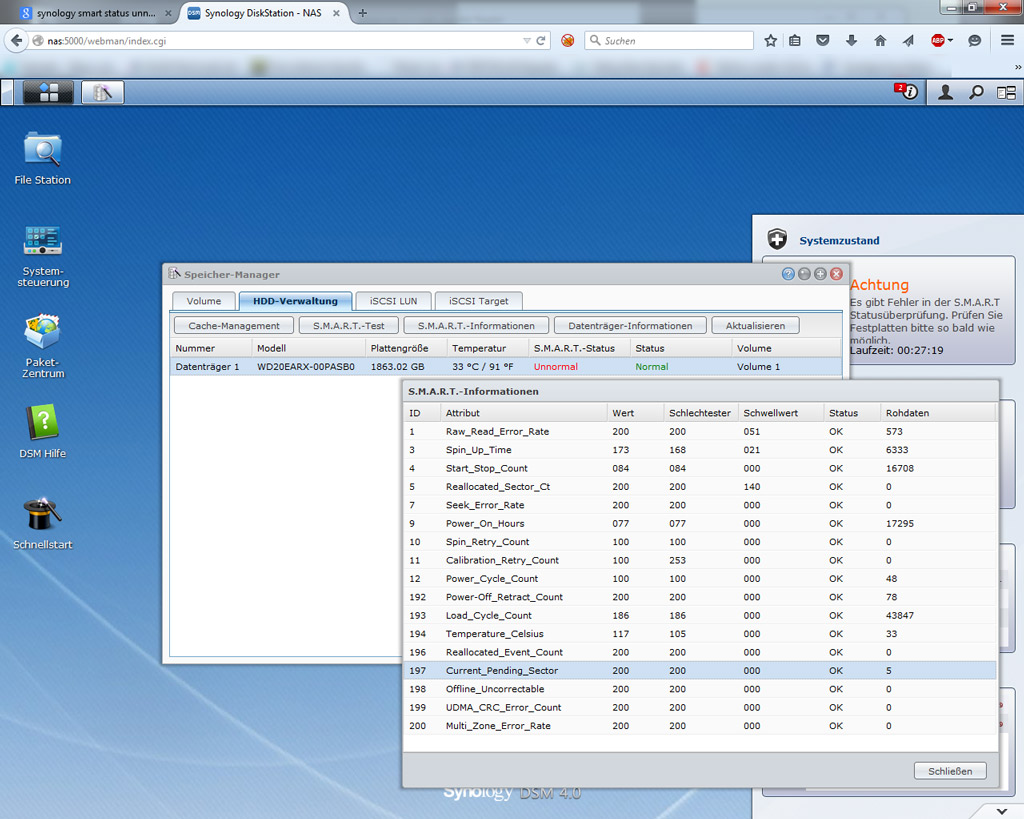
ES handel sich um eine WD20EARX ... Danke
Ihre geplante Lebensdauer hat sie ja schon etwas überschritten. Nun wurdest Du nett darauf hingewiesen, Dich um Ersatz zu kümmern. Sollte der Wert noch steigen, müsste das Ersatzsuchtempo gesteigert werden. (Ein vorheriges Backup entspannt ungemein.)
Nichts stimmt hier nicht. Du hast alles auf 0 bis auf eine sehr kleine Pending Sector. Sogar Reallocated ist noch 0! Alles gut. Aber wenns dich beruhigt und du noch keines hast, dann mach ein Backup. Lohnt sich sowieso, egal was SMART sagt. Was das Tool da für Panik schiebt keine Ahnung. Aber eine Empfehlung hab ich noch: du hast eine sehr wenig Power Cycles (-> Server/Kiste die durchläuft) aber sehr hohe Load Cycle Count. In dem Zusammenhang fällt mir ein sehr agressives Stromsparfeature von manchen WD-Platten ein, wo die nach wenigen Sekunden Inaktivität sofort den Kopf geparkt haben. Natürlich gabs dann ne Sekunde später den nächsten Zugriff und das Drive muss wieder hochfahren. Der mechanische Verschleiß davon soll wohl nicht ohne sein. Google mal nach "wd load cycle count", eventuell gibts da Hilfe.
