Weiß wer von euch ob sich dieses Bild in Tramperts Buch befindet und wenn ja, auf welcher Seite? Nur noch kurz zum Verständnis: RISC Architektur hängt mit dem reduzierten Befehlssatz zusammen und bei der Harvard Architektur sind Daten- und Programmspeicher getrennt. Beides führt dazu, dass die AVR schneller sind. Aber folgt aus einer RISC Architektur grundsätzlich eine Harvard Architektur, oder kann man das unabhängig voneinander betrachten? Gruß, Stefanie
Angehängte Dateien:
-

HarvardArchitektur.jpg
12 KB
.............man kann das unabhängig voneinander betrachten
OK, fehlt dann noch ein wichtiger Pkt, wenn man einen Atmega vorstellen möchte?
>RISC Architektur hängt mit dem reduzierten Befehlssatz zusammen
klingt irgendwie schwammig...
RISC heisst ja schon "Reduced Instruction Set Computer" (oder so
ähnlich; auf jeden Fall "Reduced...").
Könntest du den Unterschied zwischen RISC und CISC erläutern?
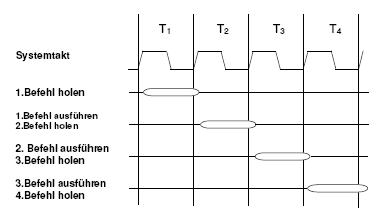
>Weiß wer von euch ob sich dieses Bild in Tramperts Buch befindet und >wenn ja, auf welcher Seite? Ja, dieses Bild befindet sich in dem Buch auf Seite 15 als Abb. 1. 1. 1. Die zugehörige Bildunterschrift lautet: "Pipelinig-Verfahren der AVR-Controller beim Holen (Instruction Fetch) und Ausführen (Instruction Execute) der Befehle".
hi, ersten vielen Dank für die Quelle und den Untertitel!! Also, bei RISC sind die Befehle werden die Befehle durch die Hardware dekodiert -> schnell. Der Befehlssatz von den AVR ist so um die 100 und bei den CISC oftmals sogar über 300 (die dafür komplex sind). Früher waren CISC-Controller sinnvoll, da der Prozessor viel schneller war als der Speicher und deshalb konnte der Prozessor statt auf den nächsten Speicherzugriff warten zu müssen, in der Zeit seinen komplexen Befehl dekodieren... Hier hab ich grad ein paar interessante Vergleiche gefunden: http://members.inode.at/g.steurer.pernsteiner/Ausarbeitung_Portalsachsen_Kapitel%202.pdf Aber irgendwie hab ich noch ein Verständnisproblem mit der ganzen Angelegenheit: Harvard-Architektur bedeutet getrennte Busse für Programmspeicher (Flash) und Datenspeicher (RAM). Pipelining bei AVRs bedeutet, dass er in einem Takt einen Befehl auf dem Flash holen kann und gleichzeitig einen Befehl in der Alu abarbeiten kann?? Hat das was mit der Harvard-Architektur zu tun???
Also, ich hab mir mal das Blockschaltbild des Atmega128 rausgeholt. Das Program Flash ist 16 Bit breit, in einem Takt wird ein Befehl in das Instruction Register geladen (was macht der Instruction Decoder noch? dachte man muss nichts mehr dekodieren, geht ja irgendwie auch ins Leere auf dem Bild) Durch den Befehl im Instruktion Register kann nun das SRAM mit den gespeicherten Daten oder die "Arbeitsregister" direkt angesprochen werden. Die 8-Bit breiten Daten werden dann doch erst beim nächsten Takt in die Register(auch im SRAM, oder?) geladen werden und dann im übernächsten Takt in der ALU bearbeitet. Also, Befehl holen und gleichzeitig in der Alu bearbeiten geht klar, aber wenn ich vorher noch was aus dem SRAM holen muss, dann funktioniert das doch nicht so ganz, oder??? Stell mich grad etwas...
