Hallo beisammen,
Ich benutze Microsoft's Active-X ADO per C um Daten in eine Datenbank zu
klopfen. Die Daten liegen in meinem Programm als zwei Double-Arrays vor.
Im Zuge der Konvertierung in einen INSERT - String laufe ich über die
Arrays in einer for-Schleife und füge an einen C-String (Char-Array) die
jeweiligen nach double konvertierten Strings an.
Anschließend wird der String per .execute an die ADO übergeben.
Der Aufruf des .execute Befehls geht dabei erstaunlich flott, selbst bei
sehr (!) langen Strings.
Das Zusammenbasteln des SQL-Strings selbst per sprintf() geht dabei
allerdings gähnend langsam von statten.
Pseudo-Code:
String: INSERT INTO ... (x,y,z) VALUES (xx,yy,zz), (xxx, yyy, zzz), ...
Bei 7 Tausend Punkten dauert das Zusammenkopieren etwa 3 Sekunden, das
Übergeben an die ADO dauert etwa 200 ms.
Die Funktion Zeit/Datenpunkte ist leider auch nicht linear, habe den
Eindruck das geht annähernd quadratisch.
Hat jemand nen besseren Vorschlag?
Schönen Abend beisammen!
Franz
Wenn ich es mir richtig überlege, wird dabei bei jedem
Schleifendurchlauf der String sqlstring umkopiert. Im normalfall wird es
ja kaum möglich sein, den anzuhängenden String direkt an das Ende des
bestehenden Strings zu setzen. (Im Speicher.) So muss für den ganzen
String ein Platz im Speicher gefunden werden, wo er in seiner vollen
Länge Platz hat. Das kann schon ein bisschen dauern.
Besser wäre es, wenn du bereits am Anfang genügend Speicher für den
sqlstring reservierst und bufferstring danach manuell dort reinkopierst.
Dein Problem ist nicht der sprintf.
Dein Problem ist der strcat.
Dies deshalb weil er bei jedem Aufruf erst mal aufwändig
das Ende des bereits vorhandenen Strings suchen muss.
(Und das führt dann tatsächlich zu einer quadratischen
Komplexität)
Wenn du daher selbst mitzählst, bis wohin sqlstring bereits
gefüllt ist, und diese Startadresse dem strcat übergibst, dann
kannst du masenhaft Suchzeit einsparen.
mr.chip wrote:
> String ein Platz im Speicher gefunden werden, wo er in seiner vollen> Länge Platz hat. Das kann schon ein bisschen dauern.
Du hast aber schon gesehen, dass hier in C und nicht in C++
programmiert wird?
>> Besser wäre es, wenn du bereits am Anfang genügend Speicher für den> sqlstring reservierst und bufferstring danach manuell dort reinkopierst.
Genau das macht er.
Danke für den Tipp mit den Pointer-Zugriffen (Pointer auf den String).
Das stimmt aber, daran hatte ich nicht gedacht, dass strcat erst mal
durchnudelt und kuckt wo "\0" kommt. Das werde ich gleich am Montag
probieren!
Frage: Tritt hier wieder ein typisches +-1-Problem auf? Also sprintf
schließt den bufferstring mit "\0" ab. Zählt strlen() dann die letzte
"\0" mit? Nicht dass strcat dann keine "\0" findet, da meckert es sonst.
----------------------------------
Mal abgesehen von der Lösung von oben (es ärgert mich dass ich da nicht
selbst drauf gekommen bin) - hat jemand ne Idee wie man (auf andere Art
und Weise) schnell und effektiv SQL-Strings zusammenbasteln kann?!
Die ADO-Funktionen möchte ich aufgrund ihrer Komplexität (.AddNew,
.Update) nicht verwenden, da das Runterbrechen der Objektorientierung
nach ANSI-C ein Riesenaufwand ist.
Danke - Franz
So rein gefühlsmäßig würde ich sagen, das liegt nicht nur an strcat:
- Ordentlich optimierter Code führt den Scan auf einem x86 im
wesentlichen in einem Maschinenbefehl aus; die String-Kopie genauso.
- Der Code für *printf und ftoa & Co. ist wesentlich komplexer, als
strcat.
