Hallo zusammen,
ich versuche gerade mein in Gleitkommaarithmetik entworfenes LMS-Filter
in ein Festkomma LMS-Filter umzubauen. Leider habe ich im Internet noch
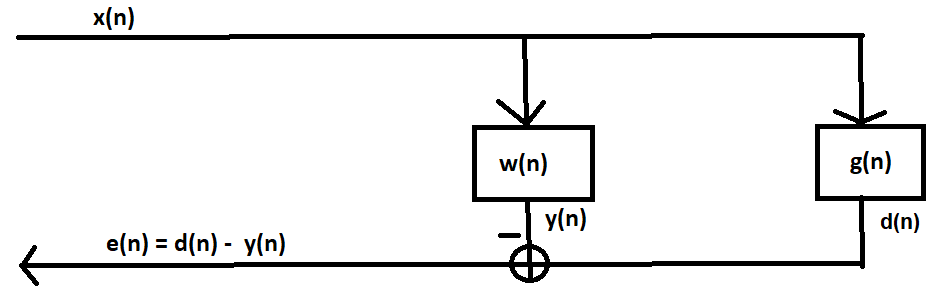
keine Antwort auf mein Problem gefunden. Die Problemstellung ist in
Zeichnung.png abgebildet. Vllt habt ihr auch noch Anmerkungen. Würdet
ihr zus. eine Over-/Underflowerkennung einbauen? Würdet ihr long integer
als Akkumulator verwenden?
Erst einmal habe ich CodeBlocks verwendet. Später soll das ganze noch
auf einen DSP und Mikrocontroller sowie ein FPGA.