OK, wer lesen kann ist klar im Vorteil ;-) Im Datenblatt steht beschrieben, wie eine Operation funktioniert. Wenn nun aber für die Addition ein Summand nicht im Register steht, muss er aber doch erst mit einem Takt in ein Register geschrieben werden -> das Piplining funktioniert nicht immer so schön wie auf dem Bild oben. D.h. für mich aber auch, dass für das Pipelining die Harvard-Architektur verantwortlich ist. Wenn das alles soweit stimmt, dann frag ich mich nur noch, was der Instruction Decoder noch soll...
Es ist schwer, den Unterschied an der Anzahl der Befehle festzumachen, z.B. der 8051 ist ein CISC, hat aber auch nur wenige Befehle. RISC machen nur eine Aktion pro Befehl (INC, BRNE), CISC haben dagegen viele kombinierte Befehle (DJNZ, CJNE, JBC) und benötigen dadurch weniger Codespeicher. Ich habe das sehr deutlich gemerkt, als ich C-Programme vom 8051 auf den AVR portiert habe. Was bequem in einen AT89C2051 paßte, ging nie in einen ATtiny2313 rein. Für die C-Programmierung habe ich mich daher auf den ATmega8 eingeschossen, obwohl die Pinzahl eines ATtiny8313 dicke reichen würde, wenn es ihn bloß endlich mal gäbe. Peter
> Für die C-Programmierung habe ich mich daher auf den ATmega8 > eingeschossen, obwohl die Pinzahl eines ATtiny8313 dicke reichen > würde, wenn es ihn bloß endlich mal gäbe. Das hörts sich bei dir ja gerade so an, als ob du jedes Projekt mit nem N-Pinner machst, koste es was es wolle. Was machst du, wenn du mal 2 Pin mehr brauchst? Fällt das Projekt dann ins Wasser? N-Pinner habe ich jetzt nur mal gesagt, weil mir der ATtiny8313 nichts sagt.
Soweit ich weiß, ist das hübsche Bildchen für einen AVR gar nicht zutreffend, weil der nur jeweils zwei Instruction-Words pipelinet, was daran erkenntlich ist, dass ein Branch-Befehl nicht mehr als zwei Takte dauert. Was grundsätzlich nichts mit der Harvard-Architektur zu tun hat, wie uns einst der Pentium mit seiner gegenüber dem Vorgänger 486 deutlich verlängerten Pipeline klarmachte: Mit 17 gegenüber 7 Bytes, die bei einem Branch verworfen werden mussten, war der Pentium einem 486 mit derselben Taktrate allemal noch unterlegen. Das änderte sich erst, als der Pentium die 200MHz erreichte, wo der 486 einfach nicht mehr mitkam. Was der Instruction Decoder da noch soll, sollte eigentlich keine Frage sein: Er ist die einzige Instanz in der Pipeline, die über die weitere Verwertbarkeit bereits eingelesener Bytes/Worte entscheiden kann... Sonst noch Fragen? Ich beantworte sie gerne, soweit ich kann. Gruß Johannes
> Pipelining bei AVRs bedeutet, dass er in einem Takt einen Befehl > auf dem Flash holen kann und gleichzeitig einen Befehl in der Alu > abarbeiten kann?? Hat das was mit der Harvard-Architektur zu tun??? Nein, Pipelining hat überhaupt nichts mit Harward zu tun. "Pipelining" ist einfach die Technik, dass die einzelnen Schritte der Befehlsabarbeitung überschneidend statt finden. Die drei Konzepte a.) RISC vs. CISC b.) Harvard vs. von-Neumann c.) Pipelining vs. Non-Pipelining haben nichts miteinander zu tun. Übrigens, in modernen PC-Prozessoren wird das Pipelining ziemlich auf die Spitze getrieben. So eine Pipeline hat oft eine Tiefe von über 20 Befehlen, und es gibt oft auch mehrere Pipelines damit zwei oder mehrere Befehle gleichzeitig bearbeitet werden können.
