Hallo Freunde, ich wollte eine Analyse von FIR-Filtern im Frequenzbereich machen. Der erste Schritt war den Frequenzgang des HP-Filters mittels FFT in Matlab zu berechnen. Der zweite Schritt war, die Filter-Koeffizienten des HP-Filters in Festkommazahl-Format (15-bit + 1-sign-bit ) umzuwandeln und den Frequenzgang des quantisierten HP-Filters zu berechnen. Meine Absicht war die Frequenzgänge zu vergleichen und über die eintretenden Quantisierungsfehler zu diskutieren. Leider ist die Skalierung so groß, dass ich keinen Vergleich machen kann. Was muss ich machen um die zu vergleichen? Normalisieren wäre meine Idee? Aber wie?
So dass der Frequenzgang bei f=0 gleich 1 ist? Also H_norm = H/H(0)?
Hi Andreas, ja, ich will das normalisieren, d.h. die max. Amplitude würde gleich 1 sein. Ich bin auch am Grübeln, ob der Vergleich sinnvoll ist, wenn man sich mit FIR Filter Algorithmen auf einem DSP beschäftigt?
Klar ist der Vergleich sinnvoll, man darf aber nicht vergessen dass durch das Begrenzen der Wortlänge nach dem Multiplizierer auch noch Rundungsfehler dazukommen. Wie man das normieren macht hab ich oben schon geschrieben: H_norm = H/H(f=0)
Hi Andreas, ich verstehe die Berechnung noch nicht. Es geht ja um einen HP-Filter, d.h. die Amplitude bei f=0 ist ja Null. Warum durch H(f=0) teilen? Kannst du mir bitte die untere Formel mit einem einfachen Beispiel erklären? H_norm = H/H(f=0)
Ups, das mit dem HP habe ich überlesen. Dann eben H/H(f→∞) bzw. f=f_s/2. Anderer Weg: schau doch einfach um welchen Faktor sich die Koeffizienten bei deiner Umrechnung ins Festkomma-Format ändern, wende diesen Faktor auf die unquantisierten Koeffizienten an, und vergleiche sie mit den quantisierten.
Angehängte Dateien:
-

fixedpointformat.jpg
55 KB
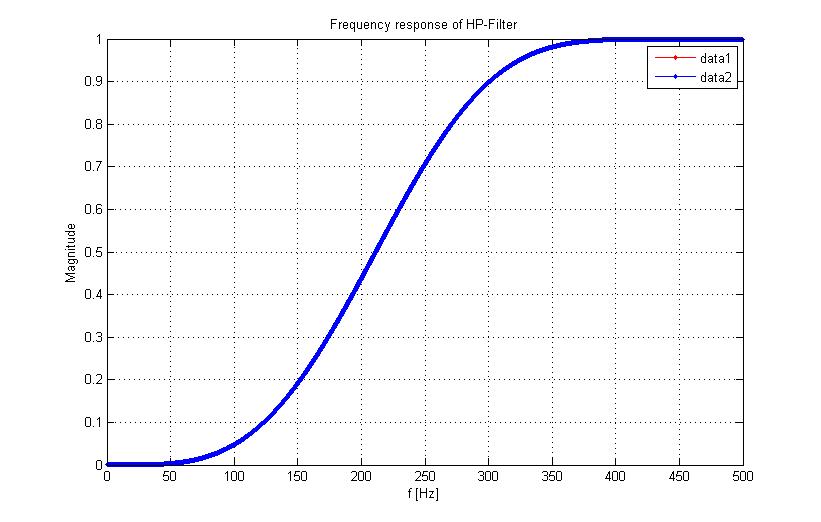
Hi Andreas, also ich beschäftige mich gerade wieder mit meinem Thema. Irgendwie kann ich die Quantisierungsfehler nicht darstellen. Ich habe die Amplitude erstmal normiert von dem unquantisierten und quantisierten HP-Filter Koeffizienten. Dafür habe ich einfach die Ergebnisse durch deren max. Amplitude geteilt. Jetzt ist die max. Ampl. gleich 1. Aber ich bin mir sicher, dass ich kleine Abweichungen sehen muss. Ist das vielleicht ein Matlabproblem? Die Quantisierung ändert ja den Frequenzgang, d.h. ich muss ja eine Abweichung sehen. Im Anhang siehst du den Plot.
