Guten Abend liebes Forum, ich bin mir nicht sicher, ob dieser Beitrag in /"Ausbildung, Studium und Beruf"/ richtig aufgehoben ist. Ich bitte um eine Verzeihung und -schiebung falls es Anstoß findet. Ich bin auf der Suche nach einer intelligenten Lösung um meine, über die letzten Jahre gesammelte - und in der letzten Zeit stark gewachsene - (digitale) Literatur aufzubewahren, zu ordnen und bestenfalls auch leicht zitierbar bzw. kopierbar zu machen. _Das Problem:_ Ich habe in den letzten Jahren recht viel Literatur in Form von Büchern (z.B. von Springerlink o.ä.), Diplomarbeiten, Dissertationen, Vorlesungsskripten, Paper und Datenblättern digital gesammelt. Alles was sich bei Recherchen eben so ansammelt. Der größte Teil (~40 GB) sind dabei PDF-Files. Mein Problem ist nun, dass ich diese Files gerne zentral sammeln und sortieren würde (z.B. nach Themen: Informatik, Physik, E-Tec usw.), die Informtionen aber eben auch gerne projektweise einbeziehen würde (z.B. das Datenblatt des AVR xyz und das Kapitel über die besten Gerichte aus dem Filter cookbook). Möglich ist es natürlich alles zu kopieren. Am liebsten wäre mir aber wenn alles zentral gespeichert werden könnte, zum Beispiel um die Kommentarfunktion von PDFs zu nutzen oder um sich die während Projekten gemachten Anmerkungen und Notizen in den Files auch später noch ohne Kopierorgien zugänglich zu halten. Andererseits werden in Projekten oft nur bestimmte Kapitel oder Abschnitte eines Dokumentes benötigt. Hier ist es wiederrum sehr hinderlich ständig ein ganzes "Buch" mitzuschleppen. Oft beginne ich Projekte in dem ich alle benötigten Informationen erst mal recht wahllos aus verschiedenen Quellen zusammenkopiere um zu einem spteren Zeitpunkt ins Detail zu gehen. Das geht mit PDF-Files oft nicht besonders gut. Ich empfinde es als umständlich erst Projektweise ein Literaturverzeichnis anzulegen und dann dann doch wieder in jedem File einzeln nachzuschlagen, wenn man die Information benötigt. Gibt es ein Tool das Referenzierungen auf ein zentrales Textdokument zuläßt? Dieses in verschiedene Kategorien Ordnen kann und fähig ist Anmerkungen/ Notizen an das Dokument anzuhängen. Ein Traum, aber nicht zwingend notwendig, wäre es, wenn dieses Programm ebenfalls eine Literaturdatenbank/ ein Literaturverzeichnis für Latex und/oder Open Office zur Verfügung stellen würde. Wie verfahrt ihr günstigstenfalls? Ich kann mir nicht vorstellen, dass ich der einzige mit diesem Problem bin. Einen sehr herzlichen Dank fürs mitüberlegen und mitdenken. Klügel
Mike Klügel schrieb: > Am > liebsten wäre mir aber wenn alles zentral gespeichert werden könnte Mir wurde mal das Tool "Memo-Master" empfohlen. Kollegen legen da alles ab: Mails, PDFs, Links, Memos usw. Kannst Du Dir mal anschauen/testen. Die Textsuche scheint recht flott zu sein.
Zotero (http://www.zotero.org/) ist ein schönes Literaturprogramm. Kann in alle mögliche Formate exportieren. Musst mal gucken, ob das reicht, ich fürchte aber du suchst etwas umfangreicheres.
Hallo Mike. Mike Klügel schrieb: > ich bin mir nicht sicher, ob dieser Beitrag in /"Ausbildung, Studium und > Beruf"/ richtig aufgehoben ist. Ich bitte um eine Verzeihung und > -schiebung falls es Anstoß findet. Ich finde, das gehört zum Selbststudium. Würde also passen. ;O) > Ich bin auf der Suche nach einer intelligenten Lösung um meine, über die > letzten Jahre gesammelte - und in der letzten Zeit stark gewachsene - > (digitale) Literatur aufzubewahren, zu ordnen und bestenfalls auch > leicht zitierbar bzw. kopierbar zu machen. Das Problem kenne ich. Auch wenn es bei mir nur 20GB PDFs sind. > Mein Problem ist nun, dass ich diese Files gerne zentral sammeln und > sortieren würde (z.B. nach Themen: Informatik, Physik, E-Tec usw.), Dazu habe ich ein Dateisystem. Es ist halb logisch aufgebaut, und trägt noch immer den unlogischen Stempel, das ich einmal gezwungen war, das ganze effektiv auf CDs für Sicherungskopien zu verteilen. Mal abgesehen davon, das ich mit dem Sammeln unter W98 angefangen habe.... PDF-Hauptordner Datenblaetter_A-K Analog_ICs AD_DA Wandler ADundDA-Wandler PCF8591_AD-DA-Converter_8Bit_I2C-Bus_Philips-NXP_27Jan2003.pdf .. .. AD-Wandler AD876.pdf AD2020_AD-Converter3digit_AnalogDevices.pdf .. .. DA-Wandler DeltaSigmaWandler Ampl_Comp_OPAMP Ampl_Comp_OPAMP BatterienAkkusUndLadung Digital_ICs ... ... hört auf mit: Kondensatoren Datenblaetter_L-Z Laengstregler Microcontroller_DSP_Prozessoren ... ... hört auf mit: Widerstaende (Z-Dioden sind ein Unterkapitel von "Dioden") Formeln_Tabellen_Doku_Application NichtE-Technik Programmieren_Daten_Krypto_ec Schaltplaene VorlesungsSkripte_ec Vortraege_Dissertationen_Thesis > Möglich ist es natürlich alles zu kopieren. Du must ja nur die Dokumente kopieren, die Du speziell im Projekt brauchst. In einen speziellen Projektordner. Wenn Du Kommentare dazu machst, benenne die Datei um. Wenn Du die gleiche Datei mit Kommentaren aus anderen Projekten zugepflastert hast, wird das irgendwann auch lästig. > oder um sich die > während Projekten gemachten Anmerkungen und Notizen in den Files auch > später noch ohne Kopierorgien zugänglich zu halten. Dann lege in Deinem PDF-Baum noch einen Ordner "Projekte" an, und speichere die kommentierten PDF Dateien mit passender Ergänzung im Dateinamen dort in einen Unterordner mit dem Projektnamen. Speicherplatz ist mittlerweile billig. > Andererseits werden in Projekten oft nur bestimmte Kapitel oder > Abschnitte eines Dokumentes benötigt. Hier ist es wiederrum