@Johannes Das hübsche Bildchen gilt für AVR, hab ich grad auch im Datenblatt selbst gefunden. Von-Neumann und Pipelining schneidet sich nach meinem Gefühl etwas, aber das kann ich akzeptieren :-) Es ist schön, langsam mal ein bißchen was zu verstehen! DANKE!! Mir fällt da noch eine Frage ein und zwar, wenn ich ein externes RAM nutze, merkt das der ATmega das eines angeschlossen ist und speichert seine "Arbeitsdaten" da dann automatisch rein, oder brauche ich dass, wenn ein anderer Baustein mit 15 Adress- und 8 Datenleitungen angesprochen wird?
@Peter Danneger, na dann freu Dich schon mal auf die tiny461/861 :-) Die sind am Kommen. Ansonsten zu Deinem Problem mit dem tiny2313 versus AT892051 kann ich nur vermuten, dass Du da vielleicht den falschen Compiler befragt hast. Allerdings, ich gebe zu, gibt es da durchaus einen Grenzbereich... Gruß Johannes
@Stefanie, in welchem Datenblatt? In dem, das ich gerade aufgeschlagen hatte, stand es nicht. Ansonsten: Nein, ein AVR merkt von sich aus nicht, dass externes RAM im Spiel ist. Und was das Speichern von Arbeitsdaten im externen RAM angeht, weiß ich bisher nur vom iccavr-C-Compiler, dass der das automatisch tut. Gruß Johannes
Datenblatt ATmega128 Seite 13. Aber das stimmt dann wohl, oder: wenn ein anderer Baustein mit 15 Adress- und 8 Datenleitungen angesprochen wird
Nunja, im aktuellen Datenblatt vom mega128 ist es Seite 15, aber ok, ich habs gefunden. Andererseits: Wenn ein externes Daten-RAM in Spiel ist, gilt die Figure 6 bzw. 7 sowieso nicht mehr... siehe Figure 13-16. Gruß Johannes
noch einer wrote: > Ansonsten zu Deinem Problem mit dem tiny2313 versus AT892051 kann ich > nur vermuten, dass Du da vielleicht den falschen Compiler befragt hast. Das kann durchaus sein. Ich habe damals (1995) den Keil kaufen lassen, also nen Profi, da der SDCC noch nichts taugte. Den AVR habe ich aber mit dem WINAVR, also Freeware benutzt. Da kann es also durchaus erhebliche Unterschiede z.B. zu nem IAR oder nem anderen Profi geben. Aber auch ein Assemblerprojekt habe ich versucht auf den AT90S2313 umzustellen, war der totale Reinfall. Ich gebe allerdings zu, daß über 120 Byte Variablen (global oder überlagert) und 128 Byte Stack oder Arrays der AVR wieder etwas effizienter sein kann. Den ATtiny8313 gibts natürlich nicht, damit war ein ATtiny2313 mit 8kB Flash gemeint, wofür ich viel Potential sehe. Auch einen ATmega328 oder ATmega648 als Erweiterung des ATmega168 würde ich als sinnvoll einschätzen. Peter
Unbekannter wrote: > Nein, Pipelining hat überhaupt nichts mit Harward zu tun. Jau, das hat nur mit dem Taktteiler zu tun. Auch die 1-Clocker 8051 (Silabs, Atmel LP-Serie) müssen Pipelining machen. Damit hat man dann den hübschen Effekt, daß man einen Pin setzen und im nächsten Zyklus trotzdem was anderes lesen kann. Bei den 12-, 6-, 4-clocker 8051 liest man richtig, aber bei den 1-clocker und den AVRs noch den vorherigen Zustand. Peter
> Den ATtiny8313 gibts natürlich nicht, damit war ein ATtiny2313 mit 8kB > Flash gemeint, wofür ich viel Potential sehe. Es gibt immerhin den Attiny84, der allerdings nur 20 Pins hat. Ansonsten nehme ich in so einem Fall eben gleich einen Atmega8. Ich brauche meistens nicht so viel Flash. Ich hätte lieber mehr RAM. Das wäre bei manchen Aufgaben, die einen Puffer brauchen, recht praktisch. Da will ich auch nicht immer gleich nen Mega128 bemühen, nur um mal mehr als 1kB zu haben.
