Hallo,
ich überlege gerade, mir in Zukunft ein Programm in C++ zum sogenannten
"Screeen Scraping" zu programmieren. Ziel soll es sein, Daten aus einer
Homepage zu extrahieren und in einer Art Datenbank zu hinterlegen.
Deswegen wollte ich Fragen, wie hierzu die allgemeine Vorgehensweise
wäre und wo ich ggf. entsprechende Lektüre zu den einzelnen Punkten
erhalten kann.
Kenntnisse im C/C++ Programmieren sowie grundlegende Kenntnisse über
Netzwerktechnologien (TCP/IP Protokolle etc.) sind vorhanden.
Meine Recherchen haben bis jetzt folgendes ergeben.
Als erste benötige ich Kenntnisse von Winsock. Dies sollte ermöglichen,
Verbindungen zu einem Server herzustellen und Daten anzufordern. Hier
stellt sich schon die erste Frage, ob ich die TCP-Funktionalitäten in
Eigenarbeit programmieren muss oder ob es fertige Bibliotheken gibt.
Hiermit meine ich das Sortieren der ankommenden Pakete sowie das
Neuanfordern falls Pakete verloren gehen.
Wenn das Funktioniert wäre schoneinmal der erste Große Schritt erledigt.
Ich möchte auch nicht gerade Morgen fertig werden.
Als zweites sollte ich mich wohl mit dem http Protokoll vertraut machen
und herrausfinden, in welchem Format die Daten der Website gesendet
werden (Seitenquelltext?).
Als letztes müsste ich mich noch in Datenbanken einlesen, um die Daten
die sich im Arbeitsspeicher befinden nun sinnvoll einzuordenen.
A. R. schrieb:> Hallo,>> ich überlege gerade, mir in Zukunft ein Programm in C++ zum sogenannten> "Screeen Scraping" zu programmieren. Ziel soll es sein, Daten aus einer> Homepage zu extrahieren und in einer Art Datenbank zu hinterlegen.>> Deswegen wollte ich Fragen, wie hierzu die allgemeine Vorgehensweise> wäre und wo ich ggf. entsprechende Lektüre zu den einzelnen Punkten> erhalten kann.>> Kenntnisse im C/C++ Programmieren sowie grundlegende Kenntnisse über> Netzwerktechnologien (TCP/IP Protokolle etc.) sind vorhanden.>> Meine Recherchen haben bis jetzt folgendes ergeben.>> Als erste benötige ich Kenntnisse von Winsock. Dies sollte ermöglichen,> Verbindungen zu einem Server herzustellen und Daten anzufordern. Hier> stellt sich schon die erste Frage, ob ich die TCP-Funktionalitäten in> Eigenarbeit programmieren muss oder ob es fertige Bibliotheken gibt.> Hiermit meine ich das Sortieren der ankommenden Pakete sowie das> Neuanfordern falls Pakete verloren gehen.>> Wenn das Funktioniert wäre schoneinmal der erste Große Schritt erledigt.> Ich möchte auch nicht gerade Morgen fertig werden.>> Als zweites sollte ich mich wohl mit dem http Protokoll vertraut machen> und herrausfinden, in welchem Format die Daten der Website gesendet> werden (Seitenquelltext?).>> Als letztes müsste ich mich noch in Datenbanken einlesen, um die Daten> die sich im Arbeitsspeicher befinden nun sinnvoll einzuordenen.
Man kann das "zu Fuß" erledigen und vom TCP/IP-Stack bis zur
eigentlichen Funktionalität alles selbst schreiben.
Man kann Bibliotheken für C/C++ nehmen oder besser dafür geeignete
Sprachen inkl. Frameworks einsetzen die das können (C#, VB, Java, Ruby,
Python etc).
Oder nutzt einfach wget
ftp://ftp.gnu.org/old-gnu/Manuals/wget/html_chapter/wget_3.html
ftp://ftp.gnu.org/old-gnu/Manuals/wget/html_chapter/wget_toc.html
und packt das Ergebnis in eine DB.
Mit der Curl-Bibliothek kannst du direkt auf der HTTP-Ebene einsteigen.
Dann geht das ganz leicht.