sehr > hinderlich ständig ein ganzes "Buch" mitzuschleppen. Jain. Speicherplatz ist billig. Aber wenn Du nur einzelne Seiten brauchst, einfach das PDF-Dokument in eine PDF-Datei "drucken" und dabei nur in der Druckerfunktion die gewünschten Seiten drucken. Geht z.B. mit Evince problemlos. > Oft beginne ich Projekte in dem ich alle benötigten Informationen erst > mal recht wahllos aus verschiedenen Quellen zusammenkopiere um zu einem > spteren Zeitpunkt ins Detail zu gehen. > Das geht mit PDF-Files oft nicht besonders gut. Ich empfinde es als > umständlich erst Projektweise ein Literaturverzeichnis anzulegen und > dann dann doch wieder in jedem File einzeln nachzuschlagen, wenn man die > Information benötigt. Ja. Das wird aber immer so sein, solange Du nicht wieder aus den einzelnen Dokumenten ein einziges neues machst. Unabhängig vom Dateiformat. Einzelne PDF Dateien binde ich mit pdftk zusammen: $ pdftk datei1.pdf datei2.pdf cat output gesamtespdf.pdf Es gehen auch mehr als zwei Dateien. Und, ja, ein GUI dafür wäre zwar nett (vieleicht kennt einer eins?), aber für meine paar Fälle geht es auch so. Wenn es mich irgendwann zusehr kneift, schreib ich in Python mal so etwas. > Dieses in verschiedene Kategorien Ordnen kann Das ist das Grundproblem der Bibliothekswissenschaften. ;O) Es existieren Kategorien a bis z. Irgendwann kommt dann etwas, was eigentlich in mehrere Kategorien fällt.....wie sortierst Du das ein? Bibliothekskataloge gehen dabei rein nach dem Titel, was aber schon bei Publikationen die ein ....unter besonderer Berücksichtigung von... enthalten, eine Entscheidung auf den ersten auftretenden Begriff verlangt. Persönlich behelfe ich mich mit "sprechenden Dateinamen". der Dateiname eines Dokumentes besteht aus Titel Bindestrich Untertitel (falls vorhanden) Tiefstrich Autornachname Tiefstrich Veröffentlichungsdatum. Bei Bedarf schiebe ich zwischen Titel/Untertitel noch Stichworte ein, wenn ich meine, das wäre sinnvoll. Beispiel: Ein Zeitschriftenartikel über uvw, der aber eine interessante Nebeninformation über xyz enthält, die nicht aus dem titel hervorgeht. Autoren lasse ich auch gelegentlich ganz weg, wenn es zu viele sind. Bei Datenblättern: Bauteilbezeichnung(en) Eigenschaften, Hersteller und Ausgabedatum des Datenblattes. Beispiel: BSS100_BSS123_N-Channel_LogicLevel_Fairchild_1996. Die Eigenschaften sind leider sehr willkürlich. Manchmal schreibe ich auch "Obsolet" oder die Gehäuseform, Spannung oder irgendwas dazu. Bei Applikationsberichten kann es sinnvoll sein, den offiziellen Dokumentnamen (gibt es nicht immer (offensichtlich)) Beispiel: TransformerAndInductorDesignForOptimumCircuitPerformance_Dixon_TexasInst ruments_SLUP205_2003.pdf Leider kann ich aus Zeitmangel bzw. fehlenden Nebeninformationen nicht immer so detailfreudig sein. Auch hat sich dieses Schema durch praktische Erfahrung in Jahren herauskristallisiert. Altbestände folgen dem darum nicht, oder weniger stringent. Ein paar Informationen in den Dateinamen zu stecken, erlaubt es, die gewöhnliche Dateisuche loszuschicken. Persönlich verwende ich "catfish" und als Indexsuche "Recoll". Recoll legt auch einen Index über den Inhalt an, wenn die datei Durchsuchbar ist. Unter Windows hatte ich mal ein spezielles Programm dafür, aber das war sonst mit nichts anderem kompatibel, und hatte ein Problem, wenn ich (wegen der Sicherungskopien auf CD damals) am Ordnerbaum umverteilen musste. Das gleiche Problem bei umgebauten Ordnerbäumen hat leider auch Bibtex (Unter Windows hatte ich mal ein spezielles Programm dafür, aber das war sonst mit nichts anderem kompatibel, und hatte ein Problem, wenn ich (wegen der Sicherungskopien auf CD) am Ordnerbaum umverteilen musste. Das gleiche Problem bei umgebauten Ordnerbäumen hat leider auch Bibtex (es konnte aber zumindest zwei alternative Ordnerbäume), obwohl das sonst sehr komfortabel ist, kompatibel und (bis auf die Notizen) vieleicht genau das ist, was Du suchst, insbesondere wenn es um eine Literaturdatenbank für Latex geht. Für meine Kurznotizen verwende ich Tomboy. Fände das aber in einigen Aspekten verbesserungswürdig. Zum erstellen meiner Sicherungskopien verwende ich rsync bzw. grsync. > Wie verfahrt ihr günstigstenfalls? Ich kann mir nicht vorstellen, dass > ich der einzige mit diesem Problem bin. Du kennst Ugol's Law? http://www.urbandictionary.com/define.php?term=Ugols%20law ;O) Datsächlich treffen hier drei nicht einfach Lösbare Probleme zusammen. Abgesehen von Deinem Wunsch nach Verlinkung und Notizen. 1) Sortierung: Wie sortiere ich etwas ein, was unter verschiedenen Kategorien passt? 2) Was mache ich, wenn ich feststelle, das meine Ordnerstruktur nicht mehr passt? Wass passiert, wenn ich die Ordnerstruktur ändere? 3) Das System sollte fehlertolerant sein. Letzteres führt mich immer dazu, "sprechende Dateinamen" zu verwenden, und eine normale Desktop und Indexsuche. Zur Not geht das auch noch mit "find" und "grep". Es gibt für mich noch einen Aspekt: Zumindest der Ordnerbaum sollte auf verschiedenen Betriebssystemen funktionieren (mit welchen Programmen ich dort suche, ist ein anderes Kapitel). Das heisst aber, ich sollte mich bei Ordner und Dateinamen auf die Buchstaben OHNE Umlaute und ß sowie die Zahlen beschränken. Als Sonderzeichen nur Bindestrich, Tiefstrich und den Punkt. Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Was Du suchst ist eine digitale Entsprechung eines "Zettelkastens". Unter diesem Suchwort findest Du zahlreiche Ansätze und ihre Probleme.
Angehängte Dateien:
-

TestMindmap.jpg
110 KB
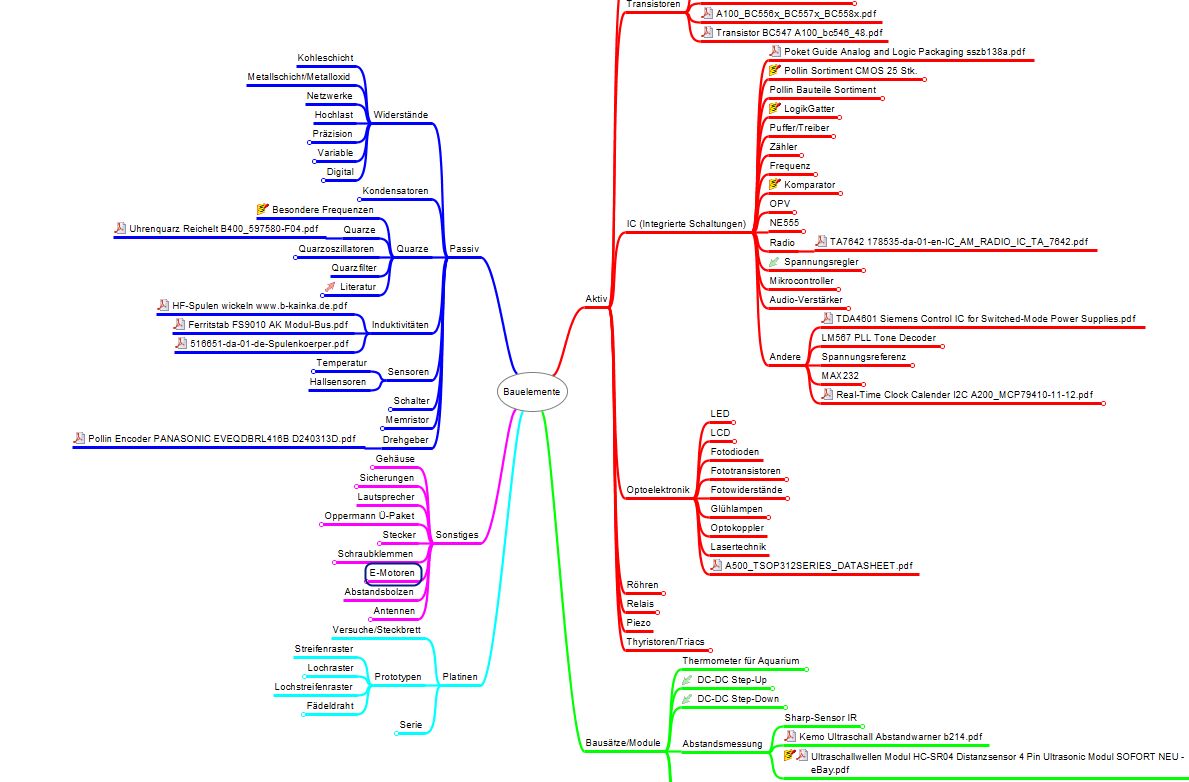
Mike Klügel schrieb: > Gibt es ein Tool das Referenzierungen auf ein zentrales Textdokument > zuläßt? Dieses in verschiedene Kategorien Ordnen kann und fähig ist > Anmerkungen/ Notizen an das Dokument anzuhängen. > Ein Traum, aber nicht zwingend notwendig, wäre es, wenn dieses Programm > ebenfalls eine Literaturdatenbank/ ein Literaturverzeichnis für Latex > und/oder Open Office zur Verfügung stellen würde. Schau Dir mal Docear an (IMHO Open-Source, gefördert von deutschen Behörden, speziell dafür ausgelegt Papers zu schreiben). Soweit ich es sagen kann, sollte das Deinen Bedarf abdecken. Ich selbst verwende Docear seit einigen Jahren, nutze aber nur einen geringen Bruchteil der vorhandenen Funktionen. Ich habe ein paar Mindmaps, jedes neue abgespeicherte PDF-Dokument sehe ich im Incoming-Mindmap (Kommentare im PDF sollten IMHO auch berücksichtigt werden) und wird z.B. als Datenblatt im Mindmap "Bauteile" in der entsprechenden Kategorie rübergezogen. Für die Referenzierungen können ansonsten auch noch speziellere Lösungen eingebunden werden. Im Anhang habe ich als Bild noch ein Beispiel eingefügt (Da bin ich mal auf die Kommentare gespannt, ist ja jetzt mein erstes mal mit Bild ;o) Sachen aus Papier verwalte ich mit dem Classei-System. Einfach mal nach Classei oder Mappei googeln, das sind Ablagesysteme ohne Ordner. Das geht in die Richtung der Manila-Maps, die man aus US-Serien kennt bzw. in Richtung der Hängeregister-Mappen. Man benötigt nur die ganze Hardware nicht und ist flexibler und platzsparender.
Hej! Vielen Dank für die vielen hilfreichen und umfangreichen Antworten. Vor allem aber auch vielen Dank, für die vielen Stichworte nach denen ich nun suchen kann. Was für ein nerdiges Thema, ich empfinde es aber wirklich als sehr schwierig auf eine gute und beständige Lösung zu kommen. Ich habe mir die vorgeschlagenen Softwares (?) heruntergeladen und bin nun in die "Testphase" eingestiegen und zumindest schoneinmal zu der Erkenntnis gelang, dass mir für die Art und und Weise wie ich arbeite, eine simple und schlanke Lösung am ehesten zusagt. Vermutlich tue ich den Entwicklern und euch (noch) unrecht. Ich schildere - wer weis, wer den Thread mal ausgräbt - trotzdem mal meinen ersten unvollständigen Eindruck. Rainer Brüderle schrieb: > Mir wurde mal das Tool "Memo-Master" empfohlen. Kollegen legen da alles > ab: Mails, PDFs, Links, Memos usw. Kannst Du Dir mal anschauen/testen. > Die Textsuche scheint recht flott zu sein. Memo-Master ist in mehreren Versionen zu Preisen zwischen umsonst und ~100 Eur erhältlich und bietet einen vergleichsweise großen Funktionsumfang und bietet auch recht Komfortabel die Möglichkeit mit dem Text eines PDF weiterzuarbeiten. Die PDFs können in ein "Memo" überführt werden, wobei die Formatierung jedoch anscheinend verloren geht. Mir scheint es tatsächlich auch sinnvolles Tool zu sein um Informationen mehrerer Domänen (Mails, Datenblätter, Notizen usw.) zu sammeln. Jan K. schrieb: > Zotero (http://www.zotero.org/) ist ein schönes Literaturprogramm. Kann > in alle mögliche Formate exportieren. Musst mal gucken, ob das reicht, > ich fürchte aber du suchst etwas umfangreicheres. Zotero hat mir auch gut gefallen. Das Programm ist recht schlank und sehr übersichtlich und verfügt (auch) über die Möglichkeit unterschiedliche Medien (Videos, PDF, Sound) abzulegen und Notizen an diese anzuhängen. Eigentlich schön und durchdacht. Mich stört allerdings etwas, das es zum Beispiel schwierig ist eine Nebenrechnung ("Kritzelei", o.ä. zu einer bestimmten Seite eines PDFs zu referenzieren) Bernd Wiebus schrieb: > Ich finde, das gehört zum Selbststudium. Würde also passen. ;O) :) Super ich habe Deinen Beitrag sehr interessiert gelesen und habe mich in vielen Punkten auch wiedererkannt. Was mir auffiel ist, dass für mich beispielsweise die Alphabetische Sortierung so gut wie keine Rolle spielt. Zu wenig halten sich meine PDFs an Beschriftungskonventionen. Richtige Lust empfinde ich auch nicht das zu ändern. :) Bernd Wiebus schrieb: >> Möglich ist es natürlich alles zu kopieren. > > Du must ja nur die Dokumente kopieren, die Du speziell im Projekt > brauchst. In einen speziellen Projektordner. Das stimmt natürlich. Bernd Wiebus schrieb: > Wenn Du Kommentare dazu machst, > benenne die Datei um. Wenn Du die gleiche Datei mit Kommentaren aus > anderen Projekten zugepflastert hast, wird das irgendwann auch lästig. Mit Kommentaren, auch sehr vielen, kann ich erfahrungsgemäß gut leben. Als recht grafisch denkender Mensch empfinde das eigentlich als große Gedächtnisstütze zu wissen welche Anmerkung wo standen. Bernd Wiebus schrieb: > Deinem PDF-Baum noch einen Ordner "Projekte" an, und > speichere die kommentierten PDF Dateien mit passender Ergänzung im > Dateinamen dort in einen Unterordner mit dem Projektnamen. Speicherplatz > ist mittlerweile billig. Ja das stimmt, Kosten entstehen keine. Ich hätte durch Vergrößerung der Struktur wohl das Gefühl, dass ich mir dadurch zusätzlich Arbeit schaffe. Ein Versuch ist es aber Wert. Bernd Wiebus schrieb: > Jain. Speicherplatz ist billig. Aber wenn Du nur einzelne Seiten > brauchst, einfach das PDF-Dokument in eine PDF-Datei "drucken" und dabei > nur in der Druckerfunktion die gewünschten Seiten drucken. Geht z.B. mit > Evince problemlos. Das war auch meine erste Idee. Mir fehlt dabei - auch nach einer längeren Testphase - das zentrale Element, auch projektweise an Notizen und Kommentare aus anderen Projekten zu gelangen. Bernd Wiebus schrieb: > Ja. Das wird aber immer so sein, solange Du nicht wieder aus den > einzelnen Dokumenten ein einziges neues machst. Unabhängig vom > Dateiformat. > > Einzelne PDF Dateien binde ich mit pdftk zusammen: > > $ pdftk datei1.pdf datei2.pdf cat output gesamtespdf.pdf Gute Gedanken. Vielen Dank. Bernd Wiebus schrieb: > Wenn es mich irgendwann zusehr kneift, schreib ich in Python mal so > etwas. Sag Bescheid ;) Bernd Wiebus schrieb: > Das ist das Grundproblem der Bibliothekswissenschaften. ;O) Es > existieren Kategorien a bis z. Irgendwann kommt dann etwas, was > eigentlich in mehrere Kategorien fällt.....wie sortierst Du das ein? Ja das ist für mich auch ein riesen Problem, speziell da viele meiner "Bücher" zu sehr unterschiedlichen Themen etwas zu sagen haben. Zum Beispiel "CodeArt" - Informatik, Kunst, Medienwissenschaften? Wie gesagt spielt eine alphabetische Ordnung... > Bibliothekskataloge gehen dabei rein nach dem Titel, was aber schon bei > Publikationen die ein ....unter besonderer Berücksichtigung von... > enthalten, eine Entscheidung