht
- Bauteil 4 scannen --> 1 Stück wird abgebucht
- Option "Einbuchen" scannen
- Bauteil 5 scannen --> 1 Stück wird eingebucht
- Bauteil 6 scannen --> 1 Stück wird eingebucht
- usw.
Ich habe gerade eben (r625) den aktuellen Trunk von Part-DB 0.2.2 nach
"tags" kopiert. Nun ist mein SVN Client grad dran, den Branch
"uneist_kami89" in den Trunk zu mergen. Ich hoffe das klappt, das
Programm scheint ein bisschen Mühe zu haben^^
Das heisst dann also, dass von jetzt an die ganze Entwicklung wieder im
Trunk stattfindet.
Ich würde vorschlagen, dass mal ein paar Leute das Update auf die
Version 0.3.0 RC1 machen (aus dem Trunk) und hier berichten ob alles
geklappt hat. Überschreibt man eine Part-DB 0.2.2 Installation mit der
0.3.0 RC1, sollte die alte config.php auf das neue Format aktualisiert
werden und dann noch ein Installer erscheinen um ein paar weitere
Angaben zu erfassen. Dann muss man noch das Datenbankupdate durchlaufen
lassen, und Part-DB 0.3.0 RC1 sollte einsatzbereit sein.
Wenn die ersten Rückmeldungen dann positiv sind, schnüre ich ein Paket
für die Version 0.3.0 RC1, das wir dann zum Download anbieten. (Für das
Updatepaket müssen dann z.B. das Verzeichnis "development" und den
Menüeintrag zu den noch nicht vorhandenen System-Updates entfernt
werden)
...und mein SVN Client ist immernoch am mergen...der braucht wohl noch
eine Weile ;-)
Verdammt jetzt habe ich fast eine Stunde (!!) gewartet und jetzt bricht
der SVN Client mit einer Fehlermeldung ab...das läuft ja super...
So ein Merge ist wohl eine Wissenschaft für sich. Erst wollte ich es mit
dem Merge-Befehl machen, hat aber nicht geklappt. So wie ich das
verstanden habe, müsste ich erst alle Änderungen vom Trunk, die seit dem
Erstellen des Branches "uneist_kami89" commited wurden, in den Branch
mergen, damit ich den Branch wieder in den Trunk mergen kann. Da all
diese commits aber sinnlos sind (weil im Branch eh alles neu ist) habe
ich nun versucht einfach die Dateien aus dem Branch in den Trunk zu
commiten. Jetzt reklamiert er irgendwas wegen Verzeichnissen die Dateien
beinhalten blabla...
Es kann sich also nur noch um Stunden handeln ;-)
So, jetzt scheint es geklappt zu haben (r626) :-)
Hat wieder fast eine Stunde gedauert zum hochladen...
@Udo
Naja, es gibt ja schon die Online Demo von K.J., die müsste sich morgen
ja wieder automatisch aktualisieren. Wenn das Update korrekt
funktioniert, erscheint dann zwar leider der Installer um noch ein
Administratorkennwort zu erstellen. Ist zwar blöd in der Online Demo,
sollte aber sicherheitstechnisch eigentlich unproblematisch sein (man
kann zwar die config vermurksen, aber die ist ja schnell wieder
hergestellt).
@K.J.
Falls jemand in der Online Demo ein Administratorkennwort eingibt,
kannst du in der config.php die Variable
"$config['installation_complete']['admin_password']" auf "false"
stellen, dann erscheint der Installer nochmals um ein neues Kennwort
einzugeben. Ausserdem musst du noch die Variable
"$config['is_online_demo']" auf "true" stellen.
Dann hoffen wir mal dass alles rund läuft ;-)
Urban B. schrieb:> Dann hoffen wir mal dass alles rund läuft ;-)
Schade, war wohl nichts, die Demo ist ziemlich tot :-(
@K.J.
Vielleicht bekommst du gescheite Fehlermeldungen wenn du in der
config.php das Debugging aktivierst (das setzt automatisch das error
reporting level runter damit man alle Fehlermeldungen und Warnungen zu
sehen bekommt). Oder mal die config.php ganz löschen und schauen ob dann
was kommt...
Und danke fürs ändern meiner Mailadresse, hat geklappt :-)
na, noch niemand die 0.3.0 RC1 ausprobiert? ;-)
Ich warte noch auf Fehlerberichte :-D
Wie gesagt, wenn hier die ersten Berichte positiv sind, werde ich
offiziell ein Archiv von der 0.3.0 RC1 stricken und dann zum Download
anbieten.
@K.J. Interessant wäre für mich noch, was bei der Online Demo vom Trunk
passiert ist, da funktioniert momentan ja gar nichts mehr...
Jup dadurch das du den Trunk geändert hast hat die sich zerlegt kümmer
mich Morgen drum.
Aso die neue Version läuft im Produktiv betrieb bei mir gut.
Und ich hab mal ein Testfile in das SVN gelegt für die Barcode
Geschichte ich muss mich aber erstmal mit dem Template System
auseinandersetzen, deswegen ist es grade nur nen Testfile.
