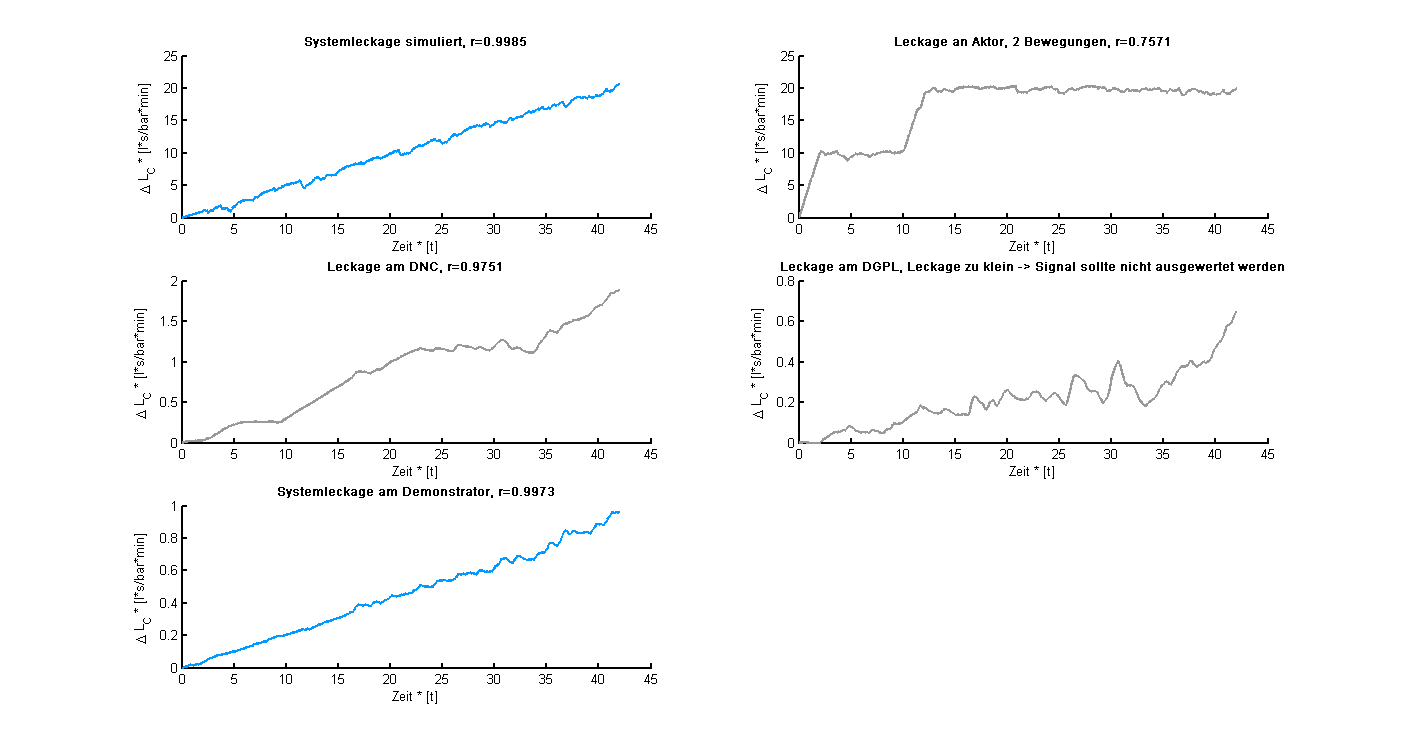
Hallo, ich möchte in einem verrauschtem Messsignal S erkennen, ob eine Gerade vorliegt oder nicht. Meine Idee war es eine Gerade G durch den ersten und letzten Messpunkt zu legen. Als nächstes wird der Korrelationskoeffizient r aus S und G bestimmt. Im Anhang finden sich einige Messignale. Die blau dargestellten sind Geraden, die Grau dargestellten sind keine. Vergleicht man abbildung 3 und 5 miteinander, so unterscheiden sich die Koeffizienten r nicht groß voneinander (0.9751 zu 0.9973). Aber das muss ja nichts heißen. Nun meine Frage. Ist der Ansatz so in Ordnung, ist er robust? Wie kann ich jetzt eine Entscheidungsgrenze festlegen (ab welchem r), ob es eine Gerade ist oder nicht? Viele Grüße Filip
Angehängte Dateien:
-

zusammenfassung_koeff.png
9,2 KB
Hallo, nein, das ist zu ungenau, weil Du nur zwei Punkte verwendest, die beide einen Fehler aufweisen. ein bessere Ansatz wäre, eine Reihe Punkte abzutasten, die in gleichem X-Abstand voneinander liegen. Dann erhälst Du eine zackige Linie. Durch diese Linie legst Du eine Gerade indem Du die Steigung und den Offset solange variierst bis die Summe der Standardabweichungen der Punkte minimal wird, d.h. der mittlere Lot-Abstand aller Messpunkte zu gedachten Linie muss minimal werden. Als Startwert kannst Du aber die beiden Punkte ausserhalb nehmen, von diesem Startwert aus beginnst Du die Variation. Dann beginnst Du rechnerisch die Gerade zu verschieben, sowohl im Offset als auch in der Steigung und berehnest die Summe neu. Das ist ein interativer Prozess dessen Genauigkeit von der Schrittweite abhängt, einen direkten Weg sofort zum Ergebnis wüsste ich nicht. Schau mal in der math. Literatur nach (Geometrie), dieses Problem ist schon tausendfach gelöst worden und müsste daher auch für Rechner beschrieben worden sein, vermutlich sogar in einem einzigen Schritt. Gruss, Christian
