Hallo, Ich möchte relativ schnell recht umfangereiche Berechnungen im FPGA ausführen. Es handelt sich um ca 20 Multiplikationen, mehrere Divisionen, Wurzel ziehen und etlichen IF verzweigungen, sowie SUB/ADDs. Es handelt sich um ca 15 Eingangsvariablen 18 bit und ergibt ein paar Ausgangsvariablen 12 Bit. Ich hab dazu max 6us Zeit. *Kurzversion meiner Frage:* Wie Implementiert man umfangreiche Berechnungen in VHDL, wenn man keinen Softcore verwenden kann/will? Dankeschön für Anregungen! --------------------------------------------------- *Langversion meiner Frage:* Wie implementiert man das am besten? Mathematisch kann ich meistens 2-5 Rechenschritte parallel ausführen, so dass ich nun eine FSM geschrieben hab, welche alles in knapp 25 CASE-Anweisungen, (70Takte, 700ns) abarbeitet. Die FSM ist daher nun auch linear aufgebaut, es gibt keine Verzweigungen. Durch die hohe Zahl von in+outputs und die großen Busse zu meinen Muliplikatoren und Divisions-Entitys wird mir eine sehr große Final State Machine mit unglaublichen vielen und großen Multiplexern, welche mir sämtliche Signale zu allen Stufen routen, erzeugt. Mein Problem ist nun, dass ich noch viel mehr Funktionalität und lineare Rechnungen implementieren will, und ich befürchte, dass eine FSM nicht der richtige Weg dazu ist, da jeder neue Schritt immer noch mehr Logik durch Multiplexer frisst. Sozusagen braucht jeder "Befehl", der in einem uC ein paar Wörter Flash-Speicher belegen würde, in der FSM hunderte bis tausende Logikgatter. Das kanns ja nicht sein ;-) Führt hierbei früher oder später kein Weg an einem SoftCore vorbei, oder gibt es sonst noch tolle Möglichkeiten, sinnvoll viele +-*/ - Berechnungen in VHDL/FPGA zu implementieren ? Dankeschön für jedes Stichwort/Anregung/ jeden Tip.
Nun ja, das alles ist ja ein Datenfluss. Dementsprechend kann man das schonmal gepipelined implementieren. Und ja solche Berechnungen kosten Ressourcen, da wirst du nicht allzuviel ändern können. Nichtsdestotrotz könnte man spezifischer antworten wenn du die Berechnungen die du machst mal genau darlegst.
Den Programmcode und das VHDL geschriebene möchte ich nicht direkt kopieren, da ich am gleichen Thema privat, als auch an der Diplomarbeit arbeite. Ich möchte nicht, dass irgendwann irgendjemand jammert dass ich mein Zeug nicht selber mache würde. (Daher habe ich erst selbst nun etwas funktionsfähiges implementiert, was aktuell extrem gut läuft, aber ich aber ich mit der Umsetzung nicht wirklich zufrieden bin) Es geht aber darum das ein paar Eckdaten (Ströme, Schaltzeitpunkte etc) eines resonanten Konverters wärend der Laufzeit zu berechnen und somit meiner Regelung/Steuerung schon im Vorraus wertvolle Daten über die Zustandsvariablen zu liefern. Dazu gibt es viele Eingangsvariablen wie Ströme, Spannungen, Regelwerte, welche alle nacheinander (teils von anderen VHDL Modulen) hereinpurzeln und berechnet werden sollten. Das schaut ca. so aus: MATLAB: slope = U / L; Udiff = U - Uout; Imax = sf* Modul(udiff); Q = shift(t1 * Imax/2,4); t2 = shift(sqrt(sf*Q*2/Udiff), 19); if t2 >= t_resonant then Qback = t4* Q/Im - I4; else QBack = Q_min etc.. etc.. .... Ds hier ist natürlich nur schnell hingekritzelt und zeigt die Art der Berechnung. Für die sehr große Zahlendynamik sind auch sehr viele shiftoperationen dabei. Mein VHDL code sieht dazu ca. so aus, ebenfalls hier nur schnell nicht funktionsfähig gefreestyled:
1 | case STATE |
2 | |
3 | when STEP1 => |
4 | div_non <= U; |
5 | div_den <= "00" & L (18 downto 2); |
6 | temp18A <= U - Uout; |
7 | NEXT_STEP <= STEP2 |
8 | |
9 | ....
|
10 | |
11 | when STEP4 => |
12 | sqrt_in <= "11" & multA_out(30 downto 19); |
13 | NEXT_STEP <= STEP5 |
14 | |
15 | ....
