Hallo zusammen, ich bin gerade dabei mir einen Überblick über existierende Mehrkern-uCs zu verschaffen. Hier die bisher gefundenen: Propeller ARM Cortex A9 Multi Core XMOS Reihe und verwandt: TI TMS320C647x Multicore DSP Kennt jemand weitere Exemplare? Danke, Stefan
Hallo, solange paralleles Rechnen möglich ist, bin ich für alle Vorschläge offen. Interessant in diesem Zusammenhang ist dann auch die Programmiererfreundlichkeit. Eine Programmierung in C wäre wünschenswert. Gruß, Stefan
Freescale S12X ist allerdings ein µC mit zwei unterschiedlichen Kernen 1x CISC (S12) + 1x RISC (XGate, optimiert auf Portansteuerung und Speicherzugriffe, nicht für komplizierte Berechnungen gedacht)
Freescale: MPC5517 (z1 + z0 Core) MPC5668G (z6 + z0 Core) MPC5644L (z4 + z4 Core) Dann noch die Derivate mit der eTPU, welche auch Multiply/Div usw. in Hardware unterstützt.
Stefan schrieb: > ich bin gerade dabei mir einen Überblick über existierende Mehrkern-uCs > zu verschaffen. Hat das einen besonderen Sinn, oder machst du das einfach zum Spaß? Stefan schrieb: > solange paralleles Rechnen möglich ist, bin ich für alle Vorschläge > offen. Warum müssen die Kerne dann in einem µC sein? Bau doch einfach mehrere ein.
Rolf Magnus schrieb: > Warum müssen die Kerne dann in einem µC sein? Bau doch einfach mehrere > ein. Ich denke mal er möchte die Kerne zusammen rechnen lassen. 2 Singlecores z.b. brauchen deutlich länger eine 32bit Variable zu übertragen als sie einfach aus dem geteilten Ram zu nehmen.
> Kennt jemand weitere Exemplare? SH2A dual SH4A multi http://america.renesas.com/products/mpumcu/multi_core/child_folder/features.jsp Olaf
parallax-propeller: http://www.antratek.com/Parallax_Propeller.html http://forums.parallax.com/forumdisplay.php?f=65
viele atmega auf einem Board ? ergänzt durch einen Chip aus einem Taschenrechner .. als FPU Gruss K.
Morgen, mehrere uC auf eine Platine zu platzieren, wäre natürlich auch eine Möglichkeit. Der Entwurfsaufwand wäre aber höher, als ein fertiges Testboard. Ich lasse mir das aber mal durch den Kopf gehen. Der Propeller kann leider nicht in C programmiert werden - das wäre aber wübschenswert. Der Tricore ist auch nicht ganz was ich suche. Der Peripheriecontroller ist nicht zum Rechnen gedacht und der DSP-Kern verarbeitet nur Festkommazahlen. Gruß, Stefan
Stefan schrieb: > Der Propeller kann leider nicht in C programmiert werden - das wäre aber > wübschenswert. Es gibt sehr wohl C Compiler dafür. Allerdings leidet die Performance gegenüber dem von Parallax favorisierten Assembler-Code erheblich, weil der Code halbinterpretiert aus dem langsamen shared RAM ausgeführt wird.
Mir entzieht sich derzeit noch der Sinn des ganzen (außer vielleicht - was ist machbar mit Parallelisierung). Ob ich jetzt einen µC finde der 2 Kerne mit je 20 MHz hat oder einen µC der zwar nur Single-Core ist, dafür aber 200 MHz...
Von Samsung: Orion: 800-MHz Cortex-A9 dual-core, Samples 3Q10, Massenproduktion 1Q11. Pegasus: 1-GHz Cortex-A9 single-core, Samples 2Q11, Massenproduktion 4Q11. Hercules: 1-GHz Cortex-A9 dual-core, Samples 3Q11, Massenproduktion 1Q12. Mercury: 600-MHz single-core Cortex-A5 (Sparrow) kommt 2010/11. Venus: 600-MHz Cortex-A5 dual-core processor kommt 2012/13. Draco: 1.2-GHz Cortex-A9 dual-core kommt 2012/13. Aquila: 1.2-GHz Cortex-A9 quad-core wird 2012/13 erwartet. Quelle: http://www.netbooknews.de/15520/samsung-smartbooks-mit-arm-cortex-a9-bereits-zum-ende-des-jahres/
Hallo, zunächst danke für die zahlreichen Hinweise. @A. K. Wusste ich noch nicht. Danke. Aber: Fließkommaunterstützung: in Vorbereitung @Jörg B. Es geht um paralleles Rechnen. Und dein Vergleich hinkt doch ziemlich. Ich hatte auch bisher keine Angaben zu Taktraten etc. gemacht. Es ging um eine allgemeine Erhebung. Im Bereich des parallelen Rechnens gibt es den Begriff der superlinearen Beschleunigung der Berechnung. D.h. Beschleunigung größer als die Anzahl beteiligter Prozessoren. Zwei Prozessoren mit 20MHz können sehr wohl schneller ein Ergebnis lieferen, als einer mit 200MHz ... wenn auch unwahrscheinlich. Gruß, Stefan
Die Frage ergibt wenig Sinn. Der Propeller z.B. hat mit dem TMS320C647x ungefähr soviel zu tun wie ein Fahrrad mit einem Eurofighter, es gibt absolut keine Überschneidung im Einsatzbereich.
