Hallo Narf,
kann es sein, dass du die Variable "level" nicht hochzählst.
Im Original wird sie im Funktionsaufruf bedient, bei dir meines
Erachtens nicht.
> Irgendwo muss ich einen kapitalen Fehler gemacht haben
Es sind zwar ein paar kleinere Probleme erkennbar, aber so richtig
kapital sehe ich nichts.
Ein Problemkreis ist der Aufruf einer Funktion aus einer ISR.
Das ist nicht gut, weil du dadurch den Compiler zwingst, in der ISR erst
mal alle Register zu sichern und danach wieder herzustellen. Das sind
schon einige Taktzyklen, erklärt aber noch nicht die Millisekunde.
EIne Operation 1<<z willst du nicht haben, weil sie der Compiler in eine
SChleife auflösen muss. Da muss man noch was anderes finden.
Auch ist die Ausgabe auf SPI noch suboptimial. Ein wesentlicher Punkt
bei SPI ist es ja, dass SPI alleine läuft. D.h. während das Byte
rausgetaktet wird, kann die CPU bereits was anderes machen. Wenn du aber
nach dem STart des raustaktens durch Zuweisung an SPDR auf die
Fertigstellung dieses Raustaktens wartest, dann verschenkst du diese
Möglichkeit.
Summa-summarum sind das noch ein paar Ansatzpunkte. Sie erklären aber
IMHO nicht, warum der ganze Vorgang sich im Millisekundenbereich
abspielt.
Den Optimizer hast du auf -Os stehen?
Rudolph schrieb:> refresh_cube(); wird sowohl aus der ISR als auch von der Hauptschleife> aus aufgerufen, das dürfte sich ein wenig in die quere kommen.
Habs zu spät gesehen: Der Timer ist noch gar nicht aktiv. Im Moment
sieht es so aus, als ob er nur die Laufzeit der Funktion feststellen
will.
Herbert schrieb:> Hallo Narf,>> kann es sein, dass du die Variable "level" nicht hochzählst.> Im Original wird sie im Funktionsaufruf bedient, bei dir meines> Erachtens nicht.
Danke, das ist in der Tat falsch. Auf der Suche nach dem Fehler habe ich
die Zeile wohl versehentlich raus genommen. Allerdings ändert dies
nichts am eigentlichen Zeitproblem da "level" nur beschreibt welche
Daten rausgeschickt werden sollen.
Karl Heinz schrieb:> EIne Operation 1<<z willst du nicht haben, weil sie der Compiler in eine> SChleife auflösen muss. Da muss man noch was anderes finden.
Das sollte eigentlich das simple Bitverschiebung sein. Einfach den Pin z
des Ports setzen.
> Auch ist die Ausgabe auf SPI noch suboptimial. Ein wesentlicher Punkt> bei SPI ist es ja, dass SPI alleine läuft. D.h. während das Byte> rausgetaktet wird, kann die CPU bereits was anderes machen. Wenn du aber> nach dem STart des raustaktens durch Zuweisung an SPDR auf die> Fertigstellung dieses Raustaktens wartest, dann verschenkst du diese> Möglichkeit.
Darüber habe ich mir auch Gedanken gemacht. Um den Prozessor nicht
ständig auf die SPI warten zu lassen bleibt in meinen Augen nur wieder
die Interrupt-Funktion. Ein Interrupt alle 16 Clock-Zyklen würde aber
wohl kaum möglich sein.
> Summa-summarum sind das noch ein paar Ansatzpunkte. Sie erklären aber> IMHO nicht, warum der ganze Vorgang sich im Millisekundenbereich> abspielt.>>> Den Optimizer hast du auf -Os stehen?
Gute Frage. Ich überprüfe dies sobald ich zu Hause bin.
Karl Heinz schrieb:> i muss kein int sein. Du zwingst den µC hier zu 16 Bit Arithmetik, die> du gar nicht brauchst. Ein uint8_t tuts auch.
Gut erkannt. Da hab' ich wohl in alte Schemeta verfallen ;)
Sind die Arduiono-Standard-Funktionen irgendwo in ihren
C-Implementierung einsehbar? Mich würde interessieren wie SPI.transfer()
intern umgesetzt ist.
Danke euch allen für eure Hinweise, sobald ich zu Hause bin setze ich
sie um und messe erneut.
