Guten Morgen zusammen,
ich bin gerade wieder Anfänger geworden und mache (seit gestern abend)
meine ersten Gehversuche mit einem STM32F4discovery, CooCoxIDE und
ARM-GCC. Es interessant, wie kitzlig so ein Cortex im Vergleich zum AVR
ist.
Dabei hangele ich mich am folgenden Tutorial entlang:
http://mystm32.de/doku.php?id=arm_interrupts_in_c
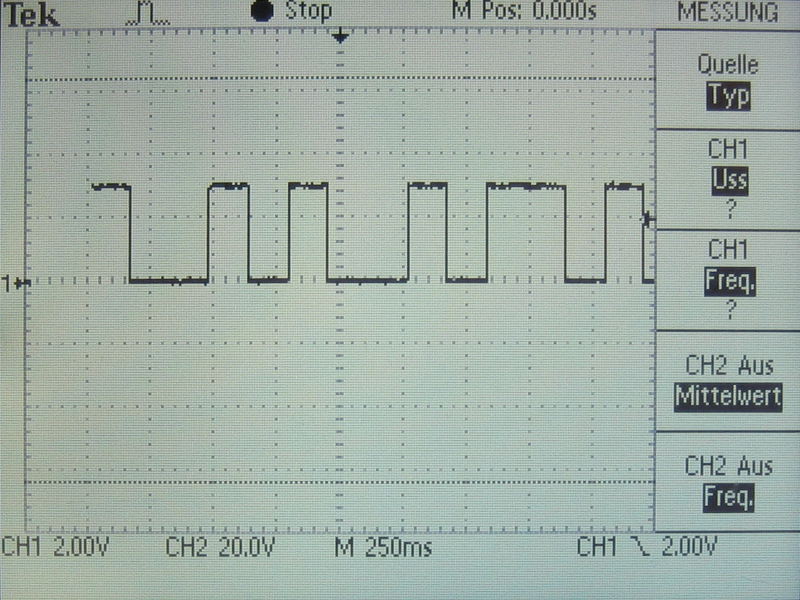
Mit dem Timer TIM7 wird eine LED getoggelt. Wie man auf dem Oszi-Bild
sieht, entstehen dabei riesige zeitliche Abweichungen, als würden
Interrupts vergessen. Daran ändert sich auch nichts, wenn ich bei
Ändert sich etwas, wenn die Interrupts ausgeschaltet werden?
etwa so:
// ISR für Timer 7
void TIM7_IRQHandler() {
__disable_irq();
GPIO_ToggleBits(GPIOD,GPIO_Pin_15); // blinkt unregelmaessig
TIM_ClearITPendingBit(TIM7,TIM_IT_Update);
__enable_irq();
}
Man sollte den Interrupt nicht erst am Ende der ISR zurücksetzen. Man
riskiert sonst, dass die ISR sofort erneut aufgerufen wird, weil es ein
paar Takte dauert, bis sich dies bis zum Prozessor rumspricht.
Stell das Skope mal auf Pulsbreitentrigger unterhalb 10µs ein und schau
an, ob es bei Pin 15 fündig wird. Könnte mir denken, dass sowas
mittendrin in den langen Phasen auftritt.
änge schrieb:> Sperrt Deine GIOToggleBits die Interrupts?
Yep, es wär sehr gut möglich, dass hier ein Konflikt dank nicht atomarem
Portzugriff auftritt.
Edit: Typisch ST-Lib. Mal wieder zu kurz gedacht:
GPIOx->ODR ^= GPIO_Pin;
Das geht natürlich gelegentlich schief.
Besser wär:
GPIOx->BSRR = (GPIO_Pin << 16) | ((GPIOx->ODR & GPIO_Pin) ^ GPIO_Pin);
Das lässt alle anderen Pins garantiert unberührt.
>Yep, es wär sehr gut möglich, dass hier ein Konflikt dank nicht atomarem>Portzugriff auftritt.
Ein Exor auf ODR ist nun mal nicht atomar.
>entstehen dabei riesige zeitliche Abweichungen, als würden>Interrupts vergessen.
Es wird kein Interrupt vergessen.
Das schnelle toggeln in der main ist das grösste Problem.
Sonst wäre der Fehler möglicherweise nur sporadisch aufgetreten.
while(1) {
GPIO_ToggleBits(GPIOD,GPIO_Pin_13); // blinkt
}
Wenn GPIO_ToggleBits(GPIOD,GPIO_Pin_13); vom Interrupt
unterbrochen wird und dieser seinerseits am selben Port
Bits ändert, kann es dazu kommen das diese Änderung gleich
nach dem Interrupt von GPIO_ToggleBits(GPIOD,GPIO_Pin_13);
wieder rückgängig gemacht wird.
Man sollte dieses Stück Code am besten gleich als warnendes
Beispiel für andere archivieren;)
Danke für die zahlreichen Rückmeldungen. Gestärkt von einem guten
Mittagessen werde ich die mal Stück für Stück abarbeiten:
A. K. schrieb:> Stell das Skope mal auf Pulsbreitentrigger unterhalb 10µs ein und schau> an, ob es bei Pin 15 fündig wird. Könnte mir denken, dass sowas> mittendrin in den langen Phasen auftritt.
Treffer! Mein Scope hat leider keinen Pulsbreitentrigger, aber es treten
Pulsereignisse mit nur 1ms Länge auf - ob die in der Mitte der langen
Phasen liegen kann ich nicht messen.
änge schrieb:> Sperrt Deine GIOToggleBits> die Interrupts?
Kann ich auf Anhieb nicht sagen, über die zahlreichen Funktionen, die
die ST-Library mitbringt habe ich noch keine Übersicht- und alle
Interrupt-Schalter kenne ich auch noch nicht, könnte also auch nicht aus
dem List-File mit Sicherheit ausschlißen, daß da eine Interruptsperre
drin ist.
A. K. schrieb:> Man sollte den Interrupt nicht erst am Ende der ISR zurücksetzen. Man> riskiert sonst, dass die ISR sofort erneut aufgerufen wird, weil es ein> paar Takte dauert, bis sich dies bis zum Prozessor rumspricht.
Das wird der nächste Versuch.
Walter Tarpan schrieb:> Das wird der nächste Versuch.
Solltest du tun. Aber die Ursache ist das weder atomare noch
abgesicherte XOR auf ODR in der Toggle-Funktion. Das ist ein absolutes
NoGo.
Walter Tarpan schrieb:> A. K. schrieb:>> Man sollte den Interrupt nicht erst am Ende der ISR zurücksetzen. Man>> riskiert sonst, dass die ISR sofort erneut aufgerufen wird, weil es ein>> paar Takte dauert, bis sich dies bis zum Prozessor rumspricht.>> Das wird der nächste Versuch.
Das Rücksetzen an den Anfang halbiert die Länge der sporadischen Peaks
auf 500ns Länge.
holger schrieb:> Ein Exor auf ODR ist nun mal nicht atomar.A. K. schrieb:> Edit: Typisch ST-Lib. Mal wieder zu kurz gedacht:> GPIOx->ODR ^= GPIO_Pin;> Das geht natürlich gelegentlich schief.>> Besser wär:> GPIOx->BSRR = (GPIO_Pin << 16) | ((GPIOx->ODR & GPIO_Pin) ^ GPIO_Pin);> Das lässt alle anderen Pins garantiert unberührt.
Neee, oder? OK, das Dingen ist wirklich deutlich kitzliger als ein AVR.
Ich habe noch viel zu lernen.
Vielen Dank für die Rückmeldungen!
Walter Tarpan schrieb:> Neee, oder? OK, das Dingen ist wirklich deutlich kitzliger als ein AVR.
An dieser Stelle nicht. Wenn du beim AVR
PORTA ^= 1;
schreibst, dann kriegst du exakt das gleiche Problem. Und müsstest es
durch
PINA = 1;
ersetzen, was aber z.B. beim Mega16 noch nicht möglich ist.
Nur die Sache mit dem Rücksetzen vom Int-Flag ist einfacher.
A. K. schrieb:>> Besser wär:> GPIOx->BSRR = (GPIO_Pin << 16) | ((GPIOx->ODR & GPIO_Pin) ^ GPIO_Pin);> Das lässt alle anderen Pins garantiert unberührt.
Merkwürdig. Das Reference Manual sagt, der Port hätte ein BSRR-Register,
der Compiler ist anderer Meinung:
"error: 'GPIO_TypeDef' has no member named 'BSRR'"
Ist da die ST-Lib unvollständig oder will sie mich als Benutzer da nicht
ranlassen?
Aber das sieht jetzt gut aus mit
GPIO_SetBits(GPIOD,(GPIO_Pin_13 << 16) | ((GPIOD->ODR & GPIO_Pin_13) ^
GPIO_Pin_13));
Was aber nach meinem Geschmack ist daß so das Setzen beliebig vieler
Bits in einem Port atomar ist.
Walter Tarpan schrieb:> "error: 'GPIO_TypeDef' has no member named 'BSRR'"
Schönes Beispiel dafür, wie 2 Leute in der gleichen Firma gegeneinander
arbeiten. Da hat der Hardware-Designer eine gute Idee gehabt, die der
Autor des Include-Files wieder zunichte machte. Das BSRR Register ergibt
nämlich in seiner Auslegung sehr viel Sinn, gerade weil man dessen beide
Hälften zusammen atomar schreiben kann. Eben deshalb sind die Ports der
STM32 16 Bits breit, nicht 32 Bits.
Nur mit dem vollständigen BSRR kann man mehr als ein Bit in einem Port
atomar auf einen beliebigen Wert setzen:
GPIOx->BSRR = mask << 16 | value;
Aber nein, da musste der Autor natürlich die Hälften wieder trennen,
weil er diesen Aspekt überhaupt nicht verstanden hat. Siehe
Beitrag "STM32 - Nerviger Bug in "stm32f4xx.h""
Anno STM32F1 konnte er den Fehler noch nicht machen, denn da waren
16-Bit Zugriffe auf die GPIO Register unzulässig. Kaum bekam er mit dem
Redesign des GPIO auf AHB statt APB die Chance...
Walter Tarpan schrieb:> Aber das sieht jetzt gut aus mit> GPIO_SetBits(GPIOD,(GPIO_Pin_13 << 16) | ((GPIOD->ODR & GPIO_Pin_13) ^> GPIO_Pin_13));
Erstaunlich. Denn GPIO_SetBits interessiert sich nur für die unteren 16
Bits und schreibt nur BSRRL. Pin 13 wird darin also entweder gesetzt,
oder unverändert gelassen, nirgends aber gelöscht.
Ich gehe davon aus, dass nun zwar Pin 15 in konstantem Zeitraster
toggelt, nicht aber Pin 13.
Mit der Lib geht eigentlich nur
if (GPIO_ReadOutputData(GPIOD) & GPIO_Pin_13)
GPIO_ResetBits(GPIOD, GPIO_Pin_13);
else
GPIO_SetBits(GPIOD, GPIO_Pin_13);
Du solltest zudem beachten, dass dieser Konflikt auch zwischen den
beiden Timer-Interrupts auftreten kann, sofern die nicht in der gleichen
premption priority liegen. Nur sehr viel unwahrscheinlicher.
A. K. schrieb:> Man sollte den Interrupt nicht erst am Ende der ISR zurücksetzen.
Warum denn das? Man setzt den erst IRQ dann zurück, wenn man mit der
Behandlung des IRQ fertig ist. Nicht eher. Zumindest wenn man darauf
Einfluss hat.
> Man> riskiert sonst, dass die ISR sofort erneut aufgerufen wird, weil es ein> paar Takte dauert, bis sich dies bis zum Prozessor rumspricht.
Ebend. Man müsste seine ISR (erst recht bei aktiviertem nested IRQ)
reentrant bauen.
Wenn die IRQ-Routine zu lang wird, um zwischen zwei Auslösungen die
main() zuzulassen, hat man an anderer Stelle was falsch gemacht.
Roland Ertelt schrieb:> Warum denn das? Man setzt den erst IRQ dann zurück, wenn man mit der> Behandlung des IRQ fertig ist. Nicht eher.
Wenn man Probleme kriegen will, nur zu.
> Ebend. Man müsste seine ISR (erst recht bei aktiviertem nested IRQ)> reentrant bauen.
Es geht nicht um verlorene Interrupts, sondern um doppelte
ISR-Aufrufe für dasselbe Ereignis.
Siehe Beitrag "STM32: Timer-ISR löst 2x aus - Fehler im Flag-Reset bei Optimierung O3"
A. K. schrieb:> Ich gehe davon aus, dass nun zwar Pin 15 in konstantem Zeitraster> toggelt, nicht aber Pin 13.
Stimmt. Nachdem die Interrupt-Geschichte so weit verstanden war, habe
ich das ad acta gelegt und bin zum nächsten Punkt weitergegangen - und
das war die Ansteuerung meines Grafik-LCDs (was auch mittlerweile
funktioniert). Jetzt bin ich gerade bei der Suche nach dem Äquivalent zu
"PROGMEM".
Es geht sozusagen weiter...
Siehe https://www.mikrocontroller.net/topic/goto_post/2700761
Die Set-Bits im BSRR haben übrigens Vorrang vor den Reset-Bits. Es
reicht also aus, in die obere Hälfte die Maske zu schreiben. Es muss
nicht das Komplement sein.
A. K. schrieb:> Die Set-Bits im BSRR haben übrigens Vorrang vor den Reset-Bits. Es> reicht also aus, in die obere Hälfte die Maske zu schreiben. Es muss> nicht das Komplement
Das verstehe ich nicht. Wenn ich die Pins von z.B. 4-12 mit einem Byte
beschreiben will, ohne die anderen Pins zu beeinflussen muß ich doch
sowohl die 1en setzen als auch die 0en löschen?
Walter Tarpan schrieb:> Das verstehe ich nicht. Wenn ich die Pins von z.B. 4-12 mit einem Byte> beschreiben will, ohne die anderen Pins zu beeinflussen muß ich doch> sowohl die 1en setzen als auch die 0en löschen?
Wenn du als Beispiel für 4 Datenbits ins BSRR den Wert 0x00F000F0
reinschreibst, also die gleichen 4 Bits sowohl setzt als auch löschst,
dann wird gesetzt. Also reicht
BSRR = 0x00F00000 | value << 4;
Wo ein Bit in value 0 ist wird gelöscht, bei 1 gesetzt. .
A. K. schrieb:> Wenn du als Beispiel für 4 Datenbits ins BSRR den Wert 0x00F000F0> reinschreibst, also die gleichen 4 Bits sowohl setzt als auch löschst,> dann wird gesetzt. Also reicht> BSRR = 0x00F00000 | value << 4;> Wo ein Bit in value 0 ist wird gelöscht, bei 1 gesetzt. .
Und das ganze atomic und auch per DMA ansteuerbar. Das hat ST gut
umgesetzt. Schon ein deutlicher Fortschritt gegenüber dem Atmega.
Nur muss man sich das halt einmal genau anschauen und sich dazu
durchreißen, diese dämlichen ST-Libs wegzuwerfen...
ich häng mich hier mal dran,
habe zwar langjährige Erfahrung im Programmieren von Firmware in C auf
8-Bit CPUs (Z180 und AVR), bin aber in Sachen ARM ebenfalls Anfänger mit
'nem STM32F407 unter CooCox IDE und ARM GCC in einem eigenen
Hardware-Design.
gibts da nicht auch 'ne Lösung, wie man das mit der ST-Lib hinbekommt?
Insbesondere vermisse ich beim ARM GCC ein Äquivalent zu den
ATOMIC-Makros, insbesondere ATOMIC_BLOCK(ATOMIC_RESTORESTATE) die es
beim AVR-GCC gibt...
gibt's da nichts Vergleichbares oder hab ich es nur nicht gefunden?
Die ST-Lib finde ich als ARM-Einsteiger an sich gar nicht schlecht, da
sie einem eine standardisierte Schnittstelle zur Peripherie liefert,
ohne daß man sich mit jedem einzelnen Bit in jedem Config-Register zu
Fuß beschäftigen muß.
Thorsten S. schrieb:> gibts da nicht auch 'ne Lösung, wie man das mit der ST-Lib hinbekommt?
Mit der unveränderten Lib m.E. nur so, wie ich oben beschrieb.
Also per if...else...
> Insbesondere vermisse ich beim ARM GCC ein Äquivalent zu den> ATOMIC-Makros, insbesondere ATOMIC_BLOCK(ATOMIC_RESTORESTATE) die es> beim AVR-GCC gibt...
Es ist ein Unterschied, ob man eine Lib aus der Erfahrung heraus
schreibt und weiterpflegt, oder als Anfängerpraktikum. Dieses
ATOMIC-Zeug war ausserdem in der avrlibc auch nicht von Anfang an drin.
Es halbwegs Gesunder wäre auch nicht auf die Idee gekommen, bei einem
Prozessor mit exzellenter Parametrisierung von Funktionen über Register
ausgerechnet zeilenschindend per Struct zu parametrisieren. Sowas macht
jemand, der als Vorbild die Lib eines Akkumulator-Prozessors wie STM8
hat.
Für mangelndes Verständnis spricht auch, dass im Code für die UART
anfangs eine Konstante 0x64 stand, erkennbar aber 100 gemeint war und
ausserdem eine Zweierpotenz besser gewesen wäre. Das ist eigentlich nur
erklärbar, wenn der Code ohne jedes Verständnis aus disassemblierten
Objektcode rausgelesen wurde.
