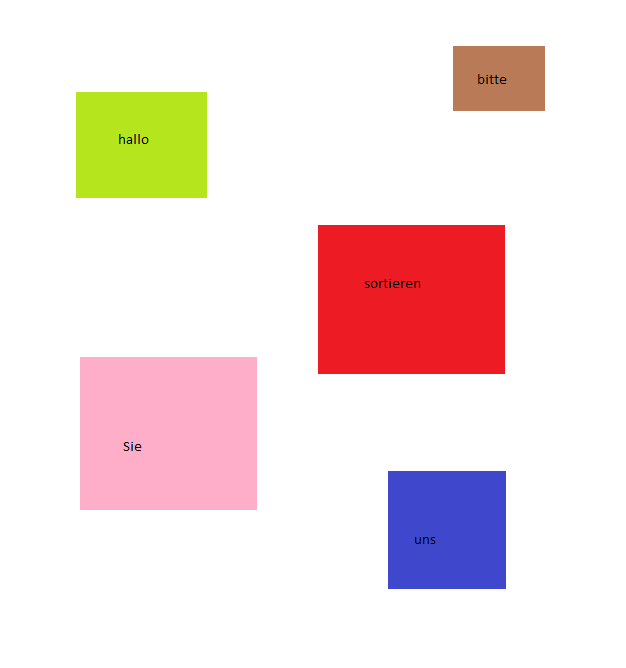

Liebe Leute, ich probiere eine Anwendung machen, die gefärbte Gebiete erkennt und filtriert. Die Gebiete enhalten auch Text und mein Problem ist, dass ich noch nicht Text und Gebiete sortieren kann. Ich habe ein Test-Case und die Resultat nach der Verarbeitung eingefügt. Aus dem Input-Bild habe ich die Farbe Röt ausgewahlt. Bildverarbeitungscript filtriert andere Farben weg und die Resultat ist schwartze Gebiete mit Text. Nach dem kann ich diese Gebiete mit der schwarze Farbe auffüllen. Meine Planung ist ein Mask-Bild zu haben, wo ich nur schwarze Gebiete ohne Text habe. Mit dem kann ich gewollte Gebiete aus originalem Bild abschneiden. Da gibt es noch ein bisschen Text auf dem Bild, die aus anderen Gebieten abgefallen haben. Das ist jetzt das Problem. In meinem Beispiel die Texte sind etwas kleine aber man kann die Texte unter und über dem "sortieren" Gebiet sehen. Ich mag wissen, wie ich kann diese Texte weg filtern? Und ja ich weiß, dass in der Resultat-Bild das grüne Gebiet ist nicht filtriert worden. Aber das Problem ist nicht so schwierig zu reparieren.
Angehängte Dateien:
-

test3.png
2,8 KB -

resultat.png
787 Bytes
Versuche doch mal, vor der Analyse eine Tiefpassfilter anzuwenden, sodass die Schriftartefakte reduziert werden. Etwas komplizierter: Einen sinnvollen Threshold festlegen, Binärbild erzeugen, darauf eine Blob-Detektion laufenlassen. Anschließend nur die Blobs auswählen, die im Originalbild die richtige Farbe haben, den Rest ignorieren. Dabei die Größe der Blobs auswerten (Blob zu klein -> Schriftartefakt)
Der Algorithmus arbeitet wie folgt: 1. Gewollte Farbe wird aus einem gefärbten Gebiete ausgewahlt. Man muss zwei Punkte aus Bild auswahlen und denn mit zweiten Punkte ein kleiner Gebiete wird aus dem Bild gemacht. 2. Abgeschnittene Teile wird in den HSV-Farbraum transformiert und nachdem der Mittelwert aus dem H- und S-Teile ist gerechnet. 3. Alle H- und S-Punkte in originalem Bild werden gegen die Mittelwerte verglichen. Wenn die H- oder S-Punkt ist in Toleranz, die Punkt auf 1 gestellt wird. Im anderen Fall die Punkt Wert 0 hat. Ich habe auch das Matlab-Skript angefügt.
Angehängte Dateien:
-