Es geht auch ohne Iteration. Wenn du die gerade finden willst, dann interpolierst du linear mit der Methode der kleinsten Quadrate. Heißt, du findest eine Gerade y =ax + b so, das für alle Punkte (xi, yi) der Term summe((a * xi + b) * (a * xi + b)) minimiert wird. Verfahren dazu gibt's - wenn ich mich recht erinnere - in der Wikipedia. Such dort (oder über Google) einfach nach "linearer Interpolation" "kleinste Quadrate" oder Varianten davon. Ist ein statistisches Verfahren, bei dem du Mittelwerte, Varianzen, Korrelationen und so berechnen musst. Wenn du dann diese Gerade gefunden hast, dann kannst du diese Summe ausrechnen und durch die Anzahl der Punkte teilen. Das gibt dir dann die Abweichung von der Geraden. virtuPIC /ggadgets for tools & toys
> nein, das ist zu ungenau, weil Du nur zwei Punkte verwendest, die > beide einen Fehler aufweisen. Zustimmung. Wenn nur einer der beiden Punkte ein Ausreißer ist, liefert das Verfahren völligen Murks. > Das ist ein interativer Prozess dessen Genauigkeit von der > Schrittweite abhängt, ... Ich würde einfach eine lineare Regression durch alle Punkte machen http://de.wikipedia.org/wiki/Lineare_Regression Das geht sehr fix, weil man die Liste der Messpunkte nur einmal durchlaufen muss und in einem Rutsch sowohl die optimalen Geradenparameter als auch den Korrelationskoeffizienten herausbekommt. > ... d.h. der mittlere Lot-Abstand aller Messpunkte zu gedachten > Linie muss minimal werden. Bei der Regression wird statt dessen der mittlere quadratische y-Abstand minimiert. Das ist aber ok, das es sich nicht um eine geometrische Gerade, sondern um eine Messkurve handelt.
