Da habe ich in der Header Datei aber folgendes gefunden:
1
typedefunion
2
{
3
WORDVal;
4
BYTEv[2]__PACKED;
5
struct__PACKED
6
{
7
BYTELB;
8
BYTEHB;
9
}byte;
10
struct__PACKED
11
{
12
__EXTENSIONBYTEb0:1;
13
__EXTENSIONBYTEb1:1;
14
__EXTENSIONBYTEb2:1;
15
__EXTENSIONBYTEb3:1;
16
__EXTENSIONBYTEb4:1;
17
__EXTENSIONBYTEb5:1;
18
__EXTENSIONBYTEb6:1;
19
__EXTENSIONBYTEb7:1;
20
__EXTENSIONBYTEb8:1;
21
__EXTENSIONBYTEb9:1;
22
__EXTENSIONBYTEb10:1;
23
__EXTENSIONBYTEb11:1;
24
__EXTENSIONBYTEb12:1;
25
__EXTENSIONBYTEb13:1;
26
__EXTENSIONBYTEb14:1;
27
__EXTENSIONBYTEb15:1;
28
}bits;
29
}WORD_VAL,WORD_BITS;
Da steht LB und HB drinne, ich glaube das die genau diesen Fall schon
vorgesehen haben. wie kann ich mit hilfe der union ein WORD_VAL
umwandeln auf BYTE?
Also irgendwie funzt das nicht Anständig.
Ich habe es mal ohne WORD_VAL gemacht:
1
WORDw=0;
2
w=(GAIN_PGA1_1|GAIN_PGA2_2|GAIN_PGA3_16);
3
bufferX[0]='X';
4
bufferX[1]=((BYTE)(w>>8));
5
bufferX[2]=((BYTE)(w));
6
bufferX[3]='X';
7
bufferX[4]='\0';
8
putsUART((char*)bufferX);
Ergebnis: er verschluckt das zweite X was angezeigt werden soll. und die
Werte davor passen auch nicht.
Das ganze mal am PC mit gcc ( funzt out of the box):
simon schrieb:> Ergebnis: er verschluckt das zweite X was angezeigt werden soll. und die> Werte davor passen auch nicht.
Dann schreib doch wenigstens, was er ausgibt. Und poste bitte den ganzen
Code. Dann spart man sich viel Rätselraten. Man sieht z.B. nicht,
welchen Typ bufferX hat. Und wenn eines der Bytes 0 ist, hört die
Ausgabe natürlich an der Stelle auf, weil das Byte dann als
String-Ende-Zeichen erkannt wird.
simon schrieb:> Was ich mich immernoch Frage was die sache mit "char" soll.> Worin unterschiedet sich Char von Byte?> typedef char CHAR8;> typedef unsigned char UCHAR8;> typedef unsigned char BYTE;>> Also scheinbar nur im Vorzeichen, nur wozu brauche ich bei einem char> ein Vorzeichen?
Wenn Du mit kleinen, vorzeichenbehafteten Werten (-128 bis 127) rechnen
willst, nimmst Du ein signed char. Wenn Deine Werte von 0 bis 255 gehen,
nimmst Du ein unsigned char. Wenn Du Buchstaben ausgeben willst, nimmst
Du ein char. Eigentlich ganz einfach.
Die Typen CHAR8, UCHAR8 und BYTE hat Dein Compilerhersteller definiert,
weil er sie anscheinend schöner fand. Ich würde die nicht in eigenem
Code nehmen. Dann lieber <stdint.h> einbinden und Du hast für kleine
Zahlen diese eindeutigen Typen:
simon schrieb:> #define GAIN_PGA1_1 (0x0001)> #define GAIN_PGA2_2 (0x0002<<3)> #define GAIN_PGA3_16 (0x0005<<6)>> WORD w = (GAIN_PGA1_1 | GAIN_PGA2_2 | GAIN_PGA3_16 );
Nein.
Ich meine an der Ausgabe. Lass es dir mal mit einem printf ausgeben. Die
0 für x muss ja irgendwo herkommen. Wenn das High-Byte in w schon 0 ist,
dann geht die Suche weiter, warum das High-Byte 0 ist und nicht warum
bei der Zerlegung was schief geht.
Daher sollte man mal klären, ob die 0 schon im w drinnen steckt oder
nicht.
> #define GAIN_PGA3_16 (0x0140)
Funzt Perfekt.
Mal so zum verstehen, was ist hier den genau schief gelaufen?
Der Preprozessor hat das als größere oder kleinere Variable gesehen?
Gibt es hier eine Einfache Möglichkeit das WORD in w dieser Funktion zu
übergeben?
