{kind=link}
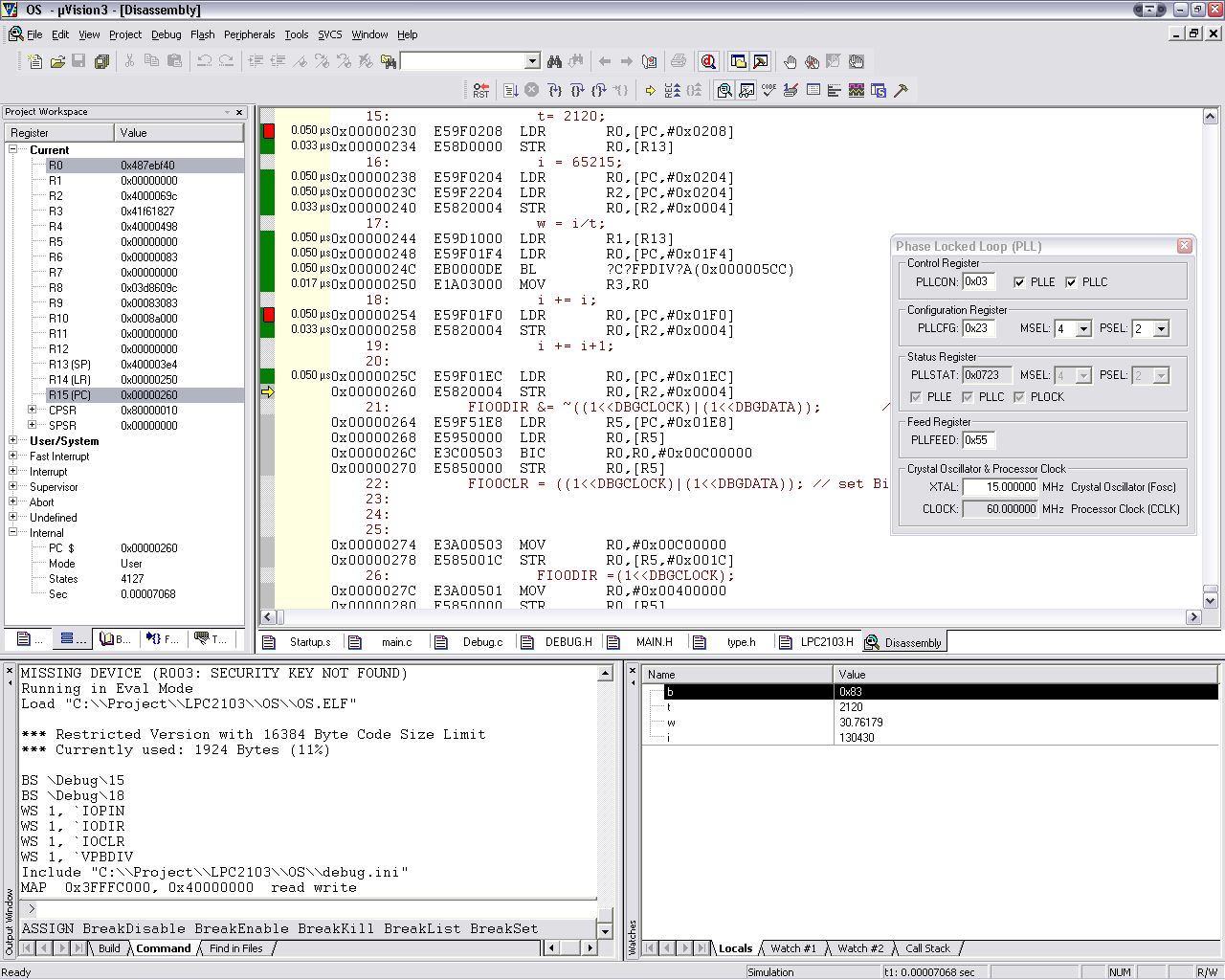
Hallo, ich habe da eine Verständnisfrage. Laut der Philips Homepage steht: http://www.philips.semiconductors.com/news/infocus/lpc2103/ "70 MHz operation (63 MIPS) from both on-chip Flash and SRAM" Wenn ich aber jetzt mal in Keil die Befehlsausführungszeiten betrachte, erreiche ich weniger als die Hälfte. Habe den Controller so Konfiguriert (15MHzQuarz, PLLx4/PLLDIVx2(M=4->Wert 3,P=2->Wert 1;). => CCLK=60MHz Das Bit Toggeln läuft in der realen Hardware mit 33ns->17,5MHz. Von daher würde ich mal behaupten, dass der Prozessor richtig konfiguriert ist. Die Assembler-Befehle liegen aber zwischen 17ns und 50ns, wobei die 17ns (würden zwar passen) fast nicht vorkommen. Rein gefühlt würde ich die mittlere Befehlsausführungszeit wohl ehr leicht oberhalt von 33ns ansetzen (siehe Bild). Also schaft mein LPC2103 20-30MIPS bei CCLK von 60MHz. Habe ich noch was falsch konfiguriert, oder sind die 63MIPS@70MHz Wunschdenken von Philips (=maximale Geschwindigkeit, wenn man nur 1 Cycle Befehle verwendet, was in der Praxis ja nicht vorkommt)? Danke, Bernd
Angehängte Dateien:
-

LPC2103_speed.gif
66 KB
Herstellerangaben zu MIPS sind ungefähr so wie die Geschwindigkeit von Autos gemessen im freien Fall. Nur zu gebrauchen als Wert der garantiert nie überschritten aber in realen Programmen kaum je erreicht wird. I/O-Pins lassen sich nur per Store-Befehl ansprechen, und der braucht halt etwas länger als die Addition zweiter Register.
