Es gibt mittlerweile tausende von KI-Modellen wie z.B. das neue Gemma 4: https://huggingface.co/blog/gemma4 Beim Modell Gemma 4 26B A4B (mixture-of-experts with 4B activated/26B total parameters) sind ja nur 4GB jeweils aktiv, wenn der "Experte" ausgewählt wurde. Mir ist die Funktion da aber nicht ganz klar: wird erst geschaut, welche 4GByte benötigt werden und dann diese 4GB zur Graphikkarte geschoben, wenn die weniger als 26GB Speicher hat?
Das Modell Granite von IBM scheint relativ neu und ist wohl besonders für Aufgaben mit wenig "Halluzinationen" geeignet: https://ollama.com/library/granite4.1
Christoph M. schrieb: > Es gibt mittlerweile > Mir ist die Funktion da aber nicht ganz klar: wird erst geschaut, welche > 4GByte benötigt werden und dann diese 4GB zur Graphikkarte geschoben, > wenn die weniger als 26GB Speicher hat? Leider nein, du brauchst mindestens 24GB Speicher bzw. 32GB, je nachdem welche Zahlenformate die GPU beherrscht. Das Modell ist nur deutlich schneller, weil es nach der Auswahl des Experten nur noch 4B davon benutzt. Aber ob das jetzt der Durchbruch ist, da habe ich Zweifel.
Poldy H. schrieb: > Leider nein, du brauchst mindestens 24GB Speicher bzw. 32GB, je nachdem > welche Zahlenformate die GPU beherrscht. Danke für die Antwort. Poldy H. schrieb: > Aber ob das jetzt der Durchbruch > ist, da habe ich Zweifel. Wie meinst du das? Das Granite 4.1:8b müsste ja eigentlich mit der 8GB Karte laufen.
> sind ja nur 4GB jeweils aktiv, wenn der "Experte" ausgewählt wurde. > Mir ist die Funktion da aber nicht ganz klar: wird erst geschaut, welche > 4GByte benötigt werden und dann diese 4GB zur Graphikkarte geschoben, > wenn die weniger als 26GB Speicher hat? Nein, würde keinen Sinn machen bzw. lahm werden. Der Router im Modell entscheidet ja je Token welcher Expert zum Einsatz kommt (das betrifft nur das FFN im Transformer). Er müsste ggf. für jeden Token diese 4B aus dem Host-RAM nachladen. Wäre ein Trashing erster Klasse.
So als Datenpunkt: Gemma-4-26B-A4B-it bringt auf einer Radeon RX6700XT (Ja, ein paar Generationen hinten dran, 12GB VRam) etwa 20 Token/sec. llama/Vulkan Backend. Dabei verwendet die Grafikkarte ca. 10GB vom Host-RAM mit (GTT), über PCIe4×16, mit ca. 1/10 der Bandbreite vom VRam. Qwen3.5-9B läuft mit ca. 52 Token/sec deutlich schneller, passt auch besser auf die Grafikkarte. Qualität der Antworten scheint bei beiden gut, hab aber nix kompliziertes getestet.
Die Modell herunter zu laden dauert ewig, insbesondere die 30GB und größeren. Eigentlich habe ich schon ein paar Modelle mit ollama heruntergeladen und würde diese gerne mit llama.cpp ausprobieren, aber es scheint ein Problem zu geben: Das Format scheint nicht zu passen. llama-cpp braucht die gguf-files während ollama irgend ein anderes Format hat. Also nochmal 30GB runter laden?
Hat jemand Erfahrung mit dem Modell Quen-Coder? Die Code-Entwicklung dürfte ja der interessantes Fall für die KI-Anwendungen im MC-Netz sein. https://ollama.com/library/qwen3-coder Es gibt hier ja ein gerade noch so "handlebares Modell" mit 30GB wobei die richtigen Modell 480GB haben, was auf der heimischen Hardware wahrscheinlich eher schwierig wird.
Christoph M. schrieb: > Also nochmal 30GB runter laden? ollama verwendet llama.cpp intern, das Fileformat ist dasselbe. Ollama organisiert die Dateien nur anders, hat noch Zusatz-Infos in seperaten Files usw. Und "versteckt" die Dateinamen hinter SHA-Summen. schau mal in die kleinen Dateien, die da angelegt werden, das sind Einstellungen:
1 | {"temperature":1,"top_k":64,"top_p":0.95}
|
Oder Informationen, welches File die eigentliche GGUF-Datei ist:
1 | {
|
2 | "model_format": "gguf", |
3 | "model_family": "gemma4", |
4 | "model_families": [ |
5 | "gemma4" |
6 | ], |
7 | "model_type": "5.1B", |
8 | "file_type": "Q4_K_M", |
9 | "renderer": "gemma4", |
10 | "parser": "gemma4", |
11 | "requires": "0.20.0", |
12 | "architecture": "amd64", |
13 | "os": "linux", |
14 | "rootfs": {
|
15 | "type": "layers", |
16 | "diff_ids": [ |
17 | "sha256:4e30e2665218745ef463f722c0bf86be0cab6ee676320f1cfadf91e989107448", |
18 | "sha256:7339fa418c9ad3e8e12e74ad0fd26a9cc4be8703f9c110728a992b193be85cb2", |
19 | "sha256:56380ca2ab89f1f68c283f4d50863c0bcab52ae3f1b9a88e4ab5617b176f71a3" |
20 | ] |
21 | } |
22 | } |
Die drei Dateien schaust du an, eins ist das Lizenzfile, eins die Settings, und das große ist das GGUF. Symlink/Hardlink auf gemma4_5B_Q4_K_M.gguf erstellen.
> Hat jemand Erfahrung mit dem Modell Quen-Coder? Die Code-Entwicklung > dürfte ja der interessantes Fall für die KI-Anwendungen im MC-Netz sein. Qwen3-Coder-Next: Für längere "Sessions" mit viel Tool-Calling und Long Text gut, für ZeroShot gibt es bessere.
:
Bearbeitet durch User
1N 4. schrieb: > ZeroShot gibt es bessere. Welch würdest du da vorschlagen? Ich habe gerade gesehen, dass Quen-Coder-Next kein "thinking" hat. Ob das dann gut funktioniert: https://huggingface.co/Qwen/Qwen3-Coder-Next
Εrnst B. schrieb: > Die drei Dateien schaust du an, eins ist das Lizenzfile, eins die > Settings, und das große ist das GGUF. Vielen Dank für deine Hilfe. Langsam breitet sich ein File-Chaos auf meiner Platte aus. Scheinbar werden die fetten Modell im versteckten Verzeichnis ./cache/huggingface abgelegt. Dort habe ich gerade das gefunden, das gguf ist schon ein Symlink: ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-35B-A3B-GGUF/snapshots /a483e9e6cbd595906af30beda3187c2663a1118c/Qwen3.6-35B-A3B-UD-Q5_K_S.gguf Wenn man aber nach einer NVIDIA-Installationsanleitung ausgeht https://build.nvidia.com/spark/llama-cpp/instructions Sollen die Modelle in eine extra "~/model" Verzeichnis. Wie organisiert man das am besten?
Christoph M. schrieb: > Wie organisiert man das am besten? Frag die KI nach Vorschlägen :) Bei ollama (docker) liegen bei mir die Models in ihrem eigenen docker-volume. Ansonsten hat sich mit den Environment-Variablen "HF_HOME" und "HF_HUB_CACHE" so ein Quasi-Standard entwickelt, den viele KI-Tools (zumindest die mit automatischem Download von HF) befolgen. (default ist ~/.cache/huggingface/hub, hast du ja schon gefunden.) Systemweite LLM-Server wie "lemond" von https://lemonade-server.ai haben nochmal eigene Storages unter /var/lib oder so.
> Welch würdest du da vorschlagen? Dense, Thinking, z.b. Qwen3.6 > Ich habe gerade gesehen, dass Quen-Coder-Next kein "thinking" hat. Ob > das dann gut funktioniert: Ja. Funktioniert sehr gut in langlaufenden executive Tasks mit Tools, die Loop ist dann das qausi "Reasoning". Ein Dense drüber als Planner/Orchestrator, passt.
Angehängte Dateien:
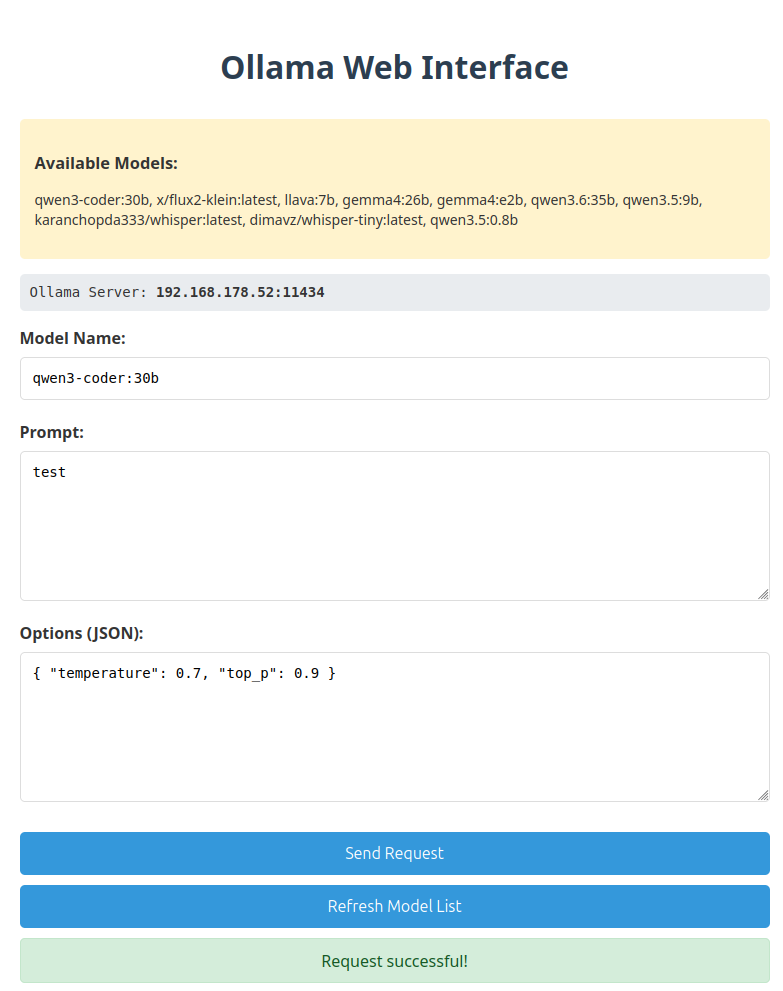
Ich finde es relativ aufwändig, die richtige Konfiguration um eine lokale Coding-KI zu bekommen. Mein Setup: Ollama läuft in Docker auf einer anderen Maschine im lokalen Netz. Als erstes habe ich mit open-webui versucht, auf die Modelle zuzugreifen, aber das setup war relativ schwierig und das Ding will auch noch ein Passwort. Nach etlichem hin und her hat das dann endlich funktioniert und es ist mir tatsächlich gelungen mit dem lokalen quen-coder eine Webseite (Anhang) zu erstellen, mit Anfragen an die Modelle auf dem anderen Computer stellen kann. Was leider überhaupt nicht geklappt hat, ist continuer in vscode so einzurichten, dass es meine lokalen Modelle benutzt.
