Hallo,
ich benötige in einem Programm die Funktion
1
exp10(x) = 10^x
, die ich mir über eine Macro
1
EXP10(x) exp( (double)(x) * (double)2.302585093 )
zugänglich mache.
Ziel ist es, was auch funktioniert, aus der gegebenen Leistung in dBm
auf die Leistung in Watt (resp. mW) zurück zu rechnen.
Dazu muss die bekannte Formel verwendet werden:
1
-- gegeben PdBm in [dBm]
2
Pmw = exp10( PdBm / 10 ) ; Pmw in [mW]
Der Wertebereich (Zahlenbereich) von PdBm E { -100dBm, .. , 20dBm } nach
Umrechnung in mW liegen die Zahlen im Bereich von 10^-10 bis 10^2.
Das passt ohne vorherige Betrachtung des dBm-Zahlenbereichs nicht in
eine 32-Bit Variable.
Deshalb beachte ich schon bei der Berechnung von exp10(PdBm) die
folgende Äquivalenz:
1
;wenn x = a + b
2
Pmw = exp10( x / 10 ) = exp10( (a + b) / 10 )
3
Pmw = exp10( a /10 + b /10 )
4
Pmw = exp10( a /10 ) * exp10( b /10 )
Die Zerlegung von x sieht dann als Bsp. so aus:
1
x = -55,3dBm
2
x = -50 dBm + -5,3dBm
3
==>
4
Pmw = exp10( -50 / 10 ) * exp10( -5,3 / 10 )
5
Pmw = 10^-5 * exp10( -5,3 / 10 )
Es bleibt also die Realisierung der Berechnung von exp10(x) im
Wertebereich von (-1 < x < 1).
*Wer hat eine Idee für einen Kurzen (Flashspeicher) und evtl. schnellen
Code ?*
_
Hab die letzte Woche mal mit Lookup-Tables rumgespielt und linearen
Lookup mit Lookup dritter Ordnung und Auswertung nach de Casteljau
rumgespielt.
"Speichersparend" und "schnell" sind natürlich relativ...
Meine beobachtungen bisher:
- Lookup 3er Ordnung braucht doppelt so viel Tabellenplatz wie
Lookup 1er Ordnung.
- 3te Ordnung brauch 6 Multiplikationen mehr als 1-te Ordnung
sowie einige Additionen mehr. Divisionen werden nicht benötigt
bzw. können vermieden werden.
- 3te Ordnung liefert doppelte Genautigkeit im Vergleich zu 1er Ordnung,
d.h. doppelt so viele Nachkommastellen
Wenn es interessiert kann ich die Methode mal vorstellen.
Die Crux ist allerdings die Berechnung der Kontrollpunkte. Ich hab mich
früher schon mal mit dem Thema beschäftigt im Rahmen von Darstellung
glatter Funktionen als kubische Bézier für SVGs, aber einen wirklich
überzeugenden Ansatz zur Bestimmung der Kontrollpunkte kann ich nicht
bieten.
Hier ein Beispiel:
http://upload.wikimedia.org/wikipedia/commons/0/0a/Gompertz-a.svg
Die Darstellung des Graphen ist nur ein recht kleiner Teil des SVG...
(als Text anzegen lassen!)
@Uwe S.:
Verwendest du an anderen Stelle im Programm Floating-Point-Arithmetik?
Wenn ja, macht die exp-Funktion den Kohl auch nicht mehr fett.
Wenn nein:
In welcher Auslösung ist das Argument (die dBm) gegeben? Wenn das nur
ganze Zahlen sind (also 1dBm, 2dBm, 3dBm usw., und nicht 1,5dBm), können
die 10 Funktionswerte einer Dekade in eine Tabelle abgelegt werden.
Wenn die Argumente feiner ausgelöst sind:
Wie fein? Wie genau muss das Ergebnis sein? Man kann da sicher eine
akzeptable Näherung finden.
