Schönen guten Tag,
ich arbeite gerade aus Interesse an einem Programm welches später
ähnlich wie Singstar oder Ultrastar in quasi realtime die Stimmlage
eines Menschens über das Mikrofon analysieren soll.
Mein erster Ansatz ist über die Fourier Transformation das
Frequenzspektrum abzufragen. Allerdings habe ich nun ein Problem mit der
erkennung einer Tonhöhe. Über die Aufnahme durch ein Mikro wird
natürlich keine saubere Frequenz aufgenommen, so das ich da nicht so
recht weiß wie ich nun aus dem entwas unübersichtlichen Frequenzspektrum
eine Tonlage interpretieren kann. Gibt es da irgendwelche Filter oder
sonstige Ansätze die mir helfen könnten das zu verstehen?
/ Paul
Eine einfache Möglichkeit:
- Wähle die unterste Oktave in der du noch sinnvollen Gesang vermutest.
- Berechne die Frequenzen aller 12 Halbtöne
- Erstelle für jeden der Halbtöne einen Puffer mit der zur Frequenz
passenden Wellenlänge (sample rate / Frequenz)
- Schreibe das gesampelte Audio-Signal in den Puffer (einfach auf die
bestehenden Werte aufaddieren und am Ende umbrechen -> Ringpuffer)
- Berechne den Energiegehalt (Quadratsumme für jeden Buffer / Länge?)
- Der Buffer, der den höchsten Energiegehalt liefert wurde von der
Stimme am besten getroffen.
Das Verfahren ist recht simpel und erfüllt auf jeden Fall seinen Zweck.
Ein wenig Feinschliff ist aber dennoch nötig/sinnvoll (Tiefpass,
Downsampling, Gewichtungen).
Bildlich beschrieben versucht das Verfahren eine stehende Welle im
Buffer aufzubauen, was nur dann funktioniert, wenn die gesungene
Wellenlänge ein ganzzahliges Vielfaches der Bufferlänge ist. Auf diese
Weise werden auch die Obertöne des Grundtons mit bewertet und die Oktave
weitgehend ignoriert (macht Singstar ja auch).
Hoffe, das gibt dir schonmal ein paar Werkzeuge an die Hand.
Ich habe gelesen das Singstar ganz auf eine FT verzichtet, in Ultrastar
NG (native Linux C++ version) allerdings verwendet wird, was zu einer
genaueren Analyse und Darstellung führt. Verstehe ich das richtig das in
deinem beschriebenen Verfahren garnicht die Fourier Transformation
benötigt wird?
- Wähle die unterste Oktave in der du noch sinnvollen Gesang vermutest.
Gibt es da so etwas wie Richtwerte, oder ist die unterste Oktave vom
referenz-lied abhängig?
Gibt es einen Namen zu diesem Verfahren oder hast du vielleicht Links zu
Artikeln die das beschreiben?
Ich sehe hier keinen Sinn in einer Fourier-Analyse. Die Fourier-Analyse
ist geeignet, wenn man sich für das Obertonspektrum eines gegebenen
Grundtons interessiert (z.B. Stimmerkennung). Für deinen Anwendungsfall
ist aber nur die Ermittlung des Grundtons wichtig.
In welcher Oktave gesungen wird ist auch egal. Wenn du in einer unteren
Oktave suchst, werden die höheren Oktaven (als Obertöne) mit erfasst -
andersrum nicht.
>Gibt es da so etwas wie Richtwerte, oder ist die unterste Oktave vom>referenz-lied abhängig?
Ich komme mit meiner Stimme bis 37 Hz runter wenn ich mich rechterinnere
(mit dem o.g. Algorithmus gemessen) - verstehen tut man da aber nichts
mehr ;)
Sing einfach mal ein paar Lieder vor dich hin und schau, in welchen
Oktaven du dich normalerweise befindest. Ich denke, dass man hier
mindestens so viel ausprobieren wie berechnen muss.
>Gibt es einen Namen zu diesem Verfahren oder hast du vielleicht Links zu>Artikeln die das beschreiben?
Öhm... nenn es Grundtonermittlung nach Giebeler :) keine Ahnung, ob das
einen Namen hat.
Das ganze ließe sich auch mit 12 FIR-Filtern erreichen, was mathematisch
identisch, aber algorithmisch unnötig komplex wäre.