|
16 | when STEP25 => |
17 | outa <= TEMP18E; |
18 | outb <= ...; |
19 | |
20 | end case |
Die Frage ist ob du mehrere Datenwerte hast, welche parallel verarbeitet werden sollen. z.b. Wert 1 hängt noch in Schritt 5, Wert 2 in Schritt 11 usw Falls ja kannst du dir die FSM sparen und gleich eine Pipeline draus machen. Falls nein, solltest du überlegen welche Schritte gleich behandelt werden können. Bsp: 2 Multiplikationen. Diese können dann die gleiche Hardware nutzen und die Eingänge werden nur per MUX umgeschalten. Dazu musst du ggf Schritte aussplitten. Überleg dir gegenbenfalls auch, ob du bestimmte Berechnungen so umformen kannst das sie gleiche Hardware nutzen können. Achja: das du durch Umstellen versuchen solltest die Divisionen und Wurzelberechnungen zu eliminieren muss man wohl nicht erwähnen. Achja, bzgl Softcore: Mit 6 us hast du je nach Taktrate (ich setze mal 100 MHz als Maximum für den Softcore an) knapp über 500 Takte zur Verfügung. Eine Division dauert je nach Implementierung dann 20-30 solcher Takte, Wurzel dürfte ähnlich sein. Sonstige Befehle würde ich mit 2 Takten veranschlagen.(Multiplikation auch). Geht sicher alles auch etwas schneller, aber es bringt nix damit zu planen nur um später festzustellen das es doch nicht reicht. So kannst du dir aber überschlagen ob das passt.
Danke für die Antworten :-) > Die Frage ist ob du mehrere Datenwerte hast, welche parallel verarbeitet > werden sollen. > z.b. Wert 1 hängt noch in Schritt 5, Wert 2 in Schritt 11 usw Ja, da hab ich schon einiges optimiert. Also ich könnte noch mehr parallelisieren, d.h. noch z.B. 2 Hardwaremultiplizierer einbauen, aber im Prinzip geht es zur Zeit schnell genug (ca 700ns), so dass ich eigentlich etwas mehr auf die Gatteranzahl achten möchte für meine nun anstehenden Erweiterungen. > Falls ja kannst du dir die FSM sparen und gleich eine Pipeline draus > machen. Versteh ich das richtig, du meinst sozusagen "voll gepipelined", also zwischen jedem Berechnungsschritt einmal FF puffer und jede Operation hat ihre Logik ? Dazu bräuchte ich dann praktisch für z.B. 20 Multiplikationen auch 20 (HW) Multiplikatoren ? Hmm.. > Falls nein, solltest du überlegen welche Schritte gleich behandelt > werden können. > > Bsp: 2 Multiplikationen. Diese können dann die gleiche Hardware nutzen > und die Eingänge werden nur per MUX umgeschalten. Gut, das habe ich versucht durch die FSM zu lösen. Die IOs sind ja in der FSM für jeden STATE exklusiv gemuxed, daher hab ich von überall zugriff auf alles -> große logik. Hmm, oder meinst du das ich es pipline und dann so ein token-ähnliches prinzip verwende (token für mult-zugriff wird weitergereicht in der pipeline) um die Multiplikatoren zuzuweisen ? Grübel Das wäre witzig. Dann müsste ich nurnoch die Multis umschalten, würde wohl viel Multiplexer sparen. Schick :-) Hm, gefällt