Hallo, ich habe ein 16Bit-paralleles Interface am FPGA, über das ich Datenwort empfange und dann in ein RAM speichere. Zum Debuggen wäre es interessant, die Anzahl der gesetzten Bits mitzuzählen, die an meinem Interface reinkommen. Allerdings kommen die Worte mit voller Taktrate rein, d.h. ich müßte die Anzahl der gesetzten Bits im Wort in einem Takt erfassen. Ich könnte natürlich mit einem "for"-Konstrukt jede Menge parallele Vergleicher erzeugen... Oder gibt es da vielleicht noch einen Trick 17?
Wozu benötigt man da Vergleicher?
d0 ---\
|
d1 --(+)--\
|
d2 ------(+)--\
|
d3 ----------(+)--\
...
|
d1 ------------------(+)--> Sum
Wenn die synthese inteligent ist dann macht sie was performantes draus.
Bronco schrieb: > Ich könnte natürlich mit einem "for"-Konstrukt jede Menge parallele > Vergleicher erzeugen... Du wirst sowieso nicht drumrum kommmen... Aber halb so schlimm: es werden nicht "jede Menge Vergleicher" herauskommen, sondern nur ein relativ simples Logikkonstrukt mit 16 Eingängen und 5 Ausgängen, weil mehr als 16 Zustände sowieso nicht vorkommen können. BTW: War alles schonmal da... https://www.mikrocontroller.net/search?query=einsen+zählen&forums[]=9
Ich hätte da dann mal was ausprobiert:
1 | library IEEE; |
2 | use IEEE.STD_LOGIC_1164.ALL; |
3 | use IEEE.NUMERIC_STD.ALL; |
4 | |
5 | entity CountOnes is |
6 | Port ( i : in STD_LOGIC_VECTOR (15 downto 0); |
7 | o : out STD_LOGIC_VECTOR (4 downto 0)); |
8 | end CountOnes; |
9 | |
10 | architecture Behavioral of CountOnes is |
11 | |
12 | begin
|
13 | -- Spartan 3
|
14 | -- Number of Slices 42
|
15 | -- Number of 4 input LUTs 73
|
16 | process (i) |
17 | variable cnt : integer range 0 to 16 := 0; |
18 | begin
|
19 | cnt := 0; |
20 | for c in 0 to 15 loop |
21 | if i(c)='1' then |
22 | cnt:=cnt+1; |
23 | end if; |
24 | end loop; |
25 | o <= std_logic_vector(to_unsigned(cnt,5)); |
26 | end process; |
27 | |
28 | -- Spartan 3
|
29 | -- Number of Slices 16
|
30 | -- Number of 4 input LUTs 28
|
31 | process (i) |
32 | variable cnt : unsigned (4 downto 0); |
33 | begin
|
34 | cnt := "00000"; |
35 | for c in 0 to 15 loop |
36 | cnt:=cnt+unsigned'("0000"&i(c)); |
37 | end loop; |
38 | o <= std_logic_vector(cnt); |
39 | end process; |
40 | |
41 | end Behavioral; |
Die erste Variante gibt einen recht aufwendigen Multiplexer und braucht 27ns, die zweite Variante die gewünschten Addierer mit 19ns Durchlaufzeit (incl. IO-Pads Treiber!)...
Lothar Miller schrieb:1 | cnt:=cnt+1; |
Das klingt ja zu schön, um wahr zu sein! Baut die Synthese da etwa einen Addierer mit 16 Eingängen?
Lothar Miller schrieb: > variable cnt : integer range 0 to 16 := 0; Interessanter Unterschied im synthese Ergebnis. Vielleicht käme die synthese mit einem range 0 to 31 besser zurecht.
Bronco schrieb: > Baut die Synthese da etwa einen Addierer mit 16 Eingängen? Nein, die baut 16 Addierer... Ottmar schrieb: > Interessanter Unterschied im synthese Ergebnis. Vielleicht käme die > synthese mit einem range 0 to 31 besser zurecht. Das ist der Synthese schnuppe.
