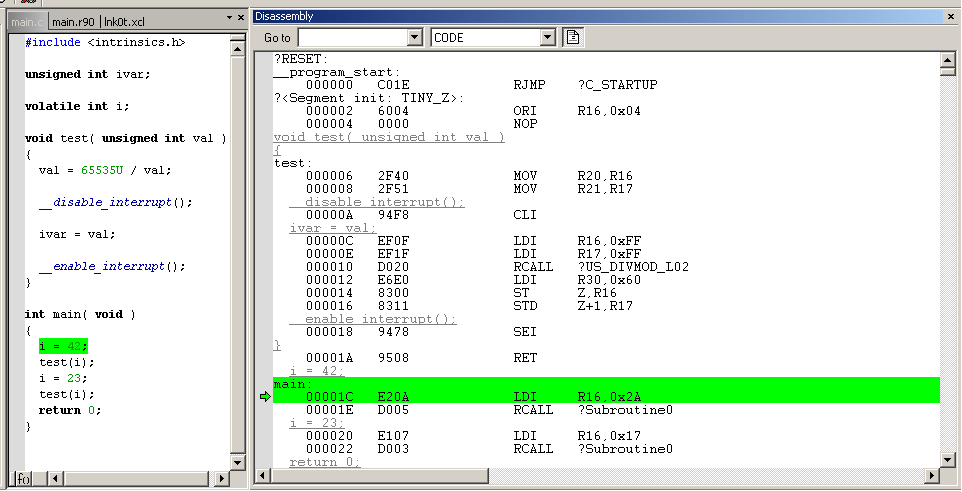
Hier mal ein harmloser Code und im Anhang das Listing, was der GCC
4.1.1. daraus verbrochen hat.
1
#include<interrupt.h>
2
3
unsignedintivar;
4
5
6
voidtest(unsignedintval)
7
{
8
val=65535U/val;
9
10
cli();
11
12
ivar=val;
13
14
sei();
15
}
Die Funktion ist klar, ich will ne Variable atomar setzen und disable
dazu die Interrupts, sollte also nur 6 Zyklen Interruptsperre kosten.
Und was macht aber der gemeine GCC ?
Er schreibt das CLI an eine völlig andere Stelle und statt 6 Zyklen
sinds nun viele hunderte und ich such mir nen Wolf, warum Interrutps
verloren gehen.
Das ist wirklich ein dicker Hund, sowas.
CLI und SEI sind wichtige Maschinenbefehle, die dürfen doch nicht
einfach willkürlich verschoben werden.
Der Programmierer denkt sich ja schließlich was dabei, wenn er sie
benutzt.
Irgendwie bin ich stocksauer.
Peter
Was ist da jetzt ein Bug ? Soweit ich weiß, ist das OK. sei() und cli()
sind keine Funktionen, daher ist deren Position nicht eindeutig
definiert. Der Compiler darf die also beliebig verschieben.
Ersetze
unsigned int ivar;
durch
volatile unsigned int ivar;
und es geht wie gewünscht.
Das kommt davon, wenn viele Leute an einem Projekt arbeiten und
keinerlei Qualitätsmanagement vorhanden ist.
Sehe ich das richtig, dass dies bei einer früheren Version nicht so war?
Weil dann ist es wirklich ein Hammer...
Benedikt K. wrote:
> Was ist da jetzt ein Bug ?
Nun, cli() ist ein Assemblermacro vom Typ _asm__ __volatile_ und darf
daher nicht verschoben werden.
Wo kämen wir denn hin, wenn Assemblerbefehle willkürlich vertauscht
werden.
Es ist auch völlig egal, ob cli() nun ein Assemblerbefehl oder ne
Funktion ist, der Programmablauf muß eingehalten werden.
Es ist zwar schön, daß Du einen Work-Around gefunden hast, aber der
beseitigt nur die Wirkung und nicht den Fehler.
Peter
P.S.:
Kann man die GCC-Version abtesten und einen Fehler (#error) ausgeben,
wenn sie die falsche ist ?
>Das ist wirklich ein dicker Hund, sowas.>Weil dann ist es wirklich ein Hammer...
@peda:
was stört dich ?
Du hast zu keinem Zeitpunkt dem Compiler mitgeteilt, das ivar eine
Variable ist die irgendwo anders benutzt wird (volatile). Somit DARF der
Compiler, wenn er das Ergebnis einer Berechnung nicht ändert,
Programmcode umstellen. Die Optimierung eine Berechnung erst
auszuführen, wenn sie benötigt wird, hat das Potential einiges einsparen
zu können. In deinem Mini-Beispiel tut sie es nicht. (selbst mit
volatile wäre ich mir nicht sicher, ob der Compiler nicht trotzdem die
Berechnung vorziehen dürfte)
C ist nicht Assembler, der Compiler darf SEHR weitgehend den
Programmfluß ändern, wenn Ergebnisse dadurch nicht beeinflußt werden.
Ergebnisse sind Ausgaben zur Außenwelt. Wie stark er dies tut kannst du
dir in den GCC-internas durchlesen. Die Optimierung wird noch
weitergehen. Es setzt allerdings voraus, zu wissen was garantiert ist
und was nicht (C-Standard).
Das ist kein BUG sondern eine falsche Annahme von "garantierten"
Abläufen deinerseits.
BTW: Über wieviel Takte sprechen wir hier eigentlich?
Peter Dannegger wrote:
>> Was ist da jetzt ein Bug ?> Nun, cli() ist ein Assemblermacro vom Typ _asm__ __volatile_ und> darf daher nicht verschoben werden.
Wird er auch nicht.
> Wo kämen wir denn hin, wenn Assemblerbefehle willkürlich vertauscht> werden.
Das darf er ohne volatile beim asm, aber das macht er ja bei dir auch
gar nicht.
> Es ist auch völlig egal, ob cli() nun ein Assemblerbefehl oder ne> Funktion ist, der Programmablauf muß eingehalten werden.
Wo steht das im C-Standard? (*)
> Es ist zwar schön, daß Du einen Work-Around gefunden hast, aber der> beseitigt nur die Wirkung und nicht den Fehler.
Nein, der Fehler ist deine Annahme, die du über deinen Code gemacht
hast.
Der Compiler hat (technisch gesehen) nicht den inline asm Code
verschoben, sondern die Division, da sie ja nur einmal gebraucht wird.
Das steht ihm frei (selbst bei -Os, der Code wird ja nicht größer
davon). Leider kann man eine Operation (wie hier die Division) nicht
als "volatile" qualifizieren um dem Compiler zu sagen, dass er diese
Operation nicht anderweitig optimieren darf. Wenn du ivar nicht die
ganze Zeit volatile qualifizieren willst, kannst du dir auch mit so
einem Konstrukt behelfen:
Mir ist unklar, wieso der Workaround (volatile unsigned int ivar)
überhaupt funktioniert.
Auch ohne volatile ist der Schreibzugriff auf ivar erstens atomar und
zweitens während der Interruptsperre.
Ist das "Zufall", d.h. kann das bei einem nicht so einfachen
Codeschnippsel anders sein?
Peter, hast du mit Code Optimierung übersetzt und -O2, -O3 oder -Os
benutzt?
Möglicherweise ist obiges Codebeispiel ein gutes Beispiel für die GCC
Option -fno-reorder-blocks.
Das basiert darauf, dass durch die ASM-Makros cli() und sei()
Blockgrenzen (Stichwort basic blocks Konzept bei Codeoptimierung im GCC)
geschaffen werden (*). Und durch die Option das Reordering über diese
Blockgrenzen verboten wird.
Eine neue Frage ist allerdings, wie man diese Option lokal nutzen
könnte.
(*) Und wo in der Doku das Blocksplitting mit _asm_ dokumentiert ist.
Ich habe bei einer kurzen Suche nur Inoffizielles gefunden:
A Practical GCC Trick To Use During Optimization
http://www.cellperformance.com/mike_acton/2006/04/a_practical_gcc_trick_to_use_d.html
Nö, -fno-reorder-blocks hilft nicht.
Sieht mir so aus, als gäbe es im C-Standard einfach keine Methode,
Peters Willen garantiert in dieser Form umzusetzen.
Jörg Wunsch wrote:
> Der Compiler hat (technisch gesehen) nicht den inline asm Code> verschoben, sondern die Division, da sie ja nur einmal gebraucht wird.
Das sind Spitzfindigkeiten und ich glaube kaum, daß es irgendeinen
nicht-GCC Compiler gibt, der sich sowas auch erlaubt.
Es ist ja auch egal, ob ich mit 100km/h auf jemanden drauf fahre oder er
auf mich, es kracht in beiden Fällen gleich schlimm.
Entweder die volatile Instruktion wird da ausgeführt wo sie steht oder
nicht.
Sie hängt ja nicht im luftleeren Raum, sondern bezieht sich natürlich
auf den Code davor und dahinter.
Dann kann man sich das volatile doch gleich sparen.
Ich arbeite jetzt erstmal mit GCC 3.4.6 weiter.
Peter
Die Kontrolle der Position der Division hat IMHO nichts mit dem volatile
bzw. dessen Fehlen zu tun.
Ich bin baff erstaunt, dass man durch -fno-reorder-blocks das nicht
kontrollieren kann.
Leider steht in obigem Artikel von Mike Acton die GCC Version nicht
drin. Vielleicht setzt _asm_ (im cli() Makro) in 4.1.1 doch keine
Blockgrenze (mehr)?
Wolfram wrote:
> BTW: Über wieviel Takte sprechen wir hier eigentlich?
Einmal über 6 und einmal über mehr als 100 (Software-Division), also
etwa das 20-fache (geschätzt).
Ist also schon ein enormer Unterschied.
Mit float Division wärs wohl mehr als das 200-fache.
Solche extremen Interruptsperren machen Dir jede Echtzeit zur Sau.
Peter
> Mir ist unklar, wieso der Workaround (volatile unsigned int ivar)> überhaupt funktioniert.
Weil er dann die Berechnung genau so wie angegeben machen muß.
> Auch ohne volatile ist der Schreibzugriff auf ivar erstens atomar und> zweitens während der Interruptsperre.
Ohne volatile darf der Compiler diesen Schreibzugriff auch beliebig
verschieben oder sogar komplett wegoptimieren. Daß irgendwo davor und
irgendwo danach mal was volatile ist, spielt dabei keine Rolle.
>> Der Compiler hat (technisch gesehen) nicht den inline asm Code>> verschoben, sondern die Division, da sie ja nur einmal gebraucht wird.>> Das sind Spitzfindigkeiten
Nein. Der Compiler selbst weiß nicht, daß das cli() und das sei() in
einem Zusammenhang stehen. Er weiß auch nicht, daß der Code dazwischen
auch in einem Zusammenhang dazu steht. Er weiß (durch volatile), daß er
das cli() und das sei() so wie im Code ausführen muß, aber er weiß
aufgrund des fehlenden volatile nicht, daß er das mit der Zuweisung und
der Division auch tun muß.
> und ich glaube kaum, daß es irgendeinen nicht-GCC Compiler gibt, der> sich sowas auch erlaubt.
Da gibt's bestimmt jede Menge, wenn vielleicht auch nicht für AVR.
> Es ist ja auch egal, ob ich mit 100km/h auf jemanden drauf fahre oder> er auf mich, es kracht in beiden Fällen gleich schlimm.
Falls du überlebst, kann es für dich schon einen Unterschied machen, ob
du wegen grober Fahlässigkeit ein paar Jahre in den Knast kommst und
persönlich für den finanziellen Schaden aufkommen mußt, weil die
Versicherung ihr Geld wiederhaben will. Es gibt eben nicht nur die
offensichtlichen Folgen.
> Entweder die volatile Instruktion wird da ausgeführt wo sie steht oder> nicht.
Sie wird.
> Sie hängt ja nicht im luftleeren Raum, sondern bezieht sich natürlich> auf den Code davor und dahinter.
Und woher soll der Compiler das wissen?
> Dann kann man sich das volatile doch gleich sparen.
Im Gegenteil. Im obigen Code fehlt das volatile.
Peter Dannegger wrote:
>> Der Compiler hat (technisch gesehen) nicht den inline asm Code>> verschoben, sondern die Division, da sie ja nur einmal gebraucht wird.> Das sind Spitzfindigkeiten
C ist (leider) manchmal eine Sprache für Rechtsanwälte, ja.
> und ich glaube kaum, daß es irgendeinen> nicht-GCC Compiler gibt, der sich sowas auch erlaubt.
Dein Glauben in allen Ehren... Erstens ist natürlich immer die Frage,
was der Standard sagt. (Schlechte Karten: über Dinge wie den
Inline-Assembler oder Interrupts lässt der sich gar nicht aus.)
Zweitens, ich habe mir mal die Mühe gemacht, deinen Code in den IAR
reinzuhacken. Bild ist angehängt, wird praktisch identisch zu GCC 4.x
compiliert.
Was mich daran wirklich nur ärgert ist, dass es offenbar keine
halbwegs portable Methode gibt, das von dir gewünschte Ergebnis zu
erreichen. (Beim IAR hilft es nicht einmal, ivar als volatile zu
qualifizieren.)
> Entweder die volatile Instruktion wird da ausgeführt wo sie steht> oder nicht.
Das wird sie ja auch. Es ist ja die (nicht volatile qualifizierbare)
Division, die an einer anderen Stelle ausgeführt wird.
> Ich arbeite jetzt erstmal mit GCC 3.4.6 weiter.
Du meinst, den Kopf in den Sand stecken ist eine praktikablere
Methode? Nur zu.
Stefan schrieb:
> Ich bin baff erstaunt, dass man durch -fno-reorder-blocks das nicht> kontrollieren kann.
-freorder-blocks ist laut Doku erst bei -O2 aktiv. Der Effekt hier
tritt aber schon bei -Os auf.
