Rolf M. schrieb:> Nano schrieb:>> Wie schon gesagt, bei dem Fallthrough Problem wird genau das gemacht:>> Siehe nochmal:>> https://lwn.net/Articles/794944/>>>> Und das ist vor allem abwärtskompatibel und würde so noch mit C89>> funktionieren. Es müsste nur der Compiler angepasst werden.>> Also Kompatibilität, indem man neue Syntax-Elemente einfach in die> Kommentare verschiebt? Das halte ich für eine sehr schlechte Idee.
Bei Übergangslösungen bis es ein mut für mutable Keyword in der nächsten
Standardversion gibt, ist das eine durchaus sinnvolle Lösung.
mut int 42: // durch das mut Keyword ist int explizit veränderlich
Zumal damit jeder Compiler umgehen kann, denn ein Compiler, diese
Funktion nicht kann, ignoriert ja ohnehin das Kommentar.
> Nano schrieb:>> Es geht also erst einmal darum, diese Möglichkeit überhaupt zu bieten.>> Da so etwas noch nicht im Sprachstandard ist, geht das jetzt also nur so>> wie bei dem fallthrough Teil auch nur über Kommentare oder>> Compilerspezifische Attribute.>> Oder Makros.>
1
>#if__STDC_VERSION__<202205L
2
>#definemut
3
>#endif
4
>
Willst du dann für jede Variablendefinition einen doppelten
Codeabschnitt schreiben?
1
#if MUT
2
mutint42;
3
#else
4
int42;
5
#endif
6 Zeilen für eine einzige Variable?
Dann doch lieber im Kommentar:
/* mut */ int 42; // compiliert überall und bietet trotzdem das Feature
bei fähigen compilern.
und später:
mut int 42; // ist dann nur noch für C2x Compiler.
Wilhelm M. schrieb:> Bei einer Schnittstelle wie> namespace ProtocollA{> class Connection {> void shutdown();> template<size_t N>> bool sendTo(const Address&, const std::array<std::byte, N>&) const;> };> }>> brauche ich keine Kommentare. Ggf. kann in der Realisierung auf noch> eine Vorbedingung wie static_assert(N < 256) eingebaut werden.
Naja, was sagt der Return-Wert? Bedeutet true, dass es einen Fehler gab
oder dass es keinen Fehler gab? Wie bekomme ich raus, welcher Fehler
aufgetreten ist? Blockiert die Funktion beim Senden oder kehrt sie
sofort zurück? Gibt es irgendwelche Voraussetzungen, die die Adresse
erfüllen muss? Was passiert, wenn sie die nicht erfüllt? Gibt es
Voraussetzungen, die das Connection-Objekt erfüllen muss, um senden zu
können? Was passiert, wenn die nicht erfüllt sind? Was wenn die Größe
erst zur Laufzeit bekannt ist? Was passiert, wenn N 0 ist? Gibt es einen
Puffer, der volllaufen kann? Gibt es irgendwelche anderen Gründe,
weshalb das Senden fehlschlagen kann?
Nano schrieb:> Und wenn aus Performancegründen Wertebereichprüfungen bewusst> weggelassen werden, dann muss der gültige Wertebereich in einem> Dokumentationskommentar definiert sein.
Das ist eigentlich völlig unabhängig davon, ob die Prüfung erfolgt oder
nicht. Wenn der Wert nicht im gültigen Bereich ist, ist das ein Fehler,
daher muss man dem Nutzer der Funktion mitteilen, was der gültige
Bereich ist.
Roland F. schrieb:> Hallo,> Nano schrieb:>> Weil man damit bestehenden Code verbessern könnte.>> Oder auch nicht.> Wer weiß ob durch die "Sprachverbesserung" nicht Seiteneffekte> entstehen, die an anderer Stelle ganz neue Probleme.
Das ist nicht möglich.
Als Kommentar wird das nämlich ignoriert und als C2x Keyword compiliert
der Code auf alten Compilern nicht.
Und ansonsten ändert sich am Code ja nichts.
Bisher gilt alles, was kein const davor stehen hat, als veränderlich.
Das wäre dann immer noch so.
Der Compiler würde bei entsprechender Compileroption dann lediglich eine
Warnung geben, dass nicht explizit der int Wert als veränderlich
definiert ist.
Und wenn es davor steht, dann würde das bei einem Compiler, der das
nicht kann, bei einem Kommentar keinen Unterschied machen und bei einem
Compiler, der das kann, der würde dann explizit wissen, dass die
Variable veränderlich sein soll und keine Warnung an der Stelle
ausgeben.
Und so sollte es ja sein.
Damit umgeht man das Problem ohne die Sprache wesentlich zu verändern,
dass man bei C vergessen hat, alle Variablen von Anfang an als implizit
const zu definieren.
Und das ist doch schön.
In Zukunft wird es mit so einer Option, wenn es dann als keyword im C2x
Standard ist dann halt lediglich etwas mehr Tipparbeit, wenn man immer
auch noch ein mut vor den Typ setzen muss, wenn der Datentyp nicht
konstant sein soll und der Compiler nicht meckern soll.
Nano schrieb:> Du bist dann doch gar nicht davon betroffen.> Wenn du nicht damit rechnest, dann nutzt du die Compileroption ja nicht.
Doch schon, denn ich bin kein Einzelkämpfer. Ich arbeite in einem
international verteiltem Team. Jeder kann etwas anderes besser.
MaWin schrieb:> Nano schrieb:>>> Ich finde es auch sehr blöd, wenn funktionale Anweisungen in Kommentaren>>> verborgen werden. Damit rechnet man nicht, vor allem nicht, wenn man>>> dieses oder jenes "neue" Feature dieser Art noch nicht kennt.>>>> Du bist dann doch gar nicht davon betroffen.>> Wenn du nicht damit rechnest, dann nutzt du die Compileroption ja nicht.>> Wenn du ein solches Feature hinter einem Schalter verbirgst, dann kannst> du es auch gleich vernünftig implementieren und ein neues keyword> einführen oder ähnliches.
Genau das habe ich doch gesagt.
Es geht aber darum, dass auch für alten nicht C2x Code nutzen zu können.
Und dann geht das nur mit einem Kommentar oder einem Attribut und beim
Attribut hättest du das Problem, dass es halt nicht mehr überall
compilieren würde, was man ja vermeiden will.
Wilhelm M. schrieb:> Stefan ⛄ F. schrieb:>>> int<0, 99> p;>>>> Bei REST Interface geben wir tatsächlich den Wertebereich an, sofern er>> für irgend etwas wichtig ist. Ich frage mich nur, was die>> Programmiersprache mit so einer Angabe anfangen soll. Sie kann ja>> schlecht bei jeder Zuweisung/Operation die Gültigkeit prüfen und ggf.>> eine Exception auslösen. Erstens gibt es in C keine Exceptions und>> zweitens würde das die Performance versauen.>> Natürlich eine Assertions-Verletzung feuern.>>> Das ist allerdings eine gute Stelle für Kommentare.>>>>> int p; // must be 0-99, requested in ticket 1234>> Nein, dann sollte man es so schreiben:>>
1
>constintp=calculate();
2
>assert((p>=0)&&(p<=99));
3
>
>> Assertionen sind auswertbare Kommentare!
Darf ich mich hier mal einklinken?
Hier steht zu assert folgendes:
https://www.c-plusplus.net/forum/topic/59867/was-ist-assert-und-was-macht-das/2
Zitat
"ASSERT wird nur im DEBUG ausgewertet.
Verwende VERIFY.
Verwendest du ASSERT und macht eine Bedingung davon abhängig dann wirst
du dich im Release wundern das es nicht mehr funktioniert da alles im
ASSERT im Release nicht ausgefügrt wird.
Ist ungefähr vergleichbar mit
#ifdef _DEBUG
wo dann nur ausgeführt wird wenn Debugmode."
??
Rolf M. schrieb:> Nano schrieb:>> Und wenn aus Performancegründen Wertebereichprüfungen bewusst>> weggelassen werden, dann muss der gültige Wertebereich in einem>> Dokumentationskommentar definiert sein.>> Das ist eigentlich völlig unabhängig davon, ob die Prüfung erfolgt oder> nicht. Wenn der Wert nicht im gültigen Bereich ist, ist das ein Fehler,> daher muss man dem Nutzer der Funktion mitteilen, was der gültige> Bereich ist.
Wenn du das in deiner Schnittstelle überprüfst, was Performance kosten
wird, dann kannst du auf den Fehler eingehen und den behandeln, sofern
es behandelbar ist. Der Nutzer deiner Schnittstelle müsste sich dann
nicht darum kümmern, da es ja deine Schnittstelle schon macht.
Nur dann, wenn der Fehler nicht innerhalb der Schnittstelle behandelbar
ist, müsstest du den Nutzer deiner Schnittstelle darauf hinweisen.
Ebenso hat man das Problem, wenn du in deiner Schnittstelle keine
Überprüfung und Fehlerbearbeitung drin hast, z.b. weil es keine
Performance kosten soll. Erst dann muss der Nutzer deiner Schnittstelle
wissen, mit welchen Daten er sie füttern darf.
Insofern ist das nicht unabhängig.
Nano schrieb:>>>> Oder Makros.>>> #if _STDC_VERSION_ < 202205L>> #define mut>> #endif>>>> Willst du dann für jede Variablendefinition einen doppelten> Codeabschnitt schreiben?#if MUT> mut int 42;> #else> int 42;> #endif
Nein.
Man schreibt ein einfach
Stefan ⛄ F. schrieb:> Nano schrieb:>> Du bist dann doch gar nicht davon betroffen.>> Wenn du nicht damit rechnest, dann nutzt du die Compileroption ja nicht.>> Doch schon, denn ich bin kein Einzelkämpfer. Ich arbeite in einem> international verteiltem Team. Jeder kann etwas anderes besser.
Wenn du an dem Code mitarbeiten musst/möchtest, dann musst die dich
natürlich den Bedingungen unterwerfen, unter dem der Code entwickelt
wird.
Aber das machst du ja ohnehin schon so, du passt ja auch dein Coding
Style daran an.
Also wirst du auch einen passenden fähigen Compiler einsetzen und das
Kommentar somit immer richtig setzen, so dass dein Code, wenn du ihn
commitest ohne Warnungen compiliert.
Femto schrieb:>>>> int p; // must be 0-99, requested in ticket 1234>>>> Nein, dann sollte man es so schreiben:>>>>
1
>>constintp=calculate();
2
>>assert((p>=0)&&(p<=99));
3
>>
>>>> Assertionen sind auswertbare Kommentare!>> Hier steht zu assert folgendes:>> https://www.c-plusplus.net/forum/topic/59867/was-ist-assert-und-was-macht-das/2>> Zitat>> "ASSERT wird nur im DEBUG ausgewertet.> Verwende VERIFY.
Was ist ASSERT?
Es ging um assert().
> Verwendest du ASSERT und macht eine Bedingung davon abhängig dann wirst> du dich im Release wundern das es nicht mehr funktioniert da alles im> ASSERT im Release nicht ausgefügrt wird.
Ja, assert() wird im Release-Build vom CPP entfernt.
assert() ist ein function-like CPP-macro, aber ohne allg. Rückgabewert
(bspw. im debug-build nicht vorgechrieben), daher kannst Du es nicht in
einem if-statement (oder #if-directive) verwenden, wenn Du das meinst.
Zusicherungen sind, wie ich oben schonmal geschrieben habe, dafür da,
die interne Logik des Artefakts sicherzustellen. Dazu gehören Vor- und
Nachbedingungen und bspw. alle Formen von Invarianten (oft
Zustandsinvarianten von Objekten).
Nano schrieb:> Zumal damit jeder Compiler umgehen kann, denn ein Compiler, diese> Funktion nicht kann, ignoriert ja ohnehin das Kommentar.
Ja. Aber nur die Versionen, bevor du Kommentare zu Syntax und Semantik
gemacht hast.
Das ist ein one-shot. Danach ist die Annahme "ignoriert ja ohnehin das
Kommentar" nicht mehr wahr.
Ab dem Zeitpunkt bekommst du nach und nach mit jedem neuen
"Kommentarfeature" die gleichen Kompatibilitätsprobleme, wie außerhalb
von Kommentaren auch.
MaWin schrieb:> Nano schrieb:>> Zumal damit jeder Compiler umgehen kann, denn ein Compiler, diese>> Funktion nicht kann, ignoriert ja ohnehin das Kommentar.>> Ja. Aber nur die Versionen, bevor du Kommentare zu Syntax und Semantik> gemacht hast.> Das ist ein one-shot. Danach ist die Annahme "ignoriert ja ohnehin das> Kommentar" nicht mehr wahr.
Doch und zwar genau dann, wenn du diese Compileroption nicht nutzt.
Es geht also auch mit einem neuen Compiler.
> Ab dem Zeitpunkt bekommst du nach und nach mit jedem neuen> "Kommentarfeature" die gleichen Kompatibilitätsprobleme, wie außerhalb> von Kommentaren auch.
Da das zuschaltbare Compileroptionen sind, sehe ich das nicht so. Die
sind nämlich kein Sprachstandard, also kann man da auch wieder
umdefinieren.
Aber wozu sollte das hier nötig sein?
Nano schrieb:> Da das zuschaltbare Compileroptionen sind, sehe ich das nicht so. Die> sind nämlich kein Sprachstandard, also kann man da auch wieder> umdefinieren.> Aber wozu sollte das hier nötig sein?
Ab dem Zeitpunkt musst du dir Gedanken darüber machen, welche
Schlüsselwort-Kommentare es bereits gab und wie es zu Uneindeutigkeiten
und Inkompatibilitäten führen kann, wenn du wieder eins einführst. Wenn
du jetzt ein weiteres Keyword wie /* immut */ einführst - warum auch
immer - dann wechselwirkt das mit dem alten /* mut */ und allen anderen.
Die Annahme, dass Kommentare neutral sind, ist ab dem Moment falsch, ab
dem du sie zur Funktionalität erhoben hast.
Und nein, "es ist hinter einem Schalter, also ist es dein Problem" ist
keine Lösung des Problems. Es wälzt die Lage lediglich auf den ohnehin
schon durch 9000 Compilervarianten gestressten Programmierer ab.
Was soll das mit diesen Kommentaren für ein neues Schlüsselwort?
Mach doch einfach
1
#if defined(ENABLE_MUTABLE)
2
# define PRE_MUT mut
3
#else
4
# define PRE_MUT
5
#endif
Dann kannst Du das passende zu Deinem Compiler einschalten (oder
ausschalten). Ok, es darf PRE_MUT nicht sonst im Code vorkommen.
Deswegen ein gescheiter Präfix.
Einen alten Code musst Du auch bei der Kommentarlösung anfassen. Der
Aufwand ist also gleich zu dieser Lösung.
Bei neuem Code baust Du das gleich ein, und kannst das feature
entsprechend Deiner Compiler-Version benutzen. Nach 10 Jahren kannst Du
es ja auch ganz raus werfen. Wie gesagt, das macht Qt schon immer recht
erfolgreich.
Nano schrieb:>> Das ist eigentlich völlig unabhängig davon, ob die Prüfung erfolgt oder>> nicht. Wenn der Wert nicht im gültigen Bereich ist, ist das ein Fehler,>> daher muss man dem Nutzer der Funktion mitteilen, was der gültige>> Bereich ist.>> Wenn du das in deiner Schnittstelle überprüfst, was Performance kosten> wird, dann kannst du auf den Fehler eingehen und den behandeln, sofern> es behandelbar ist.
Da es hier um einen programminternen logischen Fehler geht (z.B. deiner
Variable, die im Bereich 0 bis 99 liegen muss, soll jetzt plötzlich 120
zugewiesen werden), gibt es keinen sinnvollen Weg, das zu behandeln. Du
hast eigentlich in dem Fall nur drei Möglichkeiten:
1. Geordneter Rückzug, also Programm beenden
2. Schreibzugriff unterdrücken - dann steht aber ein falscher Wert in
der Variable
3. Schreibzugriff trotzdem durchführen - dann steht aber ein illegaler
Wert in der Variable
> Der Nutzer deiner Schnittstelle müsste sich dann nicht darum kümmern, da> es ja deine Schnittstelle schon macht.
Der Nutzer muss sich drum kümmern, sonst kann das Programm nicht
funktionieren. Die Schnittstelle prüft lediglich, ob die Vorgaben auch
wirklich eingehalten wurden (dann kann man den Fehler erkennen) oder
eben nicht (dann passiert halt irgendwas).
> Nur dann, wenn der Fehler nicht innerhalb der Schnittstelle behandelbar> ist, müsstest du den Nutzer deiner Schnittstelle darauf hinweisen.
Das ist aber nur bei Fehlern der Fall, die nicht intern in der
Programmlogik liegen, sondern von außen kommen, z.B. der Versuch, eine
Datei zu öffnen, die nicht existiert. Da gehört aber dann auch kein
assert hin.
> Ebenso hat man das Problem, wenn du in deiner Schnittstelle keine> Überprüfung und Fehlerbearbeitung drin hast, z.b. weil es keine> Performance kosten soll. Erst dann muss der Nutzer deiner Schnittstelle> wissen, mit welchen Daten er sie füttern darf.
Nein. Wenn er sie mit bestimmten Daten nicht füttern darf, dann ist das
so. Soll der Programmierer etwa erst durch einen Assert-Fehler bemerken,
dass 120 kein gültiger Wert für die Variable ist?
Rolf M. schrieb:> Der Quatsch schon wieder? Ja, wenn man selbst einen Header schreibt,> gehört der im Gegensatz zu den Standard-Headern nicht zum Umfang des> Standards. Was hat das jetzt mit stdint.h zu tun?
Ich habe das eben genau so mal formuliert, damit auch der Verbissenste
mal kapieren muß, daß all das, wofür man eine Datei (für gewöhnlich
Headerdatei genannt) braucht, eben prinzipiell NICHT zum Sprachumfang
gehört. Ganz egal, ob so eine Datei nun vom Hersteller einer Toolchain
oder von irgend einem anderen verfaßt wurde.
Besagte Datei muß zwangsweise vom Compiler verarbeitet werden und kann
folglich nur bereits im Sprachumfang enthaltenes Zeug beinhalten, sonst
ist sie fehlerhaft. Wer das nicht begreift, der ist schlichtweg dumm.
Fazit: Mawins Annahme, daß irgendein uint32_t o.ä. zum Sprachstandard
gehört, ist eben falsch. Und durch gebetsmühlenartiges Wiederholen wird
sie nicht wahrer.
Und was das mit dem Mantel zu tun hat? Nun, der kommt auch daher, wenn
Mawin daher kommt, aber deswegen gehört der Mantel noch lange nicht zu
Mawins Körperteilen. Genau so, wie all das Zeugs, was in einer mit der
Toolchain dazu kommt, nicht zum Sprachstandard gehört.
Benutzt euren Kopf doch mal zum logischen Denken.
W.S.
Rolf M. schrieb:>> Programmiersprache schaffen und etablieren, die alles besser kann und>> macht.>> Das haben schon so viele gemacht. Deshalb gibt es jetzt eine> unüberschaubare Anzahl von Programmiersprachen. Die eine perfekte "one> language to rule them all" ist dennoch nicht dabei.
Naja, das stimmt in der hier formulierten Allgemeinheit nicht.
Sondern:
Es hat schon viele Leute gegeben, denen C nicht gefällt oder zu wenig
kann, weswegen einige davon sich Programmiersprachen ausgedacht hatten,
die sie für besser hielten. Aber es ist jedesmal nur eine Art von
durchgekautes C dabei herausgekommen und die Toolchain für solches Zeugs
war zumeist nix als eine Art "Vorbrenner", der aus dem Quelltext einen
C-Text gemacht hat.
Und dir ist das 'unüberschaubar' ? Naja, wenn man C verbessern will ohne
es tatsächlich zu verbessern, dann ergibt das eine selbstgebaute
Zwickmühle.
W.S.
Rolf M. schrieb:> Nano schrieb:>> Wenn du das in deiner Schnittstelle überprüfst, was Performance kosten>> wird, dann kannst du auf den Fehler eingehen und den behandeln, sofern>> es behandelbar ist.>> Da es hier um einen programminternen logischen Fehler geht (z.B. deiner> Variable, die im Bereich 0 bis 99 liegen muss, soll jetzt plötzlich 120> zugewiesen werden), gibt es keinen sinnvollen Weg, das zu behandeln. Du> hast eigentlich in dem Fall nur drei Möglichkeiten:> 1. Geordneter Rückzug, also Programm beenden> 2. Schreibzugriff unterdrücken - dann steht aber ein falscher Wert in> der Variable> 3. Schreibzugriff trotzdem durchführen - dann steht aber ein illegaler> Wert in der Variable
1-3 bedeutet behandeln. Was meinst du was das ist?
Mal angenommen du hast Höhendaten vom Satellit und willst das mit einer
anderen Karte kombinieren. Dann ist ein Wolkenkratzer ein Spike, der da
nicht in die Bodenleveldaten hingehört.
Also kannst du das behandeln und bspw. mit den umgebenden Daten
nivellieren. Die Daten werden nicht perfekt sein, aber für einen
Flugsimulator reicht's.
>> Der Nutzer deiner Schnittstelle müsste sich dann nicht darum kümmern, da>> es ja deine Schnittstelle schon macht.>> Der Nutzer muss sich drum kümmern, sonst kann das Programm nicht> funktionieren.
Wie schon gerade beschrieben, es kommt ganz darauf an.
>> Nur dann, wenn der Fehler nicht innerhalb der Schnittstelle behandelbar>> ist, müsstest du den Nutzer deiner Schnittstelle darauf hinweisen.>> Das ist aber nur bei Fehlern der Fall, die nicht intern in der> Programmlogik liegen, sondern von außen kommen, z.B. der Versuch, eine> Datei zu öffnen, die nicht existiert. Da gehört aber dann auch kein> assert hin.
Das ist bereits der Fall, wenn deine Routine schnell sein soll und mit
den gleichen Daten häufig wiederholt aufgerufen wird.
>> Ebenso hat man das Problem, wenn du in deiner Schnittstelle keine>> Überprüfung und Fehlerbearbeitung drin hast, z.b. weil es keine>> Performance kosten soll. Erst dann muss der Nutzer deiner Schnittstelle>> wissen, mit welchen Daten er sie füttern darf.>> Nein. Wenn er sie mit bestimmten Daten nicht füttern darf, dann ist das> so. Soll der Programmierer etwa erst durch einen Assert-Fehler bemerken,> dass 120 kein gültiger Wert für die Variable ist?
Siehe oben. Lies da nochmal.
W.S. schrieb:> Ich habe das eben genau so mal formuliert, damit auch der Verbissenste> mal kapieren muß, daß all das, wofür man eine Datei (für gewöhnlich> Headerdatei genannt) braucht, eben prinzipiell NICHT zum Sprachumfang> gehört. Ganz egal, ob so eine Datei nun vom Hersteller einer Toolchain> oder von irgend einem anderen verfaßt wurde.>> Besagte Datei muß zwangsweise vom Compiler verarbeitet werden und kann> folglich nur bereits im Sprachumfang enthaltenes Zeug beinhalten, sonst> ist sie fehlerhaft. Wer das nicht begreift, der ist schlichtweg dumm.
Ihr schießt Euch hier regelmäßig selbst ins Knie. Haltet Euch doch mal
an die Begriffsdefinition: im C-Standard ISO/IEC 9899 ist die
Kern-Sprache (dort einfach nur Language genannt) wie auch die Header
bzw. Standard-C-Lib beschrieben.
Wenn man C nennenswert verbessert, kommt eine andere Sprache dabei
heraus. Das ist bereits mehrfach passiert.
Ich programmiere µC trotzdem in C. Ich fahre auch gerne ein Auto dass
ganz gewiss nicht das beste ist.
W.S. schrieb:> Ich habe das eben genau so mal formuliert, damit auch der Verbissenste> mal kapieren muß, daß all das, wofür man eine Datei (für gewöhnlich> Headerdatei genannt) braucht, eben prinzipiell NICHT zum Sprachumfang> gehört. Ganz egal, ob so eine Datei nun vom Hersteller einer Toolchain> oder von irgend einem anderen verfaßt wurde.
Es gehört nicht zum Sprachkern, aber zum Umfang des Standards, und das
ist es, worauf es ankommt. Es ist ein Standardheader, der mit jedem
standardkonformen Compiler mitgeliefert wird - in einer natürlich zu
genau diesen Compiler passenden Variante.
> Besagte Datei muß zwangsweise vom Compiler verarbeitet werden und kann> folglich nur bereits im Sprachumfang enthaltenes Zeug beinhalten, sonst> ist sie fehlerhaft.
Das ist grundlegend falsch. Da ein Standardheader zum Compiler gehört,
kann er intern auch beliebig auf compilerspezifische Dinge
zurückgreifen, und davon wird in der Praxis auch Gebrauch gemacht.
Tatsächlich muss es nicht mal zwingend eine Datei sein. Der Compiler
kann sich auch entscheiden, #include <stdint.h> einfach als Trigger zu
verwenden, um eine entsprechende, bereits im Compiler eingebaute
Funktionalität zu aktivieren, ohne dass überhaupt irgendeine Datei dafür
existieren müsste.
> Wer das nicht begreift, der ist schlichtweg dumm.
Nur weil du nicht begreifen kannst oder willst, dass Standardheader
nicht das gleiche sind wie Header, die man als Programmierer selbst für
sein Programm schreibst, sind andere also dumm…
Was du bisher nicht plausibel erklären konntest ist, warum es überhaupt
eine Rolle spielt, ob uint32_t nun im Sprachkern oder einem
Standardheader umgesetzt ist.
> Fazit: Mawins Annahme, daß irgendein uint32_t o.ä. zum Sprachstandard> gehört, ist eben falsch. Und durch gebetsmühlenartiges Wiederholen wird> sie nicht wahrer.
Selbstverständlich gehört es zum Standard. Du kannst das gerne im
Standard nachlesen, da ist das alles spezifiziert.
