Ich benötige für einige rechenintensive Applikationen ein Board, das möglichst viel FPGA-Power hat aber mit einer kostenfreien FPGA-Software konfigurierbar ist. Altera oder Xilinx wäre erst mal egal. Leider können die freien Versionen regelmäßig nur die mickrigen FPGAs, daher suche ich jetzt etwas, das mehrere FPGAs enthält. Kennt da einer ein System? Es gingen auch mehrere kleine Boards, die man zusammenschalten kann. Ich bräuchte dann so eine Art Modulsystem. Ich denke da an EVAL-boards, aber die haben gleich wieder viel zuviel drauf. Gefunden habe ich nur diese Copacobana-Ding, aber das ist oversized und ausserdem melden die sich nicht.
Robert schrieb: > Kennt da einer ein System? Immer wieder gern genommen: http://www.dinigroup.com/new/index.php Ernsthaft. Wer mehrere FPGA's kaufen will, hat auch das Geld um sich einen größeren FPGA + Software zu kaufen. Nicht zu vergessen, daß man auch Manpower braucht um den/die FPGA(s) zu füllen. Duke
Die Manpower habe/bin ich. Und die benötigten Cores hintereinander zu quetschen geht schneller, als die Synthesen dann dauern. Ich brauche einfach den Platz. Ausserdem sind auch größere FPGAs auf den EVAL-boards rasch voll. Man kann zwar neue kaufen, aber da ist viel zuviel Schnickschnack drauf. DNI kenne ich natürlich auch. Die Boards rangieren im 5-stelligen Bereich. Dann kaufe ich lieber ein paar V4-boards von xilinx und habe es für 1/10. Optimal wäre ein header board, mit nur dem FPGA und einem Config-Flash, das aber kaskadierbar ist. Trenz hat S3DSP boards habe ich gesehen, kosten 169,-. Dann kann ich allein für die jährliche Xilinx-Lizenz 15 Stück kaufen.
Robert schrieb: > Optimal wäre ein header board, mit nur dem FPGA und einem Config-Flash, > das aber kaskadierbar ist. Ok. > Trenz hat S3DSP boards habe ich gesehen, kosten 169,-. Die Trenz-Mikromodule sind m.W. nach auch kaskadierbar (mit bestimmten Einschränkungen). Ich glaube das der Markt für das, was Du suchst ist relativ dünn ist. Mir fällt dazu auch nur Trenz und Copacabana ein. Duke
Na dann wird es das wohl werden. Haben ja auch eine EAGLE Lib für eigene Trägerboards. Wäre schon mal die Verschaltung gelöst. Vielleicht finde ich ja aber auch noch was anderes.
Auf Opencores gibt es ein Projekt Gecko3 bei dem wie es aussieht mehrere FPGA-Boards kaskadiert werden können. Allerdings ist 'möglichst viel FPGA-Power' reichlich unscharf: Wie oft bekommst Du Deinen Core in diesen oder jenen FPGA, wieviel internen und externen Speicher brauchst Du, und wie groß ist der Bandbreitenbedarf?
Duke Scarring schrieb: > Die Trenz-Mikromodule sind m.W. nach auch kaskadierbar (mit bestimmten > Einschränkungen). Max 2. Stück - Aber auf dem Prinzip kann man ja was eigenes Bauen
2 Stück gehen beim den Trenzmodulen wohl Huckepack, wie ich sehe. Das wäre schon ok, solange ich mehrere auf ein Trägeerboard bringen kann. Das müsste ich sowieso bauen. Das Fraunhoferzeug ist mir etwas suspekt. Da hat man keine Liefergarantien, wenn man doch was Professionelles draus machen will. Ausserdem zu LTE-lastig. Das Prototyping board ginge einigermassen, aber ich sehe keine Preise. Ich habe jetzt diese Module ausgegraben: http://www.simple-solutions.de (Zefant) preislich ok und alt genug, damit es lange genug im Markt ist und man auch noch nachkaufen kann.
Also, es werden die Trenzmodule. Die Spartan 3A DSPs sind derart gut ausgebaut, dass sie die anderen boards schlagen und zudem ist das Ding noch billig. > Wie oft bekommst Du Deinen Core in diesen oder jenen FPGA, Ich brauche für die minimale Applikation ohne hohe Auflösung schon fast einen S3E für Interfaces und Verwaltung und kann dann noch nicht viel rechnen. Je nach Matrixgrösse brauche ich deutlich mehr. Ein Beispiel sind 6 DSP-Elemente vom S3-Typ, Zelle -> 4x4 -> 96 DSPs. Da läuft der ja schon über. > wieviel internen und externen Speicher brauchst Du, intern hätte man mit einem FPGA genug, um das zu speichern, was 1 FPGa an Operatoren beherbergt, weil viele pipieline und Register ist und temporär exisitiert. > und wie groß ist der Bandbreitenbedarf n 2 (100Msps/200Msps) mit n= 4..32. Das ist aber weniger das Problem. Es geht eher um Platz, z.B. für mehrere parallele FFTs und Schätzarchitekturen: Mehrere Pfade rechnen dasselbe mit denselben Daten und man kann Ergebnisse vergleichen. Je mehr Platz, desto mehr geht gleichzeitig, statt hintereinander in einem anderen Durchlauf und produktive Ergebnisse brauchen garnicht erst für später gespeichert zu werden. Wieviel man am Ende braucht, muss man sehen. Daher muss ich zulaufen können.
Angehängte Dateien:
-

fpga-audio-dsp-chaini1.jpg
280 KB -

fpga-audio-dsp-chaini2.gif
54 KB

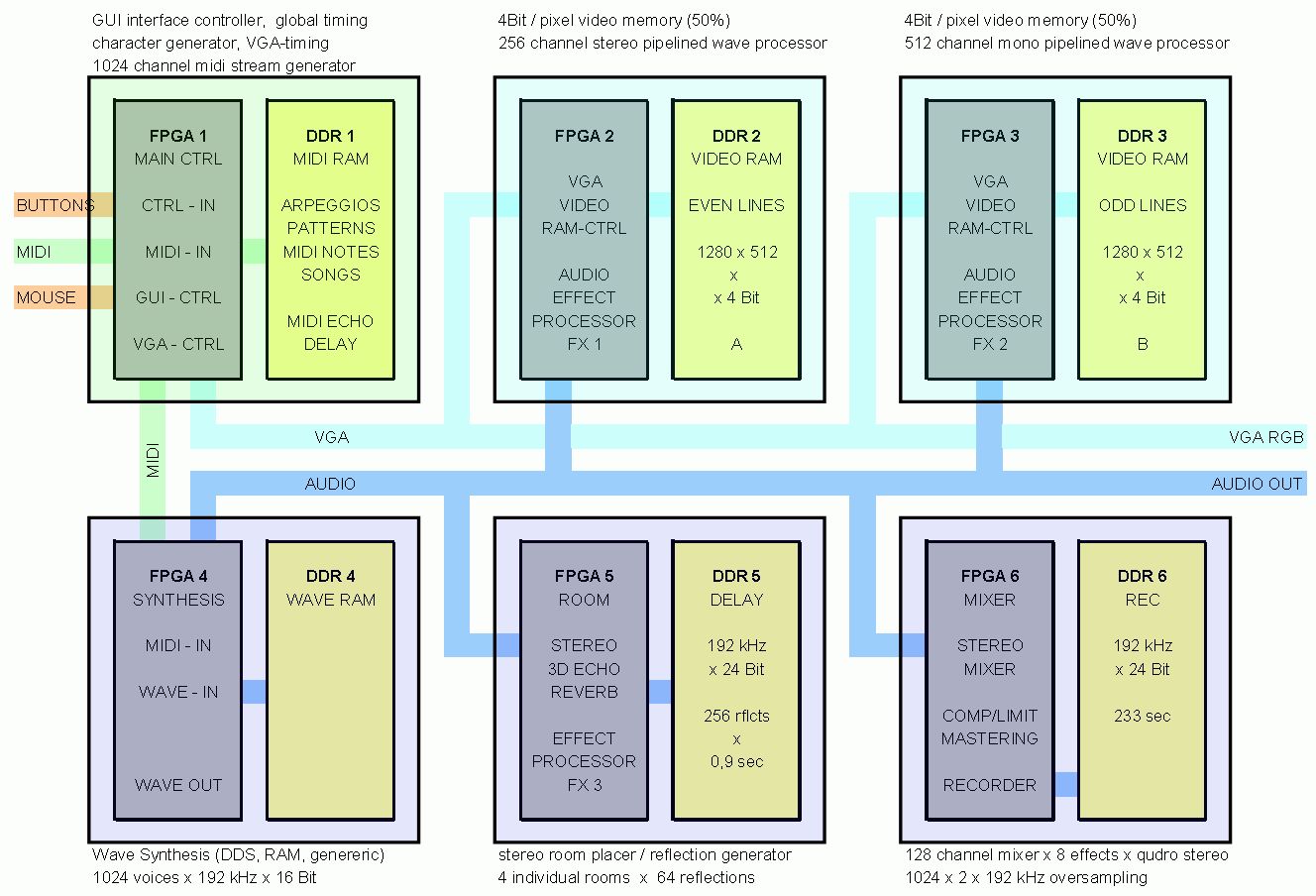
Ich bin auch am Überlegen, soetwas zu bauen oder zusammenzukaufen und bin auf eine Kombination aus EVAL-Board und Mini-boards mit nicht viel mehr drauf, als einem FPGa gekommen. Ich hatte seinerzeit so eine Plattform mit Spartan 2 aufgezogen, stiess aber schnell an die Grenzen der Chips. Später stand Neubau oder Kauf an, wobei Kauf immer die billigere Alternative darstellte. Leider habe ich bisher aber kein so richtige passendes Aufsteckboard gefunden, dass wenig genug an unnötiger Peripherie drauf hat, aber dennoch einen ordentlichen Chip trägt, mit dem man etwas anfangen könnte. Die billigen Xilinx-Eval boards tragen nur einen mickrigen FPGA und die größeren sind zu teuer und es wäre Verschwendung, die zusammenzuschalten. Die Zenfantboards habe ich mir auch schon angesehen, aber sie sind im Vergleich auch noch zu teuer und haben immer noch zuviel drauf. Die "alten" Spartan3-FPGAs wären zwar noch im Rahmen, haben aber kaum DSP/MULs. Am effektivsten scheinen mir für Rechenapplikationen die S3A DSP 1800 von Xilinx. Für netto €1000,- bekommt man 6 Trenzboards vom Typ 320EV2 mit dem B2B connector, die man auf einem selbstentwickelten board mit EAGLE leicht integrieren kann. Jedes hat ein eigenes Flash und ist individuell konfigurierbar. Das hat grosse Vorteile, weil man durch die Partitionierung der Applikation immer nur eins davon neu synthetisieren und laden muss. Das System hat dann immerhin 100.000 slices, 500 DSP-Elemente, 1,2 MB BRAM und 768 MB DDR-RAM. Ich bin schon am planen, wie das aussehen könnte. Ich muss dann nur ein Trägerboard bauen, das ausreichend Leistung bereitstellen kann und mir Gedanken über die Busverdrahtung machen.
Andererseits hätte ein XC6VLX760 sogar 118,560 slices, 25MB BRAM, 864 DSPs und ein XC6VSX475T, 74,400 slices, 38MB BRAM und 2,016 DSP Elemente.