Miß mal die Zeiten, die von beiden Routinen insgesamt gebraucht werden.
Bin auf das Ergebnis gespannt.
Uhu Uhuhu wrote:
> So rein gefühlsmäßig würde ich sagen, das liegt nicht nur an strcat:>> - Ordentlich optimierter Code führt den Scan auf einem x86 im> wesentlichen in einem Maschinenbefehl aus; die String-Kopie genauso.
Das ändert nichts daran, das die Laufzeit quadratisch wächst.
Originalvariante z.B. jeweils 20 Zeichen hinzufügen:
strcat (suchen + kopieren): 0 + 20, 20 + 20, 40 + 20, 60 + 20, 80 + 20,
100 + 20, 120 + 20, ...
mit strlen 20 + 20, 20 + 20, 20 + 20, ...
Macht im letzteren Fall 7000 * (20 + 20) = 280000 Elementaroperationen
Die strcat Variante 7000 * 20 + 20 + 40 + 60 + 80 + ... + 6980 * 20
~490000000
Zu deinem Off-by-One-Problem:
Bsp 1: String: x = "" (leer), strlen(x) = 0; x + strlen(x) zeigt auf \0.
Bsp 2: String: x = "abc", strlen(x) = 3; x + strlen(x) zeigt immer noch
auf \0.
Man könnte es auch noch eleganter machen.
Wozu den sprintf zuerst in einen Buffer schreiben lassen,
nur um diesen dann zu kopieren.
1
voidcheck2(inta)
2
{
3
charbuffer[100];
4
char*start=total;
5
inti;
6
7
*start='\0';
8
9
for(i=0;i<a;i++)
10
{
11
sprintf(start,"%d,%d,",i,i);
12
start+=strlen(buffer);
13
}
14
}
Allerdings: Mein Compiler dürfte das geschnallt haben.
Am Timing ändert sich nichts zu der Umkopiervariante.
Was aber noch was gebracht hat:
Den Returnwert von sprintf zu benutzen, anstelle des strlen
Da hast du dich aber fein säuberlich um den Aufwand für
float-Konvertierung gedrückt ;-)
Das das strcat elegant ist und nichts kostet, habe ich nicht behauptet.
Ich vermute aber nach wie vor, daß der Löwenanteil der Zeit in Franz
Wudys Code in der Konvertierung verbraten wird.
Uhu Uhuhu wrote:
> Da hast du dich aber fein säuberlich um den Aufwand für> float-Konvertierung gedrückt ;-)
7000 float sprintf sind im Vergleich zu den Millionen
Umkopieraktionen und String-Ende-Such-Schleifen nicht
das Zeitbestimmende.
Ausserdem schlagen die sprintf in beiden Code-Teilen mit
dem gleichen Zeitbedarf zu Buche.
>> Das das strcat elegant ist und nichts kostet, habe ich nicht behauptet.> Ich vermute aber nach wie vor, daß der Löwenanteil der Zeit in Franz> Wudys Code in der Konvertierung verbraten wird.
Hast du ein Programm, mit dem du es beweisen kannst?
Niemand sagt, dass float-String Wandlung gratis kommt.
Aber dann erklär mir doch bitte mal wie Franz zu seiner
'gefühlten' quadratischen Komplexität kommt. Auf die Erklärung
bin ich schon neugierig.
Uhu Uhuhu wrote:
> Ich vermute aber nach wie vor, daß der Löwenanteil der Zeit in Franz> Wudys Code in der Konvertierung verbraten wird.
Halte ich für unwahrscheinlich.
Wenn der ADO- bzw Datenbank-Interpreter 21000 Floats in unter 200ms
Parsen kann, wird das sprintf für das ausgeben nicht soo viel länger
brauchen.
Bei mir brauchen übrigens 7000 sprintf-Aufrufe mit je drei Floats
zusammen 82000000 CPU-Instruktionen...