Ach noch was:
> Ich arbeite jetzt erstmal mit GCC 3.4.6 weiter.
Ich halte es für keine Gute Idee, bei einem Fehler im Programm auf eine
Compiler-Version zu wechseln, die trotzdem das Erwartete tut, statt den
Fehler zu beheben.
> -freorder-blocks ist laut Doku erst bei -O2 aktiv. Der Effekt hier> tritt aber schon bei -Os auf.
Danke. Ich wusste nicht, welche Optimierung Peter benutzt hatte bzw.
kann es im Moment nicht ausprobieren. Deine Antwort spart mir heute
abend den Test ;-)
Jörg Wunsch:
>Sieht mir so aus, als gäbe es im C-Standard einfach keine Methode,>Peters Willen garantiert in dieser Form umzusetzen.
Keine Ahnung ob das hier eine standardkorrekte Methode ist, aber
zumindest funktioniert es:
void test( unsigned int val )
{
volatile unsigned int vol_val = val;
vol_val = 65535U / vol_val;
cli();
ivar = vol_val;
sei();
}
(Kanns im Moment nicht ausprobieren)
Würde es etwas helfen, wenn man den kompletten
Abschnitt
cli();
Zuweisung
sei();
in inline-Assmebler formuliert?
Dann könnte man das in eine (inline)Funktion packen
und die ursprüngliche Funktion würde zu:
void test( unsigned int val )
{
val = 65535U / val;
assign_atomar16( &ivar, val );
}
Xenu's Variante hilft natürlich in der Tat (und ist standardgerecht),
leider eben nur mit deutlich unoptimalem Code. GCC reserviert für
eine volatile-Variable eben immer Platz im Stackframe, und greift sie
dann dort zu.
> Würde es etwas helfen, wenn man den kompletten> Abschnitt
...
> in inline-Assmebler formuliert?
Ich denke schon, dann ist es für den Compiler ja eine einzige
Anweisung, die er nicht mehr trennen darf.
Ich kanns auch gerade nicht ausprobieren, aber nach der uralten
C-Grundweisheit: "Lieber ein Paar Klammern zuviel als zuwenig" geht
vielleicht das hier:
> volatile unsigned int vol_val = val;>> vol_val = 65535U / vol_val;
Das ist keine gute Idee, weil der Compiler nun unnütze Load-/Store-
Instruktionen erzeugt. Noch schlimmer wird es, wenn weitere Operationen
über vol_val ausgeführt werden, z.B.:
1
vol_val = 65535U / vol_val;
2
vol_val += 2;
3
vol_val -= 2;
wird zu:
1
ldi r24,lo8(-1)
2
ldi r25,hi8(-1)
3
rcall __udivmodhi4
4
std Y+2,r23
5
std Y+1,r22
6
ldd r24,Y+1
7
ldd r25,Y+2
8
adiw r24,2
9
std Y+2,r25
10
std Y+1,r24
11
ldd r24,Y+1
12
ldd r25,Y+2
13
sbiw r24,2
14
std Y+2,r25
15
std Y+1,r24
Ist vol_val nicht volatile deklariert, so optimiert der Compiler
die letzten beiden Anweisungen komplett weg.
Ich kann es mangels 4.1.1 nicht ausprobieren aber funktioniert das
vielleicht besser (Makros expandiert):
1
#include<interrupt.h>
2
3
unsignedintivar;
4
5
6
voidtest(unsignedintval)
7
{
8
val=65535U/val;
9
10
{
11
__asm____volatile__("cli"::);
12
ivar=vol_val;
13
__asm____volatile__("sei"::);
14
}
15
}
Also quasi die Erweiterung der Makros durch einleitende und schließende
Blöcke. Ich könnte mir zumindest vorstellen, dass das mit der Option
no-reorder-blocks was bringt.
EDIT: Oh, da war jemand schneller.
Nein, die Braces haben nichts mit basic blocks zu tun. Sie ändern auch
sonst nichts, da sie an der Stelle, an der die Optimierungen
ausgeführt werden, gar nicht mehr im Compiler existieren.
>> Ich arbeite jetzt erstmal mit GCC 3.4.6 weiter.>Ich halte es für keine Gute Idee, bei einem Fehler im Programm auf eine>Compiler-Version zu wechseln, die trotzdem das Erwartete tut
Also für mich steht noch nicht fest, dass dies ein fehler des
"Programms" ist. Mir scheint eher dass hier ein wesentliches Feature für
den AVR-GCC fehlt.
Es ist auch keine Lösung die Code Strecken um CLI() ... SEI() herum mit
volatile zuzuballern nur dammit der Compiler keine Möglichkeit mehr hat
Code zu verschieben.
Dies mag in einfachen Beispielen wie dem obigen noch möglich sein, aber
man denke nur daran, dass dort auch beliebige Funktionsaufrufe mit
inline Attribut stehen können und spätestens dann hat man keine Chance
mehr.
Noch ne anmerkung zu Thema "Standard":
Es ist zwar schön und gut wenn ein Compiler sich mit einer 100% Standard
Konformität brüsten kann, ist ja auch in vielen Bereichen sehr wichtig.
Aber für einen AVR C Compiler ist es mindesten so wichtig verlässlichen
Code für die typischen Einsatzfälle eines AVR zu generieren.
Dies schlägt alle mal C-Standard Konformität.
Für einen normalen C Compiler ist nur Ergebnissgleicheit wichtig.
Für einen Microkontroller Programm ist aber eine Präzise Kontrolle über
Ausführungszeitpunkt und Zeitdauer noch wichtiger, etwas was volatile
wie man sieht nur unzureichend kontrolliert.
Für mich fehlt hier eher ein
no-reorder { .... }
Block Konzept (ähnlich try{} catch{} ).
> Ich arbeite jetzt erstmal mit GCC 3.4.6 weiter
Also mir ist auch beim 3.4.6 schon öfters beim Studium des Assembler
Listings aufgefallen dass nach der cli() Instruktion Befehle auftauchten
die zu Berechnungen Ausserhalb gehörten. Ist also keine Gewähr....
Kupfer Michi wrote:
> Es ist zwar schön und gut wenn ein Compiler sich mit einer 100%> Standard Konformität brüsten kann, ist ja auch in vielen Bereichen> sehr wichtig. Aber für einen AVR C Compiler ist es mindesten so> wichtig verlässlichen Code für die typischen Einsatzfälle eines AVR> zu generieren.
Gerade der GCC ist natürlich nun alles andere als ein Compiler für
Microcontroller (vom Konzept her). Das wäre der IAR sehr viel eher,
aber selbst der nimmt sich die Freiheit, den Code anders zu sortieren,
als Peter es sich wünscht.
Ja, ich geb' dir recht, irgendeine Möglichkeit, einen Block als
"volatile" zu deklarieren, fehlt hier einfach. Peter, vielleicht
willst du ja dafür mal einen Bugreport (im Sinne von "Feature
request") aufmachen. Am besten, lass dabei auch noch das #include von
<avr/interrupt.h> weg, und code die beiden Stückchen inline asm direkt
als "asm volatile("cli")" und "asm volatile("sei")".
Wäre es nicht am saubersten mit einer eigenen Funktion für den Zugriff
auf die globale Variable zu arbeiten? Wenn man Inlining verbietet sollte
das Problem doch damit erledigt sein (wenn die paar Zyklen für rcall/ret
nicht stören).
@andreas:
Die Frage ist wie lange diese "Umgehung des Problems" hält, ein
zukünftiger Optimierer könnte inlinen.
@all:
Die Idee des Feature Request ist sehr gut. Wird nicht im Moment sowieso
darüber nachgedacht wie man auf Funktionslevel Optimierungen
kontrollierbar macht?
Wolfram wrote:
> Die Frage ist wie lange diese "Umgehung des Problems" hält, ein> zukünftiger Optimierer könnte inlinen.
Daher schrieb Andreas ja: "inlining verbieten". Das geht mit
__attribute__((noinline)), und das funktioniert sehr wohl.
>... "inlining verbieten"
Aber das kann doch allen Ernstes nicht Lösung des Grundproblems sein?
Jede atomare cli/sei Codingstrecke nochmals in eine eigene Funktion
packen?
Ich verstehe wenn man in der konkreten Situation von Peter nach
irgendwelchen Abhilfen sucht, aber als generelle Lösung?
Ich habe einige C++ Klassen die mir Timer, ADC,PC-Host Kommunikation
etc. managen. Alle vollgespickt mit cli/sei um AVR-Kontrollregister und
eigene Datenstrukturen konsistent zu halten.
Die meisten dieser Methoden selbst sind als inline deklariert damit nur
wirklich der Code generiert wird, der für den konkreten Aufruf benötigt
wird, was sehr viel bringt. Hier überall Zwischenfunktionen einzuführen
würde zu sehr hässlichem Coding führen.
Auch wenn das GCC Design schlecht zum AVR passt, so tritter er doch mit
dem Anspruch auf ein brauchbarer Compiler für den AVR zu sein
(WinAVR/GCC unterstützung in AVRStudio).
Daher denke ich nach wie vor dass die elemnatare Notwendigkeit atomare
codingstrecken spezifizieren zu können auch als "First Oder"
Sprachkonstrukt vom Compiler unterstützt werden müsste und nicht durch
irgend welche asm Einsprengsel unterhalb der Sichtbarkeitsschwelle des
Compilers.
block-interupts { // <-- push SREG; cli;
......
if(...)
return;// <-- pop SREG
} // <-- pop SREG
block-interupts hätte automatisch das oben angesprochene no-reorder
Attribut.
Etwas ähnliches habe ich mir als C++ Klasse gebastelt:
class BLOCK
{
UC sreg;
public:
BLOCK() { sreg = SREG; cli(); };// disable all interupts
~BLOCK() { SREG = sreg;}; // reestablish prior interupt
enable
state
};
//usage:
{
...
BLOCK intrpts; // cli called
...
if(...) return; // destructor called here
...
} // destructor called here
Dies hat jedoch den grossen Nachteil dass sreg auf dem Stack landet,
auch wennn genügend Register frei sind und auf das reoder Problem hat
das natürlich auch keinen Einfluss.
Die asm-Anweisung erzeugt eine leere Assembler-Instruktion, die - so
mache ich es dem Compiler zumindest weis - val als Eingabewert benutzt.
Dadurch wird erzwungen, dass val bereits an dieser Stelle den neuen Wert
hat, die Division also vor dem asm und damit vor dem cli ausgeführt
wird.
Der erzeugte Code der, den sich Peter vorgestellt hat.
Die Methode ist natürlich nicht ganz universell, da die asm-Anweisung
spezifisch an den Code zwischen cli und sei angepasst werden muss. Dafür
greift sie nur minimal in die Optimierungsmöglichkeiten des Compilers
ein.
Kupfer Michi wrote:
>>... "inlining verbieten"> Aber das kann doch allen Ernstes nicht Lösung des Grundproblems> sein? Jede atomare cli/sei Codingstrecke nochmals in eine eigene> Funktion packen?
Hat ja auch keiner gesagt. Eine universelle Lösung dafür gibt es mit
dem derzeitigen C-Standard einfach nicht, und GCC bietet auch keine
Sonderlösung dafür an.
> Ich habe einige C++ Klassen die mir Timer, ADC,PC-Host Kommunikation> etc. managen. Alle vollgespickt mit cli/sei um AVR-Kontrollregister> und eigene Datenstrukturen konsistent zu halten.Das funktioniert ja auch alles, auch in Peters Fall.
> Auch wenn das GCC Design schlecht zum AVR passt, so tritter er doch> mit dem Anspruch auf ein brauchbarer Compiler für den AVR zu sein> (WinAVR/GCC unterstützung in AVRStudio).
Ja, und? IAR doch erst recht, oder?
Das Problem ist einfach: der Compiler weiß nichts über Interrupts, das
ist in C schlicht kein Begriff. (Sehr zu meinem Erstaunen weiß eben
selbst der IAR in seinem Innersten offenbar nichts darüber.) Der
Anspruch an den Optimierer ist, bestmöglichen Code in jeder Hinsicht
zu erzeugen. Dazu gehört nun einmal auch das Verschieben von Code an
andere Stellen. Da der Compiler jedoch als solches nichts über ein
Interrupt-Konzept kennt, kann er auch nicht ahnen, dass in diesem
einen Fall das Verschieben des Codes absolut nicht wünschenswert ist.
Aus seiner Sicht ändert das Verschieben nämlich am Gesamtergebnis rein
gar nichts.
Was daher wünschenswert wäre (daher mein Vorschlag für einen feature
request) ist, dass man bestimmte Blöcke von Code als nicht
verschiebbar deklarieren kann, also gewissermaßen ein "volatile"
qualifier für einen Block. Ich habe nur keine Ahnung, wie es mit der
Implementierbarkeit dieses Wunsches aussieht.
> Daher denke ich nach wie vor dass die elemnatare Notwendigkeit> atomare codingstrecken spezifizieren zu können auch als "First Oder"> Sprachkonstrukt vom Compiler unterstützt werden müsste ...
Damit verlässt du eben nur das Terrain der Programmiersprache C.
Kann sein, dass Ada das kann, da kenne ich mich zu wenig aus.
> block-interupts { // <-- push SREG; cli;> ......> if(...)> return;// <-- pop SREG> } // <-- pop SREG
Darum geht's ja nicht. Das würde übrigens Dean Camera's
vorgeschlagener <atomic.h> ganz gut erledigen (liegt in den Patches
für avr-libc), aber auch der leidet letztlich unter Peter's Problem,
dass er die (aufwändige) Division in den Interruptschutz mit
reinnimmt.
> block-interupts hätte automatisch das oben angesprochene no-reorder> Attribut.
Das alles hilft dir gar nichts. Die Operation, um die es geht, lag ja
komplett außerhalb dessen, was bei dir "block-interrupts" wäre. Damit
ist sie völlig ungeschützt.