Die Funktion erwartet (Gain addresse, anzahl bytes, pointer auf byte)
1
w=(WORD)(GAIN_PGA1_1|GAIN_PGA2_2|GAIN_PGA3_16);
2
3
xx_write_SPI((WORD)GAIN,2,(BYTE*)&w);// Ist es auch ok hier ein WORD zu nehmen?
simon schrieb:>> #define GAIN_PGA3_16 (0x0140)>> Funzt Perfekt.>> Mal so zum verstehen, was ist hier den genau schief gelaufen?
Ist das wieder so ein Müll, dass der Compiler entgegen dem C-Standard
ein
5 << 6
als 8-Bit Operation implementiert, anstatt wie es richtig wäre als int
Operation? Bzw. der eigentliche Scheiss besteht darin, dass der COmpiler
einen int mit 8 Bit zulässt, obwohl des gegen jeden C-Standard
verstösst?
Ich frage deshalb, weil in einem anderen Thread genau dieser Müll mit
dem CSS Compiler auf einem Pic aufgetreten ist.
Das solltest du unbedingt abklären, denn das ist eine wichtige
Information für dich. Was ergibt
int i = 5 << 6;
sprintf(buffer, "T: %#d\n", i);
putsUSART( buffer );
wenn da nicht 320 rauskommt, dann such nach dem Compilerschalter, wie du
diesen Dreck abdrehen kannst. Wenn ein int nicht mehr garantiert
mindestens 16 Bit hat, und der Compiler das auch in arithmetischen
Ausdrücken mit den Promotionrules berücksichtigt, dann ist das keine
Hilfe für den Programmierer sondern dann haben sie dem Compilerbauer ins
Hirn gesch.... (wie Mundl Sackbauer sagen würde)
simon schrieb:> Funzt Perfekt.>> Mal so zum verstehen, was ist hier den genau schief gelaufen?>> Der Preprozessor hat das als größere oder kleinere Variable gesehen?
Was ist denn mit den anderen beiden Möglichkeiten? Funktionieren die
auch? Wenn ja, dann hält sich Dein Compiler nicht an den C-Standard,
weil ein int für ihn nur 8 statt mindestens 16 Bit breit ist.
Der Compiler hat also die Zahl 0x0005 als 8-Bit-Wert genommen (die
führenden Nullen interessieren nicht) und den Linksshift um 6 Stellen
auch nur mit 8 Bit gerechnet. Dann ist das oberste Bit rausgeflogen,
weil es nicht mehr in 8 Bit gepasst hat.
Wie gesagt verstößt das aber gegen den C-Standard. Wenn das der Fall
ist, solltest Du mal schauen, ob man das nicht ändern kann (per Option
beim Aufruf des Compilers).
simon schrieb:
1
xx_write_SPI((WORD)GAIN,2,(BYTE*)&w);// Ist es auch ok hier ein WORD zu nehmen?
Das wäre sinnlos, denn die Funktion erwartete einen Zeiger auf ein BYTE.
Das kannst Du als Aufrufer der Funktion nicht ändern. Du musst ihr das
geben, was sie haben will. In dem Fall will sie einen Zeiger auf ein
BYTE. &w ist aber ein Zeiger auf ein WORD. Also musst Du den BYTE* in
einen WORD* umwandeln. Der Compiler würde das auch ohne expliziten Cast
automatisch machen (er hat ja keine andere Wahl), aber das gibt dann
eine Warnung.
Den ersten Cast (WORD)GAIN kannst Du Dir dagegen sparen. Die Funktion
erwartetet ein WORD, also wird ihr der Compiler ein WORD übergeben. Auch
wenn GAIN vielleicht kein WORD ist. Bei Integern gehen solche impliziten
Casts ohne Warnung, da sie ständig vorkommen.
Das hier funktioniert wunderbar, nur ob das jetzt Zufall ist weisz ich
nicht.
Mein Problem ist das ich die Funktion nicht ändern kann/sollte weil ich
manchmal nur 1 byte schicke und manchmal auch 2, 3 oder 4 byte.
Gibt es hier den kein Trick wie ich aus dem Pointer auf mein word ein
byte pointer machen kann?
Zu den Fragen:
Alle drei der genannten Möglichkeiten Funktionieren und bringen das
richtige Ergebnis.
Ich sehe gerade, ich habe mich in meinem Beitrag verschrieben:
> In dem Fall will sie einen Zeiger auf ein> BYTE. &w ist aber ein Zeiger auf ein WORD. Also musst Du den BYTE* in> einen WORD* umwandeln.
