Hallo leute, Ich muss mich für ein Projekt im Thema "Accoustic echo cancellor" einlesen. Ich habe zwar ein paar informationen gefunden, habe aber dennoch große Lücken wie das funktionieren soll. Ich verwenden den LMS-Algorithmus, und dabei habe ich ein paar fragen dazu. Wie viele Daten werden pro Zyklus neu in den Buffer gespeichert um daraus einen neuen filterkoeffizienten zu errechnen? --> Bild Wird immer nur ein neuer Filterkoeffizient errechnet oder geschieht das durch ganze Blöcke von neuen Koeffizienten? --> Bild Ist es notwendig eine "Speech detection" einzubauen? -> Habe immer verschiedene AEC-arten gesehen, bei manche war er dabei, bei manche nicht. Und hat jemand nützliche Unterlagen zum einlesen? Wäre super wenn ein bisschen mehr Klarheit bei diesem Thema wäre. LG
Angehängte Dateien:
-

speicher.JPG
32 KB
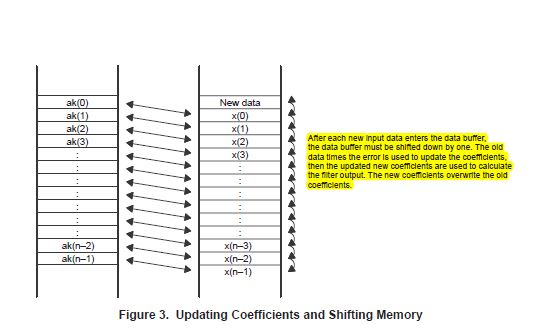
Christof schrieb: > Wie viele Daten werden pro Zyklus neu in den Buffer gespeichert um > daraus einen neuen filterkoeffizienten zu errechnen? Ein Sample wird in den Buffer geschoben. > Wird immer nur ein neuer Filterkoeffizient errechnet oder geschieht das > durch ganze Blöcke von neuen Koeffizienten? Es werden in jedem Schritt alle Filterkoeffizienten adaptiert. Was das ganze bei langen Filtern sehr rechenaufwendig macht, deshalb nimmt man einen reinen LMS nur wenn man sehr kurze Echopfade adaptieren muss. Schneller geht's mit einer Implementierung im Frequenzbereich. > Ist es notwendig eine "Speech detection" einzubauen? Eine double talk detection brauchst du immer wenn es in der Praxis funktionieren soll. > Und hat jemand nützliche Unterlagen zum einlesen? "Acoustic Echo Control – An Application of Very High Order Adaptive Filters" (http://kang.nt.e-technik.tu-darmstadt.de/nt/fileadmin/spg/lectures/af/ieee_sig_pro_mag_1999.pdf). Ausführlicher und in Buchform: Hänsler, Schmidt, "Acoustic Echo and Noise Control: A Practical Approach", ISBN 0471453463
:
Bearbeitet durch Admin
Vielleicht kann ich Dir mit diesen links auf Arbeiten der ETH aushelfen: http://e-collection.library.ethz.ch/eserv/eth:40673/eth-40673-01.pdf
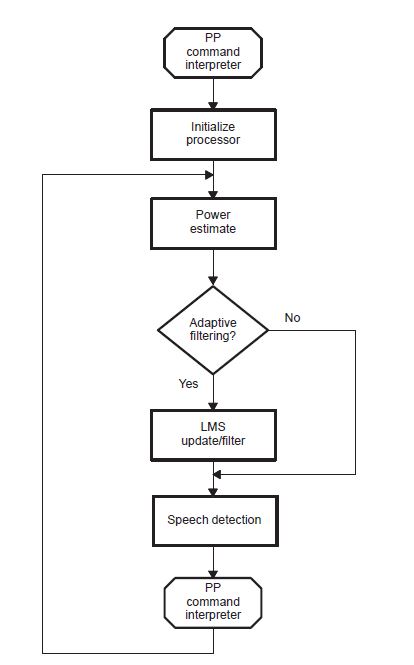
Eine Frage ist hätte ich noch, dass wo die Speech detection gemacht werden soll? Im "Bild" ist nämlich die Speech detection erst am Schluss. Ich habe mir ganze Zeit gedacht, dass die Speech detection vor dem berechnen des Ausgangs gemacht werden soll, da auch von der Speech detection bestimmt wird ob dies überhaupt berechnet wird. Oder wird es erst am Schluss gemacht und für den nächsten Zyklus bestimmt? LG
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.