Ich gehe mal davon aus, dass allen das Problem bekannt ist: Beim Schalten des FF bleibt der Ausgangspegel irgendwo in der Mitte und kippt erst verspätet in einen stabilen Zustand. Nun denke ich mir, dass ein solcher Zustand nach Verschwinden der Taktflanke (hold time) ja nur dann länger existieren kann, wenn der Analogwert des Ausgangssignal genau auf der Schaltschwelle des Eingangs liegt. Kann man denn FFs nicht einfach so bauen, dass der rückgekoppelte Haltepegel nicht genau dem entspricht, was als Pegel ausgegeben wird? Dann kann es nämlich nicht mehr passieren, dass man beim nochmaligen Eintakten in das nächste FF einen metastabilen Zustand weitertaktet, es sei denn, der verlischt gerade so blöde, dass dass wieder ein neuer MS erzeugt wird. Oder ist das schon so? Meine Frage geht nämlich dahin, ob man dem Metastabilitätsproblem lieber dadurch begegnet, dass man nochmal eintaktet, oder einfach länger wartet, bis das FF verlischt? Die Wahrscheinlichkeit, dass ein MS-Zustand noch existiert, nimmt ja mit zunehmender Zeit nach dem Takt exponentiell ab. Bei einem FF wäre die p = k * e (-2x) bei zwei FF "nur" 2 k e (-x)
> Meine Frage geht nämlich dahin, ob man dem Metastabilitätsproblem lieber > dadurch begegnet, dass man nochmal eintaktet, oder einfach länger > wartet, bis das FF verlischt? Laut Xilinx XAPP094 ist nur bei sehr hohen Taktfrequenzen Metastabilität eines FFs in heutigen FPGAs feststellbar. Das kann ich bestätigen: http://www.lothar-miller.de/s9y/categories/35-Einsynchronisieren Fazit: Ein FF reicht aus. Weil Ingenieure gerne auf der sicheren Seite sind, können 2 FF nicht schaden. Das kostet übrigens keinen zusätzlichen Aufwand im FPGA, weil so ein Schieberegister in der LUT realisiert werden kann, und das FF hinter der LUT gleich mitgenutzt wird. Ganz ohne Einsynchronisieren geht es nicht, weil unterschiedliche Routingzeiten die beste Statemachine durcheinanderbringen können...
Was Du meinst, ist wohl, dass der durch das erste FF erzeugte META in das zweite FF übernommen wird und man besser "abwartet", bis er verschwindet. Die Rechung geht nur auf, wenn Du eine Art multi cycle delay verwendest. Damit verlierst Du jeden zweiten Takt, bzw musst mit 2 zeitlich verschobenen Takten / Architekturen arbeiten. Im Prinzip so, wie bei einer langsamen Kombinatorik, die parallel aufgebaut ist, um sie zu pipelinen.
>Was Du meinst, ist wohl, dass der durch das erste FF erzeugte META in >das zweite FF übernommen wird und man besser "abwartet", bis er >verschwindet. >Die Rechung geht nur auf, wenn Du eine Art multi cycle delay verwendest. >Damit verlierst Du jeden zweiten Takt, bzw musst mit 2 zeitlich >verschobenen Takten / Architekturen arbeiten. Im Prinzip so, wie bei >einer langsamen Kombinatorik, die parallel aufgebaut ist, um sie zu >pipelinen. Verstehe kein Wort.
Peter Alfke, ehemaliger Chefdesigner bei Xilinx, hat in der Newsgroup comp.arch.fpga vor drei Jahren mal ein schönes Posting geschrieben. Es ging um Metastabilität und darüber, dass es zwar sehr oft als Ursache für Probleme dargestellt wird, das aber tatsächlich meistens nicht ist: http://groups.google.com/group/comp.arch.fpga/browse_frm/thread/c6594798db796f15/aa068f26d85cd0a7
FPGA-Pongo schrieb im Beitrag #1478725: > Bei einem FF wäre die p = k * e (-2x) > bei zwei FF "nur" 2 k e (-x) Ich komme nochmals auf diese Idee zurück: Im Prinzip ist das ja schon der Fall, da die Stabilisierungszeiten der FFs extrem kurz sind im Vergleich zu den genutzten Takten. Noch länger zu "warten" macht eigentlich keinen Sinn. Wenn die angegebene Wahrscheinlichkeit für Metastabilität nicht reicht, muss einfach das fakultative 2.FF dahinter. Da man bei sehr schnellen Schaltungen ohnehin die Eingänge irgendwo mindestens einmal registrieren muss, um die Routingprobleme zu lösen und man dazu immer das IO-Ff nutzt, ist das eigentlich ein Aufwasch.
FPGA-Pongo schrieb im Beitrag #1478725: > Meine Frage geht nämlich dahin, ob man dem Metastabilitätsproblem lieber > dadurch begegnet, dass man nochmal eintaktet, oder einfach länger > wartet, bis das FF verlischt? Ja, man kann das Weiterpropagieren des Metastabilen Zustandes unwahrscheinlicher gestalten in dem man die FF's nahe dem metastabilen FF placiert bzw auf dem kürzesten Weg routet, ergo länger wartet. MfG,
> das Flipflop verlischt Schön lautmalerisch, aber falsch. Das Flipflop kippt dann nicht "so langsam auf 0 zurück", sondern nimmt dann entweder stabil eine 1 oder eine 0 an. Je nach dem, was näher liegt. Es gibt in einem FPGA keinen metastabilen Zustand, der länger als ein paar hundert Picosekunden dauert. Bei aktuellen FPGAs wird man also frühestens ab 300Mhz wirklich metastabiles Verhalten beobachten können. Ich habe da einfach mal einen dreimonatigen Dauervversuch mit einem Spartan 3 gemacht, und bei 250Mhz nicht einen einzigen Aussetzer festgestellt.
Wobei noch zu erhähnen wäre, dass aktuelle FPGAs einen kleinen Tick schneller arbeiten, als "nur" 300 MHz ;-)
Lothar Miller schrieb: > Es gibt in einem FPGA keinen metastabilen Zustand, der länger als ein > paar hundert Picosekunden dauert. Bei aktuellen FPGAs wird man also > frühestens ab 300Mhz wirklich metastabiles Verhalten beobachten können. > Ich habe da einfach mal einen dreimonatigen Dauervversuch mit einem > Spartan 3 gemacht, und bei 250Mhz nicht einen einzigen Aussetzer > festgestellt. Die paar 100 psec fehlen an der Setupzeit zu den nächsten FFs. Und die Timinganalyze berücksichtigt das nicht. D.h. es hängt nicht nur von der Taktfrequenz sondern auch von der Grösse und Komplexität des Designs ab wie wahrscheinlich ein Fehler ist. Auf der Habenseite ist natürlich, dass die Timinganalyze den worst case bezüglich Temperatur,Versorgungspannung und Produktionstoleranzen berücksichtigt. Aber das ist auch im Auge des Betrachtersm d.h. wie paranoid ist man wenn P&R das Zieltimig nicht hinbekommt.
Lattice User schrieb: > Die paar 100 psec fehlen an der Setupzeit zu den nächsten FFs. Und die > Timinganalyze berücksichtigt das nicht. Sicher nicht? Mir fällt gerade auf, dass sich das Problem lösen liesse, wenn diese Zeit eingerechnet würde (und sich der Hersteller wirklich sicher ist, dass es maximal einige ps sind). Das Problem ist einfach, dass es theoretisch eben noch mehr sein können, wenn auch mit einer sehr geringen Wahrscheinlichkeit.
Jürgen S. schrieb: > Lattice User schrieb: >> Die paar 100 psec fehlen an der Setupzeit zu den nächsten FFs. Und die >> Timinganalyze berücksichtigt das nicht. > Sicher nicht? 100% sicher kann ich natürlich nicht sein, aber ich denke es wird nicht berücksichtigt. Könnte man rauskriegen wenn man sich den entsprechenden Pfad im Timingreport anschaut, da müsste es ja dann aufgeführt sein. Jürgen S. schrieb: > Das Problem ist einfach, dass es theoretisch eben noch mehr sein können, > wenn auch mit einer sehr geringen Wahrscheinlichkeit. Das wiederum liesse sich einfach berechnen wenn man die mittlere Lebennsdauer des metastablien Zustands kennen würde. Diese hängt aber ganz sicher auch von Dingen wie der Temperatur, Noise auf der Spannungsversorgung etc ab. Alles in allem je genauer man hinschaut desto komplexer wird das Thema. Mir kommt da gerade auch ein Gedanke: Mit einem Timingconstraint auf das Ausgangssignal des 1.FF kann man sich ein Sicherheitsmargin schaffen.
Jürgen S. schrieb: > Wobei noch zu erhähnen wäre, dass aktuelle FPGAs einen kleinen Tick > schneller arbeiten, als "nur" 300 MHz ;-) Wobei in diesem Fall ein asynchrones Design sträflicher Leichtsinn wäre... ;-)
Lattice User schrieb: > Mir kommt da gerade auch ein Gedanke: > Mit einem Timingconstraint auf das Ausgangssignal des 1.FF kann man sich > ein Sicherheitsmargin schaffen. Man könnte ein Schieberegister aus 2 bits (SRL16 o.ä) nehmen, kürzer gehts nicht. MFG
Jürgen S. schrieb: >> Die paar 100 psec fehlen an der Setupzeit zu den nächsten FFs. Und die >> Timinganalyze berücksichtigt das nicht. > Sicher nicht? Mir fällt gerade auf, dass sich das Problem lösen liesse, > wenn diese Zeit eingerechnet würde (und sich der Hersteller wirklich > sicher ist, dass es maximal einige ps sind). > > Das Problem ist einfach, dass es theoretisch eben noch mehr sein können, > wenn auch mit einer sehr geringen Wahrscheinlichkeit. Das Eigentliche Problem wird bei der Betrachtung realer Verhältnisse, bspw Ansteuerung einer FSM sichtbar. Beispielsweise soll eine one-Hot FSM mit Zuständen von einem einsynchronisierten Signal getrieben werden. Die laufzeit zu den 10 FF ist nicht gleich zu halten, da nicht alle 10 FF GLEICH NAH an den Synchronisierausgang plazierbar sind. Nun kann es geschehen das einige FF so weit entfernt platziert sind, das sie den wert sehen vor dem Recovery aus dem Meta, andere dagegen sind so nah, das sie den richtigen Wert verarbeiten. Und Voila! unter Umständen sind in der One-Hot codierten Statemachine 2 bits gesetzt so daß nur noch der Gnadenschuß per reset verbleibt. Oder der Synchroniser treibt den Reset-eingang eines 32 bit Zählers, da sind die Verhältnisse noch ärger. Mein persönliches Fazit: Hat ein einsynchronisiertes Signal mehr als ein FF zu treiben (also fanout > 1) dann muß der der Synchronizer mindestens aus 2 stufen bestehen. Und es spricht nichts dagegen, auch alle anderen Signale über zwei Stufen einzutakten. MfG,
Fritz Jaeger schrieb: > dann muß der der Synchronizer mindestens > aus 2 stufen bestehen. Wie ich sagte, es geht auch mit einem, wenn man mit dem Restrisiko leben kann, bzw. genug REserve im Timing hat und/oder es unter andere Risiken bei der FMEA fällt, denn da gibt es viel wahrscheinlichere Probleme. Lothar Miller schrieb: > Jürgen S. schrieb: >> Wobei noch zu erhähnen wäre, dass aktuelle FPGAs einen kleinen Tick > Wobei in diesem Fall ein asynchrones Design sträflicher Leichtsinn > wäre... ;-) Wieso beziehst Du Dich auf asynchron? Ich hatte Deine Aussage zu den 300MHz so aufgefasst, dass Du ab dem einen FF die Unsicherheit von einigen ps mit dem typischen routing von 1-2ns + setup zusammengefasst hast und damit auf 1/3 = 300MHz kamst. Meine Betrachung galt durchaus für synchrone Designs. Die Frage ist doch letzlich simpel: Wieviel Kombinatorik kann ich hinter die Unsicherheit des Wackel-FF noch dahinterpacken, bis ich ins nächste FF gehe: 1) Pessimistische Betrachtung: Garnix, man geht direkt ins nächste FF und hat die komplette Periode abzüglich Routing und eine überdimensionierte Sicherheit. 2) Realistische Betrachtung: Soviel, dass man stets noch 1ns Reserve für diesen Pfad hat, weil die Schaltzeit des FF in fast allen Fällen deutlich kleiner. Die Zahl der Fälle, wo das nicht der Fall ist entspricht der Wahrscheinlichkeit, einiger Lottogewinne in Folge und geht im Rauschen unter. 3) Optimistische Betrachung: Man ignoriert das Problem, nutzt nur 1 FF und hat nach der Synthese einige zufällige Reserve grösser 0, die theoretisch vom entscheidungsunwillige FF überschritten werden kann, praktisch aber dennoch reicht, weil die Synthese eh pessimistisch rechnet und der FPGA trotzdem noch funktioniert - besonders, wenn die Betriebsbedingungen nicht ausgereizt werden. 4) Die Möglichkeit "gar nicht synchronisieren" erwähne ich nur der Vollständigkeit halber. Dann hat man nämlich den instabilen Fall, wo es garantiert irgend wann vorkommt, dass unterschiedliche FFs gerade die Flanke sehen und einige falsch schalten - ganz ohne Metastabilitätsüberlegung. Nochmal zu den 500MHz: Solange Version 3 funktioniert, kann man so verfahren und glücklich sein. Meine Aussage ist aber: Die Methode 3 funktioniert nur bis an eine bestimmte, niedrige Grenzfrequenz, weil man nämlich so ein langes routing vom Pin über das FF durch die Kombi bis zum ersten FF bekommt. Zudem ist das dann rasch der lange Pfad im Design! Klopfe ich aber pauschal ein Zusatz-FF davor, habe ich nicht nur qualitativ die bessere Schaltung, sondern die Synthese hat ein entspannteres Timing und kommt zumindest statistisch auf höhere Frequenzwerte, die wiederum Sicherheit der quantitativen Art schaffen. Für den Fall, in denm die Synthese mit nur einem FF das Timing gerade schafft und der Synch-Pfad der längste Pfad ist, wäre Lothars 300MHz- Grenzfall erreicht, bei dem die Aussetzer beobachtbar sein würden.
Jürgen S. schrieb: > Wie ich sagte, es geht auch mit einem, wenn man mit dem Restrisiko leben > kann, bzw. genug REserve im Timing hat und/oder es unter andere Risiken > bei der FMEA fällt, denn da gibt es viel wahrscheinlichere Probleme. Bei allem Respekt, Restrisiko ist stümperei. Ich stell mir gerade vor das ein dunkler Fleck auf einem CT-Bild von Deinem Thorax von einem Synchronisierproblem stammt und du dann in den OP zur Lungenpunktierung geahren wirst. Wenn du das Auftreten von Sync-Problemen nicht unterbinden kannst oder willst, dann brauchst du aber auch eine Erkennung ob diese aufgetreten sind. Und deren Auswirkung als Fehler erkennbar macht resp. den FPGA resetet. Alles andere ist Murks und nicht das FF wert das man vermeintlich spart. Wenn dir die latenz zu hoch ist, dann taste die beiden FF jeweils mit der gegenläufigen Flanke ab. Reserve im timing ist auch nur die halbe wahrheit, wenn dann sollte die reserve für alle Pfade von dem Sync-Ausgang gleich sein, sonst läufts du in die von fritz geschilderten katastrophalen fehlzustände. Abgesehen davon das die Reserve schnell von den üblichen Naturumständen (Betriebsspannung schwankt, XCO jittert mehr als erwartet, Temperaturgrenzen erreicht, Bauteilalterung) aufgebraucht sind.
QA schrieb: > Bei allem Respekt, Restrisiko ist stümperei. Stümperei ist zu glauben mit 2 FFs ist das Restrisiko 0. Restriskio 0 gibt es nicht. QA schrieb: > Wenn dir die latenz zu hoch ist, dann taste die beiden FF jeweils mit > der gegenläufigen Flanke ab. Und das ist Resourcenverschwendung, mit einem Timingconstraint eine Reserve von der halben Taktdauer zu schaffen bringt mindestens die gleiche Sicherheit, im Mittel sogar mehr.
Meine beiden Vorschreiber haben es ja bereits auf den Punkt gebracht: Solche Themen wie Risiken, werden gerade durch die FMEA genauestens unter die Lupe genommen, gerade in der Medizintechnik. Wie ich oben bereits angedeutet habe, gibt es ab einem bestimmten Punkt ganz andere Risiken, die mit viel höherer Wahrscheinlichkeit Daten verfälschen. Da braucht es nicht einmal Teilchen aus dem Weltall, sondern nur solche aus Röntgenröhren oder Teilchenbeschleunigern, bzw. eine ordentliche EMI aus einem Leistungsteil, dass ein Signal verfälscht, dass Du dann technisch richtig einsynchronisiert hast und falschlicherweise berücksichtigst. Datenbusse sind da das grosse Thema. Im Prinzip läuft es darauf hinaus, dass man das Verhalten eines Systems wie einen FPGA oder Restelektronik, oder Mikroprozessor grundsätzlich als fehlerhaft annimmt und einen Überwacher beistellt. In unserem Fall des einsynronisierten Resets wird der Zustand des FPGAs, konkrete die FSMs ständig überwacht und die Daten plausibilisiert. Damit müssten sich schon zwei getrennte Einheiten "irren", was die Wahrscheinlichkeit der Nichterkennung eines Problems dann meistens weit unter die Akzeptanzgrenze drückt - z.B. unter die Chance, dass scih irgendwo ein Datenkabel löst und es zu Wackelkontakten kommt. Und nun könnte man auch ausrechnen, wie gross die Chance ist, dass durch solche Wackelkontakte (und nichts anderes sind falsch synchronisierte Signale in FPGAs) komplette Bildbereiche in einem Diagnosebild zufällig so aussehen, wie gesundes Gewebe, während dort real ein Tumor wächst und genau das tue ich jetzt mal gedanklich: Ich nehme die Zahl der Pixel, die ich benötige, um überhaupt einen Tumor zu erkennen und beziffere sie auf 3x3. Die minmale Abweichung der Helligkeiten muss mindestens 10% sein, sonst ist die Information unsicher, also "metastabil". Der Fehler müsste alle Bildveränderungen "rückändern" und träfe den Helligkeitsverlauf des Gewebes mit einer Wahrscheinlichkeit von eben diesen 10% (jeweils für alle erdecklichen Helligkeiten). Wir hätten also 10E-9 x die Wahrscheinlichkeit, dass wir nicht erkennen, dass wir einen Wackelkontakt hatten, weil der sich immer im Rauschen des Bildes bewegt hat und da wir ja sonst das Bild verworfen hätten. Wie klein die ist, kann ich nicht sagen. Da bei CBT aber immer mehrere Bildfolgen geschossen werden, um das Rauschen zu reduzieren ist das sehr rasch gegen Null. QA schrieb: > (Betriebsspannung schwankt, XCO jittert mehr als erwartet, > Temperaturgrenzen erreicht, Bauteilalterung) aufgebraucht sind. Auch die fliessen in die FMEA ein und die sich ergebenden Risiken werden schwerer bewertet, als bei Consumerprodukten. Z.B. werden Spannungsfestigkeiten höher angesetzt und wichtige Bauteile werden weiter toleriert. Zudem geht das wieder in Richtung Fehlfunktion einer Komponenten, die durch den eingesetzten Überwacher angfangen wird. Deine Bedenken sind richtig, aber hinlänglich bekannt und werden berücksichtigt. BTDT.
> Auch die fliessen in die FMEA ein und die sich ergebenden Risiken werden > schwerer bewertet, als bei Consumerprodukten. Z.B. werden > Spannungsfestigkeiten höher angesetzt und wichtige Bauteile werden > weiter toleriert. Zudem geht das wieder in Richtung Fehlfunktion einer > Komponenten, die durch den eingesetzten Überwacher angfangen wird. Deine > Bedenken sind richtig, aber hinlänglich bekannt und werden > berücksichtigt. Bei Deiner Betrachtung lässt unter anderem den Aspekt der Reaktionszeit ausser Betracht. Die Erkennung eines Fehlers und der Neustart des Systems, beispielsweise weil eine FSM sich in einem illegalen Zustand ohne Exit befindet, der nur durch einen Neustart behebbar ist, kostet sicher sekunden, wenn nicht Minuten. In der Diagnose sind da Minuten akzeptabel, bei der verwendung bildgebender Verfahren während der OP (bspw. Position Katheder) nicht. Vom Ausfall von leitsystemen in schnellen Transportmittel (bspw. Instrumentenlandesystem beim Anflug auf Landebahn bei Null sicht) mal ganz abgesehen. Ebenfalls betrachtest du nur die eine Seite der Risikoabschätzung, nämlich die Auftrittswahrscheinlichkeit, nicht aber die zweite Seite, die Folgenabschätzung. Bei Fehlern die den kompletten Kontrollverlust des Systems nach sich ziehen, ist nur eine Auftrittswahrscheinlichkeit akzeptabel die einer Jahrtausendkatastrophe (oder darunter) entspricht. Am meist unerklärlich ist allerdings, worin der Vorteil der bewusst in Kauf genohmenen Verschlechterung der Systemsicherheit/-stabilität bestehen soll? Minimaltiefe eines Synchronizer auf zwei Stufen spezifizieren und gut. Nur ein FF zum synchronisieren zu verwenden spart im FPGA/Bereich weder Kosten noch Zeit, auch nicht in der Massenproduktion. MfG,
Fritz Jaeger schrieb: > Am meist unerklärlich ist allerdings, worin der Vorteil der bewusst in > Kauf genohmenen Verschlechterung der Systemsicherheit/-stabilität > bestehen soll? > Minimaltiefe eines Synchronizer auf zwei Stufen spezifizieren und gut. > Nur ein FF zum synchronisieren zu verwenden spart im FPGA/Bereich weder > Kosten noch Zeit, auch nicht in der Massenproduktion. Das stimmt so pauschal nicht. Wie ich weiter oben schon geschrieben habe bleibe ich bei 2 FFs. Aber zum Dogma erhebe ich es trotzdem nicht. Es gibt durchaus Fälle bei denen das 2. FF auf die Perfomance geht, z.B. bei der Datenübertragung zwischen 2 Clockdomains mit Handshake. Um das zu lösen brauchts halt doch mehr als nur ein 2.FF und dann kann es schon mal sinnvoll das Risiko gegen die Kosten einen grösseren FPGA abzuwägen. Und wer Angst vor extrem seltenen Fehlfunktionen hat, sollte besser folgendn Artikel NICHT durchlesen: http://news.cnet.com/8301-30685_3-10370026-264.html
man muss hier doch schon unterscheiden, ob es sich hier um eine Herz-Lungen-Maschine handelt oder irgend was anderes... Wenn ich absolute Sicherheit will, dann bleibt mir nur eines: Einsynchronisieren in eine FF-Kette und moeglichst spaet dekodieren. Fuer normale Menschen hingegen reicht das erste FF aus (mit Flankenerkennung dann halt das erste und das zweite FF). Und dann passiert da normalerweise nix falsches. Als Entscheidungshilfe vlt. auch: Wird das Event vlt. wieder in 10 oder 50 oder 100 Mikrosekunden wieder auftreten? Waere das schlimm, wenn es einmal falsch waere? Also meine Meinung: Es kommt halt immer auch auf die Anwendung an!
Fritz Jaeger schrieb: > Bei Deiner Betrachtung lässt unter anderem den Aspekt der Reaktionszeit > > ausser Betracht. Die Erkennung eines Fehlers In keinster Weise lasse ich das ausser Betracht. Im Gegenteil: Ich hatte bereits darauf hingewiesen, dass genau das untersucht wird, und noch mehr: Es wird auch die ökonomische Komponente betrachtet, die wiederum dazu führt, dass Kompromisse in Sachen Sicherheit eingegangen werden - gerade in der Medizintechnik. Nochmal: Beim konkreten Thema hier geht es um Wahrscheinlichkeiten, die weit jenseits der Realität liegen. Konkret beim FPGa gibt es ja eine Reihe möglicher Fehlfunktion. Wie ich bereits schrieb, müssten vorher ganz andere Dinge unternommen werden, um viel wahrscheinlichere Fehler im System zu beheben. Z.B. müsste man Datenbusse generell redudant auslegen, was nicht passiert - Überwachungselemente müssten redundant ausgelegt werden, damit es zu keiner Fehlabschaltung kommt - etc etc ect. Das alles passiert nicht - aus Kostengründen! Der Schrei nach der absoluten Sicherheit ist ein utopischer Hilferuf. Wer Angst hat, sich operieren zu lassen, für den sind Fehlfunktionen der Geräte eh das kleineste Problem. Viel wahrscheinlicher ist, dass man sich eine Infektion holt, weil sich die Ärzte nicht die Hände nicht richtig gewaschen haben oder die Luftfilter über dem OP-Tisch, welche die Verdrängungsluft liefern, verkeimt sind, weil regelmässig die Wartungsinvervalle überschritten werden, wie man mir kürzlich glaubhaft versicherte.
Jürgen S. schrieb: > Wer Angst hat, sich operieren zu lassen, für den sind Fehlfunktionen der > Geräte eh das kleineste Problem. Viel wahrscheinlicher ist, dass man > sich eine Infektion holt, weil sich die Ärzte nicht die Hände nicht > richtig gewaschen haben oder die Luftfilter über dem OP-Tisch, welche > die Verdrängungsluft liefern, verkeimt sind, weil regelmässig die > Wartungsinvervalle überschritten werden, wie man mir kürzlich glaubhaft > versicherte. Oder weil dem Reinigungsteam nur noch 10 Minuten für einen OP zugestanden wird, statt wie vor dem Outsourcing 1 Stunde. (War wenn ich mich richtig entsinne in einem ARTE Beitrag erwähnt) Um zum FPGA zurückzukommen: Da gibt es auch das Risiko, dass ein Konfigurationsbit umkippt. Bei Xilinx findet man dazu ausführliche Untersuchungsergebnisse.
BTW, Xilinx hat die MTBF für zweistufige synchronizer gemessen und die Daten veröffentlicht, man muß nur etwas graben: http://www.xilinx.com/support/documentation/application_notes/xapp094.pdf http://forums.xilinx.com/t5/PLD-Blog/Metastable-Delay-in-Virtex-FPGAs/ba-p/7996 Ich interpretier die Docs so: -Beim Virtex-2Pro ist die MTBF zum Teil bedenklich klein (unter einem Jahr) -Beim Virtex4 und Virtex5 sind die Verhältnisse um Größenordnungen schlechter -das Problem wird durch eine kurze Verbindung zw. dem letzten Sync-FF und dem ersten "normalen" FF wesentlich entschärft. Ergo zweistufiger synchronizer und Constraint danach. Dann ist man zukunftssicher. MfG,
QA schrieb: > Bei allem Respekt, Restrisiko ist stümperei. Wie schützt du den FPGA dann vor Meteoriteneinschlägen? Soll heißen: wie gehst du dann mit anderen Fehlerquellen um, die um Größenordnungen wahrscheinlicher sind, als das Restrisiko beim einsynchronisieren? (Bei allem Respekt, liebe Moderatoren, ich muss meine Antwort wieder holen. Denn die war durchaus ernst gemeint, wenn auch arg sarkastisch eingedampft ;-) )
Wie schützt man ... - den FPGA vor Spannungsschwankungen vom Netzteil? - sich vor faulem Silizium, das durch die Prüfung gerutscht ist und doch nicht so funktioniert, wie die Synthese dachte? - die Schaltung vor schlechten Lötstellen, die thermisch bedingt, manchmal aussetzen? FPGAs haben da ja einige hunderte ... manche suchen in den Holzspänen und sehen die Bäume nicht vor Augen :-)
Klaus schrieb: > QA schrieb: >> Bei allem Respekt, Restrisiko ist stümperei. > > Wie schützt du den FPGA dann vor Meteoriteneinschlägen? > > Soll heißen: wie gehst du dann mit anderen Fehlerquellen um, die um > Größenordnungen wahrscheinlicher sind, als das Restrisiko beim > einsynchronisieren? > > (Bei allem Respekt, liebe Moderatoren, ich muss meine Antwort wieder > holen. Denn die war durchaus ernst gemeint, wenn auch arg sarkastisch > eingedampft ;-) ) Risiko eines Menschen durch einen Meteor getötet zu werden, Bezugsintervall 1 Jahr: 1 zu 3 Mrd. (http://www.gubi.li/wahrscheinlichkeit/index.html) Mittlere Zeit zwischen zwei Synchronisier-Fehler bei hoher Temperatur und niedriger Spannung f. einen Systemtakt 1 GHz und einer Taktrate von 1 kHz des einzutaktenden Signals: ~ 1 Minute Selbes Szenario 1 FF mehr : ~ 1 Monat (http://webee.technion.ac.il/~ran/papers/Metastability-and-Synchronizers.IEEEDToct2011.pdf) Fragen die auf kopmlett falschen Grundannahmen beruhen können nicht beantwortet werden. Durch Dein Insistieren auf diese Frage offenbarst Du nur die völlige Abwesenheit von Sachkenntnis deinerseits. MfG,
Fritz Jaeger schrieb: > kopmlett falschen Grundannahmen Fritz Jaeger schrieb: > einen Systemtakt 1 GHz So, so. 1 GHz im FPGA... ;-)
Michael S. (technicans) schrieb: > Fritz Jaeger schrieb: > >> einen Systemtakt 1 GHz > So, so. 1 GHz im FPGA... ;-) Nimm 5 Ffs bei 200MHz. Dann hast Du die Wahrscheinlichkeit. @Fritz: Das paper bescheibt die Wahrscheinlichkeit des Auftretens an sich, lässt ausser Acht, dass es ein Verlöschen im toleranten Zeitraum gibt. Das paper ist auch etwas fragwürdig, weil es den metastabilen Zustand absichtlich erzeugt. Wer ständig auf der Clockflanke sampled, bekommt zangsläufig mehr solche Fälle. Wenn Wie du das zitierst, jeden Monat eine Fehlfunktion vorkäme, würde nichts funktionieren, das kann nicht sein.
Michael S. (technicans) schrieb: > Fritz Jaeger schrieb: >> kopmlett falschen Grundannahmen > > Fritz Jaeger schrieb: >> einen Systemtakt 1 GHz > > So, so. 1 GHz im FPGA... ;-) Bspw. Virtex6 Speedgrad 3 GTX Transceiver Pll-frequency -> 3.3 GHz (http://www.xilinx.com/support/documentation/data_sheets/ds152.pdf). MGT steht für MultiGigabit Transeiver - MGT - Nomen est omen! An den IO's haben auch FPGA's die GHz Grenze geknackt. Anders wäre es ja auch nicht möglich AD-Wandler mit 125 MSPS und 14 bit Wortbreite (http://www.analog.com/en/analog-to-digital-converters/ad-converters/ad9253/products/product.html) an einem FPGA zu betreiben Und da wäre noch der Achronix (intel) Speedster22I WP -> http://www.achronix.com/wp-content/uploads/docs/Speedster22i_Product_Brief_PB024.pdf mit intern 1.0 - 1.5 GHz Mit den aktuellen Trends im FPGA-Design der letzten 5 Jahre scheinst Du Dich nicht besonders auszukennen MfG,
Fritz Jaeger schrieb: > Mit den aktuellen Trends im FPGA-Design der letzten 5 Jahre scheinst Du > Dich nicht besonders auszukennen Ach komm, hör bitte auf zu trollen! Ein solches GHz Signal willst du als asynchrones Signal per synchronizer chain samplen? Das ist doch quatsch, und das weißt du auch.