Das mit den MB und Mb solltest du nochmal üben, ... liegt ja immerhin ein Faktor 8 dazwischen
> liegt ja immerhin ein Faktor 8 dazwischen
Beim Preis übrigens auch so ungefähr ;)
ok, richtig, XC6VLX760 3MB BRAM und XC6VSX475T 4,5MB BRAM. Der Preis ist so eine Sache. Hängt sehr von der Auflage der Boards ab. Dummerweise bekommt man auch bei Xilinx / Digilent, die viel produzieren nur die kleineren FPGAs angeboten, was ich ehrlich gesagt, ungeschickt finde, weil man auf einem EVAL board schon auch die grösstmögliche APP fahren können sollte. Abspecken geht immer. Bliebe noch Spartan 6: XC6SLX100 101,261 slices, 0,1 MB BRAM und 180 DSPs.
0,6MByte :-P Aber egal, der LX100 geht doch schon nicht mehr mit dem freien ISE Webpack, oder?
Und wie wäre es hiermit? http://www.trenz-electronic.de/products/fpga-boards/trenz-electronic/gigabee-xs6lx.html
@Zonk: ok, hatte mich in der Spalte vertan. Und ja, der 100er geht nicht mehr mit der Webpacksoftware. @Rene: ja den habe ich gesehen. Der kleinere FPGA (45er) ist wieder recht klein.
Ich sage mal, wenn man sich für einen grossen FGPA entscheidet, kann man wirklich gleich die Vollversion der Software dazu kaufen. Allerdings ist man dann gleich mit 5kEUR dabei. Das ist als Hobby etwas schwer gegenzufinanzieren / zu rechnen :-) Die SW habe ich dann da liegen und muss sie allenthalben updaten, weil ich gezwungen bin, mit der Vollversion zu arbeiten. Für den Preis der SW bekommt man aber einiges mehr an Hardware. Es gibt noch einen Punkt: Ein weit ausgebautes board ist mit dem Tod des FPGA praktisch auch dahin. Wenn ich mir aber einen von mehreren kleinen "zerhaue" tausche ich das board komplett und habe nur 200,- an Reparaturkosten inkl. Versand. Aussdem bin ich nicht lahm gelegt. Wenn ich das System tatsächlich benutze / benutzen muss, weil ich eine wichtige Anwendung dafür habe, lege ich mir einfach ein Ersatz board hin und bin voll arbeitsfähig. Ich bin jetzt fest entschlosen, mir das so oder so ähnlich aufzubauen. Die Frage ist nur noch nach dem FPGA. Ok, man könnte das Spartan 6 board nehmen, bekommt aber fürs gleiche Geld nur 4 boards davon. Daher hätte man: 26.000 slices, 1MB bram, 232 DSP slices, also deutlich weniger, als mein 6er von oben. Die bessere serielle Funktionalität brauche ich nicht. Der Vorteil bestünde nur in der höheren Taktfrequenz und den gfs besseren DSP-slices. Aber man hat nur 60% der Kosteneffizienz im Vergleich zum S3A DSP. Die Spartan 6 sind halt die neuen aktuellen Chips und damit teurer. An Robert: Wofür brauchst du das Board genau?
Juergen Schuhmacher schrieb: > Ich sage mal, wenn man sich für einen grossen FGPA entscheidet, kann man > wirklich gleich die Vollversion der Software dazu kaufen. Allerdings ist > man dann gleich mit 5kEUR dabei. Das ist als Hobby etwas schwer > gegenzufinanzieren / zu rechnen :-) Stimmt so nicht. Altera Quartus II kostet so um die 2500,-. Da drin sind NIOS, DDR1/2/3 + andere Cores enthalten. Aber auch mit der freien Version kann man alle Cyclones III nehmen (bis 120 kLE, 288 18x18 Mults, 486 kByte M9K) Juergen Schuhmacher schrieb: > Es gibt noch einen Punkt: Ein weit ausgebautes board ist mit dem Tod des > FPGA praktisch auch dahin. Wenn ich mir aber einen von mehreren kleinen > "zerhaue" tausche ich das board komplett und habe nur 200,- an > Reparaturkosten inkl. Versand. Aussdem bin ich nicht lahm gelegt. Wenn Ach, es kann nur ein FPGA kaputt gehen? Was passiert, wenn Trägerplatine eine Schuß hat? Die Idee an sich finde ich sehr interessant, mehrere FPGAs als Module zu verwenden. Für diverse Projekte habe ich allerdings sowas schon mal durch kalkuliert, nur war keins wirtschaftlich! :-o (Allerdings waren es keine gekauften Module, sondern auch selbst entwickelte) Grüße, Kest
@Jürgen Schuhmacher: Videoalgorythmen und Musterkennungsverfahren sollen parallel qualifiziert werden. Im Endsystem werden dann zwar nur einige wenige Methoden zur Anwendung kommen, wo dann auch ein einzelner FPGA reichen wird, aber wenn es ums Vergleichen geht, ist es einfacher, Ergebnisse parallel berechnen und verfizieren zu können. Daher ist "as much as available" angesagt. Momentan läuft das noch auf privater Schiene, bzw in Eigenregie und darf nicht zu hohe Kosten aufwerfen. @Kest: Welche Boards hast Du getestet und durchgerechnet? > Altera Quartus II kostet so um die 2500,- Xilinx ISE ungefähr auch, soweit ich weiss. Es bleibt aber das Problem, dass man auf die Vollversion festgelegt ist und sie immer wieder kaufen muss, bis der FPGA vielleicht einmal veraltet und in der freien aufgenommen wird. Insofern stimme ich Jürgen vollkommen zu: Für die Summe von 2500,- kann ich mir gleich die dreifache Hardware kaufen und betreiben. Man muss das Gesamtsystem und die Kosten betrachten. Das Board mit dem besseren FPGA ist ja auch gleich viel teurer. Die Xilinx-PCBs mit den dicken FPGAs, die in Summe dasselbe können, kosten auch gleich 1500,- und mehr. Macht einen Gesamtpreis von >4000,-. Es kommt für den Heimgebrauch eigentlich nur die Webversion in Frage. Altera wäre für mich aber durchaus eine Alternative. Ich bin bislang nicht festgelegt. > Aber auch mit der freien Version kann man alle Cyclones III nehmen Welches Board kann man da nehmen?
http://www.enterpoint.co.uk/merrick/merrick1.html Kann man sich auch mit Webpack-kompatiblen Steinen bestücken lassen, aber da würde ich dann auch noch die 3.5k für ne ordentliche ISE-Lizenz abdrücken. Da kommts dann auch nicht mehr drauf an.
Jaja, der Traum der FPGA-Entwickler. Ein ganzer Raum voller Merricks mit wenigstens 30x40x50 Platinen zu 100 Bausteinen. Damit kann ich dann 500 Zusen emulieren. Klar, nehme ich sofort, aber wer bezahlts? Ich würde jetzt so maximal 3000,- Euro ansetzen für das Projekt und will möglichst viel Leistung dafür haben. Wenn schon die Hälfte in die SW flösse, bliebe nicht mehr viel. Die Module haben auch noch den Vorteil, dass man auch klein anfangen kann und später aufrüsten. Wenn ich wirklich mehr Power brauchen sollte, baue ich noch ein paar Module hinzu. Ich habe es mal durchgerechnet, dass ich wegen des Speichers 2 kleine Boards mit Spartan DSP für die Elementarapplikation brauche. Da Daten im loop erst weiterverarbeitet werden können, wenn sie durch durch die pipeline durch sind, habe ich Raum für ca 256 Szenarien. Das sind z.B. 4 Parametervariationen mit je 4 Stufen. Mit jeder 2er-Gruppe verdoppelt sich die Zahl der simulierbaren Fälle. Beladen werden sie alle gleichzeitig mit denselben Daten. Da könnte man die Module einfach parallel nebeneinanderhängen. Ich schaue jetzt aber trotzdem nochmal, was Altera hat.
Ich würde dir auch zu Altera und den Cyclones raten. Kennst du nicht vielleicht einen Studenten, der dann den Academic Preis beziehen könnte? Dann würde ich mir für dein Budget den Tisch mit den DE2 Boards von Terasic zuknallen, die mit der freien Software beschreibbar sind: http://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English&CategoryNo=139&No=502 Noch dazu kannst du SignalTap verwenden wenn du WebTalk zulässt, wohingegen du bei Xilinx kein ChipScope bekommst für lau
Robert schrieb: > Videoalgorythmen und Musterkennungsverfahren sollen parallel > qualifiziert werden. Im Endsystem werden dann zwar nur einige wenige > Methoden zur Anwendung kommen, wo dann auch ein einzelner FPGA reichen > wird, aber wenn es ums Vergleichen geht, ist es einfacher, Ergebnisse > parallel berechnen und verfizieren zu können. Daher ist "as much as > available" angesagt. Momentan läuft das noch auf privater Schiene, bzw > in Eigenregie und darf nicht zu hohe Kosten aufwerfen. Mh... da habe ich auch Einiges gemacht, nur verstehe ich nicht, wieso es mehrere Boards werden müssen? Um vergleichen zu können, reicht die Simulation (ob jetzt mit ModelSIM, VirtualDub, ImageJ, CUDA ist vollkommen egal). Ich habe mit allen was gemacht und es geht halt schneller, als wenn man jetzt das komplette FPGA-Design macht. Wenn der Algorithmus dann steht, kann man ja alles ins FPGA gießen. Kauf Dir einfach eine CUDA Grafikkarte und mache alles damit, so schnell an die ergebnisse kommst Du nie mit einem FPGA (schon gar nicht mit einem selbst entwickelten FPGA-Board) Robert schrieb: > Welche Boards hast Du getestet und durchgerechnet? Nur Eigenentwicklungen. Den Aufwand mehrere FPGA-Designs zu pflegen darf man nicht unterschätzen. Das klingt alles so toll und einfach, in Wirklichkeit aber sieht es ganz anders aus. Dazu kommt noch die Kommunikation zwischen den Boards. Dann noch debugging und Co... Überlege es Dir gut! Für Algorithmen-Evaluationen haben wir immer etwas größeres FPGA genommen. Wenn dann die Entwicklung fertig ist, wird kleineres FPGA bestückt (Pin-Kompatibilität). Bei Cyclones III ist es schon toll: 3c16 -> 3c40 -> 3c55 -> 3c80 -> 3c120 Man nehme einfach das nächstgrößere, wenn es nicht reinpasst ;-). Und das Beste: alle lassen sich mit WebEdition programmieren :-o -> keine Kosten Grüße, Kest
Altera ist mir schon symphatisch, keine Frage. Das mit dem SignalTAP habe ich mir auch schon überlegt. Zu der Simulation: Das Design zu simulieren und zu checken, ob es läuft ist kein Akt. Die Signalverarbeitung ist simpel und zudem ausgereift genug, sozusagen. Es geht um die Parameter und die sind nur anhand der Echtzeitdaten wirklich gut zu optimieren. Das in SW zu machen scheidet komplett aus. CUDA Grafikkarte scheidet ebenfalls aus. Es muss ein FPGA sein, weil aufgrund der späteren Datenanbindung einiges an ADCs drankommen soll und wird. Erstes Umsehen ergab das hier: http://www.hdl.co.jp/en/index.php/acm/acm-022.html Wenn ich 2 von den großen nehme, bleibe ich unter 3000,- und hätte 240.000 LEs, 500kB Ram, fast 600 Multiplier.