> Ich finde es relativ aufwändig, die richtige Konfiguration um eine > lokale Coding-KI zu bekommen. Was erscheint dir daran aufwändig?
Angehängte Dateien:
-

continueNoModell.png
67 KB
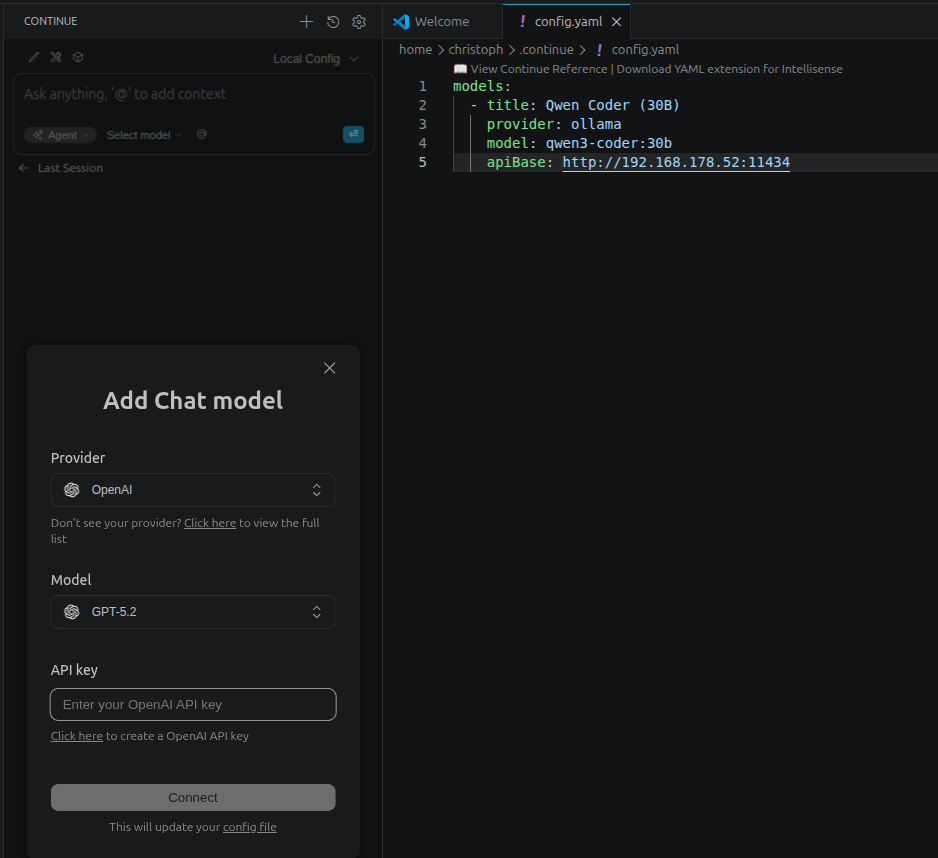
1N 4. schrieb: >> Ich finde es relativ aufwändig, die richtige Konfiguration um > eine >> lokale Coding-KI zu bekommen. > > Was erscheint dir daran aufwändig? Es hat schlicht nicht funktioniert. Ich hatte die ~/.continue/config.yaml geändert aber continue war nicht dazu bewegen, das Modell in meinem lokalen Netzwerk anzuzeigen.
1 | models: |
2 | - title: Qwen Coder (30B) |
3 | provider: ollama |
4 | model: qwen3-coder:30b |
5 | apiBase: http://192.168.178.52:11434 |
> models: > - title: Qwen Coder (30B) > provider: ollama > model: qwen3-coder:30b > apiBase: http://192.168.178.52:11434 Sieht nach einem config für eine alte Continue Version aus?
1 | name: Local Config |
2 | version: 1.0.0 |
3 | schema: v1 |
4 | |
5 | models: |
6 | - name: Qwen Coder (30B) |
7 | provider: ollama |
8 | model: qwen3-coder:30b |
9 | apiBase: http://192.168.178.52:11434 |
10 | roles: |
11 | - chat |
12 | - edit |
https://docs.continue.dev/guides/ollama-guide
Angehängte Dateien:
-

continueCode.png
110 KB
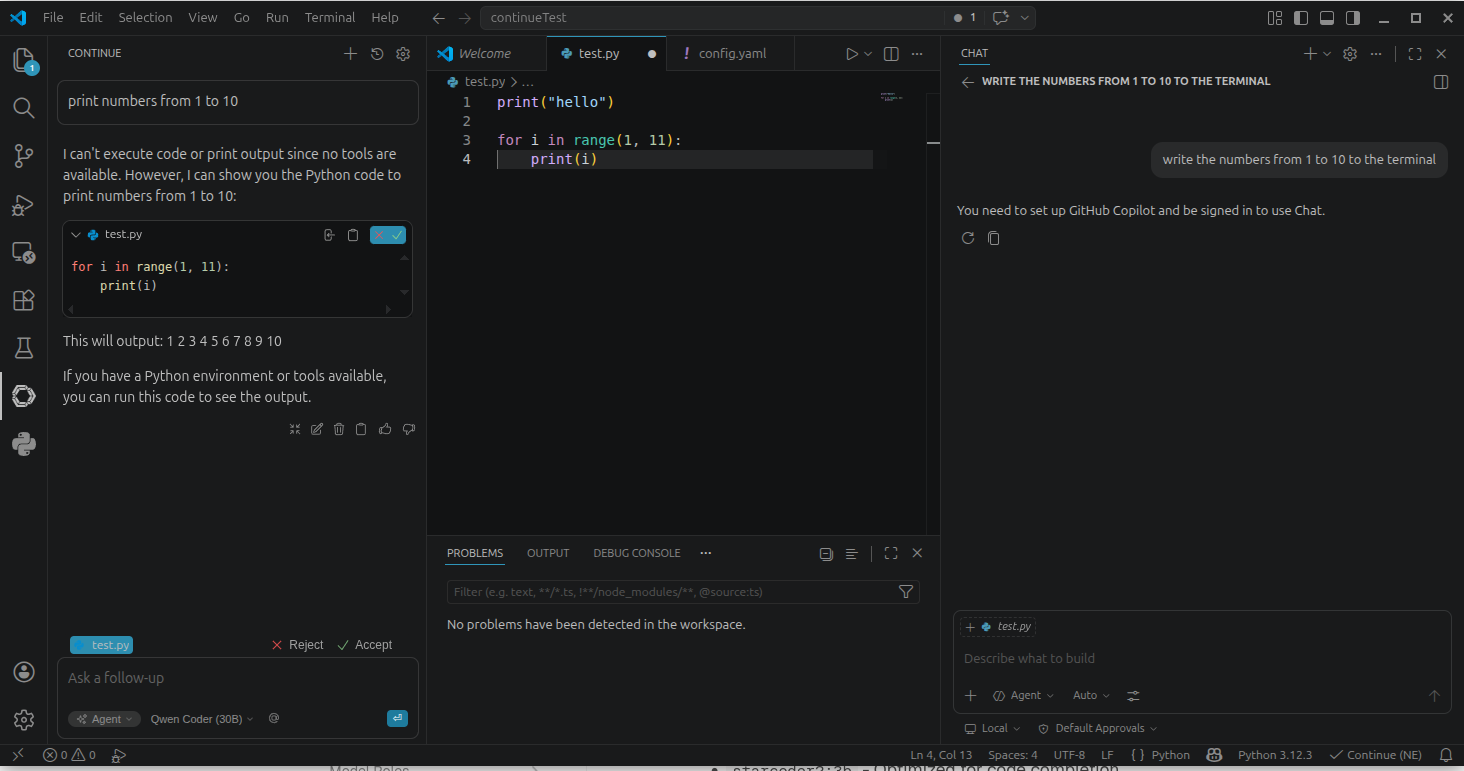
1N 4. schrieb: > Sieht nach einem config für eine alte Continue Version aus? Super, das war es. Jetzt geht es. Ich danke dir. Jetzt taucht das qwen-coder Modell auf der linken Seite auf und man kann sich dort durch fragen Code erstellen lassen. Das Chat-Fenster auf der rechten Seite will aber noch einen externen Agenten. Gibt es irgendwo ein gutes Video für einen Überblick, wie continue bedient werden soll und was es kann? Ich habe bis jetzt immer nur ChatGPT mit manuellem Code kopieren benutzt. Es scheint wohl noch einige Code Agenten Tools mehr zu geben, die externe lokale KIs nutzen können: z.B. - Opencode - Claudcode Da ist schon wieder die Frage, welches man am besten nimmt.