Hallo Yalu X.,
die Zerlegung in Dekaden habe ich schon gemacht, siehe Beispiel.
Intern rechne ich hauptsächlich mit 16Bit und 32Bit Zahlen.
Bsp.:
15,12dB wird als 1512u (uint16_t) dargestellt.
Aus diesem Beispiel
1
Pmw = exp10( -50 / 10 ) * exp10( -5,3 / 10 )
2
Pmw = 10^-5 * exp10( -5,3 / 10 )
verwende ich die 10^-5 als Auswahl für die Einheiten:
mW, µW, nW und pW und mit das Ergebnis
1
(int16_t)(exp10( -0.53 ) * 1000.0 +0.5)
stelle ich dann mit dem passenden Komma dar.
Die Auflösung der dBm liegt bei 1/100, also +1,23dBm.
Hallo Johann L.,
ja ich möchte mehr über die Methode erfahren. Ich schon eine weile her,
dass ich elliptische Kurven in C auf einem 8051 abgebildet hatte.
Da vergisst man doch so einiges aus der numerischen Mathematik.
Danke.
Uwe S. schrieb:> Die Auflösung der dBm liegt bei 1/100, also +1,23dBm.
Jetzt fehlt noch die Angabe der gewünschten Ergebnisgenauigkeit. Du
könntest bspw. die exp10-Funktion im Wertebereich [0;1) mit einer
geeigneten Potenzreihe 3. Grades annähern und kommst damit auf eine
Genauigkeit von besser als 0,3%. Das sollte auch in 32-Bit-Integer-
Arithmetik machbar sein, die du im Programm ja sowieso schon benutzt.
Uwe S. schrieb:> Hallo Johann L.,>> ja ich möchte mehr über die Methode erfahren. Ich schon eine weile her,> dass ich elliptische Kurven in C auf einem 8051 abgebildet hatte.
Kryptographie?
Yalu X. schrieb:> Du könntest bspw. die exp10-Funktion im Wertebereich [0;1) mit einer> geeigneten Potenzreihe 3. Grades annähern und kommst damit auf eine> Genauigkeit von besser als 0,3%. Das sollte auch in 32-Bit-Integer-> Arithmetik machbar sein, die du im Programm ja sowieso schon benutzt.
Ein Problem bei Verwendung von Potenzreihen ist, daß man sich damit fix
Überläufe bei Zwischenergebnissen einhandelt, ohwohl das Endergebnis im
Darstellungsbereich liegt.
Zur Illustration exp(-10):
Für exp(-10) werden die Summanden exorbitant größer als das Endergebnis,
der 4. Summand ist 416 und der 5. Summand ist -833 bei einem Endergebnis
von quasi 0.
Zudem hat man massiv mit Auslöschung zu kämpfen. Zu schreiben
hilft auch nicht gegen Auslöschung, und zu sagen, wie weit die
Zwischenergebnisse wachsen, scheint mir auch nicht unmittelber
ersichtlich...
Genau das ist der Vorteil von de Casteljau. Alle Zwischenwerte liegen
per Design im Innern des durch die Kontrollpunkte ausfgespannten
Polygons, des Kontrollpolygons.
D.h. bereits beim Erstellen der Kontrollpunkte bzw. der Tabelle kann
ganz einfach sichergestellt werden, daß es während der Berechnung keine
Überläufe gibt.
Weiters konvergiert eine Potenzreienentwicklung schlecht, wenn man nahe
zum Rand des Konvergenzradius' entwickelt. Das gilt auch für
reellwertige Funktionen, wenn Pole im komplexen liegen! Beispiel ist
arctan, der Pole bei +/- i hat.
Haben die Terme der Entwicklung unterschiedliche Vorzeichen, so führt
das zum Aufrauhen der Approximation. exp(x) ist zB streng mo.wa..
Entwichelt man mit endlicher Genauigkeit für x < 0, ist die
Approximation i.d.R nicht mo.wa.
