Hi!
Ich entwicklere gerade einen einfachen Prozessor in VHDL.
Ich habe ein Development Kit mit Stratix II von Altera und nutze Quartus
II 7.1 Webedititon.
Ich bin gerade bei meiner Alu und bin erstaunt, dass Quartus mir eine
maximalen Takt (fmax) von nur 17MHz angibt.
Der Addierer geht laut Quartus nur bis 24Mhz. Dabei habe ich einen 16Bit
Carry-Look-Ahead-Addierer implementiert.
Mich erstaunt, dass der Addierer nur so wenige LEs benötigt. Selbst wenn
ich den Addierer auf 64Bit aufstocke, steigt der Verbrauch der LEs nur
linear an (96 ALUTs f. 64Bit CLA-Addierer?).
Das kann doch nicht sein!
Der CLA-Addierer dürfte bei 64Bit doch extrem aufwändig sein...
Ich habe meinen Code jetzt nicht zur Hand (bin mom. nicht zu Hause),
aber die CLA-Addierer von Altera
(http://www.altera.com/support/examples/vhdl/v_cl_addr.html) ist sehr
ähnlich und zeigt das gleiche Verhalten:
Mit der lpm_add_sub Megafunction erreiche ich ein fmax von weit über
100Mhz.
Ich möchte aber keine Megafunction nutzen, da ich alles selber machen
möchte.
Warum ist der Addierer nun so langsam und braucht so wenige LEs?
Vielleicht optimiert Quartus die CLA-Architektur so um, dass ein
Carry-Ripple-Addierer rauskommt?
Sascha wrote:
> Vielleicht optimiert Quartus die CLA-Architektur so um, dass ein> Carry-Ripple-Addierer rauskommt?
Das könntest du doch rausfinden indem du dir den synthetisierten
Schaltplan anschaust (vorausgesetzt sowas gibt es auch bei Quartus)?
Mich wundert, dass carry_in_internal sich so lange durch-rippelt,
carry_in_internal(i+1) <= carry_generate(i) OR (carry_propagate(i) AND
carry_in_internal(i)) da müssen doch erst alle 5
carry_in_internal(1..6)-Bits nacheinander berechnet sein, bevor
carry_in_internal(7) steht.
hier ist nur ein 3Bit-CLA-Addierer gezeigt, aber da gibts keine so
langen Gatterlaufzeiten:
http://de.wikipedia.org/wiki/Paralleladdierer_mit_%C3%9Cbertragsvorausberechnung
Es wird auch nicht schneller zu implementieren sein. Der längte Pfad ist
einfach zu lang. (wundert mich ein bisschen)
Du kannst ja einfach "+" schreiben ;-) Altera macht das schon :-)
Oder Du kannst alles getacktet machen, dann hast Du zwar einen Delay bis
das Resultat fertig ist, dafür kannst du sicher bis über 200 MHz takten
(lange pipeline)
Gruß,
Kest
Ich habe meinen CLA-Addierer nach diesem Dokument gebaut:
http://www.informatik.uni-ulm.de/ni/Lehre/SS05/CompArith/ArithIntegerB2.pdf
Ich habe die Carry-Signale habe ich nach folgender Formel berechnet:
G(i) = a(i) and b(i)
P(i) = a(i) xor b(i)
c(0) = carry_eingang
c(i+1) = G(i) + P(i)c(i)
Summe s(i) = c(i) xor P(i)
Mein VHDL-Code (den ich geschrieben habe, bavor ich den Code oben von
Altera gefunden habe) ist ebenfalls so "langsam".
Wo liegt der Fehler?
Sind die Gleichungen falsch oder optimiert Quartus da was weg?
>Es wird auch nicht schneller zu implementieren sein. Der längte Pfad ist>einfach zu lang. (wundert mich ein bisschen)
Der Vorteil eines CLA-Addierers soll ja gerade sein, dass alle Pfade
gleich lang sind.
Allerdings werden pro weiterem Bit immer mehr Gatter benötigt, so dass
sich die Schaltung ab einer bestimmten Busbreite sich nicht mehr lohnt
(siehe:
http://www.informatik.uni-ulm.de/ni/Lehre/SS05/CompArith/ArithIntegerB2.pdf)
Hallo Sascha,
Du schreibst VHDL im Jahre 2007. Warum geht nicht einfach
Y <= A + B; -- so wie es Kest vorgeschlagen hat?
Quartus wird das optimal implementieren, da bin ich sicher.
Bei Deinem Prozessor gibt es sicher ganz andere Stellen wo
Du Gehirnschmalz reinstecken kannst um z.B. Speed zu optimieren,
aber doch nicht beim Addierer?!?!
c(i+1) kann nach deiner Methode erst stimmen, wenn c(i) steht, und das
hängt wieder vom Vorgänger ab, also eine typische ripple-Situation.