Kritiker schrieb: > Michael S. (technicans) schrieb: >> Fritz Jaeger schrieb: > @Fritz: > Das paper bescheibt die Wahrscheinlichkeit des Auftretens an sich, lässt > ausser Acht, dass es ein Verlöschen im toleranten Zeitraum gibt. > > Das paper ist auch etwas fragwürdig, weil es den metastabilen Zustand > absichtlich erzeugt. Wer ständig auf der Clockflanke sampled, bekommt > zangsläufig mehr solche Fälle. > > Wenn Wie du das zitierst, jeden Monat eine Fehlfunktion vorkäme, würde > nichts funktionieren, das kann nicht sein. Das Paper beschreibt im wesentlichen eine Testschaltung zur Ermittlung der recovery-time, deshalb provozierts es timing violations im IO-FF. Allerdings ist das Abtasten von einen 1 kHz Signal (externer Sammel-IRQ; Ond of Line-Sync) durch einen GHz-prozessor mE kein besonders unrealistisches Szenario. Natürlich kann man einen synchronizer so designen, das eine Weiterpropagieren des metastabilen Zustands praktisch ausgeschlossen ist. Wenn man weiß wie und warum und das will das paper vermitteln. Das ein störungsfreies Arbeiten trotz Fehler im Sekundentakt möglich ist, beweist ein Blick in die Bitfehlerstatistik bspw eines DSL-Anschlußes. CRC,FIFOS und das kompromisslose Abblocken von metastabilen Zustände vor FSM sind Schlüssel dazu. Ein bekanntes Beispiele für ein Produkt das in frühen versionen von Synchronosierfehlern geplagt worden ist, ist der Intel 8048. Notfalls hat man einen xternenSsynchroniser vor den Chip geschaltet und den zeitversatz zwischen dessen takt und den internen kompensiert). Falls dir das paper suspekt vorkommt, dann schau mal in das gestern Genannte: http://www.xilinx.com/support/documentation/application_notes/xapp094.pdf Ziel eines synchronizerdesign sollte mindestens sein das von 1000 höchsten eimes in seines lebensspanne (10 Jahre) wegen eines sync-fehlers stehen bleibt. Also eine MTBF von 10000 Jahren ist das Minimum. Und das ist mit genügend Sync-stufen leicht erreichbar. Mit nur einer und verharmlosen als Restrisiko dagegen nicht. MfG,
Klaus schrieb: > Fritz Jaeger schrieb: >> Mit den aktuellen Trends im FPGA-Design der letzten 5 Jahre scheinst Du >> Dich nicht besonders auszukennen > > Ach komm, hör bitte auf zu trollen! Ein solches GHz Signal willst du als > asynchrones Signal per synchronizer chain samplen? Das ist doch quatsch, > und das weißt du auch. Du verwechselst hier was, es geht in dem Paper um das Einsamplen eines Signals im kHZ Bereich, nicht Giga oder Gaga. MfG,
Fritz Jaeger schrieb: > Also eine MTBF von 10000 Jahren ist das Minimum. Mit welcher Begründung? Du kennst die MTBF-Betrachtungen typischer Geräte? Selbst der Beitrag eines um einen Faktor 10 schlechteren Synchronizers wäre immer noch marginal. Zudem führt ja nicht jeder Synch-Fehler zu einer Gerätediskfunktion, insbesondere nicht zu einer unerkannten und auch innerhalb der erkannten nicht immer zu einer unakzeptablen. Man muss dann eben auch eine Logikebene höher entsprechende Massnahmen ergreifen, um sich vor allerlei Problemen zu schützen. Eine redundante FSM mit delayed observation z.B. kommt bei einem fehlerhaften reset oder Zustandsübergang auch dann nicht ausser Tritt, wenn sie nicht one-hot gecoded ist, wenn nicht noch zusätzlich ein direkt folgender Synchfehler in den redundanten FSMs denselben Fehler produziert. Die Wahrscheinlichkeit dafür ist mindestens p*p womit aus lokalen Ausfallswahrscheinlichkeiten im Bereich, die sich auf einen Monat abbilden können, sofort Zeiten entstehen, die im Bereich des Alters der Erde liegen. Will heissen: Fehlschaltungen in der primären FSM durch EMV, Strahlung, Erschütterung (ja das gibt es!), schlechtes Silizium, kurzfristiges Überschreiten der Betriebsbedingungen oder auch metas kommen zwar oft vor, pflanzen sich aber nicht auf deren Ausgang fort. Bei einem funktionell sicheren Design erschlägt man gleich eine Reihe von Problemen mit einem Aufwasch. Meta-Gedöhns ist miterledigt.
Kritiker schrieb: > Das paper ist auch etwas fragwürdig, weil es den metastabilen Zustand > absichtlich erzeugt. Wer ständig auf der Clockflanke sampled, bekommt > zangsläufig mehr solche Fälle. Das ist z.B. so ein Punkt: Was in dem zitierten Dokument ungeschickt dargestellt ist, ist die Aussage, dass man metastabile Zustände leicht dadurch erzeugen könne, dass man auf der Taktflanke sample - so, als ob das dann automatisch dazu führt, dass man in einen Fehler hineinläuft. Sampeln auf der Datenflanke führt zunächst einmal immer zu einem undefinierten Zustand und nur selten bekomme ich einen metasatbilen Zustand. Die Wahrscheinlichkeit des Austretens müsste also noch mit der Wahrscheinlichkeit des Flankentreffens multipliziert werden. Das ist gfs nicht jedem auf Anhieb ersichtlich. Ferner müsste bei der realen Betrachtung Aussagen über den Jitter des Datums und des Taktes gemacht werden, denn nur dadurch bekomme ich ja mehr oder weniger häufig den Fall des sich zu spät entscheidenen FF. Die Aussage: kHz mit GHz zu sampeln hilft da her*t*zlich wenig! Zurückkommend auf die Betrachtung, dass man immer undefiniert ist, wenn man exakt auf der Flanke sampelt, ist es also letztlich nur eine Frage, ab wann ich denn jetzt bitteschön den definierten Zustand erwarte und wann sich damit überhaupt erst der Fall ergibt, dass ich infolge von MS plötzlich mehr habe. Solange man die Zeit, die das FF in dem gerade noch akzeptablen Fall der Grenzwahrscheinlichkeit, benötigt, um letztlich zu schalten, zur nominellen Schaltzeit hinzuaddiert, ist man sicher und es gibt kein falsches FF! Wenn die Betrachtungzeit lang genug ist, ist es mir egal, ob das FF in monotoner Manier direkt gegen einen Endzustand schaltet oder noch ein doppeltes Tänzchen macht. Ich greife mir also in der Betrachtungskurve aus dem Datenblatt diejenige maximale Schaltzeit heraus, für die das FF nur noch eine Meta-Wahrscheinlichkeit p00 hat, die ich akzeptieren kann und addiere sie gedanklich auf, indem ich sie bei dem budget des timings berücksichtige. Was anderes kann man als designer gar nicht tun, als formell korrekt bauen. Klar ist, dass die Problematik bei schnelleren Schaltungen quantitativ immer kritischer wird. Von der qualitativen Herangeehensweise ändert sich aber nichts: Entweder, ich habe mein timing korrekt validiert oder ich habe es nicht korrekt valdiert und was übersehen.
Eine Sache fällt mir noch ein: Von meinem Kritikpunkt der fehlenden Definition oder Angabe der Metastatistik i.A. von Jitter etc mal abgesehen, sind die Fälle, die in dem paper beschrieben werden, klinische Messungen unter Laborbedingungen. Reale FPGAs unterliegen einem deutlich höheren Rauschen, bedingt durch das ständige Schalten der Ausgänge und das Zittern der Betriebsspannung. Für das FF, dass seinen Ausgang in einem metastabilen Zustand halten will, wird dieser Balance-akt ebenso schwer und unwahrscheinlich, wie für einen Artisten im Zirkus den Ball auf der Nasespitze zu behalten, während es ein Erdbeben gibt. Meine These ist, dass das Rauschen in den FPGAs und die Unzulänglichkeiten beim GNDing und Powering Das Metaproblem reduzieren. Da sie gleichsam bei Schaltzeiten zu berücksichtigen sind / in den Timingmodellen integriert werden, haben sie mithin massive(re) Auswirkungen auf die Grenzfrequenz, als das theoretische Hinzuaddieren des budgets für Metaaktivitäten. Gegenansichten?
Fritz Jaeger schrieb: > Du verwechselst hier was, es geht in dem Paper um das Einsamplen eines > Signals im kHZ Bereich, nicht Giga oder Gaga. Das eingesampelte Signal in dem Paper hat nur 1 kHz, aber die andere Seite läuft mit 1 GHz. Deshalb hat die nächste Stufe selbst im Optimalfall nur maximal 1 ns zur Verfügung während der sie Metastabilität tolerieren kann. Für FPGA Designs ist das aber völlig unrealistisch. Realistische maximale Frequenzen der internen Logik liegen eher bei um den 400-500 Mhz, meistens eher 100-250 Mhz. Da hat dann auch ein einstufiger Synchronisierer mehr Zeit zum Auflösen der Metastabilität als ein mehrstufiger Synchronisierer, der bei 1 GHz läuft. Und unter normalen Bedingungen funktioniert auch laut Paper ja der 2-Flipflop Synchronisierer auch bei 1 GHz super, nur wenn der tau Parameter 10mal schlechter ist als gewöhnlich, weil der Prozess an seinen absoluten Grenzen was Temperatur, Spannung und Geschwindigkeit genutzt wird, dann funktioniert er nicht mehr vernünftig. Gerade das hat man aber beim FPGA nicht, diese werden eben nicht so an den Grenzen des machbaren betrieben. Die im Datenblatt angegebenen maximalen und minimalen Temperaturen und Spannungen sind weit von den Werten entfernt bei denen sich sich tau so sehr verschlechtert. Und die externen IOs und SERDES kommen eh fertig vom FPGA Hersteller, dort muss der sich einen Kopf drum machen, wie er Probleme durch Metastabilität in den Griff bekommt. Innerhalb der konfigurierbaren Logik sollten zwei Stufen nahezu immer reichen. Hier ist wohl eher der Hinweis: "the two flip-flops should be placed near each other, or else the wire delay between them would detract from the resolution time S." wichtig, denn wer das nicht durch Constraints festlegt, dem kann schnell mal passieren, dass fast keine Zeit zum Auflösen der Metastabilität des ersten Flipflops vorhanden ist. Wenn nur noch 100ps Slack vorhanden sind, dann kann natürlich auch ein klein bisschen Metastabilität zum Fehler führen. Der Fehler lag dann aber im fehlenden Contraint und nicht darin, das nur zwei Stufen verwendet wurden. Und der nächste Punkt: Es gar nicht mal so selten das man mit seltenen auftretenden Fehlern gut leben kann. Wenn der Synchronisierer bspw. in einem FIFO für einen Datenkanal liegt, der ohnehin mit Prüfsummen und Retransmit geschützt ist, dann reduziert ein Fehler nur minimal die Performance. In FIFOs kommt zusätzlich dazu das oftmals Fehler bei der Synchronisierung gar keine negativen Auswirkungen haben müssen, in sehr vielen Fällen sind die Statusbits trotz falsch übermitteltem Pointerstand der anderen Seite richtig. Grüße, Jan
Frage zum Verständnis: Dass zwei Flipflops besser sind als eines, leuchtet mir ein, weil für das Stabilwerden des ersten Flipflops (fast) die volle Taktperiode zu Verfügung steht, anders als wenn zwischen dem Eingangs-FF und dem nächstfolgenden auch noch Logik vorhanden wäre. Aber warum soll bei längerer FF-Kette die Situation sich theoretisch weiter verbessern? Das ist mir unklar. Eher würde es mir einleuchten, zwei FFs zu verwenden und durch Clock-Enables die effektive Frequenz zu reduzieren.
