Hallo Zusammen,
zuerst einmal erkläre ich euch mein Grundkonzept, was ich erreichen
will.
Anschließend beschreibe ich den aktuellen Stand und zuletzt gehe ich auf
meine noch zu lösenden Probleme ein.
FPGA ist ein ZedBoard. Ethernet PHY ist direkt drauf, muss also nicht
viel beachtet werden was die Ansteuerung angeht.
Xilix Vivado und dessen SDK sind die folgenden Entwicklungsumgebungen.
Ich möchte gerne Messdaten, welche als stream über ein AXIS Streaming
Interface empfange zunächst einmal einlesen, um sie dann memory mapped
in der SDK benutzen zu können.
Daraufhin sollen die Messdaten über Ethernet mit 1GigE an einen Desktop
Rechner gesendet werden. Dabei sollen zumindest 30MB/s erreicht werden,
besser deutlich mehr. Die Messdaten sollen kontinuierlich gesamplet
werden und nicht einmal alle X Intervalle gespeichert werden.
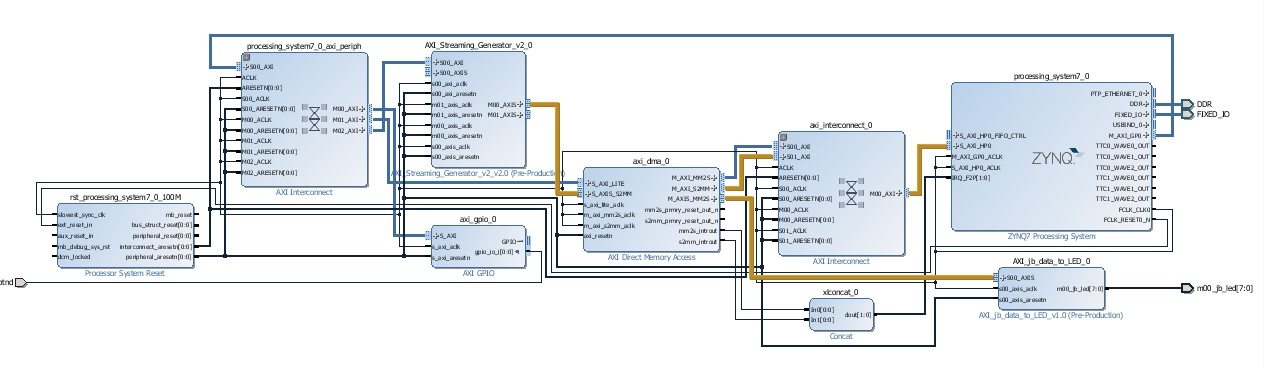
In der angehängten Grafik ist mein aktuelles Block Design zu sehen. Die
"Messdaten" werden aktuell vom "AXI_Streaming_Generator" erzeugt. Es
handelt sich um einen Counter, der hoch zählt und dabei in seiner
Geschwindigkeit einstellbar ist.
Der Daten-Stream geht zum DMA und wird memory mapped. Von dort aus
werden die Daten wieder raus an "AXI_jb_data_to_LED" geschrieben, wo sie
auf die LEDs umgesetzt werden und als Lauflicht zusätzlich angezeigt
werden.
Zu meinem Programmcode:
-Zuerst initialisiere ich den StreamingGenerator
-Initialisiere den DMA, den private-Timer und den TripleTimerCounter
(TTC0)
-Initialisiere danach das Interrupt System und enable alle Interrupts
Ethernetfunktionalität stelle ich mittels lwIP-TCP/IP-Stack her.
Programmablauf ist nun folgender:
Zu Beginn wird ein Sendepuffer angelegt, bestehend aus einem Feld aus
Charactern mit Zahlen zwischen 0 bis 9. Das sind die Daten welche per
Ethernet gesendet werden.
Über den TTC0 Timer kann das Zeitintervall eingestellt werden, in
welchem ein Paket an den TCP-Stack übergeben wird. Beim Überlauf wird
TtcTimerFlag incrementiert.
In Hauptprogramm wird zyklisch gesendet und die Funktion transfer_data()
aufgerufen. Jedes Mal wird die Queue des TCP Stacks gefüllt. Überträgt
der Transportlayer Daten, wird die Callback-Fnkt aufgerufen und die
Queue wieder gefüllt. Bei jedem Mal, wo ein Datenpaket eingefüllt wird,
wird TtcTimerFlag wieder decrementiert.
Bei jedem Überlauf von TTC0 wird ebenfalls geprüft, ob der DMA-Transfer
bereits abgeschlossen ist (TxDone und RxDone - Flags) und ggf. ein neuer
Transfer eingeleitet. Dabei werden die Daten aus dem StreamingGenerator
wieder weiter an die LED gesendet.
1
while(TxPerfDone==0){
2
if(TcpFastTmrFlag){
3
tcp_fasttmr();
4
TcpFastTmrFlag=0;
5
}
6
if(TcpSlowTmrFlag){
7
tcp_slowtmr();
8
TcpSlowTmrFlag=0;
9
}
10
xemacif_input(netif);
11
transfer_data();
12
}
Per Ethernet Daten zu senden funktioniert auch wunderbar. Das FPGA
verbindet sich als Client mit dem PC. Ich erhalte eine sich
wiederholende Zahlenfolge von 0 bis 9 und kann angeben, wieviel Megabyte
oder Gigabyte an Daten ich übertragen will, bis meine Applikation
beendet wird. Die Übertragungsgeschwindigkeit liegt bei bis zu 800MBit/s
und ist mehr als ausreichend. Jedoch sind die aktuell gesendeten Daten
relativ unspektakulär. Ich will gerne beide Elemente miteinander
verbinden:
ich möchte kein vorgefertigtes Feld an Daten über Ethernet senden,
sondern die per DMA emfpangenen Daten, welche vom StreamingGenerator
erzeugt wurden. Dabei müssen die Daten jedoch so schnell
zwischengespeichert werden, dass möglichst wenig Bandbreite verloren
geht.
Wie ich hier weiter mache bin ich mir noch nicht im klaren. Ich habe
schon an die Implementierung eines Rindpuffers oder ähnliches gedacht.
BEvor ich viel Zeit investiere würde ich gerne jedoch gerne von euch
Erfahren, was die wohl eleganteste Lösung ist und ob das aktuelle Design
dazu überhaupt zu gebrauchen ist?
Im Anhang ist das gezippte Projekt dabei. In der SDK sind unter anderem
die .c Files. Alles hier anzugeben würde den Rahmen sprengen. Das
Wesentliche ist in main.c und txperf.c zu finden.
Vielen Dank,
Grüße Julian
um nicht so sehr in die Details zu gehen.
Wäre es möglich, dass du deinen Stream in ein FIFO schickst und dieses
MemoryMapped (mit Hilfe DMA) ausließt?
danke für deine Antwort.
daran habe ich auch schon gedacht. Das würde jedoch erst einmal das
Problem lösen wie die Daten in den DMA gelangen. Momentan ist ein
"idealer Stream" davor, der in seiner Geschwindigkeit voreingestellt
werden kann (wie groß die Frame_Size ist bis der Stream quitiert wird)
Ein FiFo würde meines Erachtens nach jedoch nicht das Problem lösen,
dass ich pro Zeitintervall des TTC0 Timers, bei dessen Ablauf ich die
TCP-queue wieder fülle, auch genug Daten mit dem DMA aus dem FiFo
gezogen habe.
Wir sprechen hier von einer Speichergröße der Queue von 64 Kilobyte
(65536).
Die komplette Queue muss zu beginn einmal gefüllt werden. Danach dann
zyklisch, in Abhängigkeit von der Frequenz des TTC0 wieder entsprechend
aufgefüllt. In der Praxis werden so ungefähr zwischen zwei und drei
Kilobyte dazwischen versendet. Sich darauf zu verlassen wäre jedoch
nicht ideal.
Daher auch meine Vorstellung, die Daten nach dem Auslesen manuell in
eine neue Queue zu laden, dabei das Laden vom TTC0 Timer abzukoppeln in
einen neuen Timer TTC1 der eine höhere Frequenz hat und so z.B. 4 mal so
oft Überläuft und damit jedesmal ein neues Element ausliest,
vorausgesetzt, die Queue hat weniger als 64 Elemente.
Dann könnte nämlich im Extremfall die komplette Queue aus dem DMA an die
Queue des TCP Stacks überreicht werden.
Der Aufwand ist jedoch sehr groß, da ich noch nie eine Queue
implementiert habe und ich ncht einschätzen kann, ob es zielführend ist
oder mir die Bandbreite total einbrechen wird.
Vielleicht hat jemand bereits ein ähnliches Projekt selbst gemacht oder
irgendwo nachgelesen? Ich denke das wird wohl ein generelles Problem
sein, wie Daten so schnell versendet werden können, unabhängig von
meiner konkreten Aufgabenstellung?
Moin,
ich habe mir für solche Sachen die DMA-Engine des Blackfin
reimplementiert. Guck mal ins TRM des ADSP-BF537 o.ä., insbesondere zum
Autobuffer/Descriptoren-Thema. Was Ethernet-Uebertragung angeht, steht
da auch einiges in der Section zum "EMAC".
Der Gag ist, dass du eine verkettete Liste von Deskriptoren
typischerweise in einem L1-SRAM ablegst, auf die die DMA-Engine
zugreift. Damit kannst du prima Buffer queues implementieren, die
nahtlos und verlustfrei arbeiten (und ohne Umkopieren). Wenn die
Peripherie auf einem andern Clock nudelt, brauchst du entsprechend
DualClock-fähige FIFOs, die gibt's normalerweise als klickisupi-IP-Core.
Wenn du die EMAC-Engine auch implementierst, kannst du einen grossen
zusammenhängenden Datenblob im Speicher entsprechend ohne Overhead und
Umkopieren in UDP-Pakete zersäbeln und auf den TriMAC raushauen.
Allerdings hast du da u.U. mit lwip keinen Spass und implementierst
zumindest die UDP-Seite plus ARP usw. besser selber.
Gruss,
- Strubi
Hallo Strubi,
danke für deine ausführliche Beschreibung. Im Beispeil mit einem scatter
gather DMA habe ich folgende Code-Zeilen mal rauskopiert. Diese
beschreiben eine solche verkettete Liste wie du sie beschrieben hast.
Ist dir das Beispiel vielleicht zufällig bekannt?
Ich überlege, ob ich das Beispiel mit dem SG-DMA mir noch ein wenig
anschauen soll und dann dies in mein Design integrieren soll und ob das
zielführend ist.
So tief bin ich leider nicht in der C-Programmierung drin, dass ich das
hier alles so geschwind mache :D
Im Zusammenhang mit EMAC und ARP habe ich leider nichts mehr verstanden.
Einen eigenen EMAC möchte ich im BlockDesign nicht implementieren. Das
ZedBoard hat den PHY direkt implementiert und ich kann aus der SDK
heraus darauf zugreifen.
Aber die Überlegung mit den verketteten Listen klingt doch erstmal ganz
gut und wird mich erstmal beschäftigen! selbst wenn die Bandbreite erst
einmal nicht maximal ausgelastet wird ist es mir egal. ein erstes
Ergebnis wäre schön, an dem dann weiter gebastelt werden kann.
Übrigens verwende ich TCP, nicht UDP :)
Zuletzt noch der angesprochene Code-Auszug
1
/*
2
*
3
* This function sets up RX channel of the DMA engine to be ready for packet
4
* reception
5
*
6
* @param AxiDmaInstPtr is the pointer to the instance of the DMA engine.
7
*
8
* @return - XST_SUCCESS if the setup is successful.
Hi Julian,
genau, Scatter-Gather (SG DMA) war das Zauberwort. Das würde ich schon
mal zumindest in Software probieren: wenn ein Slice per DMA raus ist,
kannst du im Interrupt nen neuen DMA-Transfer per Hand (also CPU)
ankicken.
Ich bin mir aber nicht sicher, ob das Xilinx-Refdesign SGDMA im lwip
unterstützt, da musste man früher gehörig an den Interna rumbohren. Da
hast du dann zwei Baustellen, so oder so musst du dich dann auf
Protokollseite (logischer Layer über TCP) um das Handshaking und
allfälliges Spülen des Ringbuffers beim Ueberlauf kümmern. Ich würde mal
mit einem Software-FIFO (Buffer Queue) auf höchstem Layer anfangen, ohne
Umkopieren geht vermutlich auch beim neuesten lwip nix.
ARP ist address resolution protocol, macht der lwip schon alles. Sorry
für die Verwirrung.
Hi nochmal,
zuerst einmal: reference design benutze ich nicht mehr, ich habe mein
eigenes Blockdesign erstellt und in das boardsupportpackage (BSP)
lwip141(v1.0) eingebunden un konfiguriert, um eine möglichst hohe
Bandbreite zu realisieren. Ich kann also das aktuelle Bd ändern und den
Bitstream an die SDK senden.
"so oder so musst du dich dann auf Protokollseite (logischer Layer über
TCP) um das Handshaking und allfälliges Spülen des Ringbuffers beim
Ueberlauf kümmern. Ich würde mal mit einem Software-FIFO (Buffer Queue)
auf höchstem Layer anfangen, ohne Umkopieren geht vermutlich auch beim
neuesten lwip nix."
kannst du das bei Gelegenheit bitte noch ein wenig näher formulieren?
Wieso um Handshaking kümmern und was ist Spülen?
Und von wo nach wo wird kopiert? aus der Software-Queue in den TCP
Buffer?
Danke nochmal!
Moin,
in Kürze zu Handshaking: Wenn du einen Buffer rausschickst, aber ein ACK
verloren geht oder der Empänger einfach grade nicht will, läuft deine
Queue voll. Wenn du dann nicht mehr puffern kannst, brauchst du ein
"Flush"-Szenario (Spülen).
Kopieren: Ja, Software-FIFO nach TCP-Buffer. Das kannst du immerhin mit
Memory to memory SGDMA machen. Aber ob das Konzept so korrekt ist, kann
ich dir nicht sagen, da ich wie gesagt lwip komplett umgehe für die
GigE-Anwendungen.
Martin S. schrieb:> in Kürze zu Handshaking: Wenn du einen Buffer rausschickst, aber ein ACK> verloren geht oder der Empänger einfach grade nicht will, läuft deine> Queue voll. Wenn du dann nicht mehr puffern kannst, brauchst du ein> "Flush"-Szenario (Spülen).
Da würde ich jetzt einfach mal sagen, dass die ältesten Werte einfach
verloren gehen, wenn der Buffer voll läuft. Eine andere Möglichkeit
bleibt ja nicht, wenn ich schon am Limit was das Senden angeht bin.
oder?
> Kopieren: Ja, Software-FIFO nach TCP-Buffer. Das kannst du immerhin mit> Memory to memory SGDMA machen. Aber ob das Konzept so korrekt ist, kann> ich dir nicht sagen, da ich wie gesagt lwip komplett umgehe für die> GigE-Anwendungen.
was verwendest du für GigE wenn nicht lwip?
danke dir!
Julian B. schrieb:> Da würde ich jetzt einfach mal sagen, dass die ältesten Werte einfach> verloren gehen, wenn der Buffer voll läuft. Eine andere Möglichkeit> bleibt ja nicht, wenn ich schon am Limit was das Senden angeht bin.> oder?>
lwip wirft nix weg, das musst du dann selber machen,d.h. deinen 'tail'
der Queue den ältesten Buffer überspringen lassen.
>> Kopieren: Ja, Software-FIFO nach TCP-Buffer. Das kannst du immerhin mit>> Memory to memory SGDMA machen. Aber ob das Konzept so korrekt ist, kann>> ich dir nicht sagen, da ich wie gesagt lwip komplett umgehe für die>> GigE-Anwendungen.>> was verwendest du für GigE wenn nicht lwip?>
Rohes UDP.
Hallo,
ich wollte mich nun noch einmal zurück melden - es funktioniert! :)
die Eckdaten:
Messwerteerfassung eines 32-bit Messwerts mit bis zu 100 MHz => 400 MB/s
Daten. Messfrequenz wird auf 25 MHz geteilt um 100 MB/s zu erhalten.
Zwischenspeichern der Messwerte in einem hardware-FIFO.
Einlesen von Messdaten über den DMA in den DDR als Burst von 32 kB
Blöcken mit bis zu 330 MB/s. Der DMA wird im Simple Mode betrieben (kein
SG_DMA!) Es wird ein eigener Ringpuffer im Adressbereich des RAM
implementiert.
Übergeben der ältestens Messwerte in 32 kB Blöcken an den TCP Stack.
Damit erreiche ich nun auch 100 MB/s über Ethernet und erreiche somit
80% Auslastung ohne bislang ein Tuning des Stacks vorzunehmen.
Danke für die Hilfe!