> gibt's da nichts Vergleichbares oder hab ich es nur nicht gefunden?
In der Lib nicht. Im Prozessor ist es relativ elegant über
BASEPRI/BASEPRI_MAX realisierbar.
> ohne daß man sich mit jedem einzelnen Bit in jedem Config-Register zu> Fuß beschäftigen muß.
Das musst du spätestens dann doch tun, wenns nicht gleich funktioniert
und du per Debugger in die Register siehst.
A. K. schrieb:> Roland Ertelt schrieb:>> Warum denn das? Man setzt den erst IRQ dann zurück, wenn man mit der>> Behandlung des IRQ fertig ist. Nicht eher.>> Wenn man Probleme kriegen will, nur zu.>
Bisher hatte ich da nie Probleme. Bis auf, dass man uU einen IRQ
"verschläft", weil er erneut auslösen würde, bevor der Erste fertig ist.
Dann ist aber die ISR zu lang.
>> Ebend. Man müsste seine ISR (erst recht bei aktiviertem nested IRQ)>> reentrant bauen.>> Es geht nicht um verlorene Interrupts, sondern um /doppelte/> ISR-Aufrufe für dasselbe Ereignis.>
"Doppelte" Interrupts gibt es nicht. Zumindest wenn man keinen Mist mit
Back-Calls macht. Wie soll das auch gehen, wenn der Prozessor noch im
privilegierten IRQ-Modus ist, und man ihn (noch) nicht wieder mit
"return from interrupt" (reti) freigegeben hat. Im schlimmsten Fall wird
die ISR sofort nach dem reti wieder aufgerufen.
> Siehe Beitrag "STM32: Timer-ISR löst 2x aus - Fehler im Flag-Reset bei Optimierung O3"
Das dort zitierte Phänomen ist ein Kompiler(optimierungs)fehler. Dafür
kann der ARM nix, wenn der Kompiler ein "reti" setzt, und vorher das
"clear flag" wegoptimiert. Der ARM macht in dem Fall alles richtig, nur
der Anwender dort hat offenbar nie ins Kompilat (assembler) geschaut
oder das Projekt simuliert. Sonst hätte er den Mist bemerkt.
Wenn der dortige OP das Projekt in asm geschrieben hätte, wäre sein
"Problem" gar nicht auftreten.
PS: Wer denkt, einen ARM (oder ein ähnliches MuC-System) programmieren
zu können, ohne sich mit Assembler und den Prozessorregistern
beschäftigen zu müssen, irrt schwer.
Roland Ertelt schrieb:> Bisher hatte ich da nie Probleme. Bis auf, dass man uU einen IRQ> "verschläft", weil er erneut auslösen würde, bevor der Erste fertig ist.> Dann ist aber die ISR zu lang.
Ist es nicht so, wenn man schon zu Beginn der ISR Routine das ISR Flag
löscht und dann wenn die Hardware dieses Flag während der ISR
Bearbeitung erneut setzt, dann würde doch nach beenden der aktuellen
Bearbeitung diese gleiche ISR Rourtine erneut gestartet werden.
So verstehe ich zumindest das ISR Handling der Prioritäten.
Damit sollte auch nichts verloren gehen.
Roland Ertelt schrieb:> Wenn der dortige OP das Projekt in asm geschrieben hätte, wäre sein> "Problem" gar nicht auftreten.
Hmmm....also ich habe auf dem AVR vor der Migration 4627 Zeilen C-Code.
Wenn ich den wirklich komplett in ASM neu implementieren müßte, hätte
ich tatsächlich nicht das Problem mich über Interrupts zu ärgern- dann
wäre ich noch daran beschäftigt, beide ARM-Codes zu lernen.
Ich will mich ja nicht davor drücken Register und
Implementierungsdetails zu lernen - aber bei der Prozessorgröße ist für
mich die Grenze, wo eine Hochsprache geeigneter als Assembler erscheint
deutlich überschritten.
Walter Tarpan schrieb:> ich bin gerade wieder Anfänger geworden und mache (seit gestern abend)> meine ersten Gehversuche mit einem STM32F4discovery, CooCoxIDE und> ARM-GCC...
...UND mit der ST-Lib. Das hattest du nicht erwähnt.