Jürgen S. schrieb: > Fritz Jaeger schrieb: >> Also eine MTBF von 10000 Jahren ist das Minimum. > Mit welcher Begründung? Du kennst die MTBF-Betrachtungen typischer > Geräte? Selbst der Beitrag eines um einen Faktor 10 schlechteren > Synchronizers wäre immer noch marginal. Begründung steht im Text: "Ziel eines synchronizerdesign sollte mindestens sein das von 1000 höchsten eimes in seines lebensspanne (10 Jahre) wegen eines sync-fehlers stehen bleibt." Typische Anwendung Automatisierungstechnik: -Zerstörungsfreie Prüfung mit Ultraschall an Strangwalzanlage -Qualitätprüfung (Optisch) Vials in der Serenproduktion (Fühlstand, Etikettierung, Fremdkörper) Dergleich läuft 7x24h durch, manuelles Eingreifen nicht vorgesehen. 100% Koorektheit erforderlich. Fällt die Prüfanlage aus, steht die gesamte Produktion. Typische Stückzahlen solcher Anlagen ist 1000, die 10 Jahre Lebensdauer sind einfach Und dies ist keine Systembetrachtung bei der die Ausfallwahrscheinlichkeit aller Komponenten berücksichtigt wird, sondern nur einer einzelnen Baugruppe. Im System wird es nicht besser, also 10000 Jahre MTBF ist Minimum. Und das nur für den Fall einer einzelnen synchroniserstrecke pro Gerät. wird bspw das einkommende Signal mit fanout=10 auf 10 FF verteilt (bspw FSM-Zustandsvektor) und sind 10 FPGA's pro Gerät verbaut ((Phase-) Array-technik)) sind schnonmal zwei Größenordnungen verschenkt .... > Zudem führt ja nicht jeder Synch-Fehler zu einer Gerätediskfunktion, > insbesondere nicht zu einer unerkannten und auch innerhalb der erkannten > nicht immer zu einer unakzeptablen. Das wird hier grad gefordert, nennt man worst case szenario. Ferner ist mir persönlich der Kölner Approach "Et hät noch immer jot jejange" nicht zu eigen, sondern Murphy. Was falsch gehen kann, wird falsch gehen. Man muss dann eben auch eine > Logikebene höher entsprechende Massnahmen ergreifen, um sich vor > allerlei Problemen zu schützen. Eine redundante FSM mit delayed > observation z.B. kommt bei einem fehlerhaften reset oder > Zustandsübergang auch dann nicht ausser Tritt, wenn sie nicht one-hot > gecoded ist, wenn nicht noch zusätzlich ein direkt folgender Synchfehler > in den redundanten FSMs denselben Fehler produziert. ja klar man kann FSM auch gegen andere Fehler absichern und damit die Sicherheitsreserve auch für sync-aussetzter erhöhen. Der Entwurf einer solchen FSM ist aber deutlich aufwendiger als das zufügen eines weiteren FF. Ferner kommt durch "delayed observation" Latenz hinzu, die man gerade vermeiden will. > Die > Wahrscheinlichkeit dafür ist mindestens p*p womit aus lokalen > Ausfallswahrscheinlichkeiten im Bereich, die sich auf einen Monat > abbilden können, sofort Zeiten entstehen, die im Bereich des Alters der > Erde liegen. Will heissen: Fehlschaltungen in der primären FSM durch > EMV, Strahlung, Erschütterung (ja das gibt es!), schlechtes Silizium, > kurzfristiges Überschreiten der Betriebsbedingungen oder auch metas > kommen zwar oft vor, pflanzen sich aber nicht auf deren Ausgang fort. > Bei einem funktionell sicheren Design erschlägt man gleich eine Reihe > von Problemen mit einem Aufwasch. Meta-Gedöhns ist miterledigt. Du sprichst vor falschen Publikum. Es geht hier nicht um eine Gesamtsystembetrachtung, sondern um den Entwurf eines sicherern Synchronizers. Warum ein ganzes Team von Excel-Wahrscheinlichkeits jongloren und systemanaylitkern einsetzen, wenn ein zusätzliches FF richtig eingesetzt die MTBF um den Faktor 10^9 (von Kilo auf Tera) verbessert? Innerhalb des Avionics/Space-Bereichs mag ein funktional sichers design möglich und der Aufwand dafür vertretbar sein. Im Alltag wird man gefeuert wenn man mit einer Promotion das "Meta-Gedöhns" erledigt, was ein alter hase mit einer kleinen Ergänzung schafft. MfG,
Jan L. schrieb: > Fritz Jaeger schrieb: > Und unter normalen Bedingungen funktioniert auch laut Paper ja > der 2-Flipflop Synchronisierer auch bei 1 GHz super, nur wenn der tau > Parameter 10mal schlechter ist als gewöhnlich, weil der Prozess an > seinen absoluten Grenzen was Temperatur, Spannung und Geschwindigkeit > genutzt wird, dann funktioniert er nicht mehr vernünftig. Gerade das hat > man aber beim FPGA nicht, diese werden eben nicht so an den Grenzen des > machbaren betrieben. Die im Datenblatt angegebenen maximalen und > minimalen Temperaturen und Spannungen sind weit von den Werten entfernt > bei denen sich sich tau so sehr verschlechtert. Nun ich empfehle nochmals bei problemen mit den paper sich das das andere (Xilinx - Virtex2PRO XAPP096) anzuschauen). Da werden CLB-FF mit IO-FF verglichen, und die MTBF für die beiden Eckwerte der Corespannungen angegeben (1V65 und 1V35). Die MTBF ändert sich bei konstanten slack um mehrere Größenordnungen! (jeweils bei Raumtemperatur!!) Das Szenario hierbei ist 1 MHz async daten abgesampelt mit 100MHz. Xilinx hat die Messungen mit neueren FPGA's wiederholt (sieh Link in meinem Post weiter oben) ebenfalls bemerkenswert: die Werte für neueres Silizium sind schlechter. > Innerhalb der konfigurierbaren > Logik sollten zwei Stufen nahezu immer reichen. Hier ist wohl eher der > Hinweis: "the two flip-flops should be placed near each other, or else > the wire delay between > them would detract from the resolution time S." wichtig, denn wer das > nicht durch Constraints festlegt, dem kann schnell mal passieren, dass > fast keine Zeit zum Auflösen der Metastabilität des ersten Flipflops > vorhanden ist. Wenn nur noch 100ps Slack vorhanden sind, dann kann > natürlich auch ein klein bisschen Metastabilität zum Fehler führen. Der > Fehler lag dann aber im fehlenden Contraint und nicht darin, das nur > zwei Stufen verwendet wurden. Zustimmung, mit 2 stimmig platzierten FF ist man so gut wie immer auf der sicheren Seite. Allerdings argumentieren einige der frühen posts in diesem thread in Richtung ein einzelnes FF. Und ich interpretiere die XAPP so, das man auch bei einem zweistufigen Syncronizer einen Slack von > 2.5 ns braucht um in dem gegebenen Szenario eine MTBF von 1000 Jahren (IMHO Minimum sollten 10000 sein) sicher zu erzielen. > Und der nächste Punkt: Es gar nicht mal so selten das man mit seltenen > auftretenden Fehlern gut leben kann. Wenn der Synchronisierer bspw. in > einem FIFO für einen Datenkanal liegt, der ohnehin mit Prüfsummen und > Retransmit geschützt ist, dann reduziert ein Fehler nur minimal die > Performance. In FIFOs kommt zusätzlich dazu das oftmals Fehler bei der > Synchronisierung gar keine negativen Auswirkungen haben müssen, in sehr > vielen Fällen sind die Statusbits trotz falsch übermitteltem > Pointerstand der anderen Seite richtig. Ebenfalls Zustimmung, das Auftreten von Sync-Fehleren im Datenpfad beeinträchtigt die Stabilität nicht. Anders ist es dagegen bei FSM und (mit einer geringeren Prio) Zählern. Da sind metastabile Quellen meist tödlich. MfG,
