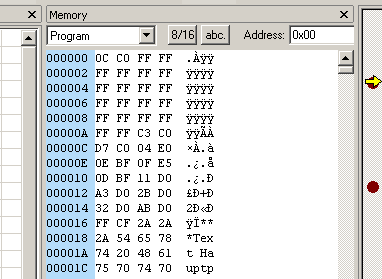
Hallo, ist zwar eine Anfängerfrage aber ich komme trotzdem nicht drauf, beim debuggen ist mir aufgefallen, dass wenn ich mir den Speicher (Programm) anschaue, vier Bytes in einer Zeile sind aber die Adresse nur 2 Byte breit ist. Kann mir das mal jemand kurz erklären? Gruß, Jürgen
Angehängte Dateien:
-

Zwischenablage01.png
2,9 KB
Der Programmspeicher (Flash) ist Word-orientiert. Eine Adresse zeigt auf ein Word. Ein Word hat 16 Bit bzw. 2 Bytes. ...
gut, wie greift das Programm dann aber auf ein einzelnes Byte zu?
kann es sein, dass im ersten Byte der Befehl steht (sofern 1 Byte Befehl) und im 2 Byte steht der Wert? Wie funktioniert das dann aber mit dem Auslesen einer Zeichenkette? Es müssten dann ja immer 2 Zeichen mit einmal ausgelesen werden?
Mit dem Befehl LPM (Load Program Memory) lassen sich auch einzelne Bytes auslesen. Die Adresse ist dann auf die ersten 64K begrenzt.
Hallo, in Assembler gibt es dazu LPM (Load from Program Memory). Dieser lädt aus einer Adresse, auf die Z, Y, X zeigt, ein Byte in ein Register. Dieser Zugriff adressiert Byte-Weise, deshalb muß die Word-Adresse dort mit 2 multipliziert werden. Programmbeispiele suchen gehen, sieht dann z.B. so aus: .CSEG ... ldi ZL, low(2*textmarke) ldi ZH, high(2*textmarke) loop: lpm r16,Z+ tst r16 ; auf 0-Byte testen breq loop_end ... ; was mit dem Byte machen rjmp loop ; und weiter ... textmarke: .db "Das ist ein Text",0 Der Inhalt, der ab .db im Flash liegt wird Wordweise gespeichert. Wenn es eine ungrade Byte-Anzahl in der Zeile ist, hängt der Assembler ein zusätzliches 0-Byte an und gibt eine Warnung (mehr ein Hinweis auf das Padding-Byte) aus. Darauf muß man unbedingt achten, wenn man z.B. Tabellen im Flash baut und den Tabellenzugriff zur Laufzeit im Programm berechnet. Gruß aus Berlin Michael
Hi
>....Die Adresse ist dann auf die ersten 64K begrenzt.
Für grösseren Speicher gibt es auch noch 'ELPM'.
MfG Spess
aha, wenn der Befehl also Byteweise arbeitet, dann ließt er beim ersten Durchlauf das erste Byte und beim zweiten Durchlauf das zweite Byte. Wenn dann der dritte Durchlauf kommt, wird der Z-Pointer um eins erhöht und wieder das erste Byte der nächsten Adresse gelesen. Hab ich das jetzt richtig verstanden? Zur Zeit programmiere ich nämlich noch in Assembler und versuche die Arbeitsweise des MCs zu verstehen, macht sich einfacher beim Debugging wenn man Bescheid weiß wie das Teil arbeitet.. :-)