Glaub mir, diese Kombination ist zum Einsteigen nicht wirklich die beste
Wahl. Leg dir zum absoluten Anfang lieber ne Demo-Version vom Keil zu
und verzichte auch erstmal auf die gesamte ST-Lib. Da weißt du, daß der
Compiler wirklich keinen Mist baut und du merkst schon bald, daß es in
fast allen Fällen leichter ist, aus eigenr Kraft mit dem µC klar zu
kommen, als wenn du zwischen deine Ideen und Hardware noch so eine
aufgebauschte Pseudo-Abstraktionsschicht zwischenschaltest.
Wenn dann deine Projekte mal größer werden, kannst du mit dem dann
angesammelten Wissen immer noch auf GCC umsteigen. Aber dann hast du
hoffentlich bereits deine eigenen ausgetesteten Sourcen und wenn es dann
Späne macht, weißt du, daß es am GCC und/oder der ST-Lib liegt - sofern
du sowas dann überhaupt noch benutzen willst.
> Es interessant, wie kitzlig so ein Cortex im Vergleich zum AVR> ist.
Nö. Die Cortexe sind überhaupt nicht kitzlig, man sollte sie bloß ein
bissel verstehen. Und nochwas: Verzichte lieber auf den Gedanken, sowas
wie EnableInt() oder DisableInt() benutzen zu wollen. Genau dann, wenn
du glaubst, sowas jetzt mal dringend zu benötigen, hast du nen schweren
Entwurfsfehler gemacht.
W.S.
>Verzichte lieber auf den Gedanken, sowas>wie EnableInt() oder DisableInt() benutzen zu wollen. Genau dann, wenn>du glaubst, sowas jetzt mal dringend zu benötigen, hast du nen schweren>Entwurfsfehler gemacht.
Zeig uns ein Beispiel grosser Meister!
@Roland: Jetzt geht das Märchen mit dem vermeintlichen Compilerfehler
wieder los. Der IF-Reset Befehl wird nicht wegoptimiert. Er ist nur zu
dicht am Return. Wegoptimiert würde die ISR in eine Dauerschleife
laufen, statt 2x ausgeführt.
@MM: Korrekt. Für die Funktion der ISR selbst ist nicht relevant, ob das
IF am Anfang oder am Ende zurück gesetzt wird.
Markus Müller schrieb:> Roland Ertelt schrieb:>> Bisher hatte ich da nie Probleme. Bis auf, dass man uU einen IRQ>> "verschläft", weil er erneut auslösen würde, bevor der Erste fertig ist.>> Dann ist aber die ISR zu lang.>> Ist es nicht so, wenn man schon zu Beginn der ISR Routine das ISR Flag> löscht und dann wenn die Hardware dieses Flag während der ISR> Bearbeitung erneut setzt, dann würde doch nach beenden der aktuellen> Bearbeitung diese gleiche ISR Rourtine erneut gestartet werden.> So verstehe ich zumindest das ISR Handling der Prioritäten.> Damit sollte auch nichts verloren gehen.
Das ist korrekt. Zumindest wenn man bei dem ARM den "nested Interrupt"
nicht nutzt wird es so passieren.
Daher verstehe ich ehrlich gesagt das Gesabbel über "doppelte
Interrupts" nicht.
Dass man die Flags erst am Ende der Routine löscht, ist mehr ein Zeichen
des Programmierers:
Hier bin ich damit fertig, jetzt kommt das Nächste.
Und es ist (m)eine Angewohnheit aus Software-IRQs von rtOS-en. Damit
umgeht man wie schon gesagt das Problem, dass man reentrant schreiben
müsste.
Es gibt noch die Unwarscheinlichkeit, dass irgend ein Bug im Kern beim
löschen des Flags andere Teile des Subsystems ändert. Daher fasse ich zu
Ändernde Werte immer erst dann an, wenn es wirklich nötig wird.
Man muss nur mal di diversen Errata zu einigen Kernen lesen. Da wird
einem Übel...
A. K. schrieb:> @Roland: Jetzt geht das Märchen mit dem vermeintlichen Compilerfehler> wieder los. Der IF-Reset Befehl wird nicht wegoptimiert. Er ist nur zu> dicht am Return.
Hm. Das musst du jetzt mal genauer erklären. Wie kann eine Befehl "zu
dicht" an einem andern stehen? Eine CPU ist kein Azubi, der früh immer
etwas länger braucht bis ers schnallt.
Und selbst wenn der Befehl "zu dicht" am Return steht, ist es trotzdem
ein Kompilerfehler. Denn wenn es ein "zu dicht[1]" gibt, muss der
Kompiler das berücksichtigen.