Das Gleitkomma-LMS-Filter ist im Anhang (siehe
Referenzcode_LMS_Float_X1D1.txt). Die Funktion habe ich anhand von
ERLE-Kurven überprüft - das passt. Zusätzlich habe ich das ganze auch in
MATLAB implementiert.
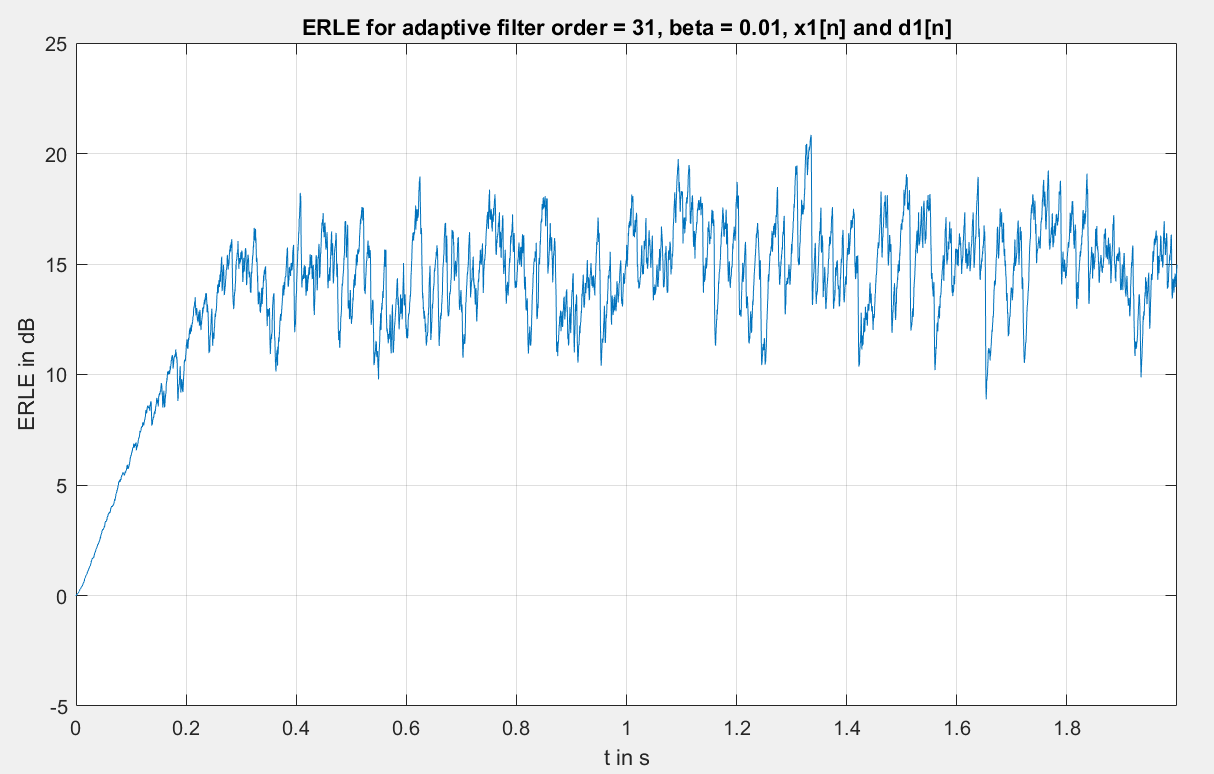
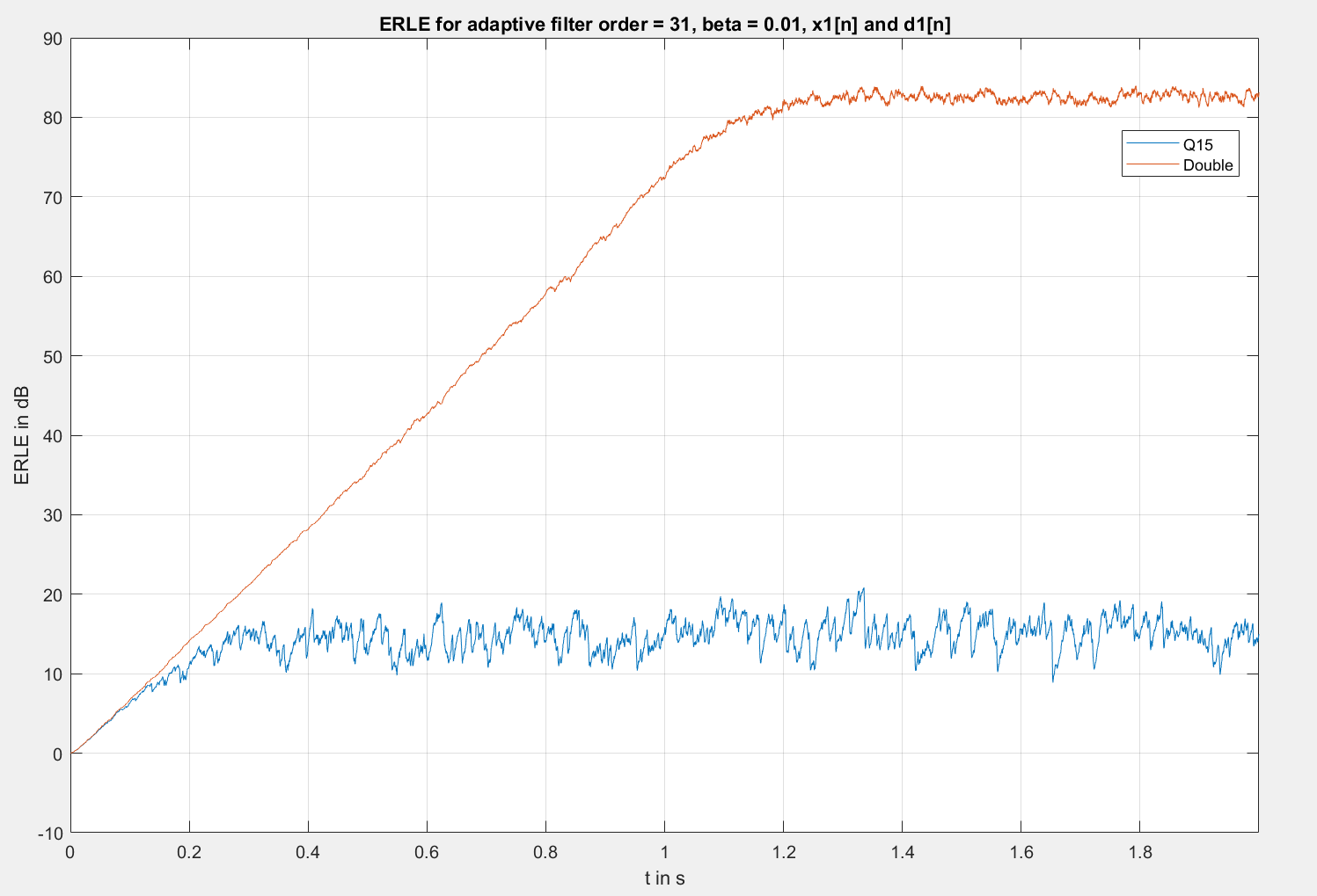
Für ein Beta (Lernrate) von 0.01 habe ich die Ergebnisse für den
Filterausgang y und den Fehler e angehängt (LMS_Data....txt). Damit man
aber besser abschätzen kann, wo sich die Fehler im C-Programm befinden,
habe ich die Signale x, d, e und y nochmal als .txt-Datei im Q15-Format
angehängt.
