Hallo, Ich bin schon lägner am Überlegen einen eigenen Processor in VHDL zu schreiben. Es soll ein 32 Bit Processor werden und einen sehr kleinen aber effektiven Instruktion Set beinhalten. Hierfür suche ich nun Ideen, was wäre eurer Meinung nach sinnvolle zu implementierende Instruktions. Hier meine bisherigen Auswahl: ALU Operationen addiere, subtrahiere, schiebe links, xor, and, or, Sprungbefehle Sprung, Call Befehl, Return Befehl, Branch if bit in SREG is set/cleared Registermanipulation Kopiere Register, Lade Register, speichere Register eventuell noch Push und Pop lassen sich eventuell einige Befehle hier einsparen oder sind wichtige Vergessen ? Gruß Tobias
Wie willst du IO machen? Memory-Mapped? Wenn nein, brauchst du noch IO Befehle. Du solltest mal ein paar Assemblerbeispiele durchgehen für andere CPUs, für Anwendungsfälle, die du dir auf deinem Vorstellen kannst. Dort dann schauen, was man einfacher machen könnte. Dementsprechend überlegen, welche Befehle du brauchst, welche nicht.
Genau Memory mapped Mir fällt grad auf links schieben fällt weg dafür sollte rechts schieben rein, da links schieben mit einer addition mit sich selbst realisiert werden kann.
Meist orientieren sich die Diskussionen über solche ISAs an Stack-Maschinen. Siehe auch INMOS Transputer. Befehle 1 Byte breit, 4-Bit Opcode, 4-Bit Konstante/Offset/Opcode. Präfix-Befehl hängt seine 4 Bit an das entsprechende Feld vom nächsten Befehl an, also in Form eines kumulierenden Operanden-Registers. 3 Register als Stack.
A. K. schrieb: > Meist orientieren sich die Diskussionen über solche ISAs an > Stack-Maschinen. > > Siehe auch INMOS Transputer. Befehle 1 Byte breit, 4-Bit Opcode, 4-Bit > Konstante/Offset/Opcode. Präfix hängt seine 4 Bit an das entsprechende > Feld vom nächsten Befehl an (kaskadierbar). 3 Register als Stack. Ich bin mir nicht ganz sicher ob ich das jetzt richtig verstanden habe, aber ich hatte schon angedacht, Register zu nutzen, und den Stack für Register Rettung und Unterfunktionen welche mit call aufgerufen werden. Da fällt mir auf das eigentlich noch ein lade Konstante in Register Befehl fehlt. Aber diese Stack Machines sehen auch interessant aus gucke ich mir nochmal genauer an.
Der Transputern-Befehlssatz selbst ist zwar nicht minimal, aber das Prinzip selbst ist praktikabel. http://www.transputer.net/iset/
TM schrieb: > Lade Register, speichere Register > > eventuell noch Push und Pop > > lassen sich eventuell einige Befehle hier einsparen Push und Pop sind nur Varianten von Lade Register/Speichere Register mit registerindirekter Adressierung und atomarem Inkrement/Dekrement des Adressregisters.
TM schrieb: > Es soll ein 32 Bit Processor werden und einen sehr kleinen aber > effektiven Instruktion Set beinhalten. Klingt eher nach RISC, oder? Und gibt es nicht schon einen wietgehen fertigen 32bitter hier im Forum vom Herrn Dose?
Ich verstehe nicht warum hier jemand den Transputer hyped. Dessen Architektur hat sich doch schon als Flop erwiesen.
Helmut S. schrieb: > Ich verstehe nicht warum hier jemand den Transputer hyped. Dessen > Architektur hat sich doch schon als Flop erwiesen. Kommt auf das Ziel an. Wer erklärtermassen einen minimalen Prozessor entwickeln will, der hat offensichtlich keine hohe Rechenleistung im Auge. Sondern eben den minimalen Aufwand. Dafür - und nur dafür - kann die Grundstruktur des Transputers Ideen liefern. Der Transputer ist massgeblich daran gescheitert, dass sich dieses Prinzip einer Leistungssteigerung jenseits der Taktfrequenz widersetzt. Nur hatte ich nicht den Eindruck, dass es ihm darum geht. Cores für FPGAs gibt es viele, darunter viele freie. Kein Grund also, selber einen zu bauen, wenns darum geht, ein Problem zu lösen. Aber da will jemand offenbar partout selber einen bauen. Wohl eher aus Neugierde und Spieltrieb.
>...und einen sehr kleinen aber effektiven Instruktion Set beinhalten.
Das widerspricht sich. Ein kleiner Bef.satz erfordert meist mehrere
Befehle fürs Programm, und ist damit autom nicht so sehr effektiv.
(Stichwort Adressierungsarten!)
TM schrieb: > einen sehr kleinen aber brainf*ck-CPU? Hätte nur 8 Befehle, allerdings ist die Effizienz nicht ganz so gut :-)
..also wenn Du es ∗einfach∗ machen willst dann nimm eine deterministische Turingmaschine also Vorlage, die kommt mit einem 7-Tupel aus</hüstel>. Noch ein paar Ein-Ausgabe-Erweiterungen dranspaxen und fertig.