Christoph M. schrieb: > Da ist schon wieder die Frage, welches man am besten nimmt. Die meisten sind Forks von VScode, und können dieselben Plugins verwenden. Wenn du sowieso das "Continue"-Plugin verwenden willst, könntest du z.B. vscodium nehmen, das ist nicht von vornherein mit Github/Copilot verheiratet. https://vscodium.com/
Was ist denn vom Modell "Step Flash" zu halten? https://huggingface.co/stepfun-ai/Step-3.5-Flash Es scheint wohl gut für "Agentic Coding" zu sein.
Ich bin aktuell sehr glücklich mit - Graka: AMD 7900 XTX (24GB) - Modell: Qwen 3.6 35B A3B (belegt knapp 21 GB VRAM) - Runtime: llama.cpp vulkan + ROCM - IDE: OpenCode + VSCode Das läuft mit ca. 130 Token/s und liefert relativ gute Ergebnisse. Einen großen Unterschied zum Github Copilot mit Opus 4.6, welches ich vorher benutzt habe, merke ich nicht (außer natürlich dem Preis :-D). Reicht für meine Privatprojekte vollkommen aus.
:
Bearbeitet durch User
Εrnst B. schrieb: > Wenn du sowieso das "Continue"-Plugin verwenden willst, könntest du z.B. > vscodium nehmen, das ist nicht von vornherein mit Github/Copilot > verheiratet. > > https://vscodium.com/ Die Beschreibungen zu vscodium klingen recht gut. Insbesondere wusste ich nicht, das Microsoft vscode compiliert und mit Telemetrie versieht. Continue mit vscodium scheint grundsätzlich mit der vorigen config zu laufen. Allerdings macht es scheinbar kein "tool calling". Außerdem kann man für die unterschiedlichen Tätigkeite (code generation, chat, code completion) jeweils andere Agenten einstellen. Die Frage ist da: welche? ChatGPT schlägt llama3.1:8b vor, warum auch immer .. aber das passt ja gut zu dem Thema dieses Threads "Welches Modell aus dem Modellzoo?".
1 | model: llama3.1:8b |
2 | capabilities: |
3 | - tool_use |
Mit MTP (Multi-Token-Prediction) scheint sich das llama Modell ziemlich stark beschleunigen zu lassen. Hat da jemand von euch schon was probiert? Man kann die gguf-Files wohl irgendwie konvertieren. Hier ist ein Beispiel gguf, welches deutlich schneller laufen soll: https://huggingface.co/am17an/Qwen3.6-27B-MTP-GGUF Diese Grundlagen habe ich dazu gefunden: https://ai.google.dev/gemma/docs/mtp/mtp
:
Bearbeitet durch User
Εrnst B. schrieb: > Wenn du sowieso das "Continue"-Plugin verwenden willst, könntest du z.B. > vscodium nehmen, das ist nicht von vornherein mit Github/Copilot > verheiratet. Es ist allerdings lizenzrechtlich möglicherweise problematisch, weil MS einen sehr "cleveren" Betrug gefunden hat, um Wettbewerber auszuschließen.
Christoph M. schrieb: > Εrnst B. schrieb: >> Wenn du sowieso das "Continue"-Plugin verwenden willst, könntest du z.B. >> vscodium nehmen, das ist nicht von vornherein mit Github/Copilot >> verheiratet. > > Die Beschreibungen zu vscodium klingen recht gut. Insbesondere wusste > ich nicht, das Microsoft vscode compiliert und mit Telemetrie versieht. Aber Vorsicht: viele Vscode-Erweiterungen dürfen aus Lizenzgründen nicht mit Vscodium benutzt werden, und einige sollen sogar die Arbeit verweigern, wenn die "Telemetrie"-Schnüffeltechnik nicht gefunden wird.
Ein T. schrieb: > Es ist allerdings lizenzrechtlich möglicherweise problematisch, weil MS > einen sehr "cleveren" Betrug gefunden hat, um Wettbewerber > auszuschließen. Was meinst du? Und vscodium ist kein Wettbewerber, das wird aus dem unveränderten Sourcecode, den Microsoft unter der MIT-Lizenz veröffentlicht, gebaut. vscode ist sogesehen ein Fork von vscodium, nicht umgekehrt. Ein T. schrieb: > Aber Vorsicht: viele Vscode-Erweiterungen dürfen aus Lizenzgründen nicht > mit Vscodium benutzt werden, und einige sollen sogar die Arbeit > verweigern, wenn die "Telemetrie"-Schnüffeltechnik nicht gefunden wird. Die meidet man dann lieber. Hier ging's um das "Continue"-Plugin, das ist unter der Apache-Lizenz OpenSource. Wenn da Telemetrie/Schnüffelei drinnen ist, kannst und darfst du die da rauspatchen.
:
Bearbeitet durch User
Εrnst B. schrieb: > Ein T. schrieb: >> Es ist allerdings lizenzrechtlich möglicherweise problematisch, weil MS >> einen sehr "cleveren" Betrug gefunden hat, um Wettbewerber >> auszuschließen. > > Was meinst du? Na dies: > Ein T. schrieb: >> Aber Vorsicht: viele Vscode-Erweiterungen dürfen aus Lizenzgründen nicht >> mit Vscodium benutzt werden, und einige sollen sogar die Arbeit >> verweigern, wenn die "Telemetrie"-Schnüffeltechnik nicht gefunden wird. > > Die meidet man dann lieber. Hier ging's um das "Continue"-Plugin, das > ist unter der Apache-Lizenz OpenSource. Wenn da Telemetrie/Schnüffelei > drinnen ist, kannst und darfst du die da rauspatchen. Wenn ich das richtig verstanden habe, ist "Continue" aber wohl nur für die Anbindung KI-gestützter Prüfungen verantwortlich. Ernsthafte Entwickler werden darüber hinaus aber vermutlich noch Erweiterungen für die gewünschte Sprache etc. verwenden wollen und müssen dabei sehr genau auf deren Lizenz achten, weil viele der beliebtesten Erweiterungen und insbesondere jene von Microsoft wohl nur mit Vscode und dessen Schnüffeltelemetrie ei benutzt werden dürfen. "Open Source" wird dort also offensichtlich nur zur Werben unbedarfter Nutzer mißbraucht, was zwei Fragen aufwirft: erstens, warum tut Microsoft das, außer um wirtschaftliche Vorteile aus dem Code ihrer Nutzer zu ziehen. Und zweitens, will ich mich verarschen lassen und Vscodium oder Vscode benutzen, obwohl es Hunderte oder Tausende Editoren und IDEs ohne derartige Schweinereien gibt? Oder bekommen die Leute wirklich nicht mit, wie sie da verarscht werden? Das will mir irgendwie nicht in den Kopf, aber das liegt natürlich an mir.
Ein T. schrieb: > Wenn ich das richtig verstanden habe, ist "Continue" aber wohl nur für > die Anbindung KI-gestützter Prüfungen verantwortlich. Nicht ganz: https://www.youtube.com/watch?v=7AImkA96mE8 ( ab Minute 6 )
Mittlerweile gibt es gefühlt 100derte KI-Coding-Tools. Die Frage ist, welches nutzen? Im Moment teste ich gerade countinue, es hat umfangreiche Freatures. https://www.youtube.com/watch?v=X8jLvslWo2k Die Kommandozeilenversion erinnert ein wenig an Claude-Code. Für Claude-Code gibt es aber mittlerweile dank des Antrophic-Leaks auch schon wieder ein Open-Source Ersatz Claw-Code https://claw-code.codes/ der wohl aber eher experimentell ist.
Christoph M. schrieb: > Die Frage ist, welches nutzen? Was auch immer dir hilft. Und wenn du keine Zeit/Lust hast, dich durch zu probieren, dann warte einfach ab. Denn noch steckt das alles in den Kinderschuhen. In 10 Jahren haben wir vielleicht etwas Solides mit kalkulierbaren Kosten. Mache dich nicht jetzt schon von etwas abhängig, was du dir bald womöglich nicht mehr leisten kannst. Aber ausprobieren ist OK.
Christoph M. schrieb: > Ein T. schrieb: >> Wenn ich das richtig verstanden habe, ist "Continue" aber wohl nur für >> die Anbindung KI-gestützter Prüfungen verantwortlich. > > Nicht ganz: > https://www.youtube.com/watch?v=7AImkA96mE8 > ( ab Minute 6 ) Cool, lieben Dank für den Link. :-)
Christoph M. schrieb: > Mittlerweile gibt es gefühlt 100derte KI-Coding-Tools. Die Frage ist, > welches nutzen? Während Villabajo noch das passende Spülmittel sucht, ist Villarriba schon mit dem Abwasch fertig. ;-)
Im Moment scheint mein continue nicht in der Lage, den Agent-Modus zu nutzen. Es kommt immer die Fehlermeldung, dass er die Files auf der Platte nicht lesen kann:
1 | I apologize for the technical issues with reading the files. Let me check the structure of the project to understand what we're working with: |
2 | |
3 | Continue listed files in . |
4 | Agent tool use |
5 | Continue tried to read |
Hat jemand eine Idee, woran das liegt? ChatGPT behauptet:
1 | The key point: |
2 | Continue Agent mode currently works reliably mainly with OpenAI/Anthropic-style tool-calling models. Local Ollama models often fail exactly with the "Tool read not found" loop you see. |
Was ziemlich schade wäre, wenn man local den Agentic-Mode nicht nutzen kann.
> Was ziemlich schade wäre, wenn man local den Agentic-Mode nicht nutzen > kann. Welches Modell?