Grüße
Narf
Karl Heinz schrieb:> Habs zu spät gesehen: Der Timer ist noch gar nicht aktiv. Im Moment> sieht es so aus, als ob er nur die Laufzeit der Funktion feststellen> will.
Exakt ;)
Simon T. schrieb:> Karl Heinz schrieb:>> i muss kein int sein. Du zwingst den µC hier zu 16 Bit Arithmetik, die>> du gar nicht brauchst. Ein uint8_t tuts auch.>> Gut erkannt. Da hab' ich wohl in alte Schemeta verfallen ;)
Welche Compilerversion benutzt Du denn?
Integer Promotion wäre auch mein Tip gewesen. Aber der avr-gcc 4.1.8
optimiert alles gnadenlos weg. Die (noch) nicht benutzte Variable level
sowieso, aber auch i in der for-Schleife. Ich komme auf ca. 800 Takte
(oder weniger) pro Durchlauf, also ca. 100us.
Momentan sehen die for-Schleifen so aus:
1
for(int i=level; i < level+8; i++) {
2
SPDR = red0[i];
3
while(!(SPSR & (1<<SPIF)));
4
}
5
Ergebnis:
6
.L9:
7
ldi r30,lo8(red0)
8
ldi r31,hi8(red0)
9
.L15:
10
ld r24,Z+
11
out 0x2e,r24
12
.L13:
13
in __tmp_reg__,0x2d
14
sbrs __tmp_reg__,7
15
rjmp .L13
16
ldi r24,hi8(red0+8)
17
cpi r30,lo8(red0+8)
18
cpc r31,r24
19
brne .L15
3 * (2 Takte Pointer laden + 8 * (3 T Wert laden und out + 16 T
Schieberegister + 5 T Schleifenende-Test)))
= Ungefähr ca. 600 Takte.
Du könntest "warten auf SPDR leer" und Ausgabe vertauschen, um die
Wartezeit sinnvoll zu nutzen:
1
for(int i=level; i < level+8; i++) {
2
while(!(SPSR & (1<<SPIF)));
3
SPDR = red0[i];
4
}
5
Ergebnis:
6
.L9:
7
ldi r30,lo8(red0)
8
ldi r31,hi8(red0)
9
.L13:
10
in __tmp_reg__,0x2d
11
sbrs __tmp_reg__,7
12
rjmp .L13
13
ld r24,Z+
14
out 0x2e,r24
15
ldi r24,hi8(red0+8)
16
cpi r30,lo8(red0+8)
17
cpc r31,r24
18
brne .L13
Noch besser wirds so:
1
... uint8_t c;
2
...
3
for(int i=level; i < level+8; i++) {
4
c = red0[i];
5
while(!(SPSR & (1<<SPIF)));
6
SPDR = c;
7
}
8
Ergebnis:
9
.L9:
10
ldi r30,lo8(red0)
11
ldi r31,hi8(red0)
12
.L15:
13
ld r24,Z+
14
.L13:
15
in __tmp_reg__,0x2d
16
sbrs __tmp_reg__,7
17
rjmp .L13
18
out 0x2e,r24
19
ldi r24,hi8(red0+8)
20
cpi r30,lo8(red0+8)
21
cpc r31,r24
22
brne .L15
Unmittelbar nachdem das SPI-Schieberegister frei wird, wird es auch neu
geladen. In den 16 Takten, die das SR beschäftigt ist, wird der nächste
Wert aus dem RAM geholt, und auf Schleifenende getestet, und es bleiben
sogar noch ein paar Takte Luft.
@ Simon T. (narfinus)
>Das sollte eigentlich das simple Bitverschiebung sein. Einfach den Pin z>des Ports setzen.
macht man auf dem AVR besser so.
http://www.mikrocontroller.net/articles/AVR-GCC-Codeoptimierung#Schiebeoperationen>Darüber habe ich mir auch Gedanken gemacht. Um den Prozessor nicht>ständig auf die SPI warten zu lassen bleibt in meinen Augen nur wieder>die Interrupt-Funktion.
Nö. Man muss nur die Dinge in der richtigen Reihenfolge tun.