Du kannst auch mal nach BPM-Countern Ausschau halten, die müssen ein
sehr ähnliches Problem lösen... nur halt in einem anderen
Frequenzbereich.
Ich suche auch schon ein Weilchen nach einem schnellen Algorithmus um
den Grundton unabhängig von den festen Noten zu ermitteln - bis jetzt
habe ich das immer mit der Holzhammer-Methode gelöst.
Vielen Dank für Deine Ausführlichen Antworten!
Ich dachte eigentlich das ich das Prinzip verstanden habe, allerdings
bekomme ich bei meinen Tests nicht immer das gewünschte Ergebnis.
Ich schreibe mal auf wie ich konkret vorgehe, falls du einen Fehler
entdeckst wäre das super wenn du mir dabei helfen könntest :)
Zuerst generiere ich die Referenzbuffer. Dabei habe ich bei meinen Tests
als Oktave 32.7hz und nachher 65.41hz genommen. die anderen halbtöne
berechne ich mit der Formel
Wobei x der gewünschte Halbton ist.
Als nächstes addiere ich in einer Schleife die Daten meines Samples auf
die Referenzbuffer und errechne die Energie jedes einzelnen buffers:
refBuffer ist ein zweidimensionales array welches alle 12 generierten
referenzbuffer enthält.
pcmData beinhaltet einen Beispielframe meiner Testdateien
in tempData werden die ergebnise der Addition gespeichert
energy ist ein array welches die errechnete Energie für jeden
referenzfall speichert.
Nach meinem Verständnis ist das genau die Vorgehensweise die du
beschrieben hast, und es macht so auch Sinn denke ich ;) Allerdings
bekomme ich bei meinen Versuchen nicht immer eine Korrekte Lösung. Als
Eingabesignale benutze ich im Moment noch saubere generierte Frequenzen
z.B. 164.81Hz (E) und 146.83Hz (D)
Fällt dir oder sonst jemandem ein Fehler auf??
Ich verwende meist
f(i) = 440.0 * 2 ^ (i / 12)
was auch in etwa deiner Formel entspricht. i = 0 liefert damit den
Kammerton A'. Verwende mal 55.0 Hz oder 110.0 als untere Grenze. Ist
dann zwar ein A, aber sonst hat es nur Vorteile.
Ich hatte jetzt noch nicht allzu viel Zeit mir das anzusehen, aber ein
paar Sachen kommen mir komisch vor:
- Wo wird refBuffer befüllt?
- Wofür befüllst du tempData?
Der Ansatz scheint aber mit meiner Beschreibung übereinzustimmen.
Finde wahrscheinlich erst am Donnerstag wieder Zeit hier nochmal
reinzusehen, sorry.
Schöne Grüße
Kai
so gehts auch.
Die Wahl des Kammertons als Oktave hat leider nichts an den Ergebnissen
geändert.
Mir ist da eben noch was eingefallen was mich etwas stuzig gemacht hat..
Wie kann denn das verfahren eigentlich funktionieren wenn man ein
Eingabesignal hat, was aber phasenverschoben ist? Also wenn wir
Referenzsignale haben die nicht verschoben sind, aber das Eingangssignal
ist um 1/2 frequenz verschoben. Wie kann dann das Verfahren trotzdem
klappen?
- ton_a_220.00.wav - Nein -> gis + e - OK - Nein -> H
11
- ton_h_246.94.wav - Nein -> cis und fis - Nein - A - OK
12
- 440hz.wav - OK - Konflikt -> A und Dis - OK
Ich vermute die Ergebnise sind so wie sie sein sollen oder? Die
Frequenzen zwischen den Oktaven werden richtig erkannt, die anderen
nicht. Die frage ist dann allerdings, wie ich dann JEDEN denkbaren Ton
herausfinden kann, den ein Mensch singen könnte, ohne zu wissen in
welchem Frequenzbereich gesungen wird? Muss ich in dem Fall wirklich
referenz Buffer für alle denkbaren Oktaven erstellen?
>Muss ich in dem Fall wirklich>referenz Buffer für alle denkbaren Oktaven erstellen?
Nein, die 55 Hz-Oktave müsste bei dir bessere Treffer erzielen. Sofern
die Oktave korrekt gewählt ist und der Messintervall lang genug,
solltest du nahezu eine 100%-Quote erzielen.
Bei obertonreichen Klängen (wie z.B. der menschlichen Stimme) müsste
auch eine zu hoch gewählte Oktave noch brauchbare Ergebnisse liefern.
