Hallo, derzeit bin ich dabei mich in die Welt des STM32F10X einzuarbeiten. Jedoch habe ich noch ein paar Fragen die ich gern erstmal kurz loswerden möchte, da ich da so ein paar Kleinigkeiten (die aber einen sehr großen Effekt haben könnten) nicht so ganz verstanden habe. Die STMs kommen ja mit einem Bootloader in einem eigenem Speicherbereich. 1.) Meine Frage ist daher, ist dieser Bereich vor überschreiben geschützt? Wenn nein, was muss gemacht werden um diesen Bereich vor einem versehentlichen überschreiben zu schützen, höchst wahrscheinlich im Linkerscript oder? 2.) Startup-Code und Linkerscript muss ich der Makefile angeben oder ist dieser schon in der stm-lib irgendwie schon integriert? (Siehe Bemerkung zum Punkt 4) (Zur Info, ich war nicht zu faul google zu bemühen nur habe ich nun schon zig verschiedene Linkerscripte u. Makefiles gesehen und kann leider nicht beurteilen ob diese nun für mich geeignet sind oder nicht. Soweit ich es mitbekommen habe liegt das an den STM-Lib Version bei einigen Versionen ist der Startup-Code in C-Realisiert worden - wenn ich mich irre bitte korrigieren) 3.) Hat jemand Erfahrungen mit dem Hitex Com-Stick gemacht? Wenn ja, eignet sich dieser zum Einstieg? Wenn nein, kann mir jemand ein Board empfehlen? Sollte jedoch auf jedenfall ein STM32F107CL sein wegen Ethernet & Co. 4.) Laut dem Hitex insiders guide gibt es zwei verschiedene STM Versionen die Acces-Line und die Performance line. Die Frage die sich mir da gerade stellt, beziehen sich diese Einschränkungen auf die STM-Lib oder sind das Einschränkungen seitens der Hardware? Wenn es Einschränkungen seitens der Hardware sind, woran erkenne ich den Unterschied ob es sich nun um die Acces-Line oder die Performance-Line handelt? Für eure Bemühungen danke ich im Voraus.
Hallo Björn, ich bin selber auch erst seit ein paar Wochen mit dem stm32 unterwegs. Zu 1) Bootloader Der Bootloader liegt im System Memory Bereich und nicht im User Flash Bereich. Application Node AN2606: The bootloader is stored in the internal boot ROM memory (system memory) of STM32 devices. It is programmed by ST during production. Somit ist der Bootloader im ROM und nicht im Flash somit nicht überschreibbar. Zu 2) Linkerscript Kann ich Dir nicht beantworten denn ich verwende derzeit den IAR KickStart bzw. hab auch etwas mit dem Atollic TrueStudio (verwendet den gcc) gespielt. Beide sind für DAUs "wie mich ;-)" nutzbar ohne am Linker und Makefile zu drehen. Welchen Toolchain verwendest Du ? Zu 3) Starterboard Ich hab mir zum Start das stm3210c-eval Board besorgt. Ja es kostet etwas Geld jedoch hatte es die Schnittstellen die ich brauchte zum loslegen. Alle TIM1 Motorcontroller-Pins rausgeführt und CAN Bus. USB, Ethernet und Touchpanel am µC wollte ich zum Test auch haben. Zu 4) stm32 linien Dieses Bild hilft evt. etwas http://www.st.com/mcu/inchtml-pages-stm32.html Wenn Du Ethernet braucht dann ist die stm32f107er Linie, die Connect Line, sinnvoll diese hat die Ethernet MAC Peripherie integriert und USB Host/OTG Peripherie. Die Performance Line (stm32f103er) hat große Variation in RAM/Flash und gute Peripherie jedoch hat diese kein Ethernet. USB ist vorhanden, jedoch kein USB Host/OTG. Die USB und der CAN Bus teilen sich den dedizierten Buffer RAM. Somit kann nicht zeitgleich CAN und USB verwendet werden sondern nur versetzt (CAN aus, USB ein und umgekehrt). zu Lib) Achtung die STM32F10xxx firmware library (FWLib) ist alt. Diese wurde durch die TM32F10xxx standard peripheral library (StdPeriph_Lib) ersetzt. [Ja der neue Name "Standard Peripherial Library" ist sehr sperrig] Der Vorteil dieser Lib ist dass von ARM Seite aus versucht wird ein Standard für