Je nach Einzelfall lassen sich die genannten Probleme zwar umgehen bzw.
werden nicht akut, aber es bedarf dafür immer einer
Einzelfallbetrachtung.
Mit de Casteljau ist das einfacher; allerdings ist wie gesagt auch
Vorarbeit auf dem PC notwendig.
Yalu X. schrieb:> Uwe S. schrieb:>> Die Auflösung der dBm liegt bei 1/100, also +1,23dBm.>> Jetzt fehlt noch die Angabe der gewünschten Ergebnisgenauigkeit.
Mir reichen 4-Nachkommastellen, d.h. die Zahl sieht so aus 9,1234.
_
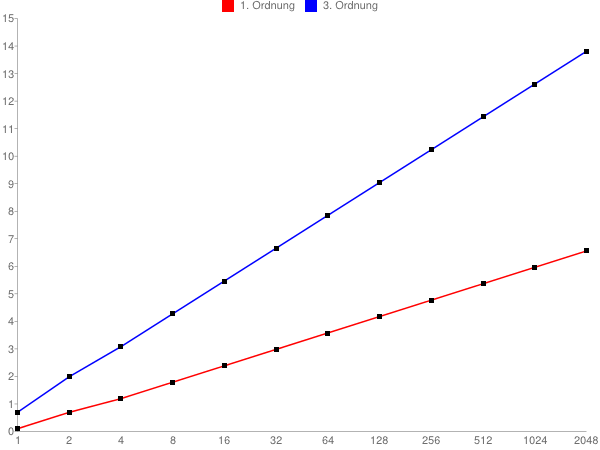
D1 sind die Dezimalen bei Approximation 1. Ordnung (liner), D3 sind die
Dezimalen bei 3. Ordnung (kubisch), ld ist logarithmus dualis.
Aus diesem Zusammenhang ergibt sich:
1) Um die Zahl der zuverlässigen (Dezimal)stellen zu verdoppeln,
muss die Anzahl der Stützstellen quadriert(!) werden.
2) Verdoppelt man die Anzahl der Stützstellen, gewinnt man linear
ca. 0.6 Dezimalen hinzu und kubisch das doppelte. Das entsprich
recht exakt 2 bzw. 4 Dualen.
Was nicht aus der Grafik ersichtlich ist: eine Tabelle für 3. Ordnung
ist doppelt so groß wie eine Tabelle für 1. Ordnung.
Die Berechnungen erfolgten auf einem PC als double.
Bei Fixpunkt-Arithmetik hat man u.U. andere Fehlerfortpflanzung, d.h.
die Graphen von oben ändern leicht ihre Steigung und werden flacher.
Irdendwann steigen sie aber nicht mehr weiter, d.h. bei weiterer
Hinzunahme von Stützstellen wird keine Genauigkeit mehr hinzugewonnen.
Wo diese Grenze bei double liegt, hab ich nicht ausgewünschelt.
Etwas überraschend ist, daß für ein Verfahren 3. Ordnung nur doppelt so
große Tabellen gebraucht werden wie für 1. Ordnung; nicht etwa 3-fach so
große.
Das liegt daran, daß die Auswahl der Kontrollpunkte mehreren
Randbedingungen unterliegen, insbesondere sind deren x-Koordinaten
vorgegeben. Dies führt dazu, daß sich die kubische Approximation verhält
wie eine quadratische. Das ist auch daran zu erkennen, daß die Dezimalen
nur doppelt so schnell wachsen wie bei der linearen Tabelle, und nicht
etwa 3-mal so schnell. Ob sich durch bessere Kontrollpunkte die Güte
steigern lässt, weiß ich nicht. Es ist zumindest zu vermuten. Bis auf
den Faktor 3 wird man m.E. aber nicht kommen.
Noch ein Rechenbeispiel:
Für eine Genauigkeit von 6 Dezimalen braucht man kubisch ca. 23
Teilintervalle, also 2·23+2 = 48 Tabelleneinträge
Für die gleiche Genauigkeit und lineare Annäherung braucht's rund 1140
Teilintervalle, also 1141 Einträge. Das ist mehr als das 20-fache!