Beim Sinus werden die Ergebnisse nicht so gut. Sägezahn oder Rechteck
sollten als Testsignal besser geeignet sein, da sie ein Obertonspektrum
besitzen.
Eine Fensterung (z.B. mit f(x) = (1 + cos(x)) * 0.5 mit x := [-PI;+PI])
dürfte die Messung zusätzlich verbessern.
Zur Not schau dich noch mal bei anderen Verfahren um - ich habe im
Moment nicht so super viel Zeit und will dich damit nicht hängen lassen
:)
Ach ja, wenn's nicht wirklich genau sein muss: Tiefpassfiltern und
Nulldurchgänge zählen. Danach Taste Auf der Klaviatur zuordnen und
Ausreißer eliminieren.
Mh dann ist das in der Tat seltsam... bzw. ich müsste noch irgendwo
einen Fehler haben den ich übersehen habe. Denn wenn ich die Oktave bei
55hz wähle bekomme ich bei meinen Testfällen immer falsche Werte, es sei
denn sie liegen zwischen 55hz und 110 hz. Auch eine Sawtooth funktion
ändert daran nichts...
Ich will dich auch garnicht von deiner Arbeit abhalten, danke das du
trotzdem hilfst sofern das zeitlich geht :)
Wenn du das schonmal so in der Art implementiert hast, wäre es möglich
mir deinen source (bzw. relevanten teil) davon zur Verfügung zu stellen?
Vielleicht finde ich meinen Fehler ja dann noch selber.
>Mir ist da eben noch was eingefallen was mich etwas stuzig gemacht hat..>Wie kann denn das verfahren eigentlich funktionieren wenn man ein>Eingabesignal hat, was aber phasenverschoben ist? Also wenn wir>Referenzsignale haben die nicht verschoben sind, aber das Eingangssignal>ist um 1/2 frequenz verschoben. Wie kann dann das Verfahren trotzdem>klappen?
Keine Sorge, das geht :)
Wie gesagt wird im Buffer eine stehende Welle erzeugt. Welche Phase die
am Ende hat ist unbekannt, aber wir bestimmen ja eh nur den
Energiegehalt.
>Wenn du das schonmal so in der Art implementiert hast, wäre es möglich>mir deinen source (bzw. relevanten teil) davon zur Verfügung zu stellen?>Vielleicht finde ich meinen Fehler ja dann noch selber.
Leider nein - ich entwickle meine Algorithmen gerne in QuickBasic 4.0 -
kaum Overhead, einfach drauflostippen und immer noch recht fix. Leider
hat die Version meinen Quelltext gefressen (QB speichert per default
Binaries) :((
Ich schreib das nochmal in Java nach - die Visualisierung ist zwar
aufwändiger, aber dafür muss ich das danach nicht nochmal schreiben.
Reicht dir erstmal eine Implementierung mit float-Werten?
- Ich schreib das nochmal in Java nach - die Visualisierung ist zwar
- aufwändiger, aber dafür muss ich das danach nicht nochmal schreiben.
- Reicht dir erstmal eine Implementierung mit float-Werten?
Ja klar das reicht, es geht ja nur darum das ich dann hoffentlich
rausfinde was ich falsch mache ;) In andere Datentypen umwandeln sollte
dann das kleinste Problem sein.
Ist echt etwas deprimierend wenn man so nette Hilfe bekommt, die methode
auch noch versteht, aber dann irgendwas nicht klappt weil ich vermutlich
nen total banalen fehler gemacht habe ;) Naja... da muss man durch :)
Da fällt mir ein, ich könnte mich ja eigentlich auch mal hier
registrieren ;)
Aus Wikipedia (http://de.wikipedia.org/wiki/Menschliche_Stimme):
>Die Tonhöhe des Grundtons der menschlichen Stimme liegt für die männliche >Stimme
bei etwa 125 Hz, für die weibliche bei etwa 250 Hz. Kleine Kinder >haben eine
Tonlage um 440 Hz. Ursache dieser Unterschiede ist die >unterschiedliche Größe des
Kehlkopfes und damit der Länge der Stimmbänder. >Der Stimmumfang beträgt 1,3 - 2,5
Oktaven. Der Frequenzbereich der >menschlichen Stimme mit den Obertönen beträgt
etwa 80 Hz bis 12 kHz. In >diesem Frequenzgang befinden sich Frequenzabschnitte,
die für die >Sprachverständlichkeit, die Betonung der Vokale und Konsonanten sowie
>Brillanz und Wärme eine Rolle spielen.