Wenn ich diesen Text richig verstanden habe, würde es reichen, wenn man
cli() und sei() aus interrupt.h entfern und in die Bibliothek
implementiert.
Well, Lock comes from a threading library, so we can assume it either
dictates enough restrictions in its specification or embeds enough magic
in its implementation to work without needing volatile. This is the case
with all threading libraries that we know of. In essence, use of
entities (e.g., objects, functions, etc.) from threading libraries leads
to the imposition of “hard sequence points” in a program—sequence points
that apply to all threads. For purposes of this article, we assume that
such “hard sequence points” act as firm barriers to instruction
reordering during code optimization: instructions corresponding to
source statements preceding use of the library entity in the source code
may not be moved after the instructions corresponding to use of the
entity, and instructions corresponding to source statements following
use of such entities in the source code may not be moved before the
instructions corresponding to their use.
Quelle : http://www.aristeia.com/Papers/DDJ_Jul_Aug_2004_revised.pdf
Was mich etwas wundert, in C werden doch auch Betriebssysteme
geschrieben, da müssen doch derartige Aufgabenstellungen alle Nase lang
auftreten.
Diese Compiler müssen doch dann dafür irgendwelche Mechanismen bieten,
sonst kommt man ja aus dem Bluescreen garnicht mehr heraus.
Das mit dem CLI kann man ja mit volatile für die Variable danach
umschiffen (wird dann zwar im Interrupt etwas teurer), aber was ist mit
sämtlichen anderen Assembler Befehlen ?
Assemblerbefehle sollten daher grundsätzlich eine Reorder-Grenze sein.
Peter
>> block-interupts hätte automatisch das oben angesprochene no-reorder>> Attribut.>Das alles hilft dir gar nichts. Die Operation, um die es geht, lag ja>komplett außerhalb dessen, was bei dir "block-interrupts" wäre. Damit>ist sie völlig ungeschützt.
Vielleicht konnte ich mich nich richtig ausdrücken und no-reorder ist
auch vielleicht nicht sugestive genug gewählt, aber ich meine damit was
du hiermit andeutest:
>dass man bestimmte Blöcke von Code als nicht verschiebbar deklarieren kann>also gewissermaßen ein "volatile" qualifier für einen Block
nähmlich der "no-reoder" block soll ohne import von ausserhalb liegenden
Codeteilen als auch export nach ausserhalb übersetzt werden, also
möglichst nahe an dem was hingeschrieben wird.
Als Programmierer habe ich letzendlich nur Kontrolle über den Block
selbst, nicht jedoch was durch verschiedene Einsatszenarien im
Wechselspiel mit den Compileroptimierungen an Coding davor oder danach
zu liegen kommt.
Oder reden wir hier aneinander vorbei?
Ein no-interupt block Konzept wäre dann nur das Sahnehäubchen oben drauf
um das lästige und Fehleranfällige push sreg;cli; pop sreg; effizienter
und für den Leser übersichtlicher Compiler erledigen zu lassen.
>Damit verlässt du eben nur das Terrain der Programmiersprache C.
Ja das ist ja mein Argument:
Es bringt nichts so zu tun als wär ein Microkontroller Programm auch
nichts anders als ein x-beliebiges PC Programm in C, in dem es gilt ein
paar Bytes von links nach rechts zu schubsen.
Interuptgetriebenes Programmieren unter harten zeitlichen
Randbedingungen und 20MIPS erfordert halt manchmal Sonderwege mit
entsprechender Elementarunterstützung durch die Sprache.
Die Aussage
"der C Standard sieht das aber nicht vor, also darf es nicht
unterstützt
werden"
wird für mich der Problemklasse nicht gerecht und dass andere Compiler
noch weniger das Problem erkannt haben ist nur ein schwacher Trost.
Wie soll man denn zu höheren Steuerungssystem z.B. in der Robotik
kommen, wenn man bei jeder Codeänderung das Assembler Listing
nachkontrollieren muss?
Peter Dannegger wrote:
> Was mich etwas wundert, in C werden doch auch Betriebssysteme> geschrieben, da müssen doch derartige Aufgabenstellungen alle Nase lang> auftreten.
Die arbeiten (zumindest auf aktueller Hardware) viel subtiler. Daher
haben sie sich alle ihre eigenen Hilfen dafür geschaffen (Stichwort
memory barrier).
Andererseits haben die keine Probleme mehr damit, dass da irgendwo
eine Multiplikation oder Division zu viel in den geschützten Bereich
geschoben wird: das merkt man schlicht nicht mehr im Ergebnis. Ist
ja weder ein Z80 noch ein AVR, auf dem die laufen.
> ..., aber was ist mit> sämtlichen anderen Assembler Befehlen?
Subexpression reordering ist kein Thema dafür. Das ist wirklich nur
in deinem Fall ein Problem. Ansonsten verlassen die sich einfach
nur darauf, dass der Compiler genau die Berechnung ausführt, die
er ausführen soll. Wann er das genau macht, interessiert dann
in der Regel nicht mehr.
Die Teile, bei denen es wirklich interessiert, was wann wie gemacht
wird (ganz wenige, vermutlich weit unter 0,1 % eines Betriebssystems,
ich hab's hier auf meinem FreeBSD nicht nachgezählt) sind dann eben
komplett in Assembler gezimmert. Dafür lohnt es sich ja auch.
Michi:
> Die Aussage> "der C Standard sieht das aber nicht vor, also darf es nicht> unterstützt> werden"
Das hat doch gar keiner gesagt. "Der C-Standard sieht es nicht
vor, und sonst braucht das bislang in diesem Detail keiner, daher
gibt's das noch nicht."
> Es bringt nichts so zu tun als wär ein Microkontroller Programm auch> nichts anders als ein x-beliebiges PC Programm in C, in dem es gilt ein> paar Bytes von links nach rechts zu schubsen.
Genau das ist der Punkt. Und wenn das verstanden wurde, wird es auch
endlich ein avr-gcc geben, der ein "void main(void)" ohne Warnung
kompiliert. Wo gibt's denn sowas, µC-Programm und eine main() mit "int"
als Rückgabewert. Da jemand so gar nicht gedacht...
Warum ist bis jetzt keiner auf die Lösung von yalu eingegangen?
Das ist doch ein gangbarer Weg, da zum ersten Mal dem Compiler
mitgeteilt wird das da eine "Beziehung" zwischen cli und der Variable
val besteht.
Die Frage ist muß das in den C-Compiler oder in die avrlibc
Sowas wie ein Makro "atomar" atomar( code, Zugewiesene Variablen)
das
atomar(
ivar = val;
,val)
umformt nach:
asm volatile (""::"r"(val));
cli();
ivar = val;
sei()
Sind Makros mit einer Variablen Anzahl von Parametern eigentlich
möglich?
Prinzipiell hat Jörg recht, das sind 0,xx1 % der Fälle, wo so etwas
interessiert. Man sollte nur abklären ab eine derartige Lösung den
Compiler dauerhaft davon abhält , Berechnungen in den atomaren Abschnitt
"reinzuziehen".
Katzeklo wrote:
> Wo gibt's denn sowas, µC-Programm und eine main() mit "int"> als Rückgabewert. Da jemand so gar nicht gedacht...
Im C-Standard.
Da gibt es zwei Möglichkeiten für main:
1
intmain(void){/* ... */return0;};
2
intmain(intargc,char**argv){/* ... */return0;};
Ausserdem gibt der C-Standard den Compilerbauern die Freiheit einen
anderen Prototypen für main anzubieten, was aber als 'implementation
defined behaviour' nicht näher spezifiziert wird (und damit nicht
portabel ist).
WIMRE gibt es irgend ein Unix, welches beispielsweise main so definiert:
1
intmain(intargc,char**argv,char**environ)
Das war wohl auch der Grund, warum solche Prototypen nicht unter
'undefined behaviour' im Standard gefallen sind.
EDIT: Typo bei 'environ'...
Wolfram wrote:
> Prinzipiell hat Jörg recht, das sind 0,xx1 % der Fälle, wo so etwas> interessiert.
Wie kommst Du denn darauf ?
Ausnahmslos jedes Assemblermacro kann davon betroffen sein !
Z.B. kann es auch bei einem SLEEP, WDR, BREAK, SEI wichtig sein, ob eine
längere Subroutine davor oder dahinter ausgeführt wird.
Es mag natürlich sein, daß die Auswirkungen nur selten auffallen, z.B.
nur bei einer ganz bestimmten Interruptkonstellation.
Deshalb ist es ja um so wichtiger, das alles in der vorgesehenen
Reihenfolge abläuft, denn Interruptfehler sind höllisch schwer zu
debuggen.
Einen Fehler, der sich nur etwa alle 24h auswirkt, debuggt kein
Entwickler gerne.
Peter
Katzeklo wrote:
> Genau das ist der Punkt. Und wenn das verstanden wurde, wird es auch> endlich ein avr-gcc geben, der ein "void main(void)" ohne Warnung> kompiliert.
Kannst du jetzt schon haben. Du musst nur mit -ffreestanding
compilieren. In einer freestanding application hat main() nämlich
keinerlei Sonderbedeutung mehr. (Es steht dann nicht einmal mehr
fest, dass es überhaupt als erste Funktion der Applikation gerufen
werden muss.)
Die Sache hat nur einen Pferfefuß: du verzichtest dann auf alle
Optimierungen, die der Compiler in Kenntnis der Eigenschaften der
Standardbibliothek für eine "hosted application" bereits zur
Compilezeit durchführen darf. Aus
1
strlen("Hello world!")
wird dann also nicht mehr die Compilezeit-Konstante 12, sondern ein
Funktionsaufruf, der zur Laufzeit ausgeführt wird.
So sehr "freestanding", wie die typische Controller-Applikation auf
den ersten Blick zu sein scheint, ist sie denn eben nicht wirklich.
Daher kann es sich einfach rentieren, sie zu einer ,,anständigen''
hosted application zu formen, dann gibt man eben seinem main() den
Rückkehrtyp int und verlässt sich drauf, dass der Compiler dank der
Endlosschleife einfach mal sowieso keine wirklichen Rückkehrwerte
implementieren muss.
Peter Dannegger wrote:
> Z.B. kann es auch bei einem SLEEP, WDR, BREAK, SEI wichtig sein, ob> eine längere Subroutine davor oder dahinter ausgeführt wird.
Kannst du mir sagen, wann du jemals auf die Idee kämst, ein BREAK
selbst einzubauen? ;-)
Ansonsten habe ich dir ja schon zugestimmt: eine Art "volatile"-
Qualifizierung eines Codeblocks kann Sinn haben als Feature. Ist eben
nur die Frage, ob und mit welchem Aufwand sowas überhaupt
implementierbar ist.
Jörg, ich verstehe es nicht. Du wirst doch selbst zugeben müssen, dass
ein Rückgabewert von "main" auf einem µC sinnfrei ist. Warum wird das
denn dann nicht einfach in den avr-gcc fest eingebaut? Wäre das einfach
zu viel Arbeit? Ich habe keine Vorstellung davon, wieviel Aufwand hinter
so einem Projekt steht, daher halt meine Frage. Es ist klar, dass es den
gcc für viele Prozessoren gibt aber es muß doch auch irgendwo eine Datei
oder was auch immer geben, in der prozessortypisches festgelegt ist.
Mal ganz naiv gedacht:
if(uctype == AVR)
expectreturnvalue = FALSE;
{...}
if(!expectreturnvalue)
suppresswarning();
Ende Geländer.
Ich kenne keinen kommerzeillen Compiler für µCs, der einen Rückgabewert
in main erwartet. Ich freue mich auf deine Erläuterungen.
Ich stimme da Peter zu. Bei mir bleibt das ungute Bauchgefühl
"Ausnahmslos jedes Assemblermacro [kann davon betroffen sein] muss
anschliessend im ASM-Listing kontrolliert werden !".
Ich konnte nicht herausfinden, was für diese speziellen Optimierung von
GCC verantwortlich ist, die bereits bei -O Optimierung stattfindet.
Man kann die Codeerzeugung von GCC selbst debuggen (z.B. -dB Option
u.a.) und sich Textdateien ausgeben lassen, die zeigen, wie GCC die
Source erkennt. Allerdings erkenne ich in der Debugausgabe zwischen
3.4.5 und 4.1.1 nicht den Punkt "Bingo! Ah, deshalb!".
Es handelt sind nicht um ein Umarrangieren von "basic blocks". _asm_
macht auch keinen basic block auf, weder bei 3.4.5 noch bei 4.1.1.
Es handelt sich dabei um ein Verschieben einer sog. "insn"
("Instruktion"). Es gibt in GCC das Konzept insns zu verschieben, um
z.B. knappe Registerresourcen oder teuere Speicherzugriffe besser
auszunutzen. Dieses Scheduling ist bereits bei -O aktiv, aber es ist im
konkreten Fall nicht der Auslöser.
Komischerweise ist keine der bei -O defaultmässig eingeschalteten
Optimierungsoptionen (Default -f...) der Auslöser bzw. kann das
Umarrangement nicht durch -fno-... unterdrückt werden.
>> Prinzipiell hat Jörg recht, das sind 0,xx1 % der Fälle, wo so etwas>> interessiert.>Wie kommst Du denn darauf ?
0,xx1 % Im Bezug auf die C-Programme des GCC
>Ausnahmslos jedes Assemblermacro kann davon betroffen sein !
Konkret sind Konstellationen C gemischt mit Assembler, wobei die C
Anweisungen einen impliziten Bezug zu den Assembler Anweisungen haben.
Hier muß es Möglickeiten geben dies dem Compiler mitzuteilen. Sachen wie
SLEEP mit explizitem Timing( nur x Takte bis zur SLEEP Anweisung) sind
am besten in Assembler zu lösen.