Hallo Johann,
danke, aber damit komme ich jetzt nicht weiter, da ich das Verfahren
nicht kenne.
Neben den Abschätzungen und der Betrachtung des Genauigkeitzuwachses,
ist die Realisierbarkeit auf einem Atmel atTiny. Wenn es keinen
Ersparnis an Flashspeicher gibt, habe ich nichts gewonnen.
Das kommt auf deine Arithmetik-Implementierung an. Und wie Yalu schon
bemerkte, hängt es auch stark davon ab, ob durch die Implementierung auf
float verzeichtet werden kann oder nicht. Wenn mit dem Verfahren immer
noch die float-Funktionen aus der Lib gesaugt werden, hat man u.U nix
gewonnen.
Herz des Verfahren ist, zwischen zwei Werten zu linearisieren:
1
static
2
//__attribute__((noinline))
3
inline__attribute__((always_inline))
4
data_tline(data_tx0,data_tx1,data_tb)
5
{
6
returnx0+b*(x1-x0);
7
}
Bei der Auswertung ist b in [0,1] und wenn es ganz klein wenig
ausserhalb von[0,1] liegt, macht das auch nix — immer unter der
Prämisse, das Zahlenformat data_t verkraftet dies. Je nach Zahlenformat
müssen Multiplikation und/oder Addition händisch aufgerufen werden.
Die Auswertung selbst sieht dann in etwa so aus:
1
staticconstdata_teps_x=1e-4;
2
3
data_teval(constfun_data_t*f,data_tx)
4
{
5
data_tb=(x-f->x_start)/f->step;
6
7
if(x<f->x_start-eps_x||x>f->x_end+eps_x)
8
{
9
printf("x = %lf nicht in [%lf, %lf]\n",x,f->x_start,f->x_end);
10
exit(1);
11
}
12
13
// a: Interval No.
14
inta=(int)b;
15
16
// Saturate it
17
if(a<0)a=0;
18
if(a>=f->n)a=f->n-1;
19
20
// b: Marks Position [0,1] in respective Interval, i.e.
21
// in [start + a*step, start + (a+1)*step]
22
b-=a;
23
24
constdata_t*py=&f->data[2*a];
25
26
// Get Control Points' y-Values
27
data_ty0_0=*py++;
28
data_ty0_1=y0_0+*py++;
29
data_ty0_3=*py++;
30
data_ty0_2=y0_3-*py++;
31
32
// 3rd Order
33
data_ty1_0=line(y0_0,y0_1,b);
34
data_ty1_1=line(y0_1,y0_2,b);
35
data_ty1_2=line(y0_2,y0_3,b);
36
37
data_ty2_0=line(y1_0,y1_1,b);
38
data_ty2_1=line(y1_1,y1_2,b);
39
40
data_ty3=line(y2_0,y2_1,b);
41
42
// 1st Order
43
data_ty1=line(y0_0,y0_3,b);
44
45
returny3;// y1
46
}
3. Ordnung braucht also 2 Speicherzugrigffe, 14 Additionen und 6
Multiplikationen mehr als 1. Ordnung; zumindest falls "line" geinlinet
wird.
Die Division durch step kann einfach vermieden und durch eine
Multiplikation ersetzt werden, indem auch 1/step in den Datensatz
aufgenommen wird. Oder durch Schieben falls möglich.