Nano schrieb:>> Da es hier um einen programminternen logischen Fehler geht (z.B. deiner>> Variable, die im Bereich 0 bis 99 liegen muss, soll jetzt plötzlich 120>> zugewiesen werden), gibt es keinen sinnvollen Weg, das zu behandeln. Du>> hast eigentlich in dem Fall nur drei Möglichkeiten:>> 1. Geordneter Rückzug, also Programm beenden>> 2. Schreibzugriff unterdrücken - dann steht aber ein falscher Wert in>> der Variable>> 3. Schreibzugriff trotzdem durchführen - dann steht aber ein illegaler>> Wert in der Variable>> 1-3 bedeutet behandeln. Was meinst du was das ist?
Nein, man hat nur eine Möglichkeit, und das ist 1.: Abbruch.
Denn das Programm ist damit nachgewiesenermaßen falsch. Punkt, Ende,
Aus.
Rolf M. schrieb:> In einem mathematischen Gleichungssystem können sich die Werte von> Variablen auch nicht ändern, da es...
Ist dir eigentlich jemals der fundamentale Unterschied zwischen
Gleichungen und Ergibtanweisungen bewußt geworden?
W.S.
Zum Feierabend haue ich jetzt - nach dem Einschränken des Wertebereiches
(s.o. int<0,99>) - noch einen Spruch raus: die fundamentalen Datentypen
sind dazu da, das man sie im wesentlichen nicht direkt benutzt: es sind
nur Grundbausteine, um sich domänenspezifische Datentypen zu erstellen.
Also statt double etwa Distance<Km>, was man dann durch Duration teilen
kann, und dann kommt Velocity dabei heraus, und eben nicht ein
semantikfreier double-Wert. Dieser Ansatz lässt sich auf alle benötigten
Objekte und ihre Typen ausdehnen, eben je nach Problem-Domäne.
W.S. schrieb:> daß all das, wofür man eine Datei (für gewöhnlich> Headerdatei genannt) braucht, eben prinzipiell NICHT zum Sprachumfang> gehört. Ganz egal, ob so eine Datei nun vom Hersteller einer Toolchain> oder von irgend einem anderen verfaßt wurde.>> Besagte Datei muß zwangsweise vom Compiler verarbeitet werden und kann> folglich nur bereits im Sprachumfang enthaltenes Zeug beinhalten, sonst> ist sie fehlerhaft.https://www.open-std.org/jtc1/sc22/WG14/www/docs/n1570.pdf> 7.1.2 Standard headers> The standard headers are ... <stdint.h> ...
Du liegst falsch. Ganz einfach.
> Wer das nicht begreift, der ist schlichtweg dumm.
Wer im Glashaus sitzt.
Wilhelm M. schrieb:> Nein, man hat nur eine Möglichkeit, und das ist 1.: Abbruch.
Denke mal ein bisschen über deinen Tellerand hinaus. Zum Beispiel an
eine Datenbank für einen Online Shop. Bloss weil irgendwo eine ungültige
Zahl aufgetaucht ist, soll ganz sicher die die DB ausfallen und damit
der ganze Online Shop.
Ähnlich ist es bei Maschinen. Bloß weil z.B. der Beschleunigungssensor
in der Stoßstange ungültige Werte liefert, sollte das Auto auf keinen
Fall mitten auf der Autobahn abschalten.
Oder wenn im Elektroherd eine Kochstelle ausgefallen ist, soll deswegen
nicht der ganze Herd unbrauchbar werden.
Deswegen eignet sich assert meiner Meinung nach in vielen Fällen nicht.
Fehler müssen oft behandelt werden. Ein Totalausfall des Programms ist
oft nicht akzeptabel.
Rolf M. schrieb:> Was du bisher nicht plausibel erklären konntest ist, warum es überhaupt> eine Rolle spielt, ob uint32_t nun im Sprachkern oder einem> Standardheader umgesetzt ist.
Dann erkläre ich es dir: jeder könnte sich eine Headerdatei schreiben
und sich Namen nach eigenem Gusto für die im Sprachstandard enthaltenen
Variablentypen selber machen. In der Vergangenheit wurde das ja auch
sehr häufig gemacht. Sowas wie uint32_t ist genauso gut oder schlecht
wie U32 oder DWORD und da das alles auf 'int' mit diversen Prädikaten
(long, signed usw.) zurückgeführt wird, wozu eben zumeist besagte
Headerdateien dienen, ist so etwas nicht zum Sprachstandard gehörig.
Man könnte es auch grob so sagen: was nicht der Compiler von sich aus
versteht, das gehört auch nicht zum Sprachumfang. Grob ist das aus 2
Gründen: zum einen mag es Compiler geben, die manche Datenformate wie
z.B. float nicht unterstützen (Tiny C oder so) und zum anderen gibt es
öfters plattform- oder tool-spezifische Dinge (siehe _irq), die
Erweiterungen von bestimmten Compilern sind und nicht zum Sprachumfang
gehören.
W.S.
(prx) A. K. schrieb:> Mit ^ dahinter hätte man das Problem nicht mit der Multiplikation> gehabt, dafür aber mit XOR ^ - das gibts in Pascal ja nicht. Also> gleiches Problem, irgendwo hätte es ein anderes Symbol gebraucht.
Irrtum.
In Pascal gibt es AND, OR, XOR, NOT und noch einiges mehr. Da braucht
man keine Sondertasten dafür. Hast du bloß nicht gewußt oder grad mal
vergessen.
W.S.
W.S. schrieb:> Man könnte es auch grob so sagen: was nicht der Compiler von sich aus> versteht, das gehört auch nicht zum Sprachumfang.
Wir haben dich schon verstanden. Deine Meinung bleibt jedoch Quatsch.
Es gibt eine Spezifikation, die fest legt, was zur Sprache gehört und
was nicht.
W.S. schrieb:> Dann erkläre ich es dir: jeder könnte sich eine Headerdatei schreiben> und sich Namen nach eigenem Gusto für die im Sprachstandard enthaltenen> Variablentypen selber machen.
Ja, und? Es geht hier um stdint.h und nicht um irgendeine selbst
geschriebene Datei. stdint.h gehört eben zum Standard.
Ich verstehe überhaupt nicht, was dich antreibt.
Es wurde bewiesen, dass du falsch liegst.
Trotzdem behauptest du weiterhin steif und fest richtig zu liegen.
Schaue vielleicht einfach mal in den C-Standard rein. Wäre das eine
Idee? Du hast es offensichtlich noch nie getan.
W.S. schrieb:> Hast du bloß nicht gewußt oder grad mal vergessen.
Es ging in meinem Beitrag um das ^ Symbol, das in Pascal für
Dereferenzierung genutzt wird, aber in C aufgrund des Operators für
exklusives Oder das gleiche Problem hätte wie *. Hast du bloss nicht
verstanden.
W.S. schrieb:> Man könnte es auch grob so sagen: was nicht der Compiler von sich aus> versteht, das gehört auch nicht zum Sprachumfang.
Zum Sprachumfang zählt alles, was der Sprachstandard definiert.
Rolf M. schrieb:> Da es hier um einen programminternen logischen Fehler geht (z.B. deiner> Variable, die im Bereich 0 bis 99 liegen muss, soll jetzt plötzlich 120> zugewiesen werden), gibt es keinen sinnvollen Weg, das zu behandeln. Du> hast eigentlich in dem Fall nur drei Möglichkeiten:> 1. Geordneter Rückzug, also Programm beenden> 2. Schreibzugriff unterdrücken - dann steht aber ein falscher Wert in> der Variable> 3. Schreibzugriff trotzdem durchführen - dann steht aber ein illegaler> Wert in der Variable
Was passiert bei?
1
chara=1234;
-> undefined behavior
das würde ich auch für
1
int<-128,127>a=1234;
erwarten. das sagt dem Compiler lediglich, dass er platz für Ganzzahlen
zwischen -128 und 127 bereitstellen soll. Diesen Bereich nicht zu
verlassen liegt dann in der Verantwortung des Programmierers.
Zombie schrieb:> Was passiert bei?> char a = 1234;> -> undefined behavior
Ja, genau. Es mangelt in C an UB. Deshalb müssen wir unbedingt auch bei
trivialsten Zuweisungen noch die Möglichkeit für UB hinzufügen.
Wilhelm M. schrieb:> Zum Feierabend haue ich jetzt - nach dem Einschränken des Wertebereiches> (s.o. int<0,99>) - noch einen Spruch raus: die fundamentalen Datentypen> sind dazu da, das man sie im wesentlichen nicht direkt benutzt: es sind> nur Grundbausteine, um sich domänenspezifische Datentypen zu erstellen.> Also statt double etwa Distance<Km>, was man dann durch Duration teilen> kann, und dann kommt Velocity dabei heraus, und eben nicht ein> semantikfreier double-Wert.
Dann haue ich jetzt auch noch einen Spruch raus:
Keine zwei Variablen sollten vom selben Typ sein, d.h. für jede Variable
wird ihr eigener Typ definiert. Für Funktionsargumente hast du diese
Vorgehensweise ja schon propagiert, aber sie sollte konsequenterweise
auf alle Variablen ausgedehnt werden.
Damit gehören fehlerträchtige Konstrukte wie bspw.
1
a=b;
endlich der Vergangenheit an. Da a und b für völlig verschiedene Dinge
stehen (sonst hätten sie nicht verschiedene Namen), ist eine Zuweisung
von b nach a grundsätzlich falsch. Wegen der unterschiedlichen
Datentypen von a und b ist nun auch der Compiler in der Lage, den Fehler
aufzudecken.
Ein weiterer Vorteil: Die eineindeutige Zuordnung zwischen Datentypen
und Variablen ermöglicht es, Variablen nach ihrem Typ zu benennen, also
bspw.
1
classDrehzahlLinkesVorderrad{
2
...
3
};
4
5
classDrehzahlRechtesVorderrad{
6
...
7
};
8
9
DrehzahlLinkesVorderradDrehzahlLinkesVorderrad;
10
DrehzahlRechtesVorderradDrehzahlRechtesVorderrad;
Somit geht aus dem Variablennamen nicht nur die Bedeutung des Inhalts,
sondern auch direkt der Datentyp hervor. Außerdem entfallen jegliche
Gründe für hässliche Suffixe an den Typnamen (bspw. "_t"), wie sie heute
noch von vielen verwendet werden.
Wer sich konsequent an diese und Wilhelms Regeln hält, wird automatisch
nur noch fehlerfreien Qualitätscode schreiben. Der Preis, den man dafür
zahlen muss, sind halt kilometerlange Header mit Klassendeklarationen,
was aber angesichts der immensen Vorteile verschmerzbar sein sollte.
Wilhelm M. schrieb:> Nein, man hat nur eine Möglichkeit, und das ist 1.: Abbruch.> Denn das Programm ist damit nachgewiesenermaßen falsch. Punkt, Ende,> Aus.
Du brichst beim Wolkenkratzer ab, mein Programm funktioniert weiter.
Yalu X. schrieb:>
> Dann haue ich jetzt auch noch einen Spruch raus:>> Keine zwei Variablen sollten vom selben Typ sein, d.h. für jede Variable> wird ihr eigener Typ definiert. Für Funktionsargumente hast du diese> Vorgehensweise ja schon propagiert, aber sie sollte konsequenterweise> auf alle Variablen ausgedehnt werden.>....>> Wer sich konsequent an diese und Wilhelms Regeln hält, wird automatisch> nur noch fehlerfreien Qualitätscode schreiben. Der Preis, den man dafür> zahlen muss, sind halt kilometerlange Header mit Klassendeklarationen,> was aber angesichts der immensen Vorteile verschmerzbar sein sollte.
Als Geschenk zwei Tags:
[ironie]
[/ironie]
Die habe ich nämlich gesucht, kann dich aber verstehen.
Nano schrieb:> Mal angenommen du hast Höhendaten vom Satellit und willst das mit einer> anderen Karte kombinieren. Dann ist ein Wolkenkratzer ein Spike, der da> nicht in die Bodenleveldaten hingehört.> Also kannst du das behandeln und bspw. mit den umgebenden Daten> nivellieren. Die Daten werden nicht perfekt sein, aber für einen> Flugsimulator reicht's.
Vielleicht magst du noch einmal erläutern, welche Verwendung ein hart im
Wertebereich eingeschränkter Typ für erwartbar abweichende Daten hat.
Die Unterstellung, dass Wilhelm in diesem Fall einen solchen Typ
verwenden würde, halte ich doch für ziemlich abwegig.
Stefan ⛄ F. schrieb:> Wilhelm M. schrieb:>> Nein, man hat nur eine Möglichkeit, und das ist 1.: Abbruch.>> Denke mal ein bisschen über deinen Tellerand hinaus. Zum Beispiel an> eine Datenbank für einen Online Shop. Bloss weil irgendwo eine ungültige> Zahl aufgetaucht ist, soll ganz sicher die die DB ausfallen und damit> der ganze Online Shop.>> Ähnlich ist es bei Maschinen. Bloß weil z.B. der Beschleunigungssensor> in der Stoßstange ungültige Werte liefert, sollte das Auto auf keinen> Fall mitten auf der Autobahn abschalten.>> Oder wenn im Elektroherd eine Kochstelle ausgefallen ist, soll deswegen> nicht der ganze Herd unbrauchbar werden.>> Deswegen eignet sich assert meiner Meinung nach in vielen Fällen nicht.> Fehler müssen oft behandelt werden. Ein Totalausfall des Programms ist> oft nicht akzeptabel.
Mit Zusicherungen (wird derzeit in C / C++ durch assert() realisiert,
in Zukunft ggf. anders) wird NIEMALS eine Behandlung von externen
Fehlern
durchgeführt: externe Fehler sind bspw. fehlerhaften Daten in einer
Datei oder
DB, falsche Benutzereingaben, Netzwerkabbruch, ... Wenn Du möchtest
kannst Du
diese externen Fehler noch in erwartbare und nicht-erwartbare
unterteilen, und
anhand dieser Unterschiedung kannst Du ggf. die Art der Fehlerbehandlung
unterscheiden: etwa Exceptions für nicht-erwartbare Fehler und
Rückgabewert
mit additiven Datentypen wie etwa std::optional<> für erwartbare Fehler.
Fehler in externen Daten sind ganz normaler Input für ein Programm und
die
Verarbeitung dieser (fehlerhaften) Daten ist ganz normaler
Programmablauf.
Aber die obige Unterscheidung spielt hier jetzt keine Rolle.
Das hat ja nichts mit Zusicherungen zu tun.
Zusicherungen stellen sicher, dass der die Programmierer keine
weniger
logische interne Fehler in die SW einbaut. Das Aufrufen einer Funktion
mit
den richtigen Parametern ist Verantwortung der Aufrufers (Caller), die
aufgerufene
Funktion (Callee) überprüft trotzdem in Form von sog. Vorbedingungen
(einer der
verschiedenen Einsatzzwecke von assert()) diese Vorbedingungen. Stell
Dir das so vor,
dass Programmierer A den Caller schreibt und Programmierer B den Callee.
Beide
gehen einen Vertrag dabei ein über die Argumente / Parameter. Gewisse
Dinge
kann der Compiler statisch prüfen z.B. die Signatur oder zur
Compile-Zeit
bekannte Werte. Alles andere kann erst zur Laufzeit geprüft werden. Es
ist aber
genauso schlimm: die SW hat einen fundamentalen Fehler! Diese Fehler
wird leider
erst zur Laufzeit aufgedeckt, aber da das Programm hier nun
nachgewiesenermaßen
inkorrekt in sich selbst ist, muss es abgebrochen werden. Es ist
gewissermaßen ein Fehler, der eigentlich zur Compilezeit aufgedeckt
werden sollte, aber bei der heutigen Technik erst zur Laufzeit
aufgedeckt wird. Daher ist die einzig sinnvolle Maßnahme hier ein
Programmabbruch.
In der Produktionsversion der SW werden die assert()-Anweisungen sowieso
durch den CPP entfernt. Dort werden also gar keine Zusicherungen
geprüft, und können demzufolge das Programm nicht abbrechen. Damit
verschwindet die Vorbedingung natürlich nicht aus dem Code, sie ist
immer noch vorhanden, aber sie hat andere Konsequenzen (ob dann ein
Abbruch erfolgt oder ein falsches Ergebnis berechnet
wird, hängt von der Art des Fehlers ab. Bricht das Programm ab, ist das
gut, läuft es mit dem unentdeckten Fehler weiter (etwa: falscher Preis
für ein Produkt) ist das schlecht).
Konstruiertes Beispiel:
1
constUserData*data=processUserInput(...);
2
constResultresult=evaluateData(data);
Die erste Funktion liest die Daten (User-Input, Netzwerkdaten,
Messwerte, ...) und
bringt sie von der externen in eine interne Form (DT UserData), sofern
sie das kann.
Falsche externe Daten führen hier als erwartbarer Fehler zu einem
nullptr-Rückgabewert.
Leider ist der Vertrag zwischen den Funktionen verletzt:
1
ResultevaluateData(constUserData*constdata){
2
Resultresult;
3
assert(data);
4
for(UserData*it=data;*data;++data)
5
result.featureA(computeA(*data));
6
}
7
returnresult;
8
}
Dummerweise verlangt evaluateData() einen Zeigerwert != nullptr, d.h.
hier gehört nullptr
nicht zum Wertebereich des Parameters data. Denn die Dereferenzierung im
Kopf des for()-stmts
führt zu einem Abbruch. D.h. der Code IN der Funktion verlangt ab einem
gewissen Punkt
(direkt vor der Schleife) dass data != nullptr ist. Diese Bedingung muss
immer gelten (daher
nennt man das Invariante). Diese Invariante ist hier (in diesem
Beispiel) identisch mit
der Vorbedingung bzgl. des Paranmeterwertes data.
BTW: dies ist natürlich letztlich ein Designfehler: anstatt eine
nullable-Referenz nämlich
einen Zeiger zu nehmen, wäre hier einen non-nullable-Referenz nämlich
eine C++-Referenz
richtig gewesen. Aber manchmal muss man ja nehmen, was man vorfindet ;-)
Der interne Fehler ist in der Verantwortung des Callers, der umgebenden
Funktion, die beide
Operationen verkettet. Hier hätte die Behandlung des externen Fehlers
stattfinden müssen:
1
constUserData*data=processUserInput(...);
2
if(!data){
3
// ... Fehlerbehandlung
4
exit(1);
5
}
6
constResultresult=evaluateData(data);
Ggf. kann man diese auch noch im Caller explizit dokumentieren:
1
constUserData*data=processUserInput(...);
2
if(!data){
3
// ... Fehlerbehandlung
4
exit(1);
5
}
6
7
assert(data);// Kommentar, der tatsächlich überprüft wird
8
constResultresult=evaluateData(data);
Bei den Tests der Software wird nun dieser Fehler auftauchen, sofern die
Tests auch mit
falschen externen Daten durchgeführt werden. Das Schöne dabei ist, dass
die Fehlermeldung
dann auch die Zeilennummer und Dateiname enthält. Ohne die Assertion
wäre eine unspezifische
segmentation violation die Folge; zum Glück bei diesem Fehler sogar
definitiv, dass liegt
aber daran, dass das Beispiel sehr sehr einfach ist (s.o.).
Sorry für den langen Text: ich hatte keine Zeit, mich kürzer zu fassen.
Zombie schrieb:> Rolf M. schrieb:>> Da es hier um einen programminternen logischen Fehler geht (z.B. deiner>> Variable, die im Bereich 0 bis 99 liegen muss, soll jetzt plötzlich 120>> zugewiesen werden), gibt es keinen sinnvollen Weg, das zu behandeln. Du>> hast eigentlich in dem Fall nur drei Möglichkeiten:>> 1. Geordneter Rückzug, also Programm beenden>> 2. Schreibzugriff unterdrücken - dann steht aber ein falscher Wert in>> der Variable>> 3. Schreibzugriff trotzdem durchführen - dann steht aber ein illegaler>> Wert in der Variable>> Was passiert bei?>
1
>chara=1234;
2
>
> -> undefined behavior> das würde ich auch für>
1
>int<-128,127>a=1234;
2
>
> erwarten. das sagt dem Compiler lediglich, dass er platz für Ganzzahlen> zwischen -128 und 127 bereitstellen soll. Diesen Bereich nicht zu> verlassen liegt dann in der Verantwortung des Programmierers.
Die Initialisierung
1
chara=1234;
ist natürlich kein UB.
Es handelt sich hier um eine gültige Integerkonvertierung.
Daher schreibt man die Initialisierung besser als
1
chara{1234};
Dann erhält man einen Compilezeit-Fehler.
1
int<-128,127>a=1234;
ergibt natürlich auch kein UB, sondern einen Assertionsfehler, wenn
das ein UDT ist, ansonsten sollten wir die Sprache ja so erweitern, dass
es kein UB ist, sondern eine interne Assertion feuert.
Nano schrieb:> 1-3 bedeutet behandeln. Was meinst du was das ist?
1 terminert das Programm, 2 und 3 hinterlässt es in einem inkonsistenten
Zustand, in dem es eigentlich nicht sein darf. Behandeln bedeutet für
mich sinnvoll damit umgehen, aber es gibt keine Möglichkeit, sinnvoll
damit umzugehen.
> Mal angenommen du hast Höhendaten vom Satellit und willst das mit einer> anderen Karte kombinieren. Dann ist ein Wolkenkratzer ein Spike, der da> nicht in die Bodenleveldaten hingehört.> Also kannst du das behandeln und bspw. mit den umgebenden Daten> nivellieren. Die Daten werden nicht perfekt sein, aber für einen> Flugsimulator reicht's.
Das ist dann aber ein Fehler in den Daten und nicht im Programm.
> Wie schon gerade beschrieben, es kommt ganz darauf an.
Ja, genau. Ich hab das Gefühl, wir reden an einander vorbei. Ich
unterscheide zwischen logischen Fehlern im Programm und Fehlern im
Input. Ersterer kann normalerweise nicht sinnvoll behandelt werden,
letzterer natürlich schon - und sollte auch.
Wilhelm M. schrieb:> Also statt double etwa Distance<Km>, was man dann durch Duration teilen> kann, und dann kommt Velocity dabei heraus, und eben nicht ein> semantikfreier double-Wert.
Das hat durchaus einen gewissen Charme, wobei ich die Einheit vom Typ
trennen würde. Ich habe letztens an einer Sprache mitgearbeitet, die
bereits einen eingebauten Mechanismus für physikalische Typen hat.
Einheiten für diese Typen kann man sich dann separat definieren. Da geht
dann sowas (in der Syntax dieser Sprache):
1
distance: length = 100km
2
duration: time = 1hour
3
my_speed: speed = distance / duration
statt 1hour kann ich z.B. genauso gut auch 60min schreiben oder die
distance in Meilen angeben. Beim Auslesen muss man natürlich dann
angeben, in welcher Einheit man's haben will. Die Umrechnung erfolgt
automatisch. Auch die lästige Unterscheidung zwischen rad und Grad
fällt z.B. weg.
In C++ sollte sich das nachbilden lassen, allerdings im Vergleich
vermutlich recht umständlich.
W.S. schrieb:> Rolf M. schrieb:>> Was du bisher nicht plausibel erklären konntest ist, warum es überhaupt>> eine Rolle spielt, ob uint32_t nun im Sprachkern oder einem>> Standardheader umgesetzt ist.>> Dann erkläre ich es dir: jeder könnte sich eine Headerdatei schreiben> und sich Namen nach eigenem Gusto für die im Sprachstandard enthaltenen> Variablentypen selber machen.
Deine Erklärung enthält nur das, was du hier gebetsmühlenartig
wiederholst, aber es beantwortet die Frage nicht. Warum ist das für
dich so ein riesiges Problem? Natürlich kann ich mir auch selbst einen
Header schreiben und mir irgendwelche eigenen Namen für die Typen
ausdenken und dann ggf. für jeden Compiler, mit dem ich arbeite, einzeln
anpassen. Nur, warum sollte ich das tun, wenn der Compiler bereits einen
Standardheader liefert, der genau das schon fix und fertig enthält? Die
Funktion sin() ist ebenfalls Teil der Standardbibliothek und kann über
einen Header verfügbar gemacht werden. Die könnte ich auch selber
schreiben, aber ich tue es nicht, da der Compiler sie ja schon
mitbringt. Wo ist da jetzt der Unterschied zu Typen wie uint32_t?
> In der Vergangenheit wurde das ja auch sehr häufig gemacht.
Ja, weil stdint.h nicht von Anfang an im Standard war und man daher
gezwungen war, es selbst zu machen. Und wie man ja am Titel des Thread
sieht, ist C89 auch noch ziemlich lange in vielen Projekten die Basis
gewesen. stdint.h wurde erst mit C99 im Standard aufgenommen.
Bei heute neu gestarteten Projekten sehe ich eher, dass auf den
Standardheader zurückgegriffen wird. Warum auch nicht? Es wäre ja recht
blödsinnig, dieses vorhandene Feature nicht zu nutzen.
> Sowas wie uint32_t ist genauso gut oder schlecht wie U32 oder DWORD und> da das alles auf 'int' mit diversen Prädikaten (long, signed usw.)> zurückgeführt wird, wozu eben zumeist besagte Headerdateien dienen, ist> so etwas nicht zum Sprachstandard gehörig.
Der Standard ist ein offiziell von der ISO veröffentlichtes Dokument, in
dem das schwarz auf weiß drin steht. Unter
https://www.open-std.org/jtc1/sc22/wg14/www/docs/n2731.pdf kannst du den
aktuellsten Draft finden. Kapitel 7.20 definiert den Header <stdint.h>.
Wie kannst du da behaupten, es sei nicht Teil des Standards?
> Man könnte es auch grob so sagen: was nicht der Compiler von sich aus> versteht, das gehört auch nicht zum Sprachumfang.
Ich würde sagen: Es gehört nicht zum Sprachkern. Die Standardbibliothek
setzt auf diesen auf und gehört aber selbstverständlich zur Sprache
dazu.