den Zugriff auf Cortex µC Peripherie auszuarbeiten. Der Zugriff auf die Cortex eigene Peripherie ist standardisiert. Die CMSIS ist in der stm32 StdPeriph_Lib enthalten. stm32 StdPeriph_Lib: File STM32F10x_StdPeriph_Lib in http://www.st.com/mcu/familiesdocs-110.html Mehr zur CMSIS auf http://www.onarm.com/download/download395.asp Wichtige Dokus: Für STM32F10x_StdPeriph_Lib: stm32f10x_stdperiph_lib_um.chm Zum Programmieren: das stm32 Referencemanual "RM0008" Je nach Linie das Data- und Erratasheet: "STM32F105/107xx" Die Standard Peripherial Library versteckt im wesentlichen die Unterschiede der einzelnen Linien so weit es eben die Hardware zulässt. Meinen Code hab ich so geschrieben dass ich nur ein paar #defines vor dem Compilieren umstellen muss... USE_STDPERIPH_DRIVER und STM32F10X_HD USE_STDPERIPH_DRIVER und STM32F10X_CL + USE_STM3210C_EVAL Dann läuft es auf dem Kundenboard mit stm32f103 oder auf dem Testboard mit stm32f107. Bei eigenen Boards ist etwas Vorsicht beim Clock und beim PLL walten zu lassen, hier sind der 107er und der 103er etwas unterschiedlich. Wenn jedoch der Quartz passt dann deckt die Standard Peripherial Library die Unterschiede zu. Am 103er Kundenboard ist daher ein 8MHz Quartz, mit PLL läuft der Core intern auf 72MHz. Am 107er Testboard ist ein 25MHz Quartz auch bei diesem läuft intern die Core mit 72MHz über den PLL. In dieser Konstellation kann die Standard Peripherial Library die Unterschiede ausgleichen. Bei anderen Quartzes braucht es dann einen Eingriff in die Library. Siehe system_stm23f10x.c Zeile 64 4. The System clock configuration functions provided within this file assume that: - For Low and Medium density Value line devices an external 8MHz crystal is used to drive the System clock. - For Low, Medium and High density devices an external 8MHz crystal is used to drive the System clock. - For Connectivity line devices an external 25MHz crystal is used to drive the System clock. If you are using different crystal you have to adapt those functions accordingly. Beste Grüße, Lukas
super danke für deine Ausführliche Beschreibung. Was ich eigentlich als IDE benutzen wollte wäre eclipse + YAGARTO. Derzeit wühle ich mich durch einige Linkerscripts durch und versuche nun ein passendes Linkerscript daraus zu bilden. Ich persönlich habe mich nun doch für den STM32F103VCT6 entschieden. Für die spätere Ethernet-Verbindung benutz ich dann später ein Ethernet-PHY der eine SPI-Schnittstelle besitzt - zwar unschön das ich diesen Klimmzug mache aber dennoch ok. Als Eval Plattform werde ich nun den primer2 benutzen um die ersten Gehversuche zu unternehmen und bestimmte Dinge zu testen, um dann möglichst schnell auf das eigentliche Projekt umzuschwenken. Das mit der Lib, habe ich bisher auch noch nicht mitbekommen, hatte mir die std_periph lib von der Homepage runtergeladen - danke für den Tipp, also werde ich dann zusehen das ich die neuere Lib herunter lade und dann teste. Aber kannst du mir den unterschied zwischen dem USB-OTG und dem normalen USB kurz erklären? Denn der unterschied ist mir derzeit noch nicht ganz klar... mfG Björn
Hallo Björn hier stehts gut und kurz beschrieben: http://de.wikipedia.org/wiki/Universal_Serial_Bus#USB_On-the-go Ein 103er kann Client sein. Der 105er und 107er kann auch Host sein. Beste Grüße, Lukas
ähm eine Frage hätte ich da noch, höchst wahrscheinlich überseh ich das ständig in den Datenblättern gibt es irgendwo eine Auflistung der interrupt-Vectoren - das wäre recht schnike für unbenutzte Interrupts die ich dann im Linkerscript dann definiert zu der adress 0 springen lasse einige habe ich ja schon quasi entdeckt nur eine komplette Auflistung wäre schön ;).