Vom Mips Bereich gibt es mehrere Multicore Implementationen. Habe mit 17 sowie 34 prozessor-CPU gearbeitet. Im Prinziep sowas wie eine Propeller CPU, nur ordentliche Rechnerkerne, ordentlicher Speicher, mehrere Ebenen von localem und shared Speicher sowie Privilegien und auch externen Speicher sowie zusätzlicher Spezial-Peripherie. Alle Kerne arbeiten Parallel, ein Kern steuert/initialisiert alle, programmupdate begrenzt auf einzelne Kerne während der Laufzeit möglich, extrem schnelle Kommunikation zwischen Kernen mit entsprechenden Buffern sowie zusätzlichen Spezialkernen wie FPU, ... .
chris schrieb: > Habe mit 17 sowie 34 prozessor-CPU gearbeitet. Ich nehme an, die neue SPARC T3 ist für dich auch nur ein besserer Microcontroller ;-).
Stefan schrieb: > Zwei Prozessoren mit 20MHz können sehr wohl > schneller ein Ergebnis lieferen, als einer mit 200MHz ... wenn auch > unwahrscheinlich. Wie soll man das verstehen? 1. finde ich das unlogisch. 2. warum ist es unwarscheinlich? Erzeugt der eine Prozessor Zufallszahlen und der andere prüft ob sie stimmen?
@ A. K. (prx) Nein, und auch wenn das MipsI Cpu sind (4k), zumindest für die Aufgabe waren sie wirklich als Mikrocontroller zu programmieren, jeder Kern, inkl microcoding der Zusatzarchitektur. Für die Interprozesskommunikation usw gab es fertige libs. Aber es stimmt, für ein derartiges Projekt konnte wegen der Resourcenverfügbarkeit eine große Funktionalität sehr effizient und schnell implementiert werden. Dafür gab es haufenweise Bugs, Fallen usw welche man im Schneckentempo im HW-Simulator ergründen konnte. Ich wollte nur darauf hinweisen, daß es in diesem Bereich einiges gibt, speziell auf die 4k Architektur aufgebaut, oder auch auf MIPS-I-- . Da gibt es sehr interessante Sachen, fast alle mit NDA, leider aber verständlich.
Stefan schrieb: > Im Bereich des parallelen Rechnens gibt es den Begriff der superlinearen > Beschleunigung der Berechnung. D.h. Beschleunigung größer als die Anzahl > beteiligter Prozessoren. Glaube nicht das es irgendein reales Beispiel gibt wo dieser Effekt auftritt. In der Realität ist ein 40MHz Prozessor zwei baugleichen 20MHz Prozessoren immer überlegen, was die Geschwindigkeit betrifft.
Stefan schrieb: > Im Bereich des parallelen Rechnens gibt es den Begriff der superlinearen > Beschleunigung der Berechnung. D.h. Beschleunigung größer als die Anzahl > beteiligter Prozessoren. Zwei Prozessoren mit 20MHz können sehr wohl > schneller ein Ergebnis lieferen, als einer mit 200MHz ... wenn auch > unwahrscheinlich. Alexander Schmidt schrieb: > In der Realität ist ein 40MHz Prozessor zwei baugleichen 20MHz > Prozessoren immer überlegen, was die Geschwindigkeit betrifft. Der Effekt tritt in der Realität sehr wohl auf, und zwar insbesondere aufgrund des Cache: Zwei Prozessoren haben zusammen logischerweise doppelt so viel Cache. Wenn der Algorithmus entsprechend aufgeteilt wird, können sich die Cache-Misses dramatisch verringern, weshalb das Programm deutlich schneller als doppelt so schnell laufen kann. Das ist allerdings nicht 'unwahrscheinlich' oder 'wahrscheinlich', sondern kann und muss vor dem Design von Hard- und Software genau entschieden werden. Trotz allem würde es mich sehr interessieren, wofür du die zwei oder mehr Prozessoren brauchst.
bob schrieb: > Der Effekt tritt in der Realität sehr wohl auf, und zwar insbesondere > aufgrund des Cache: Kannst du dafür ein reales Benchmark Beispiel nennen?
> Der Propeller kann leider nicht in C programmiert werden - das wäre aber > wübschenswert. Kann er schon: Proprietär: http://www.imagecraft.com/ Freeware: http://propeller.wikispaces.com/Programming+in+C+-+Catalina http://forums.parallax.com/showthread.php?t=119711
Stefan schrieb: > Zwei Prozessoren mit 20MHz können sehr wohl > schneller ein Ergebnis lieferen, als einer mit 200MHz Im Traum vielleicht... Du vergisst dabei, das der eigentliche Grund für die Einführung von Mehrkernprozessoren nicht das parallele Rechnen war, sondern die Physik einfach der weiteren Steigerung der Taktfrequenzen Grenzen gesetzt hat.
Ich kenne jemand in Silicon Vally, der eine Programmiersprache implementiert, wo jedes Objekt sowie Funktion ein eigener Prozessor ist. Jeder Prozessor hat nur 16(4x4) register Speicher, und kann mit dem jeweiligen 4 Nachbarprozessor seine 4 Register tauschen. Wenn ein Prozessor keine aktiven Ram-Zellen hat, dann hat er auch kein clock. Recht tolle Sache.
Alexander Schmidt schrieb: > Glaube nicht das es irgendein reales Beispiel gibt wo dieser Effekt > auftritt. Simulation von Wärmeableitung (i.e. Die-Kühlkörper-Thermodynamische Simulation) Macht man sich klar und stellt die Aufgabenteilung so ein, dass Teilaufgaben so gestellt werden können, dass z.B. Caches am Optimum arbeiten können, ist die Beschleunigung durchaus größer. Das wird sehr wohl und sehr intensiv in realen Anwenungen genutzt.
Alexander Schmidt schrieb: > bob schrieb: >> Der Effekt tritt in der Realität sehr wohl auf, und zwar insbesondere >> aufgrund des Cache: > > Kannst du dafür ein reales Benchmark Beispiel nennen? Stell dir vor, du hast eine Aufgabe, deren Daten genau halb in den Cache passen. Beispielsweise die Koordinaten bei einer n-Body-Simulation. Da du in jedem Schritt die Koordinaten aller Körper brauchst, wirst du auch in jedem Schritt den Cache vollständig neu aus dem RAM holen müssen. Das kostet extrem Zeit. Wenn du einen zweiten Prozessor dazunimmst, hat also plötzlich die ganze Aufgabe im Cache Platz und du wirst keine Misses mehr haben. Soweit verstanden?
bob schrieb: > Alexander Schmidt schrieb: >> In der Realität ist ein 40MHz Prozessor zwei baugleichen 20MHz >> Prozessoren immer überlegen, was die Geschwindigkeit betrifft. > > Der Effekt tritt in der Realität sehr wohl auf, und zwar insbesondere > aufgrund des Cache: Zwei Prozessoren haben zusammen logischerweise > doppelt so viel Cache. "Logischerweise doppelt so viel" (Naturgesetz?) sicher nicht, da ich den erhöhten Flächenbedarf für die Kerne möglicherweise durch Einsparungen am Cache ausgleichen muss. Aber nehmen wir einfach mal an, dass die Summe größer ist als bei einem einzelnen Kern. > Wenn der Algorithmus entsprechend aufgeteilt wird, können sich die > Cache-Misses dramatisch verringern, weshalb das Programm deutlich > schneller als doppelt so schnell laufen kann. Hier wird freilich impliziert, dass die Daten direkt, d.h ohne Umweg über Unified Cache oder Hauptspeicher, von einem Cache in den anderen wandern können. Das ist eine Eigenschaft die möglicherweise nicht allen hier aufgeführten Systemen gegeben ist. Der Begriff "Mehrkern-µC" ist daher auch etwas ungenau. Ein OMAP4 mit Cortex-A9 MPCore (mit zwei Kernen), DSP, einem ARM968 und zwei Cortex-M3 ist eben kein Hexa-Core. Zudem muss man mögliche Synchronisierungsverluste der Software in Kauf nehmen. Das Phänomen der "superlinearen Beschleunigung" existiert wohl, aber es gibt viel zu beachten, bevor man es beobachten kann. Gruß Marcus
Also das 2 Kerne mehr als doppelt so schnell sein sollen als einer mit doppelter Frequenz glaube ich nicht. Nehmen wir an die Daten liegen bereits im Cache, weil sie gerade initialisiert worden sind. Jetzt beginnt eine Schleife, die im ersten Durchgang lange braucht da ja auch erst mal die Instruktionen in den Cache geladen werden müssen. Nach dem ersten Durchgang liegen alle Daten und alle Instruktionen im Cache. Jetzt läuft alles mit voller Prozessor Geschwindigkeit ab. Jetzt erklärt mir mal einer wie ein zweiter Prozessor das ganze schneller als doppelt so schnell machen kann. Vor allem da er sich nicht den gleichen L1 Cache hat, und wenn er auf Daten im L2 Cache zugreifen möchte und der andere Prozessor auch gerade die gleichen Bereich liest immer mit Waitstates vertröstet wird.