Meine Daten d (DataD1Q15.txt) und x (DataX1Q15.txt) sind im Q1.15
Datenformat. Dafür wurden die double Werte für d und x mit 2^15
multipliziert. Die Ergebnisse sollen wieder als Q0.15 Zahlen (1
Vorzeichen Bit, 15 Nachkommastellen) dargestellt werden.
Hier mein aktueller Stand, nach etlichen Änderungen... :P
1
#include<stdio.h>
2
#include<stdlib.h>
3
#include<stdint.h>
4
5
#define N 32 // Anzahl adaptiver FIR-Filterkoeffizienten
Das Problem ist, dass die Werte für y sehr stark von d abweichen. Der
Fehler e = d-y ist dadurch sehr groß und wird nicht kleiner mit der
Zeit. Der Sollverlauf des Fehlers ist in
LMS_Data_X1_D1_E_Float_Order31_beta_0_01.txt zu sehen. Also werden wohl
die Filterkoeffizienten w[n] falsch bestimmt. Leider sehe ich nicht
woran es liegt. Vermutlich sind die Werte für das rechtsshiften >>15 zu
klein und werden dadurch 0 bzw. zu klein. Weiß jemand wie man das am
besten angeht?
Später soll auch noch das NLMS Filter als Festkommavariante
implementiert werden.
Über eure Hilfe oder/und Tipps für gute Literatur würde ich mich sehr
freuen! Vielen Dank im Voraus!
Hmm... scanf %d und ein int16_t? Passt das?
Ansonsten: wenn du unerwartete Ergebnisse bekommst und schon vermutest,
dass Overflows stattfinden, dann check das doch mal. Ggfs den Accu
erweitern oder saturiert arbeiten.
> fscanf(fp_d,"%d\n", &s16_x[0]);> ...> s16_prod1 = (int16_t)((s16_x[i] * s16_e )>>15);
Nur eine der beiden Zeile kann korrekt sein. Wenn ints 16 Bit sind, die
erste, wenn 32 dann die zweite.
Das könnte ich noch mit
fscanf(fp_x,"%16d\n", &s16_x[0]);
fscanf(fp_d,"%16d\n", &s16_d);
auf 16 Stellen begrenzen. Sollte aber auch ohne gehen oder?
Hmm wenn ich
s16_prod1 = (int16_t)((s16_x[i] * s16_e )>>15);
in
s32_Wert1 = s16_x[i] * s16_e;
s16_prod1 = (int16_t)(s32_Wert1>>15);
ändere? Bringt das was? Ich probiers mal. Ich bin mir nicht ganz sicher
was du meinst. Also über die Filepointer fp_x und fp_d kann ich die
Zahlen als int16 einlesen.
Wenn ich eine Zahl im Q1.15 Datenformat mit einer anderen Zahl im Q1.15
Datenformat multipliziere kommt eine Zahl im Q2.30 Datenformat raus. Die
Zahl enthält dann 2 redundante Vorzeichenbits. Durch (int16_t)(Zahl>>15)
wird daraus wieder eine Zahl im Q1.15 Datenformat, wenn ich mich nicht
irre.
s16_x und s16_d sollten Zahlen im Q1.15 Datenformat sein.
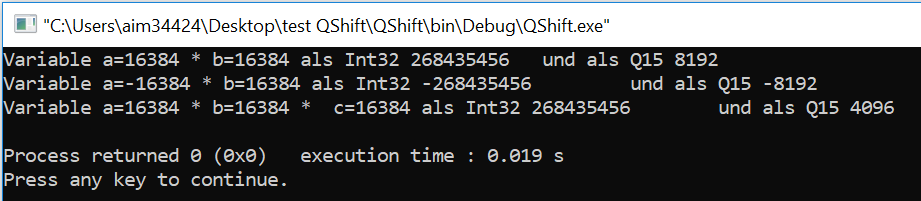
Im Anhang mal ein Beispiel, was ich meine und die zugehörige
Konsolenausgabe. Edit: Gerade gesehen, dass in der letzten Zeile nicht
int32 von 0,5*0,5*0,5 sondern nur von 0,5*0,5 ausgegeben wird mit
printf. Der Q-Wert stimmt aber.
