Hi, wenn ich Fixed-Point-Format auf meine Daten anwende, geht meine Genauigkeit bezueglich meiner Referenzwerte verloren. Ich habe eine Fehlerrate von 4%. Wenn die Zahl klein ist, springt die Fehlerrate sogar auf 28%. Das ist leider zu gross. An welchen Parametern kann man drehen, damit die Genauigkeit erhalten bleibt? Inputsample ist 12 Bit und die FIR-Koeffizienten konvertiere ich von double ins Fixed-Point-Format mit 2^18 Linksverschiebung. Die ganze Rechnung ist: (Filterkoeffizienten mal Inputsamples) + vorhergendes Ergebnis Danke fuer Ideen!
Wo geht die Genauigkeit verloren? Ganz am Anfang bei der Quantisierung der Daten? Da hilft es nur den Wertebereich stärker auszusteuern oder wenn das nicht reicht die Wortlänge zu vergrößern.
>>An welchen Parametern kann man drehen, damit die Genauigkeit erhalten >>bleibt? Dein FIR Filter berechnet ja ne Summe von Produkten. Du normierst die 18 Bit nicht nach jeder Multiplikation zurück sondern summierst die genauen Ergebnisse auf und wenn Du mit allen Summanden fertig bist schiebst Du das Ergebnis 18Bit nach rechts. Vorsicht, Vorsicht: pro Addition kommt ein Bit dazu. Für 12Bit Inputbreite und 18Bit Koeffs ist das Ergebnis 30Bit. Von diesen Produkten darf man nur zwei addieren wenn man mit 32 Bit breiten Worten arbeitet. Wenn Du für dein FIR Filter mehr Koeffizieneten benötigst muß Du mit geringeren Koeffizientenbitbreiten als 18 arbeiten. Cheers Detlef
Überläufe im Akkumulator stören nicht, solange das Endergebnis im darstellbaren Bereich bleibt. Je nachdem welche Wahrscheinlichkeit für einen Überlauf im Endergebnis du dir leisten willst kann also auch ein kürzerer Akkumulator ausreichen.
Damit können eingangsdatenabhängig Overflows auftreten. Bei Audio bewirkt das Knacken und Zerren, bei anderen Signalen ebenfalls und das ist darüberhinaus auch noch schwierig zu finden. Ich würde kein design raushauen, in dem Overflows nicht ausgeschlossen sind, egal was für Daten reinkommen. Cheers Detlef
Angehängte Dateien:
-

data.JPG
22 KB
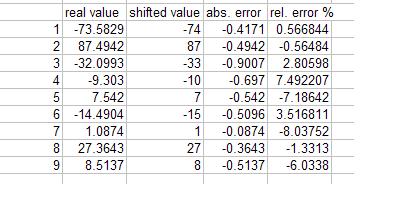
Guten Morgen Freunde, danke fuer die Rueckmeldung. Ich habe folgendes gemacht sowie ihr das empfohlen habt: - Geringere Koeffizientenbitbreite genommen (15-bit) - Erst multipliziert und addiert, und danach das Ergebnis um 15 nach rechts verschoben. Die Ergebnisse habe ich angehaengt. Die Fehlerrate koennt ihr da sehen. Bei kleinen Werten ist der Fehler sehr gross. Was kann ich noch machen? Danke im Voraus!
Die zu sehenden Fehler sind einfach die Fehler durch Truncation. Was da als shifted value herauskommt, sind die gleichen Werte, die du erhältst, wenn du die Float-Werte "truncatest" ohne zu Runden. Du könntest vor dem Shiften noch einen der 0.5 entspr. Wert addieren, um zu runden. Aber der Fehler wird nicht mehr deutlich kleiner, weil zuviel abgeschnitten wird. Lösung wäre z.B. mehr verbleibende Genauigkeit (Wer sagt denn, dass da, wo ein Komma ist, abgeschnitten werden muss? Kann auch paar Stellen weiter hinter dem Komma passieren) Oder du ditherst die Ergebnisse (z.B. per Rauschen mit Gaussverteilung auf die Werte legen u. dann abschneiden u. mehrere Werte pro Sample mit dem Rauschen erzeugen)
Hi, <Die zu sehenden Fehler sind einfach die Fehler durch Truncation. Was da <als shifted value herauskommt, sind die gleichen Werte, die du erhältst, <wenn du die Float-Werte "truncatest" ohne zu Runden. Du könntest vor dem <Shiften noch einen der 0.5 entspr. Wert addieren, um zu runden. Aber der <Fehler wird nicht mehr deutlich kleiner, weil zuviel abgeschnitten wird. Ja, das stimmt. Ich hatte die geshifteten Koeffizienten gerundet. <Lösung wäre z.B. mehr verbleibende Genauigkeit (Wer sagt denn, dass da, <wo ein Komma ist, abgeschnitten werden muss? Kann auch paar Stellen <weiter hinter dem Komma passieren) Heisst das, vor dem Shiften erst mit z.B. 100 multiplizieren und dann shiften. Einfach die Kommastelle verschieben. Das Ergebnis backshiften und durch 100 dividieren. Meinst du sowas? <Oder du ditherst die Ergebnisse (z.B. per Rauschen mit Gaussverteilung <auf die Werte legen u. dann abschneiden u. mehrere Werte pro Sample mit <dem Rauschen erzeugen) Diese Methode kenn ich nicht :-( Kannst du mir das bitte besser erklaeren? Danke!