Robert schrieb: > Zu der Simulation: Das Design zu simulieren und zu checken, ob es läuft > ist kein Akt. Die Signalverarbeitung ist simpel und zudem ausgereift :-o Wie oft ich das schon gehört habe ;-) Robert schrieb: > genug, sozusagen. Es geht um die Parameter und die sind nur anhand der > Echtzeitdaten wirklich gut zu optimieren. Das in SW zu machen scheidet > komplett aus. CUDA Grafikkarte scheidet ebenfalls aus. Es muss ein FPGA Geht es um Bilder? Videodaten? Wenn ja, dann ist ist eine simple aber gute HD-WebCam mit CUDA-Grafikkarte auf jeden Fall günstiger, als ein FPGA Board(s) für mehrere Tausend. Ehrlich gesagt, jetzt verstehe ich die Intention überhaupt nicht, was gemacht werden soll. Und wieso gerade mehrere Boards dafür notwendig sein sollen. Wie willst Du dann die Daten in so ein Board reinbekommen? Was soll rauskommen? Als VGA/DVI? Kannst Du mehr erzählen, was das für Algo ist und ob es schon in irgendeiner Form lauffähig ist? Grüße, Kest
Würde mich auch mal interessieren, was dort genau gerechnet werden soll. Wenn es FPGAs sein müssen, wird es wohl an der Zieltechnk liegen. Oder macht ihr die Simulation als Hardware-Cosimulation? Ich habe sowas kürzlich mit MATLAB gemacht. Man kann nahezu jeden Algo als FPGA Design inklusive embedded MATLAB Funktionen in ein EVAL-board reinstopfen und simulieren lassen. > Wenn ich 2 von den großen nehme, bleibe ich unter 3000,- und hätte > 240.000 LEs, 500kB Ram, fast 600 Multiplier. Wenn Du soviel investieren kannst und willst, bekommst Du dafür aber auch das Dreifache meiner Lösung, nämlich: 300.000 slices, 1500 DSP-Elemente, 3,5Mb BRAM und 2GB externes DDR-RAM. Wenn es unbedingt ein grosser Chip sein soll, dann ist aber das Altera Board (Video Kit) zu empfehlen. Das hat denselben FPGA und als Video Kit bekommt man noch AD-Wandler dazu / eine weitere Karte. Ich würde auch zu Altera raten, habe aber noch keinen Lieferanten gefunden, der so billig anbietet, wie Trenz. Alle äquivalenten Altera boards liegen eher so um 400,-. Auch die Spartan 6 boards sind in Relation immer teurer. > Dann würde ich mir für dein Budget den Tisch mit den DE2 Boards von > Terasic zuknallen, die mit der freien Software beschreibbar sind: Das V4 schaut gut aus, wobei ich nicht weiss, ob zu dem Preis der grosse FPGa bestückt ist. Sieht aber so aus, wie mir scheint. Wären 500,- Euronen. In jedem Fall wäre das ein gutes Master board, denn die kleinen Module müssen ja auch irgendwie getrieben werden.
Die genauen Aspekte der Algorythmik kann ich hier nicht offenlegen. Nur soviel: Es geht um hohe Datenraten und DSPs schaffen das um den Faktor 3-4 nicht. Habe ich genauestens durchberechnet. Der am Ende herausgekommende Algo kommt in jedem Fall wieder in ein FPGA, deshalb macht es keinen Sinn, ihn in C nachzubilden oder in eine Grafikarte zu stecken. Das Board muss autark laufen und in eine Anlage einbaubar sein. Ich brauche einfach ein board mit der Option möglichst viel dazustecken zu können, wenn es drauf ankommt. > den Tisch mit den DE2 Boards von Terasic zuknallen Tischgröße ist nicht. Eher 10x Ritter Sport :-)
Robert schrieb: > Der am Ende herausgekommende Algo kommt in jedem Fall wieder in ein > FPGA, deshalb macht es keinen Sinn, ihn in C nachzubilden oder in eine > Grafikarte zu stecken. Das Board muss autark laufen und in eine Anlage > einbaubar sein. Ich brauche einfach ein board mit der Option möglichst > viel dazustecken zu können, wenn es drauf ankommt. oben hast Du geschrieben, dass die Algorithmen mit einander verglichen werden, deshalb musst Du alles auf ein Mal in einem/mehreren FPGA(s) implementieren. Deshalb kam ich mit Simulation. Welchen Sinn soll es haben, wenn man mehrere FPGAs braucht (quasi zum Simulieren), um am Ende doch in einen alles reinzupacken? :-o Aber das kommt davon, dass wir ja nicht "alles" wissen, ist auch okay :-) Ich habe das Gefühl, dass Du unbedingt viele FPGAs verbauen möchtest, auch wenn Du es vielleicht doch später nicht brauchst ;-) Das sind halt unser aller feuchte Träume :-) Grüße, Kest
Das eine ist die Entwicklung und die Inbetriebnahme, zu dem auch die Optimierung der Parameter an die Realität gehört und das andere die Fertigung und (mögliche) Serie. Man könnte theoretisch einen Fall erzeugen, Daten messen und aufzeichnen und alles in Modelsim einspielen und mit ein und demselben Datensatz verschiedene Algos und deren Verhalten tracken und nachvollziehen. Oder man kann es in Echtzeit machen und sehen, was rauskommt/käme. Beides ist nötig. > Bei Cyclones III ist es schon toll: 3c16 -> 3c40 -> 3c55 -> 3c80 Wie ist das bei den Cyclone IV? Wie weit macht da die Webedition mit? Das Altera DE2-115 wäre schon super für den Einstieg, meine ich: Cyclone® IV 4CE115 mit EPCS64 config 2MB SRAM, 2d 64MB SDRAM, 8MB Flash SD Card, Könpfe Schalter und LEDs in Massen 16x2 LCD modul + 8x Siebensegmentanzeige Den Audiokram und Videoanschluss brauche ich nicht, kann man aber mitnehmen. Ich denke aber darüber nach das, GB-Ethernet zu nutzen, um Daten rein und raus zu bekommen. Was gäbe es denn da an Karten für den PC?
Robert schrieb: >> Bei Cyclones III ist es schon toll: 3c16 -> 3c40 -> 3c55 -> 3c80 > Wie ist das bei den Cyclone IV? > Wie weit macht da die Webedition mit? Bei Cyclone IV ist es ähnlich: im FT484 Gehäuse 4CE15 -> 4CE30 -> 4CE40 -> 4CE55 -> 4CE75 -> 4CE115 Die WebEdition kann alle Cyclones synthetisieren. Wenn Du das obige Board nimmst, kannst Du komplett alles mit WebEdition machen (SDRAM Controller ist ja schon drin und NIOS II e kannst Du auch verwenden, ohne dass Du Licence-Kosten tragen musst) Grüße, Kest
So sieht es aus, daher wird die Entscheidung meinersweits zu Gunsten Alteras ausfallen. Die Frage ist nur, wie lange es dort den ModelSIM noch geben wird... Und: Wie kommt man als Ex-Student an den günstigen Academic Preis heran? sind ja immerhin $270,- Unterschied. Das board ist wirklich nett, zumal es offenbar gleich einen USB Treiber mit dabei gibt. Die Demodesigns sind auch scon sehr schlagkräftig, gfs kann man da etwas von nutzen.
Robert schrieb: > Und: Wie kommt man als Ex-Student an den günstigen Academic Preis heran? > sind ja immerhin $270,- Unterschied. Einen Student deines Vertrauens aus dem Bekanntenkreis fragen.
Das scheitert meistens daran, dass die Studenten selber heiss werden auf das System und sich eins bestellen. 2 Liefern die Firmen aber nicht aus. Da muss schon die Uni ran und direkt gleich mehrere bestellen. Habe mir das auf der Terasic-Seite heute mal angesehen: Die verbieten das sogar und drohen dem Studi, wenn das board in kommerzieller Umgebung auftauchen sollte. Wie strikt die Immatrikulatiosbescheinigung lesen und alles, weis natürlich keiner. Ich würde es nicht probieren, da was zu tricksen. Eher schon könnte man sich bei einer Uni einschreiben und den Vorteil mitnehmen :-) > Das board ist wirklich nett, Ich frage mich, wie die das so billig an bieten können, bei dem großen FPGA. Das ist der beste aus der Linie - hat nur keine Transceiver. Scheint schwer gesponsort zu sein... > zumal es offenbar gleich einen USB Treiber mit dabei gibt. Wo steht das denn?
Man könnte doch einen nehmen, der in einem fremden Fachbereich studiert und das Ding nicht braucht. Er lötet eine LED aus, macht es damit offiziell kaputt, wirft es auf den Müll und gibt seine Eigentumrechte auf. Dann holt man es sich aus der Tonne, repariert es und baut es in die eigene Hardware chain ein :-)
@Ranga Ja und wenn man dann mal Support vom Hersteller braucht gibt man als Bezugsquelle "Müllcontainer vorm Studentenwohnheim" an :-P
Seit wann gibt es Support für Education boards? Seit wann gibt es bei Xilinx überhaupt Support? Egal, muss halt der Student fragen!
Auch wenn das Thema alt ist, greife ich den Faden auf, da ich vor der gleichen Frage stehe: Kennt oder hat jemand ein solches Mehr-FPGA-PCB? Jürgen S. schrieb: > Das System hat dann immerhin 100.000 slices, 500 DSP-Elemente, 1,2 MB > BRAM und 768 MB DDR-RAM. Ich bin schon am planen, wie das aussehen > könnte. Hast du das gebaut? Wäre das zu erwerben? Ich möchte eine frei programmierbare Spieleplattform entwickeln, in welche ich FPGA-Arcade-Spiele laden und betreiben kann. Die FPGAs müssen dafür mit der kostenlosen Version der Herstellersoftware zu programmieren sein. Welche Bausteine würden sich dafür anbieten?
Harald schrieb: > Jürgen S. schrieb: >> Das System hat dann immerhin 100.000 slices, 500 DSP-Elemente, 1,2 MB >> BRAM und 768 MB DDR-RAM. Ich bin schon am planen, wie das aussehen >> könnte. > Hast du das gebaut? Wäre das zu erwerben? Die Eckdaten hat mittlerweile ein MittelklasseFPGA wie der XC7A200T, der hat sogar mehr Slices und DSP. Kann man auch kaufen. https://www.ztex.de/usb-fpga-2/usb-fpga-2.18.e.html Da ist USB3, dickes FPGA und RAM drauf und es hat einige freie IOs.
Harald schrieb: > Ich möchte eine frei programmierbare Spieleplattform entwickeln, in > welche ich FPGA-Arcade-Spiele laden und betreiben kann. Die FPGAs müssen > dafür mit der kostenlosen Version der Herstellersoftware zu > programmieren sein. https://github.com/MiSTer-devel/Main_MiSTer/wiki Da ist die Einstiegshüde recht gering weil es VIELE Beispiele gibt, freie Lizenz reicht und 500Kbyte Ram sowie ~100000LE sind meistens auch genug, wenn es nicht gerade 3D werden soll. Für das Board gibt es fertige Erweiterungen(z.b. SDRam, VGA, usw) zu erschwinglichen Preisen und das Mainboard ist mit unter 150€ inklusive Versand zu erstehen.