Interessanter ist doch die Frage: Wenn man einen tollen Prozessor gefunden hat und dann wegen der Komponente 'toll' dessen Spezialeigenschaften ausnutzt und damit dann davon abhängig wird... was macht man dann, wenns den Prozessor auf einmal nicht mehr gibt? Also z.B. der Propeller! Wäre da nicht die logische Schlußfolgerung einen zu nehmen, den man durch ein FPGA notfalls ersetzen kann? Antwort: Propeller! Nicht das ich den supertoll fände, aber interessant schon. Zumal bald Propeller 2 kommen soll.
Marcus Harnisch schrieb: > bob schrieb: >> Wenn der Algorithmus entsprechend aufgeteilt wird, können sich die >> Cache-Misses dramatisch verringern, weshalb das Programm deutlich >> schneller als doppelt so schnell laufen kann. > > Hier wird freilich impliziert, dass die Daten direkt, d.h ohne Umweg > über Unified Cache oder Hauptspeicher, von einem Cache in den anderen > wandern können. Nein, wird es nicht. Ich habe die Annahme übersehen, dass beide Prozessoren auf vollständig getrennten Datenbereichen arbeiten. Wie dem auch sei, die Zahl der Anwendungen, die von einer solchen Idealsituation profitieren dürfte recht gering sein. -- Marcus
>Also das 2 Kerne mehr als doppelt so schnell sein sollen als einer mit >doppelter Frequenz glaube ich nicht. Doch, wenn Du eine Echtzeitsystem hast bei dem zwei Prozesse gleichzeitig etwa gleich viel Rechenzeit brauchen. Bei einem Einkernprozessor kostet der Taskwechsel zusätzliche Zeit, die bei zwei Kernen entfällt.
Alexander Schmidt schrieb: > Kannst du dafür ein reales Benchmark Beispiel nennen? Ich warte noch. Alternativ ginge auch ein wissenschaftliches Paper das diesen Effekt bei einer realen Anwendung beschreibt.
Es gab mal wohl von Intel das Statement, daß mehr als 8 Kerne für normale CPUs keinen Sinn machen. Ist aber schon Jahre alt. Auf einem Dual-Core mit WinXP jedenfalls, kriegt man so ca. 50 Prozesse angezeigt. Die werden dann irgendwie auf beide Prozessoren aufgeteilt.
Alexander Schmidt schrieb: > Alexander Schmidt schrieb: >> Kannst du dafür ein reales Benchmark Beispiel nennen? > > Ich warte noch. > Alternativ ginge auch ein wissenschaftliches Paper das diesen Effekt bei > einer realen Anwendung beschreibt. http://www.hipc.org/hipc2008/documents/HiPC-SS08-FinalPapers/1569153777.pdf http://ansys.jp/assets/white-papers/wp-amd-cfx-parallel.pdf http://vgrads.rice.edu/publications/pdfs/Computing_FFT_on_Multicore_Manycore.pdf
Arc Net schrieb: > http://www.hipc.org/hipc2008/documents/HiPC-SS08-F... Hier scheint eins solches "superlineares" Verhalten vorzuliegen. > http://ansys.jp/assets/white-papers/wp-amd-cfx-parallel.pdf Ein Werbeartikel von AMD, bei dem man die Zahlen bei den Diagrammen nicht entziffern kann, weil zu pixelig. > http://vgrads.rice.edu/publications/pdfs/Computing... Hier nicht.
(nicht "Gast") schrieb: > Jetzt erklärt mir mal einer wie ein zweiter Prozessor das ganze > schneller als doppelt so schnell machen kann. Beispiel: Das Beispiel weiterhin: Thermodynamische Simulation. Der Einfachheit halber in einem 2D Querschnitt. Ein einzelner Prozessor muss für jeden Zeitschritt die ganze Fläche bearbeiten. Der Datensatz hat in unserem kleinen Beispiel 5MB. Mit jeder Iteration wird jedes Feld angefasst. Die Cachelines des 3MB Cache wird ständig neu gesichert und geladen, weil er keine Strategie bei gleichverteilten Zugriffen. Jetzt verteile ich das Problem auf zwei Prozessoren dieser Art: Jede CPU muss nur die halbe Datenmenge + die Schnittpunkte zur anderen Datenmenge bearbeiten. Lediglich die Schnittstelle muss in jeder Iteration ausgetauscht werden. Plötzlich geibt es für die Caches eine Strategie weil die jeweilige Teilaufgabe dort vollständig hineinpasst. Er muss nicht ständig geladen und gesichert werden. Dieser Geschwindigkeitsvorteil kann den Mehraufwand durch die Kommunikation deutlich übersteigen.