Lothar Miller schrieb: > Die erste Variante gibt einen recht aufwendigen Multiplexer und braucht > 27ns, die zweite Variante die gewünschten Addierer mit 19ns > Durchlaufzeit (incl. IO-Pads Treiber!)... Die dritte Variante ist noch schneller (16.444ns):
1 | process (i) |
2 | variable c0 : unsigned (2 downto 0); |
3 | variable c1 : unsigned (2 downto 0); |
4 | variable c2 : unsigned (2 downto 0); |
5 | variable c3 : unsigned (2 downto 0); |
6 | variable cnt : unsigned (4 downto 0); |
7 | begin
|
8 | cnt := "00000"; |
9 | c0 := "000"; |
10 | c1 := "000"; |
11 | c2 := "000"; |
12 | c3 := "000"; |
13 | for c in 0 to 3 loop |
14 | c0 := c0+unsigned'("00"&i(c)); |
15 | c1 := c1+unsigned'("00"&i(c+4)); |
16 | c2 := c2+unsigned'("00"&i(c+8)); |
17 | c3 := c3+unsigned'("00"&i(c+12)); |
18 | end loop; |
19 | cnt:= unsigned'("00"&c0) + unsigned'("00"&c1) + unsigned'("00"&c2) + unsigned'("00"&c3); |
20 | o <= std_logic_vector(cnt); |
21 | end process; |
Mit Synplify Pro bekomme ich für die Variante 1 ein ganz anderers Ergebnis. V1: 25 LUT V2: 28 LUT V3: 28 LUT
Ottmar schrieb: > Mit Synplify Pro bekomme ich für die Variante 1 ein ganz anderers > Ergebnis. Und was kommt dabei heraus? Anscheinend erkennt dieser Synthesizer, dass das if nicht wirklich eine Abfrage ist, und generiert keine Multiplexer wie XST 13.2 das tut. Kurz: es ist schon sinnvoll, wenn man das Verhalten "seines" Synthesetools ab und an mal auf Eigenarten abklopft...
Angehängte Dateien:
-

V1_RTL.png
30 KB
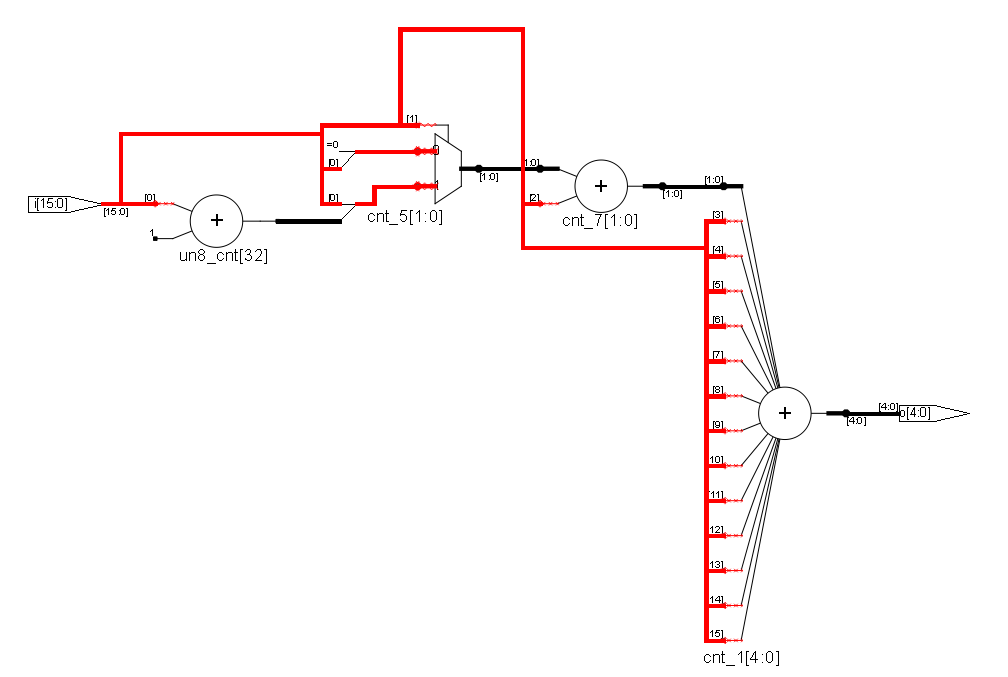
V1: Siehe Anhang. V2: Ein Adder mit 16 eingängen. Nach dem mappen: V1 benutzt einige MUXCY und reduziert damit den LUT count. V2 besteht nur aus LUT's
einsen zählen kann man auch ohne Schleife, siehe angehängten C-Code. Das ist nur Bitfummelei, auch die Multiplikation, das sollte sich leicht in VHDL umsetzen lassen, wozu ich (leider leider) nicht in der Lage bin. Cheers Detlef /*******************************************************************/ uint8_t cntbits(uint32_t a) /*******************************************************************/ {uint32_t mask=011111111111ul; a=(a-((a&~mask)>>1))-((a>>2)&mask); a+=a>>3; a=(a&070707)+((a>>18)&070707); a*=010101; return ((a>>12)&0x3f); }