Gibt es irgendwo eine kleine Installations-Anleitung?
Ich hatte mal einen Test-Server mit Version 0.2.0 (?) aufgesetzt, aber
nicht viel damit gemacht, kann ich die 0.3.0 da einfach drüber bügeln?
@K.J. OK alles klar.
M. K. schrieb:> Gibt es irgendwo eine kleine Installations-Anleitung?
Naja, so halbwegs gibts eine (mittlerweile veraltete) Anleitung im
DokuWiki:
http://partdb.grautier.com/uneistkami89/documentation/dokuwiki/index.php
Aber die bringt für die Version 0.3.0 eigentlich nicht mehr viel, die
müsste mal überarbeitet werden.
> Ich hatte mal einen Test-Server mit Version 0.2.0 (?) aufgesetzt, aber> nicht viel damit gemacht, kann ich die 0.3.0 da einfach drüber bügeln?
Ja, eigentlich muss man einfach die alten Dateien mit den Neuen
überschreiben. Da aber viele alte Dateien nicht mehr gebraucht werden,
ist es sauberer wenn man alle alten Dateien erst löscht und dann die
Neuen reinkopiert. Nur (falls vorhanden) die hochgeladenen Bilder im
Verzeichnis "img" sollten nicht gelöscht, sondern ins neue Verzeichnis
"media" verschoben werden, und die config.php sollte ebenfalls nicht
gelöscht werden. Alles andere kann man einfach löschen.
Dann sollte beim ersten Aufrufen noch der Installer erscheinen um ein
paar Eingaben zu erfassen. Dann noch das Datenbankupdate (auf das man
hingewiesen wird) durchlaufen lassen und fertig. Datenbank-Backup vor
dem Update machen falls man bereits Datensätze in der Datenbank hat!
Ich habe grad noch ein paar Änderungen hochgeladen (r631). Das
Administratorpasswort wird jetzt nicht mehr einfach als MD5-Hash in der
config.php abgelegt, sondern zuerst versalzen und dann als SHA256-Hash
abgelegt. Für den Fall, dass ein Unberechtigter Lesezugriff auf die
config.php bekommen würde, ist dies eine enorme Verbesserung der
Sicherheit weil so Rainbow Tables nichts mehr bringen.
Ich dachte, diese Änderung mache ich besser jetzt, noch bevor die 0.3.0
offiziell herausgegeben wurde. Bei denjenigen, die die 0.3.0 bereits
verwenden, wird nach dem nächsten Update einfach der
Installationsassistent nochmal aufgerufen, um das Administratorpasswort
neu einzugeben.
Bitte führt das Update auf Revision 631 durch, nachher nehme ich diese
Übergangslösung wieder raus!
Ausserdem habe ich die Dokumentation noch ein bisschen erweitert. Jetzt
ist auch erklärt, wie man Apache, PHP, MySQL und phpMyAdmin installiert.
Getestet habe ich es selbst schnell unter Ubuntu 13.04.
mfg
hmm ich beschäftige mich grad ein bisschen mit dem Thema Sicherheit um
die Doku in diesem Punkt noch zu ergänzen, und eventuell auch noch ein
paar Überprüfungen der Sicherheitseinstellungen in den Sourcecode
einzubauen.
Grundsätzlich gibt es ja zwei Varianten, Part-DB zu installieren.
Entweder installiert man es im Home-Verzeichnis und erstellt eine
Verknüpfung in /var/www, oder man installiert Part-DB direkt in
/var/www/.
Die erste Variante hat den Vorteil, dass man Part-DB ohne root-Rechte
installieren und aktualisieren kann. Allerdings müssten die Dateirechte
für die config.php und das Verzeichnis "media" dann jedoch auf 666 bzw.
777 stehen, weil der Benutzer "www-data" in diesem Fall nicht der
Besitzer der Dateien ist. Nur so kann Apache die config.php beschreiben
und Dateien nach media hochladen. Unschön ist dann allerdings, dass
die von Apache erstellten Dateien dem Benutzer "www-data" gehören, alles
andere aber dem angemeldeten Systembenutzer. Irgendwie ein bisschen ein
Durcheinander wie ich finde...
Daher frage ich mich ein bisschen, ob wir in der Doku besser nur die
zweite Variante erklären, also dass man Part-DB mir root-Rechten in
/var/www/ installiert, den Besitzer auf "www-data" und die Rechte auf
644 bzw. 755 setzt. Das Updaten wird so zwar mühsamer weil es nur mit
Root-Rechten durchgeführt werden kann, insgesamt empfinde ich diese
Variante aber als "sauberer" und auch sicherer (weil die Dateirechte so
eingeschränkter sein können, z.B. 755 statt 777).
Installiert man Part-DB auf dem Webspace eines Hosters, reichen ja auch
644/755 aus um die Dateien beschreiben zu können.
Wobei man noch berücksichtigen sollte, dass das "Update-Root-Problem"
nicht mehr vorhanden ist, sobald wir einen Updater in Part-DB
integrieren. Dann wird das Update nämlich automatisch unter dem Benutzer
"www-data" durchgeführt...