Grüßt euch, in meinem speziellen Fall geht es um Optimierungen, die nebenläufig abgearbeitet werden sollen. Der numerische Aufwand ist stark an die Initialisierung der Optimierung gebundet, sodass verschiedene Kerne mit verschiedenen Initialisierungen das Optimierungsproblem lösen. Ist die Initialisierung besonders gut gelungen, dann ist nur noch ein geringer Rechenaufwand von Nöten im Vergleich zu einer möglicherweise schlechten Initialisierung im sequentiellen Fall -> superlineare Beschleunigung möglich. Referenz, wenn auch nicht frei zugänglich: S. Behrendt: SIMULATION STUDY OF PARALLEL MODEL PREDICTIVE CONTROL, In Proceedings of 7th EUROSIM Congress on Modelling and Simulation, 2010. Gruß, Stefan
Alexander Schmidt schrieb: > Arc Net schrieb: >> http://www.hipc.org/hipc2008/documents/HiPC-SS08-F... > Hier scheint eins solches "superlineares" Verhalten vorzuliegen. > >> http://ansys.jp/assets/white-papers/wp-amd-cfx-parallel.pdf > Ein Werbeartikel von AMD, bei dem man die Zahlen bei den Diagrammen > nicht entziffern kann, weil zu pixelig. > >> http://vgrads.rice.edu/publications/pdfs/Computing... > Hier nicht. Eigentlich schon... "However, for moderately large sizes, we were able to achieve super linear speedup on SMP machines due to the increase in effective size of cache. This pattern is evident in Figures 9 & 10." Navier-Stokes solver http://nal-ir.nal.res.in/785/1/curr25feba.pdf
@Alexander Schmidt Ansonsten als Gedankenexperiment eines Benchmark-Problems. Du hast n unsortierte Zahlen und suchst eine bestimmtes darin, die im Array z.B. an Position n/2 steht. Bei einem Prozessor müssten also n/2 Vergleiche durchgeführt werden. Bei zwei Prozessoren teilt man den Array auf. Prozessor 1: Array[0...n/2-1] Prozessor 2: Array[n/2 n-1] Der Prozessor 2 würde also den gesuchten Eintrag mit nur einem einzelnen Vergleich ausfindig machen -> superlineare Beschleunigung.
@Maxx wenn solche simulationen nur 5MB hätten dann ja. nur ist das leicht weltfremd. Die haben meist einiges mehr an Daten zu verarbeiten das geheht eher richtung mehrere GB an daten je Itterations schritt. Und dann hast du das Problem, das du den ganzen Datensatz nicht mehr im Speicher halten kannst und auslagern musst. Aufteilen auf 2 Rechner könnte das Problem lösen. nur sollten die Daten der Schnittpunkte schnellgenug ausgetauscht werden. Ethernet ist da noch die langsamere aber günstige möglichkeit. Das sind aber alles Themen aus dem HPC bereich. Solche vergleiche sind immer Problem und Platform abhängig. ein problem kann z.B. auf einer CPU mit doppelt so viel Cach deutlich schneller gelöst werden als nur Faktur 2, wenn dadurch die ganzen Cach Hits und Synchonisationen wegfallen könne. (siehe Beispiel Maxx, auch wenn bei dieser Problemstellung die Annahmen in meinen augen weltfremd sind) und zum ursprünglichen Vergleich. 2 x 20Mhz systeme können Schneller als 1 x 100Mhz sein. Bei gleichen Plattform gegebenheiten sag ich mal nein. Das 100Mhz system ist dem 2*20Mhz System deutlich überlegen. Denn bei 20Mhz heist das für mich. KEIN Cach, Speicher läuft mit CPU Frequenz, no Waitstates, ... Die gleichen Parameter setz ich auch für das 100 Mhz System an. Ändert sich aber die Parameter, kann das ganze wieder anders aussehen. 100Mhz zwar mit Cach, Speicher läuft aber nur mit 66Mhz, braucht aber mindestens 1 Waitstate, ...
Sagen wir so, meine Erfahrung mit dem Mehrprozessorsystem (>10 Kerne) ist schon fast 10 Jahre her. Damals wurde ein 400Mhz PPC mit FPGA noch darum eingesetzt, also insgesamt wenn man alle Takte zusammenzählte waren es mehr als 2Ghz. Heute mit dem Atom CPU bekommt man auch ein oder zwei(thread)kerne mit entsprechender Geschwindigkeit und könnten dasselbe bei equivalenten Kosten mit nur einer cpu realisieren. Damals aber nicht.!! Daneben gibt es aber auch Anwendungen, welche nur als Mehrprozessorensysteme funktionieren, oder auch wo Mehrprozessorensysteme eingesetzte werden, um Asics oder FPGA zu ersetzten. Weiters kenne ich noch ein paar Einsatzgebiete in der Industri im Zusammenhang mit Neuronalen Netzen, Mustererkennung usw.