> fscanf(fp_x,"%16d\n", &s16_x[0]);
Nein, %hd oder SCNd16:
fscanf(fp_x, SCNd16"\n", &s16_x[0]);
Alternativ:
int tmp;
...
fscanf(fp_x,"%d\n", &tmp); s16_x[0] = (int16_t)tmp;
> s32_Wert1 = s16_x[i] * s16_e;> s16_prod1 = (int16_t)(s32_Wert1>>15);
Bei 16-Bit-ints ist die Multiplikation nur 16 Bit. Sie muß 32-Bit sein,
also mind einen Operand erweitern:
(int32_t)s16_x[i] * s16_e
Ahh danke für den Tipp mit %hd! Sehr guter Tipp, danke!
>>Bei 16-Bit-ints ist die Multiplikation nur 16 Bit.
Ja das hab ich vorhin übersehen! Hatte ich schon ausgebessert aber danke
für den Tipp!
Mein Code sieht jetzt so aus:
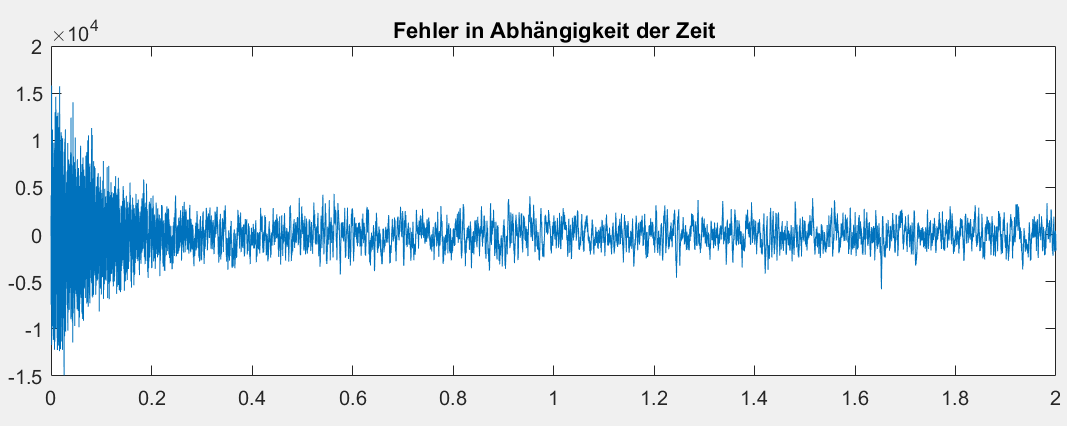
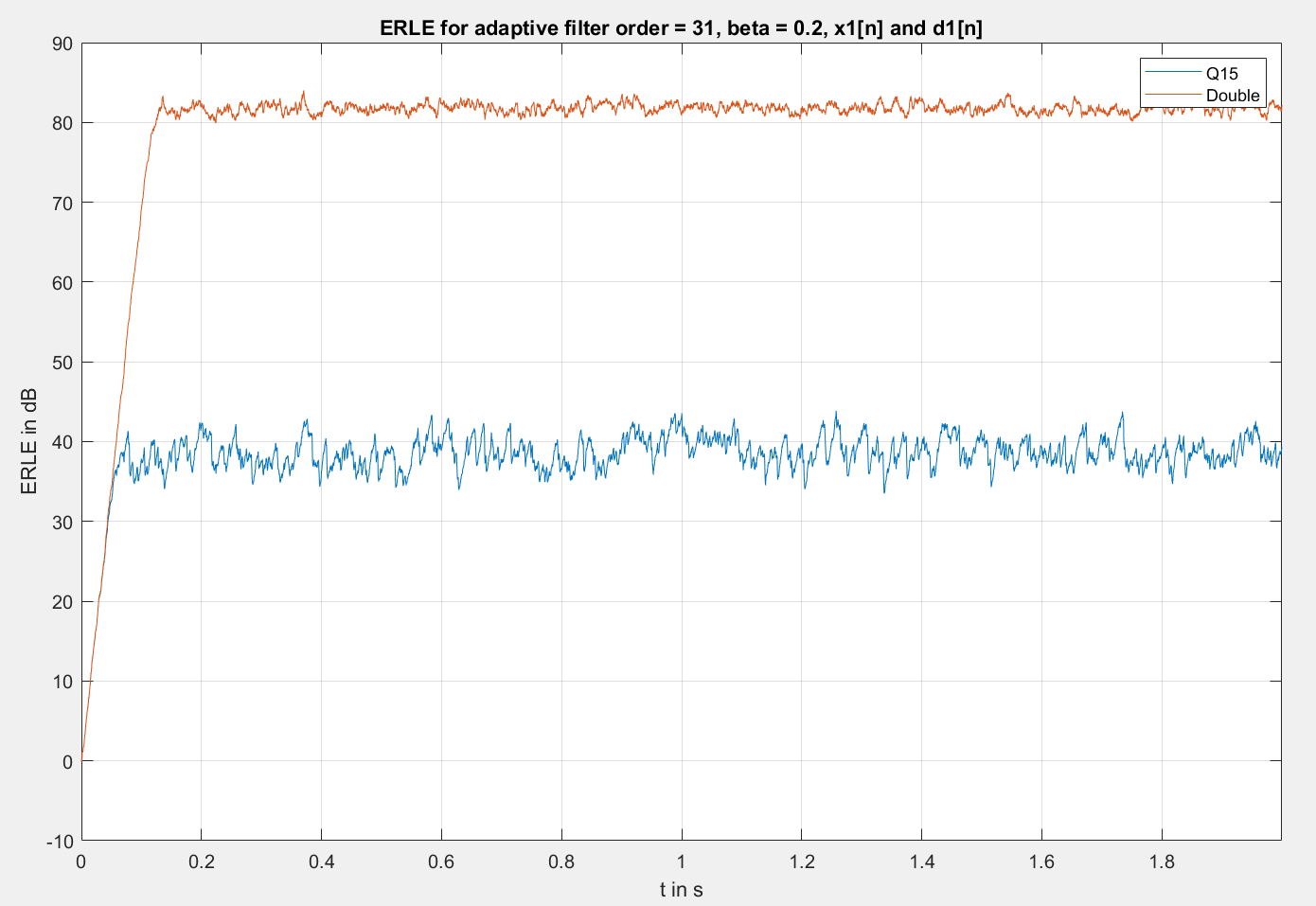
Ich hab das mal geplotted (siehe Anhang). Sieht jetzt schon mal viel
besser aus. Im Vergleich zur Double-Implementierung ist noch Luft nach
oben. Vllt muss ich mal eine höhere Lernrate testen. Ich hab mal
gelesen, dass ein zu kleines beta bei Festkommarealisierungen sonst dazu
führt, dass sich die Koeffizienten ab einem gewissen Punkt nicht mehr
ändern.
Vllt sollte ich es auch mal mit 24 Bit versuchen (also Q0.23).
Vielen Dank foobar! Der Tipp mit %hd hat mir echt geholfen! :)