"sind die 63MIPS@70MHz Wunschdenken von Philips (=maximale Geschwindigkeit, wenn man nur 1 Cycle Befehle verwendet, was in der Praxis ja nicht vorkommt)?" Genau so isses. Ist aber allgemein so, nicht nur bei Philips. Peter
Philips kann man sogar noch zu gute halten, dass man MIPS auch als die Zahl Instruktionen, die maximal pro Sekunde gefetched werden können, auslegen kann. Das wird durch das MAM und die breite Anbindung des Flashes ermöglicht. Anderen Designs wie Atmel's SAM7 sind da bereits aufgrund des Flash Interfaces niedrigere Grenzen gesetzt. Gruss, Dominic
Also wenn ich mir einen dsPIC30 (30MIPS) oder PIC18 (10MIPS) ansehe, arbeiten diese Prozessoren wirklich 95% aller Befehle in einem Zyklus ab. Ich werden mir mal einen kleinen Benchmark zusammenbauen, um einige Funktionen auf verschiedenen MCUs (PIC18, dsPIC, AVR, ARM) zu testen. Meine gestrigen Versuche sahen aber so aus, das der 16Bit dsPIC schneller war als der 32Bit LPC ARM bei halber MIPS Zahl. Gibt es den einen handlichen (vom Gehäuse her noch selber ätzen und Löten) Mikrocontroller, der so ungefähr die 4fache dsPIC30@30MIPS Performance bietet? Kann ruhig 16Bit sein, wobei 32 Bit natürlich schöner wären. Bekommt man eigentlich schon irgendwo die 40MIPS dsPIC33/PIC24? Die sollten doch zumindest etwas schneller sein.
>Also wenn ich mir einen dsPIC30 (30MIPS) oder PIC18 (10MIPS) ansehe, >arbeiten diese Prozessoren wirklich 95% aller Befehle in einem Zyklus >ab. und was hilft es mir ,wenn ich gerade die restlichen 5% der Befehle brauche ,die dann im Schnitt 4 Zyklen andauern??
