MISRA In "Gemeinsames Subset der MISRA C Guidelines" fand ich folgende Aussagen: The basic type of char, int, short, long, float and double should not be used, but specific- length equivalents should be typedef'd for the specific compiler, and these type names used in the code. Das würde vielleicht erklären, warum mir immer wieder die Datentypen int8_t oder uint32_t über den Weg laufen - so richtig kompatibel zu int sind die erfahrungsgemäß ja nicht. Aber was hat's damit allgemein auf sich? The library functions atof, atoi and atol from library <stdlib.h> shall not be used. Warum? Zu gefährlich? The time handling functions of library <time.h> shall not be used Codeabhängig wg. Interrupts?
Sich am Riemen reißender schrieb: > MISRA > In "Gemeinsames Subset der MISRA C Guidelines" fand ich folgende > Aussagen: > > The basic type of char, int, short, long, float and double should not be > used, but specific- > length equivalents should be typedef'd for the specific compiler, and > these type names > used in the code. > Das würde vielleicht erklären, warum mir immer wieder die Datentypen > int8_t oder uint32_t über den Weg laufen - so richtig kompatibel zu int > sind die erfahrungsgemäß ja nicht. Aber was hat's damit allgemein auf > sich? Weil je nach System die Typen unterschiedliche Wertebereiche haben, kann ein Programm auf einem System funktionieren, und auf einem anderen scheitern (z.B. wenn man int für Werte nimmt, die mehr als 2 Byte benötigen) > > The library functions atof, atoi and atol from library <stdlib.h> shall > not be used. > Warum? Zu gefährlich? Weil sie die ach so bösen int, long und float nehmen. Sich am Riemen reißender schrieb: > The time handling functions of library <time.h> shall not be used > Codeabhängig wg. Interrupts? Alles böse! (Ich mag keine bornierten Ideologen, deshalb auch kein MISRA.)
Gibt es im MISRA-Dokument kein "Rationale"-Kapitel, das solche Fragen beantwortet?
Sich am Riemen reißender schrieb: > The basic type of char, int, short, long, float and double should not be > used, but specific- Für char finde ich das ausgesprochen albern. Insbesondere da die Länge da eben nicht systemabhängig ist. Ein char ist ein Byte. Fertig. (Vermutlich geht es denen um die systemabhängige Definition des char als unsigned oder signed, aber wenn das im Code einen Unterschied macht, dann sollte man es explizit deklarieren und nicht einfach char nehmen.)
Mit nichten! Ein char kann auch z.B. 16 bit lang sein. Z.B. beim C2000 ist ein char immer 16 bit!
Sich am Riemen reißender schrieb: > The basic type of char, int, short, long, float and double should not be > used, but specific- > length equivalents should be typedef'd for the specific compiler, and > these type names > used in the code. > Das würde vielleicht erklären, warum mir immer wieder die Datentypen > int8_t oder uint32_t über den Weg laufen - so richtig kompatibel zu int > sind die erfahrungsgemäß ja nicht. Aber was hat's damit allgemein auf > sich? Gegenfrage: Welchen Datentyp nimmst du denn, wenn du Werte zwischen -40000 und +40000 speichern möchtest? > The library functions atof, atoi and atol from library <stdlib.h> shall > not be used. > Warum? Zu gefährlich? Nein, eher überholt. Besser sind strtol/strtoul/strtof, mit denen kann man auch fehlerhafte Strings erkennen. Das geht mit atoi etc. nicht. > The time handling functions of library <time.h> shall not be used > Codeabhängig wg. Interrupts? Da sind viele Funktionen bei, die nicht eintrittsinvariant sind. asctime etc., die liefern den formatierten String in einem statischen Stringpuffer zurück und das verträgt sich prinzipiell nicht so gut mit Nebenläufigkeit.
Stefan Rand schrieb: > Sich am Riemen reißender schrieb: >> The basic type of char, int, short, long, float and double should not be >> used, but specific- > > Für char finde ich das ausgesprochen albern. Insbesondere da die Länge > da eben nicht systemabhängig ist. Ein char ist ein Byte. Fertig. Das ist richtig. Aber ein Byte ist nicht immer ein Oktett. C99 garantiert aber, dass alle anderen Typen stets Vielfache Größen von 'char' sind und dass ein 'char' mindestens 8 Bit hat.
Sich am Riemen reißender schrieb: > MISRA > In "Gemeinsames Subset der MISRA C Guidelines" fand ich folgende > Aussagen: > > The basic type of char, int, short, long, float and double should not be > used, but specific- > length equivalents should be typedef'd for the specific compiler, and > these type names > used in the code. > Das würde vielleicht erklären, warum mir immer wieder die Datentypen > int8_t oder uint32_t über den Weg laufen - so richtig kompatibel zu int > sind die erfahrungsgemäß ja nicht. Aber was hat's damit allgemein auf > sich? Ganz einfach: C definiert nicht den genauen Wertebereich, den diese einfachen Datentypen haben, sondern der Compilerhersteller sucht sich das in Abhängigkeit von der Zielplattform aus. Es könnte durchaus sein, daß sogar auf der gleichen Plattform je nach Compiler ein int mal 16 und mal 32 Bits hat und so weiter. > The library functions atof, atoi and atol from library <stdlib.h> shall > not be used. > Warum? Zu gefährlich? Ich kann nur raten, aber wahrscheinlich aus oben genanntem Grund. char (das a in den Funktionen!), float, int und long sind ja plattformspezifische Typen. Wenn man sich eigene Typen per "typedef" schafft, dann weiß man nicht, auf welche nativen Typen diese auf jeder Plattform abgebildet werden, sodaß es zu unerwarteten Fehlfunktionen kommen könnte. > The time handling functions of library <time.h> shall not be used > Codeabhängig wg. Interrupts? Möglicherweise ist nicht einmal garantiert, daß die Plattform eine Uhr hat, die für sinnvolle Werte bei Funktionen wie time() sorgt?