Die im Skript gezeigten Gleichungen erzeugen alles parallel, nicht
nacheinander. Deshalb auch die Aussage, dass es zu groß
wird, und eine "Lösung: Kombination von CLA und Carry-Ripple Addierer"
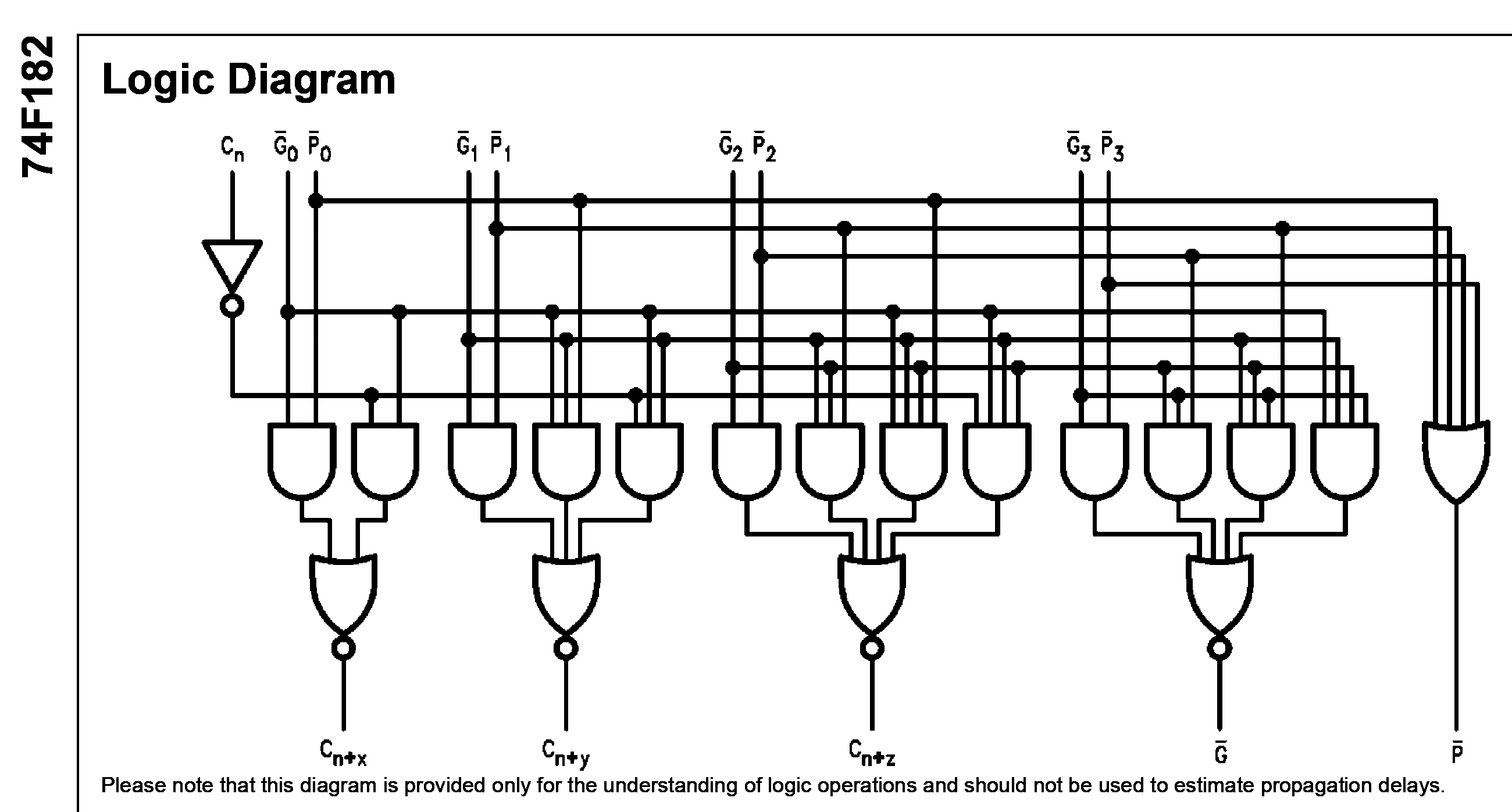
aus Seite 2. Genauso war der 74F182 gedacht, jedes 4. Carry wird
schneller erzeugt, dazwischen per ripple-carry
>c(i+1) kann nach deiner Methode erst stimmen, wenn c(i) steht, und das>hängt wieder vom Vorgänger ab, also eine typische ripple-Situation.>Die im Skript gezeigten Gleichungen erzeugen alles parallel, nicht>nacheinander.
Die Gleichung stammt aus dem Skript (2. Zeile).
Dann stimmt also der Code von Altera auch nicht...
Ich habe nochmal nur den CLA-Addierer compiliert. Alle Ein- und Ausgge
auch zu realen I/Os assigned, so dass er nichts wegoptimieren kann.
Dann erreiche ich eine Fmax nur für den CLA-Addierer von 34MHz
Dann habe ich noch einen 64 Bit Carry-Ripple-Addierer implementiert und
ich erreiche dann eine Fmax von 80MHz!
Seltsam!
>Du schreibst VHDL im Jahre 2007. Warum geht nicht einfach>Y <= A + B; -- so wie es Kest vorgeschlagen hat?
Das geht leider nicht, da dies ein Studienprojekt ist.
Zwei Leute schreiben eine CPU nach strengen Vorgaben in VHDL.