@Bernd, ohne zu wissen, wobei der dsPIC schneller war, kann man überhaupt nichts dazu sagen. Besonders unter C hängt es mehr von der Qualität des Compilers ab, wer schneller ist. Und was der GCC so für den LPC produziert, sah mir ziemlich suboptimal aus, da bestehen noch massig Reserven. Und bei den neueren LPCs haben sie wohl nochmal die Portbitschubserzeit und das SPI verbessert. Da bestand ja wirklich erheblicher Handlungsbedarf (8051 war sogar schneller). Peter
Das hängt ganz davon ab, was du mit den 30MIPS deines dsPICs anstellst. Der ARM ist sicher überlegen, wenn es um algorithmische Aufgaben geht, oder wenn ein grosses RAM gefragt ist. Wenn du allerdings nur Port Pins mit möglichst hoher Geschwindigkeit toggeln willst ist er womöglich nicht die richtige Wahl. Der ARM7 führt viele Befehle in einem Takt aus, allerdings keine Loads (3 Takte) und keine Stores (2 Takte). Ausserdem brauchen Multipliationen zwischen 2 und 7 Takten, abhängig vom Befehl (MUL, MLA, ...) und den Operanden ('kleine' Operanden sind schneller). Dein Benchmark sollte also möglichst die Funktionen testen, die du häufig benötigst. Ausserdem ist es wichtig, das MAM Modul des LPCs richtig zu initialisieren. Gruss, Dominic
Also, hier habe ich einen kleinen Benchmarktest. (Siehe Anhang) Ich habe zu jedem Programmteil die Ausführungszeit (laut Simulator) oberhalb des Programmteiles eingetragen. Für dsPIC30 und PIC24 habe ich MPLab und den C30 (demo) verwendet. Für AVR (AVR-Studio und WinAVR). Für LPC2103 (µVision und CARM von Keil (demo)). Ich muss zugeben: Auch wenn der erste Eindruck anders war, der ARM hat bis auf einen Test alle mit Abstand gewonnen, selbst bei speicherintensiven Schleifen. Nur bei 16Bit Divisionen war der dsPIC30/PIC24 schneller. Den PIC18 konnte ich auf die schnelle nicht testen, aber er dürfte bei 10MIPS so ca. 30% länger als der ATmega@16MIPS brauchen. Das heißt für mich, dass ich mich ab jetzt nur noch auf den LPC21xx konzentrieren werde. Wenn jemand Lust hat, kann er ja an meinen Benchmarktest noch den ein oder anderen Test oder die ein oder andere CPU anhängen. Dann könnte man mal herausfinden, wie leistungsfähig die MCUs wirklich sind. Grüße, Bernd
einen vergleich der performance verschiedener µController findet sich hier: http://www.freertos.org/PC/index.html gruss gerhard
Demnach schneidet der LPC2106 auch gut ab. Habe festgestellt, dass sich der LPC2103 offensichtlich auch noch mit CCLK=PLL=120MHz betreiben lässt. Muss mal schauen, ob da noch alles stabiel läuft :-)
@viele LPC2103 bei 120 MHz, nicht stabil!! MIPS definition. Da gibts es einen benchmark der so heisst (Dhrystone MIPS). Witzigerweisse kann die MIPS Zahl deutlich hoeher sein als die Anzahl der ausgefuehrten Befehle !@$! ;-) Bei ARM7 gelten die folgenden Definitionen angenommen keinerlei Wait-States: 0,9 Mips / MHz, daher kommen die 63 MIPS. Zu Thema durchschnittliche Taktzyklen pro Befehl, die Messungen waren recht gut, es sind so im Bereich 1,7 bis 1,9 CPI (Clocks Per Instruction). Zum Thema division schneller im dsPIC, das wundert mich nicht, der ARM7 hat keinen DIV befehl im assembler und muss die ganze Sache in einer SW-Library abarbeiten. Mich wuerden mal interessieren wieviel teurer der dsPIC waere im Vergleich zum LPC2103 obwohl er in den Test deutlich in Performance geschlagen wurde? Robert
