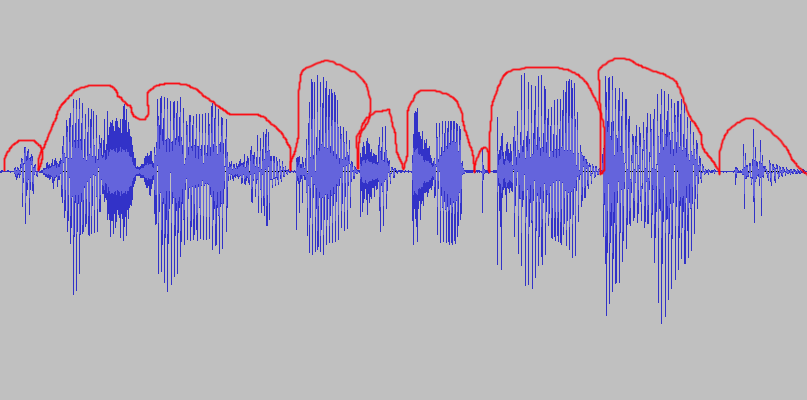
Ich habe eine Audiodatei eines Sprechers mit librosa eingelesen. Ich will nun diese Audiodatei automatisch von Atemgeräuschen befreien. Als ersten Schritt möchte ich die Audiodateien nach angehängtem Bild segmentieren. Immer dann, wenn die annähernd gezeichnete rote Linie die Nullinie schneidet, soll eine Schnittmarke existieren. Welche Methode ist hier robust?
Angehängte Dateien:
-

csdf.png
24 KB
Google mal nach voice activity detection python Gibt ein paar github Projekte dafür VG Roland
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.