1
for(i=0;i<24;i++){
2
tmp=gs_data[i];
3
while(!(SPSR&(1<<SPIF)));
4
SPDR=tmp;
5
}
6
while(!(SPSR&(1<<SPIF)));
Damit wird nach dem Schreiben der Daten ins SPI die CPU damit
beschäftigt, neue Daten aus dem RAM in ein Register zu lesen. Damit
laufen SPI und CPU paralell und die CPU muss nur noch minimal warten,
wenn die Adressberechnung und das Daten lesen weniger als 16 Takte
gebraucht haben.
>Ein Interrupt alle 16 Clock-Zyklen würde aber>wohl kaum möglich sein.
Das ist vollkommen unsinnig.
>> Den Optimizer hast du auf -Os stehen?>Gute Frage. Ich überprüfe dies sobald ich zu Hause bin.
DAS ist entscheidend für _delay_us();
http://www.mikrocontroller.net/articles/AVR-GCC-Tutorial#Warteschleifen_.28delay.h.29
Okey, das ist mir jetzt peinlich...
Auf meinem alten Oszi war der Punkt vor der Millisekunden-Anzeige
verblasst. Ich habe 0.1ms gemssen und 1ms abgelesen ...
Nicht desto trotz bin ich euch für die ganzen Anregungen unglaublich
dankbar. Der Hinweis, die Wartezeit mit dem Laden des nächsten Wertes zu
nutzen war Gold wert. Damit habe ich nochmal 40us gewonnen und bin nun
mit 75us dem theoreischen Optimum von 48us deutlich näher.
Der überarbeitete Code befindet sich im Anhang. Falls ihr noch
Vorschläge hat, immer her damit ;)
Fürs Protokoll:
Compilerversion: 3.4.2 gcc
Optimization Level: -02 (ursprünglich 01, ändert aber nichts)
@ Simon T. (narfinus)
>Der überarbeitete Code befindet sich im Anhang. Falls ihr noch>Vorschläge hat, immer her damit ;)
Hier fehlt ein Warten auf das Ende der Übertragung. Du setzt das Chip
Select mitten drin!
1
while(!(SPSR&(1<<SPIF)));
2
SPDR=1<<anode[z];
3
while(!(SPSR&(1<<SPIF)));// das fehlte!!!
4
5
//all drivers stored their data. Generate pulse for sending data to the driver-outputs
6
SPI_PORT|=(1<<SS);
7
_delay_us(5);// brauchst du nicht, die ICs sind deutlich schneller als du denkst
Simon T. schrieb:> Compilerversion: 3.4.2 gcc
Ist das die Ausgabe von avr-gcc -v
?
> Optimization Level: -02 (ursprünglich 01, ändert aber nichts)
-Os ist ein Versuch wert. Kann durchaus schneller werden.
Falk Brunner schrieb:> Hier fehlt ein Warten auf das Ende der Übertragung. Du setzt das Chip> Select mitten drin!
Autsch. So kann das nix werden. Danke für den Hinweis!
>> Compilerversion: 3.4.2 gcc> Ist das die Ausgabe von *avr-gcc -v*
Ich bin mir nicht ganz sicher was du meinst: Hier der Build-Aufruf mit
allen Parametern. Hoffe das beantwortet deine Frage.
"E:\Atmel Toolchain\AVR8
GCC\Native\3.4.2.939\avr8-gnu-toolchain\bin\avr-gcc.exe"
-funsigned-char -funsigned-bitfields -DDEBUG -O2 -ffunction-sections
-fdata-sections -fpack-struct -fshort-enums -g2 -Wall -mmcu=atmega644 -c
-std=gnu99 -MD -MP -MF "LED-Controller.d" -MT"LED-Controller.d"
-MT"LED-Controller.o" -o "LED-Controller.o" ".././LED-Controller.c"
> -Os ist ein Versuch wert. Kann durchaus schneller werden.
Ebenfalls getestet. Kein messbarer Unterschied zu sehen.