Ich denke, das eine Notwendigkeit in der Systemprogrammierung für eine
Lösung besteht steht fest.
@peda: Ich gehe davon aus du hast noch keinen Bugreport/Featurerequest
gesendet.
Man kann ja erstmal hier im Forum mögliche Lösungsansätze diskutieren.
Deshalb verstehe ich nicht warum keiner sich auf die Lösung von @yalu
bezieht.
Sie geht das Problem da an, wo es besteht: Dem Compiler ist nicht
bewußt, daß eine Beziehung zwischen den Anweisungen besteht.
Beispiel:
a=1;b=2;c=3;
sind genauso Anweisungen ohne Beziehung, damit kann der Compiler auch
umordnen ala c=3;a=1;b=2;
und genau unter dem Aspekt sieht er auch cli();ivar=...; sei();
es sei denn ich teile ihm mit daß da eine Beziehung besteht. Mit dem
asm...
geht das erstmal.
Bezüglich reordering:
Ich würde dem Compiler nicht prinzipiell das reordering verbieten
Wir sind in C nicht in Basic. Da muß sich der Programmierer schon bewußt
sein, wenn er etwas kritisches tut und sollte es dem Compiler mitteilen
(können). Also deswegen automatisch bei asm reordering auszuschalten
halte ich nicht für sinnvoll.
Ich muß sagen, wenn ich meine Programme auf dem avr betrachte, dann
betrifft dieses Problem nur 1%-0.1%. Die wirklich (Zeitkritischen)
Routinen sind im untersten Abstraktionslayer. Alles darüber hat sowieso
keinen Hardwarebezug. Allerdings sehe ich sehr wohl die Möglichkeit
durch die stärkere Optimierung, daß dies irgendwann keinen "Schutz" mehr
darstellt.
> Deshalb verstehe ich nicht warum keiner sich auf die Lösung von> @yalu bezieht.
Habe ich mich auch schon gefragt, da das die exakt richtige Lösung ist.
Wem die aus ästhetischen Gründen missfällt, der versteckt sie eben in
einem Macro.
Wahrscheinlich wäre es vielen lieber, sie könnten sich stets drauf
verlassen, dass der Code in exakt der Reihenfolge ausgeführt wird, wie
er im Quellcode steht. Tja nun, der GCC muss sich ja auch mit
SPEC-Benches rumschlagen - aus dem Eck kommt er ja - und solche
Optimierungsaspekte sind unabhängig von der Zielmaschine und sind daher
auch nicht Bestandteil der AVR-Spezifikation im Compiler.
Wer GCC einsetzt, muss mit Überraschungen hinsichtlich Umordnung
rechnen. Die sind sein Job und das Ergebnis von Jahrzehnten Forschung im
Compilerbau. Feature-Requests zum Thema "Rückbau" halte ich für
dementsprechend aussichtslos.
Man wird daher nicht darum herum kommen, dem Compiler nicht sichtbare
Abhängigkeiten explizit in den Code reinzuschreiben.
Katzeklo wrote:
> Jörg, ich verstehe es nicht. Du wirst doch selbst zugeben müssen,> dass ein Rückgabewert von "main" auf einem µC sinnfrei ist.
Nein, ist er nicht. Gemäß dem C-Standard soll der Rückkehrwert von
main() an exit() übergeben werden. (Macht er mit dem ATmega256x-Patch
übrigens im Moment gerade nicht, aber das ist ein Bug.)
Prinzipiell kann ich mich als C-Programmierer erst einmal darauf
verlassen, dass das so ist. Ich könnte beispielsweise im
Katastrophenfall (malloc() failed :^) ein return von main() machen und
ein exit() implementieren, das dann die ganze Applikation wieder
hochzieht (z. B. über einen watchdog reset, oder vielleicht einfach
nur einen Sprung nach 0).
> Warum wird das denn dann nicht einfach in den avr-gcc fest> eingebaut?
Weil der Compiler dann nicht mehr konform zum C-Standard wäre. Punkt.
Der GCC ist kein Bastelprojekt. Wer das Verhalten einer freestanding
application gern möchte, kann es mit -ffreestanding erreichen. Wer
das nicht möchte, darf sich an die Spielregeln einer hosted
application halten.
Wenn du deine eigene Programmiersprache erfinden möchtest, dann musst
du das tun.
A.K. wrote:
>> Deshalb verstehe ich nicht warum keiner sich auf die Lösung von>> @yalu bezieht.> Habe ich mich auch schon gefragt, da das die exakt richtige Lösung ist.> Wem die aus ästhetischen Gründen missfällt, der versteckt sie eben in> einem Macro.
Ich finde sie auch OK. Könnte gut sein, dass ein entsprechender
feature request mit genau sowas beantwortet wird.
>Wahrscheinlich wäre es vielen lieber, sie könnten sich stets drauf>verlassen, dass der Code in exakt der Reihenfolge ausgeführt wird..
Das ist schon eine ganze Weile nicht mehr so, auch wenn einige erst
jetzt darüber stolpern.
>unabhängig von der Zielmaschine und sind daher auch nicht Bestandteil der >AVR-Spezifikation im Compiler.
Richtig ,allerdings "Problem" der Systemprogrammierung, deshalb frage
ich mich ob die avrlibc nicht "Thread/Interruptischre" Makros bieten
sollte, eh jeder sein eigenes strikt.
>Man wird daher nicht darum herum kommen, dem Compiler nicht sichtbare>Abhängigkeiten explizit in den Code reinzuschreiben.
genau, Frage ist könnte die avrlibc das alleine (mit der vorgeschlagenen
Lsg oder braucht sie Unterstützung. @Jörg?
Ist die Lösung "resistent" gegenüber späteren stärkeren
Optimierungsversuchen des Compilers? Sonst ist ein Feature request
wirklich nötig.
Ich denke die Sache muß sowieso zu den GCC Developern. Man könnte nur
etwas Arbeit abnehmen, wenn das hier schonmal vordiskutiert wird und
ausformuliert wird.
Was für eine Feature könnte das Problem lösen? Änderung bestehender
Verhaltensweisen sollte man besser vergessen, damit löst man das Problem
einer Person zu Lasten von zwei anderen, die grad das bisherige
Verhalten benötigen.
Sinnvoll wäre vielleicht eine Art "reorder barrier", evtl als Attribut
einer "asm" Operation, mit dem der Code konsequent in ein Davor und ein
Dahinter getrennt wird. Wie einfach das zu realisieren ist, ist eine
andere Frage. Jedenfalls ist das keine Sache der AVR-Portierung sondern
ist im Kern von GCC anzusiedeln.
Wolfram wrote:
> @peda: Ich gehe davon aus du hast noch keinen Bugreport/Featurerequest> gesendet.
Stimmt.
Mein English ist nicht so besonders.
Ist irgendwie komplizierter, als in nem Forum zu posten.
Geht wohl alles nur über E-Mail und mit Anmeldung.
Peter
>"reorder barrier", evtl als Attribut einer "asm" Operation, mit dem der Code>konsequent in ein Davor und ein Dahinter getrennt wird..
Für die angegebenen Variablen
Bsp:
cli();
ivar=var;
c=1;
sti;
c=1 (c nicht volatile) hat keine Probleme bei einer Verschiebung.
Deshalb sollte der Programmierer angeben können auf welche Variablen er
Wert legt. Wie bei Lösung mit asm
Warum c1 nicht an anderer Stelle? Für eine gute Lesbarkeit will ich
zusammengehörende Variablen an einer Stelle im Programmcode ändern (muß
nicht unbedingt im Programmablauf so sein). Zukünftige Optimierungen
könnten durchaus auch zu so einer Vereinfachung führen, auch hier muß
der Compiler nur wissen auf welche Variable ich für eine atomare
Operation Wert lege.
@peda: Geht mir auch so, ein Grund mehr das ganze ansatzweise
Auszudiskutieren. Nichtdestotrotz ist ein solches Posting letzten Endes
nötig da es wohl auch ARM,ColdFire Echtzeit-Linux? betreffen könnte die
darüber stolpern könnten...
Sehr interessantes Thema das du da angebracht hast, auch wenn ich auf
keinen Fall für einen Rückschritt bin. Da muß der Programmierer dazu
lernen (wie er das dem Compiler sagt) oder die avrlibc bietet es ihm an.
Ich male mir gerade die ganzen Postings aus, wenn der Compiler noch
stärker optimiert und aus 6 Takten >2000 werden. Da sind die "volatile"
Postings gar nichts, nur das steht in der Spec. Deshalb muß eine Info
sein und eine Lösung zum Umgang mit der Problematik gefunden werden.
Möglicherweise haben wir die ja schon.
>Ist irgendwie komplizierter, als in nem Forum zu posten.>Geht wohl alles nur über E-Mail und mit Anmeldung.
Hat eigentlich irgendjemand diesen Zugang?
Also, wenn ich den weiter oben gennanten Artikel
http://www.aristeia.com/Papers/DDJ_Jul_Aug_2004_revised.pdf
richtig verstehe, dann lässt sich das Problem nur auf lib-Ebene lösen,
da das Sprachkonzept von C (und C++) Interrupts und Threads nunmal nicht
kennt, und es damit auch keine Aufgabe des Compilers sein kann, das
irgendwie zu berücksichtigen. Trotzdem gibt es "threadsichere" libs, die
auch die Ausführungsreihenfolgeoptimierung des Compilers entsprechend
beeinflussen, wobei die Threadsicherheit da nur per Assembler eingebaut
werden konnte - eben, weil es mit C gar nicht geht.
Inwieweit man jetzt cli() und sei() in der avr-libc vergleichbar
implemetieren kann, kann ich leider überhaupt nicht beurteilen.
Oliver
Hallo Peter
versuch doch mal den CVAVR ich glaube der kneift sich derlei. Jedenfalls
ist's mir seither nicht aufgefallen. Und ich binde hauptsächlich gerade
zur IRQ Steurung #asm("cli") und #asm ("sei") mit dem Inlineassembler
ein.
Im übrigen sehe ich das genau wie Du. Gerade bei der Interruptbehandlung
hat sich ein Compiler an die Vorgaben des Programmierers zu halten, und
kann nicht Codeoptimierung betreiben. Da komt es auf Zeitoptimierung an.
Aber vielleicht ist das ja auch Einstellungssache.
Da fällt mir auf: "Kann ein Compiler überhaupt und dieser im Speziellen
die Optimierung nach dem Interruptstatus ausrichten? Wäre doch sinvoll
wie an diesem Beispiel zu sehen. Und wenn ja erkennte er beim
compilieren was eine ISR ist und woran. Gibt es besondere Pragmen?"
> asm volatile ( "" : : : "memory" ).> Vielleicht hilft es ja.
Hört sich vielversprechend an.
Allerdings wird val im Register gehalten und ein Hinweis auf schmutzigen
Speicher löst vielleicht nicht die gewünschte Aktion aus.
Man könnte dann die clobber list (1) durch die Register ergänzen, die
von GCC als lokale Arbeitsregister verwendet werden. Bzw. auch um das
condition code register cc (wenn das auf dem AVR verwendet wird) oder
"brutal" alle Register...
(1)
http://gcc.gnu.org/onlinedocs/gcc-4.1.2/gcc/Extended-Asm.html#Example%20of%20asm%20with%20clobbered%20asm%20reg
Peter Dannegger wrote:
> Ist irgendwie komplizierter, als in nem Forum zu posten.
Nicht wirklich, man muss eben nur seine Gedanken sammeln.
> Geht wohl alles nur über E-Mail und mit Anmeldung.
Nicht email, sondern Bugzilla:
http://gcc.gnu.org/bugzilla/
Anmelden ja, aber das ist ja nicht der Akt. Mit der Anmeldung
darfst du auch zu anderen Bugs deine Meinung äußern.
A.K.:
> asm volatile ( "" : : : "memory" ).
Nö, half nicht, hatte ich als erstes probiert. ;-) Es ist ja keine
Operation im Speicher, die davon betroffen war, sondern in einem
Registerpaar, das nur innerhalb der Funktion benutzt wird.
> Implementiert als> asm volatile ( "" : : : "memory" ).> Vielleicht hilft es ja.
"memory" zeigt dem Compiler, dass das asm-Konstrukt Änderung im
Hauptspeicher vornimmt. Der Compiler wird deswegen Inhalte von
Variablen, die im Hauptspeicher liegen, während der Ausführung der
Assembleranweisungen nicht in Registern cachen, sondern vor dem asm in
den Speicher zurückschreiben und hinterher ggf. wieder einlesen.
Dies löst nicht das ursprüngliche Problem dieses Threads, dafür aber
andere, noch schwerwiegendere.
Während Peters Problem ein Perfomanceproblem (das aufgrund der
endlichen Ausführungsgeschwindigkeit natürlich auch die Funktion eines
Programms beeinträchtigen kann), gibt es Fälle, wo das Cachen von
Hauptspeichervariablen in Registern zu Race-Conditions und damit zu
echten Fehlern (unabhängig von der Ausführungsgeschwindigkeit) führen
können.
Deswegen ist im Linux-Kernel "memory" generell in der Clobber-List der
Interrupt-Enable/Disable-Funktionen vorhanden (Auszug aus 2.16.20):
1
staticinlinevoidraw_local_irq_disable(void)
2
{
3
__asm____volatile__("cli":::"memory");
4
}
5
6
staticinlinevoidraw_local_irq_enable(void)
7
{
8
__asm____volatile__("sti":::"memory");
9
}
Wann es ohne die "memory"s schief gehen kann (und tatsächlich auch
schon schief gegangen ist), kann man hier beim Gott persönlich
nachlesen:
http://lkml.org/lkml/1996/5/2/87
> Deswegen ist im Linux-Kernel "memory" generell in der Clobber-List der> Interrupt-Enable/Disable-Funktionen vorhanden (Auszug aus 2.16.20):
Hatten wir für die avr-libc auch schon mal diskutiert, war dann aber
wieder verworfen worden. Der einzige Fall, für den Björn Haase
das gefordert hatte, stellte sich als lokaler Compilerbug bei ihm
heraus.