Einer (das bin ich) baut alles auf Logikebene auf. ieee.numeric_Std darf
ich z.B. nicht verwenden.
Der andere benutzt vorwiegend fertige Funktionen (aber keine speziellen
Megacores der Hersteller).
Beide CPUs sollen dann vergliechen werden.
Nun möchte ich natürlich eine möglichst flinke CPU hinbekommen!
Ich werde vielleicht mal bei Altera anfragen. Schliesslich ist da deren
Code...
Hallo Sascha,
hmm, immer diese Studienprojekte... Da hast Du grade den schwierigeren
Teil erwischt.
Es ist ja auch gar nicht so einfach, die erreichbare Geschwindigkeit zu
messen. Habt ihr dafür eine einheitliche Methode vereinbart?
Entscheidend ist der Wert des Timing-Analyzers NACH dem Place&Route,
alles
andere ist theoretisch.
Ich würde dafür den Adder zwischen Register packen und die max.
Taktfrequenz ermitteln. Das lustige dabei ist, wenn Du kein
Timing-Constraint vorgibst wird Quartus wahrscheinlich nicht den max.
Wert rausgeben. Dann gibts ja noch diverse "Schrauben" mit denen Du
Quartus zur Optimierung zwingen kannst.
Alles in allem ein komplexes Thema, wo schnell Äpfel mit Birnen
verglichen werden. Hoffe das der Betreuer mehrjährige praktische
Erfahrungen im FPGA-Design hat und die Probleme kennt. Sonst wird das
ganze wertlos.
Hallo Mark,
der betreuer ist dipl. Informatiker und ist das seit einem halben Jahr.
Die mehrjähige Erfahrung gibt es leider nicht.
Ich weiss, dass es nicht einfach ist. Leider ist auch immer nicht alles
perfekt.
Nur muss ich nun einige Vorgaben erfüllen, damit ich meinen Projekt
schein bekomme. Und das ist nunmal mein primäres Ziel.
Im Skript ist gleich darunter diese serielle Berechnung in eine
parallele umgeformt "alle Signale ci lassen sich in der Zeit 3 tau
bestimmen", die ci sind nur noch Ergebnisse links vom
Gleichheitszeichen.
Ich hatte hier mal meinen ersten DDS mit TTL-16bit-Volladdierer gezeigt:
Beitrag "Frequenzerzeugung ohne DDS Overkill??"
der benutzt(wenn der 74F182 bestückt wäre) das Verfahren das im Skript
als "n-bit BCLA" beschrieben ist, also vier 4 Bit Volladdierer mit
ripple carry 74F382 und ein lookahead carry generator 74F182, der gerade
diese vier versorgen kann.
Kann das sein, dass Quartus bei einem 64-bit-addierer ein fertiges Modul
innerhalb des FPGA wählt, was er bei dem anderen einfach nicht macht?
Ein blick ins datenblatt dürfte Klarheit bringen.
Frank
Der Code ist so einfach falsch für einen CLA-Addierer.
Der Trick dabei ist ja gerade dass man nicht das letzte Carry benutzt
(also Ci) sondern das Ci in Gi + PCi-1 auflöst, und zwar so lange bis
man beim Cin angekommen ist.
Wenn alles fertig aufgelöst ist, hat man nurnoch Gs und Ps und das Cin.
Somit muss man nicht auf die Ci warten, sondern berechnet direkt aus den
Eingängen sein eigenes Ci parallel.
Bsp:
C0 = G0 + P0.Cin
C1 = G1 + P1.C0 = G1 + P1.(G0 + P0.Cin) = G1 + P1.G0 + P1.P0.Cin
C2 = G2 + P2.C1 = ...
Das Endergebnis kann man auch kurz als zB
C1 = (G1 + P1.G0) + (P1.P0).Cin
= G1:0 + P1:0.Cin
schreiben.
(Ist in manchen Büchern so)
Prinzipiell gibt es dann verschiedene Möglichkeiten das zu organisieren
(Suche zB nach Kogge-Stone)
Wie man das am Besten in VHDL schreibt bin ich mir unsicher.
Weil wie kannst Du sicherstellen, dass er das so auflöst wie Du willst ?
Und vor allem soll das ja parallel ablaufen dann, also process mit for
halte ich für schlecht.
Alles per Hand aufzulösen wäre eine Möglichkeit,
vielleicht mit einer VHDL entity für die Gleichung Ci = Gi + PiCi-1 ?
Allerdings wird das keine schöne Arbeit...
oder vielleicht eine VHDL function ?
Hmm wenn ich mirs recht überlege dürfte das für eine richtige
Architektur wie den Kogge-Stone vielleicht noch gehen. Ich hab das mal
für 16bit gemacht, allerdings als ASIC.
Schau mal hier: (leider etwas theoretisch)
http://www.acsel-lab.com/Projects/fast_adder/references/papers/Knowles-family_of_add.pdf
oder vielleicht findest Du ja auch ein gutes Buch über
Computer-Arithmetik
oder hier:
http://bwrc.eecs.berkeley.edu/IcBook/Slides/chapter11.ppt