Zombie schrieb:> Was passiert bei?> char a = 1234;> -> undefined behavior
Es werden alle Bits, die nicht in den Typ passen, abgeschnitten. Kein
UB.
> das würde ich auch für> int<-128,127> a = 1234;> erwarten. das sagt dem Compiler lediglich, dass er platz für Ganzzahlen> zwischen -128 und 127 bereitstellen soll.
Wenn das das angestrebte Ziel ist, kann man das natürlich machen. Und es
hätte durchaus seine Vorteile, denn den Programmierer interessiert in
vielen Fällen nicht die konkrete Anzahl an Bits, die der Typ hat,
sondern der Wertebereich, den er abdecken können muss.
Jemand schrieb:> Nano schrieb:>> Mal angenommen du hast Höhendaten vom Satellit und willst das mit einer>> anderen Karte kombinieren. Dann ist ein Wolkenkratzer ein Spike, der da>> nicht in die Bodenleveldaten hingehört.>> Also kannst du das behandeln und bspw. mit den umgebenden Daten>> nivellieren. Die Daten werden nicht perfekt sein, aber für einen>> Flugsimulator reicht's.>> Vielleicht magst du noch einmal erläutern, welche Verwendung ein hart im> Wertebereich eingeschränkter Typ für erwartbar abweichende Daten hat.> Die Unterstellung, dass Wilhelm in diesem Fall einen solchen Typ> verwenden würde, halte ich doch für ziemlich abwegig.
Hier verweise ich jetzt einfach mal auf mein obigen, längeren Post.
Wenn Messwerte einen Bereich von [0, 1024[ haben (der Sensor kann nichts
anderes liefern) und man dafür einen DT wie int<0, 1023> verwendet, dann
ist das absolut ok, weil der Sensor keine anderen Werte liefern kann,
egal ob das jetzt im normativen Bereich liegt, oder eine Störung durch
eine Einstrahlung ist.
Rolf M. schrieb:> In C++ sollte sich das nachbilden lassen, allerdings im Vergleich> vermutlich recht umständlich.
Dafür gibt es mittlerweile schöne Bibliotheken:
Rolf M. schrieb:> Zombie schrieb:>> Was passiert bei?>> char a = 1234;>> -> undefined behavior>> Es werden alle Bits, die nicht in den Typ passen, abgeschnitten. Kein> UB.>>> das würde ich auch für>> int<-128,127> a = 1234;>> erwarten. das sagt dem Compiler lediglich, dass er platz für Ganzzahlen>> zwischen -128 und 127 bereitstellen soll.>> Wenn das das angestrebte Ziel ist, kann man das natürlich machen. Und es> hätte durchaus seine Vorteile, denn den Programmierer interessiert in> vielen Fällen nicht die konkrete Anzahl an Bits, die der Typ hat,> sondern der Wertebereich, den er abdecken können muss.
S.o.:
Beitrag "Re: Linux ist endlich vom C89 Standard weg"
Rolf M. schrieb:> Ich würde sagen: Es gehört nicht zum Sprachkern. Die Standardbibliothek> setzt auf diesen auf und gehört aber selbstverständlich zur Sprache> dazu.
Ihr redet immer noch aneinander vorbei:
der eine meint den Sprachstandard, und dieser ISO-Standard normiert die
Kern-Sprache (dort language genannt), die Heaader, die Bibliothek, ...
der andere meint einfach nur die Kern-Sprache (language im Standard).
Solange Ihr das unter Euch nicht klärt, bleibt der Dissens.
Wilhelm M. schrieb:> Rolf M. schrieb:>> In C++ sollte sich das nachbilden lassen, allerdings im Vergleich>> vermutlich recht umständlich.>> Dafür gibt es mittlerweile schöne Bibliotheken:> auto d = 42_km;> auto t = 3_min;> ist in C++ möglich (und mittlerweile üblich).
Was ich mit "recht umständlich" meinte, ist der Code, der dafür sorgt,
dass das geht. Wie leicht kann ich da meine eigenen Typen hinzufügen?
Wie sieht es mit dem Hinzufügen zusätzlicher Einheiten zu einem
bestehenden Typ aus (natürlich nicht nur für Literals)?
Wilhelm M. schrieb:> Solange Ihr das unter Euch nicht klärt, bleibt der Dissens.
Das Problem ist, dass W.S. den Standard mit dem Sprachkern gleichsetzt
und die Standardbibliothek offenbar nicht als Teil des Standards
betrachtet, weil man sich als Anwender der Sprache ja was vergleichbares
selber schreiben könnte. Und diese Ansicht finde doch reichlich seltsam.
Rolf M. schrieb:> Wilhelm M. schrieb:>> Rolf M. schrieb:>>> In C++ sollte sich das nachbilden lassen, allerdings im Vergleich>>> vermutlich recht umständlich.>>>> Dafür gibt es mittlerweile schöne Bibliotheken:>> auto d = 42_km;>> auto t = 3_min;>> ist in C++ möglich (und mittlerweile üblich).>> Was ich mit "recht umständlich" meinte, ist der Code, der dafür sorgt,> dass das geht. Wie leicht kann ich da meine eigenen Typen hinzufügen?> Wie sieht es mit dem Hinzufügen zusätzlicher Einheiten zu einem> bestehenden Typ aus
Ich denke, die bekannteste bzw. zukunftsträchtigste Implementierung (es
gibt einige) ist:
https://github.com/mpusz/units
Hier hast Du die kompletten SI-Einheiten, so dass der Bedarf nach
Erweiterung gering sein sollte.
> (natürlich nicht nur für Literals)?
Naja, wenn Du UDL einsetzt, brauchst Du ja wohl einen sinnvollen
Ergebnistyp, sonst ist das ja Quatsch.
Rolf M. schrieb:> Wilhelm M. schrieb:>> Solange Ihr das unter Euch nicht klärt, bleibt der Dissens.>> Das Problem ist, dass W.S. den Standard mit dem Sprachkern gleichsetzt> und die Standardbibliothek offenbar nicht als Teil des Standards> betrachtet, weil man sich als Anwender der Sprache ja was vergleichbares> selber schreiben könnte. Und diese Ansicht finde doch reichlich seltsam.
Deswegen hatte ich ja in
Beitrag "Re: Linux ist endlich vom C89 Standard weg"
explizit auf den Standard verwiesen: dort gibt es keine Diskussion, der
Standard schließt die Header, Bib, ... mit ein.
W.S. meint den Sprachkern (language): dann hat er Recht mit seinen
Aussagen.
Du meinst den Standard: dann hast auch Du Recht mit Deinen Aussagen.
Hier der Link:
https://www.open-std.org/jtc1/sc22/wg14/www/docs/n1548.pdf
Rolf M. schrieb:> Deine Erklärung enthält nur das, was du hier gebetsmühlenartig> wiederholst, aber es beantwortet die Frage nicht. Warum ist das für> dich so ein riesiges Problem? Natürlich kann ich mir auch selbst einen> Header schreiben und mir irgendwelche eigenen Namen für die Typen> ausdenken und dann ggf. für jeden Compiler, mit dem ich arbeite, einzeln> anpassen.
Also erstens: Für MICH ist das alles überhaupt kein Problem.
Und zweitens: Stefan hat es bis heute noch nicht kapiert, deswegen
versuche ich wiederholt, ihm klarzumachen, was an seiner Denke falsch
ist, auch wenn Mawin mal dazwischengesprungen ist.
Ursprung:
"Kennst du uint8_t uint16_t uint32_t und Verwandte nicht?"
W.S.
W.S. schrieb:> Rolf M. schrieb:>> Deine Erklärung enthält nur das, was du hier gebetsmühlenartig>> wiederholst, aber es beantwortet die Frage nicht. Warum ist das für>> dich so ein riesiges Problem? Natürlich kann ich mir auch selbst einen>> Header schreiben und mir irgendwelche eigenen Namen für die Typen>> ausdenken und dann ggf. für jeden Compiler, mit dem ich arbeite, einzeln>> anpassen.>> Also erstens: Für MICH ist das alles überhaupt kein Problem.
Warum reitest du dann ständig darauf rum? Jedem hier ist bekannt, dass
<stdint.h> ein Header ist und dass man Header-Dateien auch selber
schreiben kann.
> Und zweitens: Stefan hat es bis heute noch nicht kapiert, deswegen> versuche ich wiederholt, ihm klarzumachen, was an seiner Denke falsch> ist, auch wenn Mawin mal dazwischengesprungen ist.> Ursprung:> "Kennst du uint8_t uint16_t uint32_t und Verwandte nicht?"
Ja, als Antwort auf
"Nicht einmal eine saubere Größenfestlegung für Integers ... haben die
in den letzten 30 Jahren hingekriegt."
Und das ist eben falsch. Solche Integers wurden in Form von typedefs vor
33 Jahren im Standard aufgenommen und sind seitdem bei jedem
standardkonformen Compiler mit dabei. Man muss sie lediglich per
#include <stdint.h> aktivieren. Das scheinst du aber aus irgendeinem
Grund nicht akzeptieren zu wollen. Selbst wenn man dir die Stelle im
Standard, wo das definiert ist aufzeigt, behauptest du felsenfest, das
gehöre nicht zum Standard.
Eine Frage: Gibt es für dich in Standard-C auch keinen Weg, Text
auszugeben, weil printf() ebenfalls zur Standardbibliothek gehört und
nicht wie z.B. das Pascal-Pendant Teil des Sprachkerns ist?
Wilhelm M. schrieb:> Die Initialisierung> char a = 1234;> ist natürlich kein UB.> Es handelt sich hier um eine gültige Integerkonvertierung.Rolf M. schrieb:> Es werden alle Bits, die nicht in den Typ passen, abgeschnitten. Kein> UB.
Anscheinend habt ihr recht. Das gilt nur für Überlauf durch
Berechnungen. Wieder etwas gelernt.
Zombie schrieb:> signed char b = 127;> ++b;> // UB
Eigentlich auch nicht, auf Grund der Integer-Promotion. Die Berechnung
wird in int durchgeführt. Es wird also erst b auf int erweitert, dann ++
gerechnet, dann das Ergebnis wieder zurück konvertiert.
Rolf M. schrieb:> Eigentlich auch nicht, auf Grund der Integer-Promotion. Die Berechnung> wird in int durchgeführt. Es wird also erst b auf int erweitert, dann ++> gerechnet, dann das Ergebnis wieder zurück konvertiert.
Jetzt bin ich verwirrt. Unter welchen Bedingungen ist ein "signed
integer overflow" denn UB?
W.S. schrieb:> Also erstens: Für MICH ist das alles überhaupt kein Problem.
Anscheinend ja doch, da du es offenbar nötig hast ständig Nebelkerzen zu
zünden, um von deinem ursprünglichen Irrtum, von dem alles ausging,
abzulenken:
Rolf M. schrieb:>> "Kennst du uint8_t uint16_t uint32_t und Verwandte nicht?">> Ja, als Antwort auf> "Nicht einmal eine saubere Größenfestlegung für Integers ... haben die> in den letzten 30 Jahren hingekriegt.">> Und das ist eben falsch. Solche Integers wurden in Form von typedefs vor> 33 Jahren im Standard aufgenommen
An dieser Stelle hättest du sagen können: Ok, ich lag falsch. Danke für
die Korrektur, jetzt bin ich schlauer geworden.
Stattdessen hast du eine irrwitzige Argumentationskette mit Sprache,
Sprachstandard und Standardlibrary angefangen, die sowieso nur in deinem
Kopf einen Sinn ergibt.
Fakt ist, dass fixed size Integers (und vieles mehr) standardisiert sind
und jeder Compiler sie liefern muss.
Ob das in einem Header oder sonst wo passiert, spielt überhaupt keine
Rolle.
Wilhelm M. schrieb:> Die Initialisierung> char a = 1234;> ist natürlich kein UB.> Es handelt sich hier um eine gültige Integerkonvertierung.
Ich muss das hier nochmal das etwas genauer schreiben: weil bei `char`
es implementation-defined ist,
ob `char` nun `signed char` oder `unsigned char` ist, macht es das ggf.
etwas komplizierter (`char` habe N Bits):
`unsigned char`:
es findet eine Initialisierung mit den unteren N Bits der rhs statt
(modulo-N)
`signed char` bei C / C++ < c++20:
das Ergebnis ist implementation-defined (kein UB)
`signed char` bei C++ >= c++20:
es findet eine Initialisierung mit den unteren N Bits der rhs statt und
die werden
als N-Bit 2er-Komplement interpretiert (alle Ganzzahltypen sind
2er-Komplement seit C++20)
Die nä. Frage war nach signed-integer-overflow (unsigned-integer
overflow ist well-defined):
1
int8_tx=std::numeric_limits<int8_t>::max();
2
++x;// signed-integer overflow -> UB
Haben wir `signed char`, dann kann `++a` oder `a++` potentiell ein
integer-overflow auftreten, was dann UB (NDR)
ist. Dies kann man in einem constexpr-Ausdruck testen, denn dann muss(!)
das UB einem Fehler ergeben.
Der GCC macht das auch (der clang leider nicht???).
Da `++a` (und `a++`) lt. Standard exakt gleich zu `a += 1` ist, ist das
dann auch UB. Hier versagt auch der GCC im o.g. constexpr-Kontext.
Bei `a = a + 1` haben wir auf der rechten Seite zunächst eine
Integralpromotion auf `int` (das kann je nach
data-model 16, 32 oder 64 Bit sein) und dann kann ein Overflow
stattfinden (ggf. erst bei 2^64-1).
Bei der Zuweisung gilt dann dasselbe wie oben, also bei C / C++ < c++20
ist es implementation-defined, ab
c++20 dann eine N-Bit-Konvertierung ins 2er-Komplement.
Wilhelm M. schrieb:> Da `++a` (und `a++`) lt. Standard exakt gleich zu `a += 1` ist, ist das> dann auch UB.
Bist du dir da sicher?
Ist es nicht eher äquivalent zu `a = a + 1`?
MaWin schrieb:> Wilhelm M. schrieb:>> Da `++a` (und `a++`) lt. Standard exakt gleich zu `a += 1` ist, ist das>> dann auch UB.>> Bist du dir da sicher?> Ist es nicht eher äquivalent zu `a = a + 1`?
Dachte ich eigentlich auch, doch:
https://en.cppreference.com/w/cpp/language/operator_incdec
Ja, ich weiß, dass ist nicht der Standard selbst ... für genauere
Recherche fehlte mir die Zeit gerade
Standard: "The expression ++E is equivalent to (E+=1)."
Beim Postfix-Operator besteht keine Alternative.
Bei E = E + 1 wird E zweimal ausgewertet, ist also nicht äquivalent.
Denn *p++ += 1 ist nicht äquivalent zu *p++ = *p++ + 1.
(prx) A. K. schrieb:> Standard: "The expression ++E is equivalent to (E+=1)."> Beim Postfix-Operator besteht keine Alternative.
Da sagt der Standard, dass (E+=1) als Seiteneffekt des Ausdrucks (E++)
stattfindet (as-if rule).
Wilhelm M. schrieb:> Haben wir `signed char`, dann kann `++a` oder `a++` potentiell ein> integer-overflow auftreten, was dann UB (NDR) ist.
Ich weiß nicht, ob es in C++ anders ist, aber den C-Standard lese ich
so, dass das nicht der Fall ist. Zumindest für Präfix-++ gilt das:
(prx) A. K. schrieb:> Standard: "The expression ++E is equivalent to (E+=1)."
Und wenn man sich das Kapitel zu compound assignment anschaut, steht da
wiederum:
"A compound assignment of the form E1 op= E2 differs from the simple
assignment expression E1 = E1 op (E2) only in that the lvalue E1 is
evaluated only once."
Das bedeutet also, das bis auf die fehlende mehrfach-Evaluation ++a
äquivalent ist zu a = a + 1, das aber kein UB ist.
> Dies kann man in einem constexpr-Ausdruck testen, denn dann muss(!)> das UB einem Fehler ergeben.> Der GCC macht das auch (der clang leider nicht???).
Ggf. ist es der GCC, der hier falsch liegt.
Rolf M. schrieb:> Und wenn man sich das Kapitel zu compound assignment anschaut, steht da> wiederum:> "A compound assignment of the form E1 op= E2 differs from the simple> assignment expression E1 = E1 op (E2) only in that the lvalue E1 is> evaluated only once."> Das bedeutet also, das bis auf die fehlende mehrfach-Evaluation ++a> äquivalent ist zu a = a + 1, das aber kein UB ist.
Wenn a vom Typ int8_t ist, dann ist (a + 1) immer UB frei (wegen
integer-promo kein overflow)
Wenn a vom Typ int (oder größer), dann ist (a + 1) bei overflow UB.
Das ist in C und C++ gleich.
Der Unterschied besteht nur bei einer signed-integer-conversion: die ist
implementation-defined, nur bei C++ ab C++20 ist das well-defined, weil
da alle integer-Type 2er Komplemente sein müssen.
(prx) A. K. schrieb:> Bei E = E + 1 wird E zweimal ausgewertet, ist also nicht äquivalent.> Denn *p++ += 1 ist nicht äquivalent zu *p++ = *p++ + 1.
Ihr kreischt ja noch immer.
Naja, wer partout immer alles in möglichst wenige Zeichen zusammenfassen
will, muß sich auch um Nebeneffekte kümmern. Und darum, daß selbige sich
bei doppelter Verwendung auch zweimal einstellen.
Und nun? Tun sich neue Paradiese auf, wenn der Linux-Kernel mit einem
"brandneuen" C übersetzt wird? Oder ist es (für euch) eher der Eingang
in die Hölle? Oder passiert überhaupt nix?
W.S.
W.S. schrieb:> (prx) A. K. schrieb:>> Bei E = E + 1 wird E zweimal ausgewertet, ist also nicht äquivalent.>> Denn *p++ += 1 ist nicht äquivalent zu *p++ = *p++ + 1.>> Ihr kreischt ja noch immer.> Naja, wer partout immer alles in möglichst wenige Zeichen zusammenfassen> will, muß sich auch um Nebeneffekte kümmern. Und darum, daß selbige sich> bei doppelter Verwendung auch zweimal einstellen.
Leider Thema verfehlt.
Nano schrieb:> Wenn du das in deiner Schnittstelle überprüfst, was Performance kosten> wird, dann kannst du auf den Fehler eingehen und den behandeln, sofern> es behandelbar ist. Der Nutzer deiner Schnittstelle müsste sich dann> nicht darum kümmern, da es ja deine Schnittstelle schon macht.
Entwickler machen sich viel häufiger Gedanken über Performance, als es
in der Praxis aus sachlichen Gründen auf deren Verbesserung oder
Maximierung ankommt. Darum haben die interpretierten Sprachen in der
Praxis auch fast überall gewonnen, und nach den einschlägigen
Programmiersprachenindizes sind die interpretierten Sprachen Java und
Python heute die beliebtesten und verbreitetsten Sprachen der Welt. (Das
ist in der Mikrocontrollerwelt, um die es hier ja geht, zwar (noch?)
nicht so, aber auch hier scheinen einige Benutzer besondere Verträge mit
den Herstellern zu haben, auf deren Basis sie für ungenutzte Ressourcen
Geld zurück bekommen...) ;-)
Karl Käfer schrieb:> Entwickler machen sich viel häufiger Gedanken über Performance, als es> in der Praxis aus sachlichen Gründen auf deren Verbesserung oder> Maximierung ankommt. Darum haben die interpretierten Sprachen in der> Praxis auch fast überall gewonnen, und nach den einschlägigen> Programmiersprachenindizes sind die interpretierten Sprachen Java und> Python heute die beliebtesten und verbreitetsten Sprachen der Welt.
Die sind verbreitet, weil die Entwickler für Firmen günstig sind, die
Newbs damit schnell zu recht kommen und die Auftraggeber die Software
möglichst kostengünstig haben wollen.
Mit beliebt hat das somit nur wenig zu tun, gut, für Newbs mag das
anders aussehen, aber die mögen bzw. mochten ja auch Basic.
Erfahrene Entwickler würden lieber in Rust oder C++ programmieren,
manche auch in C.
>(Das> ist in der Mikrocontrollerwelt, um die es hier ja geht, zwar (noch?)> nicht so, aber auch hier scheinen einige Benutzer besondere Verträge mit> den Herstellern zu haben, auf deren Basis sie für ungenutzte Ressourcen> Geld zurück bekommen...) ;-)
Da muss man ja auch ressourcensparend programmieren weil so mancher µC
nur ein paar KB hat.
Vielleicht ändert sich das mal mit neuen Speichertypen um das klassische
RAM zu ersetzen. Arbeitsspeicher der keinen Strom braucht und dabei die
Daten halten kann und trotzdem schnell wie normales RAM ist und sich gut
fertigen lässt und wenig Chipfläche benötigt und beliebig viele Schreib-
und Lesezyklen erlaubt. Dann wird es nicht lange dauern und die µC
werden mit MB an solchem Arbeitsspeicher ausgeliefert und dann darfst du
in bspw. Java oder Python programmieren.
Nano schrieb:> Erfahrene Entwickler würden lieber in Rust oder C++ programmieren,> manche auch in C.
Ich mochte Perl mehr als Python, aber Python hat die bessere
Infrastruktur inzwischen.
Jeder Aufgabe ihr Tool. Alles, was ich mittlerweile in Python so gemacht
habe, hätte ich unmöglich im gleichen Zeitrahmen mit C++, C oder Rust
machen können. Allein der Interpreter, bei dem man mal fix auf der
Kommandozeile ein paar Dinge austesten kann, um sie dann mit copy&paste
ins aktuelle Projekt zu übernehmen, ist mehr als hilfreich.
> Vielleicht ändert sich das mal mit neuen Speichertypen um das klassische> RAM zu ersetzen.
Auch mit "klassischem RAM" gibt es inzwischen genügen MCUs, die man mit
microPython programmieren kann, angefangen bei den ESPs. Aber auch die
diversen Einsteigerboards wie micro:bit oder Calliope sind nett, und sie
eröffnen die Welt der Controllerprogrammierung einer
Zielgruppe/Altersklasse, die man mit "nacktem C" nie hätte erreichen
können.
🐧 DPA 🐧 schrieb:> Freischalten von Funktionen von HW, die einem bereits gehört.> Proprietäre Firmware. Signieren von Firmware, ohne dem Nutzer eine> Möglichkeit zu geben, seien eigene Firmware mit einem eigenen Key zu> signieren. Das gehört alles verboten!
Nein das gehört nicht verboten. Das nennt sich Marktwirtschaft. Machen
wir auch so weil es einfacher ist als 10 verschiedene Hardwareversionen
zu entwickeln und wir machen nur Platinen. Das wird bei Halbleitern
nicht besser. Die Entwicklung der Zeitaufwand in der Fab ist eh der
gleiche.
Hannes B. schrieb:> Machen> wir auch so weil es einfacher ist als 10 verschiedene Hardwareversionen> zu entwickeln
Ja.
Aber warum
>> ohne dem Nutzer eine>> Möglichkeit zu geben, seien eigene Firmware mit einem eigenen Key zu>> signieren.
?
Dir gehört ein bestimmtes Produkt, bestehend aus einer Kombination von
HW und SW, mit einer bestimmten gekauften Funktionalität. Wie das
implementiert wird, ist Sache des Herstellers.
(prx) A. K. schrieb:> Dir gehört ein bestimmtes Produkt, bestehend aus einer Kombination von> HW und SW, mit einer bestimmten gekauften Funktionalität. Wie das> implementiert wird, ist Sache des Herstellers.
Das ist mir schon klar.
Und ja, ich muss den Kram nicht kaufen.
Aber trotzdem könnte man es mir ja mal verständlich erklären, warum
diese Verrammelung notwendig ist?
Dass viele Hersteller ihre Crypto nicht im Griff haben, sieht man
derzeit mal wieder eindrucksvoll an dem EC-Terminal-Chaos.
Wenn ein Hersteller das Produkt vor mir verschließt, dann habe ich halt
Bedenken, dass er irgendwann entscheidet mir das Produkt abzustellen.
Aus welchem Grund auch immer. Als Unfähigkeit (EC-Karte), oder mutwillig
(Supportende. jetzt kannst du es halt nicht mehr nutzen. Kaufen Sie
unser neues Produkt!).
Ich sehe da bei den allermeisten Produkten keinen Nachteil für den
Hersteller, wenn der Hersteller es mir freistellt, eigene Software
aufzuspielen.
MaWin schrieb:> Ich sehe da bei den allermeisten Produkten keinen Nachteil für den> Hersteller, wenn der Hersteller es mir freistellt, eigene Software> aufzuspielen.
Du willst die Viren und Trojaner im Microcode des Prozessors haben, und
nicht in den Ebenen da drüber?
Mutig ;)
Oliver
Oliver S. schrieb:> Du willst die Viren und Trojaner im Microcode des Prozessors haben, und> nicht in den Ebenen da drüber?
Warum sollte ich die da einspielen?
Und warum sollte das ein Argument dagegen sein, mir die Möglichkeit zu
geben eigenen Code zu signieren?
Und außerdem haben wir die Trojaner lange in den Intel- und AMD-CPUs
drin. Da laufen ganze Betriebssysteme (Minix) drin mit vollem System-
und Netzwerkzugriff.
Ich brauche keine Bemutterung von den Herstellern. Ich bin selbst in der
Lage zu entscheiden, was bei mir laufen soll und darf.
MaWin schrieb:> Ja.> Aber warum
Es geht hier um zwei verschiedene Dinge.
Die einen sprechen davon, dass man dem Kunden "mehr" ausliefert, aber
die Funktionalitäten dann sperrt. Sei das Silizum, oder
Softwarefunktionen, die nur mit gültiger Lizenz laufen.
So wie ich dich verstehe geht es dir aber darum, dass du ein Gerät
kaufst und darauf deine eigene Software laufen lassen möchtest.