Smarter every day. Danke für die Hilfe. >Gibt es im MISRA-Dokument kein "Rationale"-Kapitel, das solche Fragen >beantwortet? Ich hab nur das benutzt was ich bei Wiki finden konnte, ein vollständiges Originaldokument fand ich nicht. >Weil je nach System die Typen unterschiedliche Wertebereiche haben, kann >ein Programm auf einem System funktionieren, und auf einem anderen >scheitern Ahh! Das würde dann zB. bedeuten, daß eine int-Zahl, deklariert mit int32_t immer, unabhängig vom Zielsystem, 32bit hat. Wunderbar. Wenn ich jetzt noch wüßte, was Autor: Sven P. (haku) mit >eintrittsinvariant meinte... ist der Regentag gerettet.
Sich am Riemen reißender schrieb: > Wenn ich jetzt noch wüßte, was > Autor: Sven P. (haku) > mit >>eintrittsinvariant > meinte... > ist der Regentag gerettet. Neusprech: 'reentrant'. Die Funktionen benutzen einen statischen Puffer. Wenn du die Funktion aus dem Programm aufrufst und dann kommt ein Interrupt, der dieselbe Funktion seinerseits aufruft, überschreiben die beiden Aufrufe sich gegenseitig den (gemeinsamen, da statischen) Puffer.
Sven P. schrieb: > Die Funktionen benutzen einen statischen Puffer. Wobei das m.W. nur die Funktionen asctime und ctime (die auf asctime aufbaut) betrifft. Beide sind sowieso deprecated, und man sollte stattdessen strftime benutzen. Somit würde ich es verstehen, wenn MISRA asctime und ctime verböte, aber warum sind gleich alle Funktionen aus time.h böse? Sich am Riemen reißender schrieb: >>Gibt es im MISRA-Dokument kein "Rationale"-Kapitel, das solche Fragen >>beantwortet? > Ich hab nur das benutzt was ich bei Wiki finden konnte, ein > vollständiges Originaldokument fand ich nicht. Das Originaldokument gibt es nur für Geld. Wenn du MISRA benutzen musst, sollte derjenige, der dir das vorschreibt (bspw. dein Arbeitgeber), dieses Dokument haben. Wenn du MISRA nicht benutzen musst, dann mach einfach einen weiten Bogen drumherum :) Ich bezweifle allerdings, dass in dem Dokument tatsächlich Begründungen für die Regeln enthalten sind, und wenn doch, dürften viele von ihnen überholt sein. Viele der Regeln stammen noch aus Zeiten, wo C-Compiler noch nicht in der Lage waren, gefährliche Programmkonstrukte selber zu erkennen und als Warnung auszugeben. Um die MISRA-Regeln einfach zu halten, sind sie oft allgemeiner gehalten als wirklich nötig und verbieten damit auch Konstrukte, die eigentlich völlig ungefährlich sind.
Stefan Rand schrieb: > Sich am Riemen reißender schrieb: >> The basic type of char, int, short, long, float and double should not be >> used, but specific- > > Für char finde ich das ausgesprochen albern. Insbesondere da die Länge > da eben nicht systemabhängig ist. Ein char ist ein Byte. Fertig. > > (Vermutlich geht es denen um die systemabhängige Definition des char als > unsigned oder signed, aber wenn das im Code einen Unterschied macht, > dann sollte man es explizit deklarieren und nicht einfach char nehmen.) Eigentlich würde das doch auch implizit bedeuten, daß man sämtliche Funktionen, die mit Arrays aus char arbeiten, also z.B. alle Stringfunktionen oder auch fopen() nicht verwenden darf, denn man müßte ihnen ja ein Array aus char übergeben. Sven P. schrieb: > Sich am Riemen reißender schrieb: >> Wenn ich jetzt noch wüßte, was >> Autor: Sven P. (haku) >> mit >>>eintrittsinvariant >> meinte... >> ist der Regentag gerettet. > Neusprech: 'reentrant'. Die Funktionen benutzen einen statischen Puffer. > Wenn du die Funktion aus dem Programm aufrufst und dann kommt ein > Interrupt, der dieselbe Funktion seinerseits aufruft, überschreiben die > beiden Aufrufe sich gegenseitig den (gemeinsamen, da statischen) Puffer. Ich hätte da eher verboten, solche Funktionen überhaupt aus einer ISR heraus aufzurufen.
c2000 schrieb: > Mit nichten! Ein char kann auch z.B. 16 bit lang sein. Z.B. beim C2000 > ist ein char immer 16 bit! Ja und? Ist trotzdem ein Byte.
Sven P. schrieb: > Das ist richtig. Aber ein Byte ist nicht immer ein Oktett. Macht ja nix. Wenn man ein Byte braucht (für memcpy und Konsorten), dann nimmt man char, ansonsten halt uint8_t und sowas.
Stefan Rand schrieb: > c2000 schrieb: >> Mit nichten! Ein char kann auch z.B. 16 bit lang sein. Z.B. beim C2000 >> ist ein char immer 16 bit! > > Ja und? Ist trotzdem ein Byte. Ja, aber die Länge ist eben doch systemabhängig. Das ist nicht soviel anders als bei int. char ist eben mindestens 8 Bit groß, kann aber auch größer sein, int ist mindestens 16 Bit groß, kann aber auch größer sein. Der einzige Unterschied ist, daß sizeof(char) immer 1 ist, aber das hilft dir auch nicht viel.
Yalu X. schrieb: > Ich bezweifle allerdings, dass in dem Dokument tatsächlich Begründungen > für die Regeln enthalten sind Da unterschätzt du MISRA allerdings. “The time handling functions of library <time.h> shall not be used. Includes time, strftime. This library is associated with clock times. Various aspects are implementation dependent or unspecified, such as the formats of times. If any of the facilities of time.h are used then the exact implementation for the compiler being used must be determined and a deviation raised.”
Jörg Wunsch schrieb: > Da unterschätzt du MISRA allerdings. Ja, ich habe mich inzwischen auch etwas näher darüber informiert :) Bei der Diskussion hier sollte man sich der folgenden Punkte bewusst sein: - Es gibt mehrere Versionen von MISRA-C: von 1998 (C90), 2004 (C90) und 2012 (C99/C11) und zusätzlich eine Version von MISRA-C++ von 2008. Einige Widersprüche und Unklarheiten der früherensten Version sind in späteren Versionen behoben worden. - Die meisten der aufgeführten Regeln sind "required", einige aber auch nur "advisory". Man kann den Unterschied im Regeltext an den Wörtern "shall" (required) und "should" (advisory) erkennen. Die Regel, dass für die Basisdatentypen char, short, int usw. Typedefs verwendet werden sollen, ist advisory und bezieht und bezieht sich seit MISRA-C:2004 ausdrücklich auf numerische Datentypen. Der Typ char darf für Zeichen verwendet werden, jedoch ausschließlich für diese. Damit ist die Verwendung der Funktionen aus string.h legal. Es wird allerdings empfohlen, char in char_t typezudefen.
Stefan Rand schrieb: > Für char finde ich das ausgesprochen albern. Insbesondere da die Länge > da eben nicht systemabhängig ist. Ein char ist ein Byte. Fertig. Schön wärs ;-). Ich hätte es vorher auch nicht geglaubt, aber ich hatte letztens einen DSP in den Fingern dessen Compiler für einen char 16Bit benutzt hat.
Guest schrieb: > Schön wärs ;-). Ich hätte es vorher auch nicht geglaubt, aber ich hatte > letztens einen DSP in den Fingern dessen Compiler für einen char 16Bit > benutzt hat. Ja, aber nach der klassischen Definition ist ein Byte diejenige Informationseinheit, in der ein Computer ein einzelnes Zeichen speichert. Auch nach dem C-Standard belegt ein char per definitionem exakt 1 Byte. Damit ist auf deinem DSP ein Byte eben 16 Bit groß, die Größe eines char aber immer noch 1 Byte. Auf dem TMS320C30 ist sogar ein double nur 1 Byte groß.
Yalu X. schrieb: > Damit ist auf deinem DSP ein Byte eben 16 Bit groß, die Größe eines char > aber immer noch 1 Byte. Nö, ein char belegt tatsächlich bei dem Ding 2 Byte. Ist aber auch tatsächlich ein ganz perverses Vieh, die Addressieung ist auch ein wenig ungewöhnlich, weil sich hinter jeder Speicheradresse nicht ein Byte sondern ein 16Bit Wert verbirgt. Klingt komisch ist aber so ;-). Auf ein einzelnes Byte kann also gar nicht direkt zugegriffen werden.
Guest schrieb: > Nö, ein char belegt tatsächlich bei dem Ding 2 Byte. Nein. Per definitionem ist ein Zeichen ein Byte, als kleinste adressierbare Einheit. In ähnlicher Form steht das auch im C-Standard drin; die Anzahl der Bits ist dabei ausdrücklich als implementierungsabhängig offen gelassen. Internationale Standards benutzen, wenn sie eine Einheit von 8 Bits meinen, daher auch den Begriff „Oktett“ (englisch “octet”).
Jörg Wunsch schrieb: >> Nö, ein char belegt tatsächlich bei dem Ding 2 Byte. > > Nein. Ich glaube wir reden gerade ein bisschen aneinander vorbei ;-). Ich verstehe aber schon was du meinst. Ich hätte wohl besser sagen sollen, das ein char bei dem DSP 16Bit belegt, was dann von mir aus ein "Byte" ist.