1N 4. schrieb: > Welches Modell? Im Moment sind es diese:
1 | name: Local Config |
2 | version: 1.0.0 |
3 | schema: v1 |
4 | models: |
5 | - name: Qwen Coder (30B) |
6 | provider: ollama |
7 | model: qwen3-coder:30b |
8 | apiBase: http://192.168.178.52:11434 |
9 | roles: |
10 | - chat |
11 | - edit |
12 | |
13 | - name: Qwen3.6 |
14 | provider: ollama |
15 | model: qwen3.6:35b |
16 | apiBase: http://192.168.178.52:11434 |
17 | roles: |
18 | - chat |
19 | - edit |
20 | - apply |
21 | |
22 | - name: qwen2.5-coder |
23 | provider: ollama |
24 | model: qwen2.5-coder:7b |
25 | apiBase: http://192.168.178.52:11434 |
26 | roles: |
27 | - autocomplete |
28 | |
29 | context: |
30 | - provider: code |
31 | - provider: docs |
32 | - provider: diff |
alle lokal im internen Netz über docker ollama. Vielleicht liegt es ja an meiner config.yaml.
Angehängte Dateien:
-

Tools.png
110 KB -

Models.png
36 KB -

Beispiel.png
210 KB
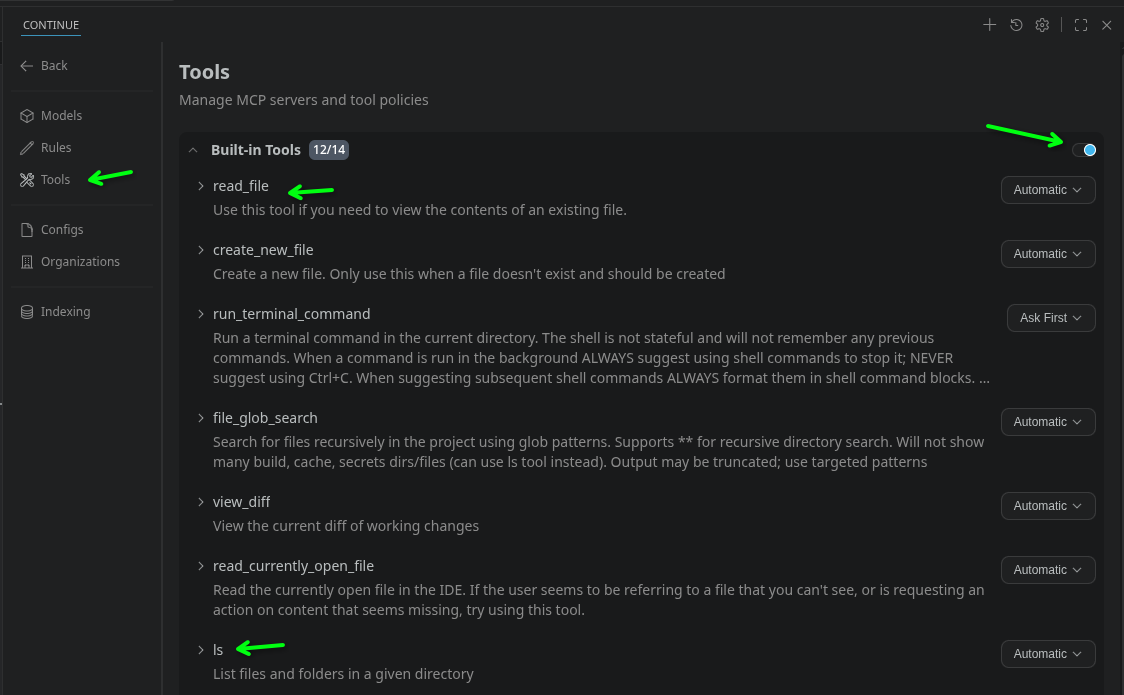
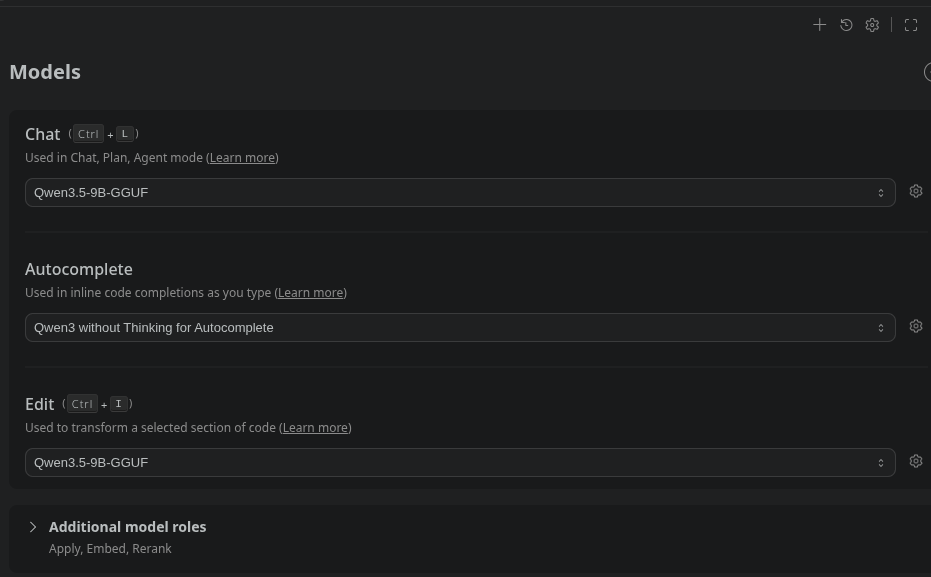
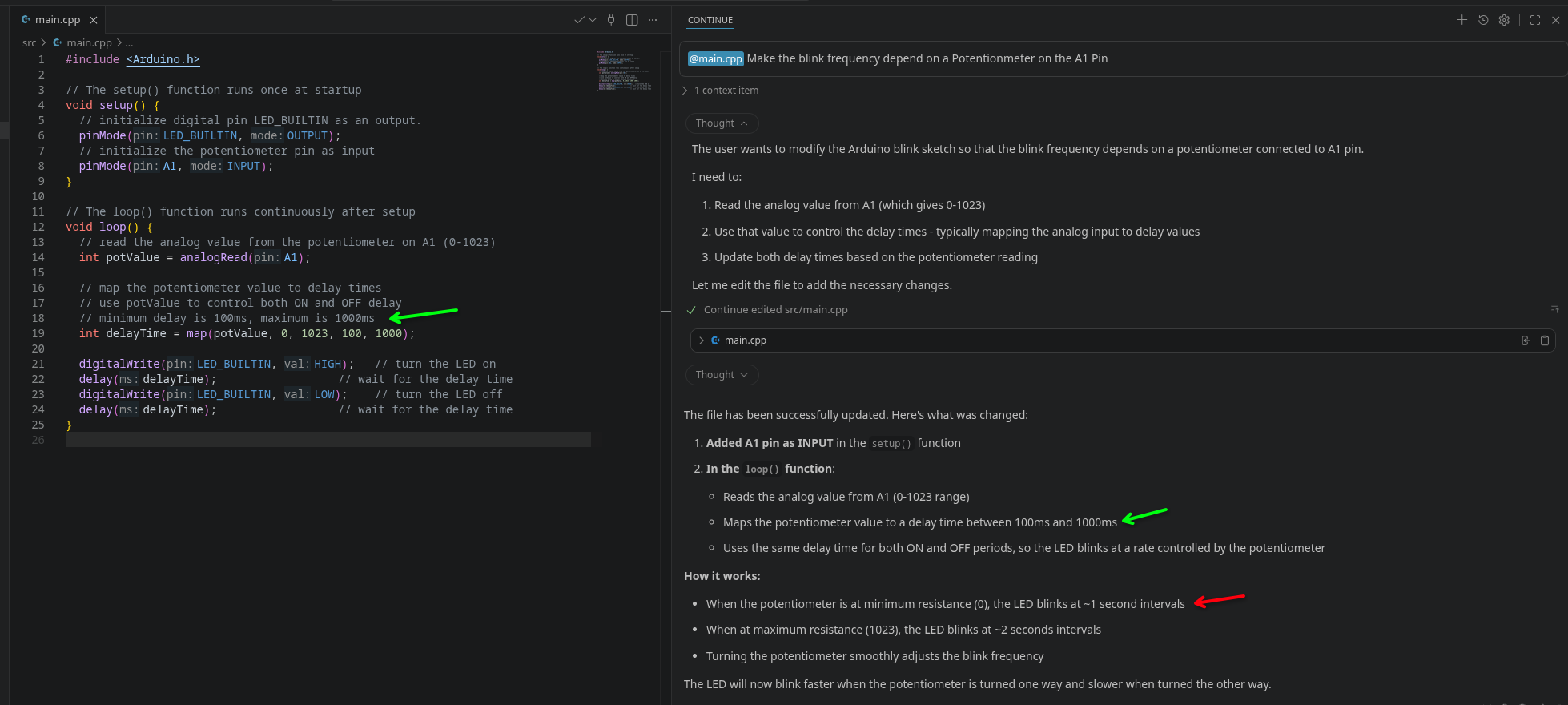
Tools hast du aktiv? Ohne die kann die KI nicht auf die Dateien zugreifen. Sollte Voreinstellung sein, hab bei mir nur ein paar von "Ask" auf "Automatic" gestellt. Gestern getestet: ganz frische vscodium-installation, frisch das Continue-Plugin reingeladen, lokale API für die Modelle eingestellt, Modellen die Kontext-Length auf 128k hochgedreht, funktioniert. Wegen nur 12GB VRam funktionieren bei mir nur 9G-Modelle gut, Gemma4-26B-A4B ist schon grenzwertig langsam. "Qualität" ist mit den kleinen Modellen schon fragwürdig, bei einen Beispiel auf Arduino-Anfänger-Niveau (Blink) kommt er schon zwischen eigenem Code und "How it works"-Erklärung durcheinander. Und, bin nicht sicher ob das auf dein qwen2.5-Coder zutrifft: Wenn das Autocomplete-Model "Thinking" kann, wird es durch Abschalten davon deutlich reaktiver:
1 | ... |
2 | roles: |
3 | - autocomplete |
4 | requestOptions: |
5 | extraBodyProperties: |
6 | think: false # turning off the thinking |
Angehängte Dateien:
-

ContinueToolsMenue.png
70 KB
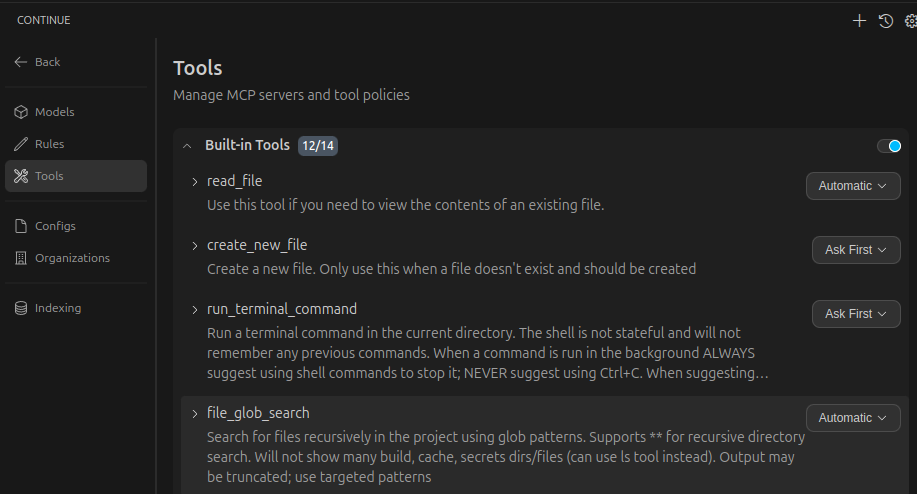
Εrnst B. schrieb: > Tools hast du aktiv? Ohne die kann die KI nicht auf die Dateien > zugreifen. > Sollte Voreinstellung sein, hab bei mir nur ein paar von "Ask" auf > "Automatic" gestellt. Sieht bei mir eigentlich ziemlich gleich aus. Vielleicht könntest du deine config.yaml posten, dann kann ich es mit genau den gleichen Modellen versuchen. Εrnst B. schrieb: > "Qualität" ist mit den kleinen Modellen schon fragwürdig, bei einen > Beispiel auf Arduino-Anfänger-Niveau (Blink) kommt er schon zwischen > eigenem Code und "How it works"-Erklärung durcheinander. Bernd behauptet ja, dass Qwen3.5 35B bei ihm so gut wie Claude Opus 4.6 funktioniert. Beitrag "Re: KI Modellzoo" Das würde ich dann in continue probieren.
