Hallo Zusammen, ich arbeite seit ein paar Monaten mit einem STM32. Genauer gesagt einem STM32103RD. Es soll eine schnelle Regelung mit ein paar weiteren "netten Funktionen" entstehen. Der µC ist extern mit einem 8Mhz Quarz getaktet. AZur Entwicklung wird Atollic TrueStudio verwendet. In der Software ist der Systemtakt auf 72Mhz eingestellt. Nur kommt mir der µC aber sehr langsam vor. Daher habe ich ein kurzes Programm geschrieben, in dem ein IO-Pin gesetzt und gleich wieder gelöscht wird, um zu sehen wie lange das braucht. Danach wird der Pin wieder gesetzt, ein Integer fünf mal hochgezählt und dann der Pin wieder gelöscht. GPIO_SetBits(GPIOB, GPIO_Pin_14); GPIO_ResetBits(GPIOB, GPIO_Pin_14); GPIO_SetBits(GPIOB, GPIO_Pin_14); i++; i++; i++; i++; i++; GPIO_ResetBits(GPIOB, GPIO_Pin_14); Wenn ich das mit dem Osci "vermesse" ergibt sich folgendes: Pin setzen und löschen: ca. 540ns Pin setzen, 5x addieren, Pin löschen: 1,4µs Die Zeit für die 5 Additionen sollte sich wie folgt ergeben: 1,4µs - 540ns = 860ns Das durch 5 sollte die Zeit für eine Addition ergeben: 860ns / 5 = 172ns Und davon der Kehrwert: 5,8Mhz Ein bisschen wenig für einen 32-bit Controller mit 72Mhz! Bei einem PIC weiß ich, dass ein Maschinenzyklus vier Taktzyklen entspricht und eine Addition einen Maschinenzyklus benötigt. Wie das bei derm STM32 ist, weiß ich nicht. Habe schon im Ref.-Manual gesucht. Mal angenommen, der STM32 würde auch 4 Taktzyklen für die Addition benötigen, dann wäre er mit knapp 24Mhz getaktet. Fehlt aber immernoch Faktor 3. Die Clock-Konfiguration sieht folgendermaßen aus: void RCC_Configuration(void) { /* PCLK2 = HCLK/2 */ RCC_PCLK2Config(RCC_HCLK_Div1); /* ADCCLK = PCLK2/4 */ RCC_ADCCLKConfig(RCC_PCLK2_Div4); /* Enable peripheral clocks --------------------------------------------------*/ /* GPIOA, GPIOB, GPIOC and ADC1 clock enable */ RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA | RCC_APB2Periph_GPIOB | RCC_APB2Periph_GPIOC | RCC_APB2Periph_ADC1 | RCC_APB2Periph_ADC2| RCC_APB2Periph_ADC3 | RCC_APB2Periph_AFIO| RCC_APB2Periph_USART1, ENABLE); } In der Datei system_stm32f10x.c kann man die Taktfrequenz und somit den Multiplier einstellen. Wenn ich das von 72Mhz auf 24Mhz verstelle wird alles auch um Faktor 3 langsamer. Aber generell kommt mir der Controller zu langsam vor. Habe ich hier einen Denkfehler oder ist der wirklich zu langsam? Falls zu langsam: Wie kriege ich den schneller??? Grüße Rainer
Da stimmt was nicht. Ich habe so im Kopf das Cortex-M3s eine Addition pro Taktzyklus machen (kann man bei ARM nachgucken nicht bei ST). Ich würde aber den Test eher mit einer millionen Additionen machen, ist einfach ein bessser Mittelwert und die Zeit für den IO-Bus usw. kannst du dann auch vernachlässigen. Ich schätze irgenetwas mit der PLL Konfiguration läuft schief.
In der Setbits Routine sind noch einige zusätzliche funktionen drin, die die Parameter prüfen. Wenn du statt der Setbits direkt die Register nimmst, wird es deutlich schneller. Das sollte dann glaub ich so aussehen:
1 | GPIOB->BSRR = GPIO_Pin_14; |
Schon mal einen Blick in den Kompileroutput geworfen? Evt ist da unnoetiger Code drinnen. Auf welcher Ausgabegeschwindigkeit wurden die GPIOx_CRH MODEy Bits initialisiert? Vielleicht steht da 2 MHz oder 10 MHz.