Jetzt wollte ich mal fragen, wie ihr das seht?
Ausserdem kam mir noch eine andere Idee in den Sinn. Irgendwie wäre es
doch schön, wenn alle "individuellen" Dateien in einem separaten
Verzeichnis liegen würden, sauber getrennt von den Part-DB
Systemdateien. Konkret denke ich da an ein Verzeichnis "data", in dem
dann die config.php und das Verzeichnis "media" liegt. Vielleicht
bräuchte man dieses Verzeichnis später auch mal noch für andere Sachen.
So ein data-Verzeichnis würde verschiedene Vorteile bieten:
- Möchte man regelmässige Backups von Part-DB machen, muss so neben der
MySQL Datenbank nur dieses eine Verzeichnis "data" mitgesichert werden.
Alle zu sichernden Dateien befinden sich in diesem Verzeichnis, und
sonst nirgendwo.
- Schreibrechte für den Webserver sind nur in diesem data-Verzeichnis
notwendig, überall sonst sind nur Leserechte nötig. So können die
Dateirechte sehr restriktiv vergeben werden, was sicherheitstechnisch
sicher keine schlechte Sache ist.
- (Man könnte sogar das data-Verzeichnis ausserhalb des Part-DB
Hauptverzeichnisses betreiben, indem man ein Symbolischer Link erzeugt.
So könnte das data-Verzeichnis z.B. auch auf einer Netzwerkfreigabe
liegen, falls das jemand brauchen kann...)
Was meint ihr dazu?
Der einzige Nachteil dieser Umstellung ist eigentlich die Umstellung an
sich^^ Solange die 0.3.0 aber noch nicht offiziell freigegeben wurde,
sollte das aber nicht so tragisch sein...
Ich wäre froh um Rückmeldungen.
mfg
Urban B. schrieb:> Jetzt wollte ich mal fragen, wie ihr das seht?
Ich bin unbedingt für die Installation unter root-Rechten. Diese
Frickeleien mit Benutzerrechten sind einfach nur Murks.
Die Trennung von Code und Konfiguratiosdaten etc. ist auch
wünschenswert.
Urban B. schrieb:> Was meint ihr dazu?
Eine Trennung von Code und Benutzerdaten würde ich auch sehr begrüßen,
vor allem in Hinsicht auf Backups.
Ich würde es durchaus nützlich finden wenn der "Durchschnittspreis für 1
Stk.: *,* €" gleich direkt bei der Bauteileübersicht als Spalte
angezeigt werden würde.
Wie legt man eig in der 0.2.2 Version Footprints an?
Die Footprints habe ich hochgeladen, werden auch unter Tools >
Footprints angezeigt, unter Bearbeiten > Footprints habe ich mir bereits
eine kleine Struktur angelegt, aber ich kann nirgends ein "Bild"
auswählen wie hier im Forum einige Beiträge weiter oben beschrieben
wurde.
Okay ich habe schonmal damit begonnen ein data-Verzeichnis zu erstellen,
und die Doku ist jetzt umgeschrieben für die Installation als root,
direkt in /var/www. Werde das Update bald hochladen.
Gerald *. schrieb:> Ich würde es durchaus nützlich finden wenn der "Durchschnittspreis für 1> Stk.: *,* €" gleich direkt bei der Bauteileübersicht als Spalte> angezeigt werden würde.
Gute Idee, habe das gleich in die v0.3.0 mit eingebaut. Ist aber
standardmässig nicht aktiviert, man muss diese Spalte in der config.php
selber aktivieren. Konkret muss man die Zeile mit dem Arrayelement
"$config['table']['category_parts']['columns']" aus der
config_defaults.php in die config.php kopieren und dort noch die Spalte
"average_single_price" einfügen. Ist halt bis jetzt noch nirgens
dokumentiert welche Spalten zur Verfügung stehen, das muss dann auch mal
noch in die Doku eingebaut werden...
> Wie legt man eig in der 0.2.2 Version Footprints an?> Die Footprints habe ich hochgeladen, werden auch unter Tools >> Footprints angezeigt, unter Bearbeiten > Footprints habe ich mir bereits> eine kleine Struktur angelegt, aber ich kann nirgends ein "Bild"> auswählen wie hier im Forum einige Beiträge weiter oben beschrieben> wurde.
Ich vermute mal, diese Option ist erst nach der Veröffentlichung von
0.2.2 hinzugefügt worden, steht also nur zur Verfügung wenn man Part-DB
direkt per SVN runtergeladen hat. Am besten wartest du auf die Version
0.3.0 :-)
lol, mir ist grad noch was merkwürdiges aufgefallen^^
In der Spalte "Datenblätter" fehlt bei mir im Firefox plötzlich das Icon
für alldatasheet.com. Dateipfad habe ich überprüft, der passt. Cache
geleert, im privaten Modus vom FF probiert, bringt alles nichts. Die
anderen zwei Icons werden richtig angezeigt. Dann habe ich mal die
Bilddatei umbenannt, dann funktionierts wieder. Wieder den alten
Dateinamen gegeben, funktioniert nicht mehr.