Noch leichter geht es, wie Arc Net schon geschrieben hat, mit Python
oder Ruby. Da sind die entsprechenden Bibliotheken schon im Standardum-
fang inbegriffen, und es bedarf nur weniger Codezeilen, um eine Website
einzulesen. Beispiel in Python:
1
from urllib.request import urlopen
2
data = urlopen('http://www.mikrocontroller.net/topic/223569').read()
Danach stehen die heruntergeladenen Daten als Bytestring in data.
Das bekommst du in C++ trotz Curl nicht in zwei Zeilen hin.
Sind die Daten HTML, kannst du daraus bestimmte Inhalte mit Regular
Expressions oder einem HTML-Parser extrahieren. Auch diese sind bei
Python schon mit dabei. Für C/C++ gibt es PCRE für Regular Expressions,
ein HTML-Parser fällt mir gerade keiner ein, es gibt aber sicher gleich
mehrere davon.
> Als letztes müsste ich mich noch in Datenbanken einlesen, um die Daten> die sich im Arbeitsspeicher befinden nun sinnvoll einzuordenen.
Da hängt es davon ab, welche Daten du in welcher Form abspeichern
möchtest. Bei Python hast du bspw. die Auswahl zwischen mehreren
integrierten Datenbanken (z.B. SQLite), bei denen du nichts zusätzlich
installieren musst. SQLite geht aber auch in C++.
Oder du kaufst die gleich eine Oracle-Datenbank, dann hast du wenigstens
was Ordentliches ;-)
Auch dafür gibt es natürlich Unterstützung sowohl für Python als auch
für C++.
A. R. schrieb:> Hallo,>> ich überlege gerade, mir in Zukunft ein Programm in C++ zum sogenannten> "Screeen Scraping" zu programmieren. Ziel soll es sein, Daten aus einer> Homepage zu extrahieren und in einer Art Datenbank zu hinterlegen.
C++ für sowas ist nicht direkt ideal, zu viel Arbeit und zu viele
Möglichkeiten für Buffer Overflows etc. Ich würde eher an Java oder C#
denken.
Screen Scraping generell ist eine schlechte Idee.
> Deswegen wollte ich Fragen, wie hierzu die allgemeine Vorgehensweise> wäre und wo ich ggf. entsprechende Lektüre zu den einzelnen Punkten> erhalten kann.>> Kenntnisse im C/C++ Programmieren sowie grundlegende Kenntnisse über> Netzwerktechnologien (TCP/IP Protokolle etc.) sind vorhanden.>> Meine Recherchen haben bis jetzt folgendes ergeben.>> Als erste benötige ich Kenntnisse von Winsock. Dies sollte ermöglichen,> Verbindungen zu einem Server herzustellen und Daten anzufordern. Hier> stellt sich schon die erste Frage, ob ich die TCP-Funktionalitäten in> Eigenarbeit programmieren muss oder ob es fertige Bibliotheken gibt.> Hiermit meine ich das Sortieren der ankommenden Pakete sowie das> Neuanfordern falls Pakete verloren gehen.
Wenn Du Winsock nimmst macht sowas das OS für Dich - dafür ist es
schliesslich da.
> Wenn das Funktioniert wäre schoneinmal der erste Große Schritt erledigt.> Ich möchte auch nicht gerade Morgen fertig werden.>> Als zweites sollte ich mich wohl mit dem http Protokoll vertraut machen> und herrausfinden, in welchem Format die Daten der Website gesendet> werden (Seitenquelltext?).
HTML, XHTML, CSS (na gut, wohl irrelevant). Wobei eine URL tatsächlich
ein beliebiges Datenformat zurückliefern kann, oder auch mehrere
Alternativen soweit ich weiss.
> Als letztes müsste ich mich noch in Datenbanken einlesen, um die Daten> die sich im Arbeitsspeicher befinden nun sinnvoll einzuordenen.
Ahhh, Datenbanken... ;-)
Wie gesagt, Screen Scraping ist böse, es könnte sinnvoll funktionieren
wenn denn jeder korrektes HTML schreiben würde. Du wirst schnell merken
dass die Web-Welt ein totaler Dschungel ist - praktisch keine Webseite
ist Standard-konform. Viel Spass damit.