Edit: Habe mal einen Vergleich von Double und Q15 angehängt (beide mit
beta=0,2).
und eine zusätzliche Division durch den ermittelten Wert
s16_input_signal_power dazu:
1
for(i=N-1;i>=0;i--)
2
{
3
// w = w + (beta*e*x)/(x*x)
4
5
s32_Wert1=s16_x[i]*s16_e;
6
s16_prod1=(int16_t)(s32_Wert1>>15);
7
8
s32_Wert2=s16_prod1*s16_beta;
9
s16_prod2=(int16_t)(s32_Wert2>>15);
10
11
s16_div=s16_prod2/s16_input_signal_power;
12
s16_w[i]=s16_w[i]+s16_div;//Achtung hier könnte Overflow auftreten
13
...
14
}
Der Rest bleibt gleich. So funktioniert das ganze leider noch nicht. Ich
habe auch mal versucht, dass ich s16_prod2 vor der Division mit
verschiedenen Werten multipliziere bzw. einen größeren Datentyp für den
Zähler, aber das hat leider auch NOCH nichts gebracht. Ich schau mir das
morgen nochmal an. Jetzt geht grad nichts mehr. ;)
Wenn du die Implementierungen vergleichen willst, solltest du beide auch
mit gleichen Daten füttern. Rechne mal die reduzierten int-Daten nach
double zurück und fütter damit die Double-Version. Dann weisst du, was
mit den reduzierten Daten überhaupt noch erreichbar ist und was durch
die int-Implementation zusätzlich verloren geht.