>>> Deshalb verstehe ich nicht warum keiner sich auf die Lösung von>>> @yalu bezieht.>> Habe ich mich auch schon gefragt, da das die exakt richtige Lösung ist.>> Wem die aus ästhetischen Gründen missfällt, der versteckt sie eben in>> einem Macro.> Ich finde sie auch OK. Könnte gut sein, dass ein entsprechender> feature request mit genau sowas beantwortet wird.
Das ist zwar eine Lösung im speziellen fall.
Aber keine generelle wie er selbst darstellt:
> Die Methode ist natürlich nicht ganz universell, da die asm-Anweisung> spezifisch an den Code zwischen cli und sei angepasst werden muss
Die braucht es aber ,mit derlei problemen umzugehen. Ich denke hier ist
es notwendig auf die Optimirungsmethode einfluss zu nehmen.
Man kann zwar bei den meißten Compilern zuvor einstellen ob zeit- oder
speicheroptimierter Code erzeugt werden soll. Mir ist jedoch nicht
bekannt, ob man dies per Pragma im sourcecode der momentanen
Programmablaufsituation anpassen oder gar ein und ausschalten kann?
Ich denke hier liegt ein grundlegender Klärungsbedarf vor, da das Timing
sehr wohl über die Qualität der Arbeit des Programmierers mit
entscheidet.
Wohl nichtzuletzt immer wieder ein Argument auch der
Hochsprachenkritiker.
>http://lkml.org/lkml/1996/5/2/87>Essentially, think of the "memory" thing as a serializing flag rather than as>a "this instruction changes memory" flag. It is extremely important that gcc>_not_ re-order memory instructions across these serializing instructions,
Wenn ich das richtig lese hatte die das gleiche Problem der
Serialisierung
Wenn ich "asm volatile ( "" : : : "memory" )" verwende kann ich aber es
nicht verhindern das die Modulooperation über das cli hinweg verschoben
wird.
Könnte es sein das sich da noch ein größeres Problem in einer der
Hauptarchitekturen zeigt???
Man sollte nicht aus den Augen verlieren, dass es sich beim skizzierten
Problem der verschobenen Division um ein ungünstiges, aber trotzdem
vollkommen korrektes Verhalten handelt. Es wird korrekt alles
ausgeführt, nur verschlechtert sich das Zeitverhalten von Interrupts.
Memory barriers hingegen stellen korrektes Verhalten sicher. Es kann,
wie im o.A. Torvalds-Text gezeigt, für ein Programm absolut wesentlich
sein, ob Speicheroperationen vor oder nach dem Aus- oder Einschalten von
Interrupts stattfinden. Finden sie zum falschen Zeitpunkt statt, kann
das Programm sich falsch verhalten.
Allerdings ist die Doku zum eCos HAL irreführend. Sie suggeriert, dass
über diese Barriere keine Reorganisation stattfindet. Das ist falsch.
Damit wird lediglich erreicht, dass keine speicherbezogene
Reorganisation stattfinden - was in den Registern passiert, bleibt davon
unberührt. Für Korrektheit reicht das aus, für ein gewünschtes
Zeitverhalten nicht.
> Könnte es sein das sich da noch ein größeres Problem in einer der> Hauptarchitekturen zeigt???
Das Problem hat so gut wie nichts mit irgendwelchen Architekturen zu
tun. Einzig Architekturen, die fast oder ganz auf Register verzichten,
bleiben davon verschont.
Jörg Wunsch schrieb:
> Hatten wir für die avr-libc auch schon mal diskutiert, war dann aber> wieder verworfen worden. Der einzige Fall, für den Björn Haase> das gefordert hatte, stellte sich als lokaler Compilerbug bei ihm> heraus.
Das ist m. E. auch ok so. Denn die Fälle, wo das "memory" wirklich
gebraucht wird, sind wahrscheinlich deutlich seltener, als diejenigen,
wo dadurch unnötigerweise Programmspeicher und Taktzyklen verschwendet
werden, zumal dadurch ja nicht jedes Problem gelöst wird.
Inline-Assembly (ob direkt oder oder in schöne Makros verpackt) ist
nun einmal ein schwieriges Thema, das nur dann sauber und ohne
Perfomance-Einbußen in den Griff zu kriegen ist, wenn eine der
folgenden Voraussetzungen gegeben ist:
- Der Compiler ist in der Lage, sämtliche Abhängigkeiten und
(Seiten-)Effekte des Assembler-Codes zu erkennen. Dann wäre jedoch
die Assembler-Sprache de facto Bestandteil der Sprache C, was nicht
realistisch ist.
- Der Programmierer ist in der Lage, sämtliche Abhängigkeiten und
(Seiten-)Effekte des Assembler-Codes zu erkennen und der Compiler
bietet eine Möglichkeit, diese Informationen entgegenzunehmen. Das
Extended Asm des GCC ist der richtige Ansatz dafür, deckt aber
sicher (noch) nicht jedes noch so exotische Problem ab.
Natürlich sind andere Wege denkbar (wie von verschiedenen Thread-
Teilnehmern bereits vorgschlagen), die weniger Nachdenken des
Programmierers erfordern, dafür aber die Optimierungsmöglichkeiten
(zumindest die lokalen) des Compilers einschränken.
<etwaswenigerernst>
Vielleicht wäre es klüger, die harmlos aussehenden cli/sei-Makros aus
der avr-libc wegzulassen. Während des Eintippens einer kompliziert
aussehende Anweisung wie
1
__asm____volatile__("cli");
hat man mehr Zeit, sich ein paar Gedanken darüber zu machen, was da
überhaupt abgeht, und vielleicht sogar mal den Onkel Google zu fragen,
was anderer Leute Erfahrung damit ist.
</etwaswenigerernst>
> Der Compiler ist in der Lage, sämtliche Abhängigkeiten und> (Seiten-)Effekte des Assembler-Codes zu erkennen.
Das kann er im hier beschriebene Fall schon prinzipiell nicht, da keine
technische Abhängigkeit gegeben ist, sondern nur in einem erwünschten
Zeitverhalten besteht.
Wolfram schrieb:
> Könnte es sein das sich da noch ein größeres Problem in einer der> Hauptarchitekturen zeigt???
A.K. schrieb:
> Man sollte nicht aus den Augen verlieren, dass es sich beim> skizzierten Problem der verschobenen Division um ein ungünstiges,> aber trotzdem vollkommen korrektes Verhalten handelt. Es wird> korrekt alles ausgeführt, nur verschlechtert sich das Zeitverhalten> von Interrupts.
Vollkommen richtig. Mich würde in diesem Zusammenhang aber mal
interessieren, wie oft die Kernel-Hacker (egal ob Linux, BSD oder
Windows) einen Blick auf den vom Compiler generierten Assembler-Code
werfen, um solche Probleme wie das von Peter beschriebene zu erkennen
und ggf.Gegenmaßnahmen zu treffen.
Allerdings vermute ich, dass sich bei den Desktop-/Server-
Betriebssystemen der verschobene Code innerhalb eines cli/sei-Paares
nicht all zu sehr auswirkt, da dadurch keine Prozessorzyklen
verschenkt werden. Es wird ja zu jedem Zeitpunkt Code ausgeführt, der
sowieso ausgeführt werden muss. Lediglich das Echtzeitverhalten, d. h.
die Raktionszeit auf Interrupts wird dadurch negativ beeinflusst.
Deswegen wäre es interessant zu wissen, wie die Programmierer von
Echtzeitsystemen mit diesem Problem umgehen.
>> Der Compiler ist in der Lage, sämtliche Abhängigkeiten und>> (Seiten-)Effekte des Assembler-Codes zu erkennen.>> Das kann er im hier beschriebene Fall schon prinzipiell nicht, da> keine technische Abhängigkeit gegeben ist, sondern nur in einem> erwünschten Zeitverhalten besteht.
Es gibt keine Abhängigkeiten, aber Seiteneffekte. Der Seiteneffekt
besteht in diesm Fall darin, dass die Interrupts gesperrt sind, was
die Reaktionszeit auf externe Ereignisse verschlechtert, was wiederum
ein guter Optimierer zu Anlass nehmen könnte, die Zeitdauer dieses
(zwar nicht destruktiven, aber doch schädlichen) Seiteneffekts auf ein
Minimum zu reduzieren.
yalu wrote:
> Es gibt keine Abhängigkeiten, aber Seiteneffekte. Der Seiteneffekt> besteht in diesm Fall darin, dass die Interrupts gesperrt sind, was> die Reaktionszeit auf externe Ereignisse verschlechtert, was wiederum> ein guter Optimierer zu Anlass nehmen könnte, die Zeitdauer dieses> (zwar nicht destruktiven, aber doch schädlichen) Seiteneffekts auf ein> Minimum zu reduzieren.
Wir begeben uns auf eine Endlosschleife zu ;-)
Wie war das? C kennt keine Interrupts/Threads/.../externe Ereignisse,
also kann auch kein Optimierungsprogramm Annahmen darüber treffen. Ich
fürchte, daß es auf einen nicht portablen (aus ANSI/ISO-Sicht) Hack
hinauslaufen wird.
yalu wrote:
> die Reaktionszeit auf externe Ereignisse verschlechtert, was wiederum> ein guter Optimierer zu Anlass nehmen könnte, die Zeitdauer dieses> (zwar nicht destruktiven, aber doch schädlichen) Seiteneffekts auf ein> Minimum zu reduzieren.
Dann würde er versuchen den sei() möglichst nahe an den cli()
heranzuführen. Mit anderen Worten: er würde anfangen Anweisungen
aus der cli() - sei() Klammerung herauszuschieben.
Meine momentan favourisierte Idealvorstellung sieht
so aus, dass man einem C-Block eine Attributierung verpassen
kann. Sowas in der Art
volatile {
cli();
...
sei();
}
dieser zusätzliche { }, markiert mittels volatile, schaltet
die Optimierung auf diesem Block ab (in Anaolgie zu einer
volatile Variablen). Ob das jetzt bedeutet, dass innerhalb
dieses Blocks überhaupt keine Optimierungen mehr stattfinden,
oder ob das nur als Barriere fungieren soll: Ich diskutiere
da noch mit mir selbst :-)
@Patrick Dohmen
>also kann auch kein Optimierungsprogramm Annahmen darüber treffen. Ich>fürchte, daß es auf einen nicht portablen (aus ANSI/ISO-Sicht) Hack>hinauslaufen wird.
Warum? Es wurde doch schon eine vollkommen standardkonforme Lösung mit
einer volatile Variable beschrieben. Fertig aus.
MfG
Falk
> Es gibt keine Abhängigkeiten, aber Seiteneffekte.
Mit diesem Gedanken näherst du dich stark dem allseits gewünschten
DWIM,NWIS Compiler (Do What I Mean, Not What I Say).
> Ob das jetzt bedeutet, dass innerhalb> dieses Blocks überhaupt keine Optimierungen mehr stattfinden,> oder ob das nur als Barriere fungieren soll: Ich diskutiere> da noch mit mir selbst :-)
Das ergibt so keinen Sinn. Mehr Sinn ergäbe es, wenn über die Grenzen
eines solchen Blocks keinerlei reordering stattfinden darf, innerhalb
jedoch schon.
Sowas kannst du machen, wenn du die Hoheit über den Compiler besitzt.
Bau dir deine eigene Version vom GCC, bau das in SDCC ein, was auch
immer. Aber erwarte nicht, dass sowas jemals in der offiziellen Distro
aufkreuzt.
Falk wrote:
> Warum? Es wurde doch schon eine vollkommen standardkonforme Lösung mit> einer volatile Variable beschrieben. Fertig aus.
Aha! Warum ist dann hier nicht "Fertig aus"?
Vermutlich weil diese Lösung nicht zufriedenstellend ist.
@Patrick Dohmen
>Aha! Warum ist dann hier nicht "Fertig aus"?
Weil mal wieder
a) die eierlegende Wollmilchsau gesucht wird
b) jeder 2. Thread nach spätestens einem Dutzend Postings ins
Philosophische abdriftet
MFG
Falk
P.S. Oink Oink!
A.K. wrote:
>> Ob das jetzt bedeutet, dass innerhalb>> dieses Blocks überhaupt keine Optimierungen mehr stattfinden,>> oder ob das nur als Barriere fungieren soll: Ich diskutiere>> da noch mit mir selbst :-)>> Das ergibt so keinen Sinn. Mehr Sinn ergäbe es, wenn über die Grenzen> eines solchen Blocks keinerlei reordering stattfinden darf, innerhalb> jedoch schon.
Das dachte ich ursprünglich auch.
Aber dann fiel mir auf, dass der Compiler im
gegenständlichen Fall ja auch die Transformation:
{
i = j;
cli();
sei();
}
anstelle von
{
cli();
i = j;
sei();
}
tunlichst nicht machen sollte.
>> Sowas kannst du machen, wenn du die Hoheit über den Compiler besitzt.> Bau dir deine eigene Version vom GCC, bau das in SDCC ein, was auch> immer. Aber erwarte nicht, dass sowas jemals in der offiziellen Distro> aufkreuzt.
Das ist mir schon klar. Auf der anderen Seite: Auch bei C gibt
es wie bei C++ einen 'demokratischen' Prozess, der darüber
entscheidet wie sich die Sprache weiterentwickelt.
Bei C++ (bei C weiss ich es nicht) war es so: Eine funktionierende
Demonstration in einem realen Compiler (g++ musste da anscheinend
oft herhalten) hat die Wahrscheinlichkeit für die Aufnahme
in den ANSI Standard enorm erhöht. Dazu noch einen
(möglichst einflussreichen) Fürsprecher auf den nächsten ANSI
Sitzungen ...