Erstmal vielen Dank für die rege Resonanz.
Die Posts sollte mir schoneinmal genug Anregungen geben weitere
Nachforschungen zu machen. In den nächsten Wochen ist erstmal Lernen für
Klausuren angesagt danach kann ich mich dann in die Thematik
einarbeiten.
Ich wollte eigendlich C++ weiterverwenden. Deswegen denke ich, dass ich
mir als Erste die Möglichkeiten der QT-Bibliothek und von Curl anschauen
werde.
Vielleicht kann mir nochmal kurz jemand helfen.
Benutze Visual Studio 2010
Wenn ich den curl Header einfügen möchte.
#include <curl/curl.h>
Kann diese Datei nicht gefunden werden.
Das heißt also wohl, dass ich die Datei vorher herrunterladen und ggf.
instllieren muss.
Habe auch eine Seite zum downloaden gefunden.
http://curl.haxx.se/download.html
Dort werde ich dann weitergeleitet auf folgende Seite.
ftp://ftp.sunet.se/pub/www/utilities/curl/
Woher soll ich wissen, welche Datei ich benötige?
A. R. schrieb:> Woher soll ich wissen, welche Datei ich benötige?
Auf der Seite gibt es einen Link namens "curl Download Wizard", der dich
mit gezielten Fragen zum Ziel führt.
Aber wahrscheinlich ist schon klar, was du möchtest, nämlich ein Paket
für "Win32 - MSVC" (ziemlich am Ende der Seite). Das enthält die bereits
kompilierte Bibliothek (libcurl) und die zugehörigen Header-Files.
Willst du die allerneueste Version, musst du den Sourcecode (am Anfang
der Seite) herunterladen und selber kompilieren. Für den Anfang sollte
aber die Prebuilt-Version genügen, so alt ist die noch nicht.
Es mag andere interessieren, dass es zu diesem Zweck bereits
Bibliotheken gibt, die den Zugriff auf die gewollten HTML/XML/DOM
Elemente/Inhalte vereinfachen und dabei fehlertolerant sind. Stichwort
"Beautiful Soup"
Auch damit (ohne Netzwerk, regexp selbst zu machen) hat man genug zu
tun, an die Daten zu kommen
A. R. schrieb:> Woher soll ich wissen, welche Datei ich benötige?
Du uebernimmst dich gerade gewaltig. Lerne erst Mal an einem kleineren
Projekt programmieren.
Yalu X. schrieb:> A. R. schrieb:> Aber wahrscheinlich ist schon klar, was du möchtest, nämlich ein Paket> für "Win32 - MSVC" (ziemlich am Ende der Seite). Das enthält die bereits> kompilierte Bibliothek (libcurl) und die zugehörigen Header-Files.
Danke für die Hilfe.
Da ich vorher noch nie eine Bibliothek eingebunden habe. Versuchte ich
zuerst mich etwas einzulesen. Hierzu habe ich folgende wie ich finde
sehr gute Anleitung gefunden.
http://curl.haxx.se/libcurl/c/visual_studio.pdf
Habe meiner Entwicklungsumgebung also mitteilen können, wo sich die
Headerdateien und die curllib.lib befindet.
Das scheint auch funktioniert zu haben, da die Entwicklungsumgebung
(Intellisense) Kenntniss von den Funktionen bekommen hat.
Nach dem Compilieren kam die Fehlermeldung, dass die dll nicht gefunden
wurde. Dies konnte damit behoben werden, dass ich die dll in den
System32 Ordner verschoben habe.
So weit so gut. Damit konnte ich alle Punkte aus der Anleitung
nachverfolgen.
Es gibt nur noch ein Problem. Wenn ich compiliere bekomme ich folgende
Ausgabe:
"MyApplication.exe": "C:\Users\Andreas
Reeh\Desktop\Ordner\Informatik\Project\libcurl\VisualStudio\MyApplicatio
n\Debug\MyApplication.exe" geladen, Symbole wurden geladen.