A. K. schrieb: > Der Aufwand? Immerhin hat er das "sehr klein" sogar extra fett betont. MIPS ist mit dem Designziel der absoluten Vereinfachung entworfen worden. Gerade die Dekodierung und Befehlsverarbeitung sind recht simpel. "Sehr klein" ist recht vage. Einen einfachen MIPS Core kann man mit etwa 10k Gattern bauen. Wenn es kleiner werden soll, dann würde ich keinen 32-bit Prozessor nehmen, sondern was mit 16 oder 8 Bit. Wenn auch der Befehlsumfang sehr klein sein soll, könnte man sich bei den PICs oder AVRs umsehen. Transputer bringt nicht viel in diesem Zusammenhang - ist schon genug Mist geschrieben worden.
Murkser schrieb: > MIPS ist mit dem Designziel der absoluten Vereinfachung entworfen > worden. Das ist richtig, aber das Ziel davon war hohe Performance mit adäquatem Aufwand, nicht Minimalismus. So ist der Registerset gross und die Codierung der Befehle ist eher platzraubend. Aber das artet nun schon etwas aus. Soll er sich die Vorschläge anschauen und entscheiden, welche Richtung ihm genehm ist, immerhin ist es seine Kiste, nicht unsere. Nackter Minimalismus rein was die Anzahl Befehle angeht, das geht ohnehin anders. MaxQ2000 hat exakt 2 Befehle. Move register to register und Move constant to register. Mehr gibts nicht. > Transputer bringt nicht viel in diesem Zusammenhang - ist schon genug > Mist geschrieben worden. Das Kernprinzip von dieser Architektur reduziert den Gesamtaufwand ziemlich deutlich. Zu Lasten von Performance, verglichen mit RISC gleicher Technologiestufe. Ich hatte den Transputer auch nicht als Krone der Schöpfung erwähnt (als Basis für real zu verkaufende Maschinen wars eine böse Falle), sondern weil bei Konzepten für minimale Maschinen praktisch immer Stack-Maschinen in der Diskussion sind, und das Kernprinzip dieser ISA ist nun einmal eine Stack-Maschine geringer Komplexität.
PS: Um das noch einmal klar zu stellen: In welche Richtung man gehen sollte hängt massgeblich vom gesteckte Ziel ab. Ist das Ziel die maximale Performance bei mässigem Aufwand, oder ist das Ziel minimaler Aufwand bei mässiger Leistung? Dabei können recht verschiedene Lösungen rauskommen. Sein "effektiv" ist sowieso ein sehr dehnbarer Begriff.
TM schrieb: > Es soll ein 32 Bit Processor werden und einen sehr kleinen aber > effektiven Instruktion Set beinhalten. Geht es bei Effizienz nur um die Anzahl der Befehle, oder um den Ressourcenbedarf der Implementierung? Im ersten Fall würde ich einen Barrelshifter zwingend vorschreiben. Denn nichts ist ineffizienter, als jeden Shift in zig einzelne Befehle aufzuteilen... Insgesamt solltest du dir aber schon vor dem Hardwaredesign Gedanken zur Toolchain für die SW-Entwicklung machen.
Oder mal einen Blick auf einen der ersten "unfreiwilligen" RISC-Prozessor werfen, Data Generals NOVA: http://en.wikipedia.org/wiki/Data_General_Nova und http://users.rcn.com/crfriend/museum/doco/DG/Nova/base-instr.html Die konnte mit einem Befehl rechnen, shiften und springen. Ok, die war "nur" 16-Bit, aber das ließe sich doch erweitern!?
DG/One schrieb: > Die konnte mit einem Befehl rechnen, shiften und springen. Ok, die war > "nur" 16-Bit, aber das ließe sich doch erweitern!? Diese DGs gabs auch auf 32 Bits erweitert. Allerdings etwas mit der Brechstange, weils unbedingt binärkompatibel bleiben musste.
Ja, die MVs als Pendant zur VAX. Ein anderes 32Bit Design von DG (Fountainhead Project) wurde ja eingestampft, weil es eben nicht kompatibel war... Aber es ging ja um den Befehlssatz. Der der Nova brauchte übrigens keinen Microsequencer sondern wurde direkt in Hardware dekodiert. Wenn man ihn sich anschaut weiß man auch warum das "so einfach" geht.
Lothar Miller schrieb: > TM schrieb: >> Es soll ein 32 Bit Processor werden und einen sehr kleinen aber >> effektiven Instruktion Set beinhalten. > Geht es bei Effizienz nur um die Anzahl der Befehle, oder um den > Ressourcenbedarf der Implementierung? Im ersten Fall würde ich einen > Barrelshifter zwingend vorschreiben. Denn nichts ist ineffizienter, als > jeden Shift in zig einzelne Befehle aufzuteilen... > > Insgesamt solltest du dir aber schon vor dem Hardwaredesign Gedanken zur > Toolchain für die SW-Entwicklung machen. Es geht noch nicht um die Implementierung, dass wäre der nächste schritt. Es geht eher darum einen kleinen Instruction set zu finden, bei welchem sagen wir mal mäßige Leistung rausspringt. Es geht nicht um den kleinsten Instruction Set dieser wäre ja ein One Instruction Set Computer. Ich stelle demnäcst nochmal meine bisherige Auswahl an Befehlen hier rein. Gruß Tobias
DG/One schrieb: > Aber es ging ja um den Befehlssatz. Der der Nova brauchte übrigens > keinen Microsequencer sondern wurde direkt in Hardware dekodiert. Wenn > man ihn sich anschaut weiß man auch warum das "so einfach" geht. Yep, ziemlich einfache Basis. Die optionale speicherindirekte Adressierung ist allerdings etwas aufwendiger. Aber die kann man ja weglassen.