Meiner Erfahrung nach verbieten das viele Firmen aus Angst, dass sie
sich so Wettbewerbsnachteile erschaffen könnten oder auch Bedenken vor
Betrug. Wenn du deine eigene Firmware drauf flashst und das Gerät geht
deswegen kaputt, dann müssen sie dir erst nachweisen, dass du eine
andere Firmware darauf geladen hast.
Operator S. schrieb:> dann müssen sie dir erst nachweisen, dass du eine> andere Firmware darauf geladen hast.
Das ist doch trivial.
Ich habe nichts gegen Ausleseschutz der Firmware und Modifikationsschutz
der Originalfirmware.
Aber es sollte immer möglich sein die Firmware zu löschen und komplett
neu anzufangen.
Diese Möglichkeit geht aber immer mehr und mehr verloren.
MaWin schrieb:> Diese Möglichkeit geht aber immer mehr und mehr verloren.
???
Bei 99,99999% aller kaufbaren Geräte, in denen eine Firmware steckt, ist
diese Möglichkeit nicht verloren gegangen, weil es die da nie gegeben
hat.
Oliver
(prx) A. K. schrieb:> Dir gehört ein bestimmtes Produkt, bestehend aus einer Kombination von> HW und SW, mit einer bestimmten gekauften Funktionalität. Wie das> implementiert wird, ist Sache des Herstellers.
Mir gehört nicht nur die Kombination / das Paket, von dem, was ich
Kaufe. Mir gehört jeder Teil, jedes Atom von dem, was ich kaufe. Der
Hersteller darf mir nicht vorschreiben, wie ich meine Sachen zu
verwenden habe.
Aber Hersteller nutzen Legale und Technische Wege, das zu umgehen /
trotzdem zu tun:
1) * as a service. Mit der Methode gehört einem schlicht nichts, und
man ist dem Hersteller voll ausgeliefert.
2) Technische Massnahmen (Verkleben, Signieren, usw.)
Die Hersteller sorgen also dafür, dass wir entweder möglichst keine
Rechte haben, oder wir diese nicht wahrnehmen können, ohne dagegen
vorgehen zu können. Das ist nicht, was unsere rechte sind, oder was wir
mit unserem zeug machen dürfen. Das ist was die willkürliche Kontrolle
der Unternehmen über unsere Besitztümer & Rechte uns machen lässt. Das
darf nicht rechtens sein! Verteidigt die Hersteller und Firmen doch
nicht auch noch! "Das ist halt so", Nein! Es muss gehandelt werden! Es
muss geändert werden!
🐧 DPA 🐧 schrieb:> Mir gehört jeder Teil, jedes Atom von dem, was ich kaufe.
Du kaufst aber nicht, was du meinst gekauft zu haben.
Dein uC mag doppelt so viel Ram auf dem Silizium haben, wie er dir
vorgibt zu haben - allein durch die Markierung des Chips durch den
Hersteller wird dies bestimmt. Du hast aber auch nur für die Hälfte des
Rams bezahlt, ergo gekauft.
Ich verstehe worauf du hinaus willst, unterstütze es sogar im Grundsatz.
Man sollte doch auch immer 100% der zur Verfügung stehenden Ressourcen
nutzen, die wir, die Menschheit erschaffen haben. Unternehmen stehen da
bloss im Wege.
Stand heute sehe ich aber keinen praktischen Weg, wie wir das im
aktuellen System umsetzen könnten.
🐧 DPA 🐧 schrieb:> Aber Hersteller nutzen Legale und Technische Wege, das zu umgehen
Das Recht ist schon eine blöde Sache: Es nutzt nicht nur einem selber,
sondern auch anderen. Das MUSS sofort geändert werden.
Oliver
Oliver S. schrieb:> Bei 99,99999% aller kaufbaren Geräte, in denen eine Firmware steckt, ist> diese Möglichkeit nicht verloren gegangen, weil es die da nie gegeben> hat.
Das ist falsch.
Die allermeisten Geräte, die ich mir bisher genauer angeschaut habe,
hatten:
- Einen Ausleseschutz für die Firmware. Das ist Ok. Einige hatten aber
nicht einmal einen Ausleseschutz.
- Die Möglichkeit die Originalfirmware zu löschen und eine eigene
Firmware aufzuspielen.
Und ich habe bei etlichen dieser Geräte eben genau jenes getan. Alte
Firmware raus, neue Firmware rein.
Das erste berühmte Beispiel, das stark durch die Medien ging, wo das
nicht mehr ging, war Tivo. Woraus der Begriff "Tivoization" entstand.
Ich beobachte, dass immer mehr Geräte tivoisiert werden.
Ich habe auch nichts grundsätzlich dagegen. Dort, wo es Sinn ergibt,
kann man das gerne einsetzen. Ich verstehe zum Beispiel, wenn man es in
safetykritischen Geräten einsetzt.
Aber bitte nicht in breiter Masse.
MaWin schrieb:> Und ich habe bei etlichen dieser Geräte eben genau jenes getan. Alte> Firmware raus, neue Firmware rein.
Rein interessehalber: was waren das für Geräte?
Oliver
Oliver S. schrieb:> was waren das für Geräte?
Das geht von kleinen Gadgets über handgetragene Geräte bis hin zu
PCI-Karten, auf denen ja auch immer öfter ein eigener kleiner Computer
werkelt.
Nano schrieb:> Karl Käfer schrieb:>> Entwickler machen sich viel häufiger Gedanken über Performance, als es>> in der Praxis aus sachlichen Gründen auf deren Verbesserung oder>> Maximierung ankommt. Darum haben die interpretierten Sprachen in der>> Praxis auch fast überall gewonnen, und nach den einschlägigen>> Programmiersprachenindizes sind die interpretierten Sprachen Java und>> Python heute die beliebtesten und verbreitetsten Sprachen der Welt.>> Die sind verbreitet, weil die Entwickler für Firmen günstig sind, die> Newbs damit schnell zu recht kommen und die Auftraggeber die Software> möglichst kostengünstig haben wollen.> Mit beliebt hat das somit nur wenig zu tun, gut, für Newbs mag das> anders aussehen, aber die mögen bzw. mochten ja auch Basic.
Vielleicht solltest Du nicht so arrogant auf die "Newbs" herabblicken...
Du warst auch mal einer, und wenn ich Deine Ausführungen so lese,
beschleicht mich der leise Verdacht, daß das womöglich noch gar nicht so
lange her ist.
> Erfahrene Entwickler würden lieber in Rust oder C++ programmieren,> manche auch in C.
Erfreulicherweise kann sich jeder in den Stackoverflow-Surveys der
letzten fünf Jahre (weiter habe ich nicht geschaut) überzeugen, daß dort
jedes Jahr Python die "Most Wanted" unter den Programmiersprachen war,
vor JavaScript und Go -- mit Ausnahme von 2021, da lag TypeScript
zwischen Python und JavaScript.
C++ liegt in den besagten Surveys in dieser Disziplin meisten so etwa
auf Platz 5, bei den abgegebenen Stimmprozenten liegt Python etwa um den
Faktor 2,5 höher, wobei der prozentuale Stimmanteil von C++ im Laufe der
Jahre eher abnimmt. Ähnliches gilt auch für C, während von den von Dir
genannten Sprachen zumindest Rust aktuell einen gewissen Aufwind
vorweisen kann. Allerdings hat es zwischendrin immer so, ich sage mal,
modische Ausreißer gegeben, die so ein bis drei Jahre einen großen Hype
gehabt haben und wie die New Kids On The Block aussahen, mittlerweile
aber wieder deutlich nachzulassen scheinen: Kotlin, Julia und Scala zum
Beispiel.
Fakt ist jedenfalls: überall dort, wo es um maximale Leistung ohne
Beschränkungen der Ressourcen geht, haben die interpretierten Sprachen
die Oberhand. Und das liegt ganz sicher nicht daran, daß Java- oder
Python-Entwickler besonders "günstig zu bekommen" wären, sondern an
gänzlich anderen Faktoren -- insbesondere der Tatsache, daß eine hohe
Performanz viel unwichtiger ist als viele Entwickler glauben, daß man in
Skriptsprachen wesentlich schneller entwickeln kann und die
Time-To-Market eine wichtige ökonomische Größe ist, die nicht selten
über Erfolg oder Mißerfolg eines Produkts entscheidet. Und in
dynamischen Umfeldern wie der Datenanalyse und dem Machine Learning
spielen die nativen Sprachen nahezu keine Rolle, allenfalls zum
Ansteuern der GPUs und in den Rechenwerken hinter den Interpretierten
werden sie (aus offensichtlichen Gründen) in größerem Umfang genutzt.
Und um Dir gleich den Wind aus den Segeln zu nehmen, ich sei ja auch nur
so einer von diesen "günstigen" Newbs: meine ersten
"Programmiererfahrungen" bestanden darin, das Spiel "Moon Landing" auf
dem HP97-Tischrechner meines alten Herrn schwieriger zu machen, danach
kamen Basic und Assembler auf dem VC-20 und später dem C64, danach C auf
einer PDP-11... tatsächlich habe ich schon mehr Programmiersprachen
vergessen, als ich heute noch beherrsche. Manchmal benutze ich Python
sogar, um C++-Code zu generieren, ist das nicht verrückt?
Wie dem auch sei: es geht nicht um "günstige" Entwickler, sondern es
geht vielmehr um Entwicklungszeit und Flexibilität. Mit "günstigen"
Entwicklern kannst Du ohnehin niemals ein marktfähiges Produkt
entwickeln, das spielt dabei überhaupt keine Rolle -- sonst wäre
übrigens COBOL die richtige Sprache für Dich, denn die guten alten
Coboleros zählen heute zu den bestbezahlten Entwicklern überhaupt. In
einigen sehr speziellen Bereichen erfreuen sich übrigens auch Smalltalk-
und Fortran-Entwickler einer hohen Beliebtheit, die sich sehr direkt in
den Gehältern niederschlägt.
Insofern, sei mir bitte nicht böse, aber von kommerzieller
Softwareentwicklung und deren ökonomischen Hintergründen scheinst Du
nicht allzu viel Ahnung zu haben, und solltest deswegen vielleicht auch
nicht versuchen, damit zu argumentieren. Für Dein Hobby kannst Du ja
benutzen, was Du magst, C, C++, Rust oder Go, meinetwegen auch
Brainfuck, APL, Erlang oder was auch immer -- ist ja okay, Deine Wahl.
Viel Spaß, Erfolg und Vergnügen damit!
> Da muss man ja auch ressourcensparend programmieren weil so mancher µC> nur ein paar KB hat.
Vielen Dank für Deine Belehrungen. Mir ist selbstverständlich klar,
warum Assembler, C und C++ auf den kleinsten und winzigsten
Mikrocontrollern nicht so bald aussterben werden, aber die hatte ich aus
meiner Betrachtung schließlich auch ganz ausdrücklich ausgenommen. Du
darfst schon ein bisschen Mitdenken, wenn Du meine Beiträge liest,
immerhin mache ich das auch beim Verfassen.
Darüber hinaus gibt es einen unübersehbaren Trend im
Mikrocontrollerumfeld: von der aktuellen Nachschubkrise einmal
abgesehen, gibt es immer größere Mikrocontroller mit immer mehr Leistung
und Speicher zu immer kleineren Preisen. Einen ESP32, auf dem mit
Micropython immerhin schon ein Python-Interpreter lauffähig ist, gibt es
heute schon für weniger als einen Euro. Für jeden einzelnen der
ATMega644 und ATMega1284 in meinem Bauteilemagazin habe ich ein
Vielfaches davon bezahlt. Daß Dir solcherlei Entwicklungen anscheinend
nicht gefallen, ändert ja nichts daran, daß es sie sehr offensichtlich
gibt, und ich fürchte, Du kannst dagegen auch nicht viel mehr tun, als
Dich damit abzufinden und diese schlichte Realität zu akzeptieren.
> Vielleicht ändert sich das mal mit neuen Speichertypen um das klassische> RAM zu ersetzen. Arbeitsspeicher der keinen Strom braucht und dabei die> Daten halten kann und trotzdem schnell wie normales RAM ist und sich gut> fertigen lässt und wenig Chipfläche benötigt und beliebig viele Schreib-> und Lesezyklen erlaubt. Dann wird es nicht lange dauern und die µC> werden mit MB an solchem Arbeitsspeicher ausgeliefert und dann darfst du> in bspw. Java oder Python programmieren.
Ja, derartige Prognosen hinsichtlich der Entwicklung von Arbeitsspeicher
höre und lese ich jetzt seit den Neunzigern. Damals hatte ein
skandinavisches Unternehmen angekündigt, binnen weniger Jahre einen
neuen Arbeitsspeichertypus auf der Basis dünner Kunststoff-Folien zu
entwickeln, mit ganz großartigen Features: er sollte wesentlich
preiswerter sein, eine deutlich höhere Speicherdichte aufweisen, zudem
erheblich schneller und zum Ladungserhalt keinen und zum Lesen und
Schreiben nur ganz geringe Spannungen und Ströme benötigen. Zu meinem
größten Bedauern war der Wunderspeicher allerdings letztes Jahr, als ich
meinen aktuellen Numbercruncher aufgebaut habe, leider immer noch nicht
verfügbar... :-(
Nebenbei bemerkt, entwickle ich zwar in Python, aber nicht in Java --
ich glaube, in meinem ganzen Leben habe ich höchstens 1k LOC in Java für
eine Integration mit einer Distributed Realtime Streaming Engine namens
Apache Storm geschrieben. Python macht mir allerdings großen Spaß,
ebenso wie C++ -- das man mit Boost::Python übrigens sehr einfach und
elegant in Python einbinden kann, wenn man die maximale Leistung
wirklich mal ausnahmsweise benötigt.
Insofern, bleib' locker: niemand will Dir Deinen Compiler, Deine
Lieblingssprache oder sonst etwas wegnehmen. Ich auch nicht, warum auch?
Ich freue mich, wenn junge Menschen sich mit Technik auseinandersetzen
und ihrerseits die Maschine beherrschen anstatt davon beherrscht zu
werden. Also weiter so, viel Spaß und Erfolg! ;-)
Karl Käfer schrieb:> Nano schrieb:>> Die sind verbreitet, weil die Entwickler für Firmen günstig sind, die>> Newbs damit schnell zu recht kommen und die Auftraggeber die Software>> möglichst kostengünstig haben wollen.>> Mit beliebt hat das somit nur wenig zu tun, gut, für Newbs mag das>> anders aussehen, aber die mögen bzw. mochten ja auch Basic.>> Vielleicht solltest Du nicht so arrogant auf die "Newbs" herabblicken...
Newbs ist das kürzeste Wort um das auszudrücken was ich meinte.
> Du warst auch mal einer, und wenn ich Deine Ausführungen so lese,> beschleicht mich der leise Verdacht, daß das womöglich noch gar nicht so> lange her ist.
Falsche Korrektheit.
Schäm dich dass du es wagst, hier wegen so etwas rumzuplärren!
Bei mir heißt es im Code immer noch Master und Slave und jetzt reg dich
auf.
Tipp: Renne dreimal um den Block, dann wird das wieder.
So, nächstes Thema:
>>> Erfahrene Entwickler würden lieber in Rust oder C++ programmieren,>> manche auch in C.>> Erfreulicherweise kann sich jeder in den Stackoverflow-Surveys der> letzten fünf Jahre (weiter habe ich nicht geschaut) überzeugen, daß dort> jedes Jahr Python die "Most Wanted" unter den Programmiersprachen war,> vor JavaScript und Go -- mit Ausnahme von 2021, da lag TypeScript> zwischen Python und JavaScript.
Nur weil es für die einfacheren Sprachen mehr Programmierer gibt,
bedeutet das nicht, dass erfahrene Entwickler sie für alles bevorzugen.
Es gibt Dinge, da kommt es auf Performance und geringem Platzbedarf an
und dann wird ein erfahrener Entwickler da kein Javascript einsetzen.
> Ähnliches gilt auch für C, während von den von Dir> genannten Sprachen zumindest Rust aktuell einen gewissen Aufwind> vorweisen kann. Allerdings hat es zwischendrin immer so, ich sage mal,> modische Ausreißer gegeben, die so ein bis drei Jahre einen großen Hype> gehabt haben und wie die New Kids On The Block aussahen, mittlerweile> aber wieder deutlich nachzulassen scheinen: Kotlin, Julia und Scala zum> Beispiel.
Rust wird weiter Erfolg haben, da Rust das gleiche kann wie C und C++
und sich prinzipiell für das gleiche eignet, aber man damit schneller
zum Ziel kommt, und sich weniger Bugs einschleichen weil es by default
nicht die Fehler hat, die C und C++ haben und oben drauf kommen dann
noch so Sachen wie Ownership und Borrowing. Und für die nebenläufige
Programmierung eignet es sich auch besser.
In dem Feld ist Rust also die Zukunft und besseres ist nicht in Sicht.
Das einzige was man versucht ist in C++ Features von Rust an C++ wieder
dranzuflanschen. Das kann für bei gewachsenem Code und der breiten Masse
an C++ Programmierer sinnvoll sein, löst aber nicht die Grundprobleme
von C++.
> daß man in> Skriptsprachen wesentlich schneller entwickeln kann und die> Time-To-Market eine wichtige ökonomische Größe ist,
Das habe ich alles schon oben erwähnt.
Du wiederholst mich.
> Mit "günstigen"> Entwicklern kannst Du ohnehin niemals ein marktfähiges Produkt> entwickeln, das spielt dabei überhaupt keine Rolle -- sonst wäre> übrigens COBOL die richtige Sprache für Dich, denn die guten alten> Coboleros zählen heute zu den bestbezahlten Entwicklern überhaupt.
Du widersprichst dir.
Wenn Cobold Entwickler die bestbezahlten Entwickler sind, dann kann
Cobold als Sprache nicht günstig sein.
> Insofern, sei mir bitte nicht böse, aber von kommerzieller> Softwareentwicklung und deren ökonomischen Hintergründen scheinst Du> nicht allzu viel Ahnung zu haben,
Wenn du richtig lesen könntest, dann hättest du oben das hier, wo du
mich wiederholst, nicht geschrieben:
> daß man in> Skriptsprachen wesentlich schneller entwickeln kann und die> Time-To-Market eine wichtige ökonomische Größe ist,
Also bla bla bla und Tschüß.
> Insofern, bleib' locker: niemand will Dir Deinen Compiler, Deine> Lieblingssprache oder sonst etwas wegnehmen.
Der einzige der nicht locker geblieben ist, bist du. Denn sonst hättest
du dir deinen obigen Erguss sparen können.
Du gehört zu solchen Leuten, die sich triggern lassen, wenn man im Code
so Sachen wie master und slave benutzt.
Dann gehst du auf die Barrikaten und kriegst nen roten Hals und besser
wird der Code durch dein Rummeckern dann auch nicht.
Nano schrieb:> Dann gehst du auf die Barrikaten und kriegst nen roten Hals und besser> wird der Code durch dein Rummeckern dann auch nicht.
OK. Der Ton dieses Threads hat sich etwas geändert: Jetzt ist
allgemeines Wehklagen dran. Naja, das erinnert mich an den ellenlangen
Thread zum Thema "warum mögen die Leute unser gutes Linux nicht".
Nur weiter so, dann kriegt ihr auch die 300 Posts hin.
W.S.
W.S. schrieb:> Nano schrieb:>> Dann gehst du auf die Barrikaten und kriegst nen roten Hals und besser>> wird der Code durch dein Rummeckern dann auch nicht.>> OK. Der Ton dieses Threads hat sich etwas geändert: Jetzt ist> allgemeines Wehklagen dran.
Das sehe ich weniger als Wehklagen, sondern als "zur Schau stellen" der
vermeintlichen eigenen Kompetenz kombiniert mit Präsentation sozialer
Inkompetenz. Also, für dieses Forum alles im grünen Bereich ;-)
Vielleicht reicht es dann später noch fürs Popcorn ...
Karl Käfer schrieb:> mittlerweile> aber wieder deutlich nachzulassen scheinen: Kotlin
Ich dachte Kotlin sei bei Android der Standard, ist das etwa schon
wieder vorbei?
Ich halte es für Unklug, sich auf eine bestimmte Programmiersprache fest
zu legen. Man schränkt sich damit nur unnötig ein. Im Beruf läuft man so
Gefahr, links und rechts von anderen überholt zu werden.
In meinem Umfeld führend folgende Dinge meistens zu einer konkreten
Wahl:
- Vorgabe vom Kunden
- Vorgabe von der Projektleitung
- Zeit-Budget (wenn es schnell gehen muss, nimmt man das, womit man
gerade am schnellsten zum Ziel kommt. Und das hängt unter anderem auch
vom Know-How ab)
- Man führt neues nur ein, wenn man dazu einen wirklich guten Grund hat
(neue Tools -> neue Probleme)
- technische Aspekte (Performance, Speicherbedarf, Startup-Zeit,
benötigte Libraries)
Meistens wurde mir die Programmiersprache vorgegeben. Ich nehme an, dass
es den meisten hier im Beruf ebenso geht.
Ich habe total untechnischen Grund, zuhause bestimmte andere
Programmiersprachen zu benutzen: Weil sie anders sind, weil ich flexibel
bleiben will.
Jörg W. schrieb:> Zombie schrieb:>> Boost stellt so einen Typ zur Verfügung:>> Nur, was hat das mit C (und C89 vs. C99 vs. C11) zu tun?
Der Thread hat sich thematisch ja schon eher in die Richtung weiter
bewegt, was man ggf. verbessern kann und wie das u.U. in anderen
Sprachen aussieht.
Jörg W. schrieb:> Naja, deshalb nun die x-te "C++ ist doch besser"-Diskussion anzufangen,> halte ich dennoch nicht für sinnvoll.
Es geht nicht primär, um "C++ ist besser". Sondern es geht darum, wie
Dinge (hier "zufälligerweise" in C) ggf. besser zu machen sind. Und da
gibt sicher den ein oder anderen Punkt, der in C++ besser zu machen ist,
gerade wenn der Vergleich eben C ist. Und - Du kennst das von mir - dann
weise ich darauf hin, dass man C nicht "verlassen" muss, und trotzdem
die Vorteile von C++ "genießen" kann. Ich denke, dass das durchaus
erlaubt ist, auch weil ja nicht immer dieselben Leute hier mitlesen.
Wer sowas wie Boost gewillt ist zu benutzen, wird das sicher selbst
finden.
Wenn jetzt jeder hier für seine Lieblingssprache anfängt, Rezepte zu
posten, ist der Thread völlig aus dem Ruder. Dass bspw. in Python ein
Integer gar keinen Overflow kennt, muss ich dir sicher nicht erklären.
Jörg W. schrieb:> Dass bspw. in Python ein> Integer gar keinen Overflow kennt, muss ich dir sicher nicht erklären.
Nein, nicht wirklich.
Jedoch ist der Bezug im Kontext Linux-Kernel und C zu Python noch loser
als zu C++.
S.a.
Beitrag "Re: Linux ist endlich vom C89 Standard weg"
Jörg W. schrieb:> Naja, deshalb nun die x-te "C++ ist doch besser"-Diskussion anzufangen,> halte ich dennoch nicht für sinnvoll.
Wenn C++ besser wäre, würde so ein Typ zum Sprachstandard gehören. (Und
das sage ich als C++ fanboy ;)
Jörg W. schrieb:> Dass bspw. in Python ein> Integer gar keinen Overflow kennt, muss ich dir sicher nicht erklären.
Auch dieser Typ fehlt leider im C++ Sprachstandard. Selbst
boost::multiprecision ist fix, was den Wertebereich betrifft.
Jörg W. schrieb:> Wer sowas wie Boost gewillt ist zu benutzen, wird das sicher selbst> finden.
Nicht zwangsläufig, boost ist so riesig und wächst beständig weiter. Ich
benutze boost oft, aber kenne vielleicht 20% davon. Die Existenz von
safe numerics ist mir erst heute wieder eingefallen (à la: da war doch
mal was...)
> Wenn jetzt jeder hier für seine Lieblingssprache anfängt, Rezepte zu> posten, ist der Thread völlig aus dem Ruder.
Ist er sowieso schon lange.
Ich hätte gerne noch mehr über das folgende diskutiert, was genau dabei
das (potentielle) Problem ist:
Zombie schrieb:> Kann mir das bitte jemand in C-Code übersetzen?>>> Koschel hatte eine Unsicherheit identifiziert, die auf ein in C89 nicht>> lösbares Problem zurückzuführen war.>> Beim Fix einer USB-Komponente entdeckte Koschel, dass nach dem Durchlauf>> einer Schleife über eine verkettete Liste der Kopfzeiger der Liste mit>> ungültigem Inhalt nachfolgenden Code-Teilen fälschlich zur Verfügung stand.>> Das liegt schlicht daran, dass in C89 die Laufvariable der Schleife>> außerhalb der Schleife deklariert werden muss und damit auch nach dem>> Schleifenblock weiterhin sichtbar ist. Ein klassischer "Leak" der>> Laufvariablen. Beim Zugriff auf die Variable nach der Schleife kommt es zum>> Bug.>> Ich habe versucht, die Konversation> (https://lore.kernel.org/all/20220217184829.1991035-1-jakobkoschel@gmail.com/)> nach zu vollziehen, aber verstehe nur Bahnhof.>> Danke!
Nach der Schleife gilt iterator == NULL.
Und wenn Du den dann dereferenzierst ...
Zumindest verstehe ich das folgende Excerpt mal so:
Zombie schrieb:>>> Koschel hatte eine Unsicherheit identifiziert, die auf ein in C89 nicht>>> lösbares Problem zurückzuführen war.>>> Beim Fix einer USB-Komponente entdeckte Koschel, dass nach dem Durchlauf>>> einer Schleife über eine verkettete Liste der Kopfzeiger der Liste mit>>> ungültigem Inhalt nachfolgenden Code-Teilen fälschlich zur Verfügung stand.>>> Das liegt schlicht daran, dass in C89 die Laufvariable der Schleife>>> außerhalb der Schleife deklariert werden muss und damit auch nach dem>>> Schleifenblock weiterhin sichtbar ist. Ein klassischer "Leak" der>>> Laufvariablen. Beim Zugriff auf die Variable nach der Schleife kommt es zum>>> Bug.
