Ich habe hier eine Structure:
Was würde mir hier sizeof(IO_VAL_DIGITAL) geben?
(ja mir ist klar das hier noch eine dekleration der eigentlichen
Variable fehlt)
1
typedefstruct__attribute__((__packed__))
2
{
3
UINT8block_time;// block time counter
4
UINT32value;// current value
5
union
6
{
7
struct
8
{
9
UINT8bEventOnMin:1;
10
UINT8bEventOnMax:1;
11
UINT8bEventOnValue:1;
12
UINT8bReserved:5;
13
}bits;
14
UINT8val;
15
}flags;
16
17
}IO_VAL_DIGITAL;
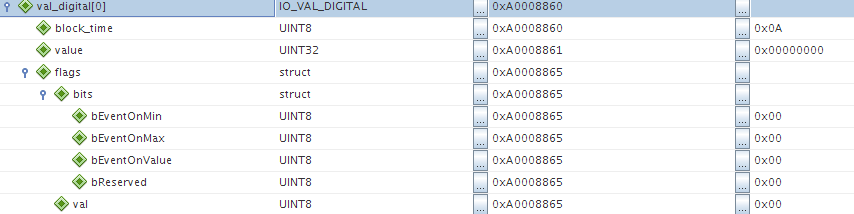
Sizeof gibt einmal 6 und einmal 12 wieder je nachdem obs packed ist oder
nicht. Nur wo kommen hier die weiteren 6 Bytes her und vorallem warum?
David Mueller schrieb:> Sizeof gibt einmal 6 und einmal 12 wieder je nachdem obs packed ist oder> nicht. Nur wo kommen hier die weiteren 6 Bytes her und vorallem warum?
Wahrscheinlich weil dein Compiler zwischen den UINT8 und den UINT32,
sowie nach dem letzten UINT8 ein paar Bytes reinpackt, um die jeweiligen
Strukturmember auf 4 Byte Grenzen zu bringen, damit der Zugriff auf die
Member einfacher (d.h. ohne großes Bytegeschupse und ausmaskieren)
erfolgen kann.
Details hängen von deiner CPU und deren Instruktionen ab, mit denen der
Compiler arbeiten kann.
Edit: Im not_packed PNG sieht man es an den Adressen ganz deutlich, dass
der Compiler ein paar padding Bytes eingeschoben hat, um irgendwelche
Alignment Anforderungen zu erfüllen.
David Mueller schrieb:> Nur wo kommen hier die weiteren 6 Bytes her und vorallem warum?
=> “padding”, “alignment”
Erforderlich für einen schnelleren (oder auf manchen Architekturen
einzig so legalen) Zugriff auf Mitglieder, deren Typ aus mehr als
einem Byte besteht.
Kannst du in deinem Beispiel übrigens vermeiden (bzw. reduzieren
auf Füllbytes nur am Ende der Struktur), wenn du “value” nach vorn
ziehst.
Gysi schrieb:>> deren Typ aus mehr als einem Byte besteht.>> Das macht irgendwie keinen Sinn.
Warum nicht?
Ein Byte ist die kleinste adressierbare Einheit in einem System
(heutzutage meist aus 8 Bit bestehend).
Mehrbyte-Datentypen bilden das ab, wofür das eine Byte nicht reicht.
Jörg Wunsch schrieb:> Erforderlich für einen schnelleren (oder auf manchen Architekturen> einzig so legalen) Zugriff auf Mitglieder, deren Typ aus mehr als> einem Byte besteht.
Weshalb muss ein 32-bit-Wort auf einem 32-bit System gepadded werden?
Gysi schrieb:> Jörg Wunsch schrieb:>> Erforderlich für einen schnelleren (oder auf manchen Architekturen>> einzig so legalen) Zugriff auf Mitglieder, deren Typ aus mehr als>> einem Byte besteht.>> Weshalb muss ein 32-bit-Wort auf einem 32-bit System gepadded werden?
Weil die CPU Architekten vorgesehen haben, dass die CPU immer nur in
32-Bit Einheiten auf den Speicher zugreifen kann und daher immer 32 Bit
in einem Rutsch einliest oder schreibt. Das Vereinfacht das Design.
Zum Beispiel.
Gysi schrieb:> Jörg Wunsch schrieb:>> Erforderlich für einen schnelleren (oder auf manchen Architekturen>> einzig so legalen) Zugriff auf Mitglieder, deren Typ aus mehr als>> einem Byte besteht.>> Weshalb muss ein 32-bit-Wort auf einem 32-bit System gepadded werden?
Tschuldigung für mein vorhergehendes Posting.