> MIPS ist mit dem Designziel der absoluten Vereinfachung entworfen > worden. Stimmt. Es sollte -mit möglichst wenig Aufwand- von nur 2 Leuten binnen nur weniger Monate eine CPU 'entworfen' werden (die auch lauffähig ist). Von hoher Performance war das meilenweit weg. Man hat auch damals (wegen dem minimalistischen) bewusst in Kauf genommen, dass die Leistung (weit) hinter damaligen CPUs zurück bleibt. >Es geht eher darum einen kleinen Instruction set zu finden, bei welchem >sagen wir mal mäßige Leistung rausspringt. wird dann wohl auf LD/ST rauslaufen.
Moin, nur so als Tip: Fang das Design in Python+MyHDL anstatt VHDL an. Du sparst Dir ne Menge Arbeit und die Lösung konvergiert - bei cleverem Entwurf der Testbench - schneller zur Stabilität, als es Dir VHDL ermöglicht. Du musst Dir nur noch die grossen Fragen stellen: * Kompatibel zu irgend einem Compiler? C oder nur asm? Debugger? * Exception-Handling, Interrupts? * Bus-Architektur? (Harvard/vonNeumann, Mischmasch?) Habe im letzten Jahr eine Menge 32 bit general purpose CPUs evaluiert, dabei kristallisierten sich nur wenige Architekturen als brauchbar heraus. Orientieren würde ich mich an: - ZPU (stackbasiert) - MIPS (ion, plasma, yellowstar, mais) - DLX - mico32, ev. microblaze-Clones Von der Kleinheit ist die ZPU sehr elegant, aber in der Basisversion langsam, da nicht pipelined. Der Befehlssatz ist sehr minimal, komplexere Befehle werden per Software-Emulation abgehandelt. Bei den andern Architekturen steckt überall ein wenig MIPS-Philosophie dahinter, die dreckigen Details finden sich dann im Handling der diversen 'Hazards' oder ev. zusätzlicher Branch-Prediction-Logik. Die machen dann auch meist die Gatter-Zusatzkosten oder ev. lästige Verlangsamungen (max. Systemclock) aus. An der zwar interessanten, doch eigenwilligen Transputer-Philosophie würde ich mich im FPGA nur bedingt festbeissen, allerdings helfen schon einige Aspekte, um für seine Spezialanwendung eine simple microcode-geschaltete Pipeline zu basteln und als Coprozessor an eine general purpose CPU von der Stange ranzuflanschen. Prinzipiell finde ich aber die Idee nicht schlecht, sich eine eigene, einfache CPU ranzuzüchten (ich hab's mir auch gegeben :-) ), die sich per copy-paste und kleinen Modifikationen auf den jeweiligen Zweck anpassen lässt. Mit einer generischen CPU würde ich allerdings nicht als erstes anfangen. Viele solche Projekte scheitern da auf den letzten Metern, weil Code-Wartung und Debugging wie auch saubere Verifikation/Validierung die Komplexität schlussendlich sprengen. In VHDL muss man sich da erst mal furchtbar viel Framework aufbauen. Grüsse, - Strubi
Hey, Also ich werds auf jeden Fall in VHDL machen in MyHDL müsste ich mich erst einarbeiten. Außerdem finde ich das Konzept mit einer Hochsprache Hardware zu beschreiben irgendwie zueinander im Widerspruch. Zur CPU. Sie soll Registerbasierend sein. Das heißt es soll ein Register file geben, welches direkt an der ALU angeschlossen ist ähnlich AVR, MSP430 Es soll eine 32 Bit CPU sein. Ein erstes Blockschaltbild und der Instruction Set folgen.
Kurzer Kommentar: > Also ich werds auf jeden Fall in VHDL machen in MyHDL müsste ich mich > erst einarbeiten. > Kann aus eigener Erfahrung sagen: es amortisiert sich nach ca. 5 Tagen :-) Spätestens wenn es an saubere Test cases geht, wird's mit VHDL zum overkill. > Außerdem finde ich das Konzept mit einer Hochsprache Hardware zu > beschreiben irgendwie zueinander im Widerspruch. > Finde ich gar nicht. Die Hardwarebeschreibung ist auf dem selben Level wie VHDL/Verilog. Nur eine andere Sprache und die Simulation/Konversion um Mengen eleganter als SystemC und ähnliche Konsorten. > Zur CPU. > > Sie soll Registerbasierend sein. Das heißt es soll ein Register file > geben, welches direkt an der ALU angeschlossen ist ähnlich AVR, MSP430 > Es soll eine 32 Bit CPU sein. > Einen Aspekt gibts da noch: Register Windows. Eine clever designte Stack-Maschine mit leckeren Pre-Fetch-Hacks ist auf dem FPGA u.U. effektiv schneller als eine Tri-Port Registerbank (inkl. Hazard-Logik).