Angehängte Dateien:
-

dnc_l_ausgleichsgerade.png
3,3 KB
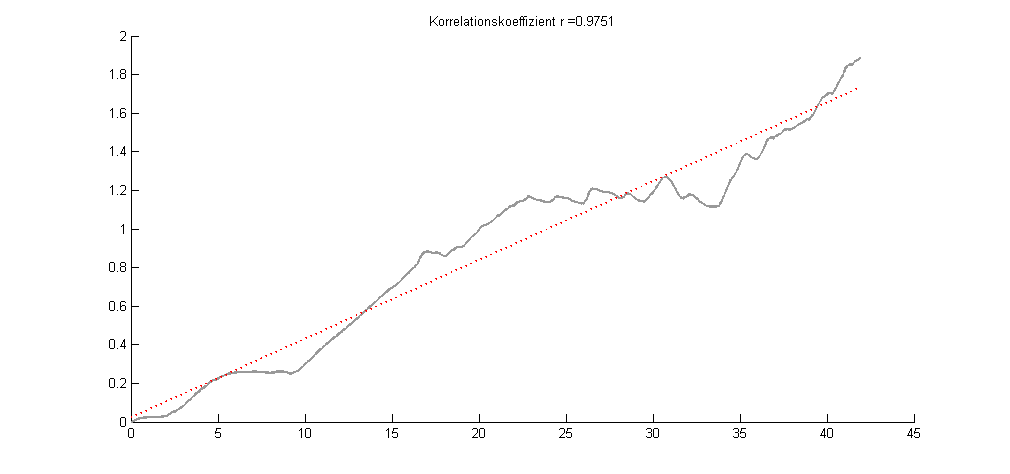
Hallo, danke für Eure Antworten. Die Ausgleichsgerade habe ich schon angewandt, es kommt jedoch, warum weiß ich noch nicht genau das gleiche heraus. (siehe Anhang). Unter Umständen reichen diese kleinen Differenzen in r ja schon aus um zu unterscheiden. Gruß Filip
Vielleicht habe ist mein Anliegen auch noch nicht ganz klar geworden. Eigentlich geht es mir vorallem darum, ob der Ansatz gerechtfertigt ist, den Korrelationskoeffizienten als Maß für die Ähnlichkeit zu verwenden. Und dann anschließend die Frage: "Wo kann ich eine Grenze setzen?" Solltet ihr wissen unter welchen Begriffen ich in der Signalverarbeitung schauen muss, wäre das völlig ausreichend. Momentan kann, dank unzureichender Kenntnisse auf dem Gebiet, nicht die richtigen Fragen stellen. Gruß Filip
> Die Ausgleichsgerade habe ich schon angewandt, es kommt jedoch, > warum weiß ich noch nicht genau das gleiche heraus. Das ist seltsam, da sich die Regressionsgerade und die Gerade durch die beiden Endpunkte in dem Beispiel schon sehr deutlich unterscheiden. Bist du sicher, dass du richtig gerechnet hast? Oder hast du vielleicht in beiden Fällen den Korrelationskoeffizienten in beiden Fällen direkt, also ohne Berücksichtigung der zuvor bestimmten Geraden berechnet? Mir erscheinen gefühlsmäßig die 0,9751 für Beispiel 3 auch etwas hoch, aber Gefühle trügen oft :) > Eigentlich geht es mir vorallem darum, ob der Ansatz gerechtfertigt > ist, den Korrelationskoeffizienten als Maß für die Ähnlichkeit zu > verwenden. Würde ich schon sagen, für solche Aufgaben ist der Korrelations- koeffizient erfunden worden. > Und dann anschließend die Frage: "Wo kann ich eine Grenze setzen?" Das ist schon schwieriger zu entscheiden. Das ist eine ähnliche Fragestellung wie die Festlegung der Fehlertoleranz, ab der produzierte Werkstücke als Ausschuss deklariert werden. Man muss sich eben Gedanken machen, bis zu welchem Fehler sie ihre Funktion noch zuverlässig erfüllen. Dazu muss man wiederum wissen, wozu und wie sie genutzt werden.