Jürgen wrote: > aha, wenn der Befehl also Byteweise arbeitet, dann ließt er beim ersten > Durchlauf das erste Byte und beim zweiten Durchlauf das zweite Byte. Nein, nicht wirklich... > Wenn dann der dritte Durchlauf kommt, wird der Z-Pointer um eins erhöht Nein... > und wieder das erste Byte der nächsten Adresse gelesen. Nicht ganz... LPM interpretiert den Z-Pointer anders als andere Befehle. Schau mal in die Befehlsbeschreibung zu LPM (AVR-Studio-Online-Hilfe, also Cursor im Editor auf LPM stellen und F1 drücken). Das Bit 0 des Z-Pointers entscheidet bei LPM, ob das H-Byte oder das L-Byte gelesen wird, Bit 1 bis 15 geben die Word-Adresse der Flash-Zelle an. Das sieht dann unterm Strich so aus, als adressiere der Z-Pointer byteweise. Der Z-Pointer wird deshalb auch nicht mit der Wordadresse der Flash-Zelle (durch das Label an den Daten repräsentiert) geladen, sondern mit dem Doppelten davon (Label * 2). Das ist aber nur bei LPM (und SPM, aber das ist eine andere Lektion) der Fall. Für andere indizierte Flash-Zugriffe über Z-Pointer (IJMP, ICALL) muss der Z-Pointer mit dem korrekten Wert (Label) geladen werden. > > Hab ich das jetzt richtig verstanden? Bisher nicht ganz, jetzt vermutlich schon. > Zur Zeit programmiere ich nämlich noch in Assembler und versuche die > Arbeitsweise des MCs zu verstehen, macht sich einfacher beim Debugging > wenn man Bescheid weiß wie das Teil arbeitet.. :-) Das ist eine gute Einstellung zur Materie. Verstehen kannst Du die Arbeitsweise der ASM-Befehle aber erst, wenn Du die Architektur der AVRs und die daraus resultierenden Adressierungsarten verstanden hast. Dabei hat es uns ATMEL schon leicht gemacht, indem die Mnemonics für verschiedene Adressierungsformen unterschiedlich sind. Es gibt also kein Einheits-MOV für alle Lade- und Kopier-Befehle wie beim 8085/8086. Frohen Rest vom Pfingstfest... ...
Angehängte Dateien:
-

Zwischenablage01.png
8,9 KB
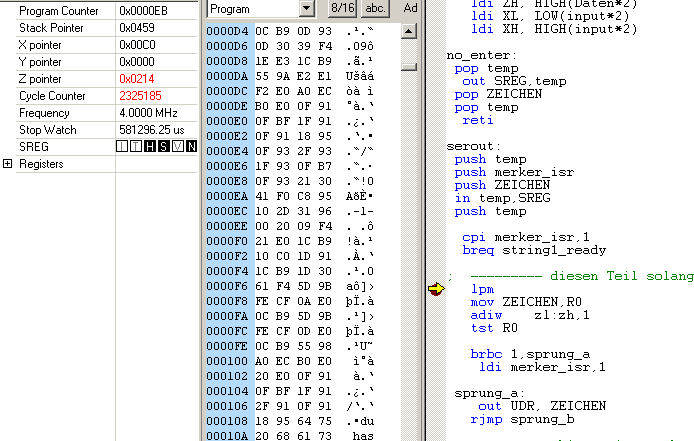
so ganz verstanden hab ich es leider immer noch nicht. Hinter jeder Speicheradresse stecken ja 2 Zeichen, weil eine Speicherzelle 16 Bit breit ist. Nun wird aber der Z-Pointer nach jedem Durchlauf um eins erhöht. Das bedeutet aber, dass mit jedem Durchlauf 2 Zeichen eingelesen werden müssten, was aber auch nicht geht.
Hi
>Hinter jeder Speicheradresse stecken ja 2 Zeichen, weil eine...
Nein. Der Z-Pointer zeigt genau auf ein Byte (Zeichen). Für das nächste
Byte muss er incrementiert werden.
Mach es doch so, wie Michael schon weiter oben beschrieben hat.
Übrigens hat der 'lpm'-Befehl verschiedene Varianten.
MfG Spess
Schau mal auf Seite 7 der Datei im Anhang. Bit 0 im Z-Pointer adressiert das Byte innerhalb der zwei Bytes großen Flash-Zelle, Bit 1 bis 15 adressieren eine von 32K Flash-Zellen. Das wirkt dann so, als würde man den Flash byteweise adressieren. Daher muss man darauf achten, dass man den Z-Pointer für LPM nicht mit der tatsächlichen Adresse (Word-basiert) lädt, sondern mit dem Doppelten davon. ...
Jetzt hab ichs, klar der Wert im Z-Pointer ist ja doppelt so groß. Deswegen wird, wenn man das zurückrechnet, theoretisch nur bei jeden zweiten Durchlauf der Adresspointer erhöht. Danke nochmal, mir ist da jetzt einiges klarer geworden.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.