fft.png
290 KB

Vancouver schrieb: > Versuche doch mal, vor der Analyse eine Tiefpassfilter anzuwenden, > sodass die Schriftartefakte reduziert werden. Also ich könnte mit einer Tiefpassfilter Frequenzen der Schriftartefakte filtern bevor ich den Punkoperator im Farbbild benutze. Hier ich habe FFT-Bild von originalem Bild. Wie ich kann Frequenzen der Schriftartefakte aus dem FFT-Bild erkennen? Ich glaube, dass vertikale und horizontale Striche Frequenzen von den Rechtecke sind.
Ich meinte einfach einen ungewichteten Mittelwert auf einem 3x3 oder 5x5 Kernel, wobei alle Koeffizienten gleich sind. Die Größe des Kernels hängt von der Breite der Schrift ab (in Pixeln).
Wenn wie im Bleistift gezeigt, die Schrift schwarz ist und keiner der Würfel im Dunklen steht, sollte die Farbe doch als Suchkriterium dienen können.
Jussi-Pekka T. schrieb: > ich probiere eine Anwendung machen, die gefärbte Gebiete erkennt und > filtriert. Dein Beispielbild ist supereinfach. Weil klare Farben verwendet werden die sich deutlich vom Hintergrund unterscheiden, weil die Bereiche nicht überlappen und durch weiss getrennt sind, die Schrift eine nicht als Rechteck und nicht als Hintergrund vorkommende Farbe ist die einfach ignoriert werden kann, weil sie rechteckig sind und damit eine einfache Form haben. Das Bild auf die Anzahl und Farbe der Farbflächen zu untersuchen ist pillepalleeinfach, ich würde scanlineorientiert mich von oben nach unten arbeiten und die erkannten Flächen in eine Datenstrukut einordnen. Das Programm wäre keine Seite lang. Aber ich befürchte, deine realen Bilder sind nicht so einfach, und daher ist das Beispielbild ungeeignet.
MaWin schrieb: > Dein Beispielbild ist supereinfach. Das Beispielbild ist ja simple, oder man kann das sogar naiv sagen, aber im Moment das ist doch genug für meine Zwecke. Das ist auch ein Resultat, wann ich eine Lösung habe und endlich teste mit einem realen Bild. Wenn das nicht geht, da gibt es kein Problem. Dann muss ich neue Lösung heurausfinden.
Angehängte Dateien:

Vancouver schrieb: > Ich meinte einfach einen ungewichteten Mittelwert auf einem 3x3 oder 5x5 > Kernel, wobei alle Koeffizienten gleich sind. Die Größe des Kernels > hängt von der Breite der Schrift ab (in Pixeln). Mit den Median- und Mittelwert die Resultät hatten etwas Unterschied. Median 9X9 war ok. Das war eine gute Idee vor der Analyse ein Punkoperationfilter anzuwenden. Ich muss jetzt probieren, wenn ich den Maskbild vor der Analyse machen kann.
:
Bearbeitet durch User
Ich schmeiss mal noch einen rein: Connected Component Labeling. (ok, Blob-Detection wurde schon genannt). Damit lassen sich auch textähnliche Objekte schnell identifizieren/eliminieren. Ein Kriterium ist schon mal, dass der Text von einem anderen gleichfarbigen Objekt umschlossen wird. Beispielbild in revers: https://section5.ch/imgs/camdemo.png Solche Brute-Force-Filtereien sind in der Machine Vision nicht sonderlich beliebt, oder man muss gleich wieder mit FPGAs für schnelle Vorverarbeitung um sich schmeissen. Gibt elegantere Lösungen und intelligente CCL-Algos sind ein spannendes Feld, wo es noch einiges zu holen gibt.
{kind=link}
Sind denn die Ausleuchtungen homogen oder wenigstens bekannt? Eigentlich ist DAS ja das Problem, der realen Bildverarbeitung, dass die Farben über die einzelnen Bereiche scheinbar varieren, weil die Belichtung ungleichmässig ist.
Strubi schrieb: > Ich schmeiss mal noch einen rein: Connected Component Labeling. (ok, > Blob-Detection wurde schon genannt). > Damit lassen sich auch textähnliche Objekte schnell > identifizieren/eliminieren. Ein Kriterium ist schon mal, dass der Text > von einem anderen gleichfarbigen Objekt umschlossen wird. > Beispielbild in revers: https://section5.ch/imgs/camdemo.png Das ist doch eine interessante Idee. Ich soll das probieren.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.