Hallo Leute,
"Kurze" Vorgeschichte zu der eigentlichen Frage:
Ich arbeite in einer Firma die unteranderem auch Software entwickelt,
wir sind ca. 40 Softwareentwickler, schwerpunkt liegt auf C/C++.
Da die Firma bereit ist, uns 2 Weiterbildungen pro Jahr zu beahlen,
haben wir uns mal einen C++-"Guru"/Dozenten eingeladen um mal zu sehen,
ob der uns was brauchbares erzaehlen kann. Das Ergebnis war ziemlich
ernuechtern.
Was ist passiert?
Der gute Mann hat erstmal einen auf ganz dicke Hose gemacht, und was
fuer ein toller super Typ er doch sei, er sei ja seit Jahren
C++-Entwickler fuer Serverprogramme und hoch parallelisierte Prozesse
bla bla.
Dann wollte er unseren Wissensstand pruefen, um zu wissen wo er denn mit
seiner Schulung ansaetzen koenne. Der Typ hatte tatsaechlich eine Art
Klausur vorbereitet. Naja, die erste Aufgabe haben wir mal gemacht, die
Aufgabestellung war in etwa:
"Schreiben sie eine Funktion, die ein Array in ein anderes Array
kopiert, und das ganze moeglichst effektiv"
Gut, nichts wildes soweit, moechte man denken. Wir also alle in etwa
sowas geschrieben:
1
voidcopy(int*src,int*dst,intelements)
2
{
3
for(inti=0;i<elements;i++)
4
dst[i]=src[i];
5
}
Dann kam Herr "Ich-weiss-alles-ueber-C++-und-ihr-seid-alle-dumm" und hat
ne kleine Standpauke gehalten:
bla bla, ihr seid alle dumm, bla bla bla, sie denken gar nicht in C++,
bla bla, sie sind alle schlecht, bla bla bla, da muessen wir bei den
grundlagen anfangen, bla bla, und hier die "richtige Loesung" der
Aufgabe:
1
voidcopy(int*src,int*dst,intelements)
2
{
3
for(inti=0;i<elements;i++)
4
*dst++=*src++;
5
}
(ueber den schleifen typ kann man streiten)
"Das ist viiieeeeel effektiver, der Geschwindigkeitsvorteil gegenueber
der Index-Variante ