Hallo,
ich habe nun ein Beispiel für ein FIFO im BlockRAM gesucht, bin aber
nicht wirklich fündig geworden. Hat jemand ein Beispiel für mich? ;-)
(Ziel: 16bit breit, ca. 16Stellen tief)
Ansonsten habe ich mir überlegt, das FIFO in etwa wie folgt aufzubauen:
Aufbau:
- vollständig synchron, gleicher Takt für Lesen und Schreiben
- nicht zeitkritisch, full/empty usw. Signale müssen nicht schon
innerhalb von einem Taktzyklus oder so aktualisiert sein
- BlockRAM als Speicher nehmen: RAMB_S16_S16
- überzählige RAM Zellen einfach nicht adressieren (oder FIFO ohne
Zusatzaufwand bis zu 1k Tiefe auslegen)
Lesen/Schreiben:
- FIFO Count mit Zählbereich der FIFO Tiefe
- Schreibadresse 2^n Bit breit
- Leseadresse 2^n Bit breit
- Write Impuls zum Schreiben von Daten
- bei jedem Write Impuls: Write Adresse um 1 erhöhen -> darf auch
überlaufen auf 0, FIFO Count um 1 erhöhen
- Leseadresse 2^n Bit breit
- Read Impuls zum Lesen von Daten -> in Register übernehmen
- bei jedem Read Impuls: Read Adresse um 1 erhöhen -> darf auch
überlaufen auf 0, FIFO Count um 1 vermindern
Flusskontrolle:
- Empty Flag: 0 wenn FIFO Count = 0, sonst 1
- Full Flag: 1 wenn FIFO Count = Maxwert, sonst 0
- Sperren der weiteren Write Impulse bei Full, Setzen eines Overflow
Flags
- Sperren der weiteren Read Impulse bei Empty, 0 als Resultat liefern
Initialzustand:
- beide Adressen auf 0
- Counter auf 0
- Empty Flag auf 1
- Full Flag auf 0
Würde das FIFO so wohl einigermassen gut funktionieren?
Habe ich etwas Wichtiges vergessen?
Viel einfacher kann man das wohl nicht aufbauen.
Hat jemand für dieses FIFO ein besseres Konzept?
Oder hat gar jemand eine Vorlage für mich ;-)
Gruss, Martin Kohler
Hallo Martin,
wenn du Webpack (Xilinx) oder Quartus (Altera) verwendest, dann kannst
du mit dem IP-Wizard ein komplettes FIFO erzeugen lassen - ist eine
Standardkomponente.
Wenn's Hausaufgabe für die Uni sein soll, dann sehen die fertige
IP-Cores wohl weniger gerne ;-)
Grüße
Thomas
Gast wrote:
> Wenn's Hausaufgabe für die Uni sein soll, dann sehen die fertige> IP-Cores wohl weniger gerne ;-)
Wäre doch mal ein netter Versuch...
Nein, ich bin hier auf Arbeit dran, das FIFO zu entwerfen und zu
implementieren.
Das Problem an den fertigen IP Cores ist, dass hier in der Firma die
Meinung vorherrscht, dass möglichst vieles möglichst plattformunabhängig
sein soll.
Der Chef sieht lieber ein in VHDL auscodiertes FIFO als ein Interface
mit angehängtem .ncd File aus dem Core Genrator.
Naja, die Verfechter der reinen Lehre...
Mir kanns recht sein, so kann ich mich VHDL-technisch etwas lernen
dabei, auch dank dieses Forums.
Platformunabhängig, aber dann doch den BlockRam? Der wird doch auch bei
jedem FPGA Hersteller leicht anders sein. Das ist ein unsinniges
Argument. Und kostet massig Zeit, was ja auch massig Geld ist.
Christian R. wrote:
> Platformunabhängig, aber dann doch den BlockRam?
Wenn ich den FIFO Speicher als Array definiere, dann nehme ich an, dass
XST dies in ein BlockRAM umsetzt. Das wäre dann die "noch reinere
Lehre", als wenn ich RAMB_S16_S16 im VHDL Code verwende.
Gibt es evtl. noch Rückmeldungen zum konzeptionellen Aufbau meines
FIFOs? Oder hat gar einer einen VHDL Beispielcode?
Über Sinn oder Unsinn möchte ich mich nicht weiter unterhalten, wie
gesagt, die "reine Lehre"...
Duke Scarring wrote:
> Sowas?:> http://mysite.verizon.net/miketreseler/sync_fifo.vhd
Ja. Sieht auf den ersten Blick gut aus, ist evtl. noch etwas zu
vereinfachen.
lala wrote:
> Das wage ich zu bezweifeln.
Begründung? Erfahrung?
-> meine Aussage basierte auf entsprechendem Erfahrungswert für das
angegebene Array, welches 8mal vorhanden war in dem Design.
>... FIFO Count um 1 erhöhen ...>... FIFO Count um 1 vermindern ...
Aber aufpassen, wenn gleichzeitig gelesen und geschreiben wird. Die
letzte Zuweisung im Prozess zählt ;-)
Lass den Fifo-Count weg, der bringt dich irgendwann in Bedrängnis.
Wenn du einen Schreib-Pointer hast, und einen Lese-Pointer, dann kannst
du dir den Fifo-Count leicht aus den aktuellen Pointer-Werten
ausrechnen.
Z.B.:
Fifo mit 16 Elementen (Zweierpotenzen sind gut für den Wrap-Around)
Wenn WR_Addr = RD_Addr --> Fifo leer
Wenn WR_Addr /= RD_Addr --> mindestens 1 Element ist im Fifo
Wenn (WR_Addr>RD_Addr)
Anzahl der Elemente <= WR_Addr - RD_Addr
sonst
Anzahl der Elemente <= 16 + WR_Addr - RD_Addr
> Wenn ich den FIFO Speicher als Array definiere, dann nehme ich an,> dass XST dies in ein BlockRAM umsetzt.
Ein 16x16Bit tiefes Fifo im BRAM ist eigentlich Ressourcenverschwendung.
Wie auch immer:
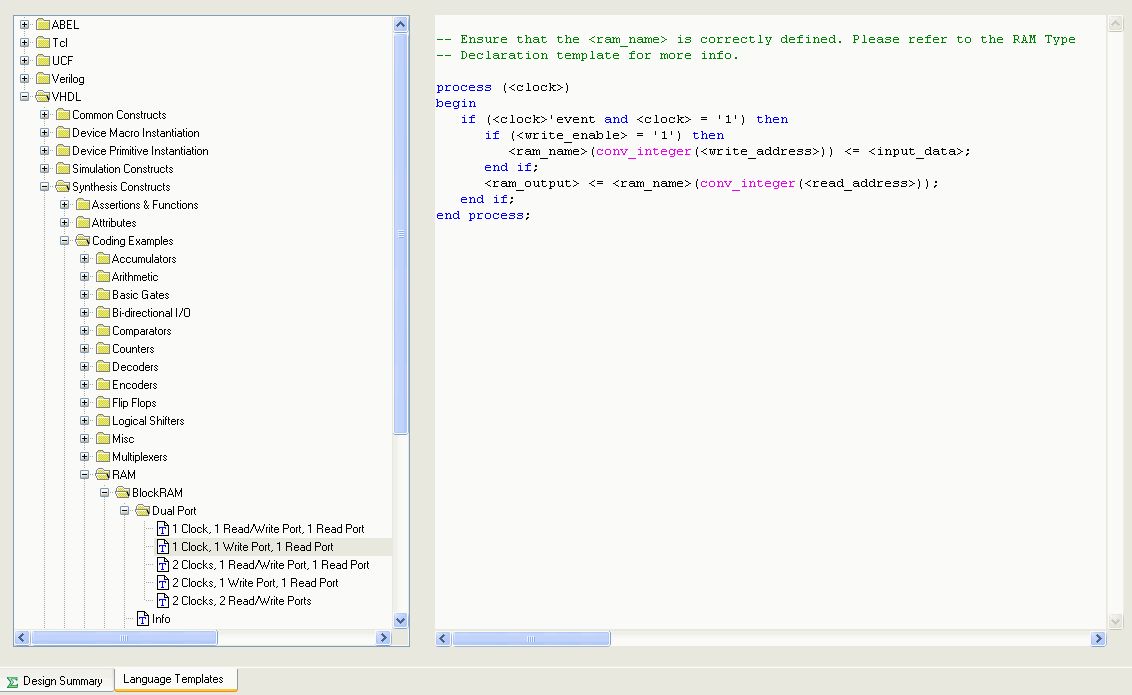
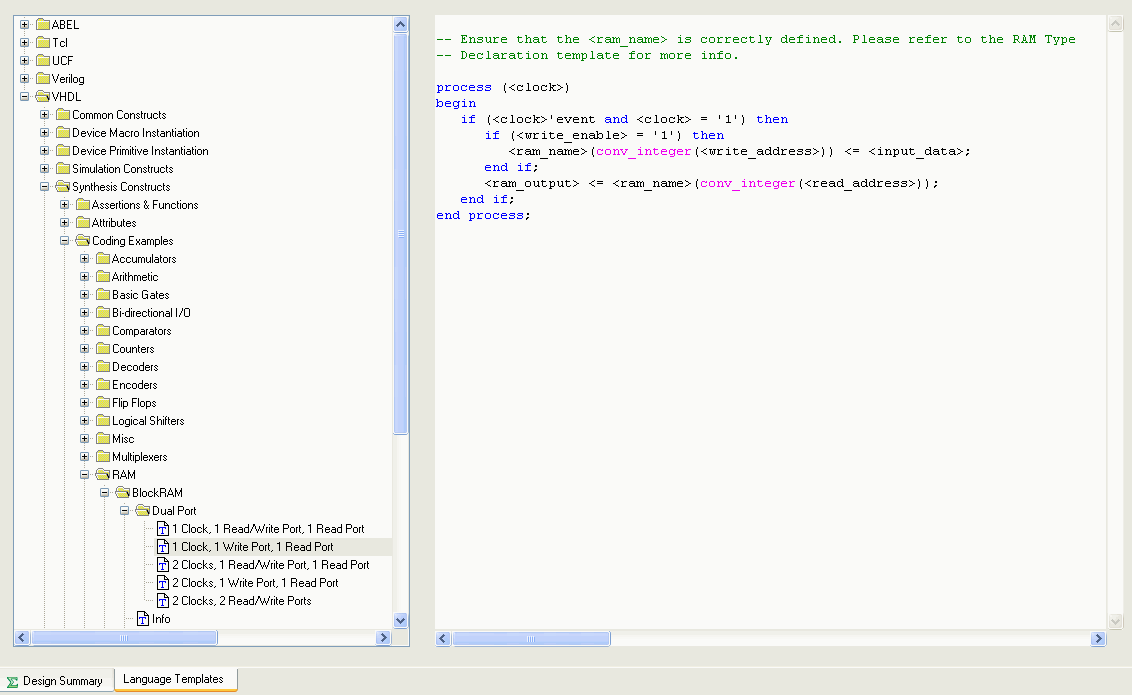
Im ISE Menüpunkt EDIT --> Language Templates und dann
VHDL --> Synthesis Constructs --> Coding Examples --> RAM --> Block Ram
--> Dual Port findet sich ein DP-RAM mit 1 Schreib und Leseport.
Der dürfte eigentlich gut geeignet sein.
EDIT:
>> http://mysite.verizon.net/miketreseler/sync_fifo.vhd> Sieht auf den ersten Blick gut aus, ist evtl. noch etwas zu vereinfachen.
Naja, der Mensch hat das mit dem Enable-Signalen noch nicht so richtig
inne:
1
-- we want to push/pop only on a '0' to '1' transition
Meine Fifos pushen und poppen solange WR bzw. RD aktiv (enabled) sind,
nicht auf irgendwelchen Flanken dieser Signale.
Lothar Miller wrote:
> Lass den Fifo-Count weg, der bringt dich irgendwann in Bedrängnis.
Mach ich.
> Wenn du einen Schreib-Pointer hast, und einen Lese-Pointer, dann kannst> du dir den Fifo-Count leicht aus den aktuellen Pointer-Werten> ausrechnen.
Wäre dann einfacher als einen Counter mitzuschleppen, ja.
> Wenn WR_Addr = RD_Addr --> Fifo leer
1
empty='1'whenwr_addr=rd_adrelse'0'
--> klar
> Wenn (WR_Addr>RD_Addr)> Anzahl der Elemente <= WR_Addr - RD_Addr> sonst> Anzahl der Elemente <= 16 + WR_Addr - RD_Addr
So was in der Art? (Pseudocode)
full lässt sich nun aber nicht einfach so beschreiben, da sind die
Adressen ja auch wieder gleich.
> Ein 16x16Bit tiefes Fifo im BRAM ist eigentlich Ressourcenverschwendung.
ist aber immer noch besser, als das BRAM brach liegen zu lassen ;-)
> Im ISE Menüpunkt EDIT --> Language Templates und dann> VHDL --> Synthesis Constructs --> Coding Examples --> RAM --> Block Ram> --> Dual Port findet sich ein DP-RAM mit 1 Schreib und Leseport.> Der dürfte eigentlich gut geeignet sein.
???
Dort befindet sich die Vorlage für die Ansteuerung (r/w) des RAM, nicht
aber das RAM selbst.
>
1
-- we want to push/pop only on a '0' to '1' transition
> Meine Fifos pushen und poppen solange WR bzw. RD aktiv (enabled) sind,> nicht auf irgendwelchen Flanken dieser Signale.
Meine Designs arbeiten auch pegelgesteuert, zur Ansteuerung werden
Triggerpulse generiert, welche genau 1 Clock lang sind.
--> ist einfacher als zu realisieren als flankengesteuert.
> So was in der Art? (Pseudocode)
So sollte es passen. Achte auf signed und unsigned bei den Adressen.
Ich lasse auch gern die Adressen auf 32 Bit laufen und nehme nur die
unteren Bits zum Adressieren. Als "Abfallprodukt" ergibt sich dann die
Zahl der übertragenen Daten. Aber auch hier mußt du auf den Überlauf
achten.
> full lässt sich nun aber nicht einfach so beschreiben, da sind die> Adressen ja auch wieder gleich.
Ja, dann melde FULL, wenn der Schreibindex eines hinter dem Leseindex
ist ;-)
So richtig "saugend" voll sollte dein Fifo sowieso nicht werden, denn
sonst reicht entweder die Fifo-Tiefe nicht oder die
Verarbeitungsbandbreite ist zu gering.
> Dort befindet sich die Vorlage für die Ansteuerung (r/w) des RAM, nicht> aber das RAM selbst.
Das RAM selbst ist auch in diesem Vorlagen-Zweig, es ist ein einfach
Array von Vektoren.
Lothar Miller wrote:
> Achte auf signed und unsigned bei den Adressen.
Ich habe vor, die Adressen als std_logic_vector zu definieren und das
DPRAM mit conv_integer(vector) zu addressieren.
1
RAM(conv_integer(AA(3downto0)))<=DA(15downto0);
Kann man eigentlich direkt mit std_logic_vector rechnen? Für das empty
Flag passt das locker ( = Operator), der Test auf "full when rd = wr +
1", geht das auch?
> Ich lasse auch gern die Adressen auf 32 Bit laufen und nehme nur die> unteren Bits zum Adressieren. Als "Abfallprodukt" ergibt sich dann die> Zahl der übertragenen Daten. Aber auch hier mußt du auf den Überlauf> achten.
Gute Idee. Danke.
> Ja, dann melde FULL, wenn der Schreibindex eines hinter dem Leseindex> ist ;-)> So richtig "saugend" voll sollte dein Fifo sowieso nicht werden, denn> sonst reicht entweder die Fifo-Tiefe nicht oder die> Verarbeitungsbandbreite ist zu gering.
Klar.
> Kann man eigentlich direkt mit std_logic_vector rechnen?
Nicht, wenn du die numeric_std Lib verwendest. Dafür gibts dann Casts
nach unsigned/singend und Konvertierungen nach integer und zurück. Aber
für einen Array-Zugriff brauchst du sowieso einen Integer. Warum nicht
die Adressen gleich als Integer verwalten?
Good old school style mit
> "full when rd = wr + 1", geht das auch?
Mit integer und unsigned geht das. Aber du solltest dir nochmal die
Überlaufgrenzen ansehen. Denn auch hier kann z.B. rd=15 sein und wr=0.
Lothar Miller wrote:
> Warum nicht die Adressen gleich als Integer verwalten?
Wahrscheinlich weil ich bisher für Adressierungen immer std_logic_vector
verwendet habe.
Würdest du die Adressen denn im gesamten Design als Integer verwalten
oder nur im FIFO Modul drin?
> mit der herstellerunabhängigen numeric_std
herstellerunabhängig ist immer gut ;-)
> Aber du solltest dir nochmal die Überlaufgrenzen ansehen.
Hab ich noch nicht getan.
Ich werde dann mal ein FIFO Modul samt passender Testbench erstellen,
dann sehen wir weiter.
> Würdest du die Adressen denn im gesamten Design als Integer verwalten> oder nur im FIFO Modul drin?
An den Schnittstellen habe ich immer std_logic.
Innerhalb der Module wird das dann sofort auf ein Integer-Signal
zugewiesen, und mit dem weitergearbeitet.
Lothar Miller wrote:
> An den Schnittstellen habe ich immer std_logic.
Dann bin ich beruhigt ;-)
> Innerhalb der Module wird das dann sofort auf ein Integer-Signal> zugewiesen, und mit dem weitergearbeitet.
Gut, werde ich auch so versuchen.
wobei - die Adressen brauch ich ja ausserhalb des Moduls gar nicht, da
kann ich auch gleich durchgängig mit "integer" resp. "natural" arbeiten.
Gibt es einen Vorteil von natural gegenüber integer, wenn bei beiden der
Range "0 to 255" definiert ist?
Lothar Miller wrote:
>> Kann man eigentlich direkt mit std_logic_vector rechnen?> Nicht, wenn du die numeric_std Lib verwendest. Dafür gibts dann Casts> nach unsigned/singend und Konvertierungen nach integer und zurück. Aber> für einen Array-Zugriff brauchst du sowieso einen Integer. Warum nicht> die Adressen gleich als Integer verwalten?
Ich habe nun versucht, die Adressen mit Integer zu verwalten:
1
generic(dat_length:natural:=16;
2
add_length:natural:=4
3
);
4
...
5
constantmem_size:integer:=2**add_length;
6
typemem_typeisarray(mem_size-1downto0)of
7
std_logic_vector(dat_length-1downto0);
8
signalmem:mem_type;
9
signaladdr_rd:integerrange0tomem_size-1;
10
signaladdr_wr:integerrange0tomem_size-1;
11
...
12
-- write data to memory
13
mem(addr_wr)<=data_in(dat_length-1downto0);
14
-- go to next write addr
15
addr_wr<=addr_wr+1;
16
...
17
-- go to next read addr
18
addr_rd<=addr_rd+1;
Das funktioniert in der Simulation auch ganz wunderbar - bis zu Adresse
15.
Sehe ich das richtig, dass sich die als Integer verwalteten Adressen nur
bis vor den Überlauf verwalten lassen? Der Überlauf führt im ModelSim zu
Fehler
"# ** Fatal: (vsim-3421) Value 16 for addr_wr is out of range 0 to 15."
Wie kann ich nun das Design auch mit Überlauf simulieren?
Doch wieder std_logic_vector für die Adresse verwenden?
Martin Kohler wrote:
> Wie kann ich nun das Design auch mit Überlauf simulieren?> Doch wieder std_logic_vector für die Adresse verwenden?
Nein, nimm für den Überlauf einen unsigned (numeric_std) ;-)
Probiers mal so:
1
addr_wr<=to_integer(to_unsigned(addr_wr,4)+1);
wenn du die alten Synopsys-Libs verwendest, mußt du auf std_logic_vector
und zurück casten.
Alternativ kannst du auch schreiben:
1
if(addr_wr<15)then
2
addr_wr<=addr_wr+1;
3
else
4
addr_wr<=0;
5
endif;
Da wäre ich mal gespannt, ob der Synthesizer rafft, dass er einfach
weiterzählen kann. Ich werde das in der Mittagspause mal probieren ;-)
Schreib ein Speicherarray statt:
1
typemem_typeisarray(mem_size-1downto0)of
besser so:
1
typemem_typeisarray(0tomem_size-1)of
Dann kannst du das Speicherarray in der "gewohnten" Reihenfolge mit :=
initialisieren.
Jetzt hab ich doch tatsächlich den lesenden Zugriff nicht synchron
gestaltet, so dass der Synthesizer mir ein distributed RAM bauen
wollte...
der process sieht nun so aus:
Hallo an alle !!!
ich habe mich direkt gefreut, als ich hier gelandet bin. Extrem
hilfreich. Aber ich hätte dazu noch eine Frage. Ich möchte ein Block RAM
mit diesem FIFO betreiben. Meine Frage lautet: brauche ich extra einen
Kode für das RAM selbst? Falls ja was für einen RAM-Kode
(FIFO-Konfiguration, dualport blockram Konfiguration). Entschuldigen
Sie, ob es eine dumme Frage ist, ich bin gerade in die FPGA- Welt
eingestiegen.
Beruk schrieb:> ich bin gerade in die FPGA- Welt eingestiegen.
Sieh dir den User Guide deines Synthesizers an. Da drin sind die
Möglichkeiten zur Instantiierung eines BlockRAMs aufgeführt.
Martin K. schrieb:> Der Chef sieht lieber ein in VHDL auscodiertes FIFO als ein Interface> mit angehängtem .ncd File aus dem Core Genrator.
Dafür gibt es auch gute Gründe. Neben der Portierbarkeit geht es vor
allem um die Loslösung von IPCores. Da gibt es einige Firmen, die von
Core-GEN Dateien wegwollen (oder "müssen").
Bei den FIFOs und BRAMs ist es allerdings so, dass dort zu einem großen
Teil echte hardware genutzt wird, z.B. für die Counter, Resets und die
Dekoder. Daher kann man nicht alles so wie vom Hersteller gedacht
nutzen, wenn man das nicht sinnvoll instanziiert.
Es kann daher passieren, dass man in VHDL etwas hinschreibt, was nicht
zu einer optimalen Struktur führt und man hinter dem zurückbleibt, was
durch konkrete Nutzung eines IP Makros und Anpassung an dieselbe möglich
gewesen wäre. Ungeschickte Bildung der Gray-Counter und deren Abfragen
zum Vergleich sind solche Kandidaten. Generell fährt man, wenn man
dedizierte FIFOs benutzt, besser, weil sie schneller takten, als BRAMs.
Wenn man aber zu viel drum herumbaut wird es wieder schlechter und man
ist mit händisch gebauten FIFOs aus Block-RAMs besser dran. Gilt aber
nur, wenn man seine Block-RAMs genau kennt und optimal nutzt.
Ganz generell kann man IP Cores nur dann toppen, wenn man wirklich genau
weiss man man tut.
J. S. schrieb:> Generell fährt man, wenn man dedizierte FIFOs benutzt, besser, weil sie> schneller takten, als BRAMs.
In welchem FPGA gibt es dedizierte FIFOs? Das ist doch immer normales
BRAM das auch als FIFO verwendet werden kann. Der IP Core bei Xilinx
macht das nicht anders.
Gustl B. schrieb:> J. S. schrieb:>> Generell fährt man, wenn man dedizierte FIFOs benutzt, besser, weil sie>> schneller takten, als BRAMs.>> In welchem FPGA gibt es dedizierte FIFOs? Das ist doch immer normales> BRAM das auch als FIFO verwendet werden kann. Der IP Core bei Xilinx> macht das nicht anders.
Hab ich auch noch nicht gehört - kenne vieles aber auch nicht 😂
Dachte das wird einfach immer als Dual-Port-RAM mit ein bisserl
Ansteuerung außenrum implementiert 🤔
Mampf F. schrieb:> Gustl B. schrieb:>> J. S. schrieb:>>> Generell fährt man, wenn man dedizierte FIFOs benutzt, besser, weil sie>>> schneller takten, als BRAMs.>>>> In welchem FPGA gibt es dedizierte FIFOs? Das ist doch immer normales>> BRAM das auch als FIFO verwendet werden kann. Der IP Core bei Xilinx>> macht das nicht anders.>> Hab ich auch noch nicht gehört - kenne vieles aber auch nicht 😂
Da muß man über ein Jahrzehnt "weggehört haben" wenn bswp. Xilinx von
den dedizierten IO-Fifos in den IO-Zellen der Series Seven spricht. (s.
UG471, p. 173) https://docs.xilinx.com/v/u/en-US/ug471_7Series_SelectIO
(Ausschnitt im Anhang).
> Dachte das wird einfach immer als Dual-Port-RAM mit ein bisserl> Ansteuerung außenrum implementiert
Falsch/garnicht gedacht, resp. schlecht/garnicht recherchiert.
Der FIFO-Generator bietet (schon immer) die Möglichkeit an, den FIFO
ggf. aus distributed RAM oder SRL16 (SRL16E, SRL32) shiftregister macros
zu bauen. (Siehe angehangenes snippet aus UG175
(http://wla.berkeley.edu/~cs150/fa13/resources/fifo_generator_ug175.pdf)).
Und "bisserl Ansteuerung" drumherum ist mindest im Fall von
Synchronisierungs-ff "spezielle" "integrated control-logic", die sich
eben nicht mit ein bisserl 0815-C-programmer-like VHDL generieren lässt.
Für FPGA's muß man eben Schaltungstechnik und deren typische Probleme
wie bspw. CDC (clock Domain Crossing) und simultanous read/write bei
Dualport kennen.
J. S. schrieb:> Ungeschickte Bildung der Gray-Counter und deren Abfragen> zum Vergleich sind solche Kandidaten. Generell fährt man, wenn man> dedizierte FIFOs benutzt, besser, weil sie schneller takten, als BRAMs.
Eben. Wobei hier der Begriff "dedizierte FIFO" mehrdeutig ist, weil er
zu einem "generierte (Netzlisten-)Fifo aus dem Core-Generator" meinen
kann, wie eben auch die dedizierten "(IO)-Fifos".
Für die Selbsterkenntnis der eigenen Unfähigkeit kann man ja mal
versuchen, eine Fifo mit unabhängigen read/write-clocks in VHDL zu
basteln, bei denen die Flag-Generierung "Full/empty") tadellos
funktioniert. Da read wie write-pointer in eigenen clock domainen laufen
ist ein Vergleich beider Latenzkorrekt nicht so trivial, wie es sich
anhören mag. Und es gibt im Bereich counter robustere und schnellere
Implementierungen als der Standard Binärcounter der durchschnittlichen
VHDL-Coder. Stichwort "Gray-encoding" und LSFR.
Klaus K. schrieb:> Der FIFO-Generator bietet (schon immer) die Möglichkeit an, den FIFO> ggf. aus distributed RAM oder SRL16 (SRL16E, SRL32) shiftregister macros> zu bauen.
Für einen FIFO würde ich beides nicht benutzen ...
Distributed RAM macht man eh nur, wenn es umbedingt sein muss - weil man
zB keine Blockrams mehr hat.
und ein BRAM als Ringpuffer mit ein paar Pointern und bisserl FIFO Logik
implementiert ist besser als Distributed RAM oder SLRs.
Aber ich würde das nicht mehr selbst machen, aber ganz stark davon
ausgehen, dass der IP-Wizard genau das macht.
Klaus K. schrieb:> Xilinx von den dedizierten IO-Fifos in den IO-Zellen der Series Seven> spricht.
Tatsache, die gibt es und sie sind sehr klein.
Klaus K. schrieb:> die sich eben nicht mit ein bisserl 0815-C-programmer-like VHDL> generieren lässt.
So sollte man generell kein VHDL schreiben. Aber man kann es selber
schreiben und es funktioniert wenn man es richtig macht.





{kind=link}
{kind=link}