@Bernd, hab mir jetzt erst die Zeit genommen deinen Benchmark und die Ergebnisse anzuschauen. Meine Folgerung kann nur sein, dass 40 PIC-MIPS ungefaehr halb so viel Performance entsprechen wie 60 LPC2103-MIPS. Wenn du von 60 MIPS sprichst meinst du damit 60 MHz (denn das sind laut Berechnung lediglich 54 MIPS) oder laeuft der LPC mit 70 MHz? Nur aus Neugierde, denn es gibt ein Vergelichspapier von Microchip das behauptet, der PIC24 und / oder DSPic waeren bei 30 MHz schneller als der LPC bei 60 MHz. Vielleicht wurde da einfach was verdreht, vielleicht ist der LPC ja mit 30 MHz schneller als der DSPic mit 60 MHz. OOpps, haette fast vergessen den gibts ja nur bis 40 MHz und dummerweise kostet bereits der 20 MHz chip mit 20 I/O Leitungen fast doppelt soviel wie der LPC2103 mit 32 I/O Leitungen. Genug gelaestert, schoenes Wochenende! Robert
@Robert: Ich hatte mich nach dem Keil Simulator gerichtet, und bei dem ist der kürzeste Befehl bei 60MHz (LPC2103) 0,017µs. Daraus habe ich auf 60MIPS geschlossen. Die Zeiten für den LPC beziehen sich also auf ECHTE 60MIPS und nicht auf 60MHz!?!?! Ich habe aber bei der Gelegenheit noch etwas weiter experientiert. Und ich muss sagen, in Punkto Performance sind alle C Compiler was für die "Tonne". Hier mal ein paar Zeiten für das Füllen/Löschen von 256 einzelnen Bytes in Assembler: Hier noch einmal die Zeiten in C: // fill 256 single bytes // dsPIC@30MIPS = 128.26µs // ATMEGA@16MIPS = 657µs // LPC2103@60MIPS = 46.93µs pa8 = a; for (i=0; i<256; i++) { *pa8++=0x11; } Und hier die Zeiten in Assembler: dsPIC30@30MIPS 8,63µs (das Füllen von 128x16Bit dauert 4,3µs): mov #0x800,w7 mov #0xFF, w6 repeat #255 mov.b W6, [W7++] Und PIC10@10MHz 103µs: LFSR 0, 0x100; pointer 0 clrf 0; GPR 0 = 8 bit counter movlw 0x55 loop: movwf POSTINC0 decfsz 0; General Purpose Register 0 bra loop Damit wäre der 60MIPS LPC2103 in C doppelt so schnell wie ein 10MIPS PIC18 in Assembler. Gegenüber dem dsPIC30@30MIPS in Assembler braucht der LPC bei doppelter MIPS Zahl die 5,4-fache Zeit :-( Zugegeben, der Vergleich ist nicht ganz fair, aber mit ARM Assembler kenne ich mich noch nicht gut genug aus. Vielleicht kann das ja mal jemand anders für mich übernehmen. Immerhin können die PICs in einem einzigen Zyklus jede beliebige Speicherzelle incrementieren. Wie lange braucht dafür ein ARM? Andererseits hat ein ARM 13x 32Bit Register. Ich denke die vielen Prozessorregister sind die Stärke des ARM, nicht so sehr seine MIPS Zahl. Ich denke die Stärken der ARM Prozessoren liegen im C Bereich. In reinem Assembler könnte der Vergleich völlig anders ausfallen. Grüße und schönen Wochenende, Bernd
Dhrystone oder Speicher füllen scheint mir als Benchmark ziemlich sinnlos und wenig aussagekräftig. Mess doch lieber mal welcher Prozessor einen FIR Filter schneller berechnet oder sowas in der Richtung.
@Andreas: Mit DSP habe ich nicht fiel am Hut. Wäre aber sicher auch interessant. Aus dem Musikbereich weiß ich, dass noch vor 10Jahren alles auf DSPs geschwört hat. Heute gibt es Tonstudios, die alleine von der Rechenleisung moderner PCs leben. Pro MIPS erreicht man bei DSPs bestimmt mehr FLOPS, aber auf das Endergebnis kommt es schließlich an. @All: Hier noch mein Versuch den letzten Test in ARM Assemnbler zu realisieren: LPC@60MIPS 25,6µs. mov r0, #0x3FFFFFFF ; RAM address mov r1, #0x55; fill value mov r2, #0x100; loop: strb r1, [R0,#0x1]! subs r2, r2, #1 bne loop Damit wäre der LPC2103 vier mal so schnell wie der PIC10. Gegenüber dem dsPIC aber immer noch 3x langsamer. Hier sind die DSP Befehle wie repeat doch zumindest in einigen Bereichen deutlich leistungsfähiger.
Wenn schon handoptimieren, dann bitte richtig ;-).
ldr r0, =0x55555555
mov r1, r0
mov r2, r0
mov r3, r0
mov r4, r0
mov r5, r0
mov r6, r0
mov r7, r0
ldr r8, =ram_address
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
stmia r8!, {r0,r1,r2,r3,r4,r5,r6,r7}
Macht ~93 Takte, also ca 1,5µsec.
Nicht dass dieser Vergleich irgendeinen Sinn hätte...
"die Stärken der ARM Prozessoren liegen im C Bereich"
Damit liegst du richtig. Erst recht C++.