Roland
[1]Auch in einer echten Multi-Tread-Umgebung muss der Kompiler korrekt
berücksichtigen, dass ein Flag löschen uU mehrere Taktzyklen dauert und
darf die Ausführung des "reti" unter keinen Umständen vor der korrekten
Ausführung der letzten Instruktion umsetzen.
>Hm. Das musst du jetzt mal genauer erklären. Wie kann eine Befehl "zu>dicht" an einem andern stehen? Eine CPU ist kein Azubi, der früh immer>etwas länger braucht bis ers schnallt.
Das zurücksetzen des Interruptflags dauert unter Umständen
etwas länger. Wenn man die Interruptroutine verlässt
bevor das Flag zurückgesetzt ist wird der Interrupt noch
einmal aufgerufen. Das ist das Problem.
@Roland: Er kann es nicht berücksichtigen, weil das keine Eigenschaft
des Prozessors ist, sondern des Gesamtsystems. Und weil er nicht wissen
kann, was der Store bedeutet. Compiler sind nicht allwissend.
A. K. schrieb:> @Roland: Er kann es nicht berücksichtigen, weil das keine Eigenschaft> des Prozessors ist, sondern des Gesamtsystems. Und weil er nicht wissen> kann, was der Store bedeutet. Compiler sind nicht allwissend.
Doch, das kann (muss) er wissen. Zumindest wenn er nach Zeit optimieren
können will, muss er sehr genau die Ausführungszteiten der einzelnen
Maschinen/Assemblerbefehle kennen. Wie sonst will er ein Loop-Unrolling
beurteilen?
Das Problem ist dort wie überall: Es muss ausgiebig getestet werden. Bei
gcc macht dass der "Kunde". Dort ist das Feedback, gelinde gesagt,
mangelhaft. Zumal 75% der Anwender nicht mal in der Lage sind einen
Kompilerfehler zu erkennen und korrekt ans Entwicklerteam zu melden.
Deswegen bekommen es ja auch einige Kompiler sauber hin, während andere
dabei scheitern.
>Doch, das kann (muss) er wissen. Zumindest wenn er nach Zeit optimieren>können will, muss er sehr genau die Ausführungszteiten der einzelnen>Maschinen/Assemblerbefehle kennen. Wie sonst will er ein Loop-Unrolling>beurteilen?
Der Compiler kennt aber nicht die Zeiten bis ein Befehl an der
Peripherie angekommen ist. Die Peripherie ist kein Bestandteil der CPU.
holger schrieb:>>Doch, das kann (muss) er wissen. Zumindest wenn er nach Zeit optimieren>>können will, muss er sehr genau die Ausführungszteiten der einzelnen>>Maschinen/Assemblerbefehle kennen. Wie sonst will er ein Loop-Unrolling>>beurteilen?>> Der Compiler kennt aber nicht die Zeiten bis ein Befehl an der> Peripherie angekommen ist. Die Peripherie ist kein Bestandteil der CPU.
Urks. Was rauchen manche Leute..?
- Es ist ganz genau bekannt, wie lange eine Operation dauert.
- Es ist ganz genau bekannt, wie lange welcher Zugriff auf welche
Register dauert.
Daraus lässt sich korrekt errechnen, wie lange eine beliebige Operation
auf ein beliebiges Register der CPU/Peripherie (und beim ARM sogar auf
externe Speicherzellen im Nachbarchip) dauert.
Ich streite gar nicht ab, dass bei einigen Operationen Kombinationen
entstehen, welche selten (bei einigen Kompilern aus Zeitgründen gar
nicht) verifiziert werden. Das ist aber ein Problem des Kompilers, nicht
des Kerns.
Und ja, die Optimierungsstufe 3 "auf Zeit" ist bei allen Kompilern eine
Wundertüte.
Nein, es ist kein GCC Bug, der macht was ihm programmiert wurde.
Der GCC hat das Flag "-mcpu=cortex-m3" vom Cortex-M3 aber damit hat der
noch lange keine Ahnung ob es ein STM, NXP oder sonst was ist. Und der
müsste vor jedem "reti" noch "nop" hinzufügen, was auch nicht wirklich
sinnvoll ist. Woher soll GCC denn wissen dass der Befehl vor dem reti
das IF löscht?
Wenn ich z.B. zu Beginn die IF lösche und ich will/muss den ISR schnell
beenden, dann wären die "nop"s eher störend.