Jürgen S. schrieb: > Eine Sache fällt mir noch ein: > > Von meinem Kritikpunkt der fehlenden Definition oder Angabe der > Metastatistik i.A. von Jitter etc mal abgesehen, sind die Fälle, die in > dem paper beschrieben werden, klinische Messungen unter > Laborbedingungen. > > Reale FPGAs unterliegen einem deutlich höheren Rauschen, bedingt durch > das ständige Schalten der Ausgänge und das Zittern der Betriebsspannung. > Für das FF, dass seinen Ausgang in einem metastabilen Zustand halten > will, wird dieser Balance-akt ebenso schwer und unwahrscheinlich, wie > für einen Artisten im Zirkus den Ball auf der Nasespitze zu behalten, > während es ein Erdbeben gibt. > > Meine These ist, dass das Rauschen in den FPGAs und die > Unzulänglichkeiten beim GNDing und Powering Das Metaproblem reduzieren. > > Da sie gleichsam bei Schaltzeiten zu berücksichtigen sind / in den > Timingmodellen integriert werden, haben sie mithin massive(re) > Auswirkungen auf die Grenzfrequenz, als das theoretische Hinzuaddieren > des budgets für Metaaktivitäten. > > Gegenansichten? Schaltungstechnisch wird eine Menge gegen das von dir beschriebene Rauschen getan (Jede menge optimierte Stütz-C direkt an den Pads, Nutzung der PCB-Polygone als C, Anpassung an SSO (simultanous switching outputs), jede zweite Innenlage ist GND, ...). Ich verlasse mich nicht auf ein rauschoptimiertes design zur Kompensation fehldesignter Synchronisierstufen. Sich darauf verlassen, das ein Gerät, das unter laborbedingungen ausfällt, es unter realen Bedingungen nicht tut, grenztm.E. schon an (akademische) Absurdität. Im Zweifelsfall testet der Kunde vor der Abgabe einer order mein Gerät in seinem Labor. Ihm dann einzureden, das das Gerät in Echt es tun wird ... ... ... . Ebenfalls gehe ich davon aus, das die Angaben zur Recoverytime etc der Hersteller aus der Statistik der QA stammt und die Datensätze für die statistik permanent erweitert werden und somit schon eine reale aussagekraft haben. MfG,
Fritz Jaeger schrieb: > Nun ich empfehle nochmals bei problemen mit den paper sich das das > andere (Xilinx - Virtex2PRO XAPP096) anzuschauen). Da werden CLB-FF mit > IO-FF verglichen, und die MTBF für die beiden Eckwerte der > Corespannungen angegeben (1V65 und 1V35). Die MTBF ändert sich bei > konstanten slack um mehrere Größenordnungen! Die MTBF schwankt um mehrere Größenordnungen, nicht aber tau und darum ging es. Tau hat eine e^(1/tau) Verbindung zur MTBF. Eine Veränderung von tau um eine Größenordnung, wie im Paper angenommen, hat daher noch deutlichere Auswirkungen. Und im XAPP096 finden sich auch die Messwerte von tau und diese Schwanken zwischen 22.7 und 52ps, also nur rund Faktor 2 und nicht Faktor 10 wie im Paper angenommen. Daneben sollte auffallen das 1.35 V und 1.65 V Corespannung deutlich außerhalb der Spezifikation für einen Virtex 2 Pro ist, eigentlich zulässig sind 1.425V bis 1.575V. Und bei 3 ns sind die Werte super, egal für welche Flipfloptyp und welche Versorgungsspannung. Gerade bei Virtex 2 Designs sollten >3 ns Slack bei ordentlichem Constraining auf jeden Fall zwischen den Flipflops vorhanden sein. Fritz Jaeger schrieb: > Ich verlasse mich nicht auf ein rauschoptimiertes design zur > Kompensation fehldesignter Synchronisierstufen. Sich darauf verlassen, > das ein Gerät, das unter laborbedingungen ausfällt, es unter realen > Bedingungen nicht tut, grenztm.E. schon an (akademische) Absurdität. Naja, wenn das tatsächliche Silizium unter Laborbedingungen ausfällt okay, aber in dem IEEE Paper ging es um rein theoretische Überlegungen zur MTBF. In deren mathematischem Modell gab es gar kein Rauschen, ein Zustand der sich selbst im Labor nicht herstellen lassen wird.
Josef G. schrieb: > Frage zum Verständnis: Dass zwei Flipflops besser sind als eines, > leuchtet mir ein, weil für das Stabilwerden des ersten Flipflops > (fast) die volle Taktperiode zu Verfügung steht, anders als wenn > zwischen dem Eingangs-FF und dem nächstfolgenden auch noch > Logik vorhanden wäre. Servus Josef, ein FF an dessem Eingang ein Signal ZWISCHEN High und Low anliegt (illegaler Pegel), schaltet mit Hoher Wahrscheinlichkeit seinen Ausgang auf einen erlaubten Pegel ('0' oder '1') und nur mit einer geringen Wahrscheinlichkeit auch wieder in einen Zwischenzustand. Die Wahrscheinlichkeit für dieses korrigierende Umschaltverhalten ist unabhängig von der Taktfrequenz und Signallaufzeiten. Weitere FF hinter der Einsynchronisierung "filteren" also immer noch die metastabilen Zustände aus, wenn beim jedem Eintakten das timing verletzt wird und die Taktperiode keine margin mehr für die Erholung aus dem metastabilen Zustand (recovery time) mehr bietet. MfG,
Angehängte Dateien:
-

XAPP094_detail.png
12 KB
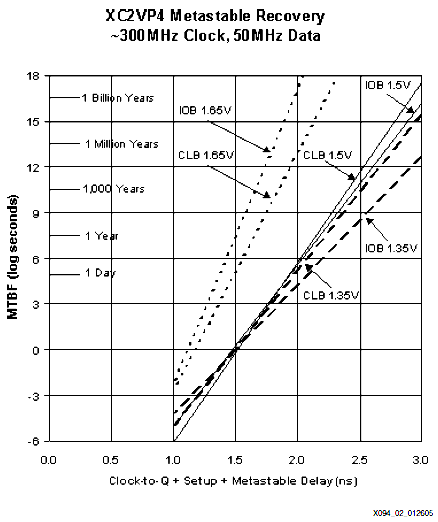
Jan L. schrieb: > Fritz Jaeger schrieb: >> Nun ich empfehle nochmals bei problemen mit den paper sich das das >> andere (Xilinx - Virtex2PRO XAPP096) anzuschauen). Da werden CLB-FF mit >> IO-FF verglichen, und die MTBF für die beiden Eckwerte der >> Corespannungen angegeben (1V65 und 1V35). Die MTBF ändert sich bei >> konstanten slack um mehrere Größenordnungen! > > Die MTBF schwankt um mehrere Größenordnungen, nicht aber tau und darum > ging es. Tau hat eine e^(1/tau) Verbindung zur MTBF. Eine Veränderung > von tau um eine Größenordnung, wie im Paper angenommen, hat daher noch > deutlichere Auswirkungen. Und im XAPP096 finden sich auch die Messwerte > von tau und diese Schwanken zwischen 22.7 und 52ps, also nur rund Faktor > 2 und nicht Faktor 10 wie im Paper angenommen. Daneben sollte auffallen > das 1.35 V und 1.65 V Corespannung deutlich außerhalb der Spezifikation > für einen Virtex 2 Pro ist, eigentlich zulässig sind 1.425V bis 1.575V. OK, ich lese aus dem Text das die Unter-/ resp. Überschreitung bewußt verwendet wurde um Eckwerte im Temperaturbereich nachzustellen, da die messungen nur bei Raumtemperatur durchgeführt worden. > Und bei 3 ns sind die Werte super, egal für welche Flipfloptyp und > welche Versorgungsspannung. Gerade bei Virtex 2 Designs sollten >3 ns > Slack bei ordentlichem Constraining auf jeden Fall zwischen den > Flipflops vorhanden sein. Ja, aber wie die Messungen für den Virtex 5 zeigen, gilt diese Forderung in leicht verschärfter Form auch für diesen. Und da ist es nicht Standard 3ns Slack anzustreben, insbesonders wenn man bei 250 MHz nur 4 ns Budget hat. Zumal man vermeint, schnelle routing-resourcen zu verschwenden, die man anderswo schmerzlich vermisst. Aber das macht gerade den Unterschied zwischen einem "bombensicheren" und einem "Is halt so"-Design aus. MfG, PS ich hänge das besprochenen Diagramm an, es zeigt wirklich gut wie stark sich slack und MTBF beeinflußen (Ordinate ist logarithmisch geteilt)!