110 Hz als Untergrenze wäre meiner Meinung nach ideal.
Bei einem Stimmumfang von 2,5 Oktaven erhalten wir 622 Hz als
Obergrenze. Also würde ich alles über 1 kHz per Tiefpass wegschneiden.
Um das Datenvolumen zu verringen kann man auch einfach downsamplen, aber
dadurch werden auch die Buffer kürzer. Wenn die zu kurz werden entstehen
erhebliche Fehler bei der Längenbestimmung und die Testfrequenzen werden
nicht mehr sauber getroffen da die Buffer ja nur ganzzahlige Längen
besitzen.
Ein Trick ist auch die Bufferlänge konstant zu wählen und das
Originalsignal mit unterschiedlichen Sample-Raten einzulesen. Als
Bufferlänge empfehlt sich ein Wert, bei dem möglichlichst viele Obertöne
mit ganzzahligen Wellenlängen angegeben werden können: Um die Obertöne
1, 2, 3, 4, 5, 6 darzustellen braucht man die Primfaktoren 2, 2, 3, 5
und erhält eine Bufferlänge von
2*2*3*5*n = 60*n
(44100 besteht übrigens aus den Primfaktoren 2*2*3*3*5*5*7*7=210*210)
... ich denke mal laut weiter ...
Zu den unterschiedlich großen Buffern:
1
s // Sample rate
2
f1 = x // Testfrequenz
3
f2 = f1 * 2 ^ 1/12 // Testfrequenz um einen Halbton erhöht
4
L1 = s / f1 // Länge des Buffers für die Testfrequenz
5
L2 = s / f2 // Länge des Buffers für die erhöhte Testfrequenz
6
k = L1 - L2 = s / f2 - s / f1 // Längenunterschied zwischen zwei Buffern
7
s = k * f1 * f2 / (f2 - f1) = k * f1 / (1 - f1 / f2)
8
= k * f1 / (1 - 2 ^ -1/12)
9
= k * f1 * 17,817153745105767553490105576143 (ungefähr)
- Angenommen, die oberste zu scannende Frequenz ist 220 Hz
- Angenommen, die Bufferlänge zweier Halbtöne soll sich um mindestens 6