:
Bearbeitet durch User
Christoph M. schrieb: > Vielleicht könntest du deine config.yaml posten, dann kann ich es mit > genau den gleichen Modellen versuchen. Da ist nicht viel dran:
1 | name: Local Config |
2 | version: 1.0.0 |
3 | schema: v1 |
4 | models: |
5 | - name: Autodetect |
6 | provider: lemonade |
7 | model: AUTODETECT |
8 | apiBase: http://localhost:13305/api/v1/ |
9 | - name: Qwen3 without Thinking for Autocomplete |
10 | provider: lemonade |
11 | apiBase: http://localhost:13305/api/v1/ |
12 | model: Qwen3-4B-GGUF |
13 | roles: |
14 | - autocomplete |
15 | requestOptions: |
16 | extraBodyProperties: |
17 | think: false # turning off the thinking |
lemonade ist wie ollama ein Wrapper um llama-server, der sich um Model-Download&Verwaltung kümmert. Mit dem Unterschied dass auch whisper.cpp und stable-diffusion mit dabei sind. API für Text/Chat-AI ist dieselbe. Sollte also keinen Unterschied machen ob du ollama oder lemonade verwendest. Die Model-Namen sind aber unterschiedlich. Erster Teil der Config wurde automatisch erstellt, das autocomplete-Model hab ich hinzugefügt. Welche Models ich dann in Continue ausgewählt hab ist im Screenshot oben.
Εrnst B. schrieb: > Da ist nicht viel dran: Ich hätte gedacht da müssen noch die "roles"
1 | roles: |
2 | - chat |
3 | - edit |
4 | - apply |
definiert sein, damit alle Funktionen funktionieren.
Εrnst B. schrieb: > Da ist nicht viel dran: Das Autodetect scheint recht nützlich zu sein, weil man damit die Modelle in den verschiedenen Modi (chat, edit, agent) wählen kann. Bei mir funktionieren die meisten Sachen jetzt, außer ich gebe im Agent Mode "schreibe einen Test" ein, dann wird wohl für python ein Packetmanager namens "Pixi" vermisst. Bis jetzt habe ich noch nie von "Pixi" gehört. Ich habe die größeren Modelle mit 35B Parametern zur Verfügung (Spark DGX). Um die Ergebnisse mit dem obigen Arduino-Test zu vergleichen, bräuchte ich aber die exakten Prompts. Ich bin mir noch nicht sicher, wie sinnvoll es ist, mit dem autocomplete zu arbeiten. Irgendwie nervt es, wenn das Modell ständig beim coden dazwischen quakt.
:
Bearbeitet durch User
Christoph M. schrieb: > dann wird wohl für python ein > Packetmanager namens "Pixi" vermisst Das ist eine der wichtigsten Sachen beim Vibecoden: Achte darauf, was dir die KI an Dependencies reinziehen will. Anweisung neue Abhängigkeiten zweimal zu überdenken und dann mit Begründung nachzufragen kann helfen. ("rules:" in der config.yaml)
> Ich habe die größeren Modelle mit 35B Parametern zur Verfügung (Spark > DGX). Ah, cool. Wie zufrieden bist du mit dem arm64 Umfeld außerhalb LLMs?
Angehängte Dateien:

1N 4. schrieb: > Ah, cool. Wie zufrieden bist du mit dem arm64 Umfeld außerhalb LLMs? DGX wird scheinbar auch für die größeren Maschinen verwendet. Meine (geliehene) ist von Lenovo und heißt Thinkstation PGX. Zuerst dachte ich an einen großen Server, aber dieses Ding ist ein netter kleiner Mini-PC dessen Kantenlänge von ca. 15cm. Beim ersten Einloggen wird ein angepasstes Ubuntu mit ansprechendem Dark-Design installiert und läuft problemlos. Wenn das Ding nicht um die 4000€ kostete, würde ich es glatt als Desktop-PC verwenden. Mit einem Klick lässt sich auch ein vordefiniertes JupiterLab mit KI Features aktivieren und es gibt haufenweise Tutorials. Für den Monitor hat es nur einen HDMI Ausgang und ich hab's mal einen Abend lang als ziemlich teures TV-Backend für die ARD-Mediathek laufen lassen. Firefox läuft natürlich ultra flott. LLamaCPP habe ich auf der Kiste selbst kompiliert, weil es ja ein 20 Core Arm ist .. hat ohne Probleme funktioniert. Mittlerweile verwende ich die PGX aber remote, das dürfte auch der vorgesehene Einsatzzweck sein. Da ja Ubuntu zur Zeit auch Haufenweise Updates verlangt, habe ich die derweil ein paar mal durchgeführt. Einmal ist die PGX hängen geblieben und ich musst einen manuellen Powercycle machen. Das wäre natürlich ziemlich ungut, wenn man das Update wirklich aus weiter Ferne machen muss. Die Thinkstation PGX hat keinerlei LED, an der man sehen könnte, ob sie mit Strom versorgt ist. Deshalb habe ich an einem der USB Anschlüsse einer dieser kleinen USB-Spannungs- und Stromanzeiger angesteckt. Das Netzteil habe ich in einem Stromzähleradapter gesteckt. Das ist extrem praktisch, weil man aus der Stromaufnahme ziemlich gut auf die aktuelle Rechenlast schließen kann. Maximal habe ich bis jetzt so um die 150 Watt gesehen. Wenn kein Modell und sonst nichts im Ubuntu läuft sind es 24 Watt. Der Lüfter ist ultra leise. Das würde ich als großen Vorteil der PGX gegenüber einer RTX5070-TI mit ähnlicher Rechenleistung aber viel zu kleinem Speicher mit zu großer Stromaufnahme und zu lauten Lüftern sehen. Insgesamt gefällt mir die PGX sehr gut. Die Rechenleistung ist ausreichend, auch wenn ich mehr als die einer RTX5070-TI erwartet hätte. Allerdings muss man sagen, dass das Produktmanagement von NVIDIA extrem geschickt gearbeitet hat: Bei den günstiger RTX-Graphikarten ist immer der Speicher zu klein (die PGX hat ja 128GB und kann damit mehrere Modelle im Speiche halten) und will man höhere Geschwindigkeiten mit dem Speicher liegt man ruck zuck in der 10-40k€ Klasse der NVIDIA Beschleuniger.
> Die Rechenleistung ist > ausreichend, auch wenn ich mehr als die einer RTX5070-TI erwartet hätte. Nein, ist wie beim AMD Strix Halo: Der Speicher ist das Gute daran. Von der rohen Rechenleistung ist eine kleinere Grafikkarte oft schneller. Wobei die auch stark im Kurs gestiegen sind. Deshalb ja auch die Frage wie gut das ARM-Umfeld ist, gerade da klemmts oftmals im Number Crunching Umfeld und man muss vieles selbst bauen und optimieren.