func_data_t wiederum ist die Nachguck-Tabelle für die Funktionswerte:
1
typedefstruct
2
{
3
// x Start, x End
4
data_tx_start,x_end;
5
// # Intervals: N
6
intn;
7
// Step: (end-start) / N
8
data_tstep;
9
// Data for function
10
// # Entries in the table: 2 * (N+1)
11
data_tdata[];
12
}fun_data_t;
Hier noch die generierte Tabelle für exp10, was für 6 Dezimalstellen,
also 16-Bit Werte, passen sollte:
1
typedefdoubledata_t;
2
3
#include"fun-data.h"
4
5
// Define _() if you need some transfrom applied to the raw data
6
// like, e.g. convert to some fixed point representation
Mit den gegebenen Anforderungen scheint mir momentan kein Verfahren
geeignet:
- 16-Bit Arithmetik
- Ergebnisse von 10^-10 bis 10^2
- Speichersparend da für ATtiny
- Schnell trotz fehlender MUL-Befehle
- "4 Nachkommastellen"
Zunächt ist die Berechnung nur für x in [0,1] also für Ergebnisse in
[1,10], was mindestens 4 Vorkomma-Bits braucht.
4 Dezimalstellen sind 13 Binärstellen, also mindestens 17 Bits.
Bei o.g. Verfahren n. Ordnung ist damit zu rechnen, daß n Bits durch die
Berechnungen verloren gehen, d.h. es braucht mindestens 17+n Bits.
Nächstes handliches Zahlenformat ist mit mindestens 4 Vorkomma- und 13
Nachkomma-Bits Q8.16 , das erst mal reingeklöppelt werden muss, d.h.
Multiplikation, Addition und Subtraktion.
Mit einem kubischen Bézier kommt man mit den Rundungsfehlern vielleicht
gerade noch hin. Oder es braucht ein Q4.20, was aber nicht ganz so
komfortabel zu multiplizieren ist.
Wirklich schnell wird die Multiplikation auf einem ATtiny aber so oder
so nicht werden...
Wozu werden die Daten eigentlich gebraucht?
- Integration zur Leistungsmessung?
- Nur zur Anzeige und dann wegen des Zalenformats als 1E-10 oder so?
Die Approximationsfehler von [0,1] skalieren bei Renormierung auf einen
anderen Urbildbereich natürlich mit...
Was mit noch einfällt ist binäre suche: Ein Ergebnis raten und den
Logarithmus ausrechnen. Mit x vergleichen und je nach Resultat ein Bit
zu y hinzunehmen und nochmal den Log berechnen und vergleichen.
ld lässt sich einfach und platzsparend berechnen, siehe [1]. Binärsuche
dürfte also das platzsparendste Verfahren sein. Wirklich "schnell" wird
es aber keinesfalls...
[1]
http://de.wikipedia.org/wiki/Logarithmus#Berechnung_einzelner_Bin.C3.A4rziffern
Hallo,
habe nur den ersten Absatz gelesen. Keine Zeit..
Die Anforderungen sind:
- n-Bit Arithmetik, n=16 oder 32 oder 64 Bit
- Speichersparend da für ATtiny
- Schnell trotz fehlender MUL-Befehle
- "4 Nachkommastellen" des Ergebnisses von exp10(x) für den Wertebereich
von (-1 < x < 1).
Uwe S. schrieb im ersten Post
> Es bleibt also die Realisierung der Berechnung von exp10(x) im Wertebereich von
(-1 < x < 1).
Johann L. schrieb:> Mit den gegebenen Anforderungen scheint mir momentan kein Verfahren> geeignet:>> - 16-Bit Arithmetik> - Ergebnisse von 10^-10 bis 10^2> - Speichersparend da für ATtiny> - Schnell trotz fehlender MUL-Befehle> - "4 Nachkommastellen">
Ich habe hier mal ein Polynom 6. Grades berechnet und in Integerarithme-
tik umgesetzt:
1
int32_tdb2ip(int16_tdb){
2
// Eingabe 0..1000 (entspricht 0,00..10,00 dBm)
3
// Ausgabe: ca. 100000000..1000000000 (entspricht 1..10mW)
4
// Genauigkeit: ±3169 (entspricht ± 31,69 nW)
5
//
6
return(((((((((((2486885l
7
*db-967785290l)>>12)
8
*db+1566098334l)>>11)
9
*db+776140196l)>>11)
10
*db+564298833l)>>10)
11
*db+471038512l)>>10)
12
*db+200005508l)>>1;
13
}
Die Funktion berechnet die mW für 1 volle Dekade, kann aber, wie du
schon selbst herausgefunden hast, leicht auf beliebige Größenordnungen
erweitert werden. Zur Anzeige musst du das Ergebnis mit ltoa in einen
String umwandeln und das Dezimalkomma an der richtigen Stelle einsetzen.