> Alles gut. Unfug, die Platte kann in dem Zustand ein OS von "leicht eingeschränkt" bis zu "unbenutzbar" bringen (ohne RAID...). > Sogar Reallocated ist noch 0! Wäre meine kleinste Sorge in dem Fall, mit Reallocated Sectors !=0 ist kein Datenverlust eingetreten. > Du hast alles auf 0 bis auf eine sehr kleine Pending Sector. Und genau die Pending Sectors sind das Problem. Das sind Sektoren, die nicht auszulesen sind und typischerweise mit einer Fehlermeldung (sector unreadable) im OS aufschlagen, aber vorher gurkt das so 15-30s rum und blockiert alles. Da besteht zwar (zumindest in der Platten-FW) noch die Hoffnung, dass man sie beim nächsten Mal wieder lesen kann (und dann reallozieren) oder durch Überschreiben gleich reallozieren kann, passiert aber eher selten. Damit hat die Platte jetzt 5 lesbare Sektoren weniger, d.h. aktuell existiert ein Datenverlust. Möglicherweise kann man die Sektoren wiederherstellen, wenn man einen langen Selbsttest laufen lässt, da ist die Platte dann aber auch einen Tag beschäftigt. Bei uns gehen Platten mit Pending Sectors wieder zum Händler zurück, meistens fliegen die damit sowieso gleich aus dem RAID...
:
Bearbeitet durch User
Georg A. schrieb: > Bei uns gehen Platten mit Pending Sectors wieder zum Händler zurück, > meistens fliegen die damit sowieso gleich aus dem RAID... Und ich habe mir extra so eine ins Raid gebaut :) War fast geschenkt. Da ich meinem Raid und den Täglichen Backup vertraue macht die mir überhaupt keine sorgen. Mittlerweile läuft die schon seit fast einem Jahr ohne Probleme oder weitere Sektoren.
foo schrieb: > Nichts stimmt hier nicht. Du hast alles auf 0 bis auf eine sehr kleine > Pending Sector. Sogar Reallocated ist noch 0! Alles gut. "This is a critical parameter. Degradation of this parameter may indicate imminent drive failure. Urgent data backup and hardware replacement is recommended." https://kb.acronis.com/content/9133 Im RAID ist das erst einmal kein Problem. Routinemässiges Scrubbing repariert solche Problemsektoren gleich oder irgendwann später zu reallozierten Sektoren und solange deren Anzahl moderat bleibt kann man damit leben. Ohne RAID signalisiert es, das Daten wahrscheinlich unwiederbringlich im Orkus sind. Wenn man Glück hat, dann bleibt es bei den Paar Sektoren und man lebt noch lange damit. Wenn man Pech hat, ist es ein Vorbote von deutlich mehr Unheil.
:
Bearbeitet durch User
16k Starts bei 17k Betriebsstunden? Krank. Eine WD green im NAS, aber Kopfparken nicht abgeschaltet? Krank. Was hier nicht stimmt: Schon die Ursprungskonfiguration. Offline-Test laufen lassen. Achtung, das dauert, Zeitangaben beachten! smartctl -t offline /dev/sdx Sind die pending sectors danach weg und kommen nicht wieder, war es "Schluckauf." Sie können auch zu echten reallocated sectors werden, dann Platte tauschen.
Jupp schrieb: > 16k Starts bei 17k Betriebsstunden? Krank. 1x pro Stunde? Wieso? > Eine WD green im NAS, aber Kopfparken nicht abgeschaltet? Krank. Wenn die alle 20min den Kopf parkt - wo ist da das Problem? Die Platte ist mit 300.000 Zyklen spezifiziert.
:
Bearbeitet durch User
A. K. schrieb: > Jupp schrieb: >> 16k Starts bei 17k Betriebsstunden? Krank. > > 1x pro Stunde? Wieso? Kaum abgekühlt, muss sie schon wieder warm laufen. Kaum warm gelaufen, wieder abkühlen usw. usw. Das kostet extrem Lebensdauer. >> Eine WD green im NAS, aber Kopfparken nicht abgeschaltet? Krank. > > Wenn die alle 20min den Kopf parkt - wo ist da das Problem? Es kostet wiederum extrem Lebensdauer. > Die Platte ist mit 300.000 Zyklen spezifiziert. (ROFL) Ja, ist sie. Wird sie aber (wahrscheinlich) nicht erreichen, die pending sectors sind ein erstes Anzeichen. Wenn man schon Desktopplatten mit "schöngezüchteten" Verbrauchswerten im NAS einsetzt, dann doch bitte so, das sie etwas länger leben. BTDTMT.