"MyApplication.exe": "C:\Windows\System32\ntdll.dll" geladen, Cannot
find or open the PDB file
"MyApplication.exe": "C:\Windows\System32\kernel32.dll" geladen, Cannot
find or open the PDB file
"MyApplication.exe": "C:\Windows\System32\KernelBase.dll" geladen,
Cannot find or open the PDB file
"MyApplication.exe": "C:\Users\Andreas
Reeh\Desktop\Ordner\Informatik\Project\libcurl\VisualStudio\MyApplicatio
n\Debug\curllib.dll" geladen, Die Binärdaten wurden nicht mit
Debuginformationen erstellt.
Der Thread 'Win32-Thread' (0x8994) hat mit Code -1072365566 (0xc0150002)
geendet.
Das Programm "[33524] MyApplication.exe: Systemeigen" wurde mit Code
-1072365566 (0xc0150002) beendet.
Hat jemand eine Idee was das sein könnte?
A. R. schrieb:> "MyApplication.exe": "C:\Users\Andreas> Reeh\Desktop\Ordner\Informatik\Project\libcurl\VisualStudio\MyApplicatio
n\Debug\MyApplication.exe"
> geladen, Symbole wurden geladen.>> "MyApplication.exe": "C:\Windows\System32\ntdll.dll" geladen, Cannot> find or open the PDB file>> "MyApplication.exe": "C:\Windows\System32\kernel32.dll" geladen, Cannot> find or open the PDB file>> "MyApplication.exe": "C:\Windows\System32\KernelBase.dll" geladen,> Cannot find or open the PDB file>> "MyApplication.exe": "C:\Users\Andreas> Reeh\Desktop\Ordner\Informatik\Project\libcurl\VisualStudio\MyApplicatio
n\Debug\curllib.dll"
> geladen, Die Binärdaten wurden nicht mit Debuginformationen erstellt.
Diese Meldungen kannst Du erstmal einfach ignorieren. Die besagen, das
Du zwar Dein Programm im Sourcecode debuggen kannst, nicht aber die
System-DLLs von Windows und auch nicht die curllib.dll selbst.
A. R. schrieb:> Das Programm "[33524] MyApplication.exe: Systemeigen" wurde mit Code> -1072365566 (0xc0150002) beendet.
Die Meldung besagt, das Dein Programm mit dem Errorcode 0xc0150002
beendet wurde. Wahrscheinlich fehlt ihm noch irgendeine DLL. Hast Du die
curl-Version mit SSL-Support genommen? Dann fehlen Dir eventuell die
OpenSSL-DLLs. Beim VisualStidio bzw. PlatformSDK müßte ein Tool Depends
bzw. DependancyWorker dabei sein. Wenn Du Deine MyApplication.exe da mal
reinwirfst siehst Du welche DLLs geladen werden bzw. fehlen.
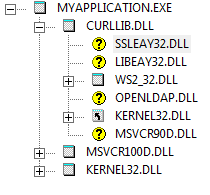
Habe mir gerade das Programm Dependency Walker herruntegeladen und auf
meine .exe angewendet.
Das Ergebniss befindet sich im Anhang.
Ist das normal, dass so viele DLLs fehlen?
Das ist bis jetzt eine endlos lange Geschichte gewesen.
Immer dann, wenn ich eine neue DLL eingefügt habe wurde eine neue DLL
gefunden welche fehlt.
Habe das ganze jetzt so lange gemacht, bis ich nur noch einen Fehler
finden konnte. Dieser befindet sich im Anhang. Hat jemand eine Idee, wie
sich das Problem beheben lässt?
DLL-Einbinden funktioniert jetzt.
Mein Programm verbindet sich mit einer Seite meiner wahl.
Speichert die Daten die empfangen werden im Heap ab und gibt einen
Pointer zurück.
Anschließen schreibe ich alle Daten auf dem Heap in ein txt-Dokument.
Geschrieben wurde das ganze in C mit curl.
Was ich empfange ist der "Seitenquelltext", den man auch mit Firefox
aufrufen kann wenn man rechts klickt und auf "Seitenquelltext anzeigen"
geht.
Habe jetzt noch 2 Fragen.
1. Im txt-Dokument ist nur ein Teil des Textes formatiert also mit
Tabulatoren und Zeilenumbrücken versehen. Ein anderer Teil ist komplett
unformatiert. Ist das normal?