Du hast die Möglichkeit den Prozessortakt an den MCO Pin ausgeben zu lassen. Üblicherweise ist das PA8, damit kannst du gut überprüfen ob er so rennt wie er soll. Der Takt wurde möglicherweise an mehreren Stellen im code definiert, fande das am Anfang auch recht stickig. Am besten gehts über den Startup code... Ping Konfiguration für PA.8 als MCO Pin
1 | /* Configure PA.08 as alternate MCO Pin */
|
2 | GPIO_InitStructure.GPIO_Pin = GPIO_Pin_8; |
3 | GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; |
4 | GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AF_PP; |
5 | GPIO_Init(GPIOA, &GPIO_InitStructure); |
6 | |
7 | RCC_MCOConfig(RCC_MCO_SYSCLK); |
Uwe Bonnes schrieb: > Schon mal einen Blick in den Kompileroutput geworfen? Evt ist da > unnoetiger Code drinnen. Yep. Ist es. Fast der gesamte Code in GPIO_SetBits ist gewissermassen überflüssig. Wer es eilig hat darf diese Funktionen nicht verwenden, sondern sollte direkt an die Portregister gehen..
Hast du da eventuell externes Flash an einem schmalen Bus (8 oder 16 bit) dran, und auch noch mit langsamen Bausteinen? Das nur als Hinweis, denn ich weiß nicht, ob dies beim STM32 möglich ist. So gut kenne ich den nicht. Außer, daß es ein ARM Cortex ist. Bei den LPC2000 (ARM7) konnte man den externen Bus verschiedenartig gestalten und konfigurieren, das ergab auch große Unterschiede in der Programmlaufzeit. Unabhängig von System- und CPU-Takt.
Außerdem kann man die Treiber für die Ausgänge konfigurieren, es gibt glaube ich Modi für 50 und 2 Mhz, hier sollte man auch noch mal gucken.
Hubu schrieb: > Außerdem kann man die Treiber für die Ausgänge konfigurieren, es gibt > glaube ich Modi für 50 und 2 Mhz, hier sollte man auch noch mal gucken. Das beeinflußt nur die Treiberstärke der Portpins (und damit die Anstiegszeiten). Das ist von ST unglücklich formuliert worden. Rainer schrieb: > /* PCLK2 = HCLK/2 */ > RCC_PCLK2Config(RCC_HCLK_Div1); Hier passt der Kommentar nicht zum Code. Duke
Hi! Also ersteinmal Danke für die schnellen Antworten. Die Ausgangstreiber sind auf 50Mhz gestellt: GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; Das man die Ausgänge schneller schalten kann, indem man direkt auf die Register schreibt ist sicherlich richtig. Dadurch wird der gesamte Chip aber auch nicht schneller :-) Habe eben einmal die Idee von "vaid" ausprobiert und den PA.8 als Ausgang für den Systemtakt konfiguriert. Passiert leider garnichts. Zuvor war der Pin als "GPIO_Mode_Out_PP" konfiguriert um eine LED zu schalten. Die LED ist zwar nach wie vor angeschlossen, aber das sollte der Sache doch keinen Abbruch tun, oder? Generell muss ich sagen, habe ich Probleme mit dem STM32. Diese riesigen vorgefertigten Lib's und Konfigurationen finde ich absolut undurchsichtig. Da blickt doch kein Mensch durch! Welche Funktionen muss ich denn alle in meinem Code aufrufen, um die wichtigesten Clocks zu konfigurieren? Ich habe auch schon einmal versucht die "SetSysClockTo72(void);" usw. alle manuell am Anfang noch einmal aufzurufen, aber das macht keinen Unterschied.
@Duke: Stimmt. da habe ich den Code geändert, den Kommentar aber nicht ... ups
Rainer schrieb: > Dadurch wird der gesamte Chip aber auch nicht schneller :-) Deine Frequenzberechnung oben ist komplett unbrauchbar. So wie du das machst kann man keine Chipfrequenz ableiten und definitiv nicht daraus schliessen, dass da etwa nur 5,8MHz am Werk wären. Beispielsweise wird die mancher Compiler deine Additionen sämtlich wegstreichen und als +5 gesammelt woanders unterbringen, sofern sich für den Wert von i überhaupt jemand interessiert. > Generell muss ich sagen, habe ich Probleme mit dem STM32. Diese riesigen > vorgefertigten Lib's und Konfigurationen finde ich absolut > undurchsichtig. Da blickt doch kein Mensch durch! Ich finde die FwLib eine eher begrenzte Hilfe. Die Chipreferenz zu lesen bleibt einem sowieso nicht erspart, aber mit der FwLib muss man zusätzlich auch noch mit der Doku der Lib kämpfen - und überlegen, welche Funktion vom Chip welcher Parametrisierung der Lib entspricht und umgekehrt. Ich halte die Parametrisierung über structs für ausgesprochen umständlich. Die Lib ist in einzelnen Fällen als Vorlage nützlich, um zu sehen wie es dort gemacht wurde.