Womit wir wieder bei dem Thema Zusicherungen wären ...
Zombie schrieb:> was genau dabei das (potentielle) Problem ist
Die Iteration erfolgt eben offenbar nicht bis der Zeiger Null ist (wie
in deinem Beispiel), sondern bis "head" erreicht ist. Siehst du hier:
https://www.vusec.net/projects/kasper/
(etwa in der Mitte)
Jörg W. schrieb:> Zombie schrieb:>> was genau dabei das (potentielle) Problem ist>> Die Iteration erfolgt eben offenbar nicht bis der Zeiger Null ist (wie> in deinem Beispiel), sondern bis "head" erreicht ist. Siehst du hier:>> https://www.vusec.net/projects/kasper/>> (etwa in der Mitte)
Verstehe ich das richtig (ich habe bislang nur den Text gelesen, nicht
den Code), dass der letzte Listeknoten nicht auf den ersten zeigt,
sondern auf den Kopfknoten. Dieser ist natürlich anders strukturell
aufgebaut, wird aber trotzdem wild ge-castet. Da dieser Iterator eben
außerhalb der Schleife auch noch zugreifbar ist, führt ein Zugriff auf
member dann zum Knall. Oder?
Jörg W. schrieb:> Ich habe das auch nicht völlig verstanden (hatte nicht so viel Zeit, das> alles zu lesen), aber irgendsowas offenbar.
Na, dann würde ich sagen: mit einer generischen Liste (template) in C++
und einer vernünftigen Schleifenform mit lokalem Iterator wäre das nicht
passiert (sorry, das war jetzt ne Steilvorlage ...)
Wilhelm M. schrieb:> Na, dann würde ich sagen
was völlig Nutzloses?
Oder wolltest du dich jetzt freiwillig melden, den kompletten Kernel auf
C++ umzuschreiben? Viel Spaß dabei … ich mein, es ist Opensource, du
kannst deinen eigenen Fork davon machen, wenn dir danach ist.
Jörg W. schrieb:> Wilhelm M. schrieb:>> Na, dann würde ich sagen>> was völlig Nutzloses?
Warum so unentspannt?
> Oder wolltest du dich jetzt freiwillig melden, den kompletten Kernel auf> C++ umzuschreiben? Viel Spaß dabei … ich mein, es ist Opensource, du> kannst deinen eigenen Fork davon machen, wenn dir danach ist.
Danke, ich arbeite schon in genug OSS Projekten mit ;-)
Wilhelm M. schrieb:> Jörg W. schrieb:>> Wilhelm M. schrieb:>>> Na, dann würde ich sagen>>>> was völlig Nutzloses?>> Warum so unentspannt?
Weil's ein ziemlich sinnloser Kommentar war.
Wenn sie halt eine Listen-/Iterator-Implementierung haben und die an
hunderten Stellen benutzt wird, dann hilft es keinem, wenn du irgendeine
C++-Standard-Liste stattdessen "empfiehlst".
Linux schmeißt auch so schon häufig genug interne APIs über den Haufen
(VMware-Nutzer können ein Lied davon singen), da braucht man nicht noch
etwas derart zentrales von Grund auf neu zu implementieren.
Jörg W. schrieb:> Wilhelm M. schrieb:>> Jörg W. schrieb:>>> Wilhelm M. schrieb:>>>> Na, dann würde ich sagen>>>>>> was völlig Nutzloses?>>>> Warum so unentspannt?>> Weil's ein ziemlich sinnloser Kommentar war.
Das mit der Steilvorlage hast Du schon verstanden, oder?
Und dass es in diesem Thread eben längst nicht mehr nur um den
Linux-Kernel geht, auch? Schließlich hast Du Dich ja hier auch zum Thema
Python geäußert ...
Wilhelm M. schrieb:> Womit wir wieder bei dem Thema Zusicherungen wären ...
Zusicherungen? Ach nö, es ist immer wieder die generelle
Erwartungshaltung der C-Programmierer, daß Variablen gefälligst ohne
eigenes Zutun initialisiert zu sein haben. Woanders lautet das
Paradigma: vor Benutzung einer Variablen hat man diese selbst
wenigstens einmal beschrieben zu haben, sonst ist deren Inhalt
unbestimmt.
Und wenn das Abbruchkriterium für eine Schleife darin besteht, daß das
letzte Element einer Liste eben keinen Nachfolger hat, dann sollte dem
Programmierer auch klar sein, daß nach Abarbeitung der Schleife der
betreffende Zeiger eben NICHT auf irgendwas sinnvolles zeigt. Also wo
ist der Fehler?
Immerhin besteht normalerweise eine nicht leere Liste aus zumindest
einem Element (oder mehreren) und da hat das allererste Element keinen
Vorgänger und das letzte Element keinen Nachfolger. Man könnte also auch
als Abbruchkriterium hernehmen, daß der Nachfolger des letzten Elementes
nicht existiert und somit nach Abarbeitung der Schleife der Zeiger auf
das letzte Element zeigt. Ob das sinnvoller wäre, wage ich zu
bezweifeln.
W.S.
W.S. schrieb:> Immerhin besteht normalerweise eine nicht leere Liste aus zumindest> einem Element (oder mehreren) und da hat das allererste Element keinen> Vorgänger und das letzte Element keinen Nachfolger.
Wenn Du den Text liest, stellst Du fest, dass es ein zirkuläre Liste
war, wobei der Kopfknoten Teil der Liste selbst ist. Sie hat also
mindestens einen Knoten.
W.S. schrieb:> Zusicherungen? Ach nö, es ist immer wieder die generelle> Erwartungshaltung der C-Programmierer, daß Variablen gefälligst ohne> eigenes Zutun initialisiert zu sein haben.
Ach nö, ewig das selbe Geplärre von dir. Die Erwartungshaltung der
C-Programmierer ist, wie bei allen anderen Programmieren von
Programmiersprachen auch (ausser dir), daß sich die Compiler an die
Spezifikation der Sprache halten. Und ja, das selbstverständlich
gefälligst ohne eigenes Zutun.
Du betreibst Cargokult-Programmierung. Kann man machen, macht man aber
besser nicht.
Oliver
Zombie schrieb:> Ich möchte nochmals auf das Thema "sicherer Integer-Typ" zurück zu> kommen. Boost stellt so einen Typ zur Verfügung:
Lustig, dass "man" jetzt nach unzähligen
selbst-in-den-Fuss-geschossen-Fällen das implementiert, was in den ach
so übel streng typisierten "Steinzeit"-Sprachen ADA und VHDL schon in
der Sprachdefinition selbst drin ist...
So insgesamt finde ich diese Trends recht unterhaltsam. Wir werden uns
evtl. noch so 5-10 Jahre mit immer strengerer Typprüfung aufhalten, und
dann wird auf den Konferenzen der nächste "Paradigm Shift" verkündet.
Wird ganz schickes "Untypescript" geben, das mit KI automatisch immer
die richtigen Cast und Konverter findet und es muss sich mehr mehr um
irgendwelche blöden Typen kümmern ;)
Georg A. schrieb:> Zombie schrieb:>> Ich möchte nochmals auf das Thema "sicherer Integer-Typ" zurück zu>> kommen. Boost stellt so einen Typ zur Verfügung:>> Lustig, dass "man" jetzt nach unzähligen> selbst-in-den-Fuss-geschossen-Fällen das implementiert, was in den ach> so übel streng typisierten "Steinzeit"-Sprachen ADA und VHDL schon in> der Sprachdefinition selbst drin ist...
Da hast Du ggf. Recht.
Jedoch ist es ja so, dass eben Ada nicht sooo verbreitet ist: weder im
Linux-Kernel noch auf den µC.
Ich denke eher, dass die meisten hier ihren "Stepanov" nicht gelesen
haben. Und mangels der Möglichkeiten der Sprache C auch gar nicht auf
die Idee gekommen sind.
Georg A. schrieb:> Wird ganz schickes "Untypescript" geben, das mit KI automatisch immer> die richtigen Cast und Konverter findet und es muss sich mehr mehr um> irgendwelche blöden Typen kümmern ;)
Bitte nicht, denn dann ergibt "1"+2 wieder 12.
Jörg W. schrieb:> Den Linux-Kernel wird weder C++ noch Python interessieren. ;-)
$ find /usr/src/linux/linux-source-5.4.0/ -iname '*.py' | wc -l
105
;-)
Ein T. schrieb:> Stefan ⛄ F. schrieb:>> Bitte nicht, denn dann ergibt "1"+2 wieder 12.>> Aber genau das ergibt es doch. Okay, jedenfalls in Perl und PHP. ;-)
Und in C / C++ einen Zeigerwert, der beim Dereferenzieren UB liefert
(zurück zum Thema).
Ein T. schrieb:> Stefan ⛄ F. schrieb:>> Bitte nicht, denn dann ergibt "1"+2 wieder 12.>> Aber genau das ergibt es doch. Okay, jedenfalls in Perl und PHP. ;-)
In Perl?
Nö.
W.S. schrieb:> Zusicherungen? Ach nö, es ist immer wieder die generelle> Erwartungshaltung der C-Programmierer, daß Variablen gefälligst ohne> eigenes Zutun initialisiert zu sein haben. Woanders lautet das> Paradigma: vor Benutzung einer Variablen hat man diese _selbst_> wenigstens einmal beschrieben zu haben, sonst ist deren Inhalt> unbestimmt.
C soll aber auch performant für alle möglichen Szenarien sein.
Wenn du ein Array bestehend aus vielen int Werten füllen sollst und es
nicht nötig ist, die int Werte im Array vorher auf 0 zu setzen, weil die
Werte ohnehin überschrieben werden sollen, dann kann man sich das
initialisieren auch sparen.
Andere Sprachen würden hier Zeit verschwenden und das Array erst einmal
initialisieren, was in dem Fall aber gar nicht notwendig wäre.
Und wenn du das brauchst, dann geht, solange die Werte nur mit einer 0
initialisiert werden sollen, auch bei 10000 Werten immer noch einfach
mit einem:
1
#define ELEMENTE 10000
2
intdaten1[ELEMENTE]={};
Lediglich wenn du das Array mit anderen Werten als 0 füllen willst, wird
es gemäß Sprachstandard doof, da wird es dann Compilerspezifisch.
Mit GCC und CLANG geht folgendes:
1
#define ELEMENTE 10000
2
intdaten[ELEMENTE]={[0...ELEMENTE-1]=1};
Dann hast du auch lauter Einsen im Array stehen.
Und ja, da wäre es schön, wenn man bei der ISO C Standarddefinition
nachhelfen würde und mit c2x oder später etwas einbaut, mit dem das dann
standardisiert geht.
> Und wenn das Abbruchkriterium für eine Schleife darin besteht, daß das> letzte Element einer Liste eben keinen Nachfolger hat, dann sollte dem> Programmierer auch klar sein, daß nach Abarbeitung der Schleife der> betreffende Zeiger eben NICHT auf irgendwas sinnvolles zeigt. Also wo> ist der Fehler?
Was ja auch logisch ist.
Denn die Prüfung kostet Zeit, während ein einfacher Zähler der mitzählt
und der so gar nicht zu einer Überschreitung führt, performancegünstiger
ist.
Nano schrieb:> Lediglich wenn du das Array mit anderen Werten als 0 füllen willst, wird> es gemäß Sprachstandard doof, da wird es dann Compilerspezifisch.> Mit GCC und CLANG geht folgendes:#define ELEMENTE 10000> int daten[ELEMENTE]={ [0 . . . ELEMENTE-1] = 1 };> Dann hast du auch lauter Einsen im Array stehen.
Auch hier könnte man wieder die Goodies von C++ nutzen (hier: IIFE):
1
autoa=[]{
2
std::array<uint8_t,100>a;
3
for(size_ti{};auto&e:a){
4
e=i++;
5
}
6
returna;
7
}();
Dann kannst Du beliebigen Inhalt als Initialisierung generieren - und
nicht compiler-spezifisch.
Nano schrieb:> Und wenn du das brauchst, dann geht, solange die Werte nur mit einer 0> initialisiert werden sollen, auch bei 10000 Werten immer noch einfach> mit einem:
Korrektur, ISO konform muss in der geschweiften Klammer eine 0 Stehen,
sonst gibt es bei aktiviertem -pedantic eine Warnung.
Leider darf es nichts anderes als eine 0 sein, nimmt man eine andere
Zahl, wird nur der erste Wert mit diesem initialisiert und der Rest
bekommt Nullen.
<c>
#define ELEMENTE 10000
int daten1[ELEMENTE] = { 0 };
</c>
Nano schrieb:> C soll aber auch performant für alle möglichen Szenarien sein.> Wenn du ein Array bestehend aus vielen int Werten füllen sollst und es> nicht nötig ist, die int Werte im Array vorher auf 0 zu setzen, weil die> Werte ohnehin überschrieben werden sollen, dann kann man sich das> initialisieren auch sparen.
Wenn der Compiler nachweisen kann, dass die Initialisierung wieder
überschrieben wird, ohne dass sie woanders sichtbar wurde, wird er sie
auch nicht ausführen. Das kannst Du ruhig dem Compiler überlassen. Wenn
Du dagegen ein Element vergisst, dass hast Du wieder UB.
Wilhelm M. schrieb:> Auch hier könnte man wieder die Goodies von C++ nutzen (hier: IIFE):> auto a = []{> std::array<uint8_t, 100> a;> for(size_t i{}; auto& e: a) {> e = i++;> }> return a;> }();>> Dann kannst Du beliebigen Inhalt als Initialisierung generieren - und> nicht compiler-spezifisch.
Geht zwar, ist aber keine schöne Lösung, da man zu viel Text für so
etwas schreiben muss.
Schön wäre etwas kurzes, wie bei dem GCC/CLANG Beispiel. Und dafür
sollte so etwas dann halt in den Sprachstandard.
In Rust geht das viel einfacher und kürzer (ein weiteres Beispiel warum
man mit Rust schneller zum Ziel kommt):
1
fn main(){
2
let data: [i32; 10] = [1; 10]; // 10 Elemente vom Typ i32 (32 Bit Integer) die mit dem Wert 1 initialisiert werden
3
println!("i= {:?}\n",data); // Ausgabe des kompletten Arrays
Wilhelm M. schrieb:> Nano schrieb:>> C soll aber auch performant für alle möglichen Szenarien sein.>> Wenn du ein Array bestehend aus vielen int Werten füllen sollst und es>> nicht nötig ist, die int Werte im Array vorher auf 0 zu setzen, weil die>> Werte ohnehin überschrieben werden sollen, dann kann man sich das>> initialisieren auch sparen.>> Wenn der Compiler nachweisen kann, dass die Initialisierung wieder> überschrieben wird, ohne dass sie woanders sichtbar wurde, wird er sie> auch nicht ausführen. Das kannst Du ruhig dem Compiler überlassen. Wenn> Du dagegen ein Element vergisst, dass hast Du wieder UB.
Das kann natürlich sein. An die Optimierung durch den Compiler habe ich
jetzt nicht gedacht.
Nano schrieb:> Wilhelm M. schrieb:>> Auch hier könnte man wieder die Goodies von C++ nutzen (hier: IIFE):>> auto a = []{>> std::array<uint8_t, 100> a;>> for(size_t i{}; auto& e: a) {>> e = i++;>> }>> return a;>> }();>>>> Dann kannst Du beliebigen Inhalt als Initialisierung generieren - und>> nicht compiler-spezifisch.>> Geht zwar, ist aber keine schöne Lösung, da man zu viel Text für so> etwas schreiben muss.
Ja, ich weiß: auch in Rust kann man einen Generator verwenden um
folgendes zu erreichen. Ja, was wird kürzer dann als dies:
1
autoa=[]{
2
std::array<uint8_t,100>a;
3
for(size_ti{};auto&e:a){
4
e=sin(2*M_PI/a.size());
5
}
6
returna;
7
}();
> Schön wäre etwas kurzes, wie bei dem GCC/CLANG Beispiel. Und dafür> sollte so etwas dann halt in den Sprachstandard.
Das obige ist Standard.
> In Rust geht das viel einfacher und kürzer.
Ja, aber wie schon zum wiederholten Mal gesagt, und das ist mein Punkt
hier: es geht ja nicht um die Migration von C nach Rust, sondern darum,
dass man in C auch die Goodies von C++ benutzen kann, ohne sich groß
umstellen zu müssen: man kann das nutzen, und bleibt sonst bei C-Code
bzw. C-like Code.
Wilhelm M. schrieb:>> Schön wäre etwas kurzes, wie bei dem GCC/CLANG Beispiel. Und dafür>> sollte so etwas dann halt in den Sprachstandard.>> Das obige ist Standard.
Also das hier ist GCC /CLANG spezifisch und nicht im C ISO Standard:
1
#define ELEMENTE 10000
2
intdaten[ELEMENTE]={[0...ELEMENTE-1]=1};// Nicht ISO konform
GCC
1
gcc -std=c17 -pedantic -Wall array.c -o array.bin
2
array.c: In function ‘main’:
3
array.c:11:31: warning: ISO C forbids specifying range of elements to initialize [-Wpedantic]
array.c:11:31: warning: use of GNU array range extension [-Wgnu-designator]
3
int daten[ELEMENTE] = { [0 ... ELEMENTE-1] = 1 };
4
^
5
1 warning generated.
>> In Rust geht das viel einfacher und kürzer.>> Ja, aber wie schon zum wiederholten Mal gesagt, und das ist mein Punkt> hier: es geht ja nicht um die Migration von C nach Rust, sondern darum,> dass man in C auch die Goodies von C++ benutzen kann, ohne sich groß> umstellen zu müssen: man kann das nutzen, und bleibt sonst bei C-Code> bzw. C-like Code.
Ok.
Nano schrieb:> Wilhelm M. schrieb:>>> Schön wäre etwas kurzes, wie bei dem GCC/CLANG Beispiel. Und dafür>>> sollte so etwas dann halt in den Sprachstandard.>>>> Das obige ist Standard.>> Also das hier ist GCC /CLANG spezifisch und nicht im C ISO Standard:
Ich sprach nicht von der Compiler-Erweiterung, sondern von meinem Code
natürlich ;-) Ist doch klar ersichtlich. Der ist standard-konform.
Wilhelm M. schrieb:> Nano schrieb:>> Wilhelm M. schrieb:>>>> Schön wäre etwas kurzes, wie bei dem GCC/CLANG Beispiel. Und dafür>>>> sollte so etwas dann halt in den Sprachstandard.>>>>>> Das obige ist Standard.>>>> Also das hier ist GCC /CLANG spezifisch und nicht im C ISO Standard:>> Ich sprach nicht von der Compiler-Erweiterung, sondern von meinem Code> natürlich ;-) Ist doch klar ersichtlich. Der ist standard-konform.
Ok, da haben wir dann aneinander vorbeigeredet.
Ich habe nicht bestritten, dass dein gezeigter C++ Code nicht
standardkonform sei. Wäre es so, hätte ich es vorher schon gesagt. Da
sagte ich aber nur, dass er sehr viel Tipparbeit bedeutet und gewünscht
wäre ja etwas sehr kurzes ohne viel Tipparbeit bei gleichzeitiger
Standardkonformität.
Interessant wäre aber mal zu erfahren, warum man so etwas wie das, was
GCC und Clang bei C bietet, nicht irgendwie in den Sprachstandard
einbaut.
Da wären die Gründe sicher interessant.
Nano schrieb:> Ok, da haben wir dann aneinander vorbeigeredet.> Ich habe nicht bestritten, dass dein gezeigter C++ Code nicht> standardkonform sei. Wäre es so, hätte ich es vorher schon gesagt. Da> sagte ich aber nur, dass er sehr viel Tipparbeit bedeutet und gewünscht> wäre ja etwas sehr kurzes ohne viel Tipparbeit bei gleichzeitiger> Standardkonformität.
Auch das stand schon oben in meinem Beitrag, und dass man in Rust auch
Generatoren verwenden kann. Naja, haste eben nicht gelesen ...
Nano schrieb:> Interessant wäre aber mal zu erfahren, warum man so etwas wie das, was> GCC und Clang bei C bietet, nicht irgendwie in den Sprachstandard> einbaut.
Der Standardisierungsprozess ist offen, Du kannst Dich da gerne
einbringen ;-)
Nano schrieb:> Karl Käfer schrieb:> Bei mir heißt es im Code immer noch Master und Slave und jetzt reg dich> auf.> Tipp: Renne dreimal um den Block, dann wird das wieder.
Nicht nötig, ich bin völlig ruhig und entspannt. Meine Kritik galt nicht
Deiner Wortwahl, sondern den Inhalten Deiner Ausführungen.
>>> Erfahrene Entwickler würden lieber in Rust oder C++ programmieren,>>> manche auch in C.>>>> Erfreulicherweise kann sich jeder in den Stackoverflow-Surveys der>> letzten fünf Jahre (weiter habe ich nicht geschaut) überzeugen, daß dort>> jedes Jahr Python die "Most Wanted" unter den Programmiersprachen war,>> vor JavaScript und Go -- mit Ausnahme von 2021, da lag TypeScript>> zwischen Python und JavaScript.>> Nur weil es für die einfacheren Sprachen mehr Programmierer gibt,> bedeutet das nicht, dass erfahrene Entwickler sie für alles bevorzugen.
Du behauptest, Java sei eine "einfachere Sprache"? Und auch Python ist,
sobald man ein gewisses Niveau erreicht hat, keine einfache Sprache
mehr. Softwareentwicklung ist ja ohnehin keine ganz einfache Tätigkeit,
und daran ändert die Wahl der einen oder anderen Sprache relativ wenig.
Ansonsten sind die Umfragen von SO bislang die beste Datenbasis, die ich
zum Thema kenne, und andere unabhängige Rankings wie TIOBE, RedMonk und
PYPL kommen gänzlich unabhängig von ihrer jeweiligen Methodik auf sehr
ähnliche Ergebnisse wie SO. Daher beziehe ich mich bei meiner
Einschätzung der Realität auf diese Datenbasis, behalte dabei aber
natürlich im Hinterkopf, daß diese nicht unbedingt der Weisheit letzter
Schluß sein können -- das ist der Natur der Sache nun einmal inhärent.
Und was ich persönlich mir wünsche und worauf ich hoffe, ist davon
unbenommen -- es gibt viele Dinge auf dieser Welt, die anders sind als
ich sie mir wünsche, aber leider komme ich nicht darum herum, trotzdem
anzuerkennen, daß sie sind wie sie sind.
Deine Argumentation beruht hingegen lediglich auf Deinen Hoffnungen,
Wünschen und Überzeugungen. Wenn Du die Welt aus dieser Perspektive
siehst, hast Du sicher ein sehr entspanntes Leben (jedenfalls, solange
ich hier nichts schreibe...), und ich gönne Dir das ehrlich, aufrichtig
und von ganzem Herzen. Bedauerlicherweise hat die Basis Deiner
Argumentation aber nur wenig Berührungspunkte mit einer Realität, in der
wir anderen Menschen leben (müssen), und die zumindest einige wenige von
uns nach Kräften so zu verändern versuchen, daß sie sich unseren
Wünschen, Hoffnungen und Überzeugungen annähert. Das geht nur, wenn man
die Realität in ihrer ganzen häßlichen Schönheit erkennt und ihre
traurige Existenz zumindest anerkennt.
Letzten Endes führen unsere unterschiedlichen Ansätze aber dazu, daß wir
gar keine gemeinsame Diskussionsgrundlage haben. Hey, ich würde es toll
finden, wenn Rust zu besserer Software führen würde. Aber deswegen kann
ich doch nicht abstreiten, daß eine riesige Codebasis in anderen
Sprachen existiert, daß Rust heute noch eher ein Nischendasein führt,
daß andere Sprachen wie Python, Java, JavaScript und Go heute offenbar
noch immer viel beliebter und weiter verbreitet sind als Rust. Das hab
ich mir ja nicht ausgedacht und ich sage das auch nicht, weil ich Rust
abwerten wollte oder es nicht mögen würde, sondern das ist einfach eine
Tatsache.
Andererseits hast Du immerhin Anlaß zur Hoffnung, denn die letzten
beiden neuen Sprachen, die erfolgreich aus dem Niemandsland aufgestiegen
sind und weiterhin wachsen, sind beides native Sprachen, nämlich Go und
Rust. Vielleicht sieht die Sache also in einigen Jahren schon wieder
ganz anders aus. Aber im Moment ist es ausweislich aller vorliegenden
Daten nun einmal Tatsache, daß die interpretierten Sprachen sowohl
verbreiteter als auch beliebter sind.
> Es gibt Dinge, da kommt es auf Performance und geringem Platzbedarf an> und dann wird ein erfahrener Entwickler da kein Javascript einsetzen.
Ich hatte NICHT gesagt, daß es solche "Dinge" nicht gäbe. Ich HATTE
gesagt, daß diese "Dinge" seltener vorkommen, als viele Entwickler
glauben.
> Rust wird weiter Erfolg haben, da Rust das gleiche kann wie C und C++> und sich prinzipiell für das gleiche eignet, aber man damit schneller> zum Ziel kommt, und sich weniger Bugs einschleichen weil es by default> nicht die Fehler hat, die C und C++ haben und oben drauf kommen dann> noch so Sachen wie Ownership und Borrowing. Und für die nebenläufige> Programmierung eignet es sich auch besser.
Na das will ich doch sehr hoffen. Nicht nur, weil ich Rust mag, sondern
vor allem auch, weil ich als Architekt, Entwickler, Betreiber und
Benutzer von Software ein starkes Interesse daran habe, daß sie
fehlerärmer, sicherer und stabiler wird.