Strubi schrieb: > Kann aus eigener Erfahrung sagen: es amortisiert sich nach ca. 5 Tagen > :-) Das hat mir jetzt erhlich gesagt Mut gemacht, mir das mal anzutun. Danke für den Einwurf. Zum Thema noch dies: Es hat einen Riesenhaufen an CPUs für FPGAs und alle kranken an einem Problem: Sie sind nicht ausgereift und zu Ende gedacht / gemacht. Plant, was, was ihr auch bauen könnt.
> Zum Thema noch dies: Es hat einen Riesenhaufen an CPUs für FPGAs und > alle kranken an einem Problem: Sie sind nicht ausgereift und zu Ende > gedacht / gemacht. Plant, was, was ihr auch bauen könnt. Du hast es auf den Punkt gebracht. Ich muss auch zugeben, ich habe es mir am Anfang auch einfacher vorgestellt. Ich denke, ich habe meine CPU auch gefühlte 3-4 mal komplett überarbeitet. So ein Rechenwerk ist schnell geschrieben. Ein paar Register sind auch kein Problem und dann Ende im Gelände. Genau so sind viele CPUs. Sind eben die akademischen Meldungen, wir könnten es auch. Dann die Tools für die Programmierung ist eine weitere Baustelle für sich. Und die Zeit vergeht.
Angehängte Dateien:
-

MISC_Prozessor.jpg
46 KB
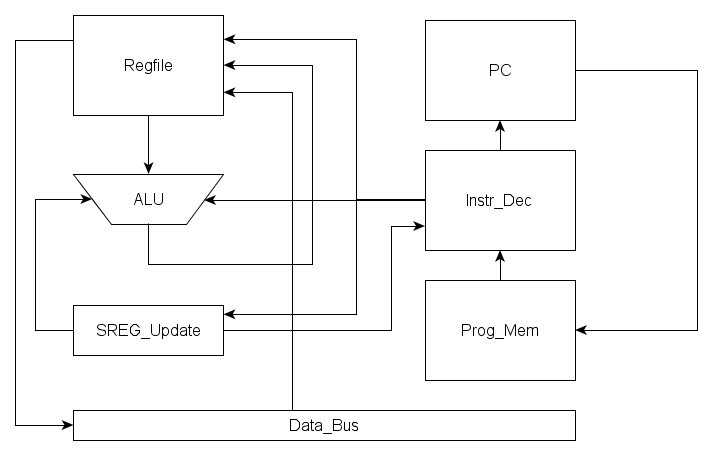
Ok, bei mir gehts nun als nächstes an den VHDL Code. Folgende Befehle sollen implementiert werden: - addiere - subtrahiere - schiebe rechts - xor - or - and - Sprung - Call - Return - Verzweige wenn Bit in sreg gesetzt/gelöscht - Lade vom Datenbus - Speichere zum Datenbus Im oberen Diagramm ist der geplante Aufbau des Prozessors sichtbar. Gruß Tobias
IMHO sollte ein Pfeil von der ALU zum Statusreg gehen und nicht vom Instruction-decode. MfG
Karl Könner schrieb: > IMHO sollte ein Pfeil von der ALU zum Statusreg gehen und nicht > vom > Instruction-decode. > > MfG Hast natürlich recht. Allerdings sollte die SREG funktionalität vom Instruction decoder enabled und disabled werden können. Also sowohl ein Pfeil von der Alu als auch vom instr_dec
Hallo, Ich werd die Fortschritte mal auf meiner Homepage dokumentieren. Als nächstes werde ich die einzelnen Komponenten wie im Blockschaltbild zu sehen entwerfen. Wenn ich mein Ziel eines ersten fertigen Entwurfs erreicht habe sage ich einfach mal bescheid. http://www.blog-tm.de/?p=80 Danke für die Anregungen. Gruß Tobias
Du kannst dir push und pop sparen... move to memory kann es ersetzen.
1 | sub sp, #8 |
2 | mov 4(sp), r0 ; push r0 |
3 | mov 0(sp), r1 ; push r1 |
es ist mehr flexibel :)
push und pop sind auch nicht vorgesehen. Dein mov Befehl wäre bei mir der OUT Befehl um daten auf den Bus zu schreiben.
Und wie möchtest du call/return from sub implementieren ?... ein Link Register könnte alles einfacher machen...
Ale schrieb: > Und wie möchtest du call/return from sub implementieren ?... ein > Link > Register könnte alles einfacher machen... ??? Call und return sind in meinem Processor vorgesehen.
Ich meine wie weil kein Push und Pop gibt, wenn du schon "push address" implementierst (für call) dann push geht genauso, denke ich.