Samples in der Länge unterscheiden
s = 6*220 Hz*17,82 = 23519 Hz
Das Originalsignal muss also mit mindestens 23519 Hz abgetastet werden -
das ist mehr als ich dachte. Die 12 Buffer sind also zwischen 107 (220
Hz) und 213 (110 Hz) Samples lang. Das wiederum sieht ok aus.
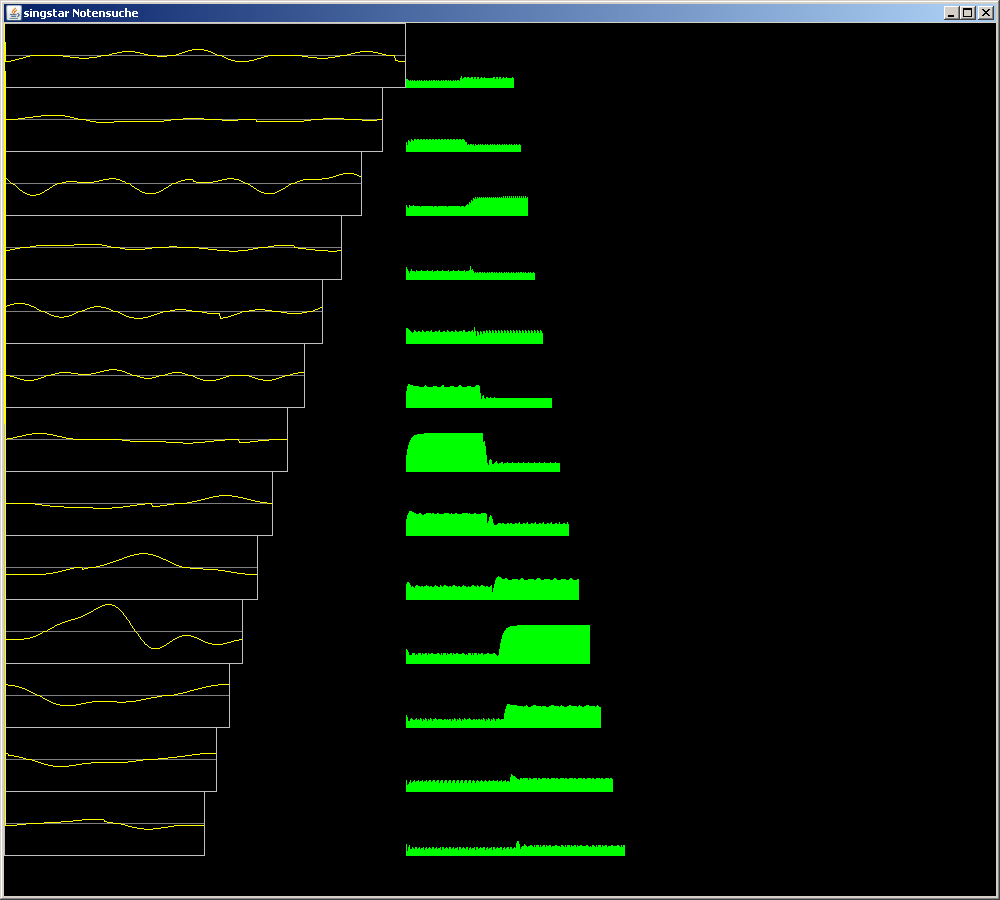
Das Programm analysiert ein Testsignal mit dem oben beschriebenen
Verfahren.
Das Testsignal ist ein mit Obertönen angereicherter Sinus, dessen
Frequenz 6 Halbtöne über der Basisfrequenz der Testoktave liegt. Nach
0,5 Sekunden wird die Tonhöhe um 3 Halbtöne angehoben. Das Gesamtsignal
ist 1 s lang.
Die gelben Graphen auf der linken Seite zeigen den Inhalt der Buffer am
Ende der Analyse an. Zeile 10 zeigt korrekter Weise genau eine Periode
des Testsignals an.
Die Grünen Diagramme daneben zeigen den Energiegehalt der Buffer nach
jedem Bufferdurchlauf an. Der kürzeste Buffer wird in einer Sekunde
natürlich öfters durchlaufen als der längste und liefert mehr Messwerte.
Interessant ist der Parameter STRENGTH. Mit dem kannst du festlegen,
wie dick das Originalsignal aufgetragen wird . 0.0 Bedeutet der Inhalt
des Buffers wird nicht überschrieben; 1.0 überschreibt den Buffer
komplett; 0.5 legt im Buffer das arithmetische Mittel vom alten und dem
neuen Wert ab. Kleinere Werte verbessern die Genauigkeit und
verschlechtern das Zeitverhalten und vice versa.
Schau mal, ob dir das schon weiterhilft... wenn ich Lust habe und es dir
hilft kommentier ich den Code noch nach ;)
schöne Grüße
Kai
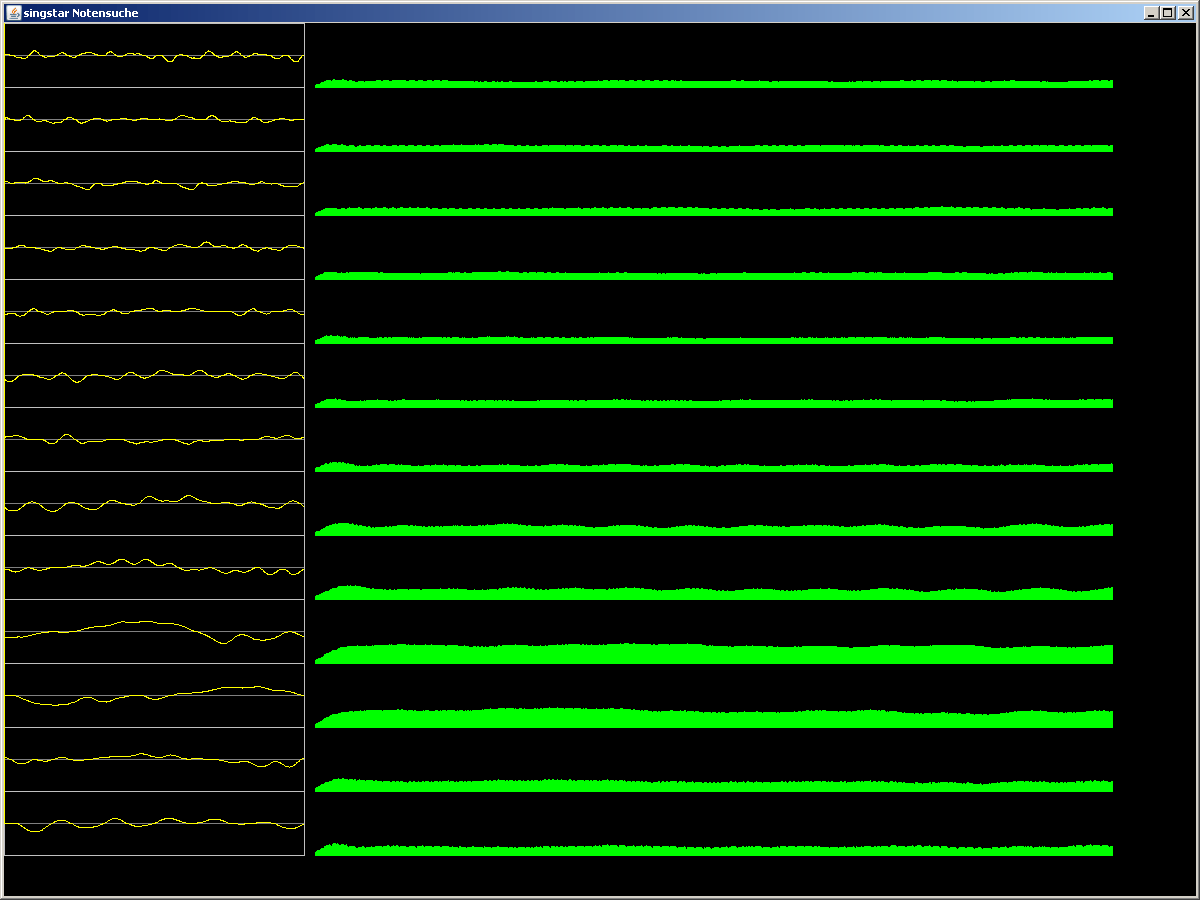
So, jetzt noch mal was näher an der Realität:
- Eingangssignal ist jetzt ein Monotones "a", 1 Sekunde, 44100 Hz, 8 bit
mono
- Den Bufferinhalt habe ich für die Darstellung auf eine feste Breite
skaliert. Der Oberste Buffer ist immer noch der längste und entspricht
der Startnote der Oktave. Die Buffer darunter entsprechen den
aufsteigenden Halbtönen. Der letzte Buffer ist genau eine Oktave Höher
als der erste. Er dient mir nur zur Kontrolle und muss normaler Weise
nicht berechnet werden.
- Die Energiepegel der Buffer werden jetzt zeitlich deutlich feiner
aufgelöst (Es ist nun eine kontinuierliche Abfrage nach jedem Sample
möglich). Werte, die untereinander dargestellt werden, wurden auch zum
selben Zeitpunkt gemessen.
(Bild im nächsten Post)
Jetzt zeigen sich auch die Schwächen des Verfahrens: Ich habe den
Einfluss der Obertöne unterschätzt. Insbesondere wenn man eine Oktave zu
niedrig misst (stell das Programm mal auf BASE_FREQUENCY = 30 Hz ein)
wird neben der korrekten Note auch die Note die 7 Halbtöne darunter
liegt stark betont. Ich habe den Effekt ein wenig dadurch gemildert,
dass die die eingelesene WAV-Datei durch einen starken Tiefpass läuft.
Die Obertöne werden hierdurch stärker gedämpft als der Grundton.
Das mit den sieben Halbtönen ergibt sich aus dem Frequenzverhältnis von
2 ^ 7/12 = 1,498 ~= 1,5
Solange wir in der korrekten Oktave messen ist das kein Problem. Aus
Sicht der Oktave darunter lässt sich aber auch ein Halbtonabstand von 7
+ 12 = 19 interpretieren:
2 ^ 19/12 = 2,9966 ~= 3
Und bei einem ganzzahligen Verhältnis bildet sich dort auch eine
stehende Welle :(
Vielleicht ist eine abgespeckte Fourier-Analyse doch sinnvoller...