Im Übrigen wäre es ein sehr starkes Argument für Rust, wenn man damit
schneller zum Ziel käme als mit C oder C++. Dieses "schneller zum Ziel
kommen" ist ja auch einer der wichtigsten Vorzüge vieler interpretierter
Sprachen und insbesondere Python -- und dieses "schneller zum Ziel
kommen" ist ja der Grund, warum die interpretierten Sprachen bisher
gewonnen haben. Eine von Pythons wichtigsten Stärken ist nämlich genau
das, schneller zum Ziel zu kommen, und meiner ganz persönlichen Ansicht
nach ist das einer der Gründe, warum sich Python gegenüber ähnlichen
Sprachen wie Ruby und Raku erfolgreich durchsetzen konnte.
Andererseits sehe ich auch, daß C++ mit dem Standard C++11 und dessen
Nachfolgern eine enorme Weiterentwicklung gemacht und dabei auch
verschiedene Features und Ideen aus anderen Sprachen mitgenommen hat.
Wenn ich modernes C++ mit seinen Vorgängern vergleiche, empfinde ich
ähnlich wie Bjarne Stroustrup, der gesagt hat: "es fühlt sich an wie
eine andere Programmiersprache". Ich glaube zwar nicht, daß C++ jemals
sein wichtigstes Alleinstellungsmerkmal aufgeben wird, nämlich die
weitestgehende Abwärtskompatibilität mit C, weswegen C++ immer gewisse
Altlasten mit sich herum schleppen wird. Aber das ändert nichts daran,
daß es besser für die immer größer werdenden Anforderungen an
Funktionalität und Komplexität von moderner Software gerüstet ist als
seine älteren Versionen. Abschreiben und verabschieden würde ich C++,
jedenfalls heute, noch lange nicht -- insbesondere dann nicht, wenn man
mal betrachtet, was im Boost-Projekt so alles vorhanden oder in der
Entstehung ist, und Boost gilt ja gemeinhin als eine Art Inkubator für
die zukünftige Weiterentwicklung des Sprachstandards. Das ist aber nur
meine persönliche Ansicht und lediglich von meinen Erfahrungen und
Beobachtungen der letzten Jahrzehnte gespeist.
> In dem Feld ist Rust also die Zukunft und besseres ist nicht in Sicht.> Das einzige was man versucht ist in C++ Features von Rust an C++ wieder> dranzuflanschen. Das kann für bei gewachsenem Code und der breiten Masse> an C++ Programmierer sinnvoll sein, löst aber nicht die Grundprobleme> von C++.
Ach, ich mache das Softwarezeugs ja schon eine Weile und habe im Laufe
der Jahre so viele Lobpreisungen, Heils- und Zukunfsversprechen
gesehen... Ich würde mich enorm darüber freuen, wenn das Eine oder
Andere davon endlich mal einträte -- allein, mir fehlt der Glaube. Weißt
Du, wir Profis haben da einen Spruch: "Immer, wenn Du etwas
idiotensicher gemacht hast, kommt die Natur und erfindet bessere
Idioten".
> Du wiederholst mich.
Na dann freu Dich doch. Das ist ein prima Indikator dafür, daß Du Recht
hast. ;-)
> Du widersprichst dir.
Nö.
> Wenn Cobold Entwickler die bestbezahlten Entwickler sind, dann kann> Cobold als Sprache nicht günstig sein.
Die Kosten von Softwareentwicklung hängen nur in sehr geringem Maße von
Gehältern einzelner Entwickler ab. Im Falle von Cobol und anderen
Sprachen ist es so, daß es eine riesige Codebasis gibt, in der enorme
Investitionen stecken und die die Basis etlicher geschäftskritischer
Applikationen ist. Für die Betreiber ist es deswegen viel billiger,
diese besonders teuren Entwickler mit der Pflege und Wartung dieser
Software zu betreuen, als sie neu zu entwickeln. Und da es einen hohen
Bedarf, aber nur ein überschaubares Angebot an solchen Entwicklern gibt,
kommen da die üblichen Gesetze der Marktwirtschaft ins Spiel. Diese
Sache mit Angebot und Nachfrage, die hast Du doch bestimmt mal in der
Schule gehört, oder nicht?
> Also bla bla bla und Tschüß.> Der einzige der nicht locker geblieben ist, bist du. Denn sonst hättest> du dir deinen obigen Erguss sparen können.> Du gehört zu solchen Leuten, die sich triggern lassen, wenn man im Code> so Sachen wie master und slave benutzt.> Dann gehst du auf die Barrikaten und kriegst nen roten Hals und besser> wird der Code durch dein Rummeckern dann auch nicht.
Ach, wie langweilig, Du wirst immer so aggressiv und unsachlich. Wenn Du
Dich nicht beherrschen kannst oder nicht darauf klarkommst, daß ich
andere Perspektiven und Überlegungen habe als Du, und deswegen andere
Meinungen vertrete, ist es vielleicht besser, wenn Du nicht mehr auf
meine Beiträge antwortest. Denn offenbar schaffst Du es weder, mich
einzuschüchtern, noch, mich zum Schweigen zu bringen. Am Ende regst
immer wieder nur Du Dich auf, pöbelst herum und beleidigst mich, ohne zu
bemerken, daß dieses Verhalten nur etwas über Dich aussagt. Das muß doch
echt nicht sein -- zumal unsere Mitleser dann ständig meine Popcorn- und
Biervorräte plündern! ;-)
Karl Käfer schrieb:> zumal unsere Mitleser dann ständig meine Popcorn- und> Biervorräte plündern! ;-)
Lach-Flash!
Ich plündere gar nix von Dir ;-) Meine Vorräte gehen dabei drauf ...
Stefan ⛄ F. schrieb:> Karl Käfer schrieb:>> mittlerweile>> aber wieder deutlich nachzulassen scheinen: Kotlin>> Ich dachte Kotlin sei bei Android der Standard, ist das etwa schon> wieder vorbei?
Ich glaube, der Standard ist eigentlich Java, aber die meisten (laut
Quellen etwa 60%) Android-Entwickler sollen Kotlin nutzen, das ja
Java-Bytecode erzeugen kann.
Stefan ⛄ F. schrieb:> Ich halte es für Unklug, sich auf eine bestimmte Programmiersprache fest> zu legen. Man schränkt sich damit nur unnötig ein. Im Beruf läuft man so> Gefahr, links und rechts von anderen überholt zu werden.
Das sehe ich genauso wie Du. Dennoch sind mir schon einige Entwickler
begegnet, die tatsächlich nur eine Sprache kannten und konnten, und die
sich zum Teil mit Händen und Füßen dagegen gewehrt haben, eine weitere
Sprache auch nur anzuschauen -- auch im professionellen Bereich.
Anfangs konnte ich mir das nicht erklären, mittlerweile habe ich aber
zumindest eine Vermutung. Und die geht so: das Erlernen der ersten
Programmiersprache ist besonders schwierig, weil man nicht nur Sprache,
Tooling und Infrastruktur, sondern auch das Programmieren selbst
erlernen muß. Also zu denken wie ein Entwickler, Probleme in kleine
Teilaufgaben zu zerlegen, größere Projekte auf mehrere Dateien zu
verteilen, Dateien und Ressourcen zu organisieren, die Dokumentation zu
finden und korrekt zu verstehen, all diese Dinge eben -- das muß ich Dir
nicht erzählen.
Das zu erlernen ist IMHO viel schwieriger als die Sprache selbst, und
viele tun sich mit dem Programmierenlernen wesentlich schwerer als mit
der Sprache. Manche erkennen aber nicht, daß man Programmieren nur
einmal lernen muß und dieses einmal erworbene Wissen dann auch auf die
meisten anderen Sprachen übertragen kann. Die Aneignung einer neuen
Sprache ist danach nurmehr ein bisschen Vokabeln und Grammatik, aber das
sehen manche leider nicht. Sie befürchten stattdessen, wieder bei Null
anfangen zu müssen, und scheuen diesen Aufwand.
> Ich habe total untechnischen Grund, zuhause bestimmte andere> Programmiersprachen zu benutzen: Weil sie anders sind, weil ich flexibel> bleiben will.
Naja, auf der Arbeit wirst Du ja nach meiner Erinnerung auch dazu
gezwungen, Java zu programmieren. Da kann ich gut verstehen, daß man das
nicht auch noch in seiner oh viel zu raren Freizeit haben will... ;-)
Karl Käfer schrieb:> ...das muß ich Dir nicht erzählen.> Das zu erlernen ist IMHO viel schwieriger als die Sprache selbst
Ja genau. Bei der Vielzahl der Programmiersprachen bringe ich manchmal
Syntaktische Kleinigkeiten durcheinander, aber das merkt man spätestens
beim Testen und man hat ja Tutorials + StackOverflow als
Erinnerungshilfe.
> Naja, auf der Arbeit wirst Du ja nach meiner Erinnerung auch> dazu gezwungen, Java zu programmieren.
Vor 2 Jahren ist Go dazu gekommen. Interessanterweise von einem
Projektleiter initiiert, nicht von den Programmierern.
Karl Käfer schrieb:> Aber an sich wäre es doch viel schöner, wenn so etwas passieren würde,> meinst Du nicht auch?
Ich wette, dass dies als ordentliche Umfrage etwa 50/50 ergeben wird.
Wilhelm M. schrieb:> Karl Käfer schrieb:>> zumal unsere Mitleser dann ständig meine Popcorn- und>> Biervorräte plündern! ;-)>> Lach-Flash!>> Ich plündere gar nix von Dir ;-) Meine Vorräte gehen dabei drauf ...
Das tut mir leid -- ich schulde Dir drei Flaschen Bier und eine Tüte
Popcorn! ;-)
Karl Käfer schrieb:> Hey, ich würde es toll> finden, wenn Rust zu besserer Software führen würde. Aber deswegen kann> ich doch nicht abstreiten, daß eine riesige Codebasis in anderen> Sprachen existiert, daß Rust heute noch eher ein Nischendasein führt,> daß andere Sprachen wie Python, Java, JavaScript und Go heute offenbar> noch immer viel beliebter und weiter verbreitet sind als Rust.
Was du leider immer noch nicht verstanden hast ist folgender
Sachverhalt:
Aus einer ökonomischen Sachverhalt (einfach, günstige Programmierer,
kurze Entwicklungszeit) der sich aus dem Markt bedingt, ergibt sich
nicht automatisch auch eine Beliebtheit, sondern eine Notwendigkeit und
das war meine Aussage in meinem allerersten Kommentar zu diesem Thema.
Und deine ganze Diskussion wo du mit "der ist gegen Newbs" gestellten
political Correctness Empörung anfängst und somit völlig am Thema vorbei
diskutierst hättest du dir sparen können. Denn einmal ging es nur um
eine kurze prägnante Beschreibung wo jeder weiß, was gemeint ist, daher
Newbs und das eigentliche Thema war beliebte Sprache vs. Sprache
genutzt aufgrund von ökonomischem Druck.
Und deswegen sind auch deine ganzen Rankings Nullaussagen in dieser
Sache.
Stell dir mal vor, Assembler macht Spaß! Bezahlen und daher nutzen tut's
in der Wirtschaft zwar fast keiner mehr, aber Spaß machen tut es.
Und C macht auch Spaß, das gilt erst recht, wenn die Ressourcen auch
noch begrenzt sind. Und darum geht es oben.
Javascript ist dagegen ziemlich langweilig. Und Basic auch.
Und du willst nun mit deiner falschen Interpretation des Marktes, dem es
um Ökonomie und nicht um Beliebtheit geht, weiß machen, dass Javascript
mehr Spaß macht als Assembler und C.
> Andererseits hast Du immerhin Anlaß zur Hoffnung, denn die letzten> beiden neuen Sprachen, die erfolgreich aus dem Niemandsland aufgestiegen> sind und weiterhin wachsen, sind beides native Sprachen, nämlich Go und> Rust.
Go wird man nicht für die Systemprogrammierung nutzen.
Rust schon, da es sich auch dafür eignet.
Bei Go verhindert das bereits der Garbage Collector, als das man damit
einen generell für alles mögliche geeigneten Kernel schreiben wollte.
> Aber im Moment ist es ausweislich aller vorliegenden> Daten nun einmal Tatsache, daß die interpretierten Sprachen sowohl> verbreiteter als auch beliebter sind.
Es geht nicht ums verbreiteter und zum beliebter siehe oben. Thema
verfehlt.
> Ich hatte NICHT gesagt, daß es solche "Dinge" nicht gäbe. Ich HATTE> gesagt, daß diese "Dinge" seltener vorkommen, als viele Entwickler> glauben.
Und es geht hier nicht um selten oder häufig.
> Thema Cobold> Und da es einen hohen> Bedarf, aber nur ein überschaubares Angebot an solchen Entwicklern gibt,> kommen da die üblichen Gesetze der Marktwirtschaft ins Spiel.
Siehste.
Und deswegen sind Javascript, Java, PHP, Python usw. Programmierer
billig zu haben, weil es da genug davon gibt und die Anforderungen
teilweise sogar gering sind.
> Ach, wie langweilig, Du wirst immer so aggressiv und unsachlich.
Wenn du mich persönlich angreifst, musst du das erwarten.
> Wenn Du> Dich nicht beherrschen kannst oder nicht darauf klarkommst, daß ich> andere Perspektiven und Überlegungen habe als Du, und deswegen andere> Meinungen vertrete,
Persönliche Angriffe sind aber keine Meinungen.
> Am Ende regst> immer wieder nur Du Dich auf, pöbelst herum und beleidigst mich, ohne zu> bemerken, daß dieses Verhalten nur etwas über Dich aussagt.
Mein großes Vorbild ist wahrscheinlich Linus Torvald.
Karl Käfer schrieb:> Stefan ⛄ F. schrieb:>> Ich halte es für Unklug, sich auf eine bestimmte Programmiersprache fest>> zu legen. Man schränkt sich damit nur unnötig ein. Im Beruf läuft man so>> Gefahr, links und rechts von anderen überholt zu werden.>> Das sehe ich genauso wie Du.
Und darum ging es nicht.
Hallo,
Karl Käfer schrieb:> Die Aneignung einer neuen Sprache ist danach nurmehr ein bisschen> Vokabeln und Grammatik...
Nun ja, wer z.B. mit einer prozeduralen Programmiersprache
"aufgewachsen" ist und dann auf eine objektorientierte Sprache (und dem
damit verbundenen Programmierparadigma) umsteigt hat mehr zu lernen als
ein paar Vokabeln und eine bisschen Grammatik.
> Sie befürchten stattdessen, wieder bei Null anfangen zu müssen,> und scheuen diesen Aufwand.
Ich glaube eher das solche Leute sich die Frage stellen warum sie sich
mit neuen Programmierparadigmen beschäftigen sollen, wo sie doch alle
Probleme auch mit ihrem bisherigen "Werkzeug" lösen konnten.
Hier ist doch ständig zu lesen unter welchem Zeitdruck Software
entwickelt werden muss. Da kann ich gut verstehen das sich manche
Programmierer lieber auf ihre Erfahrungen verlassen anstatt neue Wege
(mit neuen Fallstricken) zu gehen.
rhf
Nano schrieb:> C soll aber auch performant für alle möglichen Szenarien sein.> Wenn du ein Array bestehend aus vielen int Werten füllen sollst und es> nicht nötig ist, die int Werte im Array vorher auf 0 zu setzen, weil die> Werte ohnehin überschrieben werden sollen, dann kann man sich das> initialisieren auch sparen.>
Hier haust Du aber was durcheinander bzw. würde ich W.S. Aussage hier
nicht so starr sehen.
Um mal bei dem Arraybespiel zu bleiben: Wenn ich sicher weis, das ich
das Array mit Werten fülle bevor ich den ersten lesenden Zugrriff auf
selbiges mache, dann muß ich das ganz sicher nicht initialisieren, das
geschieht dann halt bei Befüllen mit Werten. Gilt natürlich analog auch
für alle anderen Variablen. Wenn ich allerdings nicht sicher stellen
kann das eine Variable bei der ersten Abfrage mit sinnvollen Werten
belegt ist, dann macht die Initialisierung schon Sinn, sonst können da
sehr lustige Dinge raus kommen.
> Andere Sprachen würden hier Zeit verschwenden und das Array erst einmal> initialisieren, was in dem Fall aber gar nicht notwendig wäre.
Das wäre z.B.?
Nano schrieb:> Mein großes Vorbild ist wahrscheinlich Linus Torvald.
Nachgewiesenermaßen ist er sozial ein Totalausfall. Bin jetzt nicht
sicher, wie Du das mit dem Vorbild meinst ...
Zeno schrieb:> Nano schrieb:>> C soll aber auch performant für alle möglichen Szenarien sein.>> Wenn du ein Array bestehend aus vielen int Werten füllen sollst und es>> nicht nötig ist, die int Werte im Array vorher auf 0 zu setzen, weil die>> Werte ohnehin überschrieben werden sollen, dann kann man sich das>> initialisieren auch sparen.>>> Hier haust Du aber was durcheinander bzw. würde ich W.S. Aussage hier> nicht so starr sehen.> Um mal bei dem Arraybespiel zu bleiben: Wenn ich sicher weis, das ich> das Array mit Werten fülle bevor ich den ersten lesenden Zugrriff auf> selbiges mache, dann muß ich das ganz sicher nicht initialisieren, das> geschieht dann halt bei Befüllen mit Werten. Gilt natürlich analog auch> für alle anderen Variablen. Wenn ich allerdings nicht sicher stellen> kann das eine Variable bei der ersten Abfrage mit sinnvollen Werten> belegt ist, dann macht die Initialisierung schon Sinn, sonst können da> sehr lustige Dinge raus kommen.
Genauer gesagt ist der Zugriff auf nicht-initialisierten Speicher UB.
Kann man gut in einem constexpr-Kontext beobachten bzw. zeigen.
Wie ich oben schon mal gesagt habe, wird der Compiler "unnötige"
Initialisierungen weg-optimieren, wenn er nachweisen kann, das kein
anderer Zugriff erfolgen kann.
Ansonsten hilft ggf. auch der Einsatz einen UB-sanitizers, um das
aufzudecken.
Anfänger machen sich meisten viel zu viel Gedanken um
Mikro-Optimierungen, und vergessen dabei manchmal andere wichtigere
Entscheidungen, etwa ob eine Datenstruktur für den angestrebten Einsatz
wirklich performant ist (s.a. std::vector<> im Vergleich zu
std::list<>).
Wilhelm M. schrieb:> Nano schrieb:>> Mein großes Vorbild ist wahrscheinlich Linus Torvald.>> Nachgewiesenermaßen ist er sozial ein Totalausfall. Bin jetzt nicht> sicher, wie Du das mit dem Vorbild meinst ...
Die Kondition des Sozial seins, auch manchmal als "Normal" sein
bezeichnet, ist eine ernstzunehmende mentale Störung!
Wilhelm M. schrieb:> Nano schrieb:>> Mein großes Vorbild ist wahrscheinlich Linus Torvald.>> Nachgewiesenermaßen ist er sozial ein Totalausfall. Bin jetzt nicht> sicher, wie Du das mit dem Vorbild meinst ...
Bekannt ist seine Neigung zu drastischer Ausdrucksweise. Sozialverhalten
umfasst aber viel mehr als das.
Wilhelm M. schrieb:> Nano schrieb:>> Mein großes Vorbild ist wahrscheinlich Linus Torvald.>> Nachgewiesenermaßen ist er sozial ein Totalausfall. Bin jetzt nicht> sicher, wie Du das mit dem Vorbild meinst ...
Dann bin ich für alle Übertretungen entschuldigt. Ich kann ja dann nicht
anders. Ihr braucht also mit mir Verständnis und Toleranz, ich kann
nichts dafür. :)
Nano schrieb:> Was du leider immer noch nicht verstanden hast ist folgender> Sachverhalt:>> Aus einer ökonomischen Sachverhalt (einfach, günstige Programmierer,> kurze Entwicklungszeit) der sich aus dem Markt bedingt, ergibt sich> nicht automatisch auch eine Beliebtheit, sondern eine Notwendigkeit und> das war meine Aussage in meinem allerersten Kommentar zu diesem Thema.
Bedauerlicherweise bist Du derjenige, der nicht versteht.
> Und deine ganze Diskussion wo du mit "der ist gegen Newbs" gestellten> political Correctness Empörung anfängst und somit völlig am Thema vorbei> diskutierst hättest du dir sparen können.
Das habe ich ja auch, bitte lern lesen. Mit keinem Wort habe ich mich an
Deiner Wortwahl gestört, das ist allein Deine eigene Fehlinterpretation.
Könntest Du jetzt wohl bitte damit aufhören, mit diesen Unterstellungen
vom Thema abzulenken? Danke.
> Und deswegen sind auch deine ganzen Rankings Nullaussagen in dieser> Sache.
Warum fühle ich bloß mich gerade an Morgensterns Palmström erinnert?
> Stell dir mal vor, Assembler macht Spaß! Bezahlen und daher nutzen tut's> in der Wirtschaft zwar fast keiner mehr, aber Spaß machen tut es.> Und C macht auch Spaß, das gilt erst recht, wenn die Ressourcen auch> noch begrenzt sind. Und darum geht es oben.
Stell' Dir mal vor, Assembler und C haben mir auch Spaß gemacht. Mit C++
und Python habe ich allerdings Sprachen entdeckt, die mir noch mehr Spaß
machen.
> Javascript ist dagegen ziemlich langweilig. Und Basic auch.
Ach, wenn man wie ich vom HP-97 kam, dann war Basic schon eine sehr
coole Sache. Und JavaScript, naja... als die ersten Browser mit
JavaScript kamen, habe ich noch CGIs in C entwickelt (mit der bekannten
Library von Lincoln D. Stein, hach...), und daß dieses Browserdingsi auf
einmal bewegte Dinge jenseits von <marquee>, <blink> und animierten GIFS
animieren konnte, das war schon schick. Die Sprache selbst war aber
schon damals ein ziemlicher Krampf, und ihr seitdem immer weiter
ausgeuferter Mißbrauch zu Werbe-, Ressourcenverschleuder- und ähnlichen
Nervzwecken hat meine Freude daran immer schneller abkühlen lassen.
Zudem kenne ich bis heute leider keine einzige JavaScript-Engine, die
keine erheblichen Memoryleaks aufweist.
> Und du willst nun mit deiner falschen Interpretation des Marktes, dem es> um Ökonomie und nicht um Beliebtheit geht, weiß machen, dass Javascript> mehr Spaß macht als Assembler und C.
Ich find' JavaScript auch nicht so toll, komme aber nicht darum herum,
daß eine Vielzahl der Entwickler in der SO-Survey JavaScript als eine
ihrer "Most Wanted" Sprachen angeben. Also: nicht als Sprache, zu der
sie durch ihren Beruf gezwungen werden, sondern als Sprache, die sie
nutzen WOLLEN (siehe dazu auch unter [3]). Diese Tatsache einfach
sachlich und objektiv festzustellen zwingt mich ja nicht dazu, mir die
Wünsche dieser Mehrheit zueigen zu machen.
[3] https://dict.leo.org/englisch-deutsch/to%20want> Go wird man nicht für die Systemprogrammierung nutzen.> Rust schon, da es sich auch dafür eignet.
Wer redet denn von Systemprogrammierung? Ach ja, Du. Und nur Du.
Ausschließlich Du. Veränderst Du wieder mal mitten in einer Diskussion
das Thema, um dann am Ende doch noch irgendwie glauben zu können, daß Du
Recht hattest? Pardon, aber das hatten wir ja schon häufiger, und
diesmal werde ich mich nicht darauf einlassen.
> Es geht nicht ums verbreiteter und zum beliebter siehe oben. Thema> verfehlt.
Aber klar doch, haargenau darum ging es in meinem Ausgangsbeitrag, auf
den Du so aggressiv und arrogant geantwortet hast. Warte, ich verlinke
Dir den Beitrag noch einmal, dann kannst Du das noch einmal nachlesen:
[1]. In diesem Beitrag von mir steht wörtlich: "[...] die beliebtesten
und verbreitetsten Sprachen der Welt".
[1] Beitrag "Re: Linux ist endlich vom C89 Standard weg">> Ich hatte NICHT gesagt, daß es solche "Dinge" nicht gäbe. Ich HATTE>> gesagt, daß diese "Dinge" seltener vorkommen, als viele Entwickler>> glauben.>> Und es geht hier nicht um selten oder häufig.
Doch, genau darum geht es. Mein Eingangssatz in dem soeben erwähnten und
verlinkten Beitrag [1] von mir war nämlich: "Entwickler machen sich viel
häufiger Gedanken über Performance [...]". "Häufig" steht da,
wortwörtlich, siehst Du das? Beherrschst Du die Kulturtechnik des
verstehenden Lesens? Hier noch einmal zur Erinnerung:
[1] Beitrag "Re: Linux ist endlich vom C89 Standard weg"> Siehste.> Und deswegen sind Javascript, Java, PHP, Python usw. Programmierer> billig zu haben, weil es da genug davon gibt und die Anforderungen> teilweise sogar gering sind.
Da ich mir angesichts meiner einschlägigen Erfahrung mit Deinen Aussagen
angewöhnt habe, jede davon genauer zu überprüfen, habe ich mal ein wenig
mit Python, Pandas und den Rohdaten der StackOverflow-Survey von 2021
herumgespielt, die kann man ja als CSV herunterladen. Nachdem ich zuerst
alle NaNs und Outlier verworfen und die Daten dann nach den jeweiligen
Programmiersprachen aufgedröselt habe, habe ich nun einige meiner
Vermutungen bestätigt gefunden, und zudem neue Erkenntnisse gewonnen.
Vielen Dank dafür, daß Du (wenngleich unfreiwillig) meinen Horizont
erweitert hast.
Ich habe folgende Sprachen untersucht, weil sie hier im Thread erwähnt
worden sind, und sie nach "interpretierten" und "nativen" Sprachen
gruppiert, wie folgt:
1
interesting_languages = {
2
'interpreted': [
3
'Java', 'JavaScript', 'TypeScript', 'Python',
4
'Ruby', 'PHP', 'Perl', 'Raku'
5
],
6
'native': [
7
'C', 'C++', 'Rust', 'Go'
8
]
9
}
Dabei kam heraus, daß Entwickler interpretierter Sprachen im Schnitt ca.