Von Elektor/CircuitCellar ist gerade ein Buch angeküdigt oder schon lieferbar: http://www.elektor.de/products/books/english/microprocessor-design-using-verilog-hdl.2077346.lynkx "Microprocessor Design using Verilog HDL" Dem Inhaltsverzeichnis ist nicht sehr viel zu entnehmen, aber das Autor scheint kein Schwafelschmidt zu sein. "Er entwickelte alle fünf Generationen des Rabbit-Mikroprozessors (ein Z180-Clone), von denen ein Exemplar mit der Juno-Mission zum Jupiter flog. ...Z8000..." Funkamateur scheint er auch noch zu sein.
Hallo, Ich hab gemerkt das ich hier ja auch einen Account besitze. Der Prozessor nimmt langsam etwas gestallt an: Alle Befehle, welche in einem Takt ausgeführt werden sind implementiert. Als nächstes sind JUMP, CALL, RETURN und Branches dran. http://www.blog-tm.de/?p=80 Allerdings bin ich mir momentan nicht ganz sicher welche Flags für das Statusregister wichtig sind. Momentan habe ich: Carry Flag, Zero Flag, Negative Flag und ein Interrupt Flag. Die AVRs haben ja noch ein Signed Flag. benötige ich dieses und worin unterscheidet sich das nochmal vom Negative Flag. gruß Tobias
Christoph Kessler (db1uq) schrieb: > "Er entwickelte alle fünf > Generationen des Rabbit-Mikroprozessors (ein Z180-Clone), von Ich kann mich erinnern, dass zu meiner Zeit mal einer einen RISC-PRozessor in Verilog gemacht hat. War eine Studienarbeit. Später dasselbe als DA mit einem anderen zusammen. Den hat ES2 dann in einen ASIC gestopft. Das war 1994. Ich bin nicht so sicher, ob das Sinn macht eine Universal-CPU zu machen, wo es inzwischen von den Softcores wieder weg geht in Richtung hardcore ARM mit pipelining und allem Pi Pa Po.
> Ich bin nicht so sicher, ob das Sinn macht eine Universal-CPU zu machen, > wo es inzwischen von den Softcores wieder weg geht in Richtung hardcore > ARM mit pipelining und allem Pi Pa Po. Das ist eine interessanter Gedankengang, den ich in einer Schulung in die Mitte gefragt hatte. AN den Hardcore wollte keiner so richtig ran. Die Hauptgründe: Ein Produkt das heute entwickelt wird, muss über mehrere FPGA Generationen pflegbar sein. Es stellt keiner sicher, dass der Hardcore xy in die nächste FPGA-Generation auch verfügbar sein wird. Es könnte eine Marketingblase sein. Preislich sind die FPGAs mit Hardcores auch sehr teuer. Auch aus Wirtschaftlichkeit lohnt es sich auch über einen Softcore nachzudenken.
Als übung entwickle ich gerade ein 6809 core. Ist das Ding kompliziert. Kein wunder warum RISC is the way to go. Man kann viel mehr packen in ein RISC core als eine von diesen alten CISC Prozessoren. Ich schreibe es in Verilog.
Ale schrieb: > Als übung entwickle ich gerade ein 6809 core. Ist das Ding kompliziert. Bei CISC kommt noch hinzu, dass mehrere Takte für einen Befehl benötigt werden. Das ist dann ein Maschinenzyklus. Ich hatte mich am Z80 probiert und kam auch zu dem gleichen Ergebnis. Das wird eine Menge code.
René D. schrieb: > Bei CISC kommt noch hinzu, dass mehrere Takte für einen Befehl benötigt > werden. Das ist dann ein Maschinenzyklus. Typisch für CISCs ist eine uneinheitliche Laufzeit der Befehle. Das macht aber aus der Laufzeit langsamer Befehle keinen Maschinenzyklus. Eine Register-Register Addition wird durch die Fähigkeit, auch zum Speicher hin addieren zu können, nicht notwendigerweise langsamer. Zudem ist das Sache der Implementierung. Ein typischer komplexer CISC Befehl ist beispielsweise mem1 = mem1 op reg2 und der lässt sich ziemlich gut pipelinen als fetch decode fetch address decode load address op load store op store mit einem Durchsatz von 1 Takt pro Befehl, solange keine Interlocks auftreten (siehe Cyrix M1/M2). Für den gleichen Durchsatz muss ein RISC gleich drei Befehle pro Takt ausführen können, der CISC nur einen. Oder umgekehrt ausgedrückt: Der CISC Prozessor dürfte dafür effektiv 3 Takte benötigen und läge immer noch nicht schlechter als der RISC mit 1 Takt pro Befehl. Freilich ist das nur ein Teilaspekt eines viel komplexeren Szenarios.
Der eigentliche Unterschied ist die platzsparende Entscheidung damaliger Architekturen für einen kleinen Registerkontext (Akku), und Nutzung des damals vergleichweise schnellen Speichers in vielen Befehlen. Eine RISC Architektur mit vielen Registern, wie AVR, ist im Ablauf einfacher, benötigt aber recht viel Platz dafür, verglichen mit beispielsweise 6502. Nur ist der Platzunterschied heute nicht mehr relevant. Zur Einordnung: Die 32 Register eines AVR benötigen allein für die Speicherung als 6T-Zelle ~1500 Transistoren, dazu kommt der Aufwand für mehrere gleichzeitige Zugriffe. Eine 6502 CPU hatte aber insgesamt überhaupt nur ~3500 Transistoren an Bord. Bei einem FPGA rechnet sich das freilich völlig anders.