Current_Pending_Sectors sind die Sektoren die "for reallocating" anstehen. Solange nicht auf diese Sektoren zugegriffen wird, verbleiben sie in diesem Status. Wenns Dich interresiert, kannst Du diesen Offline-Test machen. Kann Dir aber auch egal sein. Entscheidend ist die zahl der reallocated Sektoren. Wenn diese mehr oder weniger schnell ansteigt, würde ich mich mehr oder weniger schnell nach 'ner neuen Platte umsehen.
siggi schrieb: > Current_Pending_Sectors sind die Sektoren die "for reallocating" > anstehen. Solange nicht auf diese Sektoren zugegriffen wird, verbleiben > sie in diesem Status. Soweit korrekt, aber... > Kann Dir aber auch egal sein. Entscheidend ist die zahl der reallocated > Sektoren. ...hier wird's falsch. Ein pending sector ist ein pending sector, weil der Zugriff auf ihn bereits Fehler verursacht hat. Das, was in diesem Sektor stand, ist wahrscheinlich verloren oder er war beim letzten Versuch nicht mehr beschreibbar. Wann die Platte daraus einen echten reallocated macht bleibt ihr überlassen. Insofern: Nicht egal, im Auge behalten!
siggi schrieb: > Current_Pending_Sectors sind die Sektoren die "for reallocating" > anstehen. Solange nicht auf diese Sektoren zugegriffen wird, verbleiben > sie in diesem Status. Richtig. Diese Blöcke haben mal Lesefehler produziert. Wenn sie das beim nächsten Zugriff wieder tun, werden sie durch Reserveblöcke (spares) ersetzt. Wenn nicht, werden sie wieder freigegeben. Beim Sparing gehen ggf. Daten verloren, dann wenn der Originalblock nicht durch ECC korrigiert werden kann. Ich hatte auch mal die Idee, eine WD Green in einem USB-Gehäuse zu verwenden. Ist sparsam und auf Geschwindigkeit kommt es nicht an. Der Händler meinte jedoch, dass die Green-Serie nur für maximal acht Stunden Dauerbetrieb spezifiziert sei und bei längerem Dauerlauf WD die Garantie verweigert. Er riet zur (gleichteuren) Red, die ist für Dauerfeuer freigegeben.
Der tiefere Sinn hinter pending blocks dürfte in der Hoffnung liegen, dass der nächste Zugriff schreibend erfolgt. Dann erledigt sich das Problem von selber - entweder wird gleich reloziert, oder voller Vertrauen in den Plattengott an die alte Stelle nochmal geschrieben.
Ich möchte Euren Darstellungen zu "pending sectors" widersprechen. Nach meinem Verständnis sind das unlesbare Sektoren. Diese behalten ihren Status so lange, bis sie doch bei einem Leseversuch wieder lesbar erscheinen (unwahrscheinlich) oder der betroffene Sektor vom Betriebssystem überschrieben werden will. In diesem Fall gibt es zwei Möglichkeiten: Der betroffene unlesbare Sektor lässt sich beschreiben und die Anzahl der "pending sectors" wird um eins vermindert. Der betroffene unlesbare Sektor lässt sich nicht beschreiben. In diesem Fall stellt die Festplatte einen Ersatzsektor bereit. Die Anzahl der pending sectors verringert sich widerum um eins. Zusätzlich erhöht sich die Anzahl der "reallocated sectors" um eins.
Peter M. schrieb: > Ich möchte Euren Darstellungen zu "pending sectors" widersprechen. Wem? Alles, was du schreibst, stand schon so da.
Peter M. schrieb: > Ich möchte Euren Darstellungen zu "pending sectors" widersprechen. [schnipp] Genauso ist das. Außerdem ist keiner der SMART Parameter - schon gar nicht für sich allein - ein sicherer Indikator für einen anstehenden Ausfall der Festplatte. Es gibt da von Google ein schönes Paper, wo sie Langzeitbeobachtungen ihrer Server mal statistisch untersuchen. Ihr Fazit war: erhöhte SMART-Fehlerzähler erhöhen zwar die Wahrscheinlich- keit für einen Ausfall der Platte, aber nicht signifikant. Sie hatten sowohl Platten, die vor dem Ausfall gar keine Auffälligkeiten zeigten als auch Platten die trotz pending sectors noch Monate bis Jahre unauffällig weiter gelaufen sind (meist bis sie ohnehin ausgemustert wurden). Wenn irgendwas als Indikator taugt, dann wenn ein Zähler sich kurzfristig - also über Stunden bis Tage - stetig weiter erhöht. Detail am Rande: meine älteste Platte hier hat jetzt 57375 Stunden auf dem Buckel (gut dreimal so lange wie die des TE) und 12 pending sectors. Reallocated sectors ist 0. Die macht täglich einen kurzen und wöchentlich einen langen SMART Test - alle ohne Fehler. Ist übrigens eine Samsung HD401LJ (400G, SATA).