66931.85 US-$ im Jahr verdienen, Entwickler nativer Sprachen dagegen
71785.31 US-$. Anders gesagt, bekommen Entwickler interpretierter
Sprachen 6.76 % weniger Gehalt, wie die angehängte Grafik
"native_vs_interpreted_with_php.png" zeigt. Wenn ich die PHP-Leute
herausrechne, sind es sogar nur 5.85 %.
Bestätigt sehe ich mich also, daß Entwickler für interpretierte Sprachen
und solche für native Sprachen gar nicht so unterschiedlich viel kosten.
Das hatte ich vorher schon vermutet, aber eben nur vermutet und deswegen
nicht öffentlich äußern wollen. (Tatsächlich lege ich nämlich Wert
darauf, meine Aussagen begründen und belegen zu können; das
Hinausposaunen gefühlter Annahmen überlasse ich gerne anderen.)
Was mich hingegen überrascht hat, ist, daß Perl- und Ruby-Entwickler
heute ähnlich teuer wie Rust-Entwickler sind
("mean_salary_per_language.png"). Nur knapp darunter liegen C-, C++-,
Java- und Python-Entwickler und das Schlußlicht von den in diesem Thread
erwähnten Sprachen bilden die armen PHP-Entwickler. Mit Ausnahme der
PHP-Entwickler liegen die Gehälter aber relativ nah beieinander, und ein
Unternehmen, das seine Sprache(n) und Entwickler auf so einer Basis
auswählt, lebt ohnehin nicht lange. (Achtung: die X-Achse der
letztgenannten Grafik beginnt NICHT bei 0!)
Ein Whiskerplot über die Gehälter nach Sprachen
"salaries_per_language.png" zeigt jedoch, wie groß die Varianzen sind
und wie nah die Sprachen am Ende dann doch beieinander liegen. Der obere
Plot in der Grafik zeigt die Verteilunge der Gehälter unterhalb von 300k
US-D, deswegen die vielen Ausreißer, während ich in der unteren Grafik
nur die realistischeren Gehälter zwischen 10k und 150k US-$
berücksichtigt habe. Im Kern zeigen beide Grafiken jedoch sehr ähnliche
Gehaltsverteilungen, die sich weitestgehend überschneiden und daher
vermutlich von anderen Faktoren als der präferierten künftigen
Programmiersprache abhängen.
Die Behauptung, daß Entwickler interpretierter Sprachen signifikant
günstiger seien als jene nativer Sprachen, können wir also getrost dem
Reich der urbanen Legenden zuordnen. Dies vor allem auch wegen der sehr
hohen Gehälter für die interpretierten Sprachen Ruby und, vor allem, dem
(für mich überraschenden) Spitzenreiter Perl, der sogar Rust noch
abhängt. Wegen so geringer Differenzen macht sich jedenfalls kein
Betriebswirt ins Höschen oder muß sich gar sein Näschen pudern.
Okay, wenn billige Entwickler als Erklärung für die große Beliebtheit
und die hohe Verbreitung von interpretierten Sprachen also ausfallen und
diese Sprachen außerdem ja noch andere bekannte Nachteile haben,
namentlich eine geringere Performance und einen höheren
Ressourcenbedarf, ergibt sich als einziger logischer Schluß, daß die
interpretierten Sprachen andere Vorteile haben, aufgrund derer sie so
erfolgreich sind. Meine Vermutung ist immer noch dieselbe, die ich schon
sehr früh in diesem Thread angedeutet habe: daß nämlich die Performance
und der Ressourcenbedarf keine allzu große Rolle spielen. Mit haargenau
dieser Aussage war ich in meinem ersten Beitrag in diesen Thread
eingestiegen, nachzulesen hier: [1].
[1] Beitrag "Re: Linux ist endlich vom C89 Standard weg">> Ach, wie langweilig, Du wirst immer so aggressiv und unsachlich.>> Wenn du mich persönlich angreifst, musst du das erwarten.Ich soll Dich persönlich angegriffen haben? Wie denn? Womit denn?
Tatsächlich warst Du es doch, der hier wie ein betrunkener Holzfäller um
sich geschlagen hat, gleich mit Deinen ersten Sätzen in Deiner ersten
Antwort [2] auf meinen Beitrag von oben [1] ließest Du mich wissen, daß:
- Entwickler, die mit interpretierten Sprachen arbeiten,
billige Anfänger ("Newbs") seien
- Entwickler, die mit interpretierten Sprachen arbeiten,
so dumm seien, daß sie sogar Basic mochten
- Entwickler, die mit interpretierten Sprachen arbeiten,
unerfahrene, unfähige Dummbeutel sind, die mit "richtigen"
(nach Deiner Definition von "richtig") Sprachen nicht zurecht
kommen können
- Erfahrene Entwickler lieber mit C, C++ und Rust arbeiten
Das heißt: trotz meiner mehr als 35 Jahre Berufserfahrung mit etlichen
Sprachen tust Du mich gleich mal von vorneherein als billigen Anfänger
ab. Und natürlich weißt nur Du, was erfahrene Entwickler wollen.
Janeeisklaa.
Tatsächlich gebe ich mir aufgrund meiner sattsamen Erfahrungen mit Dir
mittlerweile gar keine Mühe, mich zurückzuhalten, wenn ich es mit Dir zu
tun habe. Ich weiß ja, daß Du Kritik und Widerspruch nicht ertragen
kannst, und dann schnell aggressiv und beleidigend wirst. Deswegen gibt
es nichts einfacheres für mich, als Dich immer nur höflich und
respektvoll zu behandeln und nichts weiter zu tun, als völlig sachlich
meine Meinungen zu vertreten. Danach muß ich nur noch anwarten, bis Du
irgendwann ausflippst und Dich selbst entlarvst -- für mich ist das sehr
komfortabel. ;-)
[1] Beitrag "Re: Linux ist endlich vom C89 Standard weg"
[2] Beitrag "Re: Linux ist endlich vom C89 Standard weg"
Karl Käfer schrieb:> Was mich hingegen überrascht hat, ist, daß Perl- und Ruby-Entwickler> heute ähnlich teuer wie Rust-Entwickler sind
Das könnte ein typisches Problem mit Statistiken sein. Wenn sich nämlich
herausstellen sollte, dass Perl-Entwickler wesentlich älter sind, weil
andere Sprachen schon vor langer Zeit den Rang abgelaufen haben. Mit dem
Alter steigt meist auch das Einkommen.
In dem Fall hättest du nicht den sich im Gehalt ausdrückenden Wert der
Programmierkenntnis in Perl ermittelt, sondern bloss die Abhängigkeit
des Gehalts vom Alter. ;-)
Eine weiterer Schmutzeffekt könnten die Bereiche sein, wo die Sprachen
eingesetzt werden. Das erklärt beispielsweise PHP, das jeder Wordpress
nutzende 08/15 Webdesigner für bescheidene Ansprüche irgendwie kennen
muss. Und davon gibts reichlich, viele sind vergleichsweise niedrig
bezahlte Frischlinge.
(prx) A. K. schrieb:> Karl Käfer schrieb:>> Was mich hingegen überrascht hat, ist, daß Perl- und Ruby-Entwickler>> heute ähnlich teuer wie Rust-Entwickler sind>> Das könnte ein typisches Problem mit Statistiken sein. Wenn sich nämlich> herausstellen sollte, dass Perl-Entwickler wesentlich älter sind, weil> andere Sprachen schon vor langer Zeit den Rang abgelaufen haben. Mit dem> Alter steigt meist auch das Einkommen.>> In dem Fall hättest du nicht den sich im Gehalt ausdrückenden Wert der> Programmierkenntnis in Perl ermittelt, sondern bloss die Abhängigkeit> des Gehalts vom Alter. ;-)
Das könnte sein, ich bin ja selbst einer von diesen "Konvertiten", die
von Perl zu Python gewechselt sind. Aber erfreulicherweise enthalten die
Daten auch Angaben zum Alter sowie dazu, wann der Entwickler mit dem
Programmieren angefangen und wieviele Jahre professioneller Erfahrung er
hat. Insofern werde ich Deinen Hinweis morgen gerne ein wenig genauer
recherchieren, danke!
Nebenbei: da ich ja selbst zu jenen gehöre, die von Perl auf Python
umgestiegen sind, mithin also früher viele Jahre lang in Perl entwickelt
habe, weil ich auch, wie häufig Perl damals eingesetzt wurde und wie
groß die vorhandene Codebasis in dieser Sprache ist. Und da wir
sicherlich beide wissen, wie ungerne Unternehmen neues Geld dafür
ausgeben, vorhandene und funktionierende Lösungen zu ersetzen, könnte
auch eine Verknappung der verfügbaren Perl-Entwickler die Daten
beeinflußt haben. Vielleicht fällt mir ja eine Möglichkeit ein, auch das
noch zu prüfen.
In dem Zusammenhang fällt insbesondere auch Ruby in den obengenannten
Daten auf. Einen Weggang der Entwickler, wie er bei Perl zu beobachten
war, habe ich bei Ruby noch nicht wahrgenommen, und der Ruby-Boom --
nicht zuletzt befeuert von Ruby On Rails, auf dem meines Wissens auch
dieses Forum basiert -- begann IIRC deutlich später als die große Zeit
von Perl. Auch diesbezüglich werde ich mal nachgrübeln, inwieweit ich
solche Entwicklungen in den Daten nachvollziehen kann. Vielleicht sollte
ich auch mal in die Daten der Vorjahre schauen und mit Plotly Express
ein paar hübsch animierte Visualisierungen erstellen, mal schauen... ;-)
> Eine weiterer Schmutzeffekt könnten die Bereiche sein, wo die Sprachen> eingesetzt werden. Das erklärt beispielsweise PHP, das jeder Wordpress> nutzende 08/15 Webdesigner für bescheidene Ansprüche irgendwie kennen> muss. Und davon gibts reichlich, viele sind vergleichsweise niedrig> bezahlte Frischlinge.
Naja, Web- und insbesondere PHP-Entwicklung wurde schon seit jeher
schlechter entlohnt als andere Bereiche und Sprachen. Das ist kein neues
Phänomen und hat womöglich auch zu dem verbreiteten Vorurteil
beigetragen, daß die Entwickler interpretierter Sprachen generell
weniger verdienten.
Was mich im Übrigen auch wundert, ist, daß Java-Entwickler so
vergleichsweise schlecht bezahlt werden. Java ist insbesondere im
Enterprise-Umfeld besonders beliebt und große Konzerne neigen häufig zu
eher höheren Gehältern, wie man auch hier im Forum daran erkennen kann,
wieviele Leute gerne einen gut bezahlten und sicheren Konzernjob
ergattern wollen. Und auch im Javabereich gibt es ja viele ältere,
erfahrene Entwickler, bei denen das von Dir erwähnte Senioriätsprinzip
zumindest theoretisch greifen müßte. Was mag da los sein, hast Du eine
Idee?
Karl Käfer schrieb:> bei denen das von Dir erwähnte Senioriätsprinzip> zumindest theoretisch greifen müßte
Als Java-Programmierer wird man zwar auch älter, aber anders als bei
Perl wachsen viele nach. Es sind heute viel mehr als früher, aufgrund
des erheblichen Wachstums der Branche. Welche Sprachen werden heute als
Teil akademischer Ausbildung gelehrt? Mir fehlt der Überblick.
Das erwähnte Alter ist nur ein einzelner Parameter, da gibts noch
andere. Die Schwierigkeit bei Statistiken ist eben, die vielen Parameter
einzufangen und einzurechnen, um sicher zu sein, dass man nicht zum
Ergebnis kommt, die Störche brächten die Babys.
Karl Käfer schrieb:> Nano schrieb:>> Es geht nicht ums verbreiteter und zum beliebter siehe oben. Thema>> verfehlt.>> Aber klar doch, haargenau darum ging es in meinem Ausgangsbeitrag,
Du hast ja auch schon da das Thema verfehlt.
> [1] Beitrag "Re: Linux ist endlich vom C89 Standard weg"
Und direkt darunter habe ich geantwortet und dir gesagt:
"Die sind verbreitet, weil die Entwickler für Firmen günstig sind, die
Newbs damit schnell zu recht kommen und die Auftraggeber die Software
möglichst kostengünstig haben wollen.
Mit beliebt hat das somit nur wenig zu tun, gut, für Newbs mag das
anders aussehen, aber die mögen bzw. mochten ja auch Basic.
Erfahrene Entwickler würden lieber in Rust oder C++ programmieren,
manche auch in C."
Daraus ergeben sich 2 Aussagen:
1. Firmen nutzen diese vielfach, weil damit Geld gespart wird.
2. Und im zweiten Abschnitt geht es gleich um die Beliebtheit, wo ich
dir anhand von 1 begründe, dass es da nicht um Beliebtheit geht.
> Dabei kam heraus, daß Entwickler interpretierter Sprachen im Schnitt ca.> 66931.85 US-$ im Jahr verdienen, Entwickler nativer Sprachen dagegen> 71785.31 US-$. Anders gesagt, bekommen Entwickler interpretierter> Sprachen 6.76 % weniger Gehalt, wie die angehängte Grafik> "native_vs_interpreted_with_php.png" zeigt. Wenn ich die PHP-Leute> herausrechne, sind es sogar nur 5.85 %.>> Bestätigt sehe ich mich also, daß Entwickler für interpretierte Sprachen> und solche für native Sprachen gar nicht so unterschiedlich viel kosten.
6 bis 7 % Gehaltsunterschied ist nicht unerheblich.
> Was mich hingegen überrascht hat, ist, daß Perl- und Ruby-Entwickler> heute ähnlich teuer wie Rust-Entwickler sind
Ja, was wohl an der Seltenheit liegt entsprechende Leute zu finden.
Dann muss man halt mehr zahlen.
> Die Behauptung, daß Entwickler interpretierter Sprachen signifikant> günstiger seien als jene nativer Sprachen, können wir also getrost dem> Reich der urbanen Legenden zuordnen.
6-7 % Gehaltsunterschied ist kein Hintergrundrauschen.
Deine Daten bestätigen eher meine Aussage als deine.
>>> Ach, wie langweilig, Du wirst immer so aggressiv und unsachlich.>>>> Wenn du mich persönlich angreifst, musst du das erwarten.>> Ich soll Dich persönlich angegriffen haben? Wie denn? Womit denn?
Na hier:
Beitrag "Re: Linux ist endlich vom C89 Standard weg"
Dein erster Satz zur Anleitung, dabei war das gar nicht relevant:
> Vielleicht solltest Du nicht so arrogant auf die "Newbs" herabblicken...
Und im gleichen Kommentar deine nächste Beleidigung:
> Insofern, sei mir bitte nicht böse, aber von kommerzieller> Softwareentwicklung und deren ökonomischen Hintergründen scheinst Du> nicht allzu viel Ahnung zu haben, und solltest deswegen vielleicht auch> nicht versuchen, damit zu argumentieren. Für Dein Hobby kannst Du> Tatsächlich warst Du es doch, der hier wie ein betrunkener Holzfäller um> sich geschlagen hat,
Ich habe nur auf deine Angriffe entsprechend reagiert.
> gleich mit Deinen ersten Sätzen in Deiner ersten> Antwort [2] auf meinen Beitrag von oben [1] ließest Du mich wissen, daß:>> - Entwickler, die mit interpretierten Sprachen arbeiten,> billige Anfänger ("Newbs") seien>> - Entwickler, die mit interpretierten Sprachen arbeiten,> so dumm seien, daß sie sogar Basic mochten>> - Entwickler, die mit interpretierten Sprachen arbeiten,> unerfahrene, unfähige Dummbeutel sind, die mit "richtigen"> (nach Deiner Definition von "richtig") Sprachen nicht zurecht> kommen können
Dergleichen habe ich gar nicht geschrieben. Ich habe geschrieben:
"Die sind verbreitet, weil die Entwickler für Firmen günstig sind, die
Newbs damit schnell zu recht kommen und die Auftraggeber die Software
möglichst kostengünstig haben wollen.... "
Da steht günstig und nicht billig und es stimmt auch. Ein PHP
Programmierer kostet weniger als ein C oder C++ Programmierer.
Und es ist auch richtig, dass Python bei Newbs beliebt ist, weil man
damit schnell zum Ziel kommt, während man sich bei C noch um die
Speicherverwaltung selber kümmern müsste, was Newbs abschreckt.
Ich habe also lediglich Fakten geliefert, und wie du jetzt oben
verlautbaren lässt, hast du das falsch verstanden und mich dann
anschließend, siehe oben angegriffen.
> - Erfahrene Entwickler lieber mit C, C++ und Rust arbeiten
Und das ist auch wahr.
Java mit seinem Garbage Collector ist bei erfahrenen Entwicklern nicht
so beliebt wie C++.
> Das heißt: trotz meiner mehr als 35 Jahre Berufserfahrung mit etlichen> Sprachen tust Du mich gleich mal von vorneherein als billigen Anfänger> ab.
Von dir habe ich gar nicht gesprochen, ich bin auf deine Aussage ein und
habe dir versucht zu erklären, woran das liegt und dafür hast du mich
angegriffen und ich habe dann darauf entsprechend reagiert. Das Problem
liegt also an dir, weil du nen Elefanten aus nichts machst.
> Und natürlich weißt nur Du, was erfahrene Entwickler wollen.> Janeeisklaa.
Jupp.
> Ich weiß ja, daß Du Kritik und Widerspruch nicht ertragen> kannst, und dann schnell aggressiv und beleidigend wirst.
Das ist eine weitere Unterstellung. Ich gebe nur raus, wenn man mich
vorher beleidigt, nie anders herum und das war hier schon immer so.
Wer mit mir also niveauvoll diskutiert, der kriegt von mir auch
niveauvolle Antworten.
Wer mich aber persönlich angreift, wie du es getan hast, der kriegt dann
eben auch die entsprechende Reaktion darauf.
>Deswegen gibt> es nichts einfacheres für mich, als Dich immer nur höflich und> respektvoll zu behandeln und nichts weiter zu tun, als völlig sachlich> meine Meinungen zu vertreten.
An deinen obigen Unterstellungen war nichts sachlich.
Ach, inzwischen sind wir bei der verbalen Prügelei angekommen. O ha.
Da kommt mir ein altberliner Witz in den Sinn: sagt ein Gammler zu einem
anderen: "Du, da hat eena jesacht, ick seh aus wie du" - Antwort: "Wer
war det? Den hau ick inne Fresse".
Na dann, frohes Weiterprügeln.
W.S.
Georg A. schrieb:> So insgesamt finde ich diese Trends recht unterhaltsam. Wir werden uns> evtl. noch so 5-10 Jahre mit immer strengerer Typprüfung aufhalten, und> dann wird auf den Konferenzen der nächste "Paradigm Shift" verkündet.> Wird ganz schickes "Untypescript" geben, das mit KI automatisch immer> die richtigen Cast und Konverter findet und es muss sich mehr mehr um> irgendwelche blöden Typen kümmern ;)
Das wäre doch toll, wenn man sich nicht mehr um blöde Typen kümmern
müsste. Noch besser wäre aber, wenn dabei auch gleich das Problem mit
blöden Typinnen gelöst werden könne. Aber ich fürchte, dass das weder
eine Sprache noch eine KI leisten können, denn dabei scheitert ja
manchmal sogar die RI.
(prx) A. K. schrieb:> Als Java-Programmierer wird man zwar auch älter, aber anders als bei> Perl wachsen viele nach. Es sind heute viel mehr als früher, aufgrund> des erheblichen Wachstums der Branche. Welche Sprachen werden heute als> Teil akademischer Ausbildung gelehrt? Mir fehlt der Überblick.
Meines Wissens sind Java und C++ dort weit verbreitet.
> Das erwähnte Alter ist nur ein einzelner Parameter, da gibts noch> andere. Die Schwierigkeit bei Statistiken ist eben, die vielen Parameter> einzufangen und einzurechnen, um sicher zu sein, dass man nicht zum> Ergebnis kommt, die Störche brächten die Babys.
Ach, ich weiß nicht... an der Churchill zugeschriebenen Aussage, "ich
glaube keiner Statistik, die ich nicht selbst gefälscht habe", ist
sicherlich etwas dran, und für Umfragen, deren Ergebnisse nach
einschlägigen Untersuchungen sehr stark von der Art der Fragestellung
abhängen, gilt das natürlich noch viel mehr. Andererseits erlebe ich
auch sehr häufig, daß viel mehr in eine Statistik hinein interpretiert
wird, als eigentlich darin steht. Das geschieht mal bewußt, häufiger
aber sogar unbewußt. Man muß also nicht nur als Produzent, sondern auch
als Konsument von Statistiken immer darauf achten, wie die Datenbasis
zustande gekommen ist, welche Aussagekraft sich daraus ableiten läßt,
welche(r) Aspekt(e) betrachtet und sie das getan wurde. Wer das nicht
penibel beachtet, wird schnell entweder vom Statistiker oder sogar vom
eigenen Kopf in die Irre geführt.
Wie dem auch sei, Du scheinst mit Deiner Vermutung absolut Recht zu
haben. In den Daten von SO ist das Alter leider nur in Altersklassen
angegeben und deswegen nur begrenzt aussagekräftig. Aber in den Daten
sind die Jahre als Coder ("yearscode") sowie die Jahre als
professioneller Entwickler ("yearscodepro") angegeben, und mit diesen
Daten ergeben sich, nach Sprachen sortiert, die in der angehängten
Grafik "yearscode_yearscodepro_per_language.png" abgebildeten Plots. In
beiden Diagrammen zeigt sich, daß Perl-Entwickler im Schnitt deutlich
mehr Erfahrung haben als die Entwickler in anderen Sprachen.
Schon häufiger habe ich nun gehört, daß das Senioritätsprinzip in
Deutschland besonders ausgeprägt sei. Darum habe ich mir das in den
weltweit gesammelten Daten von SO einmal genauer angeschaut, einmal
insgesamt und einmal nach den Sprachen aufgesplittet. Die Ergebnisse
finden sich in den anderen angehängten Diagrammen "salary_per_<xyz>.png"
und zeigen das Erwartete, daß das Senioritätsprinzip keine rein deutsche
Spezialität zu sein scheint.
Nano schrieb:> Dergleichen habe ich gar nicht geschrieben.
Laß' gut sein. Ich habe schon sehr gut verstanden, was Du geschrieben
hast, wie es gemeint, und an wen es gerichtet war. Und wenn Du gar so
empfindlich bist und alle Kritik und jeden Widerspruch gleich als
persönliche Beleidigung und als Angriff wahrnimmst, stünde es Dir besser
zu Gesicht, Dich von vorneherein erst einmal an die eigene Nase zu
fassen und Dich in Deiner eigenen Wortwahl zu mäßigen. Erstmal den
Lauten geben, über Unternehmen und "Newbs" ranten, und uns anderen
vorschreiben zu wollen, in welcher Sprache sie gefälligt gerne zu coden
haben, um als "erfahrene Entwickler" durchgehen zu dürfen, dann aber das
Schneeflöckchen zu geben, wenn die sich das nicht gefallen lassen und
Dir widersprechen, wirkt leider ein bisschen... arrogant und
inkonsequent.
All das habe ich Dir schon zwei- oder dreimal gesagt und auch, was schon
unsere Mütter wußten: wie man in den Wald hineinruft, so schallt es
wieder heraus. Ich reagiere gemeinhin sehr sensibel auf mein Gegenüber,
und wenn Du mir immer gleich mit der Keule kommst, wirst Du auch
fürderhin damit rechnen müssen, daß auch ich eine solche besitze -- und
bisher nicht glaube, daß Deine größer ist.
Was die Gehaltsunterschiede angeht, so mǘßte eigentlich jeder leicht aus
meinen Diagrammen erkennen können, wie groß die Streuungen und wie
vernachlässigbar also popelige sechs oder sieben Prozent sein müssen.
Aber laß' gut sein, Du hast Recht und ich hab' meine Ruhe. Au reservoir,
mondamin. ;-)
Karl Käfer schrieb:> Nano schrieb:> Und wenn Du gar so> empfindlich bist und alle Kritik und jeden Widerspruch gleich als> persönliche Beleidigung und als Angriff wahrnimmst, stünde es Dir besser> zu Gesicht, Dich von vorneherein erst einmal an die eigene Nase zu> fassen und Dich in Deiner eigenen Wortwahl zu mäßigen.
Der Unterschied ist, ich habe meine Aussagen allgemein gehalten und
niemanden beleidigt, mein Newb oben enthält nicht einmal einen wertenden
Charakter, der entstand bei dir lediglich nur in deinem Kopf, weil du
etwas dazu gedichtet hast, was nicht da steht. Während du deine Aussage
direkt auf mich gerichtet hast. Und das macht einen sehr großen
Unterschied aus, insbesondere juristisch.
Uns selbst wenn mein Newb eine wertende Komponente enthalten hätte und
ich z.b. gesagt hätte:
"Newbs blicken es nicht."
Dann dürfte ich das sogar sagen, denn Newbs ist nicht näher definiert,
die Gruppe ist nicht fassbar, wann ist man ein Newb, wann beginnt man
keiner mehr zu sein? Daher wäre das trotz wertendem Charakter eine
Meinung und keine Beleidigung.
Wenn du nun aber sagst:
"Nano blickt es nicht."
Dann sieht's schon juristisch ganz anders aus. Denn meine Person ist
eindeutig und dann ist das keine Meinung mehr, sondern eine klare
Beleidigung.
Deswegen nochmal, ich habe keinen beleidigt, du aber mich sehr wohl.
> Erstmal den> Lauten geben,... "Newbs" ranten,
Eben nicht.
Nochmal, der Defekt entstand in deinem Kopf.