Das ist wohl auch kein Bug vom Cortex-Kern, denn der hat auch keine
Ahnung von der Peripherie die ST/NXP/... ran hängen
Da müssten ST/NXP/... schon her gehen und wissen, wenn ein IF gelöscht
wird, und der nächste Befehl ist ein reti, dass dann der reti so lange
pausiert bis das IF auch wirklich weg ist.
Optimierungen wie unrolling gehen von Annahmen aus, nicht von Fakten.
Worst case ist dabei eine höhere Laufzeit oder mehr Code als nötig. Das
Zeitverhalten von Interrupts, Peripherie oder DMA ist ausserhalb seiner
Sicht und es einzurechnen ist Sache des Programmierers.
A. K. schrieb:> Der Compiler weiss auch nicht, dass der Store das IF zurücksetzt. Woher> denn?
Muss er auch nicht. Er muss nur wissen wie lange es dauert bzw (und)
dass ein "store" auf Adresse "0xblab1a"[1] eine atomische Operation ist,
welche nicht durch ein "reti" (und ggf weitere Operationen) unterbrochen
werden darf.
Offenbar weiss das aber der gcc nicht, weil es ihm bisher niemand gesagt
hat.
Roland
[1]der jetzt zu faul ist, rauszusuchen an welcher Adresse das "IF"
tatsächlich liegt.
Das Laufzeitproblem tritt oft bei "toggle" auf.
Was wird programmiert: Ändere mal was, was am Ausgang rauskommt ist mir
egal.
Bei Systemen mit mehreren Task und Laufzeiten, ist das Verhalten so
doppelt nicht bestimmt.
Durch Auswertung einer Uhr ist es dann nicht mehr so schädlich, wenn das
Ausgangssignal doppelt gesetzt oder rückgesetzt wird.
A. K. schrieb:> Optimierungen wie unrolling gehen von Annahmen aus, nicht von Fakten.> Worst case ist dabei eine höhere Laufzeit oder mehr Code als nötig. Das> Zeitverhalten von Interrupts, Peripherie oder DMA ist ausserhalb seiner> Sicht und es einzurechnen ist Sache des Programmierers.
Die Zeiten sind schon lange vorbei. Das war Stand 2000 so...
Sorry Roland, aber dir hier eine Vorlesung über Compiler und
Rechnerarchitekturen zu halten überschreitet grad die Kapazität meines
Tabs. Glaub es oder lass es, aber von beidem habe ich etwas Ahnung.
>> Der Compiler kennt aber nicht die Zeiten bis ein Befehl an der>> Peripherie angekommen ist. Die Peripherie ist kein Bestandteil der CPU.>>Urks. Was rauchen manche Leute..?>>- Es ist ganz genau bekannt, wie lange eine Operation dauert.
Es ist bekannt wie lange ein Assembler Befehl in der CPU dauert.
Wobei das bei ARM wohl auch noch gelogen ist.
>- Es ist ganz genau bekannt, wie lange welcher Zugriff auf welche>Register dauert.
Nein, eben nicht. Der Hersteller weiss wie lange das dauert.
Der Compiler kennt aber die Peripherie nicht.
Die Register der Peripherie hängen an unterschiedlichen
Bussen. AHBx, APBx. Der Compiler weiss nicht wie lange es dauert bis
dort Bits gesetzt, gelöscht wurden.
Genau genommen weiss der gar nicht das er gerade ein Interruptflag
löscht. Das ist für ihn nur ein Bit in einem Register das irgendwo
im RAM gemappt ist.
Roland Ertelt schrieb:> Wie kann eine Befehl "zu> dicht" an einem andern stehen? Eine CPU ist kein Azubi, der früh immer> etwas länger braucht bis ers schnallt.
Du vergißt ganz und gar die dahintersteckende Architektur:
Ein Peripherie-Core erzeugt ein Interruptsignal, das zum
Interrupt-Controller gelangt. Der verarbeitet es und interruptiert
seinerseits die CPU. Also muß nacheinander folgendes passieren:
1. der Peripherie-Core muß sein Signal wegnehmen
2. der Interrupt-Controller muß kapieren, daß die Sache erledigt ist
3. die CPU muß kapieren, daß die Behandlungsroutine zu Ende ist.
Zumeist tut man gut daran, 1. und 2, deutlich vor 3. zu erledigen.
Reentrant brauchr da GARNIX programmiert zu werden, denn die CPU weiß
ganz genau, ob der "RETI" dieses Interrupts schon gekommen ist oder
nicht und wird diesen Interrupthandler nicht ein zweites Mal starten,
solange er noch läuft.
W.S.