Bei einem aktuellen Projekt welches ich jüngst an die Wand gefahren habe, hat sich nun herausgestellt, daß eine Autokorrelation über ein Signal von etwa 4kbytes die Lösung aller Probleme darstellen würde. Dummerweise habe ich in der Hardware dazu nicht die korrekten Resourcen berücksichtigt. (jaja, hinterher ist man immer etwas gescheiter). Zur Autokorrelation von 4000 bytes sind etwa 2000 8x8 Multiplikationen mit Aufsummierung der Ergebnisse für eine Spalte als 32 bit Resultat erforderlich. Das Ganze dann etwa 2000 mal, also insgesamt etwa 2000 x 2000 = 4 Mio Operationen. Mein momentan verbauter Prozessor (Risc mit 62,5nS/Befehl) würde dazu unakzeptable 10 Sekunden vertrödeln. Abgesehen davon habe ich aber auch nicht genug Ram um die berechnete Kurve aus 32 bit Werten zur anschliessenden Analyse der Ergebnisse abzulegen, so daß auch hier Kompromisse mit einer sofortigen Interpretation von Teilintervallen des Resultats erforderlich wären. Nun stehe ich vor der Entscheidung, entweders einen PLD oder einen größeren Prozessor einzusezten. Dazu habe ich mir einen Arm9 (966E-S) mit genügend RAM ausgesucht was aber auch ein mittelgroßes Projekt scheint weil ich damit noch nie was gemacht habe. Als Alternative dazu käme evtl. ein programmierbarer Baustein mit RAM in Frage. 4kbyte für die Eingangsdaten, evtl. noch 16kbyte dazu um die Resultate abzuholen. Ram Ankopplung an CPU z. Bsp. über 10 Mhz SPI. Etwas unklar scheint mir auch die Realisierung. Ein Sequenzer würde pro Takt eine 8x8 Multiplikation und eine 32 Bit Addition machen. Nach 2000 Takten wäre eine (von 2000) Spalten berechnet. Um dies abzukürzen könnte man n gleiche Sequenzer parallel betreiben womit n Resultate nach 2000 Takten gleichzeitig fertig wären. Problem scheint, daß ein Auslesen des Rams pro Takt immer nur an einer Adresse möglich scheint, weil man sonst ein Ram mit n gleichwertigen Adressdekodern und Datenbussen brauchen würde. Welcher programmierbare Baustein scheint für sowas geeignet, bzw. gibt es weitere Lesetipps dazu ?
Nachdem die Autokorrelation ja auch nur eine Faltung ist, bin ich so frei und werfe noch das Stichwort "fast convolution" in den Ring.
Das Problem mit den RAMs selbst kannst du dadurch lösen, dass du mehrere RAMs mit den selben Daten initialisierst und dadurch an mehreren Stellen gleichzeitig lesen kannst. Außerdem sind z.B. die Block-RAMs in Xilinx FPGAs sowieso schon über zwei Ports gleichzeitig ansprechbar, was die Zugriffsrate nochmal verdoppelt. Überleg dir auch schonmal, ob es bei den Multiply-Accumulate Einheiten nicht auch ähnliche Probleme (und Lösungen dafür) gibt.
ok, wenn ich das in Wikipedia richtig verstanden habe wird die Autokorrelation über die inverse Fouriertransformation des Autoleistungsspektrums berechnet. Schaue ich beim Autoleistungsspektrum (zuvor nie gehört) nach, so scheint dies das Quadrat der FFT zu sein (?). Demnach müsste ich zuerst eine FFT Transformation machen, dann das Quadrat berechnen und dann invers FFT machen. Kann das jemand bestätigen oder geht es ganz anders ?
Würde sagen, dass kommt schon so hin. Autokorrelation ist ja ne Faltung im Zeitbereich. FFT transformiert in den Frequenzbereich, dort ist eine Multiplikation auch eine Faltung im Zeitbereich, IFFT drauf und gut. Unter Umständen muss man noch ein wenig Zero-Padding betreiben. Einige Stichworte wären dann "overlap-add" und "overlap-save" (oder -store, bin mir da nicht mehr so sicher).
ok, es scheint nicht das Quadrat der FFT sondern die Multiplikation mit der komplex konjugierten FFT zu sein. Zentrale Frage bleibt dann aber weiterhin ob es mit einem (realen) Produkt wie diesem: http://www.latticesemi.com/documents/doc28236x55.pdf oder diesem: http://www.altera.com/literature/ug/ug_fft.pdf oder einem so ähnlichen machbar ist und was dabei für eine Zeit bzw. ein Baustein rauskommen würde.