auf den ersten auftretenden Begriff > verlangt. ...kaum eine Rolle. Bernd Wiebus schrieb: > Persönlich behelfe ich mich mit "sprechenden Dateinamen". der Dateiname > eines Dokumentes besteht aus Titel Bindestrich Untertitel (falls > vorhanden) Tiefstrich Autornachname Tiefstrich Veröffentlichungsdatum. > Bei Bedarf schiebe ich zwischen Titel/Untertitel noch Stichworte ein, > wenn ich meine, das wäre sinnvoll. Beispiel: Ein Zeitschriftenartikel > über uvw, der aber eine interessante Nebeninformation über xyz enthält, > die nicht aus dem titel hervorgeht. Autoren lasse ich auch gelegentlich > ganz weg, wenn es zu viele sind. Ja das habe ich mir auch angewöhnt. Also an "gängige" und objektive Informationen im Titel einen persönlichen Kommentar anzufügen. Das geht mal mehr, mal weniger gut. Nebenbei bemerkt ist mir das Erscheinungsjahr sehr unwichtig. Bernd Wiebus schrieb: > Leider kann ich aus Zeitmangel bzw. fehlenden Nebeninformationen nicht > immer so detailfreudig sein. Auch hat sich dieses Schema durch > praktische Erfahrung in Jahren herauskristallisiert. Altbestände folgen > dem darum nicht, oder weniger stringent. kommt mir bekannt vor :) Bernd Wiebus schrieb: > Persönlich verwende ich "catfish" > und als Indexsuche "Recoll". Recoll legt auch einen Index über den > Inhalt an, wenn die datei Durchsuchbar ist. Kannte ich nicht. Sieht ganz interessant aus... Bernd Wiebus schrieb: > Das gleiche Problem bei umgebauten Ordnerbäumen hat leider auch Bibtex > (es konnte aber zumindest zwei alternative Ordnerbäume), obwohl das > sonst sehr komfortabel ist, kompatibel und (bis auf die Notizen) > vieleicht genau das ist, was Du suchst, insbesondere wenn es um eine > Literaturdatenbank für Latex geht. Ich stehe Latex sehr zwiegespalten gegenüber. Richtig glücklich werde ich damit wohl nicht mehr. ich hatte tatsächlich mal angefangen hier eine Datenbank aufzubauen, komme damit aber nicht sehr gut zurecht, beziehungsweise stört mich neben der nicht vorhanden Notizfunktion eben auch das Handling. Aber: Ja. Die Aussage ist trotzdem vermutlich richtig. Bernd Wiebus schrieb: > Du kennst Ugol's Law? > http://www.urbandictionary.com/define.php?term=Ugols%20law ;O) Ich wusste zumindest nicht, dass jemand diesem Phänomen einen Namen gegeben hat :) Bernd Wiebus schrieb: > 1) Sortierung: Wie sortiere ich etwas ein, was unter verschiedenen > Kategorien passt? > 2) Was mache ich, wenn ich feststelle, das meine Ordnerstruktur nicht > mehr passt? Wass passiert, wenn ich die Ordnerstruktur ändere? > 3) Das System sollte fehlertolerant sein. Letzteres führt mich immer > dazu, "sprechende Dateinamen" zu verwenden, und eine normale Desktop und > Indexsuche. Zur Not geht das auch noch mit "find" und "grep". Danke für die Zusammenfassung. Das bringt mich weiter. Ich glaube auch, dass Deine sprechenden Namen für mich eine - wenn auch unvollständige - aber gute simple Lösung sind. Bernd Wiebus schrieb: > Es gibt für mich noch einen Aspekt: Zumindest der Ordnerbaum sollte auf > verschiedenen Betriebssystemen funktionieren (mit welchen Programmen ich > dort suche, ist ein anderes Kapitel). Das heisst aber, ich sollte mich > bei Ordner und Dateinamen auf die Buchstaben OHNE Umlaute und ß sowie > die Zahlen beschränken. Als Sonderzeichen nur Bindestrich, Tiefstrich > und den Punkt. Das ist für mich weniger ein Problem, aber sehe ich natürlich ein. Walter Tarpan schrieb: > Was Du suchst ist eine digitale Entsprechung eines "Zettelkastens". > Unter diesem Suchwort findest Du zahlreiche Ansätze und ihre Probleme. Vielen Dank für das Stichwort. Klaus I. schrieb: > Schau Dir mal Docear an (IMHO Open-Source, gefördert von deutschen > Behörden, speziell dafür ausgelegt Papers zu schreiben). Soweit ich es > sagen kann, sollte das Deinen Bedarf abdecken. Ich selbst verwende > Docear seit einigen Jahren, nutze aber nur einen geringen Bruchteil der > vorhandenen Funktionen. Ich habe ein paar Mindmaps, jedes neue > abgespeicherte PDF-Dokument sehe ich im Incoming-Mindmap (Kommentare im > PDF sollten IMHO auch berücksichtigt werden) und wird z.B. als > Datenblatt im Mindmap "Bauteile" in der entsprechenden Kategorie > rübergezogen. Für die Referenzierungen können ansonsten auch noch > speziellere Lösungen eingebunden werden. Hej, vielen Dank. Ein interessantes Programm! Von den Mindmaps, die sich gerade im Freundeskreis stark verbreiten, war ich anfangs stark begeistert. Mein erster Kontakt damit. Ich würde es so einschätzen, dass es zu Projektbeginn sicher ein sehr nützliches Tool ist um schnell viele Information ins Projekt einzubringen und zu strukturieren. Für eine größere Datenbank (generell eine größere Projektstruktur?) wäre mir das Prinzip wohl wiederrum zu unübersichtlich. Aber vielen Dank, mit der Software werde ich mich sicher noch weiter beschäftigen. Herzlichen Dank allen Schreibern (und Lesern) und ein angenehmes Restwochenende
Hallo Mike. Mike Klügel schrieb: > Vielen Dank für die vielen hilfreichen und umfangreichen Antworten. Vor > allem aber auch vielen Dank, für die vielen Stichworte nach denen ich > nun suchen kann. > Was für ein nerdiges Thema, ich empfinde es aber wirklich als sehr > schwierig auf eine gute und beständige Lösung zu kommen. Macht nix. Du bist hier in einer nerdigen "Community".....in dieser Hinsicht kannst Du Dich gehen lassen. Hier ist der Ort dazu. ;O) > Was mir auffiel ist, dass für mich beispielsweise die Alphabetische > Sortierung so gut wie keine Rolle spielt. Zu wenig halten sich meine > PDFs an Beschriftungskonventionen. Richtige Lust empfinde ich auch nicht > das zu ändern. :) Du meinst das mit den Datenblättern? Nun, die Unterkategorien sind ja gleichwertig nebeneinander. Wenn ich eine solche Struktur habe, bleiben wenig sinnvolle Methoden über, die zu sortieren. Dateigröße bestimmt nicht, und Erstellungsdatum auch eher weniger. Bleibt der Titel, und da bietet das Dateiverwaltungssystem automatisch eine alphanumerische Ordnung an. Als ich das dann vor zig Jahren für CD-Sicherung zerteilen musste, bot sich A-K und L-Z an. Das hat sich dann so fortgepflanzt. Heute passt keiner der Ordner mehr auf eine CD. ;O) Ich könnte eigentlich die beiden Ordner wieder zusammenführen. Tauscht Klickarbeit gegen Scrollarbeit ein. ;O) > Mit Kommentaren, auch sehr vielen, kann ich erfahrungsgemäß gut leben. > Als recht grafisch denkender Mensch empfinde das eigentlich als große > Gedächtnisstütze zu wissen welche Anmerkung wo standen. Ich denke sehr textorientiert (nach Meinung von jemandem, der sich damit auskennt). Das birgt Konfliktpotential, weil es eher selten ist, und ich darum oft nicht verstanden werde oder meine Vorstellungswelt zu unbequem für andere ist. Umgekehrt gilt das dann auch. Dooferweise kann ich mir nicht aussuchen, wie ich denke. Ich kann lediglich versuchen zu simulieren wie andere Leute denken. > > Ja das stimmt, Kosten entstehen keine. Ich hätte durch Vergrößerung der > Struktur wohl das Gefühl, dass ich mir dadurch zusätzlich Arbeit > schaffe. Ein Versuch ist es aber Wert. Mmmmh. Das kann vor allem passieren, wenn du es falsch machst. Und es muss eben alles gut gekennzeichnet sein, sonnst kommst Du durcheinander. Die langen Dateinamen verlangen Geduld und Selbstdisziplin. ;O) > Das war auch meine erste Idee. Mir fehlt dabei - auch nach einer > längeren Testphase - das zentrale Element, auch projektweise an Notizen > und Kommentare aus anderen Projekten zu gelangen. > Das ist ja auch schon recht speziell, auf Notizen in Pdf Dokumenten zu referenzieren. Ich führe meine Notizen separat in Tomboy. Tomboy kommt meinen Vorstellungen schon relativ weit entgegen, hat aber für mich ein spezielles Problem, weil ich auf verschiedene Rechnern arbeite, und ich die aktualisierten Notizen nicht über einen Server verteilen kann, weil ich nicht immer und überall Internet habe. Darum per USB stick bzw. externer Platte....hier hat Tomboy aber ein kleines Problem. Manchmal aktzeptiert es die neue Datei zum synchronisieren nicht. Ich grüble schon länger über den Grund, und kann mir bisher nur erklären, dass es irgendwie mit dem Erstellungsdatum der Datei zusammenhängt. Es ist aber lästig, immer peinlichst auf genau gehende Uhren achten zu müssen. Vor allem, wenn ich mal einen Rechner unter MEZ und dann einen unter UTC habe. > Wie > gesagt spielt eine alphabetische Ordnung... > >> Bibliothekskataloge gehen dabei rein nach dem Titel, was aber schon bei >> Publikationen die ein ....unter besonderer Berücksichtigung von... >> enthalten, eine Entscheidung auf den ersten auftretenden Begriff >> verlangt. > > ...kaum eine Rolle. Unterschätze Alphanumerik nicht. Alphanumerik ist das letzte Sortierungskriterium das noch bleibt, wenn sonnst alles gleichwertig nebeneinander steht. Wenig Struktur ist immer noch besser als keine Struktur. Ohne Alphanumerik bleibt nur Brei. Wenn Du andere, bessere Strukturen hast, tritt die Alphanumerik automatisch zurück. Appropos Alphanumerik: http://nbn-resolving.de/urn:nbn:de:101-2012053100 http://files.d-nb.de/pdf/rak_wb_netz.pdf > Nebenbei bemerkt ist mir das Erscheinungsjahr > sehr unwichtig. Mir eigentlich auch. Aber wenn ich z.B. verschiedene Ausgaben eines Datenblattes habe, beiben Revisionsnummern und Ausgabedatum eigentlich als einzige Kriterien über. Alte Datenblätter sollte ich zwar nicht für neue Projekte als alleinige Grundlage verwenden, aber manchmal findet man dort Beispielschaltungen, die später aus Platzmangel weggelassen wurden, oder ich möchte wissen, ob z.B. eine bestimmte Information schon enthalten war, und darum damals schon hätte berücksichtigt werden können. Oder einfach für ein Redesign. Was konnten die Teile damals, was können sie heute, ist dadurch was zu verbessern oder war es damals schon am Limit und heute darüber hinweg. Nicht alles muss ich erst messen.... Auch wenn mir jemand erzählt: Das ging so und so, Details weiss ich aber nicht mehr, das war schliesslich 1983....dann kann 1983 (+-1 oder 2 Jahre) eines der begehrten Kriterien für eine Suche sein. >> Das gleiche Problem bei