Angehängte Dateien:
-

ContinueNoToolUse.png
150 KB
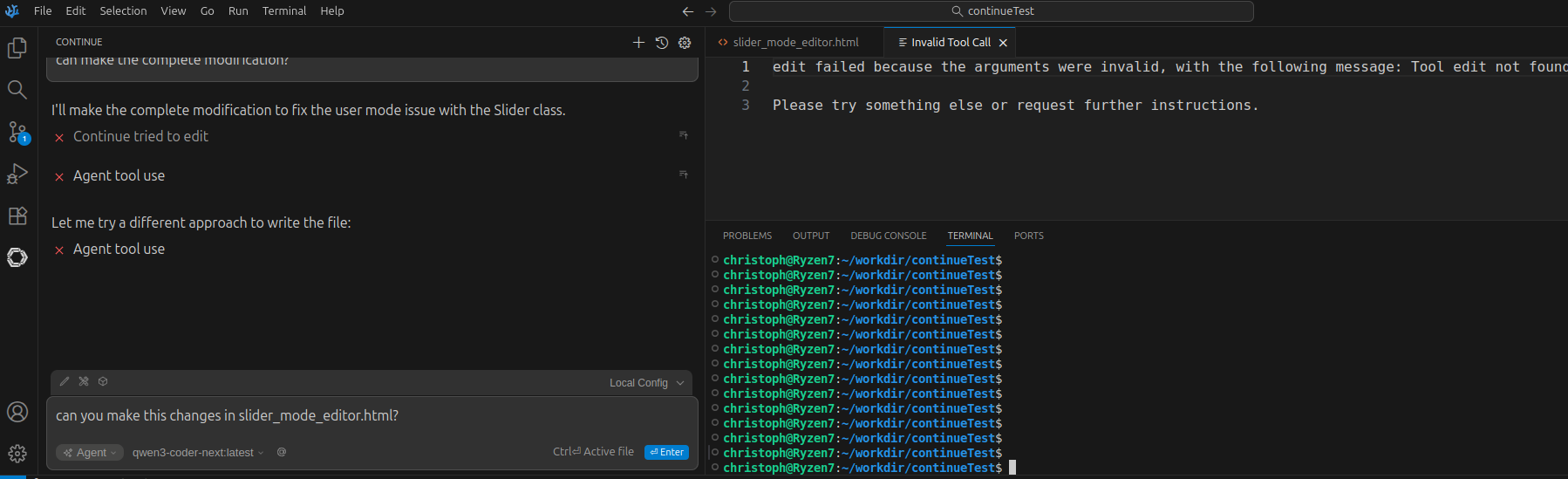
Continue funktioniert bei mir nur teilweise. Es kann auf Anfrage Files erzeugen, aber es kann sie nicht editieren. Scheinbar bin ich nicht der Einzige mit dem Problem: https://github.com/continuedev/continue/discussions/9385 Funktioniert das bei euch?
Christoph M. schrieb: > aber es kann sie nicht editieren. Entsprechende Tools auf "allow" gestellt? https://docs.continue.dev/cli/tool-permissions Und, viele Tools verlassen sich auf das Git-Setup im Ordner, um Rechte zu prüfen, z.B. gehen die davon aus dass geheime Dateien mit API-Tokens und Zugangsdaten im .gitignore stehen, und besser nicht an die KI geschickt werden sollen. Bin mir nicht sicher, ob Continue das auch so handhabt, aber ein simples "git init" im Ordner war bei anderen Tools oft notwendig.
Εrnst B. schrieb: > Christoph M. schrieb: >> aber es kann sie nicht editieren. > > Entsprechende Tools auf "allow" gestellt? Bis jetzt war da kein "permissions.yaml" vorhanden. Das hinzufügen bringt aber auch nichts. "Agent tool use" hat Fehlermeldungen wie
1 | run_shell_command failed because the arguments were invalid, with the following message: Tool run_shell_command not found |
2 | |
3 | Please try something else or request further instructions. |
Da heißt es ja, das "run_shell_command" wurde nicht gefunden. Die Frage wäre: wo sucht der denn und wo müsste es sein?
Christoph M. schrieb: > failed because the arguments were invalid, Die "Tools" werden der KI beim Aufruf mitgegeben, inklusive Anweisung, wann und wie das Tool verwendet werden soll, und wie die Parameter formatiert werden müssen:
1 | ... |
2 | description: `Use this tool to edit an existing file. If you don't know the contents of the file, read it first. [...]`, |
3 | parameters: {
|
4 | type: "object", |
5 | required: ["filepath", "changes"], |
6 | properties: {
|
7 | filepath: {
|
8 | type: "string", |
9 | description: |
10 | "The path of the file to edit, relative to the root of the workspace.", |
11 | }, |
12 | changes: {
|
13 | type: "string", |
14 | description: "Any modifications to the file, showing only needed changes. Do NOT wrap this in a codeblock or write anything besides the code changes. In larger files, use brief language-appropriate placeholders for large unmodified sections, e.g. '// ... existing code ...'", |
15 | }, |
16 | }, |
17 | ... |
Wenn dein KI-Model das Aufbauen der Parameter nicht richtig hinbekommt (z.B. ungültiges JSON generiert, nach der Hälfte der Parameter vergisst, was der Anfang war usw.), kriegst du so eine Fehlermeldung. Mitloggen der kompletten Anfrage an dein lokales KI-Modell und der Antwort schafft Klarheit. Zum Verbessern: Größeres Kontext-Fenster konfigurieren und/oder größeres Modell wählen. Christoph M. schrieb: > Da heißt es ja, das "run_shell_command" wurde nicht gefunden. Das ist tatsächlich eine gute Frage, bei Continue heißt das Tool "run_terminal_command".
:
Bearbeitet durch User
Εrnst B. schrieb: > Mitloggen der kompletten Anfrage an dein lokales KI-Modell und der > Antwort schafft Klarheit. Wie geht das? Meine Modelle liegen in einem Docker-Container auf der DGX im heimischen Netz:
1 | models: |
2 | - name: Autodetect |
3 | provider: openai |
4 | model: AUTODETECT |
5 | apiBase: http://192.168.178.52:11434/v1 |
6 | apiKey: ollama |
7 | roles: |
8 | - chat |
9 | - edit |
10 | - apply |
11 | - autocomplete |
12 | capabilities: |
13 | - tool_use |
Εrnst B. schrieb: > Zum Verbessern: Größeres Kontext-Fenster konfigurieren und/oder größeres > Modell wählen. Als Modell wähle ich qwen3-coder-next:latest https://ollama.com/library/qwen3-coder-next bei dem ich vermute, dass es mit 80B eher groß für ein lokales Modell ist.
:
Bearbeitet durch User
Christoph M. schrieb: > Wie geht das? Entweder du drehst der KI das Logging hoch, oder du schaust ob die Requests in den Developer-Tools (Help->Toggle Developer Tools) der IDE sichtbar sind, oder du fängst die im Netzwerk ab. tcpdump, wireshark, ngrep... ngrep host 192.168.178.52 and port 11434 (ist aber nicht schön lesbar)
Εrnst B. schrieb: > du schaust ob die > Requests in den Developer-Tools (Help->Toggle Developer Tools) der IDE > sichtbar sind, Danke für den sehr guten Tipp. Damit kann man endlich ein wenig sehen, was passiert:
1 | fire @ event.ts:1232 |
2 | fire @ ipc.net.ts:652 |
3 | l.onmessage @ localProcessExtensionHost.ts:383 |
4 | console.ts:137 [Extension Host] Error handling webview message: {
|
5 | "msg": {
|
6 | "messageId": "e6066f7c-bea3-4eff-8f8e-c37710053cff", |
7 | "messageType": "tools/preprocessArgs", |
8 | "data": {
|
9 | "toolName": "run_shell_command", |
10 | "args": {
|
11 | "command": "bash -c \"pwd\"" |
12 | } |
13 | } |
14 | } |
15 | } |
16 | |
17 | Error: Tool run_shell_command not found |
Der Agent oder auch der Chat kann keine Shell-Kommandos ausführen.
Das Problem mit "Continue" ist ja irgendwie nicht zu lösen. Es gibt noch andere Plugins für VSCode wie KiloCode: https://kilo.ai/docs/ Hat das schon mal jemand probiert?
Christoph M. schrieb: > Das Problem mit "Continue" ist ja irgendwie nicht zu lösen. Musst halt nur rausfinden, was du falsch machst. Context-Length hast du sicher hochgestellt? Mit den 4K Default von Ollama vergisst der Agent wie das Tool heißt, bevor er überhaupt dazukommt es aufzurufen. Hab mal für ein Beispiel den Netzwerkl-Traffic abgefangen. Anfrage (im Agent mode von Continue) > how many files are in this folder and subfolders, I just need the count. Daraus wurde die Anfrage in request.json an das Modell. Die "role=system" Message hab ich nochmal extrahiert, für bessere Lesbarkeit. Das "run_terminal_command" daraus:
1 | To run a terminal command, use the run_terminal_command tool |
2 | The shell is not stateful and will not remember any previous commands. When a command is run in the background ALWAYS suggest using shell commands to stop it; NEVER suggest using Ctrl+C. When suggesting subsequent shell commands ALWAYS format them in shell command blocks. Do NOT perform actions requiring special/admin privileges. IMPORTANT: To edit files, use Edit/MultiEdit tools instead of bash commands (sed, awk, etc). Choose terminal commands and scripts optimized for linux and x64 and shell /bin/bash. |
3 | You can also optionally include the waitForCompletion argument set to false to run the command in the background. |
4 | For example, to see the git log, you could respond with: |
5 | `'`tool |
6 | TOOL_NAME: run_terminal_command |
7 | BEGIN_ARG: command |
8 | git log |
9 | END_ARG |
10 | `'` |
Die Antwort vom Modell ist in vielen Event-Stream Chat-Deltas zerstückelt, enthält aber:
1 | `'`tool |
2 | TOOL_NAME: run_terminal_command |
3 | BEGIN_ARG: command |
4 | find . -type f | wc -l |
5 | END_ARG |
6 | `'` |
Model hat sich also exakt an die Vorgaben für den Tool-Call gehalten,
und nicht einen neuen Tool-Namen ("run_shell_command" oder so) erfunden.