Flash-Bedarf:
Mit GCC 4.2.4 und AVR-Libc 1.7.1 braucht die Funktion auf einem ATtiny13
248 Bytes Flash, die entsprechende FP-Funktion unter Verwendung von
pow() 1802 Bytes. Verwendet dein Programm sowieso schon irgendwo eine
signed 32-Bit-Multiplikation (76 Bytes), reduziert sich der zusätzliche
Flash-Bedarf durch die obige Funktion auf 172 Bytes.
Genauigkeit:
Der maximale absolute Fehler tritt bei 8,13 dBm auf:
genaues Ergebnis: 6,501297 mW
obige Funktion: 6,501265 mW
———————————
Fehler: 0,000032 mW
Der Fehler ist also kleiner als eine Einheit in der 4. Nachkommastelle.
Werden beide Ergebnisse auf jeweils 4 Nachkommastellen gerundet, kann
der Fehler auf ±1 Einheit in der 4. Nachkommastelle steigen. Das liegt
dann aber nicht an der Approximation, sondern an der Rundung.
Laufzeit:
Ich habe die Funktion nur auf dem PC getestet. Für den ATtiny musst du
die Laufzeit selber bestimmen. Sie sollte aber eher besser sein als bei
der FP-Variante.
Johann L. schrieb:> Ein Problem bei Verwendung von Potenzreihen ist, daß man sich damit fix> Überläufe bei Zwischenergebnissen einhandelt, ohwohl das Endergebnis im> Darstellungsbereich liegt.> […]> Zudem hat man massiv mit Auslöschung zu kämpfen.
Beide Probleme sind durch die Skalierung der Zwischenergebnisse mit den
Shift-Operationen beseitigt.
Danke Yalu,
das gefällt mir sehr !
Und ich erweitere mal meinen Code damit.
Nun habe ich doch eine Frage wie hast das Polynom entwickelt?
Ich will ja auch etwas lernen. :-)
Denn nun fehlt mir noch eine Näherung für negative Exponenten > -1.
Danke Yalu,
so ich habe nun den Zahlenbereich durch Skalierung auch auf die
negativen Leistungswerte erweitert.
Der Trick liegt in dieser Gleichung:
1
exp10(x) = exp10(-10 +10 +x) ; mit -10 < x < 0
2
exp10(x) = exp10(-10) * exp10(10 +x) ; mit -10 < x < 0
3
exp10(-10) = 10^-10 ; Nachkommastellen
Damit liegt der Wertebereich von (10 + x) im Wertebereich des Polynom 6.
Grades und ich sie mit der angegeben Fehlerrate verwenden.
Deinen und meinen Code habe ich nur rudimentär zusammengeführt und ich
denke hier sind noch Optimierungsmöglichkeiten !
Der Speicherverbrauch hat sich massiv verringert:
alt
1
AVR Memory Usage
2
----------------
3
Device: attiny44
4
5
Program: 4052 bytes (98.9% Full)
6
(.text + .data + .bootloader)
7
8
Data: 35 bytes (13.7% Full)
9
(.data + .bss + .noinit)
10
11
EEPROM: 66 bytes (25.8% Full)
12
(.eeprom)
neu
1
AVR Memory Usage
2
----------------
3
Device: attiny44
4
5
Program: 2846 bytes (69.5% Full)
6
(.text + .data + .bootloader)
7
8
Data: 35 bytes (13.7% Full)
9
(.data + .bss + .noinit)
10
11
EEPROM: 66 bytes (25.8% Full)
12
(.eeprom)
Damit ist dieser Änderung fertig, nun kann ich noch einige weitere
Funktionen implementieren.