Und über Unternehmen habe ich schon gar nicht "geranted". Ich sagte
lediglich, dass Unternehmen Sprachen, wo die Programmierer günstig sind,
bevorzugen und das ist ökonomisch völlig normal und entspricht auch der
Realtität.
> wie man in den Wald hineinruft, so schallt es> wieder heraus.
Dann streng dich das nächste mal an und dichte beim Lesen nicht Sachen
dazu, die nicht da stehen.
> Ich reagiere gemeinhin sehr sensibel auf mein Gegenüber,
Das sieht man. Deswegen habe ich dir auch gesagt, dass ich in meinem
Code noch eine Master und Slave Bezeichnung nutze.
Wahrscheinlich fällst du da gleich vom Stuhl, weil ich das benutze.
Vermutlich achtest du auch ganz penibel auf Gendersprech und wenn das
Fußgängermännchen bei einer Ampel nicht geschlechtsneutral ist, dann
springst du wahrscheinlich aufgrund von political Fehlverständnis auf
die Barrikaden und schreibst dem Bürgermeister einen dicken
Beschwerdebrief anstatt die Kirche einfach mal im Dorf zu lassen.
> und wenn Du mir immer gleich mit der Keule kommst, wirst Du auch> fürderhin damit rechnen müssen, daß auch ich eine solche besitze -- und> bisher nicht glaube, daß Deine größer ist.
Machst du jetzt auf Trump?
Schon erstaunlich wie man sich an so einem Thema aufgeilen kann.
Jeder huldigt halt seinem Gott oder snders herum: "Du sollst keine
Götter haben neben mir"
Nano schrieb:> Wenn du nun aber sagst:> "Nano blickt es nicht.">> Dann sieht's schon juristisch ganz anders aus. Denn meine Person ist> eindeutig und dann ist das keine Meinung mehr, sondern eine klare> Beleidigung.
Ach wo, das ist weder eine Beleidigung noch eine Meinung, sondern
lediglich das Nennen einer Tatsache.
Oder?
Hiermit erlaube ich mir, auch mal ne homöopatische Prise Schlamm für die
hier gerade stattfindende Schlacht aufzunehmen. Was - bittesehr - hat
das alles mit dem Thema dieses Threads zu tun? Rein garnichts. Außer der
Gereiztheit, daß Leute sich nicht in der ihrer eigenen Meinung nach
ihnen gebührenden Verehrung angesehen fühlen.
Karl Käfer schrieb:> Au reservoir, mondamin. ;-)
Törööh!
W.S.
Stefan ⛄ F. schrieb:> Nano schrieb:>> Denn meine Person ist eindeutig>> ?????? Schon vergessen, dass dein Ego hier anonym auftritt?
Das spielt keine Rolle, weil ein Angriff sich ja an die Person hinter
dem Pseudonym richtet.
Nano schrieb:> Stefan ⛄ F. schrieb:>> Nano schrieb:>>> Denn meine Person ist eindeutig>>>> ?????? Schon vergessen, dass dein Ego hier anonym auftritt?>> Das spielt keine Rolle, weil ein Angriff sich ja an die Person hinter> dem Pseudonym richtet.
Ihr kriegt mich nicht!
Nano schrieb:> Ihr kriegt mich nicht!
Mein Pseudonym kopieren und sich als mich ausgeben ist eine ganz billige
unterwürfige Taktik.
Insofern, wer immer du auch bist, schäm dich.
Alle anderen dürfen auf die Uhrzeit desjenigen gucken, als er das
Kommentar gepostet hat. Um 7:49 Uhr poste ich höchst selten.
Und der Mod kann die IP vergleichen, insofern ist das recht eindeutig.
@Moderation
Könntest ihr mal all IPs in diesem Thread vergleichen und gucken,
welcher Forennutzer die gleiche IP hat, wie die des Kommentators der
hier im Thread am 04.06.2022 um 07:49 Uhr gepostet hat?
Wäre doch mal interessant zu erfahren, wer da dahintersteckt.
MaWin schrieb:> Nano schrieb:>> Mein Pseudonym kopieren und sich als mich ausgeben ist eine ganz billige>> unterwürfige Taktik.>> Ja. Schäme dich!
Damit hast du dich jetzt verraten. Jetzt wissen wir, wer es war.
Nano schrieb:> eine ganz billige unterwürfige Taktik.
Was bittesehr ist eine unterwürfige Taktik?
Etwa sowas wie damals im späten oströmischen Reich aka Byzanz: sich im
Staube rückwärts kriechend wälzen vor dem Herrscher? Oder was?
W.S.
Oliver S. schrieb:> 🐧 DPA 🐧 schrieb:>> Aber Hersteller nutzen Legale und Technische Wege, das zu umgehen>> Das Recht ist schon eine blöde Sache: Es nutzt nicht nur einem selber,> sondern auch anderen. Das MUSS sofort geändert werden.
Jetzt haben sie es auf eure Autos abgesehen!
https://www.theverge.com/2022/7/12/23204950/bmw-subscriptions-microtransactions-heated-seats-feature
Tick Tack, schaut ruhig nur zu, bis ihr euch 2mal überlegen müsst, ob
ihr lieber einen gefrorenen Arsch oder weniger auf dem Konto haben
wollt! Es könnte ja sonst dem Gewinn der Autoindustrie schaden!
Daniel A. schrieb:> Jetzt haben sie es auf eure Autos abgesehen!> https://www.theverge.com/2022/7/12/23204950/bmw-subscriptions-microtransactions-heated-seats-feature>> Tick Tack, schaut ruhig nur zu, bis ihr euch 2mal überlegen müsst, ob> ihr lieber einen gefrorenen Arsch oder weniger auf dem Konto haben> wollt! Es könnte ja sonst dem Gewinn der Autoindustrie schaden!
Das war doch bis jetzt auch so. Wer etwas besseres mit seinem Geld zu
tun weiß, der kauft keine Sitzheizung.
Daniel A. schrieb:> Aber jetzt musst du dir das jeden Monat von neuem überlegen.
Kann ich, muss ich aber nicht. Ich kann mich sogar nach einem
ausgedehnten Test dagegen entscheiden.
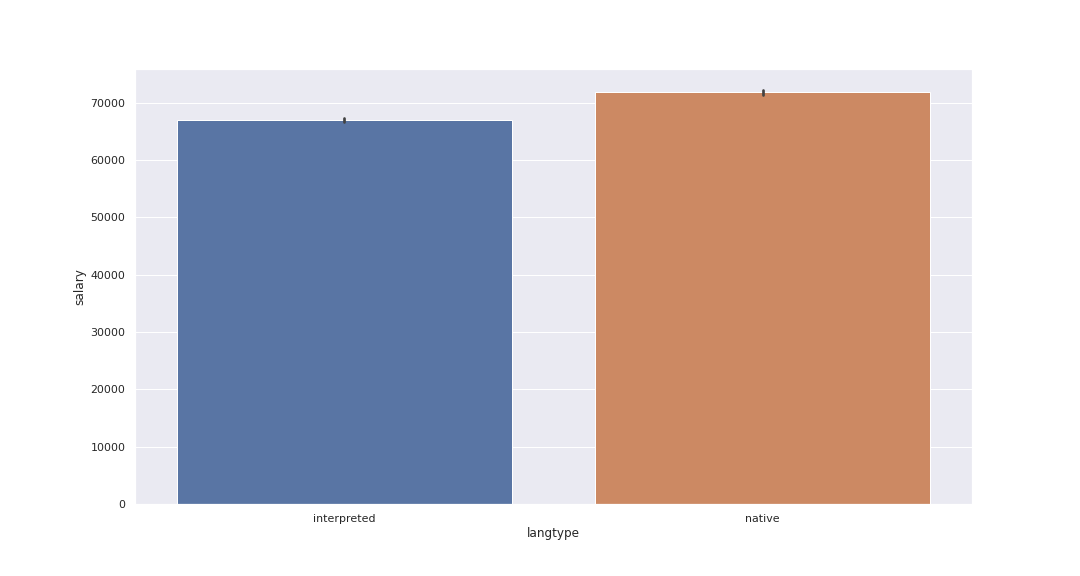
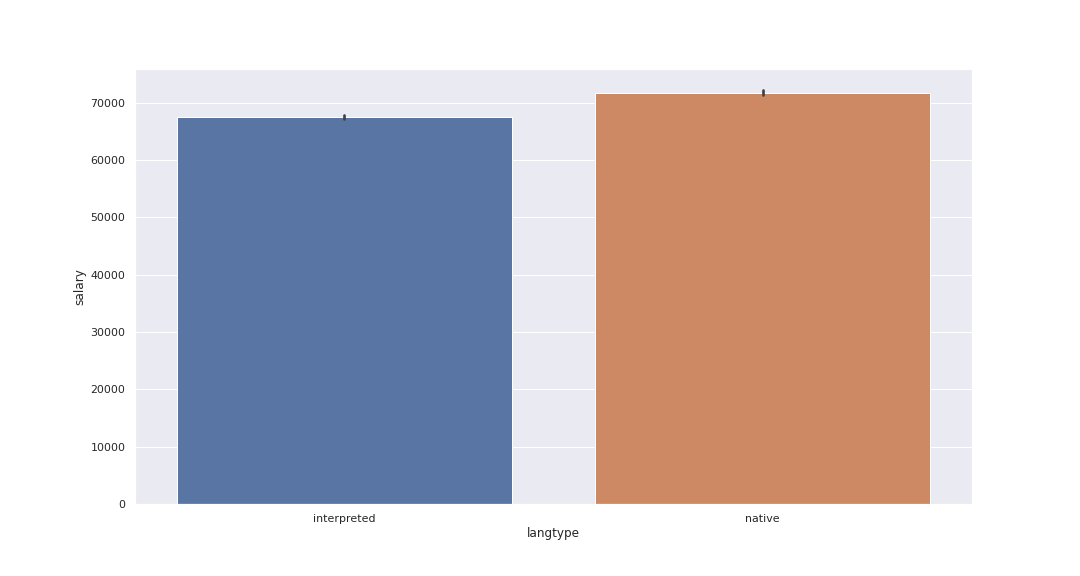
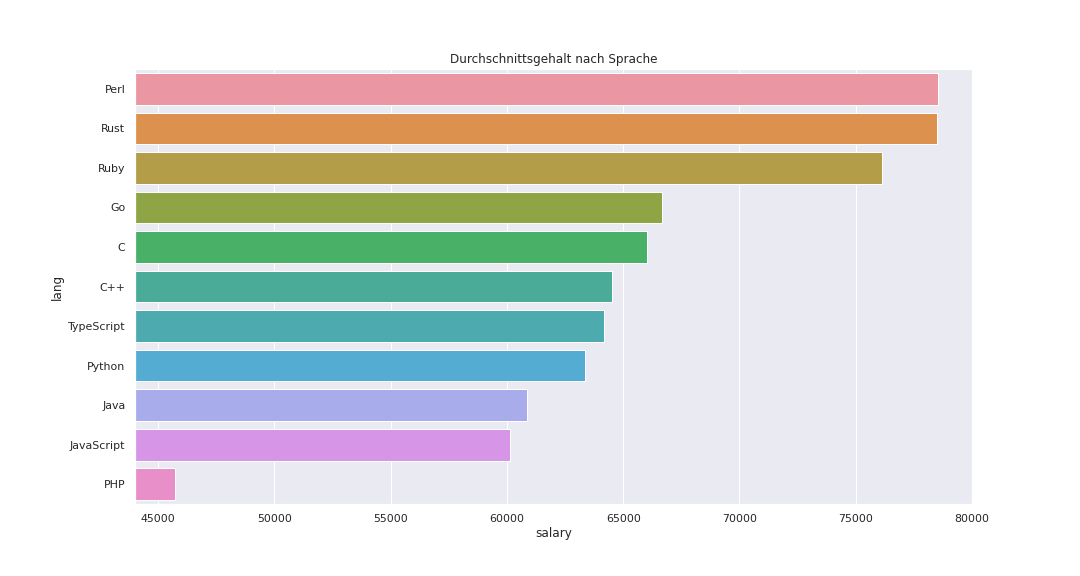
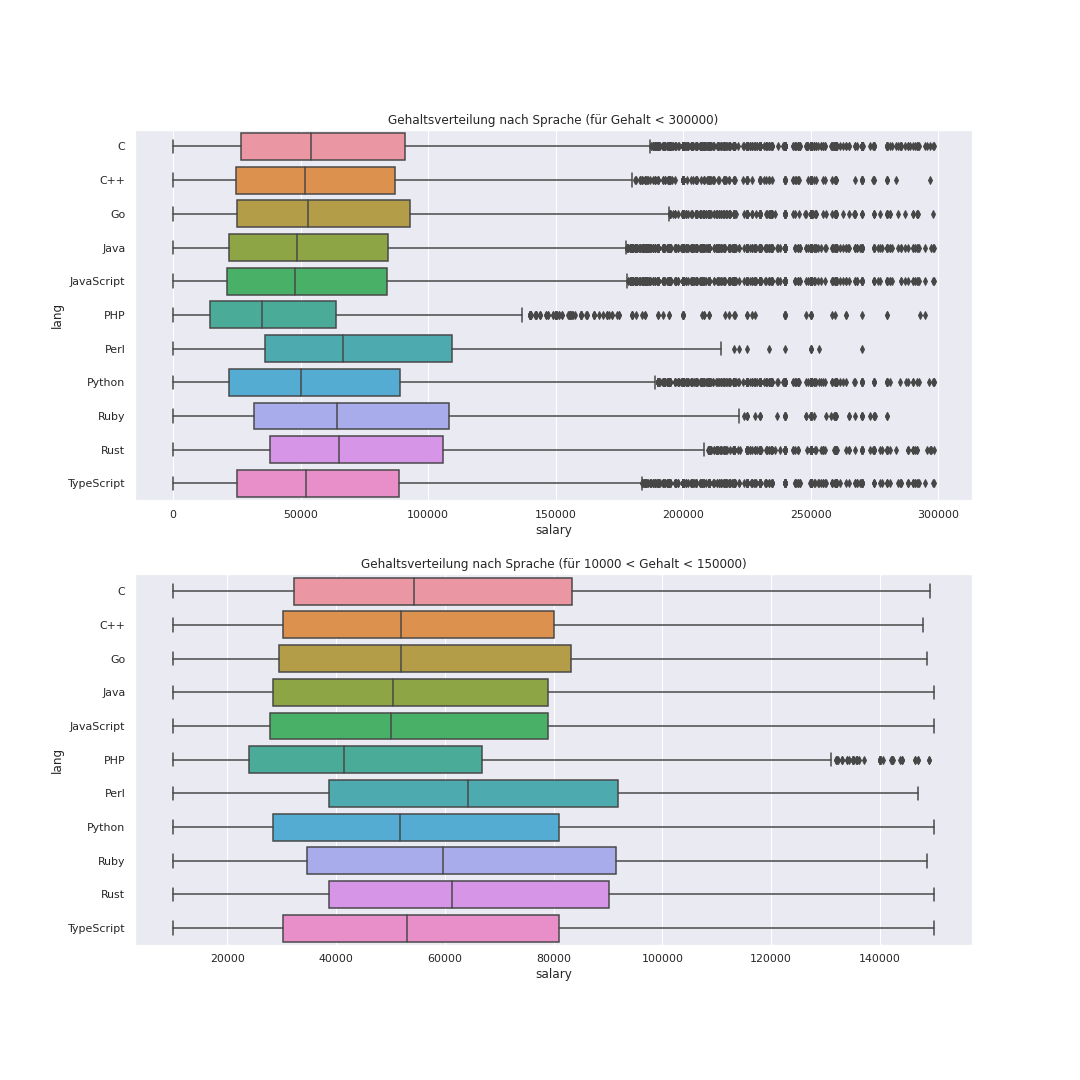
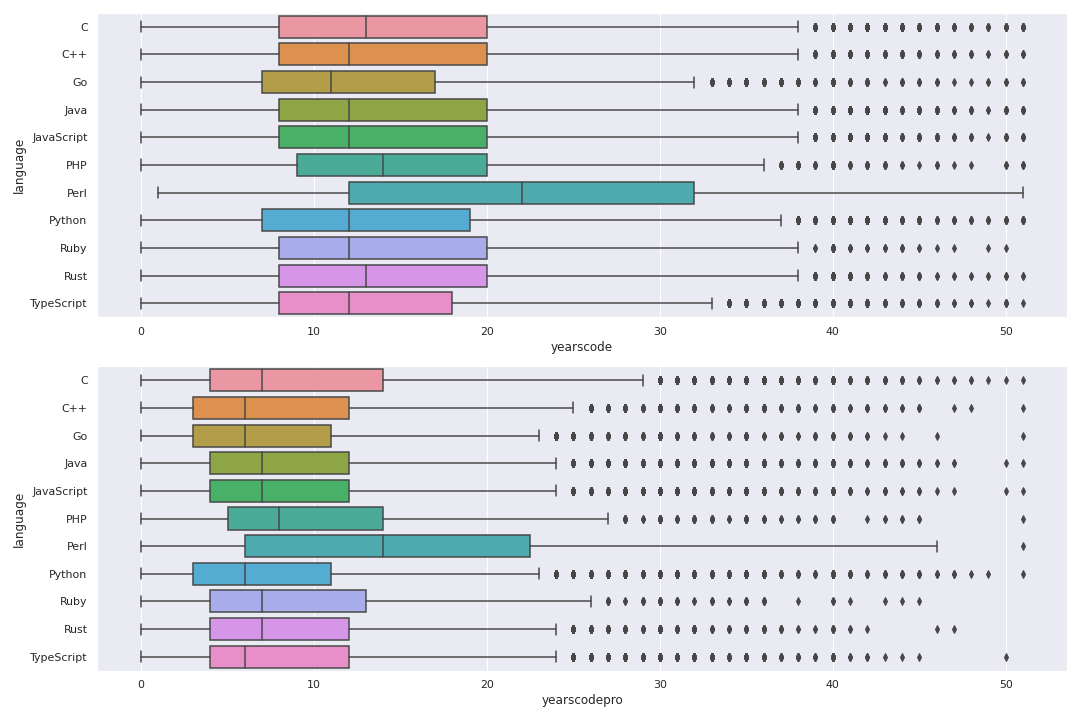
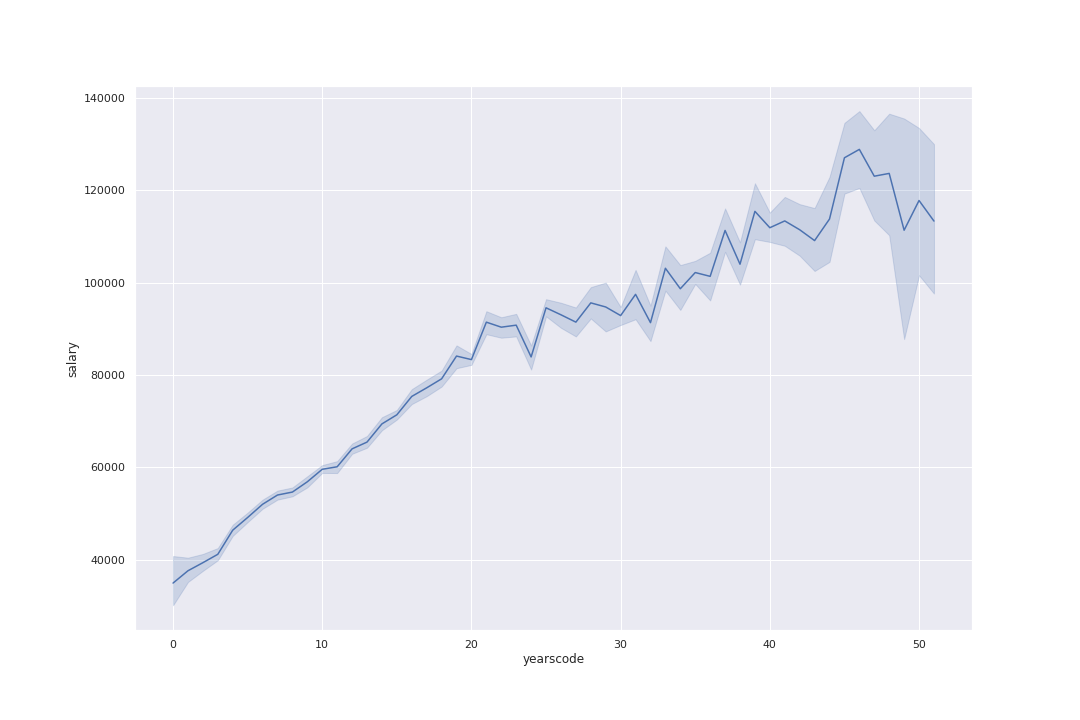
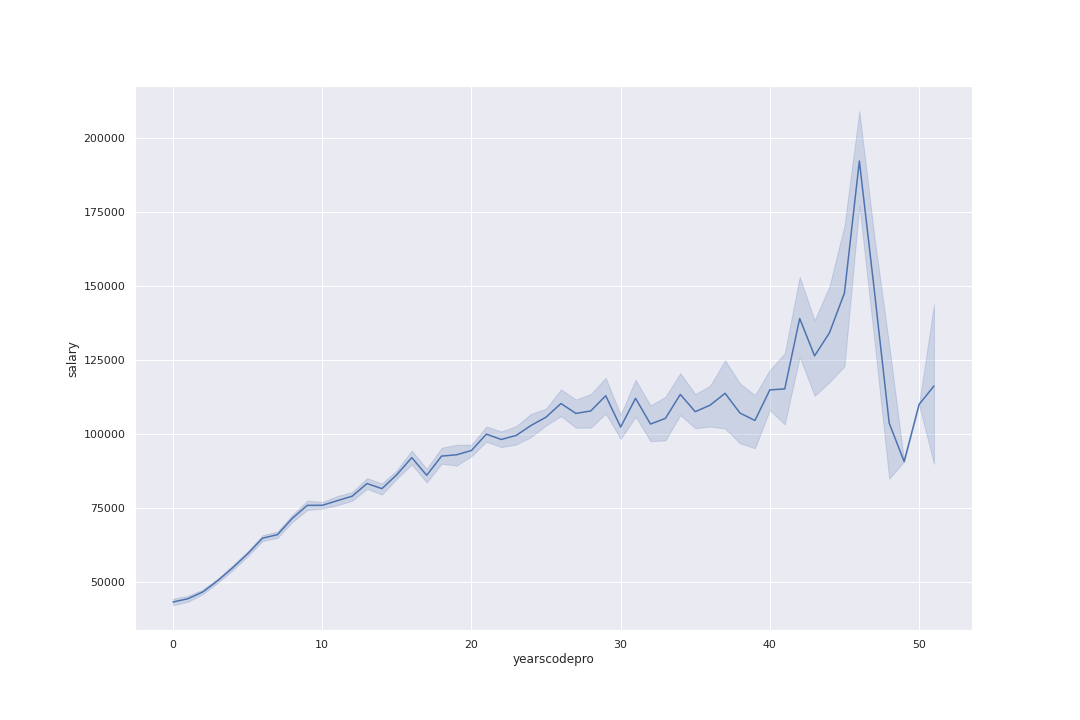
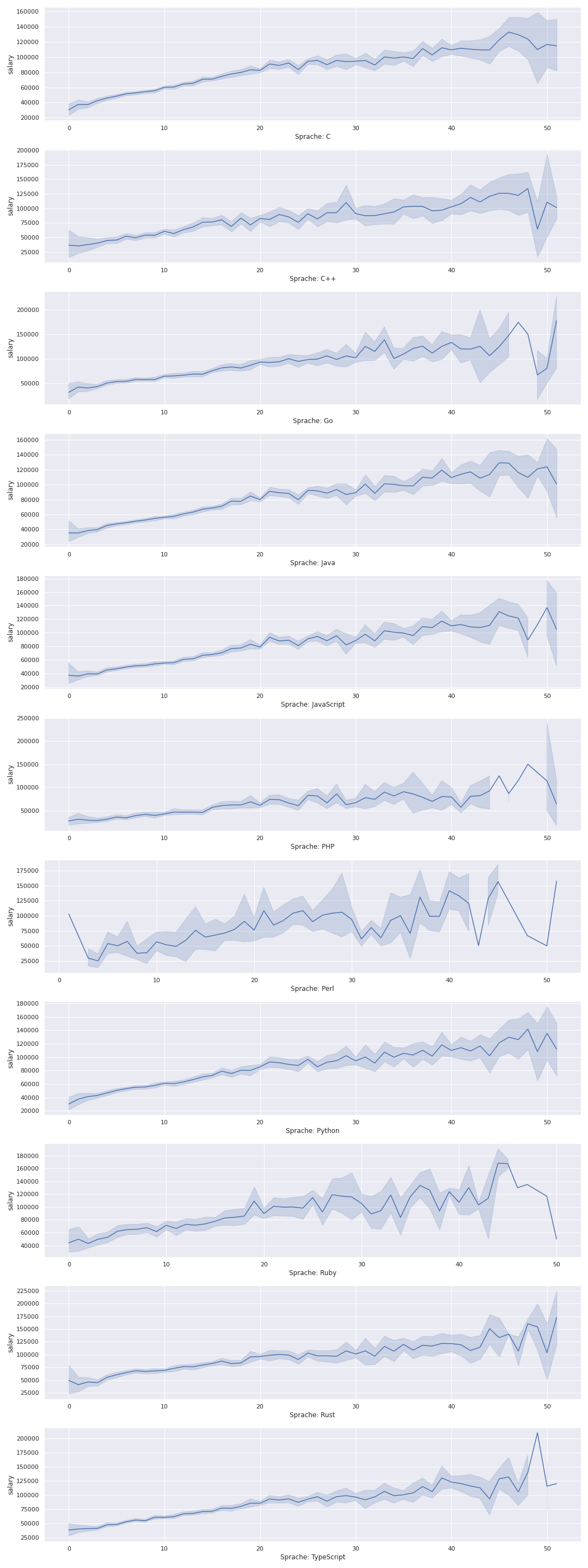{kind=link}