"Heute gibt es Tonstudios, die alleine von der Rechenleisung moderner PCs leben." Lass es ein paar Dutzend Tonstudios pro Lösung sein. Macht viel Entwicklungsaufwand umgelegt auf sehr kleine Stückzahl. Ergebnis: Kosten der Hardwarebasis sind völlig irrelevant, dafür ist die Entwicklung der Software entscheidend. Und die ist auf dem PC einfacher. Wenn das Produkt jedoch beispielsweise ein Kabelmodem werden soll, mit 6-7-stelliger Stückzahl, dann sieht die Rechung etwas anders aus. Kein Mensch kauft dir dafür einen angepassten PC ab.
@A.K.: Und wo ist die Schleife und der Single Byte Zugriff? O.K. Wir wissen jetzt alle, dass der LPC tendenziel Leistungsfähiger ist. Im Übrigen ging es mir ja nur darum, dass ich endlich die Assemblerprogrammierung aufgeben möchte und auch auf Mikrocontrollern eine höhere Spreche verwenden möchte. Und da ich keine Massenprodukte entwickle sonder nur zu Hause ein bischen bastelle, ist für mich nicht der Preis des Controllers im Vordergrund (zumindest nicht bei ein paar Euro unterschied), sondern die Einfachheit der Programmierung von größter Bedeutung. Langsammer Prozessor -> viel Optimierung erforderlich -> viel Zeit erforderlich Schneller Prozessor -> weniger Optimierung erforderlich für gleiche Performance -> weniger Aufwand bei gleichem Endergebnis und weiteres Potenzial bei Bedarf. Außerdem möchte ich mich auch nicht ständig in neue Controller einarbeiten müssen, nur weil der bisher verwendete gerade nicht mehr reicht. Dann lieber immer gleich eine Nummer größer. Und mit 7x7mm ist der LPC ja doch noch recht handlich. :-) Grüße, Bernd
Ich habe mir meine alte benchmark.c gerade noch mal angesehen. Mit dem, was ich bisher dazugelernt habe ist die Datei so nicht aussagekräftig. Außerder habe ich einen Fehler gefunden. So sollte es eigentlich richtig sein:
1 | asm volatile ("":::"memory");\ |
2 | // copy 64 32bit words
|
3 | // PIC18@10MIPS =
|
4 | // PIC24@40MIPS = 40.25?s
|
5 | // dsPIC@30MIPS = 53.66?s
|
6 | // ATMEGA@16MIPS = 274?s
|
7 | // Z16F@20MIPS = 23.0?s
|
8 | // LPC2103@60MIPS = 17.10?s
|
9 | pa32 = (long*)a; |
10 | pb32 = (long*)b; |
11 | for (i=0; i<64; i++) { |
12 | *pa32++=*pb32++; |
13 | }
|
Vielleicht ist die Idee einen MCU Benchmark zu erstellen garnicht so
schlecht, aber es müssen viele Dinge beachtet werden, die Ich darmals
vielleicht übersehen habe.
1. Generell sollte der Verwendete Compiler (Version) angegeben werden.
2. Dann sollte sichergestellt werden, daß immer die beste Optimierung
für Geschwindigkeit gewählt wird.
3. Da der C32 teilweise sehr "wild" optimiert, sind Memory Barriers (asm
volatile ("":::"memory"); // in GCC) nützlich, damit man auch wirklich
sicherstellt, daß der gesammte Codeblock auch an einem Stück ausgeführt
wird.
4. Dadurch daß man alle Variablen volatile deklariert, verhindert man
zwar, daß der Compiler die komplette Berechnung wegoptimiert, allerdings
geht hierbei auch die Stärke von CPUs verloren, welche sehr viele CPU
Register haben und eigentlich weniger Speicherzugriffe brauchen, als
andere, wenn eben nicht alles volatile ist.
5. Vielleicht währe es aussagekräftiger, wenn die einzelnen Codeblöcke
etwas umfangreicher währen und in sich bereits einen Mix aus
verschiedenen Operationen beinhalten. Also ein Benchmark für eine
komplexe float Berechnung, eine andere, die ein int Array verarbeitet,
eine Routine die Strings aufbereitet (String zusammenbauen, in den
mehrere Werte float, int ... einzuarbeiten sind) und so. Es dürfen
allerdings nur Routinen verwendet werden, die auf reinstem C basieren
oder auf absoluten Standardbibliotheken, da sonst der Vergleich
unmöglich würde.