Was mir dazu einfällt: 1) Hast du überhaupt erwogen, zunächst einmal das Rauschen zu verringern? 2) Lineare Regression hat zwar den Vorteil, dass sie leicht berechnet werden kann. Durch die Minimierung der quadratischen Abweichung vom Messwert ist dafür aber der Einfluss des Rauschens auf den Endwert ganz besonders stark. Eventuell sollte man da ein anderes Verfahren einsetzen. 3) Wie ich deine Frage verstanden habe, geht es dir vor allem darum, die Form der Kurve zu erkennen. (Stufe vs. Gerade) Ist der mögliche Zeitpunkt einer Stufe bekannt, könnte man Geraden "vorher" und "nachher" berechnen und die jeweilige Steigung (Mittelwert der Parameter a) mit dem Versatz (Differenz der Parameter b) vergleichen. Ist der Zeitpunkt nicht bekannt, könnte man die Messkurve noch mit einem Polynom dritten Grades annähern und die Parameter für x und x³ vergleichen. (Wird aber sehr aufwändig.)
Hallo Fillip, ja, das Bestimmtsheitsmass ist die Güte der Schätzung, je näher es an 1 liegt umso besser liegen die Punkte auf einer Gerade. Den Wikiartikel halte ich allerdings für unverständlich, da tut es ein normales Mathematikbuch über Statisktik auch. Bitte beachte, dass Lineare Regression NUR bei linearen Kurven funktioniert, also wenn die Messwerte um eine gerade pendeln. Sobald sie aber Funktionen darstellen wird es schwieriger, dann musst Du eine Polynom-reihen entwickeln und dann geht es ins Eingemachte. Gruss, Christian (der das zeug seit 15 jahren im Job nie wieder gesehen hat :-)
Du kannst von wegen Robustheit auch über Spearman rechnen. Die Daten werden auf Rangskalenniveau degradiert. Allgemein gibt es keine Möglichkeit schwammige Daten in exakte Ergenisse zu transformieren.
Filip wrote: > Eigentlich geht es mir vorallem darum, ob der Ansatz gerechtfertigt ist, > den Korrelationskoeffizienten als Maß für die Ähnlichkeit zu verwenden. Ich denke der Korr.Koeff. ist nicht ideal, weil die Fehler am Anfang und Ende der Gerade unverhältnismäßig stark gewichtet werden. Ich würde statt dem Produkt von Messwert und Vergleichsgerade eher mal den Betrag oder das Quadrat der Differenz aufsummieren. Was am Ende am besten funktioniert kann man aber schwer vorraussagen wenn man den darunterliegenden Prozess nicht genau kennt. Probier die verschiedenen Methoden am besten einfach mit möglichst vielen Testdaten aus (musst du sowieso machen um die Schwelle festzulegen).
Angehängte Dateien:
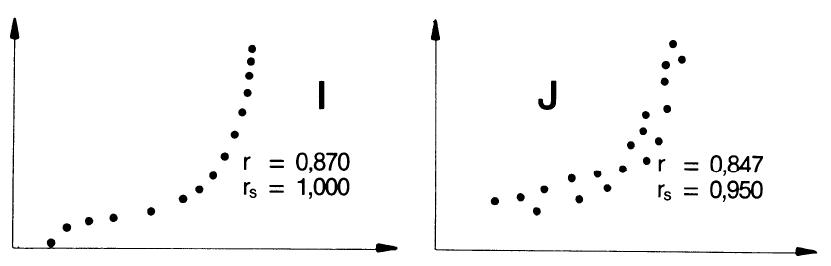
Hallo Jorge, den Korrelationskoeffizienten nach Spearman kann ich leider nicht anwenden, da auch Messwerte, die keine Gerade ergeben, einen Korrelationskoeffizienten von 1 haben (siehe Anhang). Gruß Filip
>>Das ist ein interativer Prozess dessen Genauigkeit von der Schrittweite >>abhängt, einen direkten Weg sofort zum Ergebnis wüsste ich nicht. Der große Gauß wußte den aber. Das ist kein iterativer Prozeß, das ist ne lineare Regression, wie schon gesagt wurde. Zu Fuß in Matlab geht das so: x=x(:);y=y(:); M=[x ones(length(x),1)]; coff=inv(M'*M)*M'*y; >>könnte man die Messkurve noch mit einem Polynom dritten >>Grades annähern und die Parameter für x und x³ vergleichen. (Wird aber >>sehr aufwändig.) >>Sobald sie aber Funktionen darstellen wird es schwieriger, dann musst Du >>eine Polynom-reihen entwickeln und dann geht es ins Eingemachte. Quatsch, ne quadratische oder kubische Interpolation geht genauso. Obige Zeile einfach ersetzen durch M=[x.