Du quantisierst auf 16Bit, das sind 1/65536. Deine Grafik hat vielleicht ne vertikale Auflösung von 1/500, da maß man garnix sehen. Mal data1-data2 plotten ? Normierung: die Daten aufeinander fitten ist besser als sie auf den Maxwert zu normieren; x=unquantisertes_zeug(:); y=quantisertes_zeug(:); M=[x ones(length(x,1)]; coff=inv(M'*M)*M'*y; plot(M*coff-y) Cheers Detlef
Angehängte Dateien:
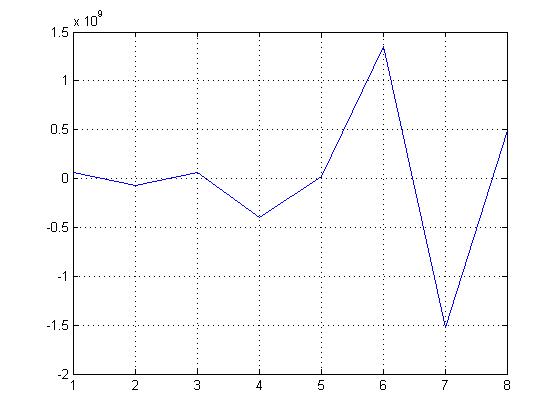
Hi Detlev, deinen Vorschlag habe ich auch geplottet. Aber trotzdem sehe ich das nicht, was ich erwarte. Das ist ja wie oben. Wenn ich beide normieren würde, dann würden die sich wieder überlappen. Ich habe so eine schöne Abb. von FIR Filterkoeffizienten beim Übergang vom Floating- ins Fixed-Point Format gesehen. Deshalb wollte ich dieses Ergebnis auch mit meinen Filterkoeffizienten darstellen. Ich könnte das einscannen, was ich meine, wenn das weiter hilft.
Angehängte Dateien:
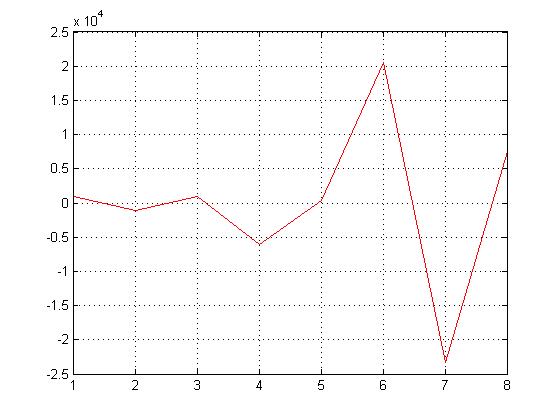
komisch, das 2.Bild ist nicht dabei, hier nochmal
>>Mal data1-data2 plotten ?
data1 und data2 waren <=1. Deine Bilder zeigen irgendwas anderes.
Cheers
Detlef
Hi Detlev, also, ich habe das auch gemacht. Da kommt aber ein ganz anderes Ergebnis, welches ich nicht interpretieren kann. Kannst du in mein Matlab-Script mal reinschauen, um zu gucken was ich falsch mache? Ich will nur eine Graphik haben, die die Quantisierungsfehler beim Übergang von Floating- ins Fixed-Point-Format darstellt.
Wenn floating point gleich viele signifikanten Stellen wie Integer hat, sieht man natuerlich nichts. Und bei Integer muss man das das etwas realistisch machen, zB ADC < 16bit und rechnen mit 32 bit. Wenn man sowas mit Single Precision float, 32 bit float vergleicht wird man wenig sehen, es kann sogar sein, dass 32bit float schlechter als 32bit int ist. Als mit 64bit Float testen. Und vielleicht von 32bit int auf 24 bit int zurueckgehen.
Guten Morgen! Ich verstehe diese Theorie noch nicht. Wo hast du das nachgelesen? Ich will das mal auch durchgehen! Kannst mir den Titel des Buches verraten oder den Link angeben?
Floats bestehen aus der Mantisse und dem Exponenten, etwa in der Form Mantisse*Basis^Exponent mit Basis=2 in binär. Da du bei einem 32bit Float ein paar Bits für den Exponenten brauchst (abhängig von der Architektur, bei single float glaub 5..7 Bit), bleiben weniger für die Mantisse übrig - ein 32bit Int hat dagegen volle 32bit "Mantisse", dafür keinen Exponenten. Versuch mal hexadezimal 123ABCDE in einem single float mit 24bit Mantisse zu verpacken. In einen 32bit Int passt es vollständig rein. Weiteres findest du auf wikipedia. Floats haben halt den Vorteil viel universeller zu sein, wenn du eine Rechnung in Int machen willst, musst du die Größenordnung der Werte viel stärker beachten. Wenn du die Größenordnung aber ganz gut einschätzen kannst, ist der Exponent beim Float redundant und der Int (je gleiche größe) bietet dir mehr nutzbare Daten.
Hallo Leute... ich habe ein Problem. kann jemand mir die lösungen von dieser aufgabe geben. 1. Diskutieren Sie die charakteristischen Vor- und Nachteile von FPGAs gegenueber Prozessoren. Das ECP2M-20 mit 18000 Zellen, 24 100MHz-Multiplizierern und 128 KB RAM sowie Konfigurationsspeicher kostet etwa gleichviel wie der Blackfin BF561 mit 600 MIPS und 300 KB Speicher. Stellen die die Rechenleistungen fuer FIR-Filter gegenueber. 2. Mit einer Rate von 100/s soll durch Korrelation der Laufzeitunterschied zwischen zwei reellen Signalen festgestellt werden. Die Signale werden simultan abgetastet (16-Bit-Abtastwerte). F¨ur jede Delayauswertung ist dazu die Korrelation: h(K,m) = summe Xn=0 bis 1023 von s1(K − n)s2(K − n + m) fuer m = −512 . . . + 511 zu berechnen. Wie hoch ist die Operationsrate bei Verwendung der schnellen Faltung?
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.