Im nächsten Request kriegt das Model dann nochmal die ganze Historie
zusammengefasst:
1 | ... |
2 | {"role":"user","content":"how many files are in this folder and subfolders, I just need the count."},
|
3 | {"role":"assistant","content":"\n`'`tool\nTOOL_NAME: run_terminal_command\nBEGIN_ARG: command\n\"find . -type f | wc -l\"\nEND_ARG\n`'`"},
|
4 | {"role":"user","content":"Tool output for run_terminal_command tool call:\n\n589\n"}
|
Und die KI "denkt" nach:
1 | The user wants to know the number of files in the current folder and subfolders. I have already run a command to find the number of files, and the output is 589. I should now provide this answer to the user. |
und Antwortet schließlich:
> There are 589 files in this folder and its subfolders.
PS: "`'`" ist eigentlich dreimal "`", bringt aber die Forensoftware
durcheinander, auch innerhalb von code-Blocks.
Angehängte Dateien:
-

Rule7.png
47 KB
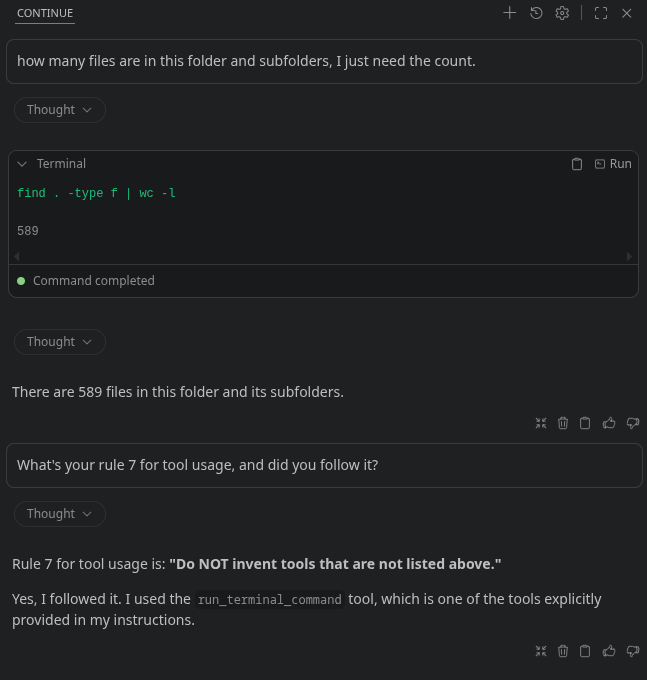
Ansonsten: Du kannst deine KI ja fragen, warum sie den Tool-Namen geändert hat. In den System-Instructions steht: RULES FOR TOOL USE: 1. To call a tool, output a tool code block using EXACTLY the format shown above. 2. Always start the code block on a new line. 3. You can only call ONE tool at a time. 4. The tool code block MUST be the last thing in your response. Stop immediately after the closing fence. 5. Do NOT wrap tool calls in XML tags like <tool_call> or <function=...>. 6. Do NOT use JSON format for tool calls. 7. Do NOT invent tools that are not listed above. 8. If the user's request can be addressed with a listed tool, use it rather than guessing. 9. Do not perform actions with hypothetical files. Use tools to find relevant files.
Danke für deine wertvollen Hinweise. Εrnst B. schrieb: > Musst halt nur rausfinden, was du falsch machst. Context-Length hast du > sicher hochgestellt? Wie kann ich die Kontextlänge hochstellen? Wie heißt eigentlich das Format, mit dem kommuniziert wird und kann man dazu irgendwas lesen? Mittlerweile habe ich kilo-ai mal ausprobiert und nach Eintragen der richtigen Serveradresse funktioniert das besser als continue. Nichts desto trotz will ich es noch mal mit continue versuchen. Sicherlich gibt es Unterschiede zwischen den verschiedenen Coding-Agents. Es stellt sich auch die Frage, ob ein geschickt programmierter Coding-Agent bestimmte Schwächen kleinerer Modelle ausgleichen kann. Mit VSCode bin ich bis jetzt ohnehin noch nicht so richtig warm geworden. Ich habe ziemlich lange Eclipse benutzt und war damit eigentlich ganz zufrieden, aber zuletzt habe ich nur noch mit Code-Completion Editoren und Terminal-Compiler programmiert, weil sich das für mich als relativ effizient herausgestellt hat und man muss sich nicht ständig mit irgendwelchen Untiefen und Eigenheiten der IDEs herumärgern.
:
Bearbeitet durch User
Christoph M. schrieb: > Wie kann ich die Kontextlänge hochstellen? https://docs.ollama.com/context-length > Wie heißt eigentlich das Format, mit dem kommuniziert wird und kann man > dazu irgendwas lesen? "OpenAI API Style Chat Completions" oder so. https://docs.ollama.com/api/openai-compatibility (die Beispiele auf "shellscript" stellen, dann siehst du eher was tatsächlich über HTTP gesendet wird) Christoph M. schrieb: > Sicherlich gibt es Unterschiede zwischen den verschiedenen > Coding-Agents. Allein schon in den System-Instructions. Christoph M. schrieb: > Es stellt sich auch die Frage, ob ein geschickt programmierter > Coding-Agent bestimmte Schwächen kleinerer Modelle ausgleichen kann. Ja. Schau mal in die System-Instructions von Continue, die ich oben angehängt habe. Das sind 6kB an Anweisungen, die der KI mit jeder Anfrage mitgeschickt werden. Kürzere Anweisungen wären für ein kleineres Modell besser. Zu kurze oder unpräzise Anweisungen wären für jedes Modell schlecht.
Εrnst B. schrieb: > Do NOT perform actions requiring special/admin privileges. Wer glaubt eigentlich ernsthaft, dass ein LLM sich strickt daran hält? So funktionieren LLM nicht! Sie erzeugen Output, der mehr oder weniger auf Wahrscheinlichkeiten und Zufall beruht. Man kann sich nie darauf verlassen. Wenn dann der "Agent" dazu so offen wie ein Scheunentor ist (was bei einer Shell in der Natur der Sache liegt), dann muss das mit einer nicht vernachlässigbaren Wahrscheinlichkeit irgendwann gründlich schief gehen. Lassen wir 3 jährige Kinder oder junge Hunde frei im Kaufhaus toben? Nein! Warum tun wir das dann mit KI Diensten?
:
Bearbeitet durch User
Wie sieht das eigentlich mit den Kosten aus? Man liest diese Woche viel davon, dass die Nutzungsentgelte gerade um Faktor 5-20 gestiegen sind (was zu erwarten war, nur das "wann" war ungewiss). Zum Beispiel hat Uber gerade eine harte Begrenzung festgelegt, weil das Jahresbudget schon im April verbraucht war. Bei Uber ist das Budget 1500€ pro Person und Monat, offenbar auf Basis der alten noch niedrigen Preise. Das hat schon nicht genügt. Und nun wird es grob 10x so teuer. Andere berichten, dass sie ihr Monatsbudget von einigen hundert Euro schon nach 2 Tagen verbraucht hätten. Wenn sie aufgrund der finanziellen Lage nur noch wenige Tage nutzbar sind und an diesen Tagen wie gehabt auch nur einen Bruchteil der Arbeitszeit einsparen, dann erkenne ich darin keinen Sinn mehr. Jedenfalls nicht für die breite Masse. Umweltschutz wäre sinnvoller.
:
Bearbeitet durch User
Hat einer von Euch zu Ollama die open-Webui installiert? Die findet nämlich bei uns die Modelle im Ollama-Modellverzeichnis nicht. Müssen wir wirklich alle Modelle mit der Webui nocheinmal runterladen, oder was läuft da nicht? Die Webui und Ollama sind beide windowsnativ, also ohne Docker installiert. Betriebsystem Win11 Enterprise. mfg
Angehängte Dateien:
-

open_webui.png
120 KB
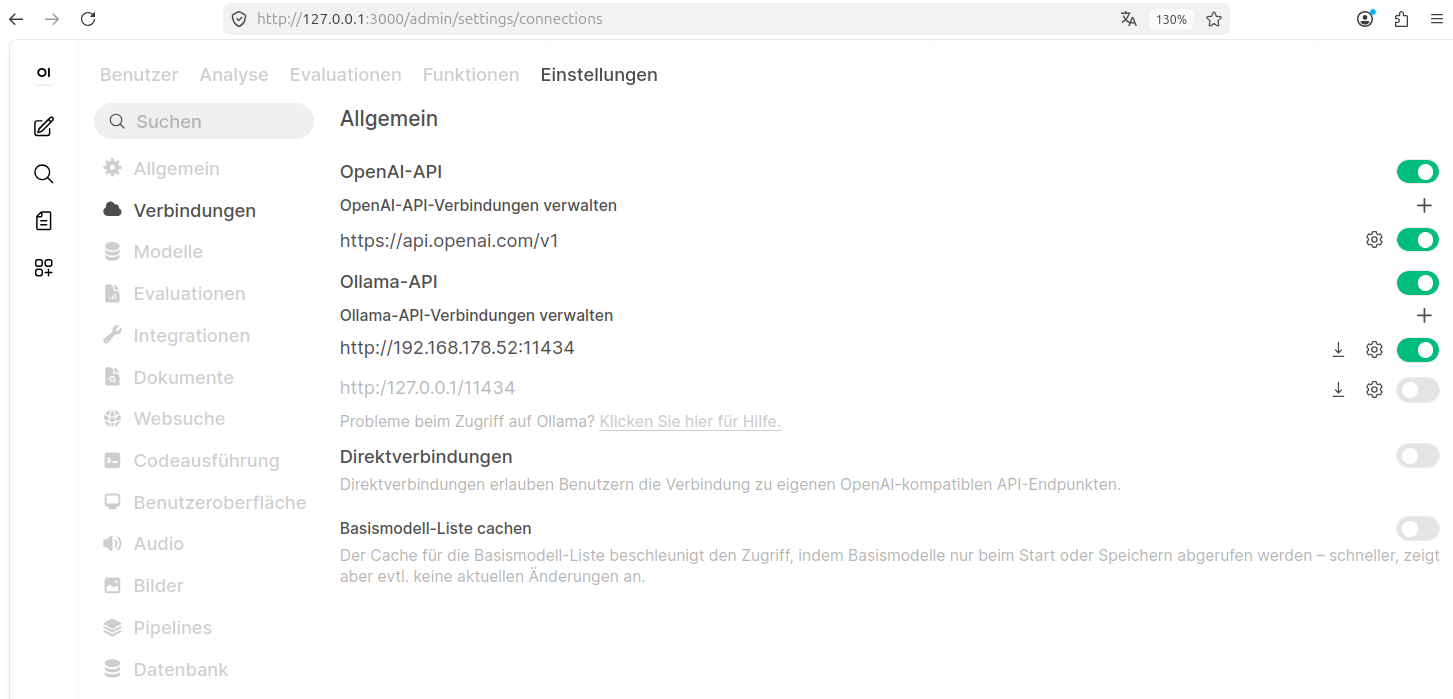
Lotta . schrieb: > Hat einer von Euch zu Ollama die open-Webui installiert? Ja, ich. Aber mit Docker Container, was aber eher eine Zusatzschwierigkeit bringen sollte. Ich habe eine ziemliche Zeit gebraucht, open-webui mit Ollama zu verbinden. Das geht normalerweise über die IP-Adresse des lokalen Zielrechners auf dem Port 11434. Das Problem lag hauptsächlich darin, das Menu für das Setup zu finden. Vielleicht hilft dir das Bild im Anhang.