> Deine Frequenzberechnung oben ist komplett unbrauchbar. So wie du das > machst kann man keine Chipfrequenz ableiten und definitiv nicht daraus > schliessen, dass da etwa nur 5,8MHz am Werk wären. Wie würdest du vorgehen? Bzw. warum ist das deiner Meinung so sinnlos? Wenn wir einmal davon ausgehen, dass der Chip in der Zwischenzeit nichts anderes macht und auch keine Interrupts dazwischenfunken sollte das doch so grob stimmen.
Rainer schrieb: > Wie würdest du vorgehen? Die Frage ist zwar nicht an mich gerichtet, aber ich machte das auch schon mal so, daß ich einfach ein Stück Code schrieb, und dessen Laufzeit mit dem Timer gemessen habe. Notfalls auch mit dem Oszi. Für eine Einschätzung reicht das. Dann kann man die Assemblerbefehle zählen, und die Zeit durch die Anzahl Befehle dividieren, um eine mittlere Zeit für einen einzelnen Befehl heraus zu bekommen. Das geht ganz einfach und gut. Und wenn das stimmt, ist was anderes im Argen. Programmiertechnik, Softwaregestaltung.
Und wenn die 72MHz dennoch nicht reichen sollten, es gibt bereits einen STM32F20x mit 120MHz. Der ist nicht 100% Pinkompatibel, ich meine 2 Pins sind anders definiert und muss man im Detail anschauen.
Rainer schrieb: > Wie würdest du vorgehen? Bzw. warum ist das deiner Meinung so sinnlos? Weil du dafür nicht einfach C Statements zusammenzählen kannst. Du musst runter aufs Assembler-Listing und darin die Befehle mit ihrer jeweiligen Laufzeit rechnen. Dazu kommen weitere Abweichungen zwischen den Varianten mit und ohne Addition, die sich durch unterschiedliches Code-Alignment ergeben können. So kann es einen Unterschied ergeben, an welche Stelle einer Flash-Line der Rücksprung aus der Funktion erfolgt.
Mit welcher Compiler Optimierungsstufe wird der Code generiert (ich hab jetzt nicht alles hier gelesen)? Mit 1 oder 2 oder 3 wird der Code auch schon mal schneller. (nicht vergessen, alles neu übersetzen!)
Rainer schrieb: > Habe eben einmal die Idee von "vaid" ausprobiert und den PA.8 als > Ausgang für den Systemtakt konfiguriert. Passiert leider garnichts. > Zuvor war der Pin als "GPIO_Mode_Out_PP" konfiguriert um eine LED zu > schalten. Die LED ist zwar nach wie vor angeschlossen, aber das sollte > der Sache doch keinen Abbruch tun, oder? Keine Ahnung ehrlich gesagt :-) Rainer schrieb: > Generell muss ich sagen, habe ich Probleme mit dem STM32. Diese riesigen > vorgefertigten Lib's und Konfigurationen finde ich absolut > undurchsichtig. Da blickt doch kein Mensch durch! > > Welche Funktionen muss ich denn alle in meinem Code aufrufen, um die > wichtigesten Clocks zu konfigurieren? Ich habe auch schon einmal > versucht die "SetSysClockTo72(void);" usw. alle manuell am Anfang noch > einmal aufzurufen, aber das macht keinen Unterschied. Ich arbeite mit Eclipse. Da kann man dann in der Projektstruktur bis in die hinterste Ecke der Standardlib vordringen und sich die Funktionen etc. anzeigen lassen. Damit wird das ganze dann zumindest ein wenig besser. Auch kann man dank der guten Namenswahl sehen welche Möglichkeiten die STDlib bietet und diese dann nutzen oder eben selbst umsetzen. Bisher musste ich feststellen, Knackpunkt ist eine gescheite Makefile (die man versteht) und vernünftiger Startupcode. Dieser stellt im Idealfall schon die Controllerclock so ein wie für das Projekt gewünscht. Bezüglich der MCO Clock schau am besten in die _rcc.c. Wenn die läuft kannst du immerhin ausschließen, dass der Controller nicht im richtigen Takt läuft. Hilfreiche Funktionen können auch RCC_GetClocksFreq usw. sein.