Lustigerweise heisst die Bilddatei "ads.png". Da ich es mir nicht anders
erklären konnte, vermutete ich mal dass Firefox aufgrund des Dateinamens
meint, dass es sich bei dem Bild um Werbung handelt. Dann kam mir in den
Sinn, dass es dann aber auch am AdBlock liegen könnte. Und tatsächlich:
Adblock deaktiviert --> Bild wird angezeigt. AdBlock aktiviert --> Bild
wird nicht angezeigt xD
Ich werde dann die Datei von "ads.png" wohl besser mal nach
"alldatasheet.png" umbenennen... ;-)
Urban B. schrieb:> Gute Idee, habe das gleich in die v0.3.0 mit eingebaut. Ist aber> standardmässig nicht aktiviert, man muss diese Spalte in der config.php> selber aktivieren.
Schon mal ein dickes Danke im voraus.
Urban B. schrieb:> Am besten wartest du auf die Version 0.3.0 :-)
Die Umsetzung in der Demoversion gefällt mir schon gut.
Ich bin schon auf das Release gespannt :)
Es ist soweit! Part-DB 0.3.0 RC1 steht ab sofort zum Download bereit!
:-)
https://code.google.com/p/part-db/downloads/detail?name=Part-DB_0.3.0.RC1.tar.gz
In Part-DB 0.3.0 sind jetzt übrigens auch .htaccess Dateien enthalten,
um die Verzeichnisse vor unbefugtem Zugriff zu schützen. Nähere Infos
dazu gibts in der Dokumentation.
Leider ist die Doku momentan aber nicht online verfügbar. Für diesen
Fall habe ich im Verzeichnis "readme" die Datei "INSTALL.txt" noch
ergänzt, ist halt nicht so schön zu lesen weils in Wiki-Syntax
geschrieben ist, aber besser als nichts :-)
@K.J. wäre super wenn du die Online-Demo noch aktualisieren könntest,
damit die Installationsanleitung aufgerufen werden kann.
mfg
Bin grad noch auf eine Idee gekommen. Wir haben ja noch den Webspace von
Christian (holle), da habe ich kurzerhand mal die Doku hochgeladen um
die Zeit zu überbrücken bis die offizielle Demo wieder aktuell ist:
http://kami89.myparts.info/dokuwiki/doku.php
Ist sonst etwas mühsam wenn man sich mit der INSTALL.txt begnügen
muss...
Danke an dieser Stelle nochmal an Christian, und sorry dass es so lange
dauert bis die Benutzerverwaltung umgesetzt wird ;-)
Ach so, ich dachte dass die Demo "Part-DB - 0.2.2 SVN (Aktuell)" auch
täglich ein Update aus dem Trunk holt, und die Demo "Part-DB - 0.3.0 SVN
Testversion" halt aus dem Branch ;-)
Daher ging ich davon aus, dass die Demo "Part-DB - 0.2.2 SVN (Aktuell)"
auch auf die Version 0.3.0 updaten müsste, da die 0.3.0 ja nun im Trunk
liegt.
Dass die Demo "Part-DB - 0.3.0 SVN Testversion" nicht mehr aktualisiert
wird, liegt daran, dass ich den Branch "uneist_kami89" gelöscht habe,
weil die Entwicklung nun ja wieder im Trunk stattfindet und der Branch
daher nicht mehr benötigt wird.
Das Beste wäre dann wohl vermutlich, wenn du die Demo "Part-DB - 0.3.0
SVN Testversion" einfach vom Branch "uneist_kami89" auf den Trunk
umstellst, dann wird die wieder korrekt aktualisiert.
Hab noch einen Wunsch. Beim CSV oder XML export wird der Hersteller und
die Part-ID (pid) nicht in einer Spalte aufgeführt.
Wäre für diese Änderung dankbar.
Christian schrieb:> Hab noch einen Wunsch. Beim CSV oder XML export wird der Hersteller und> die Part-ID (pid) nicht in einer Spalte aufgeführt.> Wäre für diese Änderung dankbar.
Kein Problem, habs gleich eingebaut und hochgeladen
(lib/lib.export.php):
https://code.google.com/p/part-db/source/browse/trunk/lib/lib.export.php?spec=svn640&r=640
Um es zu verwenden musst du in der config.php die entsprechende
$config['export']... Zeile neu definieren (aus config_defaults.php in
die config.php kopieren und dort anpassen). Für die ID-Spalte musst du
"id", für den Hersteller "manufacturer" im String ergänzen.
Hi, nachdem ich nun ebenfalls umgestiegen bin auf die partdb hab ich
gleich mal ne Frage dazu. ;)
Ich würde mir gerne statt dem Lagerort die Bestellnummern ausgeben
lassen.(Ich meine übrigens die Listenanzeige "showparts.php?xx")
Ich weiß nicht genau wieviel Aufwand das ist aber ich würd es mir auch
selbst zutrauen. Kann ja nicht so schwer sein.. Denk ich mir.(Haha)
Leider durchblicke ich den Code noch nicht wirklich. Wäre für ein paar
Tips sehr dankbar.