Noch ein Vorschlag. Der Focus auf Division in den meisten Teilen dieses Benchmarks laesst den LPC2103 eigentlich echt schlecht aussehen, der ARM7 hat naemlich keinen DIV Befehl. Waere interessant einen STM32 oder LM3xx mit Cortex M3 auch zu listen, die haben einen DIV Befehl. Da ist schon der Simulator von Keil MDK sehr aufschlussreich und hinreichend genau. Robert
Währe interessant, aber erst mal bräuchte man einen Benchmark Test,
welcher auch in der Lage ist eine halbwegs verlässliche Aussage über die
Leistung in dem ein oder anderen Bereich zu machen. Und wie oben schon
erwähnt, glaube ich nicht, daß meine Benchmark.c dazu optimal ist.
Es währe erst einmal zu Klären, was man denn überhaupt vergleichen will.
So Konstruktionen wie "asm volatile ("":::"memory");" sind GCC
spezifisch und müßten irgendwie auf andere Compiler übertragen werden.
@Bernd, so einen Benchmark gibt es sogar, meiner Meinung nach. Schau mal spasshalber rein bei http://www.eembc.org/home.php . Ich war dort ca 10 Jahr in dem Konsortium, allerdings ist der Fokus ganz eindeutig auf high-end und die Benchmark Sourcen werden nicht veroeffentlicht. Auf einem 8-bit Rechner wuerden die allermeisten Benchmarks gar nicht funktionieren wegen Speicherbedarfes. Da kommen aber solche kleinen Vergleiche wie Dein Code hinzu, wie lange dauert ein MUL, DIV, Daten verschieben, Daten mit logischen Operatoren verknuepfen, die Daten variieren von 1/8/16/32/(64?) bit und float. Das ganze in einer Schleife abarbeiten und schon hat mein einen low-end Benchmark, der dann von allen zerissen wird, die dabei nicht ihre eigenen Anwendungen wiederfinden ;-)) Gruss aus California, Robert bei Sonnenschein und 15C, ein wunderschoener Herbst- oder Fruehlingstag
Na ja, theoretisch kann man ja jeden Programmschnippsel als Benchmark für irgendetwas verwenden. Wichtig wäre nur, daß die Rahmenbedingungen stimmen. Im Endeffekt wäre es ja kein reiner CPU Benchmark, sonder immer ein Benchmark für einen Mix aus CPU und Compiler. Was nützt die beste MCU, wenn der Compiler nicht optimal arbeitet. Andersherum mag ein top Compiler einer eigentlich schlechteren MCU zum Sieg verhelfen. Wie oben schon erwähnt, verhindern zu viele "volatile"s, daß der Compiler optimalen Code erzeugt. Andererseits, läßt man volatile weg, kann es passieren, daß der ein oder andere Compiler ganze Berechnungen wegläßt, da die Ergebnisse ja nirgends mehr gebraucht werden. Man müßte also sicherstellen, daß man dem Compiler alle nur erdenklichen Freiheiten für die Optimierung unter realen Bedingungen läßt und andererseits darauf achten, daß alle Rechenergebnisse am Ende auch tatsächlich irgendwo benutzt werden, so daß der Compiler sie nicht wegoptimieren kann. Problematisch ist es auch mehrere Benchmarks in einem Program zusammenzufassen, da z.B. der C32 die Befehlsanordnung kräftig durcheinanderrüttelt. Daher auch die Idee mit der Memory Barrier, damit zusammen bleibt was zusammen gehört. Sonst wüßte man ja nie, ob zwischen zwei Breakpoints auch tatsächlich alle Befehle abgearbeitet wurden. Übrigens: Hier ist es bereits dunkel und wir haben schnuckelige -4°C, aber drinnen ist es wärmer ;-) Verwendet man in Amerika nicht eigentlich °F? Oder hast Du umgerechnent?