Wow, danke! Das hilft mir sicher weiter!! :) Ich werde es mir jetzt mal
genauer anschauen. Kommentieren brauchst du denke ich nicht extra, das
dürfte ich so nachvollziehen können, Java ist mir geläufig :)
Sorry das ich nicht eher antworten konnte, aber über Ostern habe ich den
Rechner mal aus gelassen :)
Eine Basis Frequenz von 30hz ist nicht realistisch bei einem Spiel wie
Singstar, deshalb denke ich kann man so einen Grenzfall durchaus außen
vorlassen oder?
>Sorry das ich nicht eher antworten konnte, aber über Ostern habe ich den>Rechner mal aus gelassen :)
dzdzdz... ;)
>Eine Basis Frequenz von 30hz ist nicht realistisch bei einem Spiel wie>Singstar, deshalb denke ich kann man so einen Grenzfall durchaus außen>vorlassen oder?
Leider nein... das Problem besteht auch, wenn man zwei Oktaven höher
singt und zwei Oktaven höher misst.
Spiel einfach mal mit rum... ich hoffe, du hast die nötige Java-Version
da...
Siehe auch: Beitrag "Re: Frequenz über Mikrofon einlesen ATmega16 oder 32"
Ich hab es jetzt nochmal mit dem (jetzt etwas überarbeiteten) FFT Ansatz
versucht und erhalte bei reinen Tönen auch eine 100% richtige
Trefferquote.
Ich suche nach der FFT die dominante Frequenz im real array des
Ergebnisses. Allerdings komme ich z.B. bei einem von einem Metronom
generierten Ton den ich über das Mikro aufgenommen habe nicht auf das
erwartete Ergebnis... Hast du eine Idee woher das kommen kann? Wie
gesagt, alle reinen Töne werden gut erkannt.
Im anhang ist der Ton der nicht erkannt wird.
Ein Metronom? Kenne das nur als Taktgeber für's Musizieren :)
Habe mir den Ton mal angehört - der ist extrem Obertonreich und ich
tippe, dass der Grundton verhältnismäßig leise ist... um zu wissen was
da schief geht müsstest du mir sagen, was du unter einem "etwas
überarbeitetem FFT-Ansatz" verstehst.
Na gut, ich korrigiere... ein Tongenerator der zusammen mit einem
Metronom in einem gerät agiert :-D
Die Aussage hatte nichts mit der Funktionsweise des FFT zu tun, sondern
nur mit meiner Implementierung ;). Ich führe eine ganz normale FFT
analyse durch und betrachte dabei 8096 byte. Wenn ich die dominante
frequenz daraus gefunden habe berechne ich daraus den Ton... Vor der
FFT wende ich die Hamming-Fensterfunktion an um das Signal ein wenig zu
glätten, ich hatte gehofft das hilft etwas ;)
Lass mich raten... die ermittelte Frequenz ist zu hoch :)
Das Problem bei dem Prüfton ist, dass die Obertöne eine weitaus höhere
Amplitude besitzen als der Grundton. Du ermittelst mit deinem Verfahren
nur die präsenteste Frequenz und nicht den Grundton. Du könntest
versuchen den ggT auf den lautesten fünf Frequenzen bestimmen - das
ergäbe bei entsprechender Fehlertoleranz ziemlich gut den Grundton...
glaub mir, das macht keinen Spaß :)
> Das Problem bei dem Prüfton ist, dass die Obertöne eine weitaus höhere> Amplitude besitzen als der Grundton. Du ermittelst mit deinem Verfahren> nur die präsenteste Frequenz und nicht den Grundton. Du könntest> versuchen den ggT auf den lautesten fünf Frequenzen bestimmen - das> ergäbe bei entsprechender Fehlertoleranz ziemlich gut den Grundton...> glaub mir, das macht keinen Spaß :)
Die Frage die sich mir dann natürlich als nächstes stellt (bevor ich
noch den ggT berechne ;) ), ist ob so ein Ton (oder besser gesagt ein
Ton mit so starken Obertönen das der Grundton verdeckt wird) überhaupt
in einer menschlichen Stimme vorkommen kann? Ich habe bisher nur
generierte Töne getestet, entweder die reinen Töne aus dem
Frequenzgenerator, oder Töne aufgenommen aus dem Tongenerator.
Ich werde es mal testen, allerdings denke ich, wenn ich mal wieder zu
dem eigentlichen Singstar-Gedanken zurück komme, das Obertongesang
wahrscheinlich in den Gängigen Songs seltener zu hören ist ;)