Janvi wrote: > ok, es scheint nicht das Quadrat der FFT sondern die Multiplikation mit > der komplex konjugierten FFT zu sein. Das ist das gleiche.
Fuer die Xilinx-Chips gibt's via CoreGen schon fertige FFT-Module, allerdings bin ich mir nicht sicher, ob diese IP-Cores kostenpflichtig sind. Auf nem DSP oder ARM waere sicher die FFT weniger rechenlastig, man bedenke aber, dass bei der ueblichen, eher simpel implementierten FFT die Anzahl Samples 'ne 2er-Potenz sein muessen. Wenn janvi aber 4kB als 4096 Bytes auslegt, passt's wieder :-) Fragt sich nun, welcher Aufwand groesser ist. Im FPGA haette ich es sogar mal ohne FFT probiert, und die Autokorrelation einfach "von Hand" implementiert. Resourcen sind ja meist genug da, und man kann in der Tat so einiges parallelisieren (mal eben 16 MACs instanzieren) oder mit Pipelining in der Anzahl der benoetigten Takte reduzieren. Bei einer so geringen Anzahl Samples bringt die FFT nicht extrem viel Ersparnis, der Aufwand der Implementierung duerfte hingegen erheblich hoeher sein (ausser, man hat mit CoreGen Glueck) Das nur so ein paar Gedanken.. Gruss, - Strubi
> Das ist das gleiche.
Nein, das ist das Betragsquadrat und nicht das Quadrat.
Morin wrote:
> Nein, das ist das Betragsquadrat und nicht das Quadrat.
Bitte was? Das ist gemeint, das wird gemacht, das ist beabsichtigt, das
ist das gleiche. Und natürlich gilt
http://en.wikipedia.org/wiki/Spectral_density
1. Gefordert: Faltung. 2. Vorgeschlagen: Umweg über Spektrum. 3. Das macht man mit Betragquadraten. 4. TS wundert sich über konj. komplex. 5. Hinweis: Ist das selbe mit mathematisch korrekter Formulierung und bewusst unverfälschtem Zitat vom TS. Ist doch albern, aber typisch für hier. Für jewöhnlich isset so jerejelt, dass der Kopp nich nache Beene kejelt. In diesem Sinne.
Du hast recht, das ist wirklich exterm albern. Macht aber nix, ein jeder Leser wird deine Behauptung, Quadrat und Bestragsqudrat seien dasselbe, leicht wiederfinden. In diesem Sinne: Machs gut!
Angehängte Dateien:
-

fft.jpg
100 KB