Heutzutage nimmt man GPUs. Die gehe, die liefern. Ich empfehle zB eine nVidia Tesla P100, nVidia Titan RTX, nVidia Quattro RTX, alle relativ guenstig und power ohne Ende
Gustl B. schrieb: > Ja, stimmt, aber je nach parallelisierbarkeit > ist ein FPGA doch geeigneter. Für schlecht parallelisierbare Algorithmen sind weder GPUs noch FPGAs geeignet. Und wenn es um mehrere gut parallelisierbare, aber unterschiedliche Algorithmen geht, dann kann man auch einfach mehrere GPUs in den Rechner stecken. :-)
Udo K. schrieb: > Hier gibts richtig Rechenleistung: > https://de.aliexpress.com/item/32907109444.html Super-FPGAs aus China von Ali und Baba. Das ist exakt das, was man für eine solide industrielle Entwicklung haben möchte. Keine Doko, keine Aussage zur Qualität und Lieferwahrscheinlichkeit im Bereich von unter 10% nach 6 Monaten. Das Beste ist der Spruch unten, dass er auf das Paket nur 9,99 drauf schreibt und man sich damit den Zoll sparen kann. Tatsächlich kann man hoffen, dass mal ein board durchgeht. Real sieht es eher so aus, dass man für die 149,- Dollar + Versand noch Einfuhrumsatzsteuer, sowie Zoll bezahlen darf. Damit kostet das lütte Kintex-Viech über Euronen 250,- und da es nicht sauber deklariert ist, hat man noch Aufwand mit dem Zoll, muss hinfahren und es auslösen. Bei spätesten 3. Paket hat man die Steuer am Hals, weil sie Betrügereien unterstellen. Dann gibt es Bearbeitungsgebür, erhöhten Zoll (Faktor 2) und bei gemutmaßtem Betrug der EUST auch noch doppelte UST als Strafe. Dann kosten 3 Boards schnell 1000,-! Dafür kriege ich hier in Deutschland 2 Artix Video Baords, von denen jedes einzelne die doppelten Resourcen hat, wie der Mini-Kintex!
S. R. schrieb: > dann kann man auch einfach mehrere > GPUs in den Rechner stecken. :-) WENN man einen PC hat, um was reinzustecken! Erstens fragt der TO aber nach Multi-FPGA-Systemen und damit fallen PCs und GPUs schon unter den Tisch und zweitens, kommt von der GPU-Power in typischen Anwendungen oft nicht viel an, weil man durch den PCI-Bus nix durchkriegt. Grafikkarten konnen primär das gut, wofür sie gebaut wurden, nämlich: Mit wenigen Informationen = Pixelparamter, einen Haufen ausgemalte Grafik ausrechnen und direkt ausgeben. Sie sind nicht dafür gebaut, massenweise Daten wieder über PCI zurückzuschicken. Misst man das mal nach, hat man einerseits eine Reduktion der Bandbreite auf etwa 60%, die sich IN und OUT teilen müssen, was zu etwa 20% - 30% der Leistung führt. Im nicht-burst Betrieb entstehen dann Latenzen, die sich auf die pipiline draufaddieren. Dann kann man schon gerne mal eine zweistellige Anzahl an Takten warten, bis was kommt. Ein Algo, der diese Daten braucht, um weitere Parameter setzen zu können, wird damit um einen Faktor 20x2+x abgebremst. Mehr, also 100MHz im loop sind da nicht zu machen. Das kriegt jeder Spartan 3 von vor 15 Jahren hin. Rechnet man nun die PCI-Belastung und die Dämpfung anderer Operationen, wird ein System mit 4 Karten sehr schnell an der Grenze sein, die entsteht, wenn die CPU busmäßig noch was anderes tun will, als RAM und GPU zu addressieren. Und: Der PC kostet auch Geld! Ein industrielle PC-Plattform, die über ausreichen lanes verfügt, um einige GPUs tragen zu können, ist nicht unter 1000,- zu bekommen. Auch billige Karten gehen dann ziemlich ins Geld. Eine einzelne Karte lohnt sich deshalb oft gar nicht, mehr als 4 kriegt man nicht versorgt. Es braucht also 2 oder 3 Powerkarten, die selber schon einen Tausender kosten und eine effiziente App. Für die 4k Investition kriegt man aber 10 Artix-Karten von denen jede alleine jede für sich schon eine höhere Bandbreite besitzt, als die derzeit schnellste Grafikkarte.
Weltbester FPGA-Pongo schrieb im Beitrag #6074643: > Grafikkarten konnen primär das gut, wofür sie gebaut wurden, nämlich: > Mit wenigen Informationen = Pixelparamter, einen Haufen ausgemalte > Grafik ausrechnen und direkt ausgeben. Naja, im Gegensatz zu FPGAs haben GPUs einen riesigen Haufen schnell angebundenen eigenen Speicher und eine deutlich höhere rohe Rechenleistung. Nicht überall zählt die maximale Bandbreite, und auch nicht jeder FPGA wird mit einer Hochgeschwindigkeitsschnittstelle befüttert. Weltbester FPGA-Pongo schrieb im Beitrag #6074643: > Und: Der PC kostet auch Geld! Ohne einen ordentlich ausgestatteten PC kannst du FPGA-Entwicklung aber auch vergessen. Man kann also davon ausgehen, dass zumindest ein PC vorhanden ist, der eine GPU vollständig (PCIe 16x) und eine zweite GPU zumindest teilweise (PCIe 4x) tragen kann, eventuell auch mehrere. Vielleicht hast du aber auch einfach nur den Smiley in meiner Antwort übersehen.
Im Gegensatz vum einem selbst zusammengekloppten MultiFPGA, welches erst mal noch einiges an VHDL benoetigt, plus PC Treiber auf der anderen Seite, bietet eine GPU aus der Packung raus, zB fuer 1000Euro, schon eine fertige Cuda Library. Nach einem halben Tag laeuft der Algorithmus schon. Da muss man sehr gute Gruende haben um selbst was zusammenzukloppen. zB speziell an ein abgehobenes Problem angepasste Hardware und hinreichende Stueckzahlen.
Welterfahrener FPGA-Pongo schrieb im Beitrag #6074628: > Udo K. schrieb: >> Hier gibts richtig Rechenleistung: >> https://de.aliexpress.com/item/32907109444.html > > Super-FPGAs aus China von Ali und Baba. Das ist exakt das, was man für > eine solide industrielle Entwicklung haben möchte. Keine Doko, keine > Aussage zur Qualität und Lieferwahrscheinlichkeit im Bereich von unter > 10% nach 6 Monaten. Jemand der industriell entwicklet, fragt nicht in so einem Bohnenforum, oder aber er ist wirklich unfähig. > Das Beste ist der Spruch unten, dass er auf das Paket nur 9,99 drauf > schreibt und man sich damit den Zoll sparen kann. Tatsächlich kann man > hoffen, dass mal ein board durchgeht. Real sieht es eher so aus, dass > man für die 149,- Dollar + Versand noch Einfuhrumsatzsteuer, sowie Zoll > bezahlen darf. Damit kostet das lütte Kintex-Viech über Euronen 250,- > und da es nicht sauber deklariert ist, hat man noch Aufwand mit dem > Zoll, muss hinfahren und es auslösen. Bei spätesten 3. Paket hat man die > Steuer am Hals, weil sie Betrügereien unterstellen. Dann gibt es > Bearbeitungsgebür, erhöhten Zoll (Faktor 2) und bei gemutmaßtem Betrug > der EUST auch noch doppelte UST als Strafe. Dann kosten 3 Boards schnell > 1000,-! > > Dafür kriege ich hier in Deutschland 2 Artix Video Baords, von denen > jedes einzelne die doppelten Resourcen hat, wie der Mini-Kintex! Mal mal nicht den Teufel an die Wand. Du bekommst hier in Europa kein Xilinx Board mit einem 1500 - 2500 Euro FPGA plus einer Entwicklungslizenz (gebunden an das Board) so günstig. Die FPGA's sind laut eevblog.com reballed. Die Garantie kannst du dir bei dem Preis sonst wohin stecken... Der TE hat übrigens vor 9 Jahren gefragt, lassen wir es damit gut sein...
S. R. schrieb: > Naja, im Gegensatz zu FPGAs haben GPUs einen riesigen Haufen schnell > angebundenen eigenen Speicher und eine deutlich höhere rohe > Rechenleistung. Die aber nicht nutzbar ist, wenn man die Ergebnisse nicht rausbekommt. Das ist doch das Problem. Ausserdem ist die Speicherbandbreite der Summe der Blockrams eines leistungsfähigen FPGAs immer noch höher. Hinzu kommen die FFs, als Zwischenspeicher. S. R. schrieb: > Ohne einen ordentlich ausgestatteten PC kannst du FPGA-Entwicklung aber > auch vergessen. ??? Was ist denn das bitte für eine Gegenrechnung, einen EntwicklungsPC mit einer Hardware zu vergleichen, die an einen Kunden geliefert werden muss? Sonntag abends zu viel Bier gehabt? Wenn man solche Systeme vergleich, muss die Umgebung mit bewertet werden. Bei Grafikkarten braucht es einen PCI Slot mit FPGA Anbindung oder eben einen PCI-Slot im PC. Ohne, läuft da nichts. Und auch ohne Betriebssystem läuft da nichts. Schon mal NVIDIA-Programmierung betrieben? Wir machen das seit 10 Jahren und ich sehe, wohin da die Bandbreiten gehen.
Weg mit dem Troll ! Aber subito schrieb: > Nach einem halben Tag laeuft der Algorithmus > schon. Ja, ja: Auspacken und glücklich sein. Bis auf die kleine Anwendung die man noch schreiben muss, die Resthardware, die man bauen muss, um Chips an die Grafikchips dran zu bekommen und die ganzen Kompatibilitätsprobleme der Libs. Wir schlagen uns täglich damit herum. Sobald man etwas tun will, was nicht main stream ist, hakt es an allen Ecken und Enden. Wer nur die Softwarebrille auf hat, der sieht nur ein bischen C, dass ihm symphatischer ist, als VHDL und das Befassen mit Elektronik. Die Sache ist nur die, dass man damit eben auch nur Probleme im PC lösen kann. Es braucht aber auch noch Interfaces zu den Systemen! Nimmt man z.B. die gewaltige Bandbreite paralleler Rechnungen in den GPU-Cores, dann taucht sofort die Frage auf, womit die gefüttert werden sollen. Auf der Seite des PC stehen erst einmal nur USB und Video zur Verfügung, sowie alles, was offline vorhanden ist oder virtuell erzeugt werden kann. Wettermodelle und SPICE sind sicher prima Kandidaten für paralleles Rechnnen. Aber 16 AD-Kanäle von Draussen mit 200 MHz müssen erst einmal rein in den PC. Diese Hardware als Modul zu kaufen oder gar zu bauen, dass sie PC-kompatibel wird, ist extrem teuer und stellt dann den Vorteil der scheinbar preiswerten CUDA-Technik bei Weitem in den Schatten! Sehr schnell bringt dann der Kostenvorteil nichts mehr. Die Alternative ist, die GPU-Chips selber an FPGAs anzuschließen nur dann hat man keinen Vorteil mehr mit PC-Libraries und Treibern, die schon "fertig sind".
Weltbester FPGA-Pongo schrieb im Beitrag #6074897: > Sonntag abends zu viel Bier gehabt? Das frag ich mich bei deiner Aggressivität aber gerade auch...
FPGAs haben teilweise sehr viele DSP Blöcke und viele Block RAMs. Das kann man alles voll parallel verwenden und bekommt sehr hohe Speicherbandbreiten und auch viele Multiplikationen je Zeiteinheit. Ja externes RAM ist ist meist langsamer, aber man kann auch viele SRAMs anbinden. Da gibt es sehr schnelle Bausteine. Da hat man bei zufälligen Zugriffen große Vorteile gegenüber einer GPU mit DRAM. Will sagen alles hat seine Vor- und Nachteile.