in der Firmwarelib von ST findet sich irgendwo eine Datei stm32f10x_it.c IIRC. Da stehen sie drin. Alternativ findet sich im Startupcode üblicherweise die Tabelle. Gruß, Axel
hmm kk danke habs gefunden... wie ich schon geschrieben habe, anfänger fragen ;)
xD, naja schon dennoch brauch ich ab und zu ein paar stubser in die richtige Richtung aber darauf wäre ich ehrlich gesagt nicht gekommen im startupcode nachzuschauen weil die startupcodes die ich kenne sind recht cryptisch...
Hallo Bjoern, habe heute versucht mir den toolchain von codesourcery g++ lite mit eclipse einzurichten. Compilieren geht jedoch beim linkerscript und startupscrip komme ich nicht weiter. Hast Du eine funktionierende Kombination gefunden ? Kannst mir diese bitte verraten ? Danke, Lukas
also benutzt du bei eclipse ein makefile projekt oder benutzt du selbst geschriebene makefiles? Ich benutz den wizzard der hier im Forum diskutiert wurde. Dabei lasse ich mir von eclipse eine makefile erstellen, die dann für die compilierung benutzt wird. Dadurch kann man schön nachvollziehen was der compiler überhaupt macht. Bei mir fehlt derzeit noch die angabe des start-up codes und des linkerscripts in den compile-flags, nur habe ich bei eclipse noch nichts gefunden wo ich dann die Copmpilerflags setzen kann... Aber da es eine ganz normale makefile ist sollte das funktionieren. Es fehlt halt "nur" noch das -T linkerscrip.ld. Sofern du eine Lösung gefunden hast, wäre ich dir sehr dankbar, sobald ich dann was gefunden habe sage ich dir natürlich umgehend bescheid.
Angehängte Dateien:
-

eclipse_einstellung.jpg
58 KB
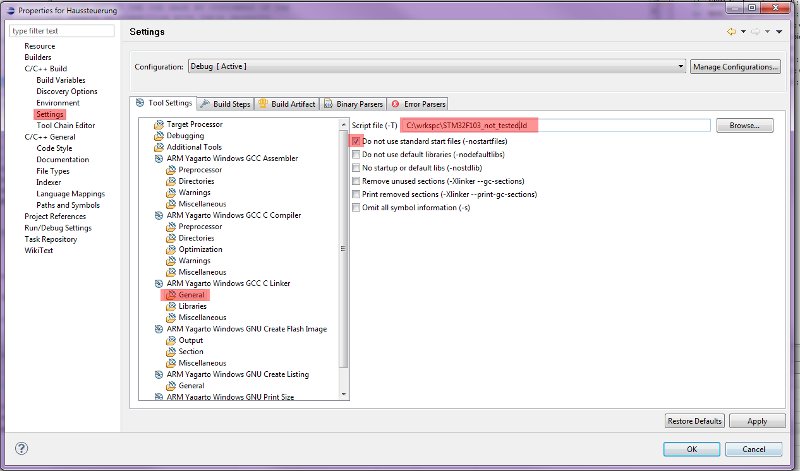
also wo ich das nun einstellen kann habe ich mittlerweile herausgefunden - augen auf beim eierlauf würde ich mal sagen ;) für den fall das ich dich richtig verstanden habe und du das linkerscript nicht eingebunden bekommst habe ich einfach mal ein Screenshot von den erforderlichen Einstellungen gemacht. Wenn ich dich nun falsch verstanden habe naja denn sag ich schonmal sorry - nur denke ich wird es bei dir anders aussehen wenn du das eclipse-plugin nicht hast. Du findest das plugin hier: http://www.sourceforge.net/projects/gnuarmeclipse und den entsprechenden Beitrag hier im Forum: Beitrag "GNUARM Eclipse Plugin"
Hallo Bjoern, ja das abgebildete Eclipse Plugin hab ich auch installiert und habs damit probiert. War mir fehlt ist ein für einen stm32f10x funktionierendes Linkerscript und einen dazu passenden Startup-Code. Die beiden aus der stm32 std. peripherie library für den attollic hab ich probiert, die werden auch genutzt jedoch passt das noch nicht, die _start passt dann aber der linker findet dann eine _init funktion nicht... Schade dass ST Mikroelectronic diese beiden Files für einen OpenSource gcc nicht bereitstellt. Muss mich wohl zuerst in die Syntax vom Linkerscript und Startupcode einlesen. Besten Dank, Lukas