A. K. schrieb: > Bei einem FPGA rechnet sich das freilich völlig anders. Vor allem, wenn man es über Länge/Komplexität von VHDL/Verilog Quellcode vergleicht und nicht übers Ergebnis. Register, Adder etc sind Standardelemente, die man aus der Lib zieht, zudem sehr schematisch. Aber eine fehlerfreie Ablaufsteuerung ist echte Arbeit, die muss man selber machen. Da kanns leicht sein, dass diese Ablaufsteuerung im Quellcode viel komplizierter aussieht als auf dem FPGA.
Der Vorteil beim FPGA ist, dass man sich bezgl der Parallelisierung frei entscheiden kann. Ein vollständig parallele CO-CPU kann z.B. mehrere Applikationen der letzten Maschinen-Codes vorausschauend ausführen und dann post selektieren, indem der tatsächlich gemeinte Befehl das Ergebnis bestimmt. Da gibt es eine Reihe von Möglichkeiten, mit der Fläche im FPGA auf Tempo zu kommen. Mir hat Rechneraufbau und Rechnerstrukturen von Vossen geholfen.
>Kein wunder warum RISC is the way to go. Wenn das (noch) stimmen würde, würde es bspw. keinen STM8 geben. >Man kann viel mehr packen in ein RISC core RISC ist (insbes weg LD/ST) einfacher zu entwickeln, und braucht weniger Transistoren (was aber heute wegen extrem geringer Kosten eigentlich nicht mehr relevant ist). Tatsache ist aber, dass sich mit etwas CISC viel mehr Leistung herausholen lässt und auch noch weniger PrgSpeicher verbraucht wird. Und ein CISC-Befehl -sofern nicht zu kompliziert- in ein einzelne einfachere (RISC- oder uOPs-)Befehle aufzuteilen ist auch nicht die Welt.
Hallo, Also es gibt was neues vom Projekt der aktuelle Stand findet sich nun in einen Git Repository. http://www.blog-tm.de/?p=80#comment-133 Der aktuelle Stand ist eine grobe implementierung, an der allerdings noch einiges gemacht werden muss. Und der Instruction set steht fest eine Instruction set summary lässt sich im repository finden. Der nächste Schritt ist nun einen Assembler zu schreiben, damit ich effektiver implementieren und testen kann. Das Assembler tool soll in Python geschrieben werden. Gruß Tobias
ich habe bei der Suche nach einer GHDL-Starthilfe dies PDF gefunden: http://www.dossmatik.de/ghdl/ghdl_unisim.pdf Erstmal vielen Dank an den Author, es hilft sehr beim Start des GHDL. Nun hab ich neugierig gleich mal in dem misc-cpu VHDL-code gestöbert, und da kam mir eine Idee zu einem "VHDL"-assembler. So als Hilfe statt eines Assemblers, und um beim austesten eines CPU-core nicht alles in "hex" eintippen zu müssen, ich habe es gleich mal mit der >Prog_Mem.vhd< der misc-cpu ausprobiert, sieht dann so aus :
1 | -- Build a 2-D array type for the RAM
|
2 | subtype word_t is std_logic_vector((DATA_WIDTH-1) downto 0); |
3 | type memory_t is array(2**ADDR_WIDTH-1 downto 0) of word_t; |
4 | |
5 | shared variable rom_counter : integer range 0 to 1000 := 0; |
6 | shared variable tmp : memory_t := (others => (others => '0')); |
7 | |
8 | --(hier noch mehr prozeduren, kompletter Text im Anhang )
|
9 | procedure jump (constant value : std_logic_vector(23 downto 0)) is |
10 | |
11 | begin
|
12 | tmp(rom_counter) := "11101111" & value; |
13 | rom_counter := rom_counter + 1; |
14 | end jump; |
15 | |
16 | |
17 | impure function init_ram |
18 | return memory_t is |
19 | begin
|
20 | load_l(x"0","0101010101010101"); -- load l r0 |
21 | load_h(x"0","0101010101010101"); -- load h r0 |
22 | load_l(x"1","0101010101010101"); -- load l r1 |
23 | load_h(x"1","0101010101010101"); -- load h r1 |
24 | add(x"0",x"0",X"1"); -- r0+r1=>r0 |
25 | outm(x"0",X"1"); -- out r0,r1 |
26 | nop; |
27 | jump(x"000000"); -- jmp 0x0000 |
28 | --for addr_pos in 0 to 2**ADDR_WIDTH - 1 loop
|
29 | -- if(addr_pos=0) then
|