Dazu müsste man jetzt die Ursache des pending sectors ergründen. Aus Software-Sicht wurde nicht zurückgelesen, was reingeschrieben wurde. ECC uncorrectable. Aus HW-Sicht kann das ein Fehler in der Magnetschicht sein. Dann kann hier kein Flußwechsel stehen. D.h. ob der Sektor "schlecht" ist oder nicht hängt vom Bitmuster ab. Schreib andere Daten rein und alles ist gut. Solche Fehler hat jede Platte, der Benutzer merkt üblicherweise nichts davon weil sich die Firmware drum kümmert. Oder eine transiente Störung, weil der Nachbar seinen neuen Verstärker für's CB-Funkgerät getestet hat. Beim nächsten Leseversuch ist alles gut. Oder wir haben eine mechanische Beschädigung der Oberfläche, z.B. durch einen Schlag. Dann ist das abgetragene Material jetzt im Plattengehäuse unterwegs. Wenn es unter den Kopf gerät, bevor es vom HEPA-Filter eingesammelt wird, hast Du den nächsten pending block. Wenn sich die Zähler für pending blocks sich kontinuierlich erhöht, spricht das für einen Oberflächenschaden. D.h. ein Staubkorn ist in der Platte, oder ein Brocken der Magnetschicht, und haut regelmäßig neue Sektoren kaputt. Meine älteste Platte hat acht spared blocks (reallocated sectors heisst das heute). Fünf davon ab Werk. Das ist eine ST-506\9 von 1983. Die Firmware des Z8-Controllers habe ich vor einigen Jahren disassembliert und mit meinem Logikanalyzer kann ich dem Ding bei der Arbeit zusehen :-)
Axel S. schrieb: > Peter M. schrieb: >> Ich möchte Euren Darstellungen zu "pending sectors" widersprechen. > > [schnipp] > > Genauso ist das. Noch einer... Wo seht ihr die Widersprüche? > Es gibt da von Google ein schönes Paper Das kann man vergessen. Ganz andere Bedingungen. > Detail am Rande: meine älteste Platte hier hat jetzt 57375 Stunden auf > dem Buckel (gut dreimal so lange wie die des TE) und 12 pending sectors. > Reallocated sectors ist 0. OK. > Die macht täglich einen kurzen und > wöchentlich einen langen SMART Test - alle ohne Fehler. Das stimmt nicht. Machte sie einen offline-long-test, würden die schwebenden Sektoren verschwinden oder als Reallokierte wieder auftauchen.
Dirk schrieb: > Axel S. schrieb: >> Detail am Rande: meine älteste Platte hier hat jetzt 57375 Stunden auf >> dem Buckel (gut dreimal so lange wie die des TE) und 12 pending sectors. >> Reallocated sectors ist 0. > > OK. >> Die macht täglich einen kurzen und >> wöchentlich einen langen SMART Test - alle ohne Fehler. > > Das stimmt nicht. Machte sie einen offline-long-test, würden die > schwebenden Sektoren verschwinden oder als Reallokierte wieder > auftauchen. Deine Glaskugel in Ehren, aber ich sehe was ich sehe. Die letzte Mail vom smartd ist vom 12. Mai und sagt daß sich die pending sectors um eins erhöht haben (und JFTR die vorhergehende Meldung für diese Platte ist vom Juni 2014). Unabhängig davon macht smartd täglich einen short SMART Test der Platte und wöchentlich einen extended Test, Und die letzten 21 Tests (mehr passen nicht ins SMART Log) sagen alle "Completed without error". Für alle meine Zwecke ist diese Plattte "alive and kicking". Es gibt genau keinen Grund sie auszutauschen. Auch wenn das - dank Backup - durchaus möglich wäre.
Axel S. schrieb: > Es gibt da von Google ein schönes Paper, wo sie > Langzeitbeobachtungen ihrer Server mal statistisch untersuchen. Ihr > Fazit war: erhöhte SMART-Fehlerzähler erhöhen zwar die Wahrscheinlich- > keit für einen Ausfall der Platte, aber nicht signifikant. Ich glaube die Autoren der Studie haben das etwas anders gesehen. Aber mehr will ich aus Höflichkeit über deinen Kommentar hier nicht schreiben.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.