(glibc-sprintf, gcc-4.2, -O2)
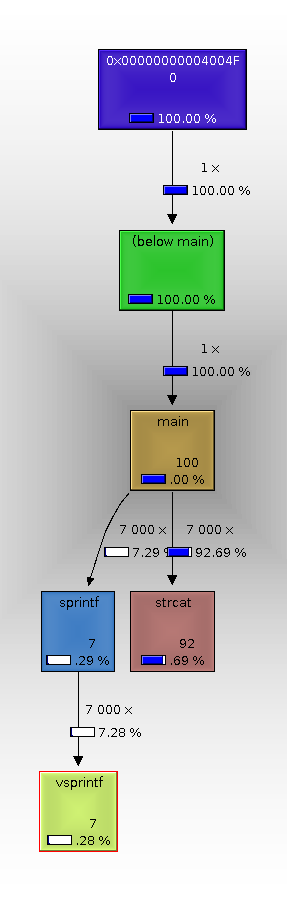
Bei der Schleife wie im Ursprungspost gehen bei mir 92.69% der Zeit für
strcat drauf, nur 7.29% für das sprintf.
(Im Anhang die wenig aussagekräftige Graphik dazu...)
/Ernst
Hallo beisammen,
danke für die vielen Antworten, wenngleich ich nicht eine derartig
hitzige Diskussion anfechten wollte.
Mir erscheint die Version
1
start+=sprintf(start,"%d,%d,",i,i);
sehr sinnvoll; und ich werde sie gleich morgen ausprobieren.
Dass sprintf nicht die schnellste Angelegenheit ist, ist klar.
Wenngleich es mir schon vorschwebte, dtostrf aus AVR zu transponieren,
die begründete Hoffnung dass der Löwenanteil auf strcat entfällt,
erspart mir (höchstwahrscheinlich) viel Zeit, da ich dieses Vorhaben nun
sein lassen kann.
Eine Frage noch, interessehalber: Wie macht man diesen schönen
Timing-Grafen?
Danke -
Franz
Franz Wudy wrote:
> Eine Frage noch, interessehalber: Wie macht man diesen schönen> Timing-Grafen?
Das wird irgendein Profiler sein.
Profiler: Programm welches ausmisst, wieviel Zeit in welchen
Programmteilen verbraucht wird.
http://de.wikipedia.org/wiki/Profiler_%28Programmierung%29
Bevor man sich an die Optimierung eines Programmes macht,
sollte man eigentlich immer einen Profiler zu Rate ziehen.
Menschen sind notorisch schlecht darin, durch Raten die
Bottlenecks in einem Programm aufzuspüren. Mit einem Profiler
hat man die Gewissheit sich um die richtigen 10% des Codes
zu kümmern.
Getreu dem Motto: 10% des Codes sind für 90% der Laufzeit
verantwortlich.
Japp. Es gibt/gab sogar Hardware-Profiler die direkt an der CPU
angeklemmt werden/wurden. Eine äüßerst geistreiche Firma wollte so mal
die Hardwareseite eines neu entwickelten Prozessor optimieren. Mittels
Profiler fand man heraus, dass dieser Prozessor die meiste Zeit immer
dieselbe Abfolge von vier Befehlen ausgeführt hat. Man dachte sich
also: "Mensch, da machen wir eine eigene Instruktion draus, dann läuft
die Kiste viermal so schnell."
Gesagt, getan. Nun hatte man also erfolgreich die Leerlauf-Schleife des
Prozessors optimiert.
JFYE :-)
> - Ordentlich optimierter Code führt den Scan auf einem x86 im> wesentlichen in einem Maschinenbefehl aus; die String-Kopie genauso.
Du meinst scas/movs/lods mit rep Präfix. Natürlich ist das nur ein
Befehl, dahinter verbirgt sich aber eine Schleife in Microcode. Wär ja
zu schön wenn die Komplexität von strlen() auf nem x86 O(1) wäre...
Nullterminierte Strings wie in C sind eigentlich so ziemlich die
dämlichste Art, um Zeichenketten zu repräsentieren. Vor einer Weile
hatten wir mal Probleme mit einer älteren Saftware, welche ziemlich
langsam war. Was haben wir (unter anderem) gefunden? Massenhaft solche
Schleifen:
1
for(size_ti=0;i<strlen(blah);++i){
2
}
Zuegegebenermassen ist obenstehender Code weitaus dämlicher als die Idee
von nullterminierten Strings. Mit einem STL-String kann man sowas
natürlich schon machen (Methode length()).
{kind=link}