Also an einem Linkerscript bin ich derzeit dabei eines zu schreiben. Jedoch für ein STM32F103VCT6 wenn du damit etwas anfangen könntest dann kann ich es gern hochladen - ist bisher aber nicht fertig und vor allem nicht getestet. Für dich gibt es schon Linkerscripts die für dein Evalboard passen müssten, und zwar in der std_peripheral lib im Rootverzeichnis musst du folgendem Pfad folgen: STM32F10x_StdPeriph_Lib_V3.3.0\Project\STM32F10x_StdPeriph_Template\True STUDIO\STM3210C-EVAL Die Linkerscripts haben dann den Dateinamen: stm32_flash.ld Aber vorsicht, nicht linkerscripts mit anderen Projekten Mischen der grund ist nämlich folgender einige setzen die unbenutzten Interrupt handler definiert zu null, so dass ein Reset durchgeführt. Andere machen dies gar nicht und wiederum andere machen das in irgendeiner *.h Datei. Wenn du anfängst verschiedene Beipiele zu mischen kann es sein das es sich dann beißt und dann ein definierter IRQ vielleicht doch einen reset zur Folge hat. Im angenehmsten Falle gibt es einen error vom Compiler ;)
also noch kurz was, zum Thema linkerscript gibts eine echt gute Seite, die das Thema Linkerscript sehr gut erklärt wie ich finde: http://sourceware.org/binutils/docs/ld/MEMORY.html#MEMORY
Kleine Anmerkung meinerseits... Ihr kennst sicher schon den Artikel STM32 Hier gibt es ein Demo-Projekt "Chan's-FAT..." von MT. Drin ist alles damit man mit OpenOCD / Eclipse usw. debuggen kann. Hier: http://www.mikrocontroller.net/articles/STM32#Demo-Projekte Mir hat es damals sehr geholfen.
ja den Artikel kenn ich, wie gesagt ich hangel mich derzeit durch einige Linkerscripts durch... aber es wird ;) Danke für den Tipp.
Hallo Markus, Hallo Bjoern, ich hab mich jetzt durch die Doku zum Linkerscript durchgearbeitet ... schwer verdauliche Kost. Zugleich versuche ich das Linkerscript und den Startupcode aus "ChaN's FAT-Module with STM32 SPI" mit Hilfe der Doku zu verstehen. Es sind viele Symbol-Namen bzw. Section-Namen enthalten welche vermutlich vom gcc Compiler (und den Libs) vorgegeben werden zb. .gnu.linkonce.t.* .init_array .ctors.* .ARM.exidx* usw. usw. Wo finde ich Infos welche dieser Namen zb. der codesourcery g++ lite (und seine libraries) verwendet ? Im Linkerscript wird in der Section .rodata zb. _preinit_array_start zwei mal zugewiesen. __preinit_array_start = .; und ein paar Zeilen weiter PROVIDE_HIDDEN (__preinit_array_start = .); Wieso erfolgt die Zuweisung 2x ? Benötigt es unterschiedliche Linkerscripts für reines "C" Programm und für "C++" Programme oder kann es immer dasselbe Linkerscript sein ? Kann mir wer bitte den Ablauf von SECTION { ... } >RAM AT>FLASH erklären. Das copy ist ja im startupcode drin das verwendet die Symbole von _sdata, _edata, _sidata. Mir ist nicht klar wann und wie im Linkerscript der Wechsel von FLASH zur RAM Adresse vollzogen wird. Besten Dank, Lukas