2. Bei machen Seiten funktioniert das ganz gut.
Bei anderen Seite muss ich Jasch rechtgeben
>Wie gesagt, Screen Scraping ist böse, es könnte sinnvoll funktionieren>wenn denn jeder korrektes HTML schreiben würde. Du wirst schnell merken>dass die Web-Welt ein totaler Dschungel ist - praktisch keine Webseite>ist Standard-konform. Viel Spass damit.
Wenn ich z.B. folgende Seite aufrufen
http://www.finanzen.net/aktien/realtimekurse.asp?inindex=1 , dann
bekomme ich zwar den Quelltext aber ohne Zahlenwerte.
Wenn ich hingegeben einen Zahlenwert markiere und dann Rechtsklicke und
auf "Auswahl-Quelltext anzeigen" klicke bekomme ich einen Quelltext
inklusive Zahlenwert. Hat jemand eine Idee woran das liegt?
Die Daten werden höchstwahrscheinlich per AJAX eingefüllt, was dein
Vorhaben in soweit vereinfache sollte, als das die Daten dann als XML
oder JSON vorliegen.
Ich würde dir empfehlen mal FireBug zu installieren, und dann im
Netzwerkmodul die AJAX Requests zu untersuchen.
Abrufen kann man diese dann wie eine "normale" Website...
GET /jquery-jetty6-test/info?wkns=623100;766403;BAY001;555750;659990;716200;725750;555200;578560;514000;703712;823212;ENAG99;840400;604843;843002;604700;750000;648300;803200;716460;578580;A1KRND;710000;BASF11;593700;519000;520000;A1EWWW;723610 HTTP/1.1
2
Host: jetty.ls-tc.de
3
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:5.0) Gecko/20100101 Firefox/5.0
Das sieht in der 2ten Zeile also nach dem GET-Befehlt so aus, als würden
einfach alle WKNs aufgelistet die ich haben möchte.
Als Antwort kommt dann eine Auflistung aller Daten:
Wie würdest du empfehlen weiter vorzugehen?
Kann ich direkt eine Anfrage senden oder muss ich vorher einen
kompletten Handshake programmieren damit der Server mich erkennt. Werde
die Seite nocheinmal im Laufe der Woche beobachten also wenn die Daten
auch aktuallisiert werden.
Werde die Tage auch nochmal alle Abläuft durchgehen die mir FireBug
anzeigt um zu verstehen, was da genau passiert.
@ Arc Net
Ja soetwas in der Richtung Javaskript ausführen dachte ich mir schon ^^.
Danke für die Info, werd mir das dem nächst mal genauer anschauen.
Die Daten zwischen GET und HTTP/1.1 sind diene URL welche du abrufen
müßtest.
Wenn du diese im Browser eingibst solltest du die gewünschten Daten als
Plain-Text angezeigt bekommen, und ebenso auch wenn du es direkt über
dein Programm abrufst.
Da die Seite kein Passwort o.ä. erfordert vermute ich mal, dass das ohne
spezielle Header klappt. Ansonsten müßte man mal weiterschauen und ggf.
noch ein simples Cookie handling implementieren.
kleine Zwischenbemerkung:
das Rechtliche nicht vergessen
einfach so Sachen von einer Homepage klauen und weiter verwenden, kann
auch in die Hose gehen (wenn man es nicht nur für sich privat nutzt)
@Robert L.,
danke für den Hinweis. Ich bin mir darüber im klaren habe auch
diesbezüglich Recherchiert. Im Moment scheint diese eine Grauzone zu
sein. Es gibt jedoch schon Präzedenzfälle, in denen Personen wegen
Ausnutzung von Screen Scraping zu Schadensersatz verklagt worden sind.
Hierbei handelte es sich jedoch um eine gewerbliche Nutzung. Ich denke,
dass die "Risiken" bei privatem Nutzen überschaubar sind. Das Programm
wird auch später nur von mir eingesetzt.