Detlef: Kommt drauf an. Man muss die Wahrscheinlichkeit eines Overflows gegen den SNR-Gewinn durch stärkere Aussteuerung abwiegen. Wenn man dauerhaft ein paar dB gewinnt indem man weiter aussteuert, dann kann es sich schon lohnen dafür einen Überlauf zu riskieren der durchschnittlich einmal im Jahr auftritt. Um Überläufe komplett auszuschließen muss der Akkumulator so breit sein wie die Summe der Beträge der Impulsantwort (l1-Norm), das können bei 4 Koeffizienten und 12x18 Bit auch weniger als 32 Bit sein.
Andreas Schwarz wrote: > Um Überläufe komplett auszuschließen muss der Akkumulator so breit sein > wie die Summe der Beträge der Impulsantwort (l1-Norm), das können bei 4 > Koeffizienten und 12x18 Bit auch weniger als 32 Bit sein. Das ist rchtig und vielleicht auch ne Lösung für DSPNeuling. Die Summe der Beträge aller 'real-values' ist 261.xx, also 9 Bit. Bei 12Bit Eingangsdaten hast Du also noch 31-9-12=10Bit Luft, Du kannst die 'real-values' also noch um Faktor 1024 aufblasen, ohne daß was überläuft. Die Addition von 0.5 vor dem Abschneiden ist gut, sonst kommt nen systematischer bias rein. Die Koeffizienten scheinen mir bißchen merkwürdig, so unterschiedlich in der Größenordnung. Wo kommen die denn her? Es gibt spezielle Entwurfsverfahren für FIR-Filter, die darauf Rücksicht nehmen, daß man die integer Koeffizienten abschneiden muß. Das bedeutet, daß man in der z-Ebene auf diskrete Plätze festgenagelt ist. Cheers Detlef
Hi nochmal, oh, ich sehe da ist ein Missverstaendnis in meinem Anhang. Was ich mit der Spalte "real values" meine, ist, ihr seht Ergebnisse aus der Multiplikation und Addition: FIR*Inputsample + prevResult Meine FIR-Coeffs: a1= -0.0106 = -347 A2= 0.0329 = 1078 A3= 0.0308 = 1009 A4=-0.1870 = -6128 A5=-0.0280 = -918 A6=0.6309 = 20673 A7=0.7148 = 23423 A8=0.2304 = 7550 Es sind insgesamt 8 Koeffizienten. Auf der rechten Seite sind die um 15-bit geshifteten Koeffizienten. Ich multipliziere diese mit Inputsamples. Im Anhang, die Spalte "real-values" ist das Ergebnis ohne das Shiften der Koeffizienten. Die Spalte "shifted value" ist das Ergebnis der geshifteten Koeffizienten. Ich hoffe, dieses Mal war das verstaendlich. Sorry. >Das ist rchtig und vielleicht auch ne Lösung für DSPNeuling. Die Summe >der Beträge aller 'real-values' ist 261.xx, also 9 Bit. Bei 12Bit >Eingangsdaten hast Du also noch 31-9-12=10Bit Luft, Du kannst die >'real-values' also noch um Faktor 1024 aufblasen, ohne daß was >überläuft. Ich habe einen Spielraum von 32-bit auf dem DSP-Chip. >Die Addition von 0.5 vor dem Abschneiden ist gut, sonst kommt nen >systematischer bias rein. Aber warum Addition? Das verfaelscht den Wert oder? Wenn ich z.B. 11.3 habe und 0.5 dazuaddiere, kommt ja 11.8 raus. Wenn ich das aufrunde, ist das schon 12. Ich habe die geschifteten Koeffizientenwerte einfach gerundet, ohne etwas dazuzuaddieren. Ist das falsch? Danke fuer eure Hilfe. Die Betreuung von euch ist echt super!!!
Deine Koeff. benutzen den vorhandenen Zahlenbereich gut, sind allerdings
Faktor 100 auseinander. Falls die Genauigkeit nicht reicht, sollte das
mit integer schwierig werden. Ich weiß allerdings auch nicht, welche
Genauigkeitsanforderungen Du hast, 32 Bit sind immerhin mehr als 180dB
Dynamikumfang.
>>Ist das falsch?
Nein, das ist richtig. Nicht: 0.5 addieren und dann runden sondern:
runden, indam man 0.5 addiert und dann abschneidet,
Cheers
Detlef
Ich würde zuerst einmal von den gerundeten Koeffizienten auf den Frequenzgang zurückrechnen. Wenn der nicht im akzeptablen Rahmen liegt helfen mehr Bit für Daten und Endergebnis auch nichts mehr.
Hi, also ich habe folgendes gemacht: -einmal die Werte um 15 geshiftet -einmal um 18 Das Shiften um 18 hat nichts gebracht. Die Ergebnisse im Vergleich mit den Ergebnissen um 15 waren sogar schlechter in unteren Frequenzbaendern. Also habe ich das bei 15-bit gelassen. Mehr faellt mir auch ncihts ein. Jetzt muss ich eine Standardabweichung berechnen um die Haueufigkeit der Fehler zu berechnen. Ich danke euch ganz herzlich fuer eure Hilfe! Ich habe eine Frage aus Neugier: Wie kann ich die dBs rechnen? Ich weiss nicht, wie Detlef auf die 180 dBs kommt :-(
~ 6db/Bit (genau: 20*log10(2)). Wenn Du mit n Bits k-Volt darstellen kannst, kannst Du mit n+1 Bit 2*k Volt darstellen, also doppelt soviel: 20*log10(2). 20*log10(2^32) ~ 180 Cheers Detlef
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.