Grüße CK
Hallo Christopher,
> Ich würde mir gerne statt dem Lagerort die Bestellnummern ausgeben> lassen.(Ich meine übrigens die Listenanzeige "showparts.php?xx")
mmh "showparts.php" klingt nach der Part-DB Version 0.2.2, wenn du den
Release Kandidat der Version 0.3.0 benutzt oder noch auf die finale
Version wartest, ist dein gewünschtes Feature bereits drin :-)
Da müsstest du dir mal die Dateien "config_defaults.php" und die
"config.php" anschauen, speziell die Variable
"$config['table']['category_parts']['columns']"
mfg
Das war ja fast zu einfach um wahr zu sein. Danke ich habs geschafft.
Hab gleich auf RC1 geupdated.
Zeile in der config_defaults.php lautet in meinem Fall nun
Geniales Script... netten Abend wünsche ich noch.
PS: Beim update meldete der Server "File does not exist:
/usr/share/javascript/toggle.js".
Lösung war: In der Datei "/etc/apache2/conf.d/javascript-common.conf"
die Zeile "Alias /javascript /usr/share/javascript/"
Kommentieren/Löschen und Apache neu starten.
Christopher K. schrieb:> Zeile in der config_defaults.php lautet in meinem Fall nun [...]
Jup das funktioniert so zwar, allerdings wird die config_defaults.php
beim nächsten Update wieder überschrieben und deine Einstellung geht
verloren. Daher musst du folgendes machen:
- Diese Zeile in die "config.php" (im Verzeichnis "data") einfügen
- Dort dann "$config" durch "$manual_config" ersetzen (in dieser Zeile)
- Die "config_defaults.php" wieder in Originalzustand bringen (optional)
So ist diese Einstellung dauerhaft in deiner persönlichen Konfiguration
gespeichert, die beim nächsten Update nicht überschrieben wird.
Ist halt leider noch nirgens dokumentiert dass man das so machen muss...
> PS: Beim update meldete der Server "File does not exist:> /usr/share/javascript/toggle.js".>> Lösung war: In der Datei "/etc/apache2/conf.d/javascript-common.conf"> die Zeile "Alias /javascript /usr/share/javascript/"> Kommentieren/Löschen und Apache neu starten.
hmm das scheint wohl ein Problem bei deiner Installation zu sein... Ist
mir jedenfalls bei Ubuntu 12.10 und 13.04 nicht aufgefallen wo ich
Part-DB jeweils teste.
> netten Abend wünsche ich noch.
ebenfalls :-)
Ahh, Das hat super funktioniert mit dem "$manual_config" in der
config.php. Ist natürlich die bessere Lösung.
Das "File does not exist: /usr/share/javascript/toggle.js" Problem hatte
ich bei 2 debian6 Rechnern mit froxxlor. Hatte alles via apt-get
installiert. Merken tut man es wenn man kein Menü sieht in der partdb.
;)
Vielen Dank...
Bin gerade dabei Part-DB 0.3.0 RC1 zu testen.
Gefällt mir grundsätzlich sehr gut :-)
Dazu habe ich vom bestehenden Part-DB 0.2.2 die Datenbank kopiert und
die frische Installation von 0.3.0 RC1 eingefügt => funktioniert alles
keine Probleme.
Jetzt habe ich noch die ganzen Bilder von img nach data/media kopiert =>
um jetzt wieder Vorschaubilder (thumbnails) zu erhalten müsste ich jetzt
jeden Artikel öffnen und das Häkchen "Als Hauptbild verwenden" setzen.
Lösungsvorschlag:
Sollte nur ein Bild vorhanden sein, so wird das automatisch als
"Hauptbild" verwendet oder man übernimmt zumindest die Zuordnung aus der
alten DB Version.
Gerald *. schrieb:> Jetzt habe ich noch die ganzen Bilder von img nach data/media kopiert =>> um jetzt wieder Vorschaubilder (thumbnails) zu erhalten müsste ich jetzt> jeden Artikel öffnen und das Häkchen "Als Hauptbild verwenden" setzen.
Stimmt, das habe ich übersehen. Ich baue gleich ein Datenbankupdate ein,
das dieses Problem im Nachhinein noch korrigiert, du musst nicht überall
das Hauptbild manuell setzen.
Danke fürs Feedback!
Urban B. schrieb:> Ich baue gleich ein Datenbankupdate ein
Ist drin --> Revision 641
Ausserdem habe ich unser DokuWiki noch um einen Read-Only Modus
erweitert, welcher standardmässig aktiviert ist, also die Bearbeitung
von Seiten verhindert. Schreibrechte erhält man, wenn man im
DokuWiki-Verzeichnis eine Datei mit dem Namen
"PART-DB_ENABLE-DOKUWIKI-WRITE-PERMS.txt" anlegt. Dies kann aber auch
bequem in der Part-DB Konfigurationsseite durchgeführt werden, aber nur,
wenn in Part-DB der Ordner "development" existiert (für Nicht-Entwickler
soll diese Option nicht sichtbar sein, so wie die Entwickler-Werkzeuge).