Arc Net schrieb: >>> http://vgrads.rice.edu/publications/pdfs/Computing... >> Hier nicht. > "However, for moderately large sizes, we were able to achieve super > linear speedup on SMP machines due to the increase in effective size of > cache. This pattern is evident in Figures 9 & 10." Hast du dir die Diagramme mal angeschaut? Die Konstellation für den super-linearen Effekt ist nur bei einem von 36 Simulationsgrößen gegeben. In diesem einen Fall ergibt sich ein Zuwachs von ca. 10 Prozent. Stefan schrieb: > Ansonsten als Gedankenexperiment eines Benchmark-Problems. > > Du hast n unsortierte Zahlen und suchst eine bestimmtes darin, die im > Array z.B. an Position n/2 steht. > Bei einem Prozessor müssten also n/2 Vergleiche durchgeführt werden. > Bei zwei Prozessoren teilt man den Array auf. > Prozessor 1: Array[0...n/2-1] > Prozessor 2: Array[n/2 n-1] > > Der Prozessor 2 würde also den gesuchten Eintrag mit nur einem einzelnen > Vergleich ausfindig machen -> superlineare Beschleunigung. Interesannt. Als ich mir gestern Gedanken über die super-lineare Beschleunigung machte, ging mir ein sehr ähnliches Gedankenexperiment durch den Kopf. Allerdings kam ich zu dem Ergebnis, das diese hier nicht auftritt. Wenn die Liste unsortiert ist, dann ist gesuchte Zahl zufällig im Array verteilt. Und somit deckst du mit dem Fall "Zahl an der Stelle n/2" nur einen kleinen Ausschnitt des Problems ab. Wenn du alle Fälle - also die alle Positionen der Zahl im Array - zusammenfasst dann ergibt sich keine super-lineare Beschleunigung.
LTspice nutzt doch in der neuen Version mehrere Kerne. Da gibts Benchmark an realen Schaltungen und dieses Programm wäre dann auch nicht off-Website wie wohl die meisten obigen Beispiele.
123 schrieb: > wenn solche simulationen nur 5MB hätten dann ja. nur ist das leicht > weltfremd. Es ist halt angepasst auf eine einfache Erklärung. Wenn ich jetzt mit den inhomogenen Clustern gekommen wäre auf denen mir das Problem praktisch begegnet ist, wär daraus ein etwas längeres Paper geworden.
@Alexander Schmidt Das ist richtig. Eine superlineare Beschleunigung zu erreichen, ist nicht der Regelfall. Dennoch ist dies eines der Wirkprinzipien dahinter. Bei meinem Problem (s. vorherigen Post) tritt aber genau diese Konstellation ausgerechnet bei hohen Laufzeiten auf. Daher ist die Parallelisierung zweckmäßig.
Morgen, @ich an eine FPGA-Lösung hatte ich bereits gedacht, aber ich bin für meinen Teil auf Fließkommaunterstütznug angewiesen. Erste Gehversuche in der Richtung haben gezeigt, dass die erreichbare Taktrate des FPGA bei einer FPU stark sinkt. Ich habe damals mit dem Virtex-4 gearbeitet und obwohl er bis 150MHz getaktet werden kann, ist die Taktrate mit FPU-Implementierung auf 20MHz gefallen. Diese Erkenntnis und der hohe Entwicklungsaufwand sind bei der Verfügbarkeit von Mehrkern-uCs nicht zu rechtfertigen. Gruß, Stefan
Hallo zusammen, noch einmal zur Existenz von superlinearer Beschleunigung der Berechnung. Diese Artikel dürfte für die Interessierenden von Belang sein: Akl - Superlinear Performance In Real-Time Parallel Computation http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.57.7777&rep=rep1&type=pdf Gruß, Stefan
Stefan schrieb: > Akl - Superlinear Performance In Real-Time Parallel Computation > http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.57.7777&rep=rep1&type=pdf Hast du das überhaupt durchgelesen? Was da drinsteht hat mit superlinearer Beschleunigung nichts zu tun. Es geht im Kern darum, dass man manche Echtzeitanwendungen nur mit n Prozessoren lösen kann, weil 1 Prozessor zu langsam ist. Das ist m.M.n. kein superlineares Verhalten.