Das muss richtig heißen:
In dem Fall will sie einen Zeiger auf ein BYTE. &w ist aber ein Zeiger
auf ein WORD. Also musst Du den WORD* in einen BYTE* umwandeln.
Genau das machst Du bei dem Funktionsaufruf ja mit dem Cast:
1
(BYTE*)&w
Das ist also so gesehen schon in Ordnung. Es ist aber nicht die beste
Methode, das zu machen. Denn es ist tatsächlich gewissermaßen "Zufall",
dass es funktioniert. Denn diese Methode verlässt sich darauf, dass die
beiden Bytes in der richtigen Reihenfolge (in der sie der Empfänger
erwartet) im Speicher des WORDs stehen. Das mag bei Deinem
Mikrocontrollertyp der Fall sein, kann auf anderen Prozessoren aber auch
genau andersrum sein.
Deshalb wäre es besser, einen Sendepuffer anzulegen, in den Du die Bytes
an die richtige Stelle legst:
1
WORDw=GAIN_PGA1_1|GAIN_PGA2_2|GAIN_PGA3_16;
2
3
BYTEbuffer[2];
4
buffer[0]=w>>8;
5
buffer[1]=w;
6
7
xx_write_SPI(GAIN,sizeof(buffer),buffer);
Falls Du die xx_write_SPI()-Funktion selber geschrieben hast, würde ich
übrigens die Reihenfolge der Parameter nr_bytes und data umdrehen. Denn
es ist allgemein üblich, zuerst den Zeiger und dann die Länge anzugeben.
Alle Funktionen in der C-Standardbibliothek erwarten das so. Es ist
irritierend, wenn das plötzlich anders ist.
Fabian O. schrieb:> Falls Du die xx_write_SPI()-Funktion selber geschrieben hast, würde ich> übrigens die Reihenfolge der Parameter nr_bytes und data umdrehen. Denn> es ist allgemein üblich, zuerst den Zeiger und dann die Länge anzugeben.> Alle Funktionen in der C-Standardbibliothek erwarten das so. Es ist> irritierend, wenn das plötzlich anders ist.
ok, Das Beispiel was ich hatte war auch ursprünglich mal so.
Also irgendwo steckt doch da echt der wurm drinne..
1
UINT32x;
2
BYTEobuf[4];
3
charbuffer[20];
4
5
x=(UINT32)831870;
6
sprintf(buffer,"VL: %d \n",x);// gibt 12 aus??
7
putsUSART(buffer);
8
9
obuf[0]=0;
10
obuf[1]=((BYTE)(x>>16));
11
obuf[2]=((BYTE)(x>>8));
12
obuf[3]=((BYTE)x);
13
14
xx_write_SPI((WORD)VLEVEL,4,(BYTE*)&obuf[0]);// ins Register schreiben
15
x=0;
16
xx_read_SPI((WORD)VLEVEL,4,(BYTE*)&x);// Zurück lesen
17
18
sprintf(buffer,"VLEVELx: %#x\n",x);// Gibt 0x7eb1 aus, wo ict das 0C ?
19
putsUSART(buffer);
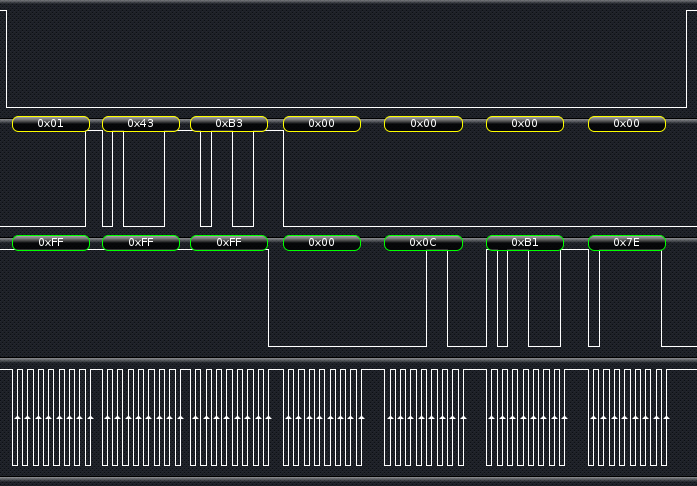
obuf wird genau mit der spi Funktion ausgegeben, ich sehe dann auch die
richtigen Werte am SPI.
0x00 0x0C 0xB1 0x7E = 831870;
Nur wie kann es sein das sprintf nur 12 Anzeigt?
Was sagt dann aus das x als UINT32 angesehen wird?
%i? %u?
ich kann im C18 manual nur noch x und X finden für den hex wert.
Aber selbst beim zweiten hex wert fehlt mir ein 0x0C