Hi, habe jetzt diesen Thread entdeckt. Da ich auch gerade an einen 32 Bit Core arbeite (mein 16 Bit Core inkl. System läuft schon siehe Beitrag "FPGA basierendes System" ), möchte ich etwas zum Assembler loswerden. Die Idee von bko ist eine gute Variante um sich schnell ein Programm für Modelsim zu stricken. Ganz am Anfang habe ich mir selber auch einen primitiven Assembler in Excel geschrieben (dann copy/paste in die Testbench (RAM-Modul)). Leider wird’s bei Labels (gerade Register-Relativ) schon etwas unangenehm. Mein Assembler für den 16 Bit Core habe ich mir mit C# geschrieben, der nimmt einfach Regex für Preprozessor (Macrofähig) / Assembler her. Für meinen 32 Bit Core habe ist nur noch der Preprocessor mittels regulären Ausdrücken erschlagen. Für den Assembler selber benutze ich „GOLD Parsing System“, das ist ein Parsergenerator (Lookahead-LR-Parse) der mir aus meiner Assembler-Grammatik dann Code generiert (ähnlich wie lex/yacc, antlr, …). [Grammatik siehe Anhang] Das ist recht einfach zu benutzen, wenn man sich etwas mit Parsern auskennt. Momentan erzeugt mein Assembler z.b. aus sowas (einfacer Test der ein Bild Dunkel->Hell macht (der 32 Bit Core Assembler von meinen 16 Bit Assembler über Preprocessorkommando geladen))
1 | org hcoreStartPc |
2 | |
3 | .def pixelCount 324000 ;740*450 |
4 | |
5 | move r20,0 ;counter |
6 | |
7 | doAgain |
8 | |
9 | move hold,testPic |
10 | moveh hold,last,>>testPic |
11 | or r0,last,0 ;source |
12 | |
13 | move hold,frame |
14 | moveh hold,last,>>frame |
15 | or r1,last,0 ;dest |
16 | |
17 | move hold,pixelCount |
18 | moveh hold,last,>>pixelCount |
19 | or r2,last,0 ;count |
20 | |
21 | move hold,$ffff |
22 | moveh hold,last,$00ff |
23 | or r5,last,0 ; |
24 | move r4,$ff |
25 | move r3,1 ; |
26 | rqld r0,0 |
27 | |
28 | loop |
29 | ld r13 ;00RRGGBB |
30 | |
31 | cmpeq r3,r2 |
32 | rqld.tc r0,2 ;request next |
33 | |
34 | and hold,r13,r5 |
35 | lsr r10,last,16 ;r10 = 0000 00RR |
36 | and r12,r13,r4 ;r12 = 0000 00BB |
37 | lsr hold,r13,8 ;hold = 0000 RRGG |
38 | and r11,last,$ff ;r11 = 0000 00GG |
39 | |
40 | ;process |
41 | |
42 | fead r10,r20 |
43 | mul_fead r10,r11,r20 ;r * c |
44 | mul_fead r11,r12,r20 ;g * c |
45 | mul r12 ;b * c |
46 | |
47 | ; |
48 | |
49 | lsr r10,r10,8 |
50 | lsr r11,r11,8 |
51 | lsr r12,r12,8 |
52 | |
53 | ;assemble |
54 | |
55 | lsl r10,r10,16 ;00RR 0000 |
56 | lsl hold,r11,8 ;0000 GG00 |
57 | or hold,last,r12 ;0000 GGBB |
58 | or hold,last,r10 ;00RR GGBB |
59 | st last,r1,0 |
60 | |
61 | cmpeq r3,r2 |
62 | br.tc loop |
63 | add r3,r3,1 ;delay slot |
64 | add r0,r0,2 ;delay slot |
65 | add r1,r1,2 ;delay slot |
66 | nop ;delay slot |
67 | |
68 | add hold,r20,1 |
69 | and r20,last,$ff |
70 | |
71 | br doAgain |
72 | nop ;delay slot |
73 | nop ;delay slot |
74 | nop ;delay slot |
75 | nop ;delay slot |
soetwas
1 | Load ucore source |
2 | Assemble |
3 | HCore Assemble |
4 | HCore Trace Long Style |
5 | $D013C680 = $00C50000 |
6 | $D013C682 = $00E9E340 |
7 | $D013C684 = $04E0D009 |
8 | $D013C686 = $2CC00000 |
9 | $D013C688 = $00E00000 |
10 | $D013C68A = $04E0D000 |
11 | $D013C68C = $2CC04000 |
12 | $D013C68E = $00E4F1A0 |
13 | $D013C690 = $04E00004 |
14 | $D013C692 = $2CC08000 |
15 | $D013C694 = $00E0FFFF |
16 | $D013C696 = $04E000FF |
17 | $D013C698 = $2CC14000 |
18 | $D013C69A = $00C100FF |
19 | $D013C69C = $00C0C001 |
20 | $D013C69E = $38A00000 |
21 | $D013C6A0 = $40C34000 |
22 | $D013C6A2 = $5820C100 |
23 | $D013C6A4 = $3AA00002 |
24 | $D013C6A6 = $28234280 |
25 | $D013C6A8 = $64C28010 |
26 | $D013C6AA = $28030684 |
27 | $D013C6AC = $64A34008 |
28 | $D013C6AE = $28C2C0FF |
29 | $D013C6B0 = $AC228A00 |
30 | $D013C6B2 = $5C028594 |
31 | $D013C6B4 = $5C02C614 |
32 | $D013C6B6 = $5CC30000 |
33 | $D013C6B8 = $64828508 |
34 | $D013C6BA = $6482C588 |
35 | $D013C6BC = $64830608 |
36 | $D013C6BE = $68828510 |
37 | $D013C6C0 = $68A2C008 |