Angehängte Dateien:
-

audioboard.jpg
140 KB

{kind=link}
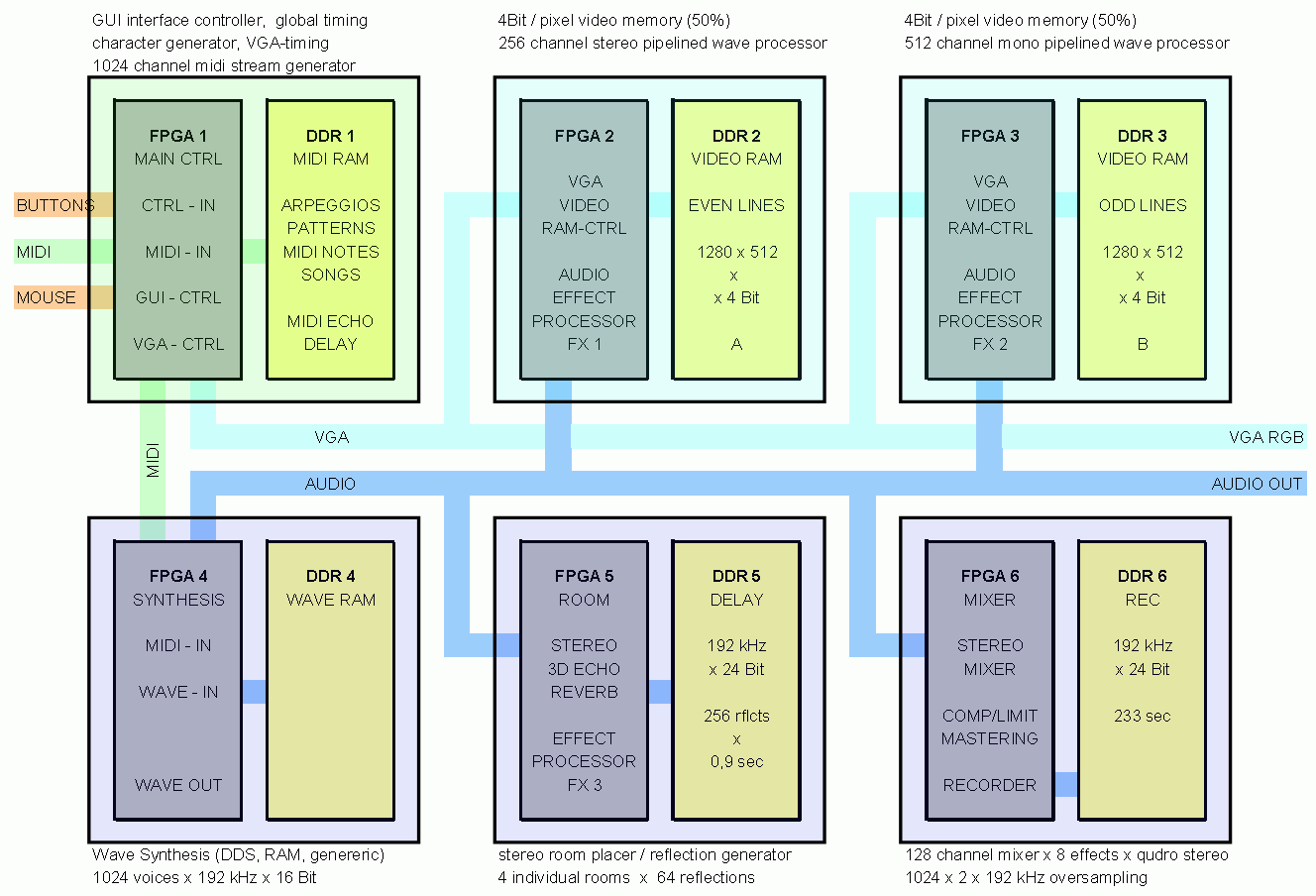
Weg mit dem Troll ! Aber subito schrieb: > Im Gegensatz vum einem selbst zusammengekloppten MultiFPGA, welches erst > mal noch einiges an VHDL benoetigt, Man kann ohne Probleme ein design anfertigen und dann die Module über die FPGA-Grenzen hinweg verschieben. Geht teilweise sogar automatisiert. Gustl B. schrieb: > Die Eckdaten hat mittlerweile ein MittelklasseFPGA wie der XC7A200T, Ja, mit jeder FPGA-Generation geht es voran, ändert aber nichts daran, dass man mehr benötigen kann, als ein FPGA hergibt. Die Strategie, den jeweils maximal noch mit der Webversion programmierbaren Baustein zu nehmen ist schon die richtige. Harald schrieb: > Jürgen S. schrieb: >> Das System hat dann immerhin 100.000 slices, 500 DSP-Elemente, 1,2 MB >> BRAM und 768 MB DDR-RAM. Ich bin schon am planen, wie das aussehen >> könnte. > Hast du das gebaut? Wäre das zu erwerben? Ich hatte damals 4 Module erworben verschaltet, allerdings händisch mit nur serieller Anbindung zwischen den Modulen. Geplant waren mal 6 bis 8. Und mit Bezug zu dem Beitrag oben ist es in der Tat so, dass die Funktion von 2 solchen Modulen inzwischen in den Artix 100 passt. Harald schrieb: > Welche Bausteine würden sich dafür anbieten? Ich würde für solche Arcade-Spielchen ein eval System nehmen, auf dem schon Stecker und Ports für VGA, Maus, Tastatur etc mit drauf sind, weil erfahrungsgemäß der klassische Nutzer dazu zurückchreckt, sich erst was aufbauen zu müssen, bevor er es ausprobiert. Für leistungsfähige Plattformen kann man dann ein weiteres FPGA Modul dranhängen. Neben den von Gustl schon erwähnten ZTEX gibt es ähnliche auch von Trenz. Ein Roh-PCB mit Artix 100 gibt es für 149,-. Das ist finanziell das effektivste, das ich kenne. Leider gibt es dazu im Ggs zu ZTEX kein Trägerboard. Daher habe ich mir was eigenes gemacht:
Gustl B. schrieb: > Ja externes RAM ist ist meist langsamer, Die RAMs für sich sind schon schnell und können mit dedizierten Speicher-Controllern auch oft viel schneller betrieben werden, als mit FPGA-IOs, slebst wenn es Kintexe et al. sind. Aber es ist eben nur ein Baustein oder es sind wenige. Vor allem sind es wenige Leitungen! Daher die Diskrepanz zwischen Block-RAM und externem RAM. Grafikkarten haben nochmals eine höhere und breitere Anbindung, aber auch die kommen nicht an die Bandbreite der Block-RAMs heran. Ich hatte an anderer Stelle am Beispiel meines Synthesizers schon darüber geschrieben, wie sich das Verhältnis darstellt und zitiere mich: Weil infolge der Echtzeitmanipulation der Stimmen und vollem pipelining der Klangsynthese sowohl die Parameter, als auch die Variablen permanent geschrieben und gelesen, sowie zurückgeschrieben werden, haben praktisch alle Block-RAMs mindestens 3 Interfaces. Solche, die als Schattenram fungieren, sogar 4, d.h. es wird auf 2 unterschiedlichen Speicherplätzen etwas ausgelesen und gleichzeitig auf die Adressen geschrieben. Daher ist der Zugriff bei 200MHz ca 3.5 x 16 Bit, was bei den RAMs im Artix 7 auf etwa 8Tbps herauskommt. Nimmt man nun noch die FFs hinzu, welche auch je Takt geschrieben und gelesen werden, wird das exorbinant: Wenige Variablen (= Signalvektoren) in einer pipeline könnten zwar in einer CPU-/GPU-ALU noch in Registern laufen und bräuchten keinen Speicherzugriff, aber bei hohem Kanalmultiplexfaktor muss auch dann gespeichert werden, weil es zu viele gleichzeitig relevante Register gibt, d.h. man müsste in ein externes RAM. Wenn nur 20% der FPGA-FFs davon betroffen sind (bei meinem Synth sind es geschätzt 35%!) dann kommen da weitere ~20Tbps hinzu. In Summe ergibt das schon das 1000-fache eines aktuellen DDR4-3200-Chips! Selbst mit mehreren Lanes, double fetch und 8 Speicher-Riegeln parallel wäre immer noch eine gute 10er-Potenz dazwischen. Nach meinen Berechnungen und Quervergleichen kommt man bei einem schnellen PC auf ein Faktor 30, um welchen der FPGA überlegen ist. Für die Rechnungen kann man Ähnliches feststellen: Da das Meiste im FPGA Entscheidung, Addition, Vergleich und Verzweigung ist und nur ein Teil Multiplikation oder Division, kommt man hinsichtlich der Speicherung von Zwischenergebnissen auch auf das 200- bis 300-fache einer einzeln 4GHz-CPU heraus. Ein typischer 8-Kerner liegt dann auch um einem Faktor 30 darunter. D.h. sowohl, was den reinen Speicherzugriff, als auch konkretes Ablegen und Holen von Ergebnissen angeht, wird ein Prozessor im Idealfall nur 3% dessen bringen, was schon ein Artix kann. Bei einem Ultrascale kommt nochmals ein Faktor 3-5.
Weg mit dem Troll ! Aber subito schrieb: > Heutzutage nimmt man GPUs. Die gehe, die liefern. Das höre ich seit 20 Jahren! Gerne wird übersehen, dass die eigentliche Anwendung eben nicht in der Box drin enthalten ist, sodass man sie herausnehmen könnte und umgekehrt auch bei FPGAs alle Cores schnell zusammengeklickt werden können und dies ohne größerere Timinganforderungen zu bekommen. Einen einfachen linearen Algo kann man in jeder Sprache hinhauen. Bei der Fragestellung, was besser und schlechter ist, wird gerne der jeweilige Vorteil nach vorn geschoben, bzw. das, was der Beurteiler gerade kennt und wer FPGAs nur gestreift hat oder nur auf SW-Ebene programmiert hat, der weiß eben nicht um die Möglichkeiten, eine Schaltung so darzustellen, dass sie effektiv arbeitet. Man versuche dazu mal mein RAM-Beispiel von oben nachzuvollziehen. Ich habe mir schon vor über 10 Jahren, nach Fertigstellung meiner P2-Version der Synths die Frage gestellt, wo die Reise hingeht und mir CUDA angesehen. Seither gab es auch immer wieder Projekte, wo man hautnah sehen konnte, was besser geht und was nicht. Ich denke, dass ich die drei Welten CUDA, FPGA und UC/PC ein wenig einschätzen und vergleichen kann und es bleibt dabei: Eine optimal an die Aufgabe angepasste Hardware ist nicht zu schlagen. Weder in Sachen Reaktionsfähigkeit, noch in Sachen Datendurchsatz, noch in Sachen Materialkosten, noch in Sachen Erweiterbarkeit. CUDA und embedded Systeme haben nur potenzielle Vorteile bei Entwicklungszeiten, aber auch nicht per se.
Jürgen S. schrieb: > Die RAMs für sich sind schon schnell und können mit dedizierten > Speicher-Controllern auch oft viel schneller betrieben werden, als mit > FPGA-IOs, slebst wenn es Kintexe et al. sind. > Aber es ist eben nur ein Baustein oder es sind wenige. Vor allem sind es > wenige Leitungen! Daher die Diskrepanz zwischen Block-RAM und externem > RAM. Grafikkarten haben nochmals eine höhere und breitere Anbindung, > aber auch die kommen nicht an die Bandbreite der Block-RAMs heran. Grafikkarten haben schon mehrere viele RAM Steine, aber das ist eben DRAM der bei zufälligen Zugriffen langsam wird. Da gibt es FPGA Board mit viel schnellem SRAM. Das ist zwar dann immernoch deutlich weniger RAM als eine aktuelle Grafikkarte bietet, aber der SRAM ist immer schnell. Mich würde ja mal interessieren wie das in einer GPU aussieht. Da ist ja bestimmt auch einiges an Cache verbaut der dann wohl ähnlich schnell wie BRAM verwendet werden kann?! Tesla hatte da ja dieses Jahr iirc seinen ersten eigenen Chip für neuronale Netze vorgestellt. https://en.wikichip.org/wiki/tesla_(car_company)/fsd_chip Und da sind 32MByte SRAM drinnen. Der bei 2 GHz läuft. Und wie das in dem Bildchen und in dem Text aussieht, werden da in jedem "Cycle" 256+128 Bytes(!!!) aus dem SRAM gelesen und 128 Bytes ins SRAM geschrieben. Das ist eine unfassbare Datenmenge. Man sieht an dem Die Foto auch schön die vielen Leitungen zum SRAM. Da machen die Leitungen schon deutlich mehr Chipfläche aus als die beiden MAC Blöcke. Zusätzlich hat der Stein noch ein 128 Bit DDR4 Interface.