Ich frage mich, warum er bei der Adderlösung II etwas anderes rausbekommt, da die Adder ja auch nur über LUTs abgebildetet werden und am Ende zu dem selben Resultat führen müssten, wie die MUX-Version. Offenbar sind die Tools dann doch nicht intelligent, wie man denkt. Was kommt denn raus, wenn man bei beiden "restucture MUX" anwrift? Auch "register retimg" sollte das tool veranlassen, die Struktur auzzubrechen.
Roberto schrieb: > Offenbar sind die Tools dann doch nicht intelligent, wie man denkt. Sie haben ihre eigene "Intelligenz", die sich von Version zu Version ändert, aber nicht zwingend weiterentwickelt... ;-) Detlef _a schrieb: > Das ist nur Bitfummelei, auch die Multiplikation, das sollte sich > leicht in VHDL umsetzen lassen, wozu ich (leider leider) nicht in > der Lage bin. Da sind ja nun einige Rechenoperationen drin, da muss der Synthesizer schon schlau sein, um die in Logik umzubiegen...
Detlef _a schrieb: > einsen zählen kann man auch ohne Schleife, siehe angehängten C-Code. Bekommt das Dein C-Code auch in einem einzigen Takt hin?
Die Anforderung für einen Takt hatte ich überlesen. Der Code braucht
vier Takte, die kannst Du allerdings pipelinen, sodass für jeden Takt
ein Ergebnis kommt, allerdings 4 Takte zeitverzögert.
Aber: Geht auch in einem Takt :-)))) , und zwar mit dem angehängten
Code. Dort habe ich die sequentiellen Rechnungen durch defines ersetzt,
braucht mehr Resourcen aber nur einen Takt, also quasi parallelisiert.
Die Multiplikation habe ich durch Addition von drei Summanden ersetzt.
Das ganze ist für 32Bit, bei 16 wird das noch bißchen übersichtlicher.
Bitte auch beachten, dass bei C Zahlen mit führender 0 als Oktalzahlen
interpretiert werden.
Danke, war Spaß gewesen.