umgebauten Ordnerbäumen hat leider auch Bibtex >> (es konnte aber zumindest zwei alternative Ordnerbäume), obwohl das >> sonst sehr komfortabel ist, kompatibel und (bis auf die Notizen) >> vieleicht genau das ist, was Du suchst, insbesondere wenn es um eine >> Literaturdatenbank für Latex geht. Hier habe ich mich geirrt. Ich meinte Jabref. Aber Jabref benutzt auch das Bibtext Format. Tatsächlich habe ich genau diese Funktion auch nie verwendet. Ich habe Jabref dazu verwendet, um Kommentare und Stichworte mit PDF Dokumenten zu verbinden. Aber wenn ich meine Ordnerstruktur geändert habe, hat Jabref die Dateien. nicht selbsttätig wiedergefunden. Oder wenn ich eine Datei nur mal umbenannt habe. Aktuell kenne ich kaum Programme, die das können. Spontan fallen mir nur wenige Methoden um das zu Bewerkstelligen: 1) Die Ordnerstruktur und die Dateien werden nur über dieses Programm geändert, das dabei eine Referenzierungstabelle anlegt. Vorteil: Wenn kein Bug auftritt, geht nichts verloren. Nachteil: Ich darf nur dieses Programm verwenden, um in den Ordnern was zu verändern > unflexibel und u.U. nicht mehr Plattformübergreifend. Die Referenzierungstabelle müsste in einem offenen Format vorliegen. Sonst droht Prprietarität mit allen Nachteilen. Python ist toll darin, Texte zu verarbeiten und zu durchsuchen. Wenn man die Referenzierungstabelle als Klarschrifttext anlegt, wäre das eine relativ einfache Lösung. 2) Es werden Hashtabellen angelegt, nach denen eine "verloren gegangene" Datei gesucht werden kann. Zuerst nach dem Dateinamen suchen, wenn der nicht gefunden wird (weil geändert) nach dem Hashcode über das komplette File. Dann nach Größe vergleichen. Problem: gefundene Dateien müssen noch manuell bestätigt werden. Weil je mehr der Hash begrenzt, umso viedeutiger wird er. Tags und Notizen verändern sowohl den Hashwert und die Größe der Datei.....dann wird sie überhaupt nicht mehr automatisch gefunden. Problem: Es kann nur immer dieses Programm, oder ein anderes, das nach (fast) den gleichen Methoden vorgeht, verwendet werden. Mit allen unwägbarkeiten, die Software so mit sich bringt. Wird sie in Zukunft noch aktualisiert (Sprich ist der Hersteller pleite)? Proprietarität: Keine Konkurenz, irre teuer bei schlechtem Produkt. Wenn aber ein offener Standard über die Methodik existiert, wäre das Problem teilweise entschärft. 3) Der Datei selber wird entweder ein Tag mit Informationen angehängt, über deren Kriteria gesucht werden kann, oder es wird als Tag ein einzigartiger "Name" angehängt, an dem sie automatisch wiedergefunden werden kann. Es gibt wohl eine Möglichkeit, Tags an PDFs anzuhängen. Aber ich bin weit entfernt davon, einen Text darüber zu verstehen...... Ausserdem, der "Tagname" sollte sich nicht verändern, wenn die Datei umbenannt wird, aber wenn Du Notizen einbindest, müstest Du formal schon eine Wahlmöglichkeit haben....Originaldatei oder eine kommentierte Datei als neue andere Datei.. Ansonsten ähnliche Probleme wie unter 2. Meine Idee mit den "Sprechenden Dateinamen" beinhaltet in gewissem Sinne die nach Kriterien durchsuchbaren Tags. Und ich kann dafür jede X-beliebige Suchfunktion benutzen. Unabhängig von der Ordnerstruktur und der Platform. Das Problem der Proprietarität tritt somit nicht auf, solange ich eine desktopsuche habe. Trozdem habe ich noch Wünsche für eine etwas luxuriösere Suche: Begriffe mit und und oder und und nicht und oder oder nicht logisch verknüpfen und auch aussondern zu können. Toll wäre eine Suchfunktion, die auch typische Rechtschreibfehler mitsucht. Z.B. ie und ei, k und ck, oder andere Variationen bis zu einer bestimmten Levenshtein-Distanz berücksichtigt. http://de.wikipedia.org/wiki/Levenshtein-Distanz > > Ich stehe Latex sehr zwiegespalten gegenüber. Richtig glücklich werde > ich damit wohl nicht mehr. Ich muss gestehen, das ich Latex als Textsatzprogramm faszinierend finde. Allerdings sind die unterschiedlichen Packets dazu, die auch noch untereinander inkompatibel sind, eher ein Problem. Solange ich bei wenigen Typen von Dokumenten bleiben kann, bleibt das Problem relativ klein. Für Sonderwünsche müsste ich davon aber wesentlich mehr verstehen und Skripte selber schreiben können. Persönlich handhabe ich Latext auf die doofe Tour: Text in einem Editor schreiben, und dann per copy und past in ein vorher geschaffenes "Leergerüst" aus latex Kommandos einhängen. ;O) Da ich nur alle paar Monate dazu komme, mal was mehr in Latex zu schreiben, ist es nicht sehr sinnvoll für mich, mich dort tiefer einzuarbeiten. Aber einfach nur vorgeschriebenen Text in vorher zusammenkopierte Latex Strukturen überzukopieren bringt schon gute Ergebnisse. Und vor allem auch mit mehr als 150 Seiten. Ab 50 Seiten tun sich sowohl Word als auch libreoffice recht schwer. Ab 70, spätestens ab 100 Seiten greife ich lieber zu Latex. Da ich die Hoffnung auf eine bessere Welt nicht aufgegeben habe, und vor allem neugierig bin, werde ich mich auch mal mit context auseinandersetzten: http://de.wikipedia.org/wiki/ConTeXt >> Es gibt für mich noch einen Aspekt: Zumindest der Ordnerbaum sollte auf >> verschiedenen Betriebssystemen funktionieren (mit welchen Programmen ich >> dort suche, ist ein anderes Kapitel). Das heisst aber, ich sollte mich >> bei Ordner und Dateinamen auf die Buchstaben OHNE Umlaute und ß sowie >> die Zahlen beschränken. Als Sonderzeichen nur Bindestrich, Tiefstrich >> und den Punkt. > > Das ist für mich weniger ein Problem, aber sehe ich natürlich ein. Das war für mich auch nie ein Problem, bis ich damit auf die Nase fiel. Zwar in anderem Zusammenhang, aber es war mir eine deutliche Warnung, vorsichtig zu sein ( https://bugs.launchpad.net/kicad/+bug/1171160 ). ;O) Walter Tarpan schrieb: >> Was Du suchst ist eine digitale Entsprechung eines "Zettelkastens". >> Unter diesem Suchwort findest Du zahlreiche Ansätze und ihre Probleme. > > Vielen Dank für das Stichwort. zum thema zettelkasten: http://www.sciencegarden.de/content/2001-07/k%25C3%25BCnstliche-intelligenz-aus-holz Tomboy ist sowas ähnliches. Mit der Querverlinkung muss ich mich aber tiefer auseinandersetzten. Die macht es automatisch. aber nur, wenn ich passend formuliere. ;O) Klaus I. schrieb: >> Schau Dir mal Docear an (IMHO Open-Source, gefördert von deutschen >> Behörden, speziell dafür ausgelegt Papers zu schreiben). Soweit ich es >> sagen kann, sollte das Deinen Bedarf abdecken. Ich selbst verwende >> Docear seit einigen Jahren, nutze aber nur einen geringen Bruchteil der >> vorhandenen Funktionen. Ich habe ein paar Mindmaps, jedes neue >> abgespeicherte PDF-Dokument sehe ich im Incoming-Mindmap (Kommentare im >> PDF sollten IMHO auch berücksichtigt werden) und wird z.B. als >> Datenblatt im Mindmap "Bauteile" in der entsprechenden Kategorie >> rübergezogen. Für die Referenzierungen können ansonsten auch noch >> speziellere Lösungen eingebunden werden. Das hört sich auch für mich sehr gut an. Wäre einen Versuch wert. Mit freundlichem Gruß: Bernd Wiebus alias dl1eic http://www.dl0dg.de
Mike Klügel schrieb: > Klaus I. schrieb: >> Schau Dir mal Docear an ... Ich selbst verwende >> Docear seit einigen Jahren, nutze aber nur einen geringen Bruchteil der >> vorhandenen Funktionen. ... > > Hej, vielen Dank. Ein interessantes Programm! Von den Mindmaps, die sich > gerade im Freundeskreis stark verbreiten, war ich anfangs stark > begeistert. Mein erster Kontakt damit. Ich würde es so einschätzen, dass > es zu Projektbeginn sicher ein sehr nützliches Tool ist um schnell viele > Information ins Projekt einzubringen und zu strukturieren. Das auf jedem Fall! Ich lerne ja das Gebiet E-Technik auch gerade neu, und dafür ist es wirklich super. Aus dem Internet kann ich mit Copy&Paste ein paar Informationsschnippsel einfügen oder ein Bild abspeichern bzw. Links auf Websites oder lokale Dateien setzen. Und im Gegensatz zur handschriftlichen Mindmap kann man das ganz leicht wieder umsortieren bzw. störende grosse Zweige auch Ausblenden. In meinen Augen sollte man sich auch nicht von den Versprechen, bzgl. Mindmaps blenden lassen. Dein Eindruck scheint mir schon richtig zu sein, Mindmaps sind wirklich gut wenn man noch keine Struktur erkennen kann und einfach erstmal sammelt und einen Überblick gewinnen möchte. Nur als Beispiel, mein Inventar für Bautteile (so es nicht Standardbauteile in Sortimentsboxen sind) ist eine Excel-Liste mit simpler Filterfunktion. Unter uns gesagt: Ich nutze Mindmaps nur am PC. Früher habe ich mir immer auf einem DIN-A-4 Blatt (meist auch noch hochkannt verwendet ;o) ) immer an unterschiedlichen Stellen die zum Thema passenden Notizen hingekritzelt. Ich hoffe, da bin ich nicht der einzige. Ich denke Du hast das schon richtig erkannt. Mit Docear werden hinzugefügte Kommentare bei PDF-Dateien erfasst und können dann einfach dem jeweiligen Projekt rüber-gezogen bzw. mehrfach verwendet werden. Das braucht aber auch wirklich seine Zeit. Ich habe gerade getestet: Bei 420 Dateien (hauptsächlich PDF) mit 14 Unterordner mit insgeamt 524 MB dauert ein einfacher Suchlauf, ohne das irgendetwas hinzugefügt wurde, schon eine gute halbe Minute. Wenn Du so große Projekte hast, könnte das wirklich schwierig werden. Mit den Funktionen wie Literatur-Datenbank usw. habe ich mich dabei noch gar nicht beschäftigt. Ansonsten würde es mich aber sicherlich interessieren, wenn Du hier noch selbst noch nach Deiner Suche, Hinweise auf interessante Systeme berichtest. Das ist ja kein Njörd-Thema mit W20-Würfeln ;o)
Bernd Wiebus schrieb: > Das hört sich auch für mich sehr gut an. Wäre einen Versuch wert. Für die einfachen Sachen ist es wirklich gut in meinen Augen. Auf jeden Fall vielen Dank für Deine Beiträge hier. Z.B. das mit der Unterschätzung der Alphanumerik lernt man ja erst mal so richtig schätzen, wenn man mal z.B. von einem System auf das andere umgestiegen ist oder umsteigen mußte. Ich denke, ich werde meinen Dateien ein paar gute Präfixe spendieren. Noch ist das für mich ja übersichtlich. Beste Grüße Klaus
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.