Rolf Magnus wrote: > Es gibt immerhin den Attiny84, der allerdings nur 20 Pins hat. Ansonsten > nehme ich in so einem Fall eben gleich einen Atmega8. Ne, der hat nur 14 Pins (12 IOs), aber real hab ich den noch nicht gefunden. Da sind ja leider immer mindestens 12..36 Monate zwischen Ankündigung und Verfügbarkeit. Und mit Evaluation-Samples habe ich zu schlechte Erfahrungen gemacht, als das ich mich nochmal darauf einlasse. Ich will reale Verfügbarkeit (mind. 2 Anbieter ab Lager) sehen, ehe ich nen Chip auch nur angucke. Peter P.S.: Das tollste war mal ein Chip, den es nur als Sample gab und der danach ersatzlos gestrichen wurde.
Da es in 1995 noch keinen 2313 AVR gab, nehme ich an, dass Du damals noch die frühen 8051-Derivate von Atmel beackert hast. Keil war da seinerzeit noch "hot", keine Frage. Was den WINAVR angeht, habe ich persönlich ganz schwere Vorbehalte, weil der Compiler "von oben" kommt - und die meisten Anwender ebenso von oben her kommen und erstmal keine Ahnung von echter resourcen-orientierter Programmierung haben. Aber das ist hier wohl ein anderes Thema. In Bezug auf die über 120 Byte Variablen muss ich allerdings einmal nachfragen, ob die mit dem AT892051 tatsächlich schon regulär waren - ich kenne mich mit dem Chip nicht so aus. Wenn ja, musste Dein Versuch der 1:1-Umsetzung eines ASM-Programms allerdings scheitern... Ansonsten, was den fiktiven ATtiny8313 angeht, wie bereits gesagt: Freu Dich schon mal auf die tinys 461/861, die kommen werden. Gruß der noch ein Johannes
Peter Dannegger wrote: > Ne, der hat nur 14 Pins (12 IOs), aber real hab ich den noch nicht > gefunden. > > Da sind ja leider immer mindestens 12..36 Monate zwischen Ankündigung > und Verfügbarkeit. > > Und mit Evaluation-Samples habe ich zu schlechte Erfahrungen gemacht, > als das ich mich nochmal darauf einlasse. > > Ich will reale Verfügbarkeit (mind. 2 Anbieter ab Lager) sehen, ehe ich > nen Chip auch nur angucke. Nun geht doch nicht immer auf Atmel los. Ich wäre froh, wenn es von den MSP430ern so ein Sortiment gäbe. Da gibt's einige kleine mit max. 8kB Flash und alles grössere hat schon mindestens 48 Pins im TQFP. Ist relativ hässlich, wenn man nur mal etwas mehr Flash und insbesondere auch RAM braucht. Jedenfalls finde ich die Typenvielfalt der AVRs schon beeindruckend.
@noch einer auf die tiny461/861 als update zum 2313 könnte man sich ja wirklich freuen, nur leider sind sie längst kein vollständiger ersatz: das gute usart fehlt leider. ein echtes update ist leider nicht in sicht...
noch mal ne kurze Frage: Bei den Erklärungen zur Harvard Architektur der AVR steht: "Andererseits muss aber Code im Datenspeicher erst in den Codespeicher übertragen werden, um ausgeführt werden zu können. " Wann könnte ich in die Situation kommen, dass im Datenspeicher Code=Befehle stehen??
> Wann könnte ich in die Situation kommen, dass im Datenspeicher > Code=Befehle stehen?? Wenn Du einen sogenannten Bootloader verwendest, der den Anwendungscode über eine "normale" Schnittstelle einliest (RS232, USB), wird der Code im Datenspeicher zwischengelagert und von dort in den Flash geschrieben. Das geht mit allen neueren AVRs, auch mit den Tinys. Bedingung ist nur das Vorhandensein des SPM-Befehls. Gruß Johannes
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.