Hallo Markus, Hallo Bjoern, ich hab mich jetzt durch die Doku zum Linkerscript durchgearbeitet ... schwer verdauliche Kost. Zugleich versuche ich das Linkerscript und den Startupcode aus "ChaN's FAT-Module with STM32 SPI" mit Hilfe der Doku zu verstehen. Es sind viele Symbol-Namen bzw. Section-Namen enthalten welche vermutlich vom gcc Compiler (und den Libs) vorgegeben werden zb. .gnu.linkonce.t.* .init_array .ctors.* .ARM.exidx* usw. usw. Wo finde ich Infos welche dieser Namen zb. der codesourcery g++ lite (und seine libraries) verwendet ? Im Linkerscript wird in der Section .rodata zb. _preinit_array_start zwei mal zugewiesen. __preinit_array_start = .; und ein paar Zeilen weiter PROVIDE_HIDDEN (__preinit_array_start = .); Wieso erfolgt die Zuweisung 2x ? Benötigt es unterschiedliche Linkerscripts für reines "C" Programm und für "C++" Programme oder kann es immer dasselbe Linkerscript sein ? Kann mir wer bitte den Ablauf von SECTION { ... } >RAM AT>FLASH erklären. Das copy ist ja im startupcode drin das verwendet die Symbole von _sdata, _edata, _sidata. Mir ist nicht klar wann und wie im Linkerscript der Wechsel von FLASH zur RAM Adresse vollzogen wird. Besten Dank, Lukas
>Kann mir wer bitte den Ablauf von SECTION { ... } >RAM AT>FLASH >erklären. Das ld.pdf in arm-2010q1/share/doc/arm-arm-none-eabi/pdf/? Section 3.6.1 HTH.
Danke, ich hab gestern bei Kapitel 3.6.8 den Lesestoff auf die Seite gelegt und auf 3.6.8.2 ist erklärt wie die Loadadresse LMA im Flash und Virtualadresse VMA im RAM zustande kommen. Danke für den Hinweis auf die PDFs im share Ordner. Diese hab ich beim Intallieren gar nicht mitbekommen. Im getting started pdf steht im Kapitel 5 wie das zusammenhängt mit dem CS3 (Codesourcery Common Startup Code Serquence) Mercy Lukas
Also um deine Frage zu beantworten für C und C++, du kannst alles in einem Linkerscript unterbekommen dafür gibt es die sectionen .ctors und .dtors die ins RAM gehören also als Beispiel: PS: Ein ... bedeutet hier das ich bestimmte Bereiche ausgelassen habe, es sich also nicht um den location pointer handelt.
1 | MEMORY |
2 | {
|
3 | RAM (rw) : ORIGIN = 0x200..., LENGTH = 64K |
4 | } |
5 | |
6 | ... |
7 | |
8 | SECTIONS{
|
9 | . = 0x200... |
10 | ... |
11 | |
12 | .ctors : |
13 | {
|
14 | PROVIDE(__ctors_start__ = .); |
15 | KEEP(*(SORT(.ctors.*))) |
16 | KEEP(*(.ctors)) |
17 | PROVIDE(__ctors_end__ = .); |
18 | } >RAM |
19 | .dtors : |
20 | {
|
21 | PROVIDE(__dtors_start__ = .); |
22 | KEEP(*(SORT(.dtors.*))) |
23 | KEEP(*(.dtors)) |
24 | PROVIDE(__dtors_end__ = .); |
25 | } >RAM |
26 | |
27 | ... |
Ich nutze so die LD Datei: - Bootloader anderer Speicherbereich als die App. - In der App muss ich kein _attribute_ angeben, die kennt der Compiller schon. Man sieht auch in der MAP Datei (Compillerschalter des Linkers) was zu welchem Block gelinkt wurde.