Guest schrieb: > Ich hätte wohl besser sagen sollen, das ein char bei dem DSP 16Bit > belegt, was dann von mir aus ein "Byte" ist. Exakt. C definiert sich sein eigenes 'Byte', das zwar meistens, aber nicht notwendigerweise mit der üblichen Definition einer 8-Bit Einheit identisch ist.
Guest schrieb: > was dann von mir aus ein "Byte" ist. Wenn du mal zu Wikipedia schaust, wirst du aber merken, dass du mit deiner Definition eines Bytes relativ allein dastehst.
Häh? Ich habe dir doch recht gegeben und eingesehen, das ich deine Antwort missverstanden hatte. Wenn man halt jeden Tag damit zu tun das ein Byte 8Bit sind muss man sich halt erstmal umgewöhnen ;-).
Guest schrieb: > Häh? Ich habe dir doch recht gegeben und eingesehen, das ich deine > Antwort missverstanden hatte. Sorry, nun hatte ich deine Antwort wohl auch noch missverstanden. ;-) Aber ich gebe dir völlig Recht, dass man sich an den Gedanken, dass ein Byte eben manchmal nicht genau 8 Bits hat, wirklich erstmal gewöhnen muss.
@Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite >Nein. Per definitionem ist ein Zeichen ein Byte, als kleinste >adressierbare Einheit. In ähnlicher Form steht das auch im >C-Standard drin; die Anzahl der Bits ist dabei ausdrücklich als >implementierungsabhängig offen gelassen. Das ist einer von vielen Gründen, warum ich kein Softwerker bin. Die ewige Variabilität elementarster Dinge gehr mir ganz schön auf den Keks. Klingt fast so, als hätten Anwälte den C-Standard geschrieben :-(
Falk Brunner schrieb: > Das ist einer von vielen Gründen, warum ich kein Softwerker bin. Ist das bei den Hardwerkern etwa anders? > Die ewige Variabilität elementarster Dinge gehr mir ganz schön auf den > Keks. Das Byte ist nicht elementar. Elementar ist das Bit ;-) > Klingt fast so, als hätten Anwälte den C-Standard geschrieben :-( Der C-Standard ist bezüglich der Verwendung des Begriffs "Byte" in sich konsistent. Viel mehr kann man nicht verlangen.
Ich könnte mir freilich vorstellen, dass man bei einer Architektur, deren chars 16 Bits haben, mit (u)int8_t nicht glücklich wird.
Falk Brunner schrieb: > Das ist einer von vielen Gründen, warum ich kein Softwerker bin. Die > ewige Variabilität elementarster Dinge gehr mir ganz schön auf den Keks. Dann pass lieber auf, dass du dich in der Hardware nicht zu sehr den elementarsten Dingen näherst, sondern lieber im etwas weniger elementaren verbleibst. ;-) > Klingt fast so, als hätten Anwälte den C-Standard geschrieben :-( Gezwungenermassen werden Standards gern etwas formal. Der ursprüngliche K&R liess in dieser Hinsicht deutlich zu wünschen übrig. Folge: Er galt bald als unpräzise.
Yalu X. schrieb: > Das Byte ist nicht elementar. Als Basis der Adressierbarkeit schon, da in C kein Konzept für Bitadressierung existiert.
Jörg Wunsch schrieb: > Aber ich gebe dir völlig Recht, dass man sich an den Gedanken, dass > ein Byte eben manchmal nicht genau 8 Bits hat, wirklich erstmal > gewöhnen muss. Im Grunde ist das ein ganz alter Hut. Erst seit sich fast die gesamte Computerwelt auf 8-Bit Bytes geeinigt hat und nur DSPs Ausnahmen bilden, ist das zur Selbstverständlichkeit geworden. Davor war bei vielen Maschinen noch nicht einmal eindeutig, wie breit ein Zeichen ist. Weil auf der gleichen Maschine im rein wissenschaftlichen Kontext gerne 6 Bits verwendet wurden, in anderem Kontext für einen grösseren Zeichenumfang aber 8 oder 9 Bits. Und keins von beiden direkt adressierbar war, weil die Maschine nur Halb- oder Ganzworte direkt adressierte. Und wenn eine Maschine doch sowas wie Bytes adressieren konnte, dann konnte es sein, dass die Adresse ein anderes Format besass als normale Wortadressen. Also eine Konvertierung von Wort- zu Byteadresse eine echte Rechenoperation darstellt (das gibts auch heute noch: MaxQ2000).
A. K. schrieb: > Ich könnte mir freilich vorstellen, dass man bei einer Architektur, > deren chars 16 Bits haben, mit (u)int8_t nicht glücklich wird. Nun, der Punkt dabei ist ja genau dieser: (u)int8_t existiert auf einer derartigen Architektur schlicht nicht, und ein entsprechendes Programm lässt sich nicht compilieren. Ist ja allemal viel besser als ein Programm, welches implizit annimmt, dass "unsigned char" 8 Bits repräsentiert, und dann erst irgendwann später "baden geht".
@Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite >Ist ja allemal viel besser als ein Programm, welches implizit annimmt, >dass "unsigned char" 8 Bits repräsentiert, und dann erst irgendwann >später "baden geht". Die Logik erschließt sich mir nicht. Welcher (C)-Programmierer geht denn NICHT davon aus, dass char 8 Bit hat?
Falk Brunner schrieb: > Die Logik erschließt sich mir nicht. Welcher (C)-Programmierer geht denn > NICHT davon aus, dass char 8 Bit hat? DSP-Programmierer? Allerdings scheint POSIX CHAR_BIT auf exakt 8 Bits festzulegen, so dass man wohl nicht beides haben kann - jene DSPs und POSIX.
Falk Brunner schrieb: > Welcher (C)-Programmierer geht denn NICHT davon aus, dass char 8 Bit > hat? Jemand, der den Standard ernst nimmt und sich bei dieser Annahme der nicht strikten Konformität seiner Applikation bewusst ist. Seit C99 gibt's ja nun auch keinerlei Grund mehr, für solche Fälle den Typ “char” zu benutzen: wer eine kleine Ganzzahl mit exakt 8 Bits benötigt, nehme halt “int8_t” oder “uint8_t”; “char” bleibt dann einfach dem vorbehalten, wofür es ursprünglich mal konzipiert war: ein Zeichen für die Ein-/Ausgabe aufzunehmen (einschließlich all der str*-Funktionen). Für diesen Zweck ist es auch völlig belanglos, ob das “char” nun vorzeichenbehaftet ist oder nicht. Wer eine kleine Ganzzahl mit mindestens 8 Bits benötigt, hat die Wahl zwischen “[u]int_fast8_t” oder “[u]int_least8_t”, je nachdem, ob ihm die Geschwindigkeit oder das Platzsparen wichtiger ist. Damit kann man relativ portabel ausdrücken, dass zwar 8 Bits genügen für den Zweck, aber (uint_fast8_t) eben auf einem ARM der Datentyp auch ruhig größer sein darf (weil es schneller geht so), oder aber (uint_least8_t) eine Umgebung wie die genannten DSPs, die keinen 8-Bit-Typ besitzt, eben dann einen größeren wählen darf.
@ Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite >> Welcher (C)-Programmierer geht denn NICHT davon aus, dass char 8 Bit >> hat? >Jemand, der den Standard ernst nimmt und sich bei dieser Annahme der >nicht strikten Konformität seiner Applikation bewusst ist. Gibt solche Leute im realen Leben? ;-) >Seit C99 gibt's ja nun auch keinerlei Grund mehr, für solche Fälle >den Typ “char” zu benutzen: wer eine kleine Ganzzahl mit exakt 8 Bits >benötigt, nehme halt “int8_t” oder “uint8_t”; “char” bleibt dann einfach >dem vorbehalten, wofür es ursprünglich mal konzipiert war: ein Zeichen >für die Ein-/Ausgabe aufzunehmen (einschließlich all der >str*-Funktionen). Für diesen Zweck ist es auch völlig belanglos, ob das >“char” nun >vorzeichenbehaftet ist oder nicht. Stimmt, das verstehe sogar ich. >Wer eine kleine Ganzzahl mit mindestens 8 Bits benötigt, hat die >Wahl zwischen “[u]int_fast8_t” oder “[u]int_least8_t”, je nachdem, ob >ihm die Geschwindigkeit oder das Platzsparen wichtiger ist. Damit kann >man relativ portabel ausdrücken, dass zwar 8 Bits genügen für den >Zweck, aber (uint_fast8_t) eben auf einem ARM der Datentyp auch ruhig >größer sein darf (weil es schneller geht so), oder aber (uint_least8_t) >eine Umgebung wie die genannten DSPs, die keinen 8-Bit-Typ besitzt, >eben dann einen größeren wählen darf. Da kann ich auch mitgehen.
Falk Brunner schrieb: > Gibt solche Leute im realen Leben? ;-) Max gewöhnt sich mit der Zeit dran, es richtig zu machen ... >>Seit C99 gibt's ja nun auch keinerlei Grund mehr, für solche Fälle >>den Typ “char” zu benutzen: ... wenn man das mal verinnerlicht hat. Oder vorher schon seine eigenen ähnlichen Typedefs dafür verwendete.
Dieser ganze Problemkreis ist IMHO in der Praxis gar nicht so sehr das Problem. Viel schwieriger ist es mit den Datentypen in Expressions klar zu kommen
1 | uint16_t value1 = 20000; |
2 | uint16_t value2 = 20000; |
3 | |
4 | uinat32_t result = value1 * value2; |
das ist jetzt natürlich ein triviales Beispiel, welches nur einen Punkt illustrieren soll: Auf einem System mit 16 Bit int geht die Berechnung schief. Auf einem System mit 32 Bit int ist das Ergebnis korrekt. Klar, kann man das mit Casts alles richtig stellen, aber praktisch gesehen würde das bedeuten, dass man viele Programmen mit Casts regelrecht spicken müsste. Was natürlich nicht passiert. D.h. auch mit dieser MISRA Regelung bleibt es nicht erspart, dass man die 'basic types' und ihr Verhalten bzw. die davon abhängigen C-Regeln kennen muss um auf der sicheren Seite zu sein.