Der Grund für den Read-Only Modus ist einfach: In der Online Demo kann
sonst jedermann irgend einen Schrott da reinschreiben ;-) Insbesondere
bei den Bash-Befehlen stellt dies auch ein Sicherheitsrisiko dar.
In der Online-Demo ist natürlich das Deaktivieren des Read-Only Modus
über die Konfigurationsseite nicht möglich.
Urban B. schrieb:> Urban B. schrieb:>> Ich baue gleich ein Datenbankupdate ein>> Ist drin --> Revision 641
Vielen Dank für die rasche Reaktion!
Wie hast du es den umgesetzt? (kann es erst Sonntag testen)
Gerald *. schrieb:> Vielen Dank für die rasche Reaktion!
Kein Problem, betrifft ja nicht nur dich, sondern auch alle anderen
Benutzer die in Part-DB 0.2.2 Bilder hochgeladen haben.
Und um genau solche Fehler zu finden gibt es ja die Release Kandidaten
:-)
> Wie hast du es den umgesetzt? (kann es erst Sonntag testen)https://code.google.com/p/part-db/source/browse/trunk/updates/db_update_steps.php
Im "case 14" ist jetzt ein Datenbankupdate, das allen Bauteilen, die
noch kein Hauptbild definiert haben, jedoch mindestens ein Bild
besitzen, eines dieser Bilder als Hauptbild definiert.
Um es zu testen müsstest du also einfach die Datei db_update_steps.php
mit der neuen Version überschreiben.
Noch ein kleiner Vorschlag meinerseits:
Um die Übersichtlichkeit zu erhöhen könnte/sollte man "obsolete
Bauteile" bei denen der Lagerstand auf null gesunken ist aus der
Bauteileübersicht ausblenden und nur mehr unter
Verwaltung / Tools > Zeige > Nicht mehr erhältliche Teile
auflisten. Dadurch wären evtl. verknüpfte Datenblätter im Falle des
Falles weiter verfügbar, nur man stolpert nicht ständig über "Leichen".
Gibt es eigentlich einen besonderen Grund warum die Standardfootprints
nicht bereits in der DB eingetragen sind?
Die Struktur könnte man ja von den Footprint Bildern übernehmen.
Würde aus meiner Sicht den Einrichtungsaufwand deutlich minimieren und
die Struktur sollte auch für 95% der Benutzer zutreffend sein (für den
Rest ist verschieben einfacher als neu anlegen).
Gerald *. schrieb:> Um die Übersichtlichkeit zu erhöhen könnte/sollte man "obsolete> Bauteile" bei denen der Lagerstand auf null gesunken ist aus der> Bauteileübersicht ausblenden und nur mehr unter> Verwaltung / Tools > Zeige > Nicht mehr erhältliche Teile> auflisten.
Keine schlechte Idee, ich nehme das mal in unsere ToDo Liste auf (wäre
zwar keine sehr grosse Sache, zwischen der Veröffentlichung der
Release-Kandidaten und dem finalen Release ist aber kein guter Zeitpunkt
um solche neuen Funktionen einzubauen).
Gerald *. schrieb:> Gibt es eigentlich einen besonderen Grund warum die Standardfootprints> nicht bereits in der DB eingetragen sind?
Diese Frage kam hier schon mehrfach :-)
Also standardmässig eingetragen würde ich nicht so gut finden, weil es
sicher viele Leute gibt die entweder gar keine, oder nur wenige
Footprints eintragen (wegen der Übersichtlichkeit). Allerdings fände ich
es auch gut, wenn es eine Option gäbe, mit der man automatisch die
wichtigsten Footprints mit einem Klick hinzufügen könnte. Ich schreib
das auch gleich in die ToDo-Liste.
Dirk B. schrieb:> bei mir wird der Preis mit DM angegeben. Wie kann ich das auf Euro> umstellen ?
In der 0.2.2 Version findest du es in der config.php unter:
$currency = "€";
In der 0.3.0.RC1 Version unter data/config.php müsste es folgender
Punkt sein:
$manual_config['money_format']['de_DE'] = '%!n Euro';
@kami89
Wenn ich über die config.php zusätzliche Spalten einblenden lasse und
danach unter Verwaltung / Tools > System > Konfiguration die Sprache
ändere, fehlen in der config.php meine Einträge für die zusätzlichen
Spalten.
Gerald *. schrieb:> @kami89> Wenn ich über die config.php zusätzliche Spalten einblenden lasse und> danach unter Verwaltung / Tools > System > Konfiguration die Sprache> ändere, fehlen in der config.php meine Einträge für die zusätzlichen> Spalten.
Hast du in der config.php die entsprechenden Einträge mit
$manual_config[] statt $config[] gemacht? Mit $manual_config[] sollte es
dauerhaft gespeichert werden.
Kurze Erklärung
$config[] muss für alle Einstellungen verwendet werden, die in der
config_defaults.php vor dem Kommentar-Block
1
Below, there are attributes which we don't want to save in the user's "config.php".