mir. > Dazu musst du ggf Schritte aussplitten. > > Überleg dir gegenbenfalls auch, ob du bestimmte Berechnungen so umformen > kannst das sie gleiche Hardware nutzen können. Ja da habe ich tatsächlich ähnliche Rechenschritte, jedoch habe ich mir noch kein floating-point-zahlenformat implementiert, so dass ich tatsächlich bei jedem schritt etwas anders shiften muss und somit bisher kein schritt identisch ist. Aber ich schreib mir wohl einen eigenen kleinen FP-multiplizierer und ALU, dann kann ich ein paar schritte wiederverwenden. Aber der Aufwand lohnt sich bis jetzt (noch) nicht. > > Achja: das du durch Umstellen versuchen solltest die Divisionen und > Wurzelberechnungen zu eliminieren muss man wohl nicht erwähnen. > Joa, um 3 Divs komme ich nicht herum, da immer 3 neue Messwerte von ADCs im Nenner liegen. Für alle anderen Berechnungen arbeite ich mit Inverswerten von L, Korrekturfaktoren etc.. > Achja, bzgl Softcore: > Eine Division dauert je nach Implementierung dann 20-30 solcher Takte, > Wurzel dürfte ähnlich sein. Sonstige Befehle würde ich mit 2 Takten > veranschlagen.(Multiplikation auch). Geht sicher alles auch etwas > schneller, aber es bringt nix damit zu planen nur um später > festzustellen das es doch nicht reicht. > So kannst du dir aber überschlagen ob das passt. Ich hab aber noch das Problem dass ich entweder auch dort shiften muss (zusätzliche takte) oder FP zahlen verwenden muss, welche aber auch mit angepassten FP-Units ihre paar 10 clk's brauchen. Dazu muss ich plötzlich jede Vergleichsoperation, addition etc auch in FP-Units ausführen lassen, wodurch dann doch einige hundert Schritte zusammenkommen (ca 70 Zeilen Matlabcode). Ausserdem haben die meisten SoftCores ja auch nur eine ALU, so dass ich garnichts mehr parallelisieren kann nehme ich an ? Ich habe eine Softcore daher eigentlich schon ausgeschlossen, weil es wohl sehr sehr knapp wird und jede us Berechnungsdauer Totzeit in mein System bringt und den ganzen tollen Vorteil des Aufwands wieder schmälert ;-) Ja also wie ich das rauslese gibts allgemein die Lösung Pipeline, FSM oder Softcore. Gut, ich schau mal ob ich was Gewinne wenn ich die Multiplexer der FMS in FFs der Pipeline umbaue^^. Wahrscheinlich hab ich zumindest einen Geschwindigkeitsvorteil gratis nehme ich an.
Ich sehe hier wenig Bedarf für eine state machine. Die vielen MUXER fressen nur viele Resourcen und Zeit. Das einizge, was man multiplexen und damit für verschiedene Stellen der Rechnung nutzen sollte, sind die Cores für Division und Wurzelziehen. Einmal müssen sie eh instanziert werden und dann kann man sie auch gkeich verketten.
Angehängte Dateien:
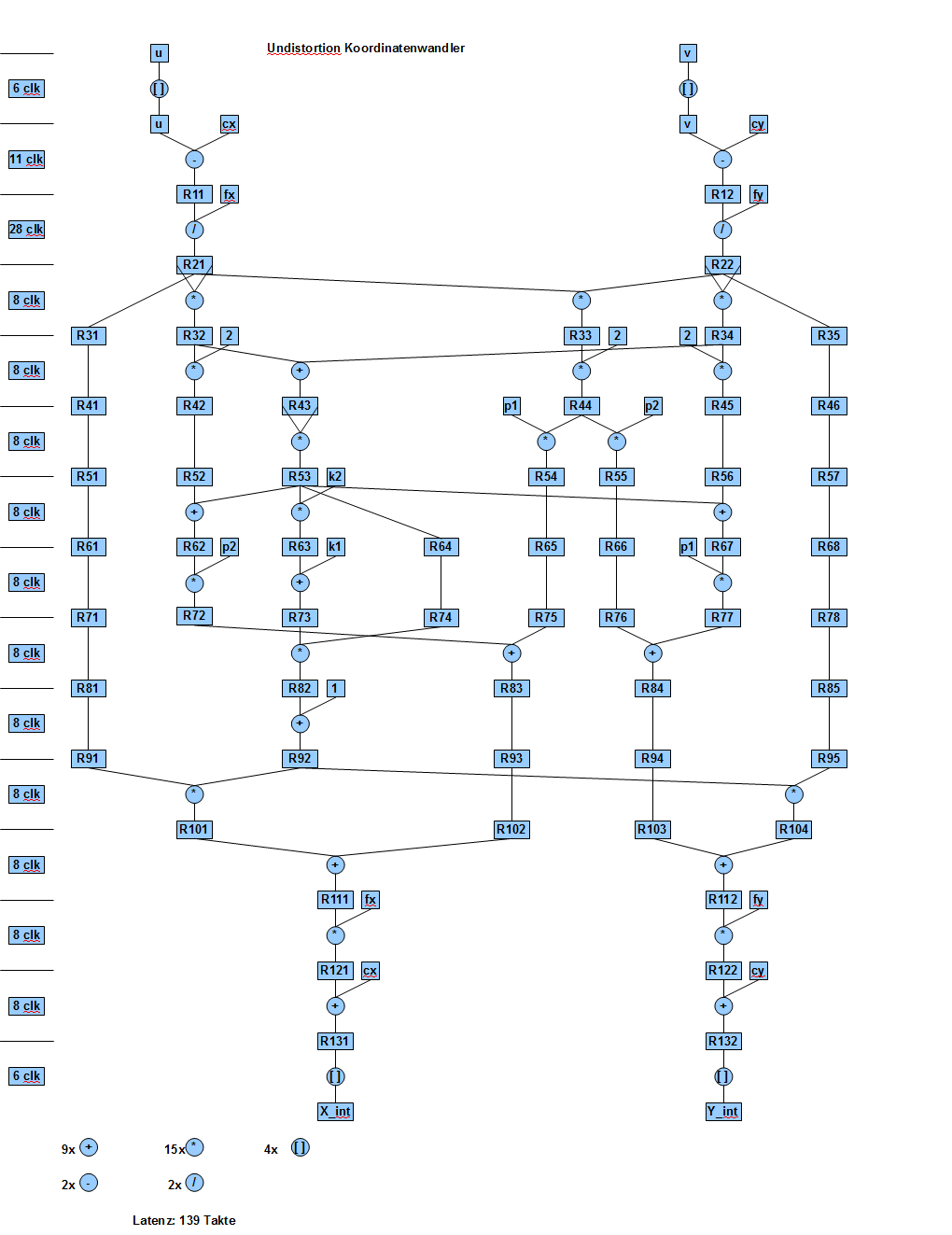
Ich hatte an sowas gedacht (siehe Anhang). Das ist ein Auszug aus meiner Studienarbeit. Hier ging es um eine 32bit Floating-Point Koordinatenwandlung, es wurde so designed dass ich mit jedem Takt eine neue Koordinate anelgen kann und nach einer gewissen Latenz die gewandelten Koordinaten wieder eine pro Takt rausbekomme