*x x ones(length(x),1)]; oder M=[x.*x.*x x.*x x ones(length(x),1)]; >>Bei der Regression wird statt dessen der mittlere quadratische >>y-Abstand minimiert. Ich habe dfit.m angehängt, das minimiert die Summe der Quadrate der Lote der Punkte auf die Ausgleichsgerade. >>Unter Umständen reichen diese kleinen Differenzen in r ja schon aus um zu >>unterscheiden. zwischen 0.97 und 0.99 als Korrelationskoeffizient liegen doch Welten. Grenze bei 0.99 und fertig ist die Laube. Math rulez! Cheers Detlef
Hallo Detlef, schön das du hier noch ein bisschen Mathe reinbringst :-) Würde in matlab auch mit polyfit gehen. Hast du evtl. auch eine Idee, wie man zeigen kann, das eben noch Welten zwischen 0.97 und 0.99 liegen? Ich mache mir natürlich selbst auch meine Gedanken. Wenn ich es weiß, werde ich mich melden. Gruß Filip
Hallo Filip, ich weiss nicht genau was du rauskriegen möchtest (s.o. Andreas). Der Vorteil der Rechnung auf Ordinalniveau liegt beispielsweise darin, dass für die Irrtumswahrscheinlicheit mit exakten Wahrscheinlichkeiten aus Permutationen gerechnet werden kann. Das Verfahren ist teststärker. Es kommt dabei auf die inviduelle Anordnung der Messwerte an. Gerechnet wird die Anzahl der günstigen Anordnungen geteilt durch die Anzahl der möglichen Anordnungen. Man bekommt schnell eine hohe Granularität. Verfahren dieser Art welche man individuell auf das Datenmaterial anpassen kann sind völlig transparent und lässt die Leute, die berechtigt an Statisten zweifeln bei Begutachtungen ins Grübeln kommen. Für kurvilineare Zusammenhänge habe ich in der Vergangenheit über Legendre Polynome gerechnet. Aufgrund der Orthogonalität der L.P. kann man Modelle mit unterschiedlichem Grad durchrechnen und sich für "best fit" entscheiden. Bei der Irrtumswahrscheinlichkeit muss man das aber berücksichtigen. Jedes "Modell" ist ein Griff in die Urne (p nach Bonferroni). Man muss sich möglicherweise noch ein paar Gedanken mehr machen. Gut das Verfahren ist nicht ganz sauber (ex post). Bei deiner Rechnung über den Korrelationskoeffizienten habe ich noch keine Signifikanzrechnung (über den F-Test) entdecken können. Nackte Zahlen sagen nicht viel aus. Ich glaube zwar nicht, dass Dein Problem damit gelöst wird, möchte aber auf Überraschungen hinweisen. Beispielsweise können mäßige Korrelationen signifikant werden, wenn die Anzahl der Beobachtungen groß genug ist (logisch). Umgekehrt sind hohe Korrelationen bedeutungslos wenn nur wenige Messwerte zugrundeliegen. "Numerical Recipes in C" (Internet) versetzt dich innerhalb von kurzer Zeit in die Lage selbst Signifikanztests durchführen zu können. Beispielweise kann ein R-Quadrat (=Varianz) von 0,09 hochsignifikant sein, wenn es den Zusammenhang zwischen Rauchen und Lungenkrebs anhand von 10 MIO Bundesbürgern nachweist. Es interessiert mich trotzdem was du eingentlich machen willst. Gruss
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.