1 | The basic type of char, int, short, long, float and double should not be used, but specific- |
2 | length equivalents should be typedef'd for the specific compiler, and these type names |
3 | used in the code. |
greift zu kurz, weil es nicht vollständig auf die Datentypen von Zwischenergebnissen wirkt. > >
1 | > The library functions atof, atoi and atol from library <stdlib.h> shall not be used. |
2 | > |
Selbes Problem. Da stecken implizite Annahmen über die basic datatypes drinnen.
Karl Heinz Buchegger schrieb: > Klar, kann man das mit Casts alles richtig stellen, aber praktisch > gesehen würde das bedeuten, dass man viele Programmen mit Casts > regelrecht spicken müsste. Wobei das nur bei Typen ab (u)int32_t relevant ist. In C kann man statt Casts auch das geringfügig elegantere INT32_C(literal) verwenden. Nur ist man dann in C++ geleimt, denn da fand es offenbar jemand angesichts von int32_t(literal) unnötig.
A. K. schrieb: > Nur ist man dann in C++ geleimt, In C++ haben Integer-Literale automatisch den "richtigen" Datentyp, und zwar den kleinsten ausreichenden, aber mindestens "int". In C++ möchte man halt nicht für jeden Datentyp noch ein Makro haben um dahin zu casten, sondern verwendet entweder explizite casts: static_cast<uint_least32_t>(eine16bitzahl) oder Konstruktion: uint_least32_t { eine16bitzahl }.
Kindergärtner schrieb: > In C++ haben Integer-Literale automatisch den "richtigen" Datentyp, und > zwar den kleinsten ausreichenden, aber mindestens "int". Das ist in C auch so. Zum Problem wird es bei Ausdrücken der Art 50000 * 2 die man schon gerne in 32 Bits rechnen will, aber nicht unbedingt in 64 Bits. Und das ist ohne irgendwelchen Zirkus drumrum nicht universell möglich. Der Vorteil der Makros wie INT32_C(n) gegenüber (int32_t)(n) oder int32_t(n) liegt in der grösseren Sicherheit, wenn hinter dem INT32_C nicht wiederum ein Cast steckt, sondern beispielsweise etwas wie #define INT32_C(n) n ## L Denn dann kriegt man bei fehlerhafter Verwendung zwar lustige Fehlermeldungen, riskiert aber nicht, hier versehentlich einen Pointer oder schlimmeres in int32_t zu casten. Ich mag Casts nicht so, diese Dinger sind mir etwas zu brachial. Ein Cast frisst alles was auch nur im entferntesten konvertierbar ist.
A. K. schrieb: > Ich mag Casts nicht so, diese Dinger sind mir etwas zu brachial. Ein > Cast frisst alles was auch nur im entferntesten konvertierbar ist. Oder wie ich es gerne ausdrücke: Ein Cast ist die C Schreibweise für "Halt die Klappe und mach es einfach"
Diese 'usual arithmetic conversions' ziehen aber noch viel schönere Kreise:
1 | int x = -1; |
2 | unsigned int y = 0; |
3 | |
4 | if (x < y) |
5 | puts("x < y"); |
6 | else if (x > y) |
7 | puts("x > y"); |
Ist alles nicht so einfach :-}
c2000 schrieb: > Mit nichten! Ein char kann auch z.B. 16 bit lang sein. Z.B. beim C2000 > ist ein char immer 16 bit! Char kann bei einigen DSP auch 24bit sein.
A. K. schrieb: > Ich könnte mir freilich vorstellen, dass man bei einer Architektur, > deren chars 16 Bits haben, mit (u)int8_t nicht glücklich wird. Das ist nicht weiter problematisch, das eigentlich Problem ist der doppelte Speicherverbrauch, auch bei simplen Strings.
A. K. schrieb: > die man schon gerne in 32 Bits rechnen will, aber nicht unbedingt in 64 > Bits. Und das ist ohne irgendwelchen Zirkus drumrum nicht universell > möglich. Tjo, man muss sich halt vorher den Wertebereich überlegen und casten/konstrukten. Wird ggf etwas unübersichtlich... Gilt auch hier: Karl Heinz Buchegger schrieb: > Auf einem System mit 16 Bit int geht die Berechnung schief. Auf einem > System mit 32 Bit int ist das Ergebnis korrekt. Letzteres kann sein, muss aber nicht; hängt davon ab ob es eine 16bit-Multiplikations-Instruktion gibt und wie sich die CPU beim Überlauf verhält; ist undefiniertes Verhalten und plattform/Compiler-abhängig. A. K. schrieb: > riskiert aber nicht, hier versehentlich einen Pointer > oder schlimmeres in int32_t zu casten. In C, ja. In C++ kann man wie oben angemerkt static_cast<uint32_t>() oder uint32_t{} verwenden, was ebenfalls das Casten von Pointern o.ä. verweigert und außerdem keine lustigen Syntaxerrors produziert. A. K. schrieb: > Ein > Cast frisst alles was auch nur im entferntesten konvertierbar ist. Deswegen hat C++ hat die benannten Casts, wo man explizit angibt was dieser Cast machen soll, und wenn das so nicht geht gibts einen Compilerfehler.