Cheers
Detlef
P.S. So sieht das expandierte Makro aus: :-))))
return
((((((((a-((a&~(011111111111ul))>>1))-((a>>2)&(011111111111ul)))+(((a-((
a&~(011111111111ul))>>1))-((a>>2)&(011111111111ul)))>>3))&070707)+(((((a
-((a&~(011111111111ul))>>1))-((a>>2)&(011111111111ul)))+(((a-((a&~(01111
1111111ul))>>1))-((a>>2)&(011111111111ul)))>>3))>>18)&070707))+((((((a-(
(a&~(011111111111ul))>>1))-((a>>2)&(011111111111ul)))+(((a-((a&~(0111111
11111ul))>>1))-((a>>2)&(011111111111ul)))>>3))&070707)+(((((a-((a&~(0111
11111111ul))>>1))-((a>>2)&(011111111111ul)))+(((a-((a&~(011111111111ul))
>>1))-((a>>2)&(011111111111ul)))>>3))>>18)&070707))<<6)+((((((a-((a&~(01
1111111111ul))>>1))-((a>>2)&(011111111111ul)))+(((a-((a&~(011111111111ul
))>>1))-((a>>2)&(011111111111ul)))>>3))&070707)+(((((a-((a&~(01111111111
1ul))>>1))-((a>>2)&(011111111111ul)))+(((a-((a&~(011111111111ul))>>1))-(
(a>>2)&(011111111111ul)))>>3))>>18)&070707))<<12))>>12)&0x3f);
/*******************************************************************/
uint8_t cntbits1(uint32_t a)
/*******************************************************************/
{
#define mask (011111111111ul)
#define a0 ((a-((a&~mask)>>1))-((a>>2)&mask))
#define a1 (a0+(a0>>3))
#define a2 ((a1&070707)+((a1>>18)&070707))
//#define a3 (a2*010101)
#define a3 (a2+(a2<<6)+(a2<<12))
return ((a3>>12)&0x3f);
}
Ähm, bin nicht sicher, ob das ein Takt wird. Muß ich nochmal frischer drüber nachdenken. Cheers Detlef
Wenn's denn noch interessiert: Ja, das geht in einem Takt. Wird aber ne fette kombinatorische Logik mit entweder sehr vielen Gattern nebeneinander (viel Resourcen) oder viele Gatter hintereinander (lange Laufzeit). Cheers Detlef
Logisch, dass das in einem Takt gehen muss. Denn in dem geposteten Rechenwerk sind nur Addierer, Subtrahierer und Schiebeoperatoren beteiligt. Aber nichts, was gespeichert werden müsste. Wenn das Ganze allerdings Teil eines getakteten Systems ist, dann wird hier nur eine geringe Taktfrequenz erreicht werden können, weil die Durchlaufzeit durch das Rechenwerk recht lang sein wird...
In meinem ursprüglichen Algorithmus mußte man sehr wohl was abspeichern, da brauchte man 4 Takte. Dafür war die Logik einfach. Die Logik wird komplexer wenn man das Ergebnis in einem Takt braucht, aber auch da gibts tradeoffs: entweder langsam (Gatter hintereinander, geringe maximale Taktfrequenz) oder Gatter parallel (aufwendig). Am schnellsten/auwendigsten wäre es, die 2^16 Quersummen aus einer Tabelle zu holen. Am langsamsten/einfachsten ist es, die 16Bit sequentiell durch einen Addierer zu schieben. Zwischen den beiden Extremen kann man sich beliebig bewegen, kommt drauf an, was man will/muß, aber das ist immer so. Cheers Detlef
Detlef _a schrieb: > In meinem ursprüglichen Algorithmus mußte man sehr wohl was abspeichern Ja, den Algorithmus kennt ja nun keiner ausser dir... > Zwischen den beiden Extremen Interessant wären Zahlen zum Ressourcenverbrauch, zur Durchlaufzeit und zur Toolchain. Hast du da was?
Lothar Miller schrieb: > Detlef _a schrieb: >> In meinem ursprüglichen Algorithmus mußte man sehr wohl was abspeichern > Ja, den Algorithmus kennt ja nun keiner ausser dir... > Klar kennen den Algorithmus auch andere, den Algorithmus hatte ich doch oben dargestellt. Außerdem stammt der leider nicht von mir sondern ist der Standard zum Bits zählen in C, siehe z.B. ersten hit für 'number of set bits in a word'. Wenn man den kennen wollen würde, könnte man den auch vor meinen Einlassungen schon gekannt haben. Es gibt im übrigen nichts, was nur ich alleine wüßte, zumindest auf technischem Gebiet. >> Zwischen den beiden Extremen > Interessant wären Zahlen zum Ressourcenverbrauch, zur Durchlaufzeit und > zur Toolchain. Hast du da was? Nein, hab nix, kann kein VHDL, naja, so gut wie nicht. Cheers Detlef
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.