2
[...]
stehen. Dies sind diejenigen Einstellungen, die bei Updates nicht
überschrieben werden, die bleiben für immer so erhalten wie sie mal
definiert wurden. Alle Einstellungen nach dem Kommentarblock werden
nicht in der config.php gespeichert. z.B. die verfügbaren Sprachen
oder Währungen haben in der config.php grundsätzlich nichts zu suchen.
Diese können bei Updates auch überschrieben werden, z.B. wenn wir eine
neue Sprache oder eine neue Spalte in den Tabellen hinzufügen sollen die
ja dem Benutzer dann auch zur Verfügung stehen, und nicht durch die
config.php wieder mit den alten Werten überschrieben werden. Möchte man
aber trotzdem aus irgend einem Grund an diesen Variablen was verändern,
können sie in der config.php als $manual_config[] überschrieben werden.
Hallo Zusammen,
Erstmal Respekt vor Eurer Arbeit ...
Ich wollte gestern die V 0.3.0.RC1 installieren , aber der Installer
kommt immer nur bis zu der Einstellung " Zeitzone und Sprache" und egal
was ich versuche es endet mit einer Meldung , wie:
Die gewählte Sprache "de_CH" wird vom Server nicht unterstützt!
Bitte installieren Sie diese Sprache oder wählen Sie eine andere.
Was mache ich falsch ?
Wie und wo könnte ich diese Sprachen installieren ?
Installieren wollte ich die Applikation ich auf einem "Schweizer"
WebHost --> andere Webapplikationen machten bisher keine Probleme
Peter Müller schrieb:> Was mache ich falsch ?
Hast du evtl. schon mal versucht "de_CH (UTF-8)" auszuwählen?
Nicht UTF-8 Versionen bringen bei mir auch die genannte Fehlermeldung.
@kami89
Danke für die ausführliche Antwort!
Ich hatte sogar deine Erklärung vom 23.5 gelesen, nur irgendwie...
Egal, mit welcher Auswahl ich es versuche, ich bekomme immer dieselbe
Fehlermeldung ...
Auf dem Server sind folgende Versione aktuell:
PHP-Version: 5.3.10
MySQL-Version: 5.5.29
Perl-Version 5.12.4
Ich habe mich mal an einer Installation versucht. Revision 642 geladen,
Aufruf der Seite:
1
Die Datei "config.php" konnte nicht beschrieben werden. Überprüfen Sie, ob genügend Rechte vorhanden sind.
Kopiere ich die config_defaults.php nach config.php kommt die nächste
Fehlermeldung, wobei diese Meldung noch nicht mal im Part-DB-Design
kommt, sondern nur als Plaintext.
1
Bitte verschieben Sie die folgenden Dateien und Ordner ins Verzeichnis "data":
Warum ist dann die config_defaults.php dann nicht schon im
data-Verzeichnis? Verschiebe ich die zuvor kopierte config.php nach
data, so gibts die nächste Fehlermeldung:
1
Es gab ein Fehler bei der Aktualisierung ihrer config.php:
2
Fehler beim Updaten der config.php: Unbekannte Version!
Einerseits muss die config_defaults.php direkt im Zielverzeichnis liegen
und falls die config.php weder im Hauptverzeichnis noch in data
vorliegt, die config_defaults.php nach config.php kopiert werden. Dazu
sollte die config_defaults.php auch die richtige Versionsnummer tragen.
Für den Anwender wäre eine manuelle Bearbeitung der Konfiguration für
eine Erstinstallation wenig bis gar nicht zumutbar. Wäre doch nett, wenn
wir das nicht benutzerfreundlicher hinbekämen :-)
Peter Müller schrieb:> Egal, mit welcher Auswahl ich es versuche, ich bekomme immer dieselbe> Fehlermeldung ...
Bei welchem Webhoster bist du?
Füge bitte mal am Anfang der start_session.php die folgenden Zeilen ein:
Und stelle hier die Ausgabe rein, vielleicht sieht man da was
auffälliges.
@Udo
1
Die Datei "config.php" konnte nicht beschrieben werden. Überprüfen Sie, ob genügend Rechte vorhanden sind.
Das heisst, dass Apache keine Schreibrechte im Verzeichnis "data" hat,
wo er die config.php anlegen möchte. In der Doku ist beschrieben wie die
Rechte gesetzt werden sollen:
http://kami89.myparts.info/dokuwiki/doku.php?id=installationUdo Neist schrieb:> Kopiere ich die config_defaults.php nach config.php kommt die nächste> Fehlermeldung, wobei diese Meldung noch nicht mal im Part-DB-Design> kommt, sondern nur als Plaintext.> Bitte verschieben Sie die folgenden Dateien und Ordner ins Verzeichnis "data":
Man darf die config_defaults.php NICHT nach config.php kopieren, das
gibt ein Durcheinander. Die config_defaults.php ist nicht mehr wie bei
Part-DB 0.2.2 die config.php.template nur eine Vorlage für die
config.php, sondern die hat jetzt auch eine "richtige" Aufgabe im
System. Dort sind nämlich alle verfügbaren Sprachen, die installierte
Part-DB Version uvm. gespeichert, das hat in der config.php alles nichts
zu suchen.