Also der STM32 läuft scheinbar doch mit 72Mhz! Ich habe Über den Pin PA8 nun den Systemtakt ausgeben lassen und da kommen genau 72Mhz heraus. Dass das vorher nicht funktioniert hat lag an meiner Dummheit. Ich habe das Osci an den Pin PB8 gehalten und mich gewundert, weshalb da nichts passiert. Mein Fehler, sorry! @A.K. Du hast natürlich recht, dass ich nicht einfach von den C-Statements auf Maschinenbefehle und deren Laufzeit usw. zurückschließen kann. Ich habe eine Weile PIC's in Assembler programmiert und da ist das noch eine "alte Gewohnheit" einfach mal zu denken, dass eine Addition "soundsoviele" Taktzyklen benötigt. Ich finde es aber erschreckend, dass ein so schneller Prozessor so lange für so simple Operationen braucht. "Markus Müller" hat wahrscheinlich recht, dass ich mich einmal mit den Einstellungen des Compilers auseinander setzen sollte. Das habe ich bisher nicht getan. @Markus Müller > Und wenn die 72MHz dennoch nicht reichen sollten, es gibt bereits einen > STM32F20x mit 120MHz. Das versuche ich zu vermeiden. Ich kriege da bei den neuen PC-Programmen schon immer zuviel. Frei nach dem Motto: Das Programm ist sauschlecht programmiert und voller Bugs. Aber macht ja nichts: Da soll sich der Anwender einfach schon wieder einen neuen PC kaufen g PS: IO setzen mit GPIOB->BSRR = GPIO_Pin_14; ist doppelt so schnell wie mit GPIO_SetBits(GPIOB, GPIO_Pin_14); :) Danke für den Hinweis.
Rainer schrieb: > Ich finde es aber erschreckend, dass ein so schneller Prozessor so lange > für so simple Operationen braucht. Du bist immer noch auf dem Holzweg, weil du immer noch nicht weisst, was da für ein Code dahinter steht. Wenn du ohne Optimierung übersetzt hast, dann läuft das für jedes i++ möglicherweise ungefähr so ab, wenn i global ist: Lade Adresse von "i" nach R0 aus dem Flash, 5 Takte Lade [R0] nach R1, 2 Takte Addiere 1 auf R1, 1 Takt Speichere R1 nach [R0], 2 Takte = 10 Takte oder so in der Grössenordnung (die Takte pro Befehl sind grad aus dem Ärmel, also leg mich nicht drauf fest). Wenn du das dann optimiert übersetzt, dann wird daraus: Addiere 1 auf das Register in dem "i" liegt, 1 Takt. Oder auch: garnix, weil der Compiler das als Unfug erkennt und wegoptimiert. Machst du das auf einem PIC, dann wird daraus Addiere 1 auf Speicherstelle "i", 1 Befehlszyklus wenn i 8 Bit breit und die richtige Bank aktiv ist - aber auch nur dann.
@A. K. Ich habe dich schon verstanden. Ich hätte mich vielleicht anders ausdrücken sollen: Es ist erschreckend, wie fatal sich schlecher / nicht optimierter Code auf die Performance auswirken kann. Wie gesagt: Ich habe mich bisher nicht mit den Einstellungen des Compilers auseinander gesetzt. Da der µC mit der vollen Taktfrequenz läuft, kann der langsame Ablauf nur an nicht optimiertem oder auch umständlichem Code liegen.