@ Läube,
was für mich interessant ist wäre primär diese Seite.
http://www.finanzen.net/aktien/realtimekurse.asp?inindex=1
Es wird folgender Header gesendet:
1
GET /lightstreamer/STREAMING_IN_PROGRESS?LS_session=S784e56152a6c7560T2008647&LS_phase=103&LS_domain=finanzen.net& HTTP/1.1
2
Host: push.finanzen.net
3
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:5.0) Gecko/20100101 Firefox/5.0
Als Antwort kommt dann ein Quelltext. Das ganze Funktioniert auch per
Software ganz gut. Nur die Software beendet sich nachdem der Quelltext
empfangen worden ist.
In der Übersicht in Firefox also im Firebug bleibt die Session jedoch
aufrechterhalten und an den Quelltext werden im Fester "Antwort" ständig
noch Daten dran gehangen.
In dieser Form:
A. R. schrieb:> Nur die Software beendet sich nachdem der Quelltext> empfangen worden ist
Dann musst du mal die Software ändern ;)
A. R. schrieb:> Eine Idee wie man diese Daten noch empfangen könnte?
Es gibt Prinzipiell zwei Arten:
- pull: Der Client ruft die Daten in festgelegten Intervallen ab
- push: Der Client hält die Verbindung offen und liest einfach brav
weiter, zwischen den Daten können aber Pausen sein.
Das einfachste wird sein mit einer passenden Library halt mal zu schauen
was hier zutrifft.
in Java könnte das z.B. so aussehen:
Ok danke für die Hilfe!
Werde die Codes dem nächst in pre Tags schreiben.
Komme auch langsam vorran.
Mein Fehler war, dass ich vorher ermitteln muss, welche Session mir der
Server zuweist. Also eigendlich ganz logisch.
Ich muss nämlich die Daten mit einem GET-Befehl der folgenden Struktur
anfordern
1
GET /lightstreamer/STREAMING_IN_PROGRESS?LS_session=S784e56152a6c7560T2008647&LS_phase=103&LS_domain=finanzen.net&
Die Session kann ich anfordern indem ich mit einem POST folgende Daten
sende.
Jetzt stehe ich vor dem Problem, dass ich aus dem Code einen String mit
dem Inhalt S8006a449d216bfd9T0512540 erzeugen muss.
Ich bin so weit, dass ich einen Pointer (Pointer_Anfang) habe, der auf
das S aus S8006... zeigt und ich habe einen Pointer (Pointer_Ende) der
auf das Zeichen nach der 0 aus ...2540 zeigt.
Wie bekomme ich nun die Länge zwischen den beiden Pointer herraus?
Mein Ansatz war dieser:
1
Laenge=Pointer_Ende-Pointer_Anfang;//Ermitteln der Länge des gesuchten Strings
2
Rueckgabe=(char*)malloc(Laenge*sizeof(char));
3
strncpy(Rueckgabe,Pointer_Anfang,Laenge);
4
returnRueckgabe;
5
}
Jedoch liefert mir Pointer_Ende-Pointer_Anfang den Wert 68 zurück und
nicht 25.
A. R. schrieb:> Jetzt stehe ich vor dem Problem,
Wenn das tatsächlich ein Problem ist, wäre es vermutlich schlauer nicht
mit C zu programmieren sondern irgendwas das komfortabler mit Strings
umgehen kann ;)
Ansosnten gibt es hier gibt es eine kleine Einführung in die
Stringverarbeitung, auch wie man Strings zerlegen kann:
http://www.c-howto.de/tutorial-strings-zeichenketten-stringfunktionen.html
@ Läubi,
die Möglichkeiten der Bibliothek string.h sind mir durchaus bekannt.
Ich habe das Problem mittlerweile mit ein paar Schleifen gelöst.
Ich habe mir folgende Funktion erstellt:
Bin nun so weit, dass ich die Anfrage mit der Sessionsnummer erfolgreich
sende. Anschließend bekomme ich den Quelltext vom Server gesendet.
Dieser ist im Header mit 2300Zeichen angegeben. Diese bekomme ich auch
erfolgreich empfangen. Das ganze geschieht in 2 Paketen mit 1200 Zeichen
und 1100 Zeichen. Die Bibliothek rufte eine meine Funktionen auf, in der
ich die Daten in den Heap und anschließen von dem Heap in eine .txt
Datei schreibe. Momentan habe ich folgendes Problem:
Nachdem meine Funktion beendet ist springt das Programm zurück in die
.dll von curl. Während das Programm in dieser Datei herruspring bekomme
ich eine Fehlermeldung "HEAP CORRUPTION DETECTED".