1 | /*SEARCH_DIR(C:/WinARM/CodeSourcery/lib/gcc/arm-none-eabi/4.2.3/thumb);*/ |
2 | |
3 | MEMORY |
4 | {
|
5 | ramboot (rwx) : ORIGIN = 0x20000000, LENGTH = 0x200 |
6 | ram (rwx) : ORIGIN = 0x20000200, LENGTH = 0x4800 |
7 | romboot (rx) : ORIGIN = 0x00000000, LENGTH = 8K |
8 | rom (rx) : ORIGIN = 0x00002000, LENGTH = 119K |
9 | } |
10 | SECTIONS |
11 | {
|
12 | . = 0x0; /* From 0x00000000 */ |
13 | .vectors : {
|
14 | *(.vectors) /* Interrupt Vector */ |
15 | *(.boot) /* Boot-ROM Code */ |
16 | *(.boottbl) /* Boot-ROM Code-Tabellen (Const Werte) */ |
17 | } >romboot |
18 | . = 0x2000; /* From 0x00001800 */ |
19 | .text : {
|
20 | *(.appvectors) /* Interrupt der Applikation */ |
21 | *(.text) /* Program code */ |
22 | *(.rodata) /* Read only data */ |
23 | *(.rodata.str1.4) |
24 | _etext = .; |
25 | } >rom |
26 | |
27 | . = 0x20000000; /* From 0x20000000 */ |
28 | .bootdata : {
|
29 | *(.bootdata) /* Data memory bootloader */ |
30 | } >ramboot /* Keine Initialisierung mit 0 */ |
31 | |
32 | . = 0x20000200; /* From 0x20000200 */ |
33 | .data : {
|
34 | _data = .; |
35 | *(.data) /* Data memory */ |
36 | *(.eh_frame) |
37 | _edata = .; |
38 | } >ram AT > rom |
39 | |
40 | .bss : {
|
41 | _bss = .; |
42 | *(.bss) /* Zero-filled run time allocate data memory */ |
43 | _ebss = .; |
44 | } >ram AT > rom |
45 | } |
46 | /*========== end of file ==========*/ |
Im Code muss ich dann für alle Routinen und Variablen den Bereich für den Bootloader angeben:
1 | //*******************************************************************************
|
2 | // Definition Flash-Bereich für Programm
|
3 | #define __boot __attribute__ ((section(".boot")))
|
4 | // Definition Flash-Bereich für Flash-Daten (nach Programm)
|
5 | #define __boottbl __attribute__ ((section(".boottbl")))
|
6 | // Definition RAM-Bereich
|
7 | #define __bootdata __attribute__ ((section(".bootdata")))
|
8 | |
9 | u8 __bootdata FW_ForceHW; |
10 | |
11 | void __boot FW_Main(void) |
12 | {}
|
Markus danke für dein Script, aber was ich grad nicht so recht verstehe ist, warum der Bootloader in der definition mit drin ist... ich dachte der wird über den Boot-Pins konfiguriert oder versehe ich mich da? Oder ist das ein eigener Bootloader wenn ja, ich dachte der wird ab Werk mitgeliefert und ich muss mir da keine sorgen drum machen oder doch?
Ich hab mir einen eigenen Bootloader geschrieben. Der ist sogar im gleichen Quellcode untergebracht. Damit sich die Speicherbereiche nicht überlappen musste ich das aufteilen. Denn wenn mein Bootloader aktiv ist, kann der den gesammten Flash (ausser der des Bootloader-Bereichs) löschen und der Bootloader darf deshalb daraus keinen Code anspringen. Ich habe einen für USB und einen für RS232 geschrieben. Ich könnte den auch auf CAN oder andere Schnittstellen umbiegen. War eine nette Erfahrung. Der USB Bootloader war ziemlich kniffelig, denn ich musste aus der APP (über USB Befehl) in den Bootloader springen und der musste die USB-Initialisierung aus der App übernehmen. Dazu kam, dass ich den gesammten USB-Code aus der FW-Lib umkopieren musste, so dass der 2x vorhanden war, einmal im Bootloader-Bereich und einmal im App-Bereich. Denn der App-Bereich darf auch keinen Code vom Bootloader anspringen. Also ein Quellcode mit zwei Applikationen drin...