Angehängte Dateien:
-

STM32F207_120MHZ.png
29 KB
War gerade am Spielen, äääh.. Testen eines F207VC boards. Hab mal den obigen Code geladen und angepasst, denn wenn man die Variable i nicht benutzt, dann Optimiert einem der Compiler das gleich ganz raus. Deshalb hab ich mal folgendes verwendet:
1 | uint32_t i = 0; |
2 | |
3 | while(i < 0x87654321) |
4 | {
|
5 | GPIOA->BSRRL = GPIO_Pin_7; // Pin A7 high |
6 | GPIOA->BSRRH = GPIO_Pin_7; // Pin A7 low |
7 | GPIOA->BSRRL = GPIO_Pin_7; // Pin A7 high |
8 | i++; |
9 | i++; |
10 | i++; |
11 | i++; |
12 | i++; |
13 | GPIOA->BSRRH = GPIO_Pin_7; // Pin A7 low |
14 | }
|
Der Compiler macht dann leicht optimiert dieses hier draus, vor allem daran zu erkennen dass aus den paar i++ ein i+= 5 gebaut wurde:
1 | ??LOOP1: |
2 | 0x8000e4a: 0x4932 LDR.N R1, ??Data65 ; GPIOA_BSRR |
3 | 0x8000e4c: 0x800a STRH R2, [R1] ; Pin A7 High |
4 | 0x8000e4e: 0x804a STRH R2, [R1, #0x2] ; Pin A7 Low |
5 | 0x8000e50: 0x800a STRH R2, [R1] ; Pin A7 High |
6 | 0x8000e52: 0x1d40 ADDS R0, R0, #5 ; i += 5 |
7 | 0x8000e54: 0x804a STRH R2, [R1, #0x2] ; Pin A7 Low |
8 | 0x8000e56: 0x4930 LDR.N R1, ??Data66 ; 0x87654321 |
9 | 0x8000e58: 0x4288 CMP R0, R1 ; i < 0x87654321? |
10 | 0x8000e5a: 0xd3f6 BCC.N ??LOOP1 ; 0x8000e4a |
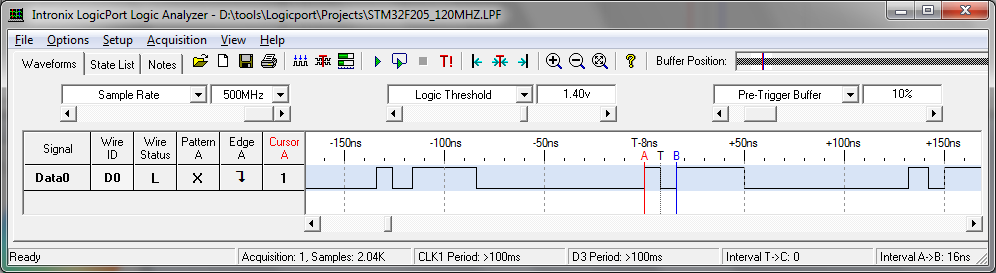
Wie auch an den Adressen zu erkennen ist, läuft der Code im Flash. Nun Logicport an den Pin gehängt, Ergebnis hängt bei. Was man nun erkennen kann: * Es ist möglich die I/Os in 8,33ns umzuschalten. * Der Sprung an den Anfang der Schleife dauert vergleichsweise lange (hier schwächelt der Flash Beschleuniger) * Die gesamte Schleife braucht 144ns. Das entspräche dann im Schnitt 1 Waitstate. ST verspricht eigentlich 0 Waitstate performance. Naja. Gut, Wenn man ein Programm ohne Sprünge hat? (ist halt Marketingmännisch gerundet). Egal wie, langsam würde ich das nun aber gleicht garnicht nennen. Vor allem für einen 6EUR controller... wer in der Preisregion schnelleres hat, bitte gerne... (Kinetis?) Ach ja: Die F103 dürften bei 72MHz nicht ganz halb so schnell sein.
> ST verspricht eigentlich 0 Waitstate performance. Naja. Gut, Wenn man ein > Programm ohne Sprünge hat? Ja, nur dann. Aber das ist realitätsfern. Der "Beschleuniger" kann nur die ersten 4 Bef's auffangen, danach läufts wieder ausm Flash. Und der geht nur mit 32 MHz. (war schon öfters Thema)
Hannes S. schrieb: > 0x8000e4a: 0x4932 LDR.N R1, ??Data65 ; GPIOA_BSRR > * Der Sprung an den Anfang der Schleife dauert vergleichsweise lange > (hier schwächelt der Flash Beschleuniger) Ich weiss grad nicht wie breit die Einträge vom Flash-Cache sind, aber *e4a ist möglicherweise etwas ungünstig. Könnte mit Zieladresse *e4c oder *e50 besser aussehen.
Hannes S. schrieb: > Ach ja: Die F103 dürften bei 72MHz nicht ganz halb so schnell sein. Wobei die meisten davon die GPIOs auf den APBs haben, nicht wie neuere auf dem schnelleren AHB. Könnte bremsen
A. K. schrieb: > Ich weiss grad nicht wie breit die Einträge vom Flash-Cache sind, aber > > *e4a ist möglicherweise etwas ungünstig. Könnte mit Zieladresse *e4c > > oder *e50 besser aussehen. In der Tat, e4c ist 1 Takt besser. Man lernt nie aus. Damit wären es dann 134ns. Und die Waitstates hätten schon eine 0 vor dem Komma... Und ja, richtig: I/O bei den 103ern braucht 2 clocks, also 28ns bei 72MHz.
Hannes S. schrieb: > * Die gesamte Schleife braucht 144ns. Wobei der Code besser optimiert sein könnte. Die beiden LDR.N wären ausserhalb der Schleife besser untergebracht.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.