S. R. schrieb: > Ohne einen ordentlich ausgestatteten PC kannst du FPGA-Entwicklung aber > auch vergessen. Realitätsabgleich: Hier hat die ganze Abteilung Laptops mit immerhin 32 GB RAM, M2 SSD, Dockingstation und zwei Monitore. Jürgen S. schrieb: > CUDA und embedded Systeme haben nur potenzielle Vorteile bei > Entwicklungszeiten, aber auch nicht per se. Für Firmen die seit je her nur (embedded) Software gemacht haben, kann das schon attraktiv sein. Von der Herangehensweise ist es ja ähnlich wie wenn man beginnt Vektoroperationen wie SSE/Neon einzusetzen. CUDA ist halt ein herrlich schlechtes Beispiel weil es nur mit NVIDIA geht. Intel und Altera hatten beide schon vor dem Merger begonnen OpenCL zu puschen. Da gab es hierzu auch schon Diskussionen im Forum, mein aktueller Stand ist, dass dies auch noch/eher eine Utopie ist als das was wir uns darunter wünschen würden (write once, deploy everywhere...) Die Diskussion zu Speicher-/Busbandbreite hier ist sehr wichtig, da sich hier entscheidet ob eine Lösungsvariante am Schluss taugt. Sehr spannend hierzu ist natürlich, dass z. B. AMD hier auch nicht schläft und ihre CPU und GPU viel enger verheiratet als die Konkurrenz. Ich habe aber selber noch kein Beispiel gesehen, wo das massiv ausgenutzt wird. Hat hier im Forum jemand Beispiele?
Die Diskussion ist mal wieder uC typisch lächerlich, 99% der Diskutanten haben noch nie ein ernsthaftes FPGA Projekt durchgezogen. Damit unsere lieben Nachbarn sich nicht in einem fort über deutsche Ingenieure totlachen, ein paar Anmerkungen: 1. Es gibt nicht "den FPGA". Der billigste fängt bei Digikey bei ca. 5 Dollar an (da passt ein grösseres Schieberegister rein), die richtig grossen kosten ca. 92000 Dollar (kein Verschreiber) Und auch die haben grad mal 3-5 Millionen Logikelemente und magere 0.1 - 0.5 GB internes Ram... 2. FPGA und GPU/CPU haben komplett andere Anwendungen. CPU/FPU: brachiale Floating Point Leistung im Terra/PetaFlop Bereich, die jeden FPGA richtig alt aussehen lässt. nur als Hint: schon mal versucht im FPGA Wurzel zu ziehen, oder einen Sinus zu berechnen, oder eine IEEE 64 Bit Division gemacht? Oder schon mal 128 GByte DDR5 Grafikspeicher an den FPGA angeschlossen? Das kann man zwar machen, aber man muss schon sehr leidensfähig sein. FPGA: Gigantomanische serielle I/O Performance bei nicht standardisierten Spezialprotokollen mit relativ wenig internem Bufferspeicher und hoher Parallelisierbarkeit. Sobald die Anwenung in Stückzahlen > 10^5 - 10^6 verkauft wird, gibt es dafür aber einen Interfacechip um < 10 Dollar. 3. Preis. FPGA, wie gesagt bis zu 92000 Dollar Leistungsfähige CPU/GUP: 500-5000 Dollar. Es gibt also für richtig fette FPGAs, abgesehen von Spezialanwendungen in sehr geldkräftigen Bereichen (Milität, GHz Messtechnik, ASIC Entwicklung, CERN und Telekom) keine Anwendung. Die kleinen bis mittleren FPGAs werden verbaut, aber auch nur dort wo es um Anbindung von schnellen seriellen Protokollen (ADCs/DACs) geht. Da wird dann ein wenig Vorverarbeitung gemacht, und dann gehen die Daten über PCIe an ne CPU damit sich auch die Programmierer damit rumärgern können. Portabel ist das ganze sowieso nicht, d.h. die Anbindung an den Laptop/PC wird man bei solchen Datenschleudern immer haben.
Udo K. schrieb: > 1. Es gibt nicht "den FPGA". > > Der billigste fängt bei Digikey bei ca. 5 Dollar an (da passt ein > grösseres Schieberegister rein), ... https://www.digikey.com/product-detail/en/lattice-semiconductor-corporation/ICE40LP384-SG32/220-2646-ND/3974680 https://www.digikey.com/product-detail/en/lattice-semiconductor-corporation/ICE40UL640-SWG16ITR50/220-1961-2-ND/5130905 Bei beiden passt wesentlich mehr als ein Schieberegister rein, im UltraLight mit seinen BlockRAMs kann man leicht einen Softcore unterbringen. Beide haben sogar den Konfigurationsspeicher auf dem Chip (OTP).
Udo K. schrieb: > schon mal versucht im FPGA Wurzel zu ziehen, Ja > oder einen Sinus zu berechnen Ja > eine IEEE 64 Bit Division gemacht? Ja Wurzel und Division laufen in 64 Bit mit 33..35 Takten Latenz in 200MHz. Beides lässt sich in LA4 auch mit 18 Takten machen, bei entsprechendem Invest in AREA. In der "normalen", platzsparenden Konfiguration sind es 66 Takte. Der berechnete! Sinus ohne Tabelle geht in Richtung 18 Takte für eine 100dB-Qualität. In platzsparender Konfiguration 33 Takte. In dieser normalen Konfig laufen die auch auf 300MHz. Das ist zunächst langsam! Da es aber pipelines sind, bekommt man immerhin mit jedem Takt ein Ergebnis. In einen Artix15 passen laut Synthese mindestens 18 solcher DIV-Einheiten. Macht 18 Divisionen alle 300 MHz. Rein rechnerisch sind das "nur" 5GOPs. Da man die Ergebnisse in ähnlicher Weise parallel weiterverarbeiten und zugreifen kann, entfallen durch die Speicherung in FFs sehr viele Zugriffe auf Register und externes RAM, was eine CPU auch erst noch leisen müsste. Die Kosten für einen Artix 15 liegen bei unter 20,- Was leistet eine Intel CPU zu dem Preis? Ein Intel I7 mit 4 Kernen wird mit unter 100GFlops angegeben. Das ist locker einen Faktor 20 über dem des FPGA. Nimmt man aber die real mögliche Auslastung und zieht noch die Speicherbandbreitenthematik heran, bröselt der Vorteil der CPU rasch zusammen und die vielen "Terras" erweisen sich als "Flop" :D Ich habe das vor Kurzem erst wieder einem Kunden vorgerechnet, der die gesamte Mathematik in einem ARM machen wollte, "weil der effektiver ist". Bei dem hat es schon in der Erstbetrachtung nicht mehr hingehauen. Ich konnte sogar zeigen, dass die Zynq-Lösung materialmässig teuer kommt. Grundsätzlich ist dein Einwand aber richtig: Solche Operationen sind in FPGAs unverhältnismäßig schlecht umzusetzen. Es schreit gerade danach, neben den MULs in küftigen Technologien auch DIVs und andere festverbaute Co-Prozessorfunktionen einzubauen. Von Intel dürfte da demnächst wohl einiges kommen! Ich würde mir diesbezüglich eine (a*a - b*b) / srqt(c) - Enheit wünschen. Damit kriegt man nicht nur die Wurzel (oder per Einspeisung von C*C) eine klassische Division mit zwei möglichen Komponenten frei Haus, sondern erledigt auch eine ganze Reihe von Rechenanforderungen bei Iterationen, Konvergenzrechnungen etc. Das nächste wäre eine Sammlung von Log-Buildern mit den man leichter (invers) Potenzieren und im Komplexen rechnen könnte. Ich habe mal abgeschätzt, dass sich in eine aktuellen Silizium CMOS-Technologie eine Wurzel mit einem 64Bit-Eingang und 32.32-Ausgang in unter 10ns machen lassen sollte. Platzsparend als pipeline mit 8 Takten sollte das auf maximal 40ns kommen können. Bei 8 solchen Einheiten hätte man >200 MHz. mit geringer 8er Latenz.
Andi schrieb: > Udo K. schrieb: >> 1. Es gibt nicht "den FPGA". >> >> Der billigste fängt bei Digikey bei ca. 5 Dollar an (da passt ein >> grösseres Schieberegister rein), ... > > https://www.digikey.com/product-detail/en/lattice-semiconductor-corporation/ICE40LP384-SG32/220-2646-ND/3974680 > > https://www.digikey.com/product-detail/en/lattice-semiconductor-corporation/ICE40UL640-SWG16ITR50/220-1961-2-ND/5130905 > > Bei beiden passt wesentlich mehr als ein Schieberegister rein, im > UltraLight mit seinen BlockRAMs kann man leicht einen Softcore > unterbringen. > Beide haben sogar den Konfigurationsspeicher auf dem Chip (OTP). Ich sagte doch ein grosses Schieberegister. Was willst du mit 16 Pins und 80 CLB's (Was immer das bei Lattice ist) sonst machen? Ein Softcore zum LED blinken lassen ist vielleicht auch eine Idee, wenn man keine Mikrocontroller um 0.5 Euro programmieren kann... Aber willst du damit wirklich gegen einen Intel i7 antreten?