Hallo, ich habe es gelesen. Es werden Probleme diskutiert und unter Annahme einer bestimmten, das Problem betreffenden Anzahl an beteiligten Prozessoren stellt sich superlineare Beschleunigung ein. Aus Abschnitt 3.2: Speedup. The speedup provided by P over S is speedup(1; n) = (n + 2^n)/(n + 1), which is superlinear in n, and evidently the speedup theorem fails in this case as well. Gruß, Stefan
Angehängte Dateien:
-

3.2.2.jpg
17 KB
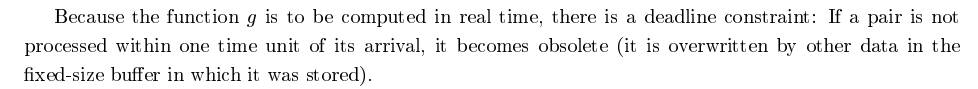
Stefan schrieb: > Speedup. The speedup provided by P over S is speedup(1; n) = (n + > 2^n)/(n + 1), which is superlinear in n, and evidently the speedup > theorem fails in this case as well. Das ist nur unter der Prämisse gültig, dass hier ein Echtzeitsystem vorliegt, dass Daten so schnell verarbeiten muss wie sie eintreffen.
Alexander Schmidt schrieb: > Das ist nur unter der Prämisse gültig, dass hier ein Echtzeitsystem > vorliegt, dass Daten so schnell verarbeiten muss wie sie eintreffen. Ist vielleicht etwas speziell! In dem Beitrag http://www.springerlink.com/content/pum235ttq0836l16/fulltext.pdf geht es um parallele Suche. Hierbei wird lediglich eine Lösung gesucht und dann die Suche abgebrochen. Nun kann es bei günstiger Konstellation zu superlinearer Beschleunigung kommen, wenn einer der Prozessoren in von ihm zu verarbeitenden Teilraum sehr schnell die Lösung findet. Die superlineare Beschleunigung ist allerdings keinesfalls garantiert. Generell kann meiner Meinung nach nur bei Vorhandensein solcher Abbruchkriterien eine solche Beschleunigung vorkommen. Solch ein Szenario kann ich mir auch bei Datenbanksuchen vorstellen, um die Praxisrelevanz herzustellen. Ich bin weiterhin an einer regen Diskussion interessiert! Gibt es noch weitere Hinweise auf Mehrkern-uCs? Gruß, Stefan
Passt auch zum Thema: http://www.heise.de/newsticker/meldung/Sparsamer-Forth-Mikrocontroller-mit-144-Kernen-1122006.html "... 144 einzelne 18-Bit-Forth-Mikrocontroller des Typs F18A mit jeweils eigenem RAM und ROM (je 64 18-Bit-Words) ..."
Die rege Diskussion wird durch das Posten von Springer-Links sicherlich nicht angefeuert. Die Inhalte dort sind Normalsterblichen verwert.
Stefan schrieb: > http://www.springerlink.com/content/pum235ttq0836l... Auf das Paper habe ich von hier keinen Zugriff, werde ich bei Gelegenheit in der Uni anschauen. > geht es um parallele Suche. Hierbei wird lediglich eine Lösung gesucht > und dann die Suche abgebrochen. Nun kann es bei günstiger Konstellation > zu superlinearer Beschleunigung kommen, wenn einer der Prozessoren in > von ihm zu verarbeitenden Teilraum sehr schnell die Lösung findet. Genau das meine ich auch. Wenn eine Proz. die Aufgabe löst können die anderen sofort aufhören. Je nachdem wann wo die Lösung im Suchraum ist kann das /in einem Versuch/ mit mehreren Prozessoren länger oder kürzer dauern als mit einem einzelnen. Wenn man sich jedoch anschaut was passiert wenn man über mehrere Versuche mittelt, dann sieht man das hier kein superlin. Beschleunigung auftreten kann. Ist die Lösung im Suchraum gleichverteilt, dann gibt es auch keine superlineare Beschleunigung. Weil die durchschnittliche Suchzeit mit n Prozessoren 1/n ist. Den Fall mit nicht gleichverteilten Lösungen im Suchraum habe ich jetzt noch nicht durchgedacht, aber auch hier müsste es analog durchschnittlich keine schneller Lösung geben. > Gibt es noch weitere Hinweise auf Mehrkern-uCs? Propellor, wurde zwar schon genannt ist aber schnell und explizit als Mehrkerner erfunden.
