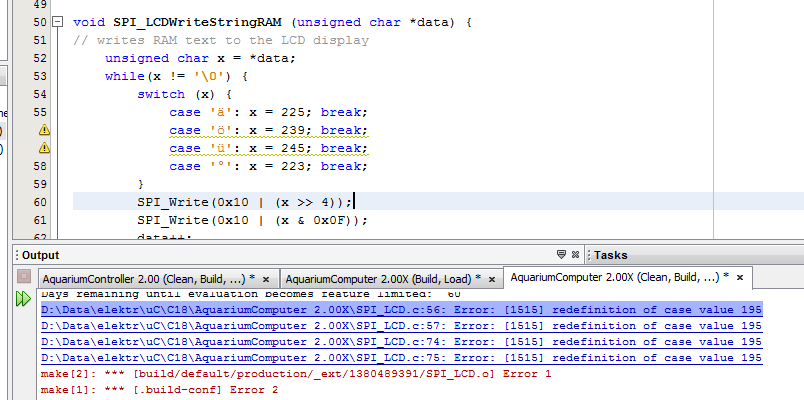
mit C18 unter MPLAB X findet der compiler, dass 'ä', 'ö' und 'ü' den selben wert hat (siehe screenshot), unter MPLAB 8.x ging das ohne probleme. beim projekt kann man das encoding format (standardmässig UTF-8) umstellen, aber das bringt auch nix. kennt jemand den work arround?
Angehängte Dateien:
-

Unbenannt.png
34 KB
Für die Umlaute wird einfach mal gern mit "Escape-Buchstabe zum schalten auf andere Tabelle + zwieter Buchstabe zum Zeichen aus dieser Tabelle auswählen" gearbeitet. Und je nach Standard anders umständlich. Deswegen "sieht" der Compiler immer nur das Escape-Zeichen oder die Escape-Sequenz und meint das Teil wär schon mal da gewesen. mfg mf
@homunculus: welchen zahlenwert denn? wenn ich z.b. das wort "Löffel" schreiben will, kann ich ja nicht einfach statt des 'ö' eine zahl zwischen dem 'L' und dem 'f' schreiben. @Mini Float: OK, das mag die ursache sein, aber wie kann ich das umgehen?
@Mini Float:du hattest recht. "zurück" wird als "zurück" abgespeichert (das file mit dem wordpad geöffnet)
switch(x) {
case 132: // ä
...
case 148: // ö
...
case 129: // ü
...
case '°': ...
}
Der Compiler macht aus '<Zeichen>' nichts anderes als dieses ins
Zahlenformat zu überführen. In einem (unsigned)char kannst du 256
verschiedene Werte (Zeichen) ablegen.
Wenn du wissen willst welcher Zahlenwert hinter welchem zeichen steckt,
kannst du zum Beispiel so etwas machen.
#include <stdio.h>
int main() {
int i;
for(i = 0; i < 256; ++i)
printf("%i - %c\n", i, i);
return 0;
}
Master Snowman schrieb: > mit C18 unter MPLAB X findet der compiler, dass 'ä', 'ö' und 'ü' den > selben wert hat (siehe screenshot), unter MPLAB 8.x ging das ohne > probleme. beim projekt kann man das encoding format (standardmässig > UTF-8) umstellen, aber das bringt auch nix. kennt jemand den work > arround? Zur Info: chars sind normalerweise signed, die Umlaute haben also negative Charcodes. switch() hat jedoch ein unsigned char als Argument, d.h. alle case-Werte werden in unsigned char gewandelt. Bei negativen Werten ist das ein Problem. fchk
Ok, danke. ich sehe immer mehr durch. die switch-anweisung ist gelösst, jetzt bleibt aber noch, wie ich in meinem programmcode z.b. "Löffel" schreiben soll.
Master Snowman schrieb: > Ok, danke. ich sehe immer mehr durch. die switch-anweisung ist gelösst, > jetzt bleibt aber noch, wie ich in meinem programmcode z.b. "Löffel" > schreiben soll. Text editor, unter National Language Code Page auf 1250 ANSI - Central Europe) einstellen. Vielleicht hilft das. Gruß Hermann
@Hermann U.: ja, das war's. es gibt zwar nur "Windows-1250" zur auswahl, aber es hat geholfen. für alle, die das gleiche problem haben oder jene, die diesen thread später finden: 1. Project -> Properties -> General -> Encoding -> Windows-1250 2. entsprechendes dokument, das probleme macht, ein zeichen ändern (z.b. leerschlag irgendwo hinzufügen) und neu abspeichern 3. kompilieren ps: ohne schritt 2, geht's nicht vielen dank an alle! :-)
Hermann U. schrieb: > Text editor, unter National Language Code Page auf 1250 ANSI - Central > Europe) einstellen. Vielleicht hilft das. Master S. schrieb: > 1. Project -> Properties -> General -> Encoding -> Windows-1250 > 2. entsprechendes dokument, das probleme macht, ein zeichen ändern > (z.b. leerschlag irgendwo hinzufügen) und neu abspeichern > 3. kompilieren > ps: ohne schritt 2, geht's nicht Bei mir geht es nicht, was mache ich falsch? hat es vielleicht mit Windows Region und Sprachen was zu tun? Sieht immer noch so aus: "zurück"
Nach dem Umstellen der Codierung musst Du jetzt noch alle Umlaute korrigieren. Vermutlich verwendet der Editor eine Form von UTF-8, in dem ein ü als zwei Bytes in der Datei stehen. Dabei ist das erste Byte für ä, ö und ü gleich. Es gibt sogar einen Code in Unicode für stelle das folgende Zeichen als Umlaut (mit 2 Punkten drüber dar). Da könntest Du aber ein zweites u in zurück erkennen. Bestimmt gibt es auch Programme, die die Codierung einer Textdatei umwandeln können. Die Codierung im Editor musst Du aber auf alle fälle auch ändern.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.