Also der Bootloader selbst hört sich sehr interessant an, via CAN brauch ich eigentlich nicht, sofern ich darf würde ich mir aber gern später ein paar Anregungen für meine spätere RTOS portierung. Aber je mehr ich darüber nachdenke, ein selbst gestrickter Bootloader macht doch mehr sinn als ich zuerst dachte fällt dann bei dir das umgestecke der Bootjumper dann weg?
Alles fällt weg. Die PC-Software (selbst geschrieben) ist ja über USB mit dem Board verbunden. Da macht es auch Sinn ein FW-Update über das gleiche Programm zu machen. Mann kann einem Kunde ja schlecht sagen er soll daoch bitte das Gerät aufschrauben, Jumper setzen und ein Programm von einem anderen Hersteller benutzen. Andere Boards werden dann nur über den vorhandenen RS232-Stecker geupdatet. Dazu veranlasst dann meie PC-Update-Software einen Sprung in den Bootloader, mit Versionsanzeige von Applikation und Bootloader.
Hmm also interesse habe ich schon an dem Bootloader, also wenn das für dich ok wäre würde ich den gern für meine Haussteuerung / RTOS verwenden, aber auch nur wenn es für dich ok wäre. mfG
Ich hab ein PN geschrieben. Als OS hab ich keines verwendet, ich mache die Programmierung immer so, dass alle Programmteile aus dem Main-Loop nacheinander aufgerufen werden. So werden dann die Tasks für IIC, Seriell, CAN, AD-Wandler uvm. aufgerufen. Die einzelnen Tasks haben jeweils eine eigenständige Schrittkette für den korrekten Ablauf. Sobald ein Task irgend wie warten muss, dann wird sofort raus gesprungen, so dass die CPU über den Main-Loop die anderen Tasks bedienen kann. Wenn der wieder in den wartenden Task kommt, dann springt er an die Position der Schrittkette und sieht ob das Warten zu Ende ist und weiter gemacht werden kann oder nicht. Der Vorteil: - Kein Code-Overhead durch Betriebssystem - Man weiß genau was wie funktioniert und wann welcher Task dran kommt - Alle Proßesse laufen Asynchron zueinander, also wenn ein anderer Task eine IIC-Abfrage startet, so wird der "Warten" (raus springen) bis der IIC-Task die Meldung bringt "Daten OK". - Ein zyklischer Aufruf kann auch selbst gemacht werden, indem z.B. das Sekunden-Timer-Puls-Bit abgefragt wird (das auch für genau einen Main-Loop-Task gesetzt ist und alle Tasks bekommen den mit) - Ich hab einen Zyklus-Zahler drin, der die Main-Loop Zyklen je Sekunde zählt, wenn der abrupt viel weniger Zyklen macht, dann weiß ich, dass ich eine Ausführungs-Bremse eingebaut habe. - Wenn ein Task "Hängt" weil eine Bedingung niemals erfüllt wird, so laufen alle anderen garantiert weiter. - Der Watch-Dog braucht auch nur im Main-Loop bedient werden und wenn der anschlägt weiß man genau, dass das System buggy ist. Einen Nachteil meiner Struktur hab ich bisher nicht gefunden, ausser dass man etwas mehr Gehirnschmalz für die "No-Wait" Programmierung benötigt.
gut n Endlosloop bekommst du schon hin ^^ sobald du nur eine for, dowhile, while schleife drin hast (falsche Bedingungen, HW-Defekt oä. vorrausgesetzt) Bei einem richtigen scheduler hast du den Vorteil das du definitiv keinen Hänger hinbekommst, anders sieht es aber bei tasks die sich selbst unterbrechen können zB. prioritäten gesteuert sofern keine deadlock erkennung eingebastelt wurde. Natürlich hat sowas seinen Preis, aber dafür wird man damit belohnt das man dann wieder weniger Gehirnschmalz rein setzen muss nachdem ein Scheduler u. das Framework einwandfrei funktioniert ^^ Aber ok sind zwei Ansichten und ich denke mal beide Methoden, haben ihre vor und nachteile, kommt halt auf den Anwendungsfall an.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.