Hallo,
Ich habe eine Anwendung in embedded VC++, die während der Laufzeit
dlls mit Loadlibrary läd.
Damit weitere zu ladende dlls ohne die Anwendung neu zu übersetzen
hinzugefügt werden können, habe ich eine Textdatei, aus der ich die
Namen der dlls in ein Feld
'unsigned short DllDatei[20]'
einlese.
Die Dlls werden dann mit
LoadLibrary(..., (unsigned short*)&DllDatei[0])
geladen. Das hat soweit auch funktioniert.
Nun verwende ich den gleichen Code auch in einem Win32 Projekt in VC++
2003.(Man braucht keine Zielhardware mit WinCE mehr).
Es kommt allerdings ein Fehler, dass unsigned short * nicht in LPCSTR
konvertiert werden kann, was in eVC++ noch ging.
LPCSTR ist als 'const CHAR *LPCSTR' definiert.
Wenn ich den Aufruf in:
LoadLibrary(..., (CHAR*)&DllDatei[0])
ändere, kommt zwar keine Fehlermelding mehr, der Linker kann allerdings
auch mit LoadLibraryA nichts mehr anfangen.
Hat schon mal jemand Dlls mit zur Laufzeit erstellten Namen geladen und
kann mir helfen?
Gut wäre es auch wenn jemand die *.lib kennt, in der Loadlibrary
steht, damit ich sie dem Linker hinzufügen kann. Die MSDN konnte mir
zwar für alle möglichen CE versionen die lib sagen, aber nicht für
win32.
Gruß
bla
PS: Wenn ich testweise mit LoadLibrary(..., "name.dll") eine dll lade
geht es und der Linker nacht auch keine Probleme
Hi ich vermute mal irgendein Problem mit der Zeichenkodierung. Irgendwo in den M$ Compileroptionen kann man einstellen wie ein String repräsentiert wird (UTF8, Unicode usw.). Matthias
Sofern Deine Anwendung nicht Unicode verwendet, ist es schlichtweg ein
Fehler, Strings in short-Arrays abzulegen.
Wenn Du also statt
'unsigned short DllDatei[20]'
korrekt
'TCHAR DllDatei[20]'
schreiben würdest, dann könntest Du auch die völlig unnötige
Arrayadressbestimmung beim Aufruf von LoadLibrary weglassen.
Das geht dann nämlich auch so:
LoadLibrary(..., DllDatei)
und ist obendrein auch noch viel lesbarer.
Der vordefinierte Datentyp TCHAR wird abhängig von den Compileroptionen
wahlweise in einen Einzelbyte-Char oder aber in einen Unicode-Char
übersetzt.
habe jetzt alles auf TCHAR umgestellt. Der Linker Error bleibt allerdings. Auch eine direkte Angabe des Namens geht nicht mehr, ohne dass ich an den Projekteinstellungen was geändert habe.
Angehängte Dateien:
-

Unicode.jpg
40 KB
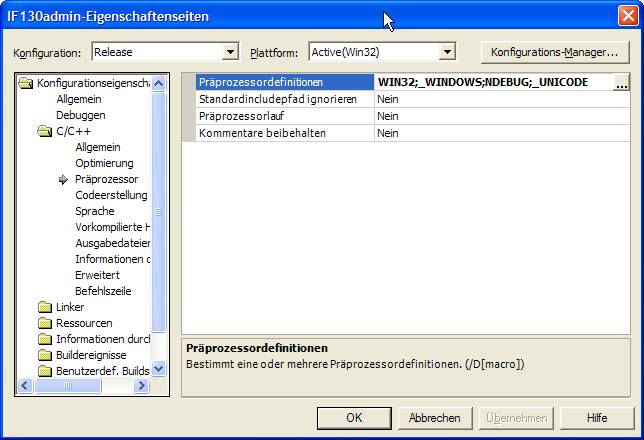
@bla Unter den Embedded-Systemen (z.B. Windows Mobile für PDAs) geht nur Unicode. D.h. bei einem String wird pro Zeichen 2 Bytes verwendet. Damit Du unter Win32 keine Probleme bekommst, solltest Du Dein Projekt auch auf Unicode einstellen (Menü Projekt -> Eigenschaften von <Projekt>... -> Konfigurationseigenschaften / C/C++ / Präprozessor -> Eigenschaft "Präprozessordefinitionen", dort ;_UNICODE anhängen). Ich habe dazu mal einen Screen-Shot angehängt. Ich bin übrigens etwas irritiert von Deinem LoadLibrary-Aufruf ( LoadLibrary(..., DllDatei) ). Laut MSDN wird sowohl bei LoadLibrary als auch bei LoadLibraryEx als erster Parameter der DLL-Name als (Unicode-)String-Pointer angegeben. Es könnte natürlich auch sein, daß ich was übersehen habe... Die Funktion LoadLibraryA ist die 1-Byte-Variante. Die Unicode-Version ist LoadLibraryW. Hinter LoadLibrary verbirgt sich ein #define, der je nach Projekteinstellung entweder zu LoadLibraryW oder LoadLibraryA aufgelöst wird. Wenn Du in den Projekteinstellungen bei Linker/Eingabe die Option "Standardbibliotheken ignorieren" auf "nein" belassen hast, mußt Du keine Windows-Standard-Library explizit dazulinken. Beim Lesen aus einer Datei mit den C-Standard-Funktionen werden die Zeichen i.d.R. in Byte-Strings geschrieben. Um Unicode-Strings zu bekommen, mußt Du eine explizite Konvertierung von Byte nach Unicode einbauen. Hierzu gibt es "Conversion Macros" und im MSDN einen Artikel mit dem Titel "TN059: Using MFC MBCS/Unicode Conversion Macros" (Suche nach "Conversion Macros"). Noch einen kleinen Tipp: hinter den Macros LPSTR, LPCSTR, LPWSTR, LPCWSTR, LPTSTR und LPCTSTR steckt eine gewisse Systematik. "LP" bedeutet long pointer, "STR" steht natürlich für string, in diesem fall 0-terminiert, "C" für const, "W" für wide, also für MBCS/Unicode, und "T" bedeutet entweder Byte- oder Wide-String, je nach Einstellung über #define (im Projekt oder auch im Code). Gruß Markus
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.