Hallo Leute! Ich versuche jetzt ein paar Sachen zu erklären: Also, ein Scheduler ist dafür zuständig die Prozesse der CPU zuordnen. Es gibt 2 Grundsysteme: kooperatives Multitasking(Der aktive Prozess gibt von sich aus die CPU nach einem bestimmten Zeitpunkt frei) und verdrängendes Multitasking(Der Scheduler kann einem aktiven Prozess die CPU entziehen(durch Timer-Interrupt z.B.)). Scheduler-Strategien: - first come - first serve: Also nach dem Prinzip "Wer zuerst kommt, malt zuerst", d.h. je früher der Prozess da ist, desto früher wird ihm die CPU zugeteilt. - Prioritätssteuerung: jedem Prozess wird eine Priorität hinzugeteilt. Je höher diese ist, desto früher wird dem Prozess die CPU zugeteilt. - round robin(zeitverschiebeverfahren): Die Prozesse sind in der Warteschlange, diese wird durch "Wer zuerst kommt, malt zuerst" angeordnet oder? Je früher ein Prozess kommt, desto weiter vorne steht er in der Warteliste. Und dann gibt es eine Zeitschlitz, d.h. wenn dieser 20ms wäre, dann wird der 1. Prozess 20ms die CPU bzw. Ressourcen zugeteilt und dann stellt er sich hinten in der Warteschlange an --> 2. Prozess kommt für 20ms dran usw. Stimmt das was ich bisher gesagt habe? Fehlt noch etwas, was noch wichtig zu sagen wäre? Wie ist denn das? Wird nach 20ms ein Timer-Interrupt ausgelöst, d.h. round robin wird nur beim verdrängenden Multitasking verwendet? Bei Prioritätssteuerung und first come - first serve, wenn der Prozess die CPU zugeteilt wird, wie lange wird da der Prozess ausgeführt? Bis er fertig ist? Oder wie geht das genau? Wie hängt das zusammen? "Scheduling als arbeiten mit Listen": Ok ich weiß nur das es eine Prozess-Tabelle gibt. Wie werden die Prozesse da angeordnet? Sind die irgendwie in der Tabelle angeordnet? Diese Prozesse in dieser Tabelle sind mit Pointern verbunden, also einfach eine einfach verkettet Liste. Und in welche Reihenfolge wird verkettet? Also wie anordnen? Es gibt da Ready-, Blocked-, und Free-Listen, d.h. nur Prozesse die Ready sind in die Ready-List, die Blocked sind die Blocked-List usw., richtig? Naja erstmal das hier verstehen, vielleicht weiß ich dann genau wie gemischtes Scheduling und watch Dog funktioniert. Bitte helft mir! Danke. mfg scheduler
scheduler schrieb: > Wie ist denn das? Wird nach 20ms ein Timer-Interrupt ausgelöst, d.h. > round robin wird nur beim verdrängenden Multitasking verwendet? Es gibt üblicherweise einen zyklischen Timer. Dessen Interrupt kann den Scheduler beeinflussen, also beispielsweise Tasks für lauffähig zu erklären. Das ist unabhängig davon, ob kooperativ oder verdrängend. Der Unterschied ist nur, dass der Interrupt in einem kooperativen System stets zur aufrufenden Task zurückkehrt und eine ggf. notwendige Umschaltung zu einem anderen von der Task kontrollierten Zeitpunkt erfolgt, während der Interrupt in einem verdrängenden System ggf. zu einer anderen Task zurückkehrt. > Bei Prioritätssteuerung und first come - first serve, wenn der Prozess > die CPU zugeteilt wird, wie lange wird da der Prozess ausgeführt? Bis er > fertig ist? Oder wie geht das genau? Wie hängt das zusammen? Ist es wirklich so schwierig, konkrete Suchbegriffe mit Leben zu füllen?
Du hast scheinbar ein Script oder sowas in der Art vorliegen, in dem nicht nur allgemeine Begriffe zu Schedulern vorkommen, sondern beispielhaft bestimmte Organisationsformen dargestellt werden. Allerdings gibt es mehrere Wege nach Rom, so dass der Entwickler eines Schedulers einige Freiheit hat, seine Informationen zu strukturieren. Das können eine oder mehrere einfach oder doppelt verkettete Listen oder auch Arrays sein, oder was auch immer.