15C ist ca 59F. Du hast den Nagel mit der Kombination Compiler / MCU voll auf den Kopf getroffen. Da trennt sich auch oft die Spreu vom Weizen, der GCC schneidet oft nicht so toll ab in der Kombination Kompaktheit/Performance. Manchmal lohnt sich fuer 5% Unterschied in Performance oder Groesse ein grosser Betrag, denn das macht den im Zweifelsfall Unterschied zwischen 2 sonst vergleichbaren Endprodukten. Wieder gilt, wenn der Programmierer in beiden Faellen gleich faehig ist. Es fehlt ausserdem auch noch die Selbststaendigkeit der Peripherie. So kann z.B. bei manchen MCUs, die Kombination Schnittstelle mit DMA die CPU sehr entlasten, vor allem von echtzeitkritischen Anforderungen und hohen Baudraten. Selbiges gilt fuer ADC + DMA usw. Bei EEMBC haben sich ca. 20 Firmen, die alle MCUs herstellen manchmal fast die Koepfe eingeschlagen was getestet werden sollte. Der eine hatte ein tolle CPU aber keine Peripherals (z.B. Intel, AMD, High-End ARM XScale...), andere haben ein komplettes System auf dem Chip aber die CPU leistet nur 10% der erst erwaehnten. Je nach Anwendung kann z.B. ein Soft-UART voll ausreichend sein, sofern es anderweitig wenig Echtzeitanforderung gibt, wenn aber schnell auf einige Interrupts reagiert werden soll, z.B. Motorsteuerung, Umrichter, dann kommt man in echte Konflikte. Es ist ein sehr weites Feld, das mit den Benchmarks, hab da schon viel gemacht, aber es gibt nicht wirklich einen Benchmark, der es allen recht machen kann. Z.B. hat hier noch fast keiner verstanden was DMIPS heisst. Es ist ein Benchmark, genannt Dhrystone, der die Anzahl der Dhrystones misst mit Bezug auf eine steinalte Architektur VAX PDP11, welche per Definition 1 MIPS hatte. Gruss, Robert
Robert Teufel wrote:
> mit Bezug auf eine steinalte Architektur VAX PDP11, welche per
Fast. Die Referenz ist die (32bit) VAX 780, nicht die (16bit) PDP11. Und
die hatte nur per Definition 1 MIPS, nicht wirklich.
@A.K. Du hast natuerlich recht mit der 780. Im Bezug auf MIPS allerdings denke ich, das ist sehr stark eine Sache der Definition. All die MIPSs, die immer erwaehnt werden, z.B. Cortex M3 mit 1.25 DMIPS/MHz, beziehen sich auf diesen VAX780 Wert. Eine MIPS Bewertung ohne einen festen Code ist noch weniger sinnvoll als es dieser Dhrystone Code ohnehin schon ist. Die meisten Architekturen koennen NOPS echt schnell ausfuehren ;-) Also wenn schon die sinnlosen MIPS, dann bitte DMIPS und nicht einer der sagt, mein Micro kann nur alle 16 Zyklen eine MUL durchfuehren oder die Sache mit den Port Toggeln.... Robert
Ich beziehe mich dabei auf diesen Wikipedia Satz: "For a while the VAX-11/780 was used as a baseline in CPU benchmarks because its speed was about one MIPS. Ironically enough, though, the actual number of instructions executed in 1 second was about 500,000." Klar konnte man mit NOPs auch schneller sein, aber es entbehrt nicht einer gewissen Ironie wenn die "Einheit" MIPS nicht einmal dort auch nur annähernd passt wo sie herkommt.
Naja Benchmarks sind auf eine gewisse weiße immer relativ. Das erinnert mich an die Highend Grafikkarten. Die eine hat laut Hersteller einen schnelleren Chip. Trotzdem kann die Grafikkarte mit dem langsameren Chip bei vielen Anwendungen (Spielen) mit halten. Also die Leistung ist schlicht von der Anwendung abhängig. MFG Patrick
@Patrick Du hast den Nagel absolut auf den Kopf getroffen. Benchmarks sind in erster Linie dazu da, eine Vorauswahl zu treffen, denn fuer eine groessere Anwendung ist es nicht praktikabel mehrere Prozessoren auf der Hardware zu testen. Meiner Meinung nach kommt der Ansatz von http://www.eembc.org dem Gedanken am naehesten verschiedene Anwendungen zu testen. Allerdings sind diese Benchmarks nicht open source, sondern werden mit Aufwand gepflegt von ein paar Ingenieuren, die auch Familien muessen. Der Vorteil bei diesen Benchmarks ist eine recht gute Vergleichbarkeit. Leider sind die "low end 32-bit" sehr schwach vertreten, keiner will Tests veroeffentlichen, bei denen er schlechter abschneidet als der direkte Mitbewerb. Gruss, Robert
Ach immer mit dem Geschwindigkeits Vergleich da ! Erinnert mich an einen Professor der alles mit einem Controller abdecken will. Naja der Techniker von heute muss Flexibäl sein. Ich will da ned sagen für jedes Projekt einen anderen nehmen sondern nicht nur an die Rechenleistung denken! Was nutzt ein 64 Bit µC @200MHz wenn man nur I/O macht wie Parallelport/SPI/TWI dann sind die 200MHz durch die Interrupts weg. Da nehm ich doch lieber so ein PICxx mit DMA oder ARM xxxx (Cortex M3)mit DMA und lass die ganzen Trnasfers im Hintergrund laufen und hab dann denn Kern frei für die eigentliche Arbeit. Aber der allerwichtigste Faktor ist man muss das Teil auch verstehen! Wer schon Probleme hat das Datenblatt eines AVR's oder 8051er zu lesen der wird sich wohl nicht bei den 32Bit (Monstern) leichter tuen. MFG Patrick
Nochmals überarbeitete Datei benchmark.c weil die ATmega Werte falsch waren. Messungen ohne Codeoptimierung.