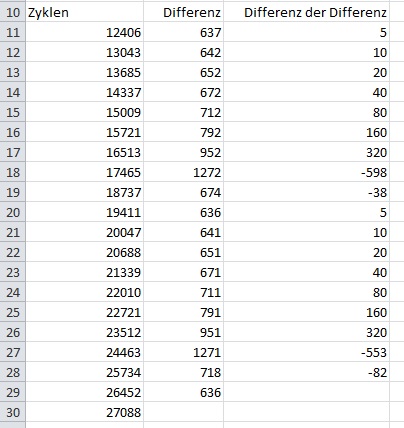
Ich habe gerade die refreshCube()-Funktion im AVR-Simulator nochmal
durchlaufen lassen und festgestellt dass sich ihre Durchlaufzeit nicht
konstant ist sondern sich 8 Aufrufe lang verdoppelt und dann wieder beim
geringsten Wert anfängt (siehe Anhang). Momentan bin ich mir nicht ganz
sicher ob es ein Bug oder Feature daher schlafe ich erstmal darüber.
Danke nochmals für das tolle Feedback!
Simon T. schrieb:
uint8_t anode[] = {0x01,0x02,0x04,0x08,0x10,0x20,0x40,0x80}; //Current
anode
[...]
SPDR = 1<<anode[z];
Das ist doch ein ziemlicher Unsinn. Wennschon Lookuptabelle mit
vorberechneten Werten, dann muß die Operation, die vorberechnet wurde
natürlich verschwinden, sonst kommt Müll raus, nämlich in 5/8 der Fälle
schlicht eine 0. Also richtig:
SPDR = anode[z];
Aber mal abgesehen davon, wäre es viel sinnvoller, z einfach statt mit
++ mit << zu behandeln. Die Operation kostet nur einen einzigen Takt,
Index-Increment und Table-Lookup sind sehr viel teurer. Die acht Byte
RAM für die Tabelle werden obendrein noch eingespart.
Also:
static uint8_t z = 0x01;
bleibt so
[...]
und dann statt
SPDR = 1<<anode[z];
[...]
if(z<8)
{
Z++;
}
else
{
z=0;
level =level + 8;
}
einfach
SPDR = z;
z = z << 1;
if (z == 0)
{
z = 1;
}
oder natürlich sehr viel eleganter in einer richtigen Sprache:
lds zreg,z ; 2
out SPDR,zreg ; 1
lsl zreg ; 1
brne done ; 1 2
ldi zreg,1 ; 1
done:
sts z,zreg ; 2
;--
; 8
Wo man sehr schön sehen kann, daß das ganze Z-Handling in konstant 8
Takten zu erledigen ist. Noch schneller geht es, wenn ein Register frei
ist, um z dauerhaft zu halten, dann halbiert sich das nochmal, weil die
teueren Lade- und Speicheroperationen wegfallen.
Übrigens kann der ganze Code noch etliche algorithmische Verbesserungen
vertragen, das ist alles ziemlich suboptimal. Wenn ich mich taktmäßig
nicht verzählt habe, ist es durchaus möglich, den SPI konstant so
schnell zu beschicken, wie er die Daten überhaupt entgegennehmen kann.
Allerdings: in C geht das entweder garnicht oder es kommt etwas sehr
unleserliches heraus, das nur noch rein formal C ist. Besser gleich in
Asm schreiben.
Wenn die Ausgabe schnell sein soll, dann schreib doch schon alles in der
richtigen Reihenfolge in ein Array.
Dann sparst Du Dir das ganze Pointer-Rumgerechne im Interrupt.
Und natürlich die UART im SPI-Mode, damit kommen die Bytes lückenlos
raus:
@ Karl Heinz (kbuchegg) (Moderator)
>>Besser gleich in Asm schreiben.> Compiler sind ja auch keine Trottel.
Was man von einigen missionarischen Forumsteilern nicht so leicht
behaupten kann . . . ;-)
Falk Brunner schrieb:>>>Besser gleich in Asm schreiben.>>> Compiler sind ja auch keine Trottel.>> Was man von einigen missionarischen Forumsteilern nicht so leicht> behaupten kann . . . ;-)
Tja, im Unterscheid zu eurem heißgeliebten und von euch zum Fast-Gott
hochstilisierten C-Compiler ist es mir möglich, in schlichtem Asm eine
Routine zu schreiben, die die SPI-Ausgabe bei diesem Problem durchgehend
mit Vmax beschicken kann und zwar so, daß der Code, der das tut, lesbar
bleibt.