Ich hab jetzt mal den Zähler vorher multipliziert (<<16). Anfangs sehen
die Fehler e ganz gut aus. Irgendwann weichen die Fehler zu sehr vom
Ideal ab (vgl. Data_E... und Data_Y... der Gleitkommarealisierung).
>>Wenn du die Implementierungen vergleichen willst, solltest du beide auch
mit gleichen Daten füttern.
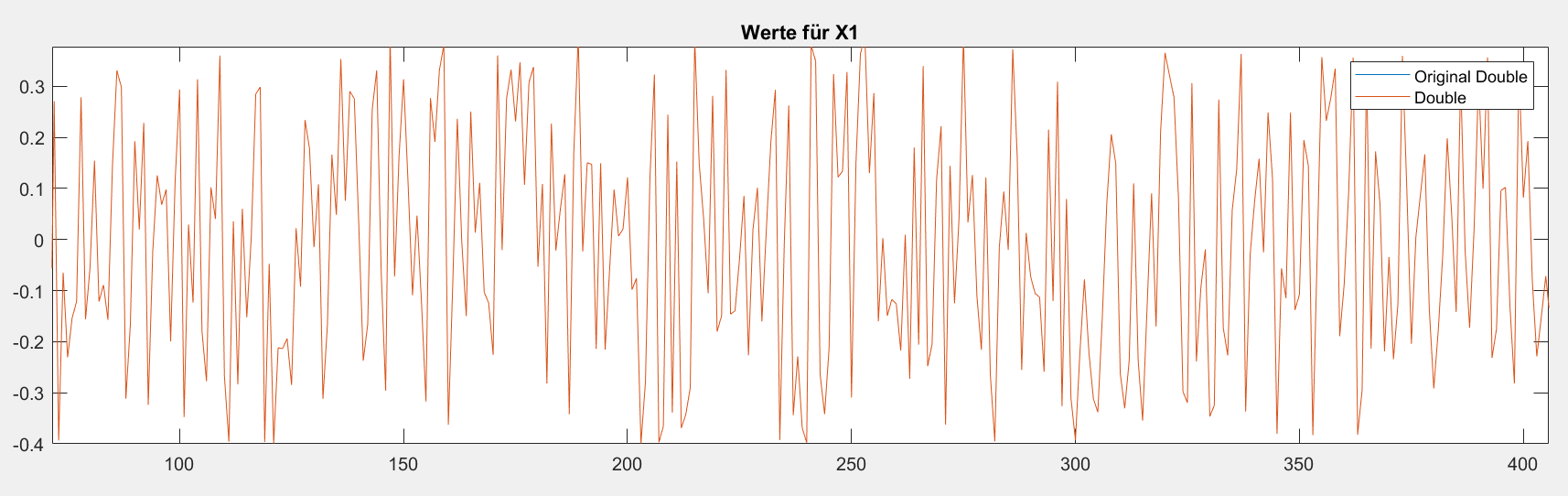
Danke für den Tipp. Ich habe mal eben die verwendeten Q15 Werte für X
und D in MATLAB als Ganzzahlen eingelesen und dann durch 2^15 geteilt.
Dann habe ich diese wieder in ein txt-file geschrieben (als Double) und
anschließend nochmal gelesen und in MATLAB mit den Original Double
Werten von X und D verglichen.
Es scheint, dass das nicht das Problem ist.
> Es scheint, dass das nicht das Problem ist.
Das siehst du anhand des grafischen Vergleichs? Da sind, wenn's hoch
kommt, gerade mal die oberen 7-8 Bit zu erkennen und natürlich stimmen
die überein - die Unterschiede sind in den abgeschnittenen unteren 32-48
Bits.
Nein ich hab mir auch die Abweichung plotten lassen und die Differenz in
den Arrays überprüft. Aber so vom Prinzip her hast du es gemeint oder?
Ich hab jetzt mal zusätzlich noch
if(s16_input_signal_power == 0){ s16_input_signal_power = 1; }
eingebaut. Bin weiter am schauen woran´s liegt.
Bei der Division geht wohl viel verloren. Vllt sollte ich für den
Quotienten 64 Bit verwenden. Ich versuch das mal.
Meine Koeffizienten w werden scheinbar irgendwann zu groß... Dadurch
wird dann auch y zu groß. Ich weiß noch nicht wie ich das umgehe. Hab
jetzt zus. noch eine Overflow/Underflowerkennung drin mit Sättigung.