A. K. schrieb: > Der Unterschied ist nur, dass der Interrupt in einem kooperativen System > stets zur aufrufenden Task zurückkehrt und eine ggf. notwendige > Umschaltung zu einem anderen von der Task kontrollierten Zeitpunkt > erfolgt, während der Interrupt in einem verdrängenden System ggf. zu > einer anderen Task zurückkehrt. Beim kooperativen System kann ja der Prozess jeder Zeit die CPU entziehen und der Interrupt kehrt zum ausführendem Task zurücke, was meinst du damit? Und den Rest des Satzes verstehe ich leider gar nicht :(. Tut mir leid, aber kannst du mir das nochmal erklären bitte?
scheduler schrieb: > aber kannst du mir das nochmal erklären bitte? Es gibt eine Menge Literatur zu diesem Thema. Die wäre wohl der bessere Ansatz. Es gibt auch offen verfügbaren und z.T. recht kompakten Beispielcode zu Schedulern, nämlich in den vielen RTOS-Kernels.
Angehängte Dateien:
-

prozess.jpg
56 KB
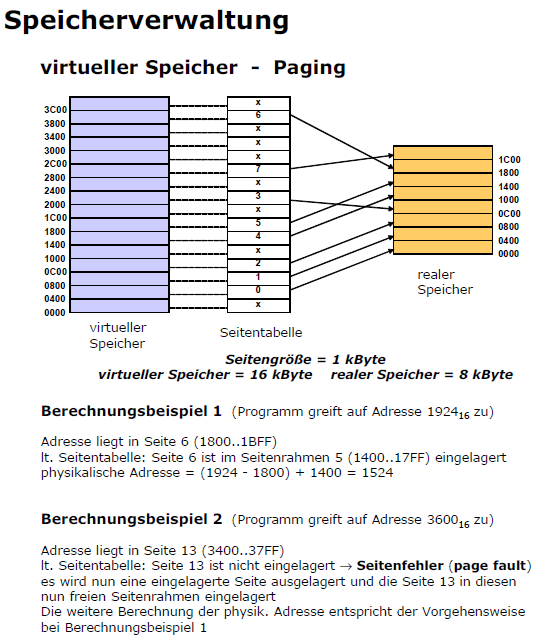
Danke dir! Und noch eine Frage: Der Prozess befindet sich ja auch einer physikalischen Adresse und auf einer virtuellen Adresse. Aber heißt das? Was passiert da ungefähr? Was bringen diese virtuellen Adressen und physikalischen? Virtueller Speicher: So ein virtueller Speicher wird ja auf einem Massenspeicher geholt, wenn der Speicher auf dem RAM nicht mehr ausreicht, oder? Da gibts ja so Seitenrahmen(realer Speicher) und Seiten(virteuller Speicher). Naja und die MMU ist dafür zuständig von virtueller Adresse auf physikalischer Adresse zu rechne, aber was hat das für einen Siinn? Wenn es eh genügend physikalischen Speicher gibt, warum macht man dann einen virtuellen? Ich hab im Anhang ein Bild zu 2 physikalischen Addressen berechungs-bsp. Kann dir mir jemand wer erklären bitte? Dann müsste ich auch das Paging verstehen. Danke.
scheduler schrieb: > Naja und die MMU ist dafür zuständig von virtueller Adresse auf > physikalischer Adresse zu rechne, aber was hat das für einen Siinn? Wenn > es eh genügend physikalischen Speicher gibt, warum macht man dann einen > virtuellen? - Weil es eben nicht notwendigerweise genug physikalischen Speicher für den gesamten Adressraum aller Prozesse gibt. Jedenfalls nicht zu dem Zeitpunkt, zu dem diese Konzepte und die Betriebssysteme entstanden. Heute ist dieser Aspekt nicht mehr so deutlich sichtbar, aber lass mal 20 Anwender gleichzeitig auf einem Rechner mit 4MB RAM arbeiten... - Weil Prozesse oft inkrementell wachsen. Was macht man, wenn 10 Prozesse dicht an dicht im Speicher liegen, und der erste will wachsen? - Weil man einen Schutzmechanismus benötigt, der einem Prozess den Zugriff auf Kernel-Speicher und andere Prozesse verweigert. - Weil heutige Betriebssysteme u.U. Disk-Files in den virtuellen Speicher abbilden und Disk-I/O damit von Paging kaum noch unterscheidbar ist. usw. Auf die Gefahr hin, mich zu wiederholen: Du brauchst ein Lehrbuch, kein Stochern im Nebel.
Danke, ja Lehrbuch habe ich nicht, nur so ein .pdf wo net wirklcih viel drinnen ist :/. Kannst du mir bitte das 1. Bsp erklären? Seite ist ja im Virtuellen Speicher und Seitenrahmen im realen Speicher. Mann soll ja die virtuelle Adresse 1924 in eine physikalische Adresse umwandeln. Bitte erklär mir das.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.