38 | $D013C6C2 = $2C630000 |
39 | $D013C6C4 = $2C628000 |
40 | $D013C6C6 = $4C604000 |
41 | $D013C6C8 = $5820C100 |
42 | $D013C6CA = $22FFFFCE |
43 | $D013C6CC = $0880C181 |
44 | $D013C6CE = $08800002 |
45 | $D013C6D0 = $08804082 |
46 | $D013C6D2 = $B0E00000 |
47 | $D013C6D4 = $08A50001 |
48 | $D013C6D6 = $28C500FF |
49 | $D013C6D8 = $20FFFFA2 |
50 | $D013C6DA = $B0E00000 |
51 | $D013C6DC = $B0E00000 |
52 | $D013C6DE = $B0E00000 |
53 | $D013C6E0 = $B0E00000 |
54 | Generate 648526 word |
55 | Finished to assemble 877 lines in ,75s (1165,3 ls) |
56 | Store to destination |
Den Trace Code, kann man dann auch einfach ins Modelsim kopieren, oder eben ein 'Memory'-Component mit Inhalt direkt erstellen. Eine gutes Beispiel für einen Assembler in Perl ist P65 (6502 Assembler), ich glaube kompakter gehts nicht.
Schön das das Projekt auf Intresse trifft. Leider hab ich momentan kein internet und komm nur über die Uni oder über nen surf stick rein. Der Python assembler wird sich also noch etwas hinziehen und somit auch die Fehler beseitigung im Instruction decode block der CPU Gruß Tobias
Marten W. schrieb: > > Leider wird’s bei Labels (gerade Register-Relativ) schon etwas > unangenehm. Idee eines VHDl-asm-Sprunglabels rückwärts, am Sprunglabel vorwärts knoble ich noch...
1 | architecture rtl of ProgMem is |
2 | |
3 | ------------------------------------------------------------------------------------------
|
4 | |
5 | impure function init_ram |
6 | return memory_t is |
7 | |
8 | variable label1 : std_logic_vector(23 downto 0); |
9 | |
10 | begin
|
11 | |
12 | org(to_unsigned(0,32)); |
13 | load_l(x"0","0101010101010101"); -- load l r0 |
14 | -- (...)
|
15 | load_h(x"3",x"1234"); -- load h r3 |
16 | load_h(x"4",x"0001"); -- load h r3 |
17 | prog_label(label1); |
18 | |
19 | add(x"3",x"4",X"3"); -- r3+r4=>r3 |
20 | outm(x"0",X"1"); -- out r0,r1 |
21 | add(x"0",x"0",X"1"); -- r0+r1=>r0 |
22 | outm(x"0",X"1"); -- out r0,r1 |
23 | nop; |
24 | svr(x"2",x"0"); |
25 | |
26 | jump(label1); -- jmp 0x0000 |
Hallo, Nach einer längeren Pause hab ich nun das Python Programm, welches beim MISC Processor die ASM Befehle zu Opcodes convertiert. Der nächste Schritt ist den Code zu verifizieren und weitere Dokumentation zu schreiben. Auch soll die Resetlogik auf einen synchronen "Reset" umgeschrieben werden. Außerdem bin ich am überlegen die gesamte Beschreibung nochmal in Verilog zu schreiben und damit auf Verilog umzusteigen, da ich momentan mehr mit Verilog arbeite und ich mit mit Verilog angefreundet hab. Die aktuellen Dateien befinden sich auf GitHub... https://github.com/TM90/MISC_Processor
Welche Flags hast du denn nun implementiert und wie werden sie von den Operationen beeinflusst? Dazu habe ich in deinem instruction set summary nichts gefunden. Micha
Sinus Tangentus schrieb: > Welche Flags hast du denn nun implementiert und wie werden sie von > den > Operationen beeinflusst? Dazu habe ich in deinem instruction set summary > nichts gefunden. > Micha Das hab ich ganz vergessen mit reinzunehmen da hast du natürlich Recht. Ich merks mir mal und update dann die instruction set summary... Allerdings steht das mit den SREGs auch noch nicht richtig fest und ist eine Baustelle. Momentan sind implementiert: Ein zero, negative und carry Flag... Dies ist aber nicht Final ein Interrupt Enable Flag wird es auf jeden Fall noch geben.
Wenn du 2er-Komplement-Arithmetik machen willst, wäre ein Overflow-flag nicht schlecht. Das lässt sich sonst nur ziemlich aufwändig mit den vorhandenen Befehlen umgehen. D.h., du müsstest sonst nach jedem Arithmetikbefehl explizit nachschauen ob sich das Vorzeichen geändert hat oder nicht und ob das jeweils rechtens war
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.