Werner schrieb: > Das ist nicht weiter problematisch, Wenn man diesen Typ in übernommenem Quellcode an tausend Stellen stehen hat schon. Erst recht, wenn dann auch noch ein Protokoll existiert, dass 8-Bit Bytes voraussetzt. > das eigentlich Problem ist der > doppelte Speicherverbrauch, auch bei simplen Strings. Wenn man sowieso exotisch programmieren muss, weshalb dann nicht konsequent? Also mit 3 oder 4 Zeichen in einem 24 Bit Wort. ;-) Es hat auch schon Systeme gegeben, in denen platzsparenderweise 3 Zeichen in 16 Bits codiert wurden (Radix 50).
A. K. schrieb: > Es hat auch schon Systeme gegeben, in denen platzsparenderweise 3 > Zeichen in 16 Bits codiert wurden (Radix 50). Ja, kenn ich auch noch. PDP-11-Zeiten lassen grüßen. Neulich habe ich eine Beschreibung gelesen, bei der jemand sowas in der Jetztzeit wiedererfunden hat. Natürlich nicht etwas dasselbe, was DEC seinerzeit als Radix-50 benutzt hat, das wäre wohl zu einfach gewesen. :/ Allerdings muss man sagen, dass auf diesen Systemen R50 nicht den Typ "char" hatte.
Jörg Wunsch schrieb: > Natürlich nicht etwas dasselbe, was DEC seinerzeit als Radix-50 Ausserdem hätte heute niemand mehr verstanden, wieso das Radix-50 heisst, wo es doch 40 Zeichen codiert. ;-)
Werner schrieb: > Char kann bei einigen DSP auch 24bit sein. Nein. Wolltest du nicht künftig einen Thread erst lesen, bevor du kommentierst?
Stefan Rand schrieb: >> Char kann bei einigen DSP auch 24bit sein. > > Nein. Mir ist zwar kein Beispiel bekannt, aber so ein definitives "Nein" würde ich da nicht hinschreiben. Selbstverständlich kann es das sein, vom C-Standard her wäre das völlig in Ordnung.
Angehängte Dateien:
-

sizes.png
7,1 KB
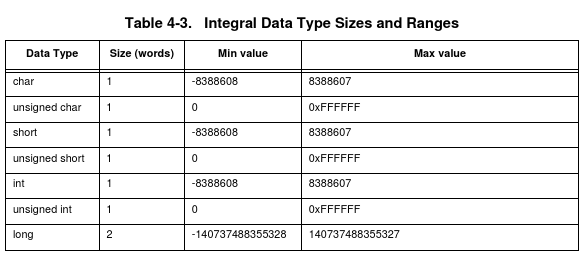
Jörg Wunsch schrieb: > Mir ist zwar kein Beispiel bekannt, Der 56k von Motorola wäre so ein Beispiel. Im Anhang ein Ausschnitt dem "Motorola DSP56000 Family Optimizing C Compiler User's Manual".
Jörg Wunsch schrieb: > Mir ist zwar kein Beispiel bekannt, aber so ein definitives "Nein" > würde ich da nicht hinschreiben. Selbstverständlich kann es das > sein, vom C-Standard her wäre das völlig in Ordnung. Stimmt, ich habe nicht richtig gelesen.
Stefan Rand schrieb: > Werner schrieb: >> Char kann bei einigen DSP auch 24bit sein. > > Nein. > > Wolltest du nicht künftig einen Thread erst lesen, bevor du > kommentierst? Nein, aber du bist jetzt etwas schlauer ... Beitrag "Re: Fragen zu MISRA"
Karl Heinz Buchegger schrieb:1 | > The basic type of char, int, short, long, float and double should not be |
2 | > used, but specific- |
3 | > length equivalents should be typedef'd for the specific compiler, and |
4 | > these type names |
5 | > used in the code. |
> greift zu kurz, weil es nicht vollständig auf die Datentypen von > Zwischenergebnissen wirkt. ACK, sicher greift das zu kurz. Aber MISRA kann ja nicht die Integer-Promotion-Regeln neu definieren. Oder es müsste fordern, daß Programme so zu schreiben sind, dass sie - So geschrieben sind, als sei int nur 16 Bits groß - In einer Cast-Orgie ausarten In der Praxis beobachte ich die 2te alternative. Der Code ist gespickt mit Makros, die zu den eigentlichen Operationen expandieren und fleissigst Casts einfügen. Das führt dann zu Code mit Zeilen, die mehrere hundert Zeichen lang sind und zu 90% aus Casts bestehen. Hört sich übel an, ist aber so — zumindest für den Code von Kunden, den ich hin und wieder mal zu Gesicht bekomme. Falk Brunner schrieb: > @ Jörg Wunsch (dl8dtl) (Moderator) Benutzerseite > >>> Welcher (C)-Programmierer geht denn NICHT davon aus, dass char 8 Bit >>> hat? > >>Jemand, der den Standard ernst nimmt und sich bei dieser Annahme der >>nicht strikten Konformität seiner Applikation bewusst ist. > > Gibt solche Leute im realen Leben? ;-) Zumindest unter den zig (offiziellen) Architekturen, die GCC unterstützt, gibt's m.W. keine einzige, die für BITS_PER_UNIT einen anderen Wert als 8 verwendet, also Bytes mit 8 Bits. Hin und wieder gibt's Fragen in den Mailing-Listen bezüglich BITS_PER_UNIT > 8 für irgendwelche Sonderlocken gedrechselten, hausbackenen Architekturen. Unterstützung dafür gibt's aber nicht...