Es geht dabei nicht um den offensichtlichen Bug der geposteten C-Routine
beim Z-Handling (den ich in C korrigiert habe), auch nicht nicht um
meinen Vorschlag für eine wesentlich effizienteres Handling der
Z-Geschichte insgesamt (die ich sogar in beiden Sprachen korrekt
vorgeschlagen habe), sondern um die ganze verschissene Routine
insgesamt, die vor allem WEGEN der systemimmanenten Nachteile von C so
erheblich suboptimal ist.
Das war nämlich der springende Punkt der Darstellung in Assembler. Die
Darstellung der Möglichkeit zum taktgenauen Timing. Das haben die Herren
Opponenten entweder garnicht begriffen oder bewußt verdrängt (letzteres
halte ich für sehr viel wahrscheinlicher, ich kenne meine Gegner).
Ich habe allerdings auch keine große Lust, mich von solchen
Realitätsverweigerern öffentlich herabwürdigen zu lassen.
Interessanterweise verstößt sogar der Herr Moderator damit gegen die
Nutzungsregeln des eigenen Forums. Und das sogar in verschärfter Form,
denn die Fakten stehen gegen ihn und ich bin ziemlich sicher: Er weiß
das nur zu genau.
Ich bin jedenfalls jederzeit bereit, eine ASM-Routine zu posten, die
wirklich das tut, was ich behaupte, also in Summe: alle 16 Takte das
nächste Byte per SPI entsprechend dem in C geposteten Algorithmus.
Einzige Bedingung:
Zuvor postet einer der Herren eine C-Routine, die das Gleiche zu leisten
vermag! Sie sollte natürlich noch lesbar und als C erkennbar sein und
sie muß natürlich portabel sein, denn das ist ja der so überaus wichtige
Grund, warum man so dringend unbedingt C verwenden sollte...
OK, ich mache es euch etwas einfacher bezüglich der Portabilität: Das
Zielsystem ist konstant, der Code muß sich einfach nur mit _mehr als
einem_ C-Compiler mit gleichem Ergebnis übersetzen lassen...
Nimmst du die Herausforderung an, Karl-Heinz? Oder du, Falk? Sagt jetzt
ja oder schweigt für immer!
@ c-hater (Gast)
>Tja, im Unterscheid zu eurem heißgeliebten und von euch zum Fast-Gott>hochstilisierten C-Compiler ist es mir möglich, in schlichtem Asm eine>Routine zu schreiben, die die SPI-Ausgabe bei diesem Problem durchgehend>mit Vmax beschicken kann und zwar so, daß der Code, der das tut, lesbar>bleibt.
Mann, bist DU GUT!!!!
C-Programmierer können das auch, sei es als Inline ASM oder einzelen
ASM-Funktion/Datei.
>insgesamt, die vor allem WEGEN der systemimmanenten Nachteile von C so>erheblich suboptimal ist.
Sie erfüllt ihre Funktion, sowohl logisch wie zeitlich.
-> Keine Notwedigkeit für Optimierungen (jenseits des sportlichen
Ehrgeizes)
>Das war nämlich der springende Punkt der Darstellung in Assembler. Die>Darstellung der Möglichkeit zum taktgenauen Timing.
Die keiner bestritten hat, die aber in den wenigsten Fällen, nicht mal
hier, benötigt wird. Selbst eine Videogenerierung geht heute in C!
Beitrag "ATmega8 erzeugt Video in C!"Beitrag "Video Erzeugung mit LPC213x in C"
Das kann selbst der AVR, wenn man den UART im SPI-Modus nutzt, dank
Sendepuffer ist taktgenaues Timing nicht nötig!
>Ich habe allerdings auch keine große Lust, mich von solchen>Realitätsverweigerern öffentlich herabwürdigen zu lassen.
Was EIN Geisterfahrer? NEIN, HUNDERTE!!!
>Interessanterweise verstößt sogar der Herr Moderator damit gegen die>Nutzungsregeln des eigenen Forums.
Merkst dus noch? Oder ist das deine ganz normale Paranoia?
>Und das sogar in verschärfter Form,>denn die Fakten stehen gegen ihn und ich bin ziemlich sicher: Er weiß>das nur zu genau.
Is schon gut . . .
>Ich bin jedenfalls jederzeit bereit, eine ASM-Routine zu posten, die>wirklich das tut, was ich behaupte, also in Summe: alle 16 Takte das>nächste Byte per SPI entsprechend dem in C geposteten Algorithmus.