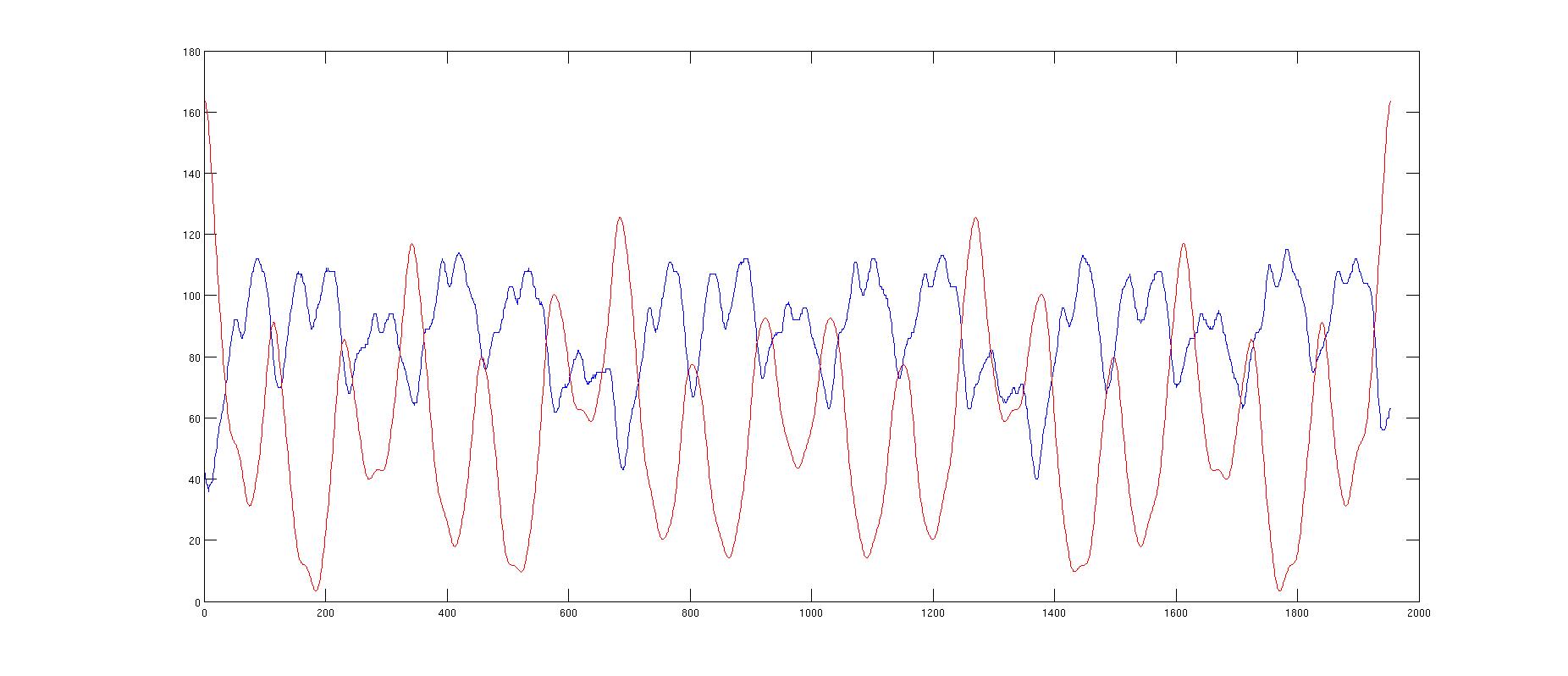
zwischenzeitlich habe ich mir ein Matlab Manual schnabuliert und die Sache ausprobiert. Wie man im Diagramm sieht, tut das sogar wie gewünscht. Die blaue Kurve ist das abgetastete Eingangssignal bei welcher die Frequenz erkannt werden soll. Es gibt eine Doppelhöcker Formation wobei jeweils der dritte Doppelhöcker etwas kleiner ist. Die zweiten drei Doppelhöcker unterscheiden sich in der Form aber etwas von den ersten Drei, wobei der Ausreiser in der Amplitude nach unten nicht gerade typisch für das Problem ist, also nicht allgemein zum drauf triggern genommen werden kann. Nach einer Fouriertransformation mit : >> b=abs(ifft(abs(fft(a)).^2)) erhält man die rote Kurve (b). Das erste Maximum hinter Null kennzeichnet eine halbe Umdrehung, das zweite bei etwa 700 ist aber etwas größer womit das dann auch die korrekte Periode wäre. Wie man in einem Matlab Skript auf die 700 plus etwas als Ergebnis kommt rätsle ich gerade noch etwas. Für einen Prototyp wär das soweit ok. Jetzt habe ich aber gesehen, daß Matlab verschiedene Möglichkeiten zur Codeerzeugung bietet. Code für Mikrokontroller ist wohl aussichtslos zumal hier die Einschränkung gilt, daß Zugriffe auf Matlab Bibliotheken nicht gehen. Bleibt noch beim VHDL Generator zu hoffen, dass dieser ein synthetisierbaren Code absetzt. Hatte auf diesem Weg schon mal jemand Glück mit der Codeerzeugung ?
>Außerdem sind z.B. die Block-RAMs in Xilinx >FPGAs sowieso schon über zwei Ports gleichzeitig ansprechbar, was die >Zugriffsrate nochmal verdoppelt. Mit jeweils einem Clock Delay kann man jede RAM-Zelle in beliebig viele Spiegel ausmappen.
Jürgen Veith wrote:
> Hatte auf diesem Weg schon mal jemand Glück mit der Codeerzeugung?
Ja, ich habe mich einmal damit beschäftigt (Filter-Design-HDL-Coder und
HDL-Coder für Simulink) und ein Tutorial geschrieben. Funktioniert
relativ simpel und spuckt direkt synthetisierbaren Code aus.
HDL-Coder-Toolbox vorausgesetzt ;^) .
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.