Jürgen S. schrieb: > Udo K. schrieb: >> schon mal versucht im FPGA Wurzel zu ziehen, > Ja >> oder einen Sinus zu berechnen > Ja >> eine IEEE 64 Bit Division gemacht? > Ja > > Wurzel und Division laufen in 64 Bit mit 33..35 Takten Latenz in 200MHz. > Beides lässt sich in LA4 auch mit 18 Takten machen, bei entsprechendem > Invest in AREA. In der "normalen", platzsparenden Konfiguration sind es > 66 Takte. Der berechnete! Sinus ohne Tabelle geht in Richtung 18 Takte > für eine 100dB-Qualität. In platzsparender Konfiguration 33 Takte. In > dieser normalen Konfig laufen die auch auf 300MHz. > > Das ist zunächst langsam! > > Da es aber pipelines sind, bekommt man immerhin mit jedem Takt ein > Ergebnis. In einen Artix15 passen laut Synthese mindestens 18 solcher > DIV-Einheiten. Macht 18 Divisionen alle 300 MHz. Rein rechnerisch sind > das "nur" 5GOPs. Da man die Ergebnisse in ähnlicher Weise parallel > weiterverarbeiten und zugreifen kann, entfallen durch die Speicherung in > FFs sehr viele Zugriffe auf Register und externes RAM, was eine CPU auch > erst noch leisen müsste. Die Kosten für einen Artix 15 liegen bei unter > 20,- Was leistet eine Intel CPU zu dem Preis? > > Ein Intel I7 mit 4 Kernen wird mit unter 100GFlops angegeben. Das ist > locker einen Faktor 20 über dem des FPGA. Nimmt man aber die real > mögliche Auslastung und zieht noch die Speicherbandbreitenthematik > heran, bröselt der Vorteil der CPU rasch zusammen und die vielen > "Terras" erweisen sich als "Flop" :D Ich denke die externe Speicherbandbreite ist in vielen Fällen durch die schnellen Caches kein so grosses Thema. Aber ein DDR4 Riegel mit ca. 25 GBytes/Sekunde oder eine TBit Netzwerkkarte ist auch nicht leicht zu schlagen. Was gibt es sonst noch? Richtig 2 Speicherriegel und zwei Netzwerkkarten :-) > Ich habe das vor Kurzem erst wieder einem Kunden vorgerechnet, der die > gesamte Mathematik in einem ARM machen wollte, "weil der effektiver > ist". Bei dem hat es schon in der Erstbetrachtung nicht mehr hingehauen. > Ich konnte sogar zeigen, dass die Zynq-Lösung materialmässig teuer > kommt. In der Diskussion hier vermischen wir wild uC Anwendungen, Audio Streaming und Filterung und High Performance Computing. Und jeder will rechthaben... Tut mir echt leid für das Wirrwarr! In vielen Anwendungen wo schnelle ADCs gebraucht werden, ist natürlich ein FPGA drinnen, anders geht es nicht. Die CPU brauchst du dann aber in der Regel trotzdem noch, da heute ein Produkt mit >100 MByte / Sekunde Datendurchsatz ohne standardisierte PC Schnittstellen am Markt nicht ernst genommen wird. > Grundsätzlich ist dein Einwand aber richtig: Solche Operationen sind in > FPGAs unverhältnismäßig schlecht umzusetzen. Es schreit gerade danach, > neben den MULs in küftigen Technologien auch DIVs und andere > festverbaute Co-Prozessorfunktionen einzubauen. > > Von Intel dürfte da demnächst wohl einiges kommen! Da bin ich gespannt, die letzen Jahre haben sie ja geschlafen. > Ich würde mir diesbezüglich eine (a*a - b*b) / srqt(c) - Enheit > wünschen. Damit kriegt man nicht nur die Wurzel (oder per Einspeisung > von C*C) eine klassische Division mit zwei möglichen Komponenten frei > Haus, sondern erledigt auch eine ganze Reihe von Rechenanforderungen bei > Iterationen, Konvergenzrechnungen etc. > > Das nächste wäre eine Sammlung von Log-Buildern mit den man leichter > (invers) Potenzieren und im Komplexen rechnen könnte. > > Ich habe mal abgeschätzt, dass sich in eine aktuellen Silizium > CMOS-Technologie eine Wurzel mit einem 64Bit-Eingang und 32.32-Ausgang > in unter 10ns machen lassen sollte. Platzsparend als pipeline mit 8 > Takten sollte das auf maximal 40ns kommen können. Bei 8 solchen > Einheiten hätte man >200 MHz. mit geringer 8er Latenz. Danke für die detaillierte Info, und Hut ab vor der Leistung! Du gehörst sicher zu den 1%, die ich von meiner Polemik ausnehme. Ich kann das aber nicht mehr programmieren. Da muss ich mir ja praktisch eine Floating Point ALU mit Gattern basteln, die eine N-stufige Pipeline hat. Die Anzahl und Aufteilung der Pipeline muss ich in Abhängigkeit vom konkreten FPGA genau wählen. Dazu muss ich die FPGA Spezialblöcke und die Synthese Tools in und auswendig kennen, damit ich auf nennenswerte Performance komme. Nicht zu vergessen die Mathematik dahinter ist nicht ganz trivial. (Und dann ärgere ich mich garantiert mit 18 Bit breiten Mutliplizierern rum, warum sind die nicht 64 Bit breit...) Und das ist erst der Anfang. Die Daten müssen ja auch erst irgendwoher kommen. In Windows sage ich da OpenFile(), und dann ReadFile(), eventuell mache ich das in einer Schleife für N Threads. Aber im FPGA muss ich meine Low Level Struktur mit den ganzen kritischen Buffern und Datenpfaden erst mal detailliert plannen, und in unzähligen Versuchen optimieren. Verwendest du da eigenlich noch VHDL? Gibt es da inzwischen schon etwas besseres für so komplexe Dinge? Auf der CPU Seite schaut es wesentlich gemütlicher aus. All das (und viel mehr) haben die CPU Hersteller zum Glück für mich schon erledigt. Ich kann mich direkt um die Anwendung kümmern. In C/C++ schreibe ich y = sin(x), und das ist meistens ausreichend schnell. Sonst verwende ich die Intel MKL Libs, und habe recht einfach einen Faktor 10. So wie ich das sehe, ist ein FPGA nur schneller als eine CPU/GPU, wenn ich sehr viele Operationen parallel machen kann, und es keine Abhängigkeiten gibt. Dann kann ich aber auch 10^6 CPUs verwenden, und die Frage reduziert sich auf die Kosten. Was ist günstiger und hat mehr Flops / Million Euro? Die Supercomputer verwenden jedenfalls CPUs, gemischt mit GPUs. Von FPGAs habe ich da noch nichts gehört. Ich glaube ich liege mit meiner Einschätzung noch immer richtig, FPGAs bitte nur dort, wo es absolut nicht ohne geht.
Udo K. schrieb: > Ich sagte doch ein grosses Schieberegister. Was willst du mit > 16 Pins und 80 CLB's (Was immer das bei Lattice ist) sonst > machen? Der billigste von mir jemals verbaute FPGA war vor 12 Jahren ein Spartan 3A. Der kostete damals im Einkauf unter 3,-! Untergebracht waren: 1x CAN-Slave 1x I2C-Master 8x Registerbank mit 64 Speichern / 256 Plätzen mit 8 Bit. 1x Fehlererkennungsmodul 1x Leitungstester 1x CEC 1x EERPOM-Schnittstelle 2x Temperatursensoren also nix mit "ein großes Schieberegister". Udo K. schrieb: > Von FPGAs habe ich da noch nichts gehört. Banken verwenden Multi-FPGA-Plattformen für solides und robustes Datenmanagement und Transaktionen.
Udo K. schrieb: > In C/C++ schreibe ich y = sin(x), Damit benutzt du eine Library. Das geht in VHDL auch durch Instanziierung einer Sinusfunktion als Core. Wenn du Programmiertechniken vergleichen möchtest, müsstest du schon Multithreading-Funktionen verwenden, die sowohl eine CPU als auch einen FPGA auslasten. Schneller hingeschrieben ist C++ allemal, aber das heißt für die Ausführungsgeschwindigkeit meistens das Gegenteil.
Udo K. (udok) >Die Supercomputer verwenden jedenfalls CPUs, >gemischt mit GPUs. >Von FPGAs habe ich da noch nichts gehört. https://www.nextplatform.com/2019/04/18/supercomputer-mixes-streams-with-cpu-gpu-and-fpga/
Udo K. schrieb: > Ich sagte doch ein grosses Schieberegister. Was willst du mit > 16 Pins und 80 CLB's (Was immer das bei Lattice ist) sonst > machen? Glue-Logic, Standard-Logik Gräber aufräumen/ersetzen. Spart Platz auf der Leiterplatte, ist einfacher zu Routen, kleinere Lagerhaltung, weniger Feeder im Pick&Place Automat, weniger Pins zu testen im Flying-Prober etc. (Das galt damals ja alles auch schon für PAL/GAL, nur ist der Preis heute besser). Hat uns dann auch gut den Arsch gerettet, da dann nachträglich ein paar Signale "entprellt" werden mussten (Selbstverursachte EMV Störungen in Leistungselektronik). Im kleinsten MachXO 128 war dazu noch locker Platz (Hatte aber mehr als 16 Pins :-)). Aber das geht alles am eigentlichen Thema dieses Threads vorbei :-) Udo K. schrieb: > Verwendest du da eigenlich noch VHDL? > > Gibt es da inzwischen schon etwas besseres für so komplexe Dinge? Willkommen im uC VHDL Forum! Das ist so zu sagen eines unserer Lieblingsthemen das wir hier in unregelmässigen Abständen diskutieren, ergänzen, Erfahrungsberichte austauschen. Gibt mehrere Threads dazu. Kurze Antwort: Nein, wir sind alle noch am Suchen. Es gibt Tools die Teilprobleme erfolgreich adressieren aber ob das für dich/deine Anwendung besser ist, muss gut evaluiert werden.
Ich finde ja, da bräuchte es mal einen Standard (https://imgs.xkcd.com/comics/standards.png ). Ich weiß aber nicht genau wofür. Ich denke mir das so: Man hat zusätzlich zu CPU, GPU, ... auch noch einen FPGA im System. Und der kann dynamisch rekonfiguriert oder eben schnell konfiguriert und neu gestartet werden. Und dann können Programme da (partielle)Bitstreams mitbringen. Also ein Musikprogramm DAW bringt da einen Bitstream mit. Wenn der Rechner einen FPGA hat, dann wird der Bitstream geladen, und dann werden z. B. Effekte auf der Musik in Hardware im FPGA gerechnet. Hat der Rechner keinen FPGA wird das eben auf der CPU/GPU mit OpenCL gemacht. Man müsste aber eben standardisieren wie so ein Bitstream aufgebaut ist und auch was das FPGA können muss oder wie es dem System sagt was es kann. Vermutlich geht das eher gut über so ein Zwischenformat wie im Browser mit WebAssembly (https://www.destroyallsoftware.com/talks/the-birth-and-death-of-javascript ) oder eben bei Java mit der JVM. Man liefert also eine ART Bitstream mit, und zwar für einen virtuellen FPGA den es nicht gibt, aber eine Software (je nach FPGA Hersteller des verbauten FPGAs) am PC versteht das Format und übersetzt das. Gut, das dauert vermutlich etwas, aber das ist ja nur einmalig. Danach liegt ein passender Bitstream für den verbauten FPGA vor. Oder ... es gibt nicht so irre viele Hardwarevarianten und die Softwarehersteller haben einfach mehrere Bitstreams auf Lager.
{kind=link}
Gustl B. schrieb: > Ich weiß aber nicht genau > wofür. Ich denke mir das so: > Man hat zusätzlich zu CPU, GPU, ... auch noch einen FPGA im System. Und > der kann dynamisch rekonfiguriert oder eben schnell konfiguriert und neu > gestartet werden. Und dann können Programme da (partielle)Bitstreams > mitbringen. Ja, so etwas braucht es definitiv, schon seit min. 15 Jahren. Ist es immer noch so, dass die ganze partielle Rekonfigurationsgeschichte bei Xilinx unter NDA steht? (also Datenblatt dazu, Tools um es zu nutzen etc.) NDA ist schon mal das komplette Gegenteil von Standard... Mit dem (overengineered bzw. oversized) IP-XACT und dem Standard für verschlüsselte IP Cores würde es Ansätze in diese Richtung geben ohne das es heute wirklich was nutzt. Gustl B. schrieb: > Man liefert also eine ART Bitstream > mit, und zwar für einen virtuellen FPGA den es nicht gibt, aber eine > Software (je nach FPGA Hersteller des verbauten FPGAs) am PC versteht > das Format und übersetzt das. Gut, das dauert vermutlich etwas, aber das > ist ja nur einmalig. Genau so läuft das bei den GPUs mit ihren Shadern. "Shader werden initialisiert, bitte warten" Da gibt es zwei standardisierte Sprachen (je eine für DirectX und OpenGL. Vulkan? Keine Ahnung) und diese Shaderprogramme werden dann bei der ersten Nutzung für die Ziel-GPU kompiliert (einer der Gründe wieso ein GPU Treiber > 100 MB ist, da gerne mal ein LLVM und was sonst noch mit kommt). Stellt euch mal vor, ihr dürft eurem Kunden zusammen mit dem Treiber im Hintergrund noch "nebenbei" ein Vivado mit 18 GB installieren :-) Gustl B. schrieb: > Oder ... es gibt nicht so irre viele > Hardwarevarianten und die Softwarehersteller haben einfach mehrere > Bitstreams auf Lager. Das klappt, solange der Kunde die eine, oder eben die andere Xilinx Alveo Karte hat. Ist wohl auch genau das Ziel von Xilinx. ----------------------- Wie kommen wir weiter auch wenn die FPGA Hersteller es nicht begreifen, dass die interne Architektur/Bitstream offen dokumentiert sein sollte wie ein CPU Instruction Set? Reverseengineering und Open Source Tools. Genau damit sieht man jetzt schon genau diese Demonstrationen, auch wenn die erzielbare Frequenz noch hinkt. Raspberry Pi mit ICE40 drangesteckt, der dann seine Software selber kompiliert und Synthese/P&R für den ICE40 macht.