Ich könnte mir vorstellen, dass die Bibliothek nur 2300 Zeichen
reserviert und abstürtzt, nachdem der Server weiter Daten schickt.
Bin aber momentan sehr müde und habe nun mehrere Stunden am Stück an
meinem Programm geschrieben. Es ist also genug für Heute.
Vielleicht hat eine von euch noch eine Idee. Bin gerade am verzweifeln.
Ich sende ein GET und zwar genau das selbe wie auch Firefox es sendet.
Die Sessionnummer wird mir vorher vom Server mitgeteilt.
1
GET /lightstreamer/STREAMING_IN_PROGRESS?LS_session=S281ce2fc3ba2c36eT0856430&LS_phase=4303&LS_domain=finanzen.net& HTTP/1.1
2
Host: push.finanzen.net
3
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:5.0) Gecko/20100101 Firefox/5.0
A. R. schrieb:> Hat jemand eine Idee woran das liegen könnte?
Das liegt im Ermessen des Servers (*). Wenn du kein Chunked verarbeiten
kannst/möchtest, schick halt eine HTTP/1.0 Anfrage...
Wenn du kein Keep-Alive möchtest, eben ein Connection: close usw.
Es macht ja keinen Sinn, die Firefox Header alle 1:1 zu kopieren, wenn
das den Server zu einer Antwort veranlasst, die dein Programm garnicht
versteht.
*) Üblich: Wenn der Server die Dokumentenlänge schon weiß, wenn die
Antwort gesendet werden muss, schickt er einen Content-Length Header,
wenn "das Script noch läuft", benutzt er Chunked-TE.
Übrigens:
http://www.finanzen.net/nutzungsbedingungen.asp
1
(3) Insbesondere ist eine automatisierte Abfrage der von finanzen.net bereitgestellten Inhalte ohne ausdrückliche schriftliche Genehmigung in jeglicher Form nicht zulässig.
>Das liegt im Ermessen des Servers (*). Wenn du kein Chunked verarbeiten>kannst/möchtest, schick halt eine HTTP/1.0 Anfrage...>Wenn du kein Keep-Alive möchtest, eben ein Connection: close usw.>Es macht ja keinen Sinn, die Firefox Header alle 1:1 zu kopieren, wenn>das den Server zu einer Antwort veranlasst, die dein Programm garnicht>versteht.
Ich muss aber die Header so gestalten, dass der Server damit etwas
anfangen kann. Es bringt nichts eine HTTP/1.0 Anfrage zu senden wenn der
Server nur Chunked kann. Da muss ich mich an dem orientieren, was der
Server verarbeiten kann.
Kann nur den Client an den Server anpassen nicht andersherum.
Bin mittlerweile schon ein Stück weiter. Habe in dieser Zeile
das http:// vergessen. Dann bekomme ich von dem Server auch einen Header
mit chunked Codierung.
Desweiteren konnte ich herrausfinden, dass die Homepage und andere auch
einen kommerziellen Streamer verwendet.
http://www.lightstreamer.com/
Konnte mir von diesem eine Dokumentation zu dem Protokoll besorgen.
Weiß also ca. was ich wann schicken muss.
Versuche mich nun in Multithreading einzuarbeiten.
Εrnst B✶ schrieb:
1
(3) Insbesondere ist eine automatisierte Abfrage der von finanzen.net
2
bereitgestellten Inhalte ohne ausdrückliche schriftliche Genehmigung in
3
jeglicher Form nicht zulässig.
Danke für die Information habe das noch nicht gelesen. Die rechtlichen
Bedenken wurden ja bereits angesprochen. Da ich kein Rechtsanwalt bin
muss ich mal Nachfragen. Es ist klar, dass dies in den AGB steht aber
wenn ich mich nicht täusche muss ich die AGB nur dann bestätigen, wenn
ich mich auf der Seite registriere. Kann mich nicht mehr erinnen denen
zugestimmt zu haben.