Vielen Dank für die tolle Unterstützung !
Uwe S. schrieb:> Nun habe ich doch eine Frage wie hast das Polynom entwickelt?
Die Polynomkoeffizienten (in Floating-Point) habe ich mit dem Remez-
Algorithmus berechnet:
http://en.wikipedia.org/wiki/Remez_algorithm
Um das Polynom in Integer-Arithmetik zu übertragen, habe ich es erst die
Koeffizienten des Polynoms um den Faktor 10⁸ hochsakliert, so dass der
Wertebereich des Ergebnisses von 1…10 nach 10⁸…10⁹ angehoben und damit
den Wertebereich von int32_t bestmöglich ausnutzt, ohne dabei die
Ziffernfolge des Ergebnisses zu verändern.
Dann habe ich das Polynom nach dem Horner-Schema umgeformt, um die
Potenzen wegzubekommen:
http://de.wikipedia.org/wiki/Horner-Schema
Darin habe ich jeden Teilausdruck bestehend aus Muliplikation und
anschließender Addition so mit einer Zweierpotenz skaliert, dass beim
maximalen Argument von 1000 das Ergebnis des Teilausdrucks gerade noch
in den Wertebereich von int32_t passt. Dadurch wird die Bitauflösung der
Berechnungen deutlich verbessert, ohne dass es dabei zu Überläufen
kommt.
Da die >>-Operation einer Division mit Abrunden entspricht, habe ich
schließlich alle Ausdrücke der Form a>>b durch a+(1<<b-1)>>b ersetzt, so
dass gewöhnlich gerundet und damit die Genauigkeit noch etwas verbessert
wird.
Hallo Yalu X.,
vielen Dank, deine Ausarbeitung habe mir sehr geholfen!
Ich bin leider schon etwas aus der Übung und hätte mir die Verfahren
nicht so schnell angeeignet.
Die numerische und diskrete Mathematik liegt schon etwas zurück.
Yalu X. schrieb:> Da die >>-Operation einer Division mit Abrunden entspricht, habe ich> schließlich alle Ausdrücke der Form a>>b durch a+(1<<b-1)>>b ersetzt, so> dass gewöhnlich gerundet und damit die Genauigkeit noch etwas verbessert> wird.
Noch ein kleiner Nachtrag:
a >> b durch [a + 1 << (b-1)] >> b
Oder allgemeiner
a / c durch (a + c/2) / c
Hoffe da jetzt keinen Fehler gemacht zu haben. Allerdings ist die
Rundung hier nur für positive Zahlen korrekt, richtig?
Simon K. schrieb:> Oder allgemeiner> a / c durch (a + c/2) / c>> Hoffe da jetzt keinen Fehler gemacht zu haben. Allerdings ist die> Rundung hier nur für positive Zahlen korrekt, richtig?
Ja, für positive Zahlen stimmt das. Leider wird in C (anders als bspw.
in Python) gegen 0 gerundet. Bei positiven Divisionsergebnissen wird
also ab-, bei negativen aber aufgerundet. Das macht beim Arbeiten mit
negativen Zahlen oft Fallunterscheidungen erforderlich.
Die >>-Operation mit negativem linken Operand ist zwar implementation-
defined, zumindest die C-Compiler für i86-Prozessoren und AVRs generie-
ren daraus aber Code, der einer Division durch eine Zweierpotenz mit
Abrunden (auch bei negativen Ergebnissen) entspricht. Deswegen funktio-
niert die von mir verwendete Rundung auf dem geforderteten Zielsystem,
dem ATtiny, und auf dem PC. Ich hätte aber dazuschreiben sollen, dass
das nicht für alle Plattformen garantiert und somit nicht portabel ist.
{kind=link}