Wie langweilig. Solche Spielchen waren vor 10 Jahen hipp, heute ist das
Usus.
BTW. Du hast dir noch nie die SPI-Ausgabe WIRKLICH angeschaut, ich meine
mit dem Oszi. Denn dann wüßtest du, dass der AVR NICHT lückenlos
SPI-Daten senden kann. Es ist IMMER mindests 1 CPU-Takt Pause zwische
den Datenpaketen. Mit dem UART im SPI-Modus kann das anders sein, ich
meine das klassische SPI-Modul.
>Einzige Bedingung:
Keine Lust auf Schattenboxen. Das war in dem Thread keine Sekunde das
Thema und ist HIER auch gar nicht nötig.
>Nimmst du die Herausforderung an, Karl-Heinz? Oder du, Falk? Sagt jetzt>ja oder schweigt für immer!
Ich glaube kaum, dass DU das festlegst.
Ausserdem steht die Lösung schon in den Links. Und ein voll portable
Schreibweise bringt wenig, denn eine andere CPU wie PIC, MSP430 & Co hat
andere Register und ggf. Logik.
Aber kämpfe ruhig weiter an deiner ASM-Front. Dein Urgroßvater hat das
gleiche in Stalingrad gemacht, wenn gleich eher unfreiwillig.
Falk Brunner schrieb:> Aber kämpfe ruhig weiter an deiner ASM-Front. Dein Urgroßvater hat das> gleiche in Stalingrad gemacht, wenn gleich eher unfreiwillig.
Tja, irgendwer muß ja die für diverse Zielsysteme optimierten libs und
Codegeneratoren schreiben...
Alles Stalingradkämpfer? Bedauernswerte Ewiggestrige? Uhuh, das werden
die aber garnicht gerne hören. Diese Leute halten schließlich deinen
Fetisch am Rande der Benutzbarkeit. (Was auch immer ihr Motiv dafür sein
mag...)
;o)
Simon T. schrieb:> "E:\Atmel Toolchain\AVR8> GCC\Native\3.4.2.939\avr8-gnu-toolchain\bin\avr-gcc.exe"
D.h. 3.4.2 war die Version der Atmel AVR Toolchain. Laut deren Release
Notes ist dort ein avr-gcc Version 4.7.2 drin. Mit 4-er Versionen bis
4.6 würdest Du wahrscheinlich wesentlich schlechtere Ergebnisse
bekommen. Wenn Du in einem Windows Kommandozeilenfenster folgendes
eingibst:
bekommst Du das, was ich wissen wollte.
Die Klemmschwester hat in Ihrem Eifer noch einen kleinen Fehler
übersehen, den Du aber inzwischen sicher auch selber gefunden hast:
1
if(z<8)
2
{
3
Z++;
4
}
5
else
6
{
7
z=0;
8
level =level + 8;
9
}
Wahrscheinlich sollte z (klein) an der Stelle nicht bis 8 laufen.
Vielleicht besser so oder ähnlich:
@ c-hater (Gast)
>Tja, irgendwer muß ja die für diverse Zielsysteme optimierten libs und>Codegeneratoren schreiben...
Aber das bist ganz sicher nicht du, wenn du nicht mal zwischen Anwendung
und Lib unterscheiden kannst.
>Alles Stalingradkämpfer? Bedauernswerte Ewiggestrige?
Könner, die wissen wo ASM angebracht ist und wo nicht.
So, da bin ich wieder.
Ich danke euch allen für die guten Verbesserungsvorschläge. Was die
Assembler-Umsetzung angeht halte ich mich jedoch für absolut
unqualifiziert Routinen zu entwickeln die denen des C-Compilers
überlegen sind. Des Weiteren ist das Setzen der Schieberegister nur ein
Aspekt des LED-Cubes, d.h. ich habe noch genug andere Baustellen. Womit
wir auch schon beim Grund sind weshalb ich auf eine UART-Umsetzung
verzichten möchte. Diese Schnittstelle soll im kompletten System dazu
dienen, LED-Daten vom PC aus entgegen zu nehmen (ein möglicher
Betriebsmodus).