Den gcc ändern: Da trau ich mich ehrlich nicht drüber. Dazu
versteh ich zuwenig von den gcc Internals.
Falk wrote:
> b) jeder 2. Thread nach spätestens einem Dutzend Postings ins> Philosophische abdriftet
Das sehe ich in diesem Thread aber nicht. Ich kann schon verstehen, daß
man weder alle Optimierungen verbieten will, noch eine -
möglicherweise - hundertfache Ausführungszeit hinnehmen möchte. Es fehlt
ein Mittelding, was wohl der Grossteil der Poster in diesem Thread
genauso sieht.
> P.S. Oink Oink!
Würdest Du mich diesbezüglich aufklären?
@Patrick Dohmen
>Das sehe ich in diesem Thread aber nicht. Ich kann schon verstehen, daß>man weder alle Optimierungen verbieten will, noch eine ->möglicherweise - hundertfache Ausführungszeit hinnehmen möchte. Es fehlt>ein Mittelding, was wohl der Grossteil der Poster in diesem Thread>genauso sieht.
Ja.
>> P.S. Oink Oink!>Würdest Du mich diesbezüglich aufklären?
Das war ein Gruss an die eierlegende Wollmilchsau. ;-) Never mind.
MFG
Falk
>Aha! Warum ist dann hier nicht "Fertig aus"?
Weil nicht sicher ist, das die Lösung auch für andere (zukünftige)
Optimierungen sicher ist.
Das ist aber nur mit einem Eintrag im Bugzilla zu klären.
> Du wirst doch selbst zugeben müssen, dass ein Rückgabewert von "main"> auf einem µC sinnfrei ist. Warum wird das denn dann nicht einfach in> den avr-gcc fest eingebaut?
Also statt einfach die konforme und universelle Variante zu verwenden,
soll im GCC extra für AVR eine Sonderbehandlung eingebaut werden, nur
damit er dann auch die nicht konforme Variante, die keinerlei Vorteile
hat, akzeptiert?
> Siehe http://www.ecos.sourceware.org/docs-1.3.1/ref/ecos...> HAL_REORDER_BARRIER().>> Implementiert als> asm volatile ( "" : : : "memory" ).
Genau das macht doch auch schon die im Compiler eingebaute Funkton
__sync_synchronize().
Ich sehe da schon einen Unterschied:
asm volatile ( "" : : : "memory" ).
erzeugt keinen Code, sondern steuert das Verhalten des Compilers
hinsichtlich Optimierung von Speicherzugriffen.
__sync_synchronize
hingegen erzeugt, sofern überhaupt vorhanden, zusätzlich
Prozessorbefehle, die dafür sorgen, dass auch seitens der Maschine kein
reordering über diese Grenze stattfindet.
Falk wrote:
>>> P.S. Oink Oink!>>Würdest Du mich diesbezüglich aufklären?>> Das war ein Gruss an die eierlegende Wollmilchsau. ;-) Never mind.
Sowas ähnliches hatte ich mir schon gedacht. Danke trotzdem, hätte ja
auch ein (mir nicht bekanntes) Akronym sein können ;-)
Wolfram wrote:
>>Aha! Warum ist dann hier nicht "Fertig aus"?>> Weil nicht sicher ist, das die Lösung auch für andere (zukünftige)> Optimierungen sicher ist.> Das ist aber nur mit einem Eintrag im Bugzilla zu klären.
Genau!
Ist das obige Problem u.U. nicht auch zum Großteil hausgemacht?
CLI ist der Vorschlaghammer, der immer den kompletten Prozessor lahm
legt. Es wäre doch geschickter, nur die Interruptquelle zu sperren, die
den Zugriff auf 'ivar' stören könnte. Und dann ist die Frage, ob das
Problem der Ausführungsreihenfolge überhaupt noch relevant ist.
Profibauer wrote:
> CLI ist der Vorschlaghammer, der immer den kompletten Prozessor lahm> legt.
Bei nur 6 Zyklen ist es ein Uhrmacherhämmerchen.
200 Zyklen währen ein Vorschlaghammer.
> Es wäre doch geschickter, nur die Interruptquelle zu sperren, die> den Zugriff auf 'ivar' stören könnte.
Nein, wäre es nicht.
Es könnten dann sämtliche anderen Interrupts, die in der Pollingsequenz
dahinter liegen, dazwischen hauen und in der Summe eine zu hohe
Latenzzeit bewirken.
Außerdem ergibt das mehr Code.
Und wenn die Enable Bits im gleichen Register wie die Pending-Bits
liegen (z.B. I2C), tappt man in die nächste AVR-Fallgrube (Pending-Bits
dürfen nie zurückgeschrieben werden).
> Und dann ist die Frage, ob das> Problem der Ausführungsreihenfolge überhaupt noch relevant ist.
Es ist dem Interrupt relativ wurscht, ob nur er selber oder alle anderen
mit für eine sehr lange Zeit gesperrt sind.
Peter
>Es könnten dann sämtliche anderen Interrupts, die in der Pollingsequenz
dahinter liegen, dazwischen hauen und in der Summe eine zu hohe
Latenzzeit bewirken.>
Dann stellt sich die Frage, ob der Prozessor nicht generell 'ne Nummer
zu klein gewählt wurde.
@Profibauer
>>Es könnten dann sämtliche anderen Interrupts, die in der Pollingsequenz>>dahinter liegen, dazwischen hauen und in der Summe eine zu hohe>>Latenzzeit bewirken.>>Dann stellt sich die Frage, ob der Prozessor nicht generell 'ne Nummer>zu klein gewählt wurde.
Quark! Das läuft alles wunderbar, solange der Compiler nicht so "schlau"
ist, und lange Operationen "illegal" in einen Block schiebt, in dem die
Interrupts gesperrt sind. Hier ist ausnahmsweise mal der Compiler
"Schuld", weil er versucht schlauer zu sein als der Programmierer. Hier
gehts schief.
MFG
Falk
> Hier ist ausnahmsweise mal der Compiler> "Schuld", weil er versucht schlauer zu sein als der Programmierer.
Das ist sein Job. Die Schuld des Programmierers ist es anzunehmen,
dass der Compiler alles exakt in der Abfolge umsetzen müsse, wie es
niedergeschrieben worden ist. Wenn man das haben will, muss man in
Assembler programmieren.
Wir sind uns doch inzwischen einig, dass das ein Manko von C als
solches ist, das sich letztlich nur durch ein compilerabhängiges
Feature ausgleichen lässt, eben sowas wie ein volatile für einen
brace block.
>Das ist sein Job.>Wenn man das haben will, muss man in Assembler programmieren.
So sehe ich das auch. Wie groß wäre das Getöse, wenn der Compiler nicht
optimieren würde. Und irgendwo muß man die Hinweise auch 'mal ernst
nehmen, daß die Reihenfolge der Abarbeitung eben nicht so ist, wie man
es eintippt.
Aus der Diskussion lerne ich: was der Compiler macht ist kein schwerer
Bug, sondern ein Kompromiß, den man als 'erfahrener Programmierer'
kennen sollte. Dafür werden wir ja schließlich bezahlt ;-)
Und um die 200 Taktzyklen einzuschätzen: bei 16MHz dauern die etwa 13µs.
Gut, müßte nicht unbedingt sein, aber damit sollte man leben können. Und
wenn man dies absolut nicht akzeptieren kann, dann werden eben ein paar
Zeilen Assembler eingetippt.
Deshalb Änderungen am Compiler vorzunehmen würde ich nicht fordern.
Profibauer wrote:
>>Das ist sein Job.>>Wenn man das haben will, muss man in Assembler programmieren.>> So sehe ich das auch.
Ich nicht. Das ist ein Manko in C an sich.
Um es loszuwerden, muss an der Sprachdefinition
gedreht werden.
Zur Zeit geht es halt nur über Assembler, aber das
muss ja nicht so bleiben.
> Wie groß wäre das Getöse, wenn der Compiler nicht> optimieren würde.
Das fordert auch niemand.
Nur stellt sich in diesem Fall heraus, dass der Programmierer
den Optimizer leiten muss.
> Aus der Diskussion lerne ich: was der Compiler macht ist kein> schwerer Bug
Das sehe ich auch so.
Den Compiler trifft keine Schuld. Hier sind die Möglichkeiten
von C an sich nicht ausreichend.
> wenn man dies absolut nicht akzeptieren kann, dann werden eben ein paar> Zeilen Assembler eingetippt.
Im Moment: ja
Auf lange Sicht ist das nicht akzeptabel.
> Deshalb Änderungen am Compiler vorzunehmen würde ich nicht fordern.
Richtig: Zuerst müsste man die Sprachdefinition ändern und
erst dann werden Compiler umgebaut.
Das Ganze ist wie 'volatile'. Dieses Schlüsselwort gab es im
Ur-C genausowenig wie void oder const. Im Laufe der Zeit hat
sich herauskristallisiert, dass man sowas benötigt und es
wurde in die Sprachdefinition aufgenommen.
Die C Defintion sind ja nicht die '10 Gebote': Für alle
Zeiten unabänderlich. Schwierig wird nur, jemanden aus dem
ANSI Kommitee als Fürsprecher zu gewinnen. Einen gcc-Kundigen
zu finden, der eine Vorabänderung im Compiler als
'proof of concept' durchführt, müsste möglich sein.
> Warum schafft es dann der ICC?
Krass gesagt: weil er so schlecht optimiert, dass er gar nicht erst
auf die Idee kommt, die Division überhaupt zu verschieben.
Das ist ja genau das, was Karl Heinz auch mit den Veränderungen im
C-Standard meinte: die ursprünglichen C-Compiler kannten derartige
Optimierungen überhaupt nicht, dass man bestimmte Werte in einem
Register zwischenspeichert. Die brauchten noch explizit das
Schlüsselwort "register" dafür. Dementsprechend brauchte man dort
keine Daten als "volatile" zu deklarieren.
Mittlerweile sind die Compiler eben mit ihren Optimierungen mal wieder
einen Schritt weiter, und der C-Standard müsste nachziehen.
>Krass gesagt: weil er so schlecht optimiert, dass er gar nicht erst>auf die Idee kommt, die Division überhaupt zu verschieben.
So kann man sich natürlich auch aus der Affäre ziehen. Dass der Compiler
einfach gut ist und erkennt, dass ein Verschieben an dieser Stelle nicht
sinnvoll ist, kommt wohl überhaupt nicht Frage, wie?
Du mußt es so sehen, ICC ist kein Wald- und Wiesencompiler, den es für
10000 Architekturen gibt. Der ICC ist für Mikrocontroller entwickelt
worden, und wird weiter für solche optimiert und erweitert, erfolgreich
derzeit mit Version 7. Siehst du ja schon daran, dass ein "int
main(void)" nicht erwartet wird. Scheiß auf den C-Standard, er stammt
aus einer Zeit, als noch niemand ansatzweise daran gedacht hat, µCs in C
zu programmieren. Und sämtliche Erweiterungen des Standards haben es
nicht wirklich gebracht.
@Patrick Dohmen
>Oho, jetzt kommt die Militante Fraktion und wirft den gesamten>Gesprächsverlauf wieder zurück ins Mittelalter...
;-)
Naja, nicht ganz. Aber die Jungs die den AVR-Port geschrieben haben
sollten/müssen schon ein paar Besonderheiten von uCs beachten. Und man
hätte ja in den Macros sei() und cli() die diversen, schon vorhandenen,
Macros für volatile, memory block und weissderTeufelwas einbauen
könen/müssen, um eben solche "Optimierungen" zu verhindern. Schliesslich
sind sämtliche Register im AVR auch als volatile gekennzeichnet.
MfG
Falk
Jens wrote:
> So kann man sich natürlich auch aus der Affäre ziehen. Dass der Compiler> einfach gut ist und erkennt, dass ein Verschieben an dieser Stelle nicht> sinnvoll ist, kommt wohl überhaupt nicht Frage, wie?
Nur dann, wenn du nachweist, dass er es ansonsten beherrscht. ;-)
Im Ernst: natürlich könnte ein Compiler für Controller für sich
entscheiden, etwas über Interrupts zu wissen und die Interrupt-
steuerung (cli/sei) dann als Kriterium benutzen, den Code dazwischen
entsprechend im Optimierungsverhalten anzupassen. Das hätte ich dem
IAR sogar zugetraut, da bei ihm __enable_interrupt und
__disable_interrupt tatsächlich im Compiler selbst implementiert sind,
nicht wie bei GCC als inline assembly.
Es ist aber, unabhängig davon, eben verdammt schwierig, die Intention
des Programmierers nur an Hand dessen zu entscheiden und die richtige
Wahl zu treffen. Du willst ja nicht grundsätzlich, während die
Interrupts verboten sind, auf jegliche Optimierung verzichten -- das
wäre genauso am Ziel vorbei geschossen:
1
cli();
2
/* 500 Lines of code */
3
sei();
> Du mußt es so sehen, ICC ist kein Wald- und Wiesencompiler, den es> für 10000 Architekturen gibt. Der ICC ist für Mikrocontroller> entwickelt worden, und wird weiter für solche optimiert und> erweitert, ...
Das alles trifft auf den IAR genauso zu, das zieht also nicht
wirklich. Ja, er warnt auch nicht für void main(void) ;-) (schlägt
aber in seinem leeren main(), wenn man es von ihm anlegen lässt, sehr
wohl int main(void) ... return 0; vor). Andererseits ist natürlich
gerade der IAR durchaus dafür bekannt, im hier diskutierten Segment
mit den besten Code abzuliefern. Außerdem besitzt er die umfassendste
C99-Implementierung, die ich bislang gesehen habe. Kann denn außer
IAR und GCC überhaupt noch jemand auch nur ansatzweise C99 (damit
meine ich mehr, als dass es //-Kommentare auch in C gibt)?