Eigentlich brauchst Du fast keine Multiplexer. Du könntest statt lauter FlipFlops für die Ein- und Ausgabewerte z.B. nur ein RAM Block nehmen (als dual ported ram) und dir eine mini-ALU darum aufbauen. Per State machine würdest Du die Adresse für die zwei Operanden aus dem RAM wählen und der ALU den zugehörige Rechenoperation mitteilen. Wenn das Ergebnis vorliegt kannst Du per Statemachine einen Schreibbefehl in denselben RAM Block ausführen. Somit könntest Du die Logikaufwand auf einen Multiplizierer und einen Volladdierer beschränken.
Danke für die Einschätzungen. Ich bin gerade dabei das Ganze umzuschreiben und große Blöcke zu pipelinen und die entstandenen Blöcke mit einer FSM zu bedienen, wodurch ich manche Blöcke öfter verwenden kann und die FSM selbst nur ein paar States hat. Michael O. schrieb: > Du könntest statt lauter FlipFlops für die Ein- und Ausgabewerte z.B. > nur ein RAM Block nehmen (als dual ported ram) und dir eine mini-ALU > darum aufbauen. > Per State machine würdest Du die Adresse für die zwei Operanden aus dem > RAM wählen und der ALU den zugehörige Rechenoperation mitteilen. Wenn > das Ergebnis vorliegt kannst Du per Statemachine einen Schreibbefehl in > denselben RAM Block ausführen. Hört sich an wie ein klassisches Rechenwerk mit ALU und Speicherkontroller an. Nur die Befehle wären fest im Steuerwerk/FSM verankert. > Somit könntest Du die Logikaufwand auf einen Multiplizierer und einen > Volladdierer beschränken. Ja, ich dachte auch schon daran selbst einen passenden "Prozessor" zu schreiben. Nur fehlen dann neben Divisionseinheit, Multiplizierer und Volladdierer dann noch ein Größenvergleich/Verzweigungsbefehl, Sprungbefehl, evtl Shiftoperation, und IO Befehle. Ausserdem müsste dieses Rechenwerk auch wieder Operationen parallel verarbeiten können etc.. Wäre sicher intressant und möglich, aber ist mir gerade zu aufwendig, da mein eigentliches Ziel und Inhalt meiner Arbeit ganz woanders liegt, der VHDL Teil ist bloß mein Mittel es zu Implementieren. Thx an alle!
Die Frage ist doch, mit welcher Datenrate dort diese "u","v" reinkommen. Wenn die 180 Takte Latenz stimmen, hast du bei 90MHz eben genau 500kHz Datenrate. Wenn dies reichen -> state machine nutzen und resourcen sparen.
Hallbergmoser schrieb: > Die Frage ist doch, mit welcher Datenrate dort diese "u","v" reinkommen. > Wenn die 180 Takte Latenz stimmen, hast du bei 90MHz eben genau 500kHz > Datenrate. Wenn dies reichen -> state machine nutzen und resourcen > sparen. Falsch. Mit jedem Takt stecke ich einen Wert hinein und nach 139 Takten bekomme ich mit jedem Takt einen Wert heraus (falls du mich meintest).
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.