Nochmals danke für die ausgezeichneten Ratschläge. Wer nun persönlich
welche Progammmiersprache bevorzugt ist doch Geschmackssache. Jede hat
ihre Vor- und Nachteile.
@Leo C.
"E:\Atmel Toolchain\AVR8
GCC\Native\3.4.2.939\avr8-gnu-toolchain\bin\avr-gcc.exe" -v
Using built-in specs.
COLLECT_LTO_WRAPPER=e:/atmel\ toolchain/avr8\
gcc/native/3.4.2.939/avr8-gnu-toolchain/bin/../libexec/gcc/avr/4.7.2/lto
-wrapper.exe
Target: avr
Configured with:
/data2/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/src/gc
c/configure
LDFLAGS=-L/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/av
r8-gnu-toolchain-win32_x86/lib CPPFLAGS= --target=avr
--host=i686-pc-mingw32 --build=x86_64-pc-linux-gnu
--prefix=/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/avr
8-gnu-toolchain-win32_x86
--libdir=/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/avr
8-gnu-toolchain-win32_x86/lib --enable-languages=c,c++ --with-dwarf2
--enable-doc --disable-shared --disable-libada --disable-libssp
--disable-nls
--with-mpfr=/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/
avr8-gnu-toolchain-win32_x86
--with-gmp=/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/a
vr8-gnu-toolchain-win32_x86
--with-mpc=/home/toolsbuild/jenkins-knuth/workspace/avr8-gnu-toolchain/a
vr8-gnu-toolchain-win32_x86 --enable-win32-registry=avrtoolchain
--with-pkgversion=AVR_8_bit_GNU_Toolchain_3.4.2_939 --with-bugurl=h
Thread model: single
gcc version 4.7.2 (AVR_8_bit_GNU_Toolchain_3.4.2_939)
Ich hoffe das dir das hilft, denn ehrlich gesagt habe ich momentan keine
Ahnung was du meinst ;).
Grüße
Narf
Ich würde nicht bestreiten, das Programmteile mit solchen Anforderungen
wie Taktgenau am besten (und wohl auch einzig) in ASM zu schreiben sind.
Nur, wenn man 32..128kb mit weiterem sinnvollem Code füllen will, dann
ist das via GCC einfacher und schneller. Die Optimierungs-Algorithmen
mögen viel simpler sein, aber die Geschwindigkeit und Ausdauer mit der
der GCC sie runterspult sind manuell nicht erreichbar. Nicht immer nur
Einzelteile anschauen. BTW, ich habe schon AVR-ASM gesehen, wo ein
Switch über ein Byte als 256Worte lange Sprungtabelle gebaut war. Zwar
konstante Laufzeit, aber riesig und kaum wartbar. Sowas lass ich gerne
den Compiler sortieren. Ein Werkzeugmacher benutzt ja oft eine
Fräsmaschine, obwohl er auch feilen gelernt hat.
c-hater schrieb:> Nimmst du die Herausforderung an, Karl-Heinz?
Welche Herausforderung?
Eine SPI Routine zu schreiben?
Das ist doch pipifax.
Machen wir doch Nägel mit Köpfen! Schreieben wir ein richtiges Programm!
Schön umfangreich und mit schöner Funktionalität.
Und dann sehen wir mal, wessen Programm schneller fertig ist und wessen
Programm weniger Fehler aufweist. Denn das ist es, was letzten Endes in
der Mehrheit der Masse aller Programme zählt.
Ich bräuchte zb eine Regelung für meine Gasthermen-Heizung (2-Punkt
Regler genügt). Komplett mit mindestens 3 Heizprogrammen (natürlich
konfigurierbar), die Tageszeit und Wochentag abhängig das Heizprogramm
abspulen, Bedienung am Gerät mit Drehencoder und LCD, Temperaturaufnahme
mit einem DS1820, integriert mit einem kleinen HTML-Server auf ENC28J60
Basis, der mir eine Fernbedienung bzw. Abfrage des Status aus dem Web
erlaubt. Im Moment studiere ich gerade den Radig-Webserver, aber mit dem
bin ich nicht so glücklich.
Na, was ist?
> denn die Fakten stehen gegen ihn
Die Fakten sind, dass hier kein Mensch taktgenaues Timing benötigt.
Schnell genug ist völlig ausreichend.
So siehst aus.