Abdul K. schrieb: > Die rege Diskussion wird durch das Posten von Springer-Links sicherlich > nicht angefeuert. Die Inhalte dort sind Normalsterblichen verwert. Eigenartig. Ich habe auch außerhalb der Hochschulumgebung Zugriff auf den verlinkten Inhalt. Der Artikel ist sonst auch unter ftp://ftp.cs.utexas.edu/pub/AI-Lab/tech-reports/UT-AI-TR-88-80.pdf erreichbar. @Εrnst B✶ Interessant. Aber Zitat: 'ab dem zweiten Quartal 2011 ausliefern zu können'. @Alexander Schmidt Zuerst ein kleines Beispiel (ähnlich deinem) und dann meine Gedanken dazu. Wir haben eine Matrix (Matlab-Notation) A=(1 2 3 4 ; 5 6 7 8 ; 9 10 11 12; 13 14 15 16) Ziel ist es nun eine bestimmte Zahl zu finden und dann kann abgebrochen werden. Da ich es nicht besser weiß, durchsuche ich die Matrix zeilenweise. D.h. im seq. Lauf: Ges. 1 - 1 Vergleich notwendig 2 - 2 Vergleiche usw. Das sind dann im Mittel (1+2+3+4+...+16)/16 = 8.5 Vergleiche. Jetzt will ich vier Prozessoren nutzen. Spalte also meine Matrix auf (jeweiles einen 2x2 Block): A1=(1 2;5 6) A2=(3 4;7 8) usw. Dann kann man auf dem Papier mal nachvollziehen, wie viele Vergleich notwendig sind. D.h. im par. Lauf: Ges. 1 - 1 Vergleich 2 - 2 Vergleiche 3 - 1 Vergleich 4 - 2 5 - 3 6 - 4 7 - 3 8 - 4 9 - 1 10 - 2 11 - 1 12 - 2 13 - 3 14 - 4 15 - 3 16 - 4 Das sind dann im Mittel 2.5 Vergleiche und somit keine superlineare Beschleunigung im Mittel - richtig. Ich sehe das aber isolierter. Der Speedup ist definiert als seq. Laufzeit geteilt durch par. Laufzeit - unabhängig vom Problem und den Daten! Hier ist der Speedup aber datenabhängig. Sollte ich also die 9 suchen, dann hätte ich in diesem isolierten Fall superlineare Beschleunigung - auch wenn das im Mittel nicht der Fall ist. Über alle Daten tritt superlineare Beschleunigung in immerhin 37.5% aller Fälle auf. Gruß, Stefan
Stefan schrieb: > Sollte ich also die 9 suchen, dann hätte ich in diesem isolierten Fall > superlineare Beschleunigung - auch wenn das im Mittel nicht der Fall Du darfst aber den Ort der Lösung nicht als gegeben ansehen, weil du sonst die Lösung auch schon kennst.
Stefan schrieb: > Abdul K. schrieb: >> Die rege Diskussion wird durch das Posten von Springer-Links sicherlich >> nicht angefeuert. Die Inhalte dort sind Normalsterblichen verwert. > > Eigenartig. Ich habe auch außerhalb der Hochschulumgebung Zugriff auf > den verlinkten Inhalt. > Der Artikel ist sonst auch unter > > ftp://ftp.cs.utexas.edu/pub/AI-Lab/tech-reports/UT-AI-TR-88-80.pdf > Ah danke. Bei Springerlink kommt bei mir nur Müll zurück. Die filtern halt nach IP oder Cookie. Warum stellt jemand seinen Artikel zu Springer, wenn er das genauso gut per Internet und Google verbreiten kann?
Abdul K. schrieb: > Warum stellt jemand seinen Artikel zu Springer, wenn er das genauso gut > per Internet und Google verbreiten kann? Man pubziliziert in einer Fachzeitschrift, um auf interessiertes Fachpublikum zu stoßen. Die Zeitschrift wird in diesem Fall von Springer veröffentlicht.
Hallo zusammen, > Du darfst aber den Ort der Lösung nicht als gegeben ansehen, weil du > sonst die Lösung auch schon kennst. Über dieses Argument musste ich eine Weile nachdenken ... und dir recht geben. Daher präzisiere ich meine Aussage und stelle fest, dass der Algorithmus superlineare Beschleunigung für bestimmte gesuchte Werte erreicht. Aus ingenieurstechnischer Perspektive ist das Ergebnis dennoch interessant, da die Beschleunigung superlinear ausfällt für gesuchte Werte, die bei der sequeziellen Suche eine hohe Anzahl an Operationen erfordert. Im Falle eines Echtzeitsystems also, bei dem die maximale Ausführungszeit relevant ist, ist dieser Umstand also sehr willkommen. GRuß, Stefan
Meine Suche schaut aber abwechselnd an den Anfang und die Mitte der Daten, also bei Hausnummer 10 Datens ist die Suchreihenfolge: 1 6 2 7 3 8 4 9 5 10 Und siehe da, parallele Verarbeitung mit zwei Kernen bringt nur eine lineare Beschleunigung. Und maximale Ausführungszeit ist bei deiner Suche auch linear, denn das Maximum hat man immer dann, wenn die gesuchte Zahl die letzte kontrollierte ist.
Tja, so ist das mit Beispielen ... sie hinken. Falls noch jemand einige Tipps oder Links zu Mehrkern-Mikrocontrollern hat, ist er oder sie willkommen. GRuß, Stefan
Danke Horst, das nenne ich mal hilfreich. Das Board ist tatsächlich sehr interessant. Gruß, Stefan
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.