Das 32 Bit Wort an sich muss überhaupt nicht gepadded werden, wenn 4
Byte Alignment gefordert ist. Aber zwischen dem vorhergehenden 1 Byte
und dem 32-Bit (4 Byte) Wort werden 3 Bytes eingeschoben, damit das 32
Bit Wort wieder auf einer Adresse zu liegen kommt, an der die CPU mit
einem einzigen Zugriff lesen oder schreiben kann.
Es ist nicht ungewöhnlich, dass derartige CPU zb von Adresse 1 gar nicht
lesen können. Der Lesezugriff geht auf Adresse 0 und anstatt lediglich 1
Byte, werden gleich die nächsten 4 Bytes in einem Rutsch (weil es ja ein
32 Bit System ist) geladen. d.h. die Ladeoperation kann von (Byte-)
Adresse 0, von Adresse 4, von Adresse 8, von Adresse 12, etc. etc. lesen
(bzw. schreiben). Bei einer deratigen Operaion wandern in einem Aufwasch
4 Bytes über den 32 Bit Datenbus in das 32 Bit Register. Um ein
einzelnes Bytes von Adresse 1 zu lesen, müssen dann zb die 4 Bytes von
Adresse 0-3 gelesen werdem und der nicht gebrauchte Teil wird zb mittels
einer and-Operation ausmaskiert und das interessierende Byte wird
zurechtgeschoben. Jetzt stell dir mal vor, welchen Aufwand man treiben
muss, wenn die 32 Bit auf die Speicherbytes 2, 3 und 4 verteilt sind.
Und dann setzt diesen Aufwand in Relation dazu, wenn die 32 Bit schon so
im Speicher liegen, dass sie mit einer einzigen Operation geladen werden
können.
Da hast du deine Motivation fürs Padding.
Somit habe ich die Wahl,
entweder die Bytes schön Anordnen (packen) so das ich
später die struktur wirklich am stück habe
oder
den compiler das mit zusätzlichen bytes auffüllen lassen,
dafür aber schnelleren Zugriff zu haben.
Korrekt?
David Mueller schrieb:> Korrekt?
Korrekt.
Es gibt einen Begriff dafür in der Informatik, der dir noch oft begegnen
wird:
Time for Space
Man erkauft sich Laufzeit, indem man Speicher dafür opfert. Man erkauft
sich Speicher, in dem man Laufzeit dafür opfert.
Ja, das packed ist für dich wichtig wenn du zb die Struktur als
"Schablone" über einen Speicherbereich gelegt wird, dafür muss das
Alignment passen.
Wenn du nur auf die einzelnen Member der Struktur zugreifst kann dir das
egal sein.
Ansich kanns mir ja Wurst sein, nur ich brauche die Struktur möglichst
knapp, da ich später die ganze Struktur auf ein Flash Speicher schreibe.
so in der Art write_structure(&IO_VAL_DIGITAL);
Ist natürlich auch hier wieder die Frage ob man sich das gönnt da mehr
Speicher zu verschwenden.
foobar schrieb:> Wenn du nur auf die einzelnen Member der Struktur zugreifst kann dir das> egal sein.
Vorausgesetzt, die jeweilige Architektur unterstützt überhaupt einen
unaligned access. Bei einem ARM zum Bleistift kann man mit der
gepackten Struktur im Speicher einfach gar nicht arbeiten.
David Mueller schrieb:> Somit habe ich die Wahl,
Naja, wie ich oben schon andeutete, kann man als Kompromiss zumindest
die Anordnung im Speicher noch verbessern. Die Regel lautet dabei:
die Strukturelemente, die die größten Alignment-Anforderungen haben
(auf einem ARM wären das die mit 64 Bit, auf einem x86-PC wären das
alle mit 32 Bit und mehr) kommen zuerst, von da immer kleiner werdend.
Der Unterschied ist, deine derzeitige Anordnung bringt:
1
0 1 2 3 4 5 6 7 8 9 10 11 12
2
block [padding] v__a__l__u__e flags [ padding ]
3
time
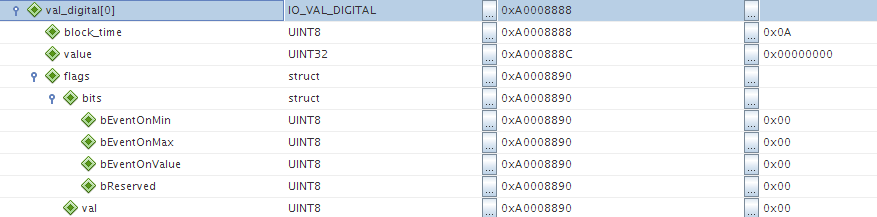
Wenn du value nach vorn nimmst, bekommst du:
1
0 1 2 3 4 5 6 7
2
v__a__l__u__e block fla [pad-
3
time gs ding]
d. h. du verbrauchst nur noch 2/3 des Speichers mit der ungepackten
Struktur.