Falk wrote:
> Und man hätte ja in den Macros sei() und cli() die diversen, schon> vorhandenen, Macros für volatile, memory block und weissderTeufelwas> einbauen könen/müssen, um eben solche "Optimierungen" zu verhindern.
Ja, mach mal.
Mir dünkt, du hast die Tragweite dieser deiner Behauptung noch nicht
verstanden und sehr wahrscheinlich nicht einmal yalu's Vorschlag
mitsamt dessen Begründung. Sonst wüsstest du nämlich, warum das so
nicht machbar ist.
Nun ist es aber wirklich an der Zeit, dass mal jemand von denen, die
hier am lautesten rufen, den feature request schreibt.
@Jörg Wunsch
>Es ist aber, unabhängig davon, eben verdammt schwierig, die Intention>des Programmierers nur an Hand dessen zu entscheiden und die richtige>Wahl zu treffen. Du willst ja nicht grundsätzlich, während die>Interrupts verboten sind, auf jegliche Optimierung verzichten -- das>wäre genauso am Ziel vorbei geschossen:> cli();> /* 500 Lines of code */> sei();
Ja. Aber es wurde doch schon mehrfach gesagt, dass man dem Compiler
beibigen muss, cli() und sei() auasi als Sequence Point oder wie auch
immer das heisst aufzufassen und über diesen Punkt darf nix verschoben
werden. Wenn ich das richtig verstanden haben gibts beim GCC schon
einige "geheime" Schalter/Attribute, die das machen. Und selbst wenn
derBlcok zwischen cli() und sei() nicht optimiert wird, sollte das wnig
Einfluss auf die Performance haben, da diese Befehle sinnvollerweise nur
sparsam eingesetzt werden.
MFG
Falk
Ich denke ISO/ANSI kann man vergessen - für alles unterhalb
Betriebssystemebene scheinen die sich nicht zu interessieren, sonst
würden sie es endlich mal auf die Reihe bekommen portable Bitfelder und
Fractional-Zahlen zu standardisieren.
> Aber die Jungs die den AVR-Port geschrieben haben> sollten/müssen schon ein paar Besonderheiten von uCs beachten.
Das Wörtchen "müssen" reduziert die Wahrscheinlichkeit, dass sich jemand
eines solchen Themas überhaupt annimmt. Open source wie GCC heisst: Nimm
was da ist, oder löse dein Problem selbst oder hoffe, dass jemand so
nett ist es zu tun. Aber verlange nicht von anderen, für Lau dein
Problem zu lösen, auch nicht wenn du es für wirklich sinnvoll, nötig,
unverzichtbar hältst.
Wie oben schon gelegentlich angeführt, hat die Spezifikation der
Zielmaschine im GCC herzlich wenig Einfluss auf maschinenunabhängige
Optimierungen wie diese Verschiebung der Division.
Wenn eine Portierung auf eine bestimmte Zielmaschine im
maschinenunabhängigen Kern des Compiler rumferkelt, dann reduziert das
dementsprechend das Wahrscheinlichkeit einer Übernahme in den
offiziellen Quellcode. Mal abgesehen davon, dass es entsprechend mehr
Kenntnis seitens des Programmierers verlangt also sonst nötig.
Speicherbezogene barriers sind einfach, wie hier schon gesehen, auch als
Bestandteil von cli/sei möglich (siehe dazu Jörgs Kommentar), aber lösen
das hier beschriebene Problem nicht.
Falls ein Compiler anbieten würde, zwischen cli() und sei() mal zu
optimieren und mal nicht, bleibt es letztlich doch am Programmierer
hängen, diese Situation überhaupt zu erkennen und entsprechende Optionen
anzufordern. Automatisch wird es wohl nicht funktionieren (können).
@Profibauer
>Falls ein Compiler anbieten würde, zwischen cli() und sei() mal zu>optimieren und mal nicht, bleibt es letztlich doch am Programmierer>hängen, diese Situation überhaupt zu erkennen und entsprechende Optionen>anzufordern. Automatisch wird es wohl nicht funktionieren (können).
Das wäre IMHO vollkommen OK.
MFG
Falk
Ein anderer, offensichtlicher Workaround: Übersetze diese Source ohne
-O* Optimierung!
Packe den Codeteil, der auf die cli/sei-Klammer angewiesen ist, in ein
eigenes Sourcefile. Übersetze dieses ohne Optimierung.
Den Rest der Source kommt in andere Quelldateien, die dann mit
Optimierung übersetzt werden können.
Objektdateien zusammenlinken und fertisch.
Mich stört mehr, dass man (ich) nicht aus der GCC Doku erfahre, welche
Optimierungsstrategie für das Verzögern der ersten Anweisung
verantwortlich ist.
Die -f... Schalter bei den -O Optionen beeinflussen diese Art der
Optimierung nicht. D.h. man kann genau diese Optimierung nicht selektiv
ab- oder abschalten und man hat nur die Holzhammer-Methode oben.
@Stefan
>Packe den Codeteil, der auf die cli/sei-Klammer angewiesen ist, in ein>eigenes Sourcefile. Übersetze dieses ohne Optimierung.
Na DAS ist weiss Gott ein Würg-Around!
>ab- oder abschalten und man hat nur die Holzhammer-Methode oben.
Das mit der volatilen temporären Variablen fand ich äusserst schmerzarm.
MFg
Falk
Falk wrote:
> @Stefan>>>Packe den Codeteil, der auf die cli/sei-Klammer angewiesen ist, in ein>>eigenes Sourcefile. Übersetze dieses ohne Optimierung.>> Na DAS ist weiss Gott ein Würg-Around!
Daran ist garnichts Würg.
Du wirst lachen, das werde ich wohl nehmen.
Es koste gerademal 2 Worte mehr (RCALL+RET) und die Optimierung braucht
man auch nicht auszuschalten. Der Compiler sieht ja das andere Objekt
nicht, kann es also nicht reinoptimieren.
> Das mit der volatilen temporären Variablen fand ich äusserst schmerzarm.
Das ist wesentlich teurer, da ja ständig im SRAM rumgewuselt werden muß.
Peter
> Allerdings vermute ich, dass sich bei den Desktop-/Server-> Betriebssystemen der verschobene Code innerhalb eines cli/sei-Paares> nicht all zu sehr auswirkt, da dadurch keine Prozessorzyklen> verschenkt werden. Es wird ja zu jedem Zeitpunkt Code ausgeführt, der> sowieso ausgeführt werden muss. Lediglich das Echtzeitverhalten, d. h.> die Raktionszeit auf Interrupts wird dadurch negativ beeinflusst.> Deswegen wäre es interessant zu wissen, wie die Programmierer von> Echtzeitsystemen mit diesem Problem umgehen.
Auch dort gibt es Situationen in denen das Zeitverhalten kritisch ist
und z.B. beim Zugriff auf Peripheriegeräte bestimmte Reihenfolgen und
Timings eingehalten werden müssen (auf dem AVR z.B.
EEPROM/Watchdog-Zugriffe)
Beispiel:
http://lkml.org/lkml/2006/11/1/254
Falls man noch (standardkonforme) Wünsche äussern darf
#pragma atomic|interruptable|monitor on|off
und
#pragma reorder on|off
....
womit wir entlich beim richtigen Ansatz sind.
benötigt wird:
#pragma opt(imice) on
#pragma opt(imice) off
#pragma opt(imice) time
#pragma opt(imice) memory
Diese vier Pragmen sollte ein Compiler für wohl jeden µC (ich behaupte
gar jeden Prozessor) beherschen und zur not das gesamte pipelinig nebst
Cash neuordnen können wenn es der Programierer so will!
Schließlich muss der Programmierer (Mensch) Herr über das System bleiben
und nicht sein Sklave.
Dies All Jenen ins Stammbuch, welche glauben der Programmierer ist
schuld, weil er etwas logisches vom Tool erwartet, was für jedoch dessen
Direktiven widerspricht. Hier sind die Direktiven die Falschen nicht der
Programmierer, der Herr des Codes sein muß.
Ein Tool sollte ein Hilfsmittel bleiben. seine Direktiven sind den
Erfordernissen anpassbar zu gestallten. Tut man dies nicht, so verfehlt
das Tool seine Aufgabenstellung und wird dem Markt nicht gerecht. Dies
als kleine philosophische Anmerkung.
Seltsam ist nur, dass man diejenigen, die hier die schlauesten Reden
schwingen, nie sieht, wenn's um das Lösen von Problemen geht...
Geschweige denn dabei, sich auch nur mal annähernd ein Stück
Compilercode anzugucken. (*)
Sorry, aber die Optimierung ist mittlerweile einfach mal viel zu
komplex geworden, als dass sich ein Compilerhersteller noch darauf
einlassen könnte, sie irgendwo zwischen zwei Quellzeilen mal nur
so auf die Schnelle umschalten zu können. Mittlerweile optimieren
die Compiler über komplette Projekte hinweg (also über mehr als eine
Quelldatei).
(*) Ich hab' zumindest wenigstens ein Alibi, auch wenn ich vom
Compilerbau selbst keine große Ahnung habe. Der 0b-Patch für die
Binärkonstanten ist praktisch mittlerweile von den GCC-Entwicklern
akzeptiert worden, es braucht nun nur noch jemanden mit den nötigen
Rechten und der Zeit, damit er in den GCC integriert wird. Wenn dann
die Damen und Herren des ISO-Kommittees das nächste Mal zusammensitzen,
können sie dann nicht mehr lapidar feststellen, dass der entsprechende
Standardvorschlag mangels ``lack of precedence and sufficient value''
verworfen worden ist...
Generischer Ansatz für Interrupt-feste Zuweisungen, basierend auf yalu's
Lösung ("poor man's template" - in C++ sieht sowas hübscher aus).
[--std=gnu99]
>Seltsam ist nur, dass man diejenigen, die hier die schlauesten Reden>schwingen, nie sieht, wenn's um das Lösen von Problemen geht...>Geschweige denn dabei, sich auch nur mal annähernd ein Stück>Compilercode anzugucken. (*)
Sorry ich bnutze CVAVR und habe das Problem nicht, obgleich auch dieser
optimiert.
Compiler baue ich auch (noch) nicht, aber ich weiß was ich benötige und
das suche ich mir.
Meine eigenen von CVAVR compilierten Code studiere ich sehr wohl,
fremdes eher selten (da fremden Gedanken zu folgen oft schwerer ist noch
dazu wen noch werd drüber ist), schon um zuerfahren was er draus macht,
seine Funktion zu verstehen und daraus zu lernen.
Ich bin seit 37 Jahren Autodidakt in Sachen Elektronik und
Programierung, während ich in Sachen Philosophie tatsächlich ein paar
Semester hatte. Ohne dieses eigenständige Hinter_die_Kulissen schauen
wäre ich ein typischer Mediamarktkunde(Blödmann, Mausschubser)
Nun zum Eesentlichen: Der einzige Grund warum ich nicht die fertige
Lösung anstrebe ist ein Mangel an Zeit. An Ehrgeiz oder Neugier
jedenfalls mangelt es mir nicht. Und das notwendige Wissen würde ich mir
erwerben, schon um das Problem zu lösen und eine Beitrag zu leisten. Nur
glaube ich, dass wer da bereits drinnen steckt diese Anregung wesentlich
schneller und leichter umsetzen kann als ich, der ich mich erst
einarbeiten müßte.
Ich weis 99% sind Fleiss, aber ohne 1% Idee läuft halt gar nichts.
keep smile ;-))
Hallo, ich habe diesen langen Thread nicht komplett durchgelesen und nur
überflogen.
Die angesprochenen Optimierungen im GCC können wirklich ein Ärgernis
sein, vor allem, wenn sie zu fehlerfhaftem Code führen (zB nicht-atomare
Port-Zugriffe wegen CSE-Optimierung).
Ob die neuen SSA-Optimierungsstrategien in GCC besseren Code bewirken,
bleibt abzuwarten. Ich für meinen Teil bin da eher skeptisch und
verwende weiterhin die stabile 3.4.6, die dichten Code erzeugt (dichter
als 4.x). Optimierungen sind nämlich nur in wenigen Ausnahmefällen
maschinenunabhängig...
Wie auch immer.
Zum Workaround können Barrieren dienen, über die GCC nicht hinweg
optimiert -- aus welchen Gründen auch immer.
Eine dieser Barrieren wurde schon genannt:
Eine weitere Barriere stellt das explizite reloaden eines Wertes in eine
bestimme Registerklasse dar. RELOAD lässt GCC vergessen, welchen Wert
eine bestimmte Variable hat:
__asm____volatile(";RELOAD ""r"" with ""dis":"=""r"(dis):"0"
Ohne RELOAD wählt GCC absoluten Zugriff, weil er die Adresse zur C-Zeit
berechnen kann. (zwar nicht als Konstante, aber als Immediate).
1
foo:
2
ldi r24,lo8(48) ; tmp42,
3
sts display,r24 ; <variable>.digit, tmp42
4
sts display+1,r24 ; <variable>.digit, tmp42
5
sts display+2,r24 ; <variable>.digit, tmp42
6
sts display+3,r24 ; <variable>.digit, tmp42
7
ret
Mit RELOAD muss der Zugriff indirekt erfolgen:
1
foo:
2
ldi r30,lo8(display) ; dis,
3
ldi r31,hi8(display) ; dis,
4
/* #APP */
5
;RELOAD z with dis
6
/* #NOAPP */
7
ldi r24,lo8(48) ; tmp42,
8
st Z,r24 ; <variable>.digit, tmp42
9
std Z+1,r24 ; <variable>.digit, tmp42
10
std Z+2,r24 ; <variable>.digit, tmp42
11
std Z+3,r24 ; <variable>.digit, tmp42
12
ret
Mit RELOAD kann übrigens nicht erzwungen werden, daß eine Variable in
einem bestimmten Register angelegt wird. Wählt man als Constraint etwa
"z", dann hätte das bewirkt nur, daß sich 'dis' zum Zeitpunkt des asm im
Z Register befindet. Es bedeutet nicht, daß 'dis' im Z-Register lebt!