Dass die Fehlermeldung nicht im Part-DB Design daherkommt ist natürlich
schade, liegt aber daran dass bereits ganz am Anfang der
start_session.php geprüft werden muss, ob sich die genannten Dateien und
Ordner am "falschen" Ort befinden, also noch dort wo sie in Part-DB
0.2.2 abgelegt wurden. Solange diese Dateien (vor allem die config.php)
nicht am richtigen Ort liegen, sollte das Skript nicht weiter ausgeführt
werden damit es nicht zu anderen Problemen kommt. Und weil es zu diesem
Zeitpunkt noch keine Klasse "HTML" und damit Templates gibt, kann nicht
das Design von Part-DB benutzt werden.
Ich kann aber mal versuchen ohne Templates der Fehlermeldung ein Design
zu verpassen, an dem man eindeutig erkennt dass es sich um eine
Fehlermeldung von Part-DB handelt.
Udo Neist schrieb:> Warum ist dann die config_defaults.php dann nicht schon im> data-Verzeichnis?
Weil im data-Verzeichnis nur Dateien sind, die nicht von Part-DB
stammen (bis auf die index.html und .htaccess). Dort sind nur
Benutzerdaten, oder mit anderen Worten, alles was der Benutzer kopieren
müsste um ein Backup anzulegen. Die config_defaults.php hingegen ist
eine Systemdatei von Part-DB, dort dran darf der Benutzer auf keinen
Fall dran rumfummeln. Alles ausserhalb des data-Verzeichnis ist tabu für
den Benutzer, weil es sonst beim nächsten Update gleich wieder
überschrieben werden würde. Das passiert mit den Dateien im
data-Verzeichnis nicht.
Udo Neist schrieb:> Verschiebe ich die zuvor kopierte config.php nach> data, so gibts die nächste Fehlermeldung:> Es gab ein Fehler bei der Aktualisierung ihrer config.php:> Fehler beim Updaten der config.php: Unbekannte Version!
Das war die config.php, die du von der config_defaults.php kopiert hast?
Dann ist klar dass er die nicht updaten kann, weil es keine config.php
von der Part-DB 0.2.2 ist. Der Updater erwartet hier entweder eine
config.php von Part-DB 0.2.2 die er dann aktualisiert, oder aber eine
config.php die mit dem Installer erzeugt wurde und somit eine korrekte
Versionsnummer enthält.
Udo Neist schrieb:> Für den Anwender wäre eine manuelle Bearbeitung der Konfiguration für> eine Erstinstallation wenig bis gar nicht zumutbar. Wäre doch nett, wenn> wir das nicht benutzerfreundlicher hinbekämen :-)
Wozu willst du denn die config.php vor der ersten Benutzung manuell
erstellen wenn es doch einen grafischen Installer gibt, der dann die
config.php korrekt erzeugt? :-)
Es ist eigentlich ganz einfach:
Szenario 1: Neuinstallation, es existiert keine config.php
Part-DB das erste mal aufrufen -> Installer durchlaufen lassen -> fertig
Mächte man zusätzlich noch die Konfuguration manuell verändern kann man
das jetzt tun, weil die config.php jetzt ja existiert.
Szenario 2: Part-DB 0.2.2 auf 0.3.0 updaten
Part-DB 0.3.0 ins Installationsverzeichnis entpacken, alte Dateien
überschreiben. Part-DB aufrufen, Meldung "Dateien nach data verschieben"
befolgen (nichts rumfummeln, nur verschieben). Part-DB nochmals
aufrufen, config.php wird automatisch auf das neue Format aktualisiert,
Installer durchlaufen lassen, fertig.
Und wenn Part-DB motzt dass nicht genügend Rechte zum Schreiben der
config.php vorhanden sind: Korrekte Rechte (nach Doku) vergeben -->
nochmals versuchen --> fertig
:-)
Dann wäre es doch viel sinnvoller, die Fehlermeldung zu korrigieren. Ein
Verweis auf das Wiki wäre hier auch hilfreich. Ein grafischer Installer
sollte mit klaren Meldungen kommen und nicht nur irgendwelche
Fehlermeldungen. In dieser Form würde ich keinesfalls einem Release
zustimmen.
Wenn die Rechte der Verzeichnisse nicht stimmen, sollte das gemeldet
werden. Natürlich könnte eine Routine first_install() ja auch versuchen,
die Rechte zu korrigieren. So verwirrt das ganze. In meinem Filemanager
gibt es eine Klasse class.fileio.php, deren Funktion aboutFile() zeigt,
wie man die Rechte eines Files/Verzeichnisses unter PHP auswertet.
Die config_defaults.php führt in die Irre. Viele PHP-Projekte schleppen
eine solche Datei mit, die dann oft vom Anwender umkopiert werden soll,
damit die Installation klappt. Einfach die Datei gleich schon im
data-Verzeichnis unterbringen und eventuell auch defaults.php nennen
oder eine leere config.php mitliefern? Die config.php aus 0.2.2 würde ja
entsprechend umgeschrieben.
Grüße
Udo
PS: SVN speichert die Datei/Verzeichnisrechte, da sollte man diese von
Anfang an auch richtig einstellen :-)