Christophz schrieb: > Ist es immer noch so, dass die ganze partielle > Rekonfigurationsgeschichte bei Xilinx unter NDA steht? (also Datenblatt > dazu, Tools um es zu nutzen etc.) > > NDA ist schon mal das komplette Gegenteil von Standard... Also zumindest seit ich Xilinx kenne ist das nicht der Fall. Mittlerweile sind die Tools sogar kostenlos verfuegbar, wenn ich mich richtig erinnere. https://www.xilinx.com/content/xilinx/en/products/design-tools/vivado/implementation/dynamic-function-exchange.html Edit: Jep, seit Vivado 2019.1 sogar im Webpack kostenlos verfuegbar.
Gustl B. schrieb: > Man hat zusätzlich zu CPU, GPU, ... auch noch einen FPGA im System. > Und der kann dynamisch rekonfiguriert oder eben schnell konfiguriert > und neu gestartet werden. Das kenne ich von Mobilplattformen, die ihre eigenen DSPs enthalten und wo die Anwendungen dann mal eben schnell ein zu beschleunigendes Programm reinladen. Gern gemacht für Audio- und Videofilter. > Und dann können Programme da (partielle)Bitstreams mitbringen. > Also ein Musikprogramm DAW bringt da einen Bitstream mit. > Wenn der Rechner einen FPGA hat, dann wird der Bitstream geladen, und > dann werden z. B. Effekte auf der Musik in Hardware im FPGA gerechnet. Man will sich aber auch den FPGA mit anderen teilen können (wir sind ja nicht bei den Mobilplattformen, die aus Batteriegründen ohnehin nur eine Brachialanwendung gleichzeitig können und auch nicht für Multitasking gedacht sind). Die prinzipielle Parallelität von FPGAs wäre da super, allerdings steht dem die Räumlichkeit im Wege. Haben die Großen das Problem schon sinnvoll gelöst, oder muss man selbst sicherstellen, dass sich die (partiellen) Bitstreams nicht überlappen? > Hat der Rechner keinen FPGA wird das eben > auf der CPU/GPU mit OpenCL gemacht. Das wird relativ schwierig, weil man da komplett andere Konzepte für braucht. Oder anders ausgedrückt: Wenn man das Problem auf eine GPU-freundliche Weise ausdrückt, dann wird die FPGA-Logik eigentlich auch nur eine breite Vektoreinheit. Daher würde ich das lieber auf der Anwendungsebene realisieren, wie es bisher auch der Fall ist (MMX-Fallback bei fehlender SSE-Unterstützung, Emulation statt JIT bei unbekannter Host-Architektur, etc.) > Man müsste aber eben standardisieren wie so ein Bitstream > aufgebaut ist und auch was das FPGA können muss oder wie > es dem System sagt was es kann. Das sollte sich recht gut abstrahieren lassen, zumal sich FPGAs im Grundprinzip nur wenig unterscheiden (am Ende gibt es nur LUTs, FFs und einige Fixed-Function-Blöcke). Eigentlich kann man da eine recht gebrauchbare Netzliste reinkippen und fertig. Bei solchen Ansätzen kommt es auch nicht auf maximale Performance mehr an, sondern auf Universalität. > Vermutlich geht das eher gut über so ein Zwischenformat wie im > Browser mit WebAssembly oder eben bei Java mit der JVM. WebAssembly eher weniger (zumal es in der Realität hauptsächlich für Spielereien und Bitcoin-Trojaner benutzt zu werden scheint...), aber GPUs machen das jetzt schon so. Die bisherigen Shader-Sprachen liegen eher auf dem Niveau von C, daher braucht man einen recht ordentlichen Compiler. Mit Vulkan gibt es SPIR-V, was ersten ein definiertes Bitformat hat (man spart sich also den fehlerträchtigen Parser) und wesentlich näher an der Hardware liegt. Darum löst Vulkan auch langsam die bisherigen Ansätze ab. > Oder ... es gibt nicht so irre viele Hardwarevarianten und > die Softwarehersteller haben einfach mehrere Bitstreams auf Lager. Keine gute Idee. Damit landest du bei der DOS-Kompatiblitätshölle, wo jede Soundkarte irgendwie SoundBlaster sprechen musste, weil sonst nichts ging. Da braucht man schon noch eine Ebene dazwischen, um Fortschritte erzielen zu können. Christophz schrieb: > Da gibt es zwei standardisierte Sprachen (je eine für DirectX und > OpenGL. Vulkan? Keine Ahnung) und diese Shaderprogramme werden dann bei > der ersten Nutzung für die Ziel-GPU kompiliert (einer der Gründe wieso > ein GPU Treiber > 100 MB ist, da gerne mal ein LLVM und was sonst noch > mit kommt). Der andere Grund ist, dass Grafikkartenhersteller notorische Cheater sind und bei Compilerproblemen lieber in der neuen Treiberversion handgeklöppelte Ersatzshader für bestimmte Problemkinder mitliefern. Das Spiel sagt "bitte Shader vorbereiten" und der Grafiktreiber sagt "oh, den Shader kenne ich, ich nehme einen anderen". Deswegen sehen manche Spiele bei unterschiedlichen Treiberversionen auch unterschiedlich aus. Christophz schrieb: > Stellt euch mal vor, ihr dürft eurem Kunden zusammen mit dem Treiber im > Hintergrund noch "nebenbei" ein Vivado mit 18 GB installieren :-) Wenn man die Treiberqualität von Grafiktreibern als Maßstab nimmt... dann gehe ich lieber in die Ecke und weine. Wenn "corner cutting" darauf hinausläuft, dass noch zwei Wände vom Haus stehen und ständig mit Bluescreen umfallen, dann verzichte ich lieber dankend darauf. (Es ist etwas besser geworden, seit Windows auch für den Desktop 3D benutzt, aber trotzdem.) Aber mit einer ordentlichen Abstraktion und halbwegs gebrauchbaren Bitformaten bräuchte man vom VivadoQuartusIseDiamond ja nur ein paar Kleinteile. Dass die Hersteller das nicht wollen, ist aber aus deren Sicht nachvollziehbar. Christophz schrieb: > Reverseengineering und Open Source Tools. Mal schauen. Erstmal brauchen wir programmierbare FPGAs in hinreichender Breite. Einen ICE40 auf einen Raspberry zu stecken meine ich damit nicht. Intel hat ja mal Xeon-Prozessoren mit FPGA für Rechenzentren vorgestellt, ist daraus eigentlich was geworden? Das muss jetzt (mit kleinen FPGAs) nur noch im Massenmarkt ankommen. PS @Gustl: Sowas wäre im Übrigen meine Forschung gewesen, wenn da nicht andere Dinge dazwischen gekommen wären. ;-)
S. R. schrieb: > Intel hat ja mal Xeon-Prozessoren mit FPGA für Rechenzentren > vorgestellt, ist daraus eigentlich was geworden? Intel hat schon vor dem Kauf von Altera mehrfach angekündigt, dass sie verstärkt FPGA-Technologie in den CPUs einsetzen werden. Einerseits aus Gründen der update-Fähigkeiten aber auch zum Anpassen an unterschiedliche Hardware. Es dürfte auch ein Teil von Intelligenz zur thread-Verwaltung und Sicherung des OS und lowlvel Zugriffe dorthin verlagert werden.
S. R. schrieb: > Man will sich aber auch den FPGA mit anderen teilen können (wir sind ja > nicht bei den Mobilplattformen, die aus Batteriegründen ohnehin nur eine > Brachialanwendung gleichzeitig können und auch nicht für Multitasking > gedacht sind). Die prinzipielle Parallelität von FPGAs wäre da super, > allerdings steht dem die Räumlichkeit im Wege. Tja das müsste dann irgendwie in Parzellen unterteilt werden können. Und jede Parzelle für sich enthält dann DSPs, BRAM, PLL, ... und ist getrennt von den Anderen konfigurierbar. Ein großes Design füllt dann eben mehrere Parzellen. Und man kann Anforderungen stellen wie dass man noch SRAM vraucht oder mindestens n Leitungen zu einer anderen Parzelle. S. R. schrieb: > Das wird relativ schwierig, weil man da komplett andere Konzepte für > braucht. Oder anders ausgedrückt: Wenn man das Problem auf eine > GPU-freundliche Weise ausdrückt, dann wird die FPGA-Logik eigentlich > auch nur eine breite Vektoreinheit. > > Daher würde ich das lieber auf der Anwendungsebene realisieren, wie es > bisher auch der Fall ist (MMX-Fallback bei fehlender SSE-Unterstützung, > Emulation statt JIT bei unbekannter Host-Architektur, etc.) Das meinte ich auch. Also wenn man keinen FPGA im Rechner hat, dann wird eben ein für CPU oder GPU optimierter Code ausgeführt. Als Softwarehersteller muss man also weiterhin ein Binary für die CPU mitliefern das dort läuft wenn kein FPGA da ist. Mit FPGA werden ja auch nur manche Teile dorthin ausgelagert. Cooler wäre aber schon eine Zwischensprache oder so die dann erst lokal für CPU, GPU oder FPGA übersetzt wird. Aber das wird schwer weil das eben andere Ansätze sind. Da müsste man das eigentlich zu lösende Problem noch hoherleveliger beschreiben und zwar so, dass dann irgendeine Software lokal aus dieser Beschreibung selbst eine Lösung baut. Und zwar für das Ziel dass sie für passend hält. ABer da sind wir noch nicht. S. R. schrieb: > Keine gute Idee. Damit landest du bei der DOS-Kompatiblitätshölle, wo > jede Soundkarte irgendwie SoundBlaster sprechen musste, weil sonst > nichts ging. Da braucht man schon noch eine Ebene dazwischen, um > Fortschritte erzielen zu können. Kommt drauf an was das Szenario ist. Wenn man eine große Firma ist und da nur wenige unterschiedliche Hardware sehr oft rumstehen hat, dann ist das kein Problem. Für Endkunden macht das nur Sinn wenn man so wie Apple einen kleinen Gerätepark hat. S. R. schrieb: > Intel hat ja mal Xeon-Prozessoren mit FPGA für Rechenzentren > vorgestellt, ist daraus eigentlich was geworden? Die gibt es schon noch IIRC. Der 6138P hat einen Arria 10 mit drinnen. Ja und große Firmen wie Microsoft setzen auch stark auf FPGA https://www.microsoft.com/en-us/research/publication/configurable-cloud-acceleration und https://www.microsoft.com/en-us/research/project/project-brainwave . S. R. schrieb: > Sowas wäre im Übrigen meine Forschung gewesen, wenn da nicht > andere Dinge dazwischen gekommen wären. ;-) Tja :-) Ist ein spannendes Feld. Aber ... vielleicht kommen ja auch bald überall diese neuronalen Netze in ICs.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.