> ACK, sicher greift das zu kurz. Aber MISRA kann ja nicht die > Integer-Promotion-Regeln neu definieren. Oder es müsste fordern, daß > Programme so zu schreiben sind, dass sie > > - So geschrieben sind, als sei int nur 16 Bits groß > > - In einer Cast-Orgie ausarten > > In der Praxis beobachte ich die 2te alternative. Der Code ist gespickt > mit Makros, die zu den eigentlichen Operationen expandieren und > fleissigst Casts einfügen. > > Das führt dann zu Code mit Zeilen, die mehrere hundert Zeichen lang sind > und zu 90% aus Casts bestehen. Misra fordert u.a., dass der Programmierer zeigt, was vor sich geht. Das bedeutet, dass implizite Typwandlungen (z.B. durch die Integer Promotion Regeln verursacht) verpönt sind. Hier kann nicht geprüft werden, ob der Programmierer dieses Verhalten bedacht hat. Daher muss jede Typwandlung mit einem cast angezeigt werden. > Zumindest unter den zig (offiziellen) Architekturen, die GCC > unterstützt, gibt's m.W. keine einzige, die für BITS_PER_UNIT einen > anderen Wert als 8 verwendet, also Bytes mit 8 Bits. Die Diskussion macht nur dann Sinn, wenn Du Code schreiben willst, welcher auf verschiedenen Umgebungen läuft. Sei es, weil dein Code über Jahre genutzt wird und sich die Welt weiterdreht. Oder sei es, weil du verschiedene Projekte für verschiedene Kunden mit unterschiedlichen Umgebungen bearbeitest.
A. K. schrieb: > Zum Problem wird es bei Ausdrücken der Art > 50000 * 2 > die man schon gerne in 32 Bits rechnen will, aber nicht unbedingt in 64 > Bits. Streng genommen möchte man sie nicht zwingend in 32 Bit, aber in einem Datentyp rechnen, der groß genug ist, um 100000 aufzunehmen. Man bräuchte also eigentich die Möglichkeit, einen gewünschten Minimal-Wertebereich anzugeben. In C++ könnte man sich mit Templates dafür sogar was stricken. Jörg Wunsch schrieb: > A. K. schrieb: >> Es hat auch schon Systeme gegeben, in denen platzsparenderweise 3 >> Zeichen in 16 Bits codiert wurden (Radix 50). > > Ja, kenn ich auch noch. PDP-11-Zeiten lassen grüßen. Wenn man bei modernen Systemen nach ulkigend Datentypen sucht, wird man bei den Grafikkarten fündig. Da gibt's sogar einen Datentyp, der in 32 Bit drei Gleitkommazahlen mit gemeinsamem Exponent speichert.
Steffen Rose schrieb: > Misra fordert u.a., dass der Programmierer zeigt, was vor sich geht. > Das bedeutet, dass implizite Typwandlungen (z.B. durch die Integer > Promotion Regeln verursacht) verpönt sind. Hier kann nicht geprüft > werden, ob der Programmierer dieses Verhalten bedacht hat. Daher muss > jede Typwandlung mit einem cast angezeigt werden. Was natürlich voraussetzt, dass der Programmierer damit umgehen kann. Mit einem Cast hat man auch gerne schnell einen Überlauf plattgemacht o.ä.
Sven P. schrieb: > Was natürlich voraussetzt, dass der Programmierer damit umgehen kann. > Mit einem Cast hat man auch gerne schnell einen Überlauf plattgemacht > o.ä. Fehler können in beiden Fällen gemacht werden. Klar. Wobei der Misra Checker schon davor warnt, wenn man "runter-casted". Der Vorteil von expliziten cast's gegenüber impliziten cast's ist hauptsächlich, dass ein zweiter Mensch formaler prüfen kann. Er muss nicht ständig über die Datentypen grübeln. Ich denke, viele hier werden Schwierigkeiten haben, die Integer Promotion (heißt es nicht Integral Promotion?) Regeln zu erläutern. Bei expliziten cast's ist das einfacher, solange man natürlich auf gleiche Typen cast'ed. Steffen
Also üblicherweise benutzt man ein statische Analyse Tool, dass MISRA C kann. Der wird einen warnen, wenn das Risiko eines Überlaufs besteht.
Üblicherweise kombiniert man mehrere Methoden. Und dabei sollte eine Codedurchsicht nicht fehlen.
Für die Prüfung von C-code gibt es einige Stellen, die das übernehmen und dokumentieren. Die arbeiten zeilenweise.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.