Vielen Dank für die ganzen Antworten und auch das schicke Beispiel von
Jörg,
ich habe nun so wie beschrieben VALUE vorgezogen und tatsache selbst
ungepackt sagt sizeof nun 8. was also 2x32Bit entspricht.
jetzt ist die Sache klar :-)
Damit erübrigt sich ansich auch die Frage ob eine structure immer gleich
angeordnet ist. Was natürlich wichtig ist beim wieder lesen vom Flash.
Jörg Wunsch schrieb:> Bei einem ARM zum Bleistift kann man mit der> gepackten Struktur im Speicher einfach gar nicht arbeiten.
Das ist falsch, ab ARMv7 können die "normalen" 8,16,32-bit
Speicherzugriffsoperationen (LDR{B,H,}, STR{B,H,}) auch auf unaligned
Speicher zugreifen, die CPU übersetzt die Zugriffe ggf. in
aufeinanderfolgende aligned 32bit-Zugriffe und erledigt die
Bitshift/mask-iererei automatisch. Die Multi-Word-Zugriffe (STM, LDM,
STD, LDD etc) benötigen allerdings immer noch 32bit-Alignment. Das
Problem ist nun bei unaligned Zugriffen dem Compiler beizubringen auf
jeden Fall erstere Art von Instruktion zu generieren...
Dr. Sommer schrieb:> Das ist falsch, ab ARMv7 können die "normalen" 8,16,32-bit> Speicherzugriffsoperationen (LDR{B,H,}, STR{B,H,}) auch auf unaligned> Speicher zugreifen
OK, dann ist das bei mir im Kopf aus der Zeit noch so hängengeblieben,
da die betreffenden Kollegen mit älteren ARM-Architekturen unterwegs
waren.
Jörg Wunsch schrieb:> Dr. Sommer schrieb:>> Das ist falsch, ab ARMv7 können die "normalen" 8,16,32-bit>> Speicherzugriffsoperationen (LDR{B,H,}, STR{B,H,}) auch auf unaligned>> Speicher zugreifen>> OK, dann ist das bei mir im Kopf aus der Zeit noch so hängengeblieben,> da die betreffenden Kollegen mit älteren ARM-Architekturen unterwegs> waren.
Das Feature muss aber explizit aktiviert werden und ist ab ARMv6
zuschaltbar. Allerdings wirkt sich das wie auch auf x86 negativ auf die
Performance aus.
Matthias
Besonders interessant ist die Sache mit dem Alignment bei TCP/IP über
Ethernet. Ein Ethernet-Header besitzt eine Länge von 14 Byte. Daran
schließen sich zwei IP-Adressfelder mit jeweils 32 Bit an. Wenn man nun
eine Speicherverwaltung für Netzwerkpuffer verwendet, die jeweils an
Wortadressen beginnen, gibt es das Problem, dass sich die
IP-Adressfelder nicht mit Einzelinstruktionen auslesen lassen.
Aus diesem Grunde hatte ich vor langer Zeit einmal die
Speicherverwaltung für einen Netzwerkstack komplett umschreiben müssen.
Der Hersteller behauptete zwar, den Stack auch auf ARM getestet zu
haben, aber es gab doch zu viele Stellen im Code, in denen das Alignment
überhaupt nicht passte. Teils waren sogar Funktionen wie htons()
fehlerhaft implementiert.
Und für den Stack hatten wir damals rund 30.000,- EUR bezahlt. :-/
Als wir den "Hersteller" mit den genannten Problemen konfrontierten, gab
er ganz lapidar zu, von dem Stack auch keine Ahnung zu haben, sondern
ihn von irgendwo zugekauft zu haben. Die Leute hatten ihn aber auch
nicht vollständig selbst entwickelt, sondern auch nur zusammengeklaut,
denn einige Quellcodeteile stammten vom ehemals sehr guten
NCSA-Telnet-Stack für MS-DOS.
Μαtthias W. schrieb:> Das Feature muss aber explizit aktiviert werden
Ob es standardmäßig aktiv ist ist implementation defined - auf den STM32
scheint das der Fall zu sein.
> und ist ab ARMv6 zuschaltbar.
Ok, hätte "mindestens ARMv7" schreiben sollen ;)
> Allerdings wirkt sich das wie auch auf x86 negativ auf die> Performance aus.
Klar, es werden mehr Buszugriffe benötigt. Es ist allerdings immer noch
effizienter als die Bitmaskiererei "manuell" im Programm zu machen...
Dr. Sommer schrieb:> Ob es standardmäßig aktiv ist ist implementation defined - auf den STM32> scheint das der Fall zu sein.
Bis auf die F0 Serie, denn der Cortex M0 Core ist kein ARMv7 und kann es
nicht.