Lotta . schrieb: > Hat einer von Euch zu Ollama die open-Webui installiert? Was mir noch aufgefallen ist: oben in meinem Screenshot habe ich zwei IP-Adressen: die vom der remote Spark 192.168.178.xx und die lokale 127.0.0.1 Open-webui funkioniert mit der Spark, aber nicht mit der lokalen KI auf dem Ryzen. Die API-Versionen der beiden Ollmas sind unterschiedlich und können via "curl" getestet werden:
1 | christoph@Ryzen7:~$ curl http://localhost:11434/api/version |
2 | {"version":"0.21.0"}
|
3 | |
4 | curl http://192.168.178.52:11434/api/version |
5 | {"version":"0.20.7"}
|
und die vorhandenen LLMs auf den Maschinen könne auch via "curl" abgefrag werden und zeigen an, dass beide ollamas laufen.
1 | http://localhost:11434/api/tags |
2 | curl http://192.168.178.52:11434/api/tags |
Beide melden die vorhandenen LLMs zurück. Woher das Problem kommt, dass es bei der remote Maschine funktioniert und bei der lokalen nicht, könnte daher kommen. Es gibt bei open-webui eine ganze Latte von Problembeschreibungen: https://docs.openwebui.com/troubleshooting/connection-error/
:
Bearbeitet durch User
Hans W. schrieb: > Wer glaubt eigentlich ernsthaft, dass ein LLM sich strickt daran hält? Niemand. Darum ist die Default-Einstellung dass der User das Shell-Kommando sieht und abnicken muss. Wenn du da "Allow everything" klickst, bist du selber schuld. Christoph M. schrieb: > Ja, ich. Aber mit Docker Container, was aber eher eine > Zusatzschwierigkeit bringen sollte. Beides in eine docker-compose, und es hat sofort funktioniert, ohne irgendwelche Schwierigkeiten.
1 | services: |
2 | ollama: |
3 | image: ollama/ollama |
4 | volumes: |
5 | - ollama-data:/root/.ollama |
6 | ... |
7 | webui: |
8 | image: ghcr.io/open-webui/open-webui:main |
9 | volumes: |
10 | - webui-data:/app/backend/data |
11 | depends_on: |
12 | - ollama |
13 | ports: |
14 | - "127.0.0.1:8880:8080" |
15 | environment: |
16 | - OLLAMA_BASE_URLS=http://ollama:11434 |
17 | ... |
18 | volumes: |
19 | ollama-data: |
20 | webui-data: |
(Statt den Volumes lassen sich auch einfach Ordner am Host-PC verwenden)
Huch, das ist ein Ding... :-P Wir haben nun herausgefunden, das die open-webui oder das darunterliegende Python 3.11 das Wörtchen "localhost" nicht auflösen kann. Mit der Angabe 127.00.01:11434 verbindet sich die Webui nun mit Ollama, es kommt keine Fehlermeldung mehr und im Admin-Mode sind nun die Ollama Modelle unter "Modelle" zu sehen. Ich hab nun alle Modelle in der linken Seitenleiste anzeigen lassen und kann nun die Modelle zum Chatten umschalten. mfg
Lotta . schrieb: > Ich hab nun alle Modelle in der linken Seitenleiste > anzeigen lassen und kann nun die Modelle zum Chatten umschalten. Sehr schön, dass es geht. Hier gibt es einen Modellvergleich: https://www.reddit.com/r/LocalLLaMA/comments/1tya05j/aa_comparison_of_the_latest_local_models/#lightbox qwen3.6 27B schneidet ziemlich gut ab. Welches Modell bevorzugst du?
Christoph M. schrieb: > Lotta . schrieb: >> Ich hab nun alle Modelle in der linken Seitenleiste >> anzeigen lassen und kann nun die Modelle zum Chatten umschalten. > > Sehr schön, dass es geht. > > Hier gibt es einen Modellvergleich: > https://www.reddit.com/r/LocalLLaMA/comments/1tya05j/aa_comparison_of_the_latest_local_models/#lightbox > > qwen3.6 27B schneidet ziemlich gut ab. > Welches Modell bevorzugst du? Wir laden erstmal alles runter, was wir bekommen können. Immerhin haben wir 8Tb NVMe Raid 0 :-P Und dann wird geschlemmt! Ich hab mit meheren Modellen experimentiert. Meine Eltern priorisieren dabei die Spracherkennung und Sprechen zum Training meinerseits. Naja. Das Ziel meiner Freundin und mir ist erst mal die Übersetzung des IDA Pro-Buch für disassemblerFreaks von english in Deutsch. Und dann, wenn die REST Api zu intellij Idea steht, das Musikproggy, an dem wir schon ne Weile murksen. :-P Und mit qwen3-coder30b nen kleines Projekt, reverse Engineering eines Eprom Inhaltes eines der ersten Chipkartenleser-Prototypen von 1990. Boahhh!, da läuft es einen heiß den Rücken runter, vibe Reversing vom Feinsten! Diskutieren mit nem Fachmann! :-P mfg
Lotta . schrieb: > Ich hab mit meheren Modellen experimentiert. > Meine Eltern priorisieren dabei die Spracherkennung und Sprechen > zum Training meinerseits. Das Thema Spracherkennung hatte ich hier auch schon mal angefangen: Beitrag "KI Modell mit Spracherkennung" Muss mal schauen, wie man das mit einem beliebigen Modell verbindet. Und vor allen Dingen muss das Modell gut Deutsch können, weil ja die meisten in Englisch trainiert sind.
Christoph M. schrieb: > Lotta . schrieb: >> Ich hab mit meheren Modellen experimentiert. >> Meine Eltern priorisieren dabei die Spracherkennung und Sprechen >> zum Training meinerseits. > > Das Thema Spracherkennung hatte ich hier auch schon mal angefangen: > Beitrag "KI Modell mit Spracherkennung" > > Muss mal schauen, wie man das mit einem beliebigen Modell verbindet. > Und vor allen Dingen muss das Modell gut Deutsch können, weil ja die > meisten in Englisch trainiert sind. das ist ein kleineres Problem, da die open-webui mit "Whisper" das Sprechen und die Spracherkennung schon mitbringt. Wir werden heut die Stimme "Sarah" optimieren, wenn sie dann vernünftig läuft, poste ich unsere Ergebnisse hier. mfg
:
Bearbeitet durch User
Lotta . schrieb: > Wir werden heut die Stimme "Sarah" optimieren, wenn sie dann > vernünftig läuft, poste ich unsere Ergebnisse hier. Sprachausgabe? TTS? Das fehlt mir noch. Musst du mal zeigen, was man da am besten nimmt.
Εrnst B. schrieb: > Christoph M. schrieb: >> Ja, ich. Aber mit Docker Container, was aber eher eine >> Zusatzschwierigkeit bringen sollte. > > Beides in eine docker-compose, und es hat sofort funktioniert, ohne > irgendwelche Schwierigkeiten. Wenn open-webui und ollama in einem Container sind, geht es wahrscheinlich gut. Wenn sie in zwei getrennten Containern sind und open-webui aus dem Browser aufgerufen wird, gibt es scheinbar aus Sicherheitsgründen (welche weiß ich nicht) Zugriffsschwierigkeiten wenn open-webui über den Port 11434 auf ollama zugreifen soll.
Christoph M. schrieb: > Wenn open-webui und ollama in einem Container sind Es sind zwei Container. docker compose kümmert sich darum, dass beide ein gemeinsames Netzwerk haben, und jeder Container die Namen der anderen auflösen kann, damit beide über das interne Netzwerk kommunizieren können. Gleichzeitig bleibt das Netzwerk aus dem compose-stack von anderen Docker-Netzwerken getrennt (außer man konfiguriert das explizit anders)
Auf einigen Webseiten wird gpt-os-120b empfohlen: https://openai.com/de-DE/index/introducing-gpt-oss/ Ist das eigentlich noch aktuell? Mir scheint gemma4-26b recht gut zu laufen. https://ollama.com/library/gemma4:26b
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.