Fritz Jaeger schrieb: > Ja, aber wie die Messungen für den Virtex 5 zeigen, gilt diese Forderung > in leicht verschärfter Form auch für diesen. Und da ist es nicht > Standard 3ns Slack anzustreben, insbesonders wenn man bei 250 MHz nur 4 > ns Budget hat. Zumal man vermeint, schnelle routing-resourcen zu > verschwenden, die man anderswo schmerzlich vermisst. Aber das macht > gerade den Unterschied zwischen einem "bombensicheren" und einem "Is > halt so"-Design aus. Naja, mag dort tatsächlich problematisch werden, wobei ich 3ns Slack zwischen den Flipflops durchaus auch bei 4ns gesamt noch ganz gut machbar halte. Die Flipflops kann man ja direkt in benachbarten CLBs plazieren, in ein bis zwei Hops kann man ein Haufen CLBs erreichen und der Routing Delay liegt noch deutlich unter 1ns und weder die Plazierung wird sonderlich schwer noch verbraucht man irgendwelche raren Routingresourcen.
Fritz Jaeger schrieb: > Warum ein ganzes Team von Excel-Wahrscheinlichkeits > jongloren und systemanaylitkern einsetzen, wenn ein zusätzliches FF > richtig eingesetzt die MTBF Das ist doch genau das, was ich sage. Nur präzisiere ich die Aussage dahingehend, dass man die MTBF an irgen detwas was festmachen muss und nicht nur einfach FFs ausgiessen soll, nach der Methode "ich haue mal eine unbekannte Zahl an Sicherheitsmassnahmen rein und dann ist es gut". Denn das Prinzip besteht weiter: Das zusätzliche FF löst das Problem nicht, es reduziert es nur und damit ist die gegebene Vorgehensweise genau die, die ich oben beschreibe: Erst Nachdenken, was man braucht und dann entscheiden, was man tun muss, um es zu erreichen. Ich behaupte nirgends, dass man generell mit einem FF auskommt. Im Gegenteil: Mithin führt eine an Randbedingungen orientierte Entscheidungssweise dazu, dass man in u.U. auch 3 oder mehr FFs einsetzen muss und zwar in genau den Fällen der hohen Taktfrequenz, bei gfs noch ungünstigen bei Bedingungen. Darüber muss man nachdenken. Es ist dazu keinesfalls notwendig, DAFÜR Excelsystemanalyes zu betreiben. Diese muss aus anderen Gründen betrieben werden. Du fokussierst immer noch zu sehr auf dieses eine Problem. Zu ingenieurmässigem Handeln gehört vor allem auch, ein Problem im Gesamtzusammenhang zu sehen und sich von Dogmen zu lösen, die hier z.B. dazu führen, dass die halbe Welt mit 2 FFs einsynchronisier, weil sie es so gelernt haben, ohne zu verstehen, dass das in 98% der Anwendungen zu viel und in 1% der Andwengungen zu wenig ist. Fritz Jaeger schrieb: > Ich verlasse mich nicht auf ein rauschoptimiertes design zur > Kompensation fehldesignter Synchronisierstufen. Es geht genau ums Gegenteil, nämlich den Umstand, dass trotz der von Dir angeführten Gegenmassnahmen (Ablocken etc) ein vielbeschäftigtes FPGA stark rauscht und sich die realen Werte von den Laborwerten stark unterscheiden. Jan L. schrieb: > In deren mathematischem Modell gab es gar kein Rauschen Ganz genau das ist das Problem! Das Rauschen ist aber nötig, um überhaupt eine Entscheidung des FFs herbei zu führen, weil der echte Metazustand sonst ewig dauern würde. Damit stelle ich sofort die Frage, wie sie den simuliert haben wollen, bzw, das, was sie messen, rechnerisch abbilden(?) - Eine mathematisch Betrachtung dieser Problematik ist IMO nicht sinnvoll möglich, da sich das Sytem, je exakter die Flanke getroffen wird, immer chaotischer verhält. Ich halte mich da lieber an praktische Betrachtungen und jetzt kommen wir darauf zurück, dass der nicht simulierbare Fall des sehr lang metastabilen FFs, das noch in die Schaltzeit des Folge-FF reinreichen könnte, eben genau das erfordert, was ich mit den Gegenmassnahmen oben beschreibe: Für die theoretischen Fälle des Fehlschaltens reicht die Grobbetrachtung der Wahrscheinlichkeit und ein Design des Synchronizers nach Datenblatt, dergestalt, dass es im Rahmen der geforderten MTBF nach Lastenheft sicher ist. Ende! Darin enthalten sind alle bekannten Unsicherheiten des FPGA-Verhaltens i.A. seiner Betriebsbedingungen. Für weitergehende Betrachtungen und der Forderung nach "absoluter" Betriebssicherheit, reicht die Theroie nicht aus, weil ich einen immer chaotischeren Fall heranziehen muss, den keiner berechnen kann. Also muss ich annehmen, dass das System trotzdem falsch schalten kann und an anderer Stelle gegenwirken. Es ist dann aber egal, ob es nochmal 5 oder 10 Grössenordnungen (un)wahrscheinlicher ist, weil diese Gefahr längst von anderen dominiert wird und die genaue Grössen unbekannt ist. Es reicht zu wissen, dass sie kleiner ist, als der zuvor angenommene Grenzwert. Die Gegenmassnahmen habe ich auch bereits angedeutet: Fritz Jaeger schrieb: > Anders ist es dagegen bei FSM und > (mit einer geringeren Prio) Zählern. Da sind metastabile Quellen meist > tödlich. Eben nicht! Dort genau muss angesetzt werden, um Schaltungen sicher(er) zu machen, als es im Rahmen der Design-constraints und einem gesunden budget von einer halben ns für die Taktreservn möglich ist. Sobald die Wahrscheinlichkeit der Metaprobleme unter einen gewissen Grenzwert gedrückt wurde (der bereits bei MTBF = Monaten liegen kann), gibt es in jedem halbwegs normalen System sofort viel wahrscheinlichere Ursachen, die zum Ausfall oder unentdeckten Fehler führen können, speziell im Bereich der Analogwertverarbeitung / Messungen. *DAS!* ist der Sollfokus eines sicheren Schaltungsdesigns. Weitere Detailbetrachtungen zur Metastabilität sind unnötig und verstellen nur den Blick auf das Wesentliche. Viele Schaltungen verrennen sich nicht infolge fehlerhafter Synchronisation auf Taktebene, sonden auf der Funktionsebene, weil z.B. während eines gerade gestarteten Initvorgangs nochmal ein Initimpuls von einem Controller kommt oder das Signal analog nicht sauber genug war und das keiner berücksichtigt hat.
Jürgen S. schrieb: >> In deren mathematischem Modell gab es gar kein Rauschen > Ganz genau das ist das Problem! Das Rauschen ist aber nötig, um > überhaupt eine Entscheidung des FFs herbei zu führen, weil der echte > Metazustand sonst ewig dauern würde. Es gibt eben nicht einen Metazustand sondern ganz viele. Und während es in dem mathematischen Modell zwar tatsächlich ein Spannungslevel gibt, bei dem die Schaltung ewig in gleichen Zustand hängen bleibt, geht die Wahrscheinlichkeit gegen 0 Null in genau diesem Zustand zu landen, es ist schließlich nur ein einziger Punkt, jede minimale Abweichung sorgt dafür das die Metastabilität früher oder später aufhört. Landet man irgendwo in der Nähe, hält die Metastabilität umso länger an je näher man an diesem Punkt ist. Das Modell dürfte zumindest für kurze Metastabilität ganz gut hinkommen, aber bei längerer Metastabilität dürfte eher das Rauschen entscheidend für die Dauer sein als ein paar nV Unterschied.
Jan L. schrieb: > Es gibt eben nicht einen Metazustand sondern ganz viele. Sagen wir es besser so: Es gibt viele Schaltverläufe, die als MSZ eingruppiert werden müssen. Jan L. schrieb: > Das Modell dürfte zumindest für kurze > Metastabilität ganz gut hinkommen und genau die ist ja nicht das Problem.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.