Henry wrote: > Nochmals überarbeitete Datei benchmark.c Mir ist aufgefallen, dass die Parameter für Multiplikation und Division zwar 16 bzw 32bit Typen sind, die Werte allerdings nicht alle Bits belegen (y16, y32). Die Laufzeit einer Software Divison unterscheidet sich aber zum Teil erheblich in Abhängigkeit von den tatsächlichen Werten. Multiplikation auch (z.B. beim ARM7), nur ist da der Unterschied nicht so dramatisch. Gruß Marcus http://www.doulos.com/arm/
Mal eine Frage zu dem Benchmark. Müsste der dsPIC30 nicht besser abschneiden als der PIC24 bei dem Sinus berechnen ? Wie der Name des dsPIC schon besagt hat ja der DSP-Funktionalitäten die sich positiv auf das auswirken müssten ? Oder liege ich hier falsch ? MFG Patrick
Naja ich find so Benchmarks sowieso immer lustig. Denn man kann nie mit normierten Codes das optimum herausholen also -> Warum macht man dann die Sachen ? MFG Patrick
Es ist zwar schon lange her, dass ich dieses Thread gestartet habe, aber wie oben ja auch schon erwähnt, testet man immer die Kombination aus MCU und Compiler. Wieso versucht man überhaupt sowas wie einen Benchmark zu basteln? Die Idee war überhaupt erst mal ein Gefühl für die Leistungsfähigkeit der einzelnen MCU/Compiler Kombinationen zu bekommen. Aufgrund unterschiedlicher Peripherie und unterschiedlicher Kompileroptionen kann ohnehin nur ein grober Vergleicht entstehen. Niemand hat behauptet, dass so ein Benchmark eine für den Einzelfall richtige Aussage zuläßt. Aber eben doch ein grobes Gefühl darüber vermittelen kann, was mit Standardcode möglich ist. Wieso dsPIC30 und PIC24 gleich abschneiden ist einfach. Soweit ich mich erinnere gabe es darmals nur einen Compiler für die 16 Bit PICs. Wenn ich mich recht erinnere war es so, dass der Compiler die speziellen DSP Funktionen garnicht zur Codeerzeugung verwendet hat, sofern man nicht spezielle in Assembler geschriebene Bibliotheken verwendet hat. Das mag sich inzwischen geändert haben, da es ja mittlerweile unterschiedliche Compiler gibt. Grüße, Bernd
Ich habe mir grad auch mal die benchmark.c angeschaut. Dabei ist mir aufgefallen dass die PIC24 bei den 8 und 16 bit copy, fill und clear Tests wesentlich schneller sein müssten, wenn man statt der for-schleife ein repeat-konstrukt benutzt. Also in etwas wie asm:
1 | repeat w2 |
2 | mov.b [w0++],[w1++] |
Dazu kommt ein wenig Overhead um die Pointer in die Arbeitsregister zu laden. Damit kommt man dann auf weniger als 10µs für 256 x 8 bit oder 256 x 16 bit bei 40Mhz. Sogar die die 24F schaffen das dann in weniger als 20µs bei ihren max 16Mhz.
Ist es denn so schwer zu verstehen, dass es bei diesem Benchmark um ein PI mal Daumen Einschätzung des Controllers geht. Weder die Qualität des Compilers noch die Vorzüge der Assembler Programmierung stehen zur Diskussion.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.