MfG Georg-Johann
Zielkonflikt. Da <ivar> üblicherweise volatile sein wird, ist Version 1
doch sinnvoller, sonst erbt <x> diese Eigenschaft und steckt im
Speicher. Nur sollte dann keine aufwendige Typkonvertierung in der
Zuweisung drin sein. Also besser nicht double x = safe_assign(1).
@SprinterSB: Interessanter Ansatz. Aber wird man sich auf CSE_BARRIER
verlassen können? Dieses asm-statement ist ja ein ziemliches Nichts.
Wenn das also nicht offiziell so definiert ist, könnte dieses Verhalten
irgendwann wieder verschwinden.
>Korrektur:>>#define safe_assign(dst,src) \> { typeof(dst) x = (src); \> asm volatile (""::"r"(x)); \> cli(); \> dst = x; \> sei(); \> }
Dies ist nicht korrekt. x ist hier nut Input-Operand des asm. Das mag in
einigen Fällen das Problem lösen, garantiert es aber nicht.
Hier hilft das eben beschriebene RELOAD:
> Sorry, aber die Optimierung ist mittlerweile einfach mal viel zu> komplex geworden, als dass sich ein Compilerhersteller noch darauf> einlassen könnte, sie irgendwo zwischen zwei Quellzeilen mal nur> so auf die Schnelle umschalten zu können. Mittlerweile optimieren> die Compiler über komplette Projekte hinweg (also über mehr als eine> Quelldatei).
Ob man das auch für jede einzelne Zeile festlegen muss, nein, solange
man Inlining, bei Bedarf, erzwingen kann.
ICC und VC lassen es zumindest zu das man die Optimierungsstufe auf
Funktionsebene festlegt.
A.K. wrote:
> @SprinterSB: Interessanter Ansatz. Aber wird man sich auf CSE_BARRIER> verlassen können? Dieses asm-statement ist ja ein ziemliches Nichts.> Wenn das also nicht offiziell so definiert ist, könnte dieses Verhalten> irgendwann wieder verschwinden.
Ich verwende es in avr-gcc 3.4.6. Tatsächlich ist es nicht spezifiziert,
was das macht (oder nicht macht). Für den Moment bin ich aber glücklich
damit, weil es mir die SFR-Zugriffe atomar hält (zumindest
Setzen/Löschen eines Bits im bitadressierbaren I/O-Bereich). Korrekt
müsste man jedes Setzen/Löschen schachteln à la
1
{
2
unsignedcharsreg=SREG;
3
cli();
4
PORTB&=~(1<<7);
5
SREG=sreg;
6
}
Auch nicht lecker...
Wenn ich mal auf avr-gcc 4.x umsteige, werd ich schauen, ob das Problem
dort immer noch besteht und ggf. eine neue Lösung finden müssen.
Es ist übrigens kein Bug in GCC, weil der Zugriff ja nicht atomar sein
muss. Hier wäre ein __attribute__((atomic)) wünschenswert (genauer wäre
ein Qualifier "atomic" adäquat und nicht ein Attribut, aber Attribute
sind im gcc-Backend wesentlich einfacher zu implementieren als
Qualifier, die eine nicht vorgesehene Spracherweiterung bedeuten und
sich quer durch GCC ziehen würden).
Selbst komplett leere inline asm können ihren Zweck erfüllen. Das oft
von Einsteigern verwendete nop() zum Verhindern des Wegoptimierens einer
Schleife, die keine Wirkung auf die Welt hat, kann tatsächlich
entfallen:
1
unsignedchati;
2
3
for(i=0;i<10;i++)
4
asmvolatile("");
genügt. Es bewirkt allerdings nicht, daß i von 0 bis 9 läuft (wenn ist's
Zufall). Es bewirkt nur, daß das asm zur Laufzeit 10 mal ausgeführt
wird. (Das könnte freilich auchbedeuten, daß die Schleife aufgerollt
wird... was mit -O2/-Os allerdings nicht geschieht.)
A.K. wrote:
> Und mal als Demonstration, warum C++ bei Microcontrollern durchaus> sinnvoll sein kann:>
1
>template<classt>classsafe_var{
2
>public:
3
>voidoperator=(trhs){
4
>ttmp=rhs;
5
>RELOAD("r",rhs);
6
>cli();
7
>value=tmp;
8
>sei();
9
>}
10
>
Die korrekte Anwendung ist:
1
template<classt>classsafe_var
2
{
3
public:
4
voidoperator=(trhs)
5
{
6
RELOAD("r",rhs);
7
cli();
8
value=rhs;
9
sei();
10
}
11
12
....
Es muss das Objekt durch RELOAD geschleust werden, das in einem Register
gehalten werden soll! rhs ist IN und OUT-Operand des asm!
BTW: Zudem hat das sei() einen Nebeneffekt auf SREG.
> BTW: Zudem hat das sei() einen Nebeneffekt auf SREG.
Verstehe nicht, was du damit sagen willst.
Gänzlich korrekt ist natürlich eine Variante mit gerettetem SREG statt
sei(). Und wird Interrupts, weil es um Effizienz geht, eher ungesicherte
Zugriffe direkt auf <value> verwenden wollen.
Hallo Peter
Hast du dein Problem inzwischen gelößt bekommen?
Und hast du es mit dem externen Objekt erschlagen oder Hast du einen
Kompfortableren Weg gefunden?
Auch sonst würde mich iteressieren was sich aus dieser Diskussion
entwickelt oder ob sie nur im Sande verläuft. Ist dort noch wer am Ball
geblieben?
man sieht sehr deutlich: CVAVR hält sich trotzt Optimierung an die
vorgegebenen zeitlichen Abläufe
Sicher entspricht dieses Verhalten nicht nur meinen sondern auch Peters
Erwartungen.
ich behaupte mal das CVAVR damit klar punktet
Bbei bedarf kann ich gern die kompletten Files meines Testprojektes
einstellen aber das wesentliche ist wohl schon zusehen.
> CVAVR hält sich trotzt Optimierung an die> vorgegebenen zeitlichen Abläufe
Kunststück. Nach diesem Code zu schliessen, ist dessen Optimierung in
den 80ern stecken geblieben. Erstens ergibt sich aus dem Code, dass
Parameter immer im Speicher übergeben werden, was bei einer derart
registerorientierten CPU ziemlicher Unfug ist. Zweitens kommt dabei
ungefähr das heraus, was GCC bei "volatile var" erzeugt.
PS: In anderen Worten: Ein schlecht optimierender Compiler wird folglich
deinen Vorstellungen eher entsprechen als ein gut optimierender. Weil er
ziemlich schematisch vorgeht und nicht umordnet. Bei Mikrocontrollern
mag das eben deshalb sogar tatsächlich von Vorteil sein. Nur sollte man
dann eben nicht über mangelnde Optimierung meckern.
nun,
an dem Code gibt es nicht viel zu optimieren und GCC scheint einfaches
eher zu "verschlimmbessern"
Jedenfalls weis ich hier was passiert und vermag mich darauf
einzustellen.
Ich weiß nicht warum, aber ich mag es nicht wenn ein Programm seine
Interessen über die Meinen hängt.
Habe die Diskussion aus Interesse mal verfolgt und bin mir jetzt sicher:
mein Umstieg zu C ist endgültig abgewählt, ich bleibe bei ASM, da weiss
ich was passiert, wenn CLI steht, wird auch CLI ausgeführt ...basta, und
ich bekomm nicht irgendwelche Befehle untergemogelt, die unnötig sind,
nur um den Flash vollzubekommen.
Wenn da schon Profis wie Peter D. bei bestimmten Sachen das Handtuch
werfen, dann hab ich wahrscheinlich mein erstes C-programm erst zur
Rente am laufen (und bis dahin sind es noch paar Jahre).
> ich bleibe bei ASM
Wenn du das kannst und so viel Zeit hast, das alles zu debuggen und
noch zu pflegen: nur zu.
Bei mir war damit vor ca. 15 Jahren finito. Das Leben ist einfach zu
kurz dafür. Der letzte ernsthafte Versuch war es damals, einem alten
robotron-Stiftplotter eine neue Firmware zu verpassen, damit er
richtiges HPGL kann statt des robotron-Verschnitts. Das Projekt ist
nie geworden, die Zeit reichte hinten und vorn nicht dafür.
Dann nochmal ein Aufflammen, als ich mich Ende 2000 nach ca. 10jähriger
Abstinenz mal mit einigermaßen aktuellen Controllern beschäftigen wollte
und einfach gerade zu einen PIC gegriffen habe. Das vergleichsweise
wirklich kleine Projekt hat so lange zum Debuggen gebraucht, dass der
Entschluss fest stand, dass mein nächster Controller einer ist, für den
es eine Hochsprache gibt. Da ich mit Windows nichts am Hut habe und
alles auf Unix laufen können musste, blieb praktisch nur ein Controller
übrig, für den es einen GCC-Port gab, und auf diese Weise bin ich zu
den AVRs gekommen.
>mein Umstieg zu C ist endgültig abgewählt, ich bleibe bei ASM
Warum meinen eigentlich viele dass C eine "Fortsetzung" von ASM ist, und
alles was mit ASM geht auch in C geht ? Das gleiche gilt für C / C++,
Opel / VW, Blond / Brunette, Äpfel / Birnen, etc.
Wenn du nur Projekte machst die in ASM besser realisierbar sind, fein.
Für mich sieht's zwar so aus als ob du krampfhaft nach einem Grund
suchst nicht auch noch C zu lernen, aber das ist nun eine rein
subjektive boshafte Unterstellung.
Bei mir ist es fast umgekehrt: Ich kann (leider) kein ASM, aber bei
manchen Projekten habe ich mir schon gesagt, man, das wäre in ASM gerade
einfach besser. Nun könnte ich einerseits sagen ASM lerne ich nicht,
weil mit C ja eh alles viel besser ist, oder ich könnte einfach sagen:
Entweder ASM lernen oder "einfach mal die Fresse halten" (Zitat Ende)
P.S.
Warum gibt's eigentlich Toastbrot ? Laugenbrötchen schmecken doch viel
besser!
@Jörg
Wenn man sich die Zeit nimmt, solltest Du lieber schreiben.
Ich habe 1980 auch ein Z80-System gelötet (fädeln mit ROM, D-RAM und
Peripherie) und anschließend in Assembler programmiert, da ein
C-Compiler zu teuer war und man sich die Zeit genommen hat.
Nachdem ich die kleinen MCU’s entdeckt hatte, die keine solchen
Ansprüche wie ein Z80 stellen, habe ich zu Begin auch nur Assembler
programmiert. Stellt man dann aber fest, das sich der Prozessor nur in
Warteschleifen befindet, will man mehr. Eine Ausgabe mit Hilfe einer LED
reicht nicht, es muss dann schon ein LCD- oder gar TFT-Display und Menue
gesteuert sein, was natürlich nicht mehr oder nur mit großem Aufwand in
Assembler erledigt werden kann. Bis man dann irgendwann feststellt, das
man eigentlich nur Funktionalitäten in einer MCU reinbaut, die
eigentlich nicht gerade sinnvoll oder schon in anderer Form billiger und
fertig zu haben sind.
Hat man aber Zeitkritische Dinge zu verrichten, macht eigentlich
Assembler schon Sinn, wenn man sich nicht auf die angegebenen Zeilen
bzw. die Reihenfolge der Abarbeitung in C verlassen kann.
Ich kann nicht nachvollziehen, warum mich ein Compiler/Linker nicht
fragt, ob die Zeilen wichtig sind oder wegoptimiert werden können.
Warum fragt mich der Compiler/Linker nicht, ob ich Wert auf die
Reihenfolge der Befehle lege, so wie ich es geschrieben habe, oder Der
Compiler/Linker die Blöcke optimieren darf.
Warum arbeitet ein solcher Compiler/Linker immer im Stillen?
Warum muss ich nach 2 Jahren meine Programme überarbeiten, da sich die
Funktionen und Libraries geändert haben und sich keine meiner Programme
mehr ohne Fehlermeldungen und Compiler/Linker-Abbrüche übersetzen lässt?
In ASM habe ich solche Probleme eigentlich nicht!
@Peter
Dem Peter möchte ich noch danken, das dieser Fehler hier bekannt wurde.
Daraufhin habe ich bei mir nachgeschaut und mein Fehler beim EEPROM
schreiben gefunden. Ich bin auch diesem Problem/Fehler aufgesessen.
Hi,
Excuse for my english, i can't write in german, so i think that a simple
aproach can be taken, a memory barrier, that is:
void test( unsigned int val )
{
val = 65535U / val;
_asm__ __volatile_ ( "" : : "memory" (val));
cli();
ivar = val;
sei();
}
This will tell gcc thet you need the val at this point, so it will make
it avaliable before the cli(), it's a little work arround that can be a
macro to bariier any memory var, :) :
void test( unsigned int val )
{
182: bc 01 movw r22, r24
val = 65535U / val;
184: 8f ef ldi r24, 0xFF ; 255
186: 9f ef ldi r25, 0xFF ; 255
188: 0e 94 4e 01 call 0x29c ; 0x29c <__udivmodhi4>
_asm__ __volatile_ ( "" : : "memory" (val));
cli();
18c: f8 94 cli
ivar = val;
18e: 70 93 25 02 sts 0x0225, r23
192: 60 93 24 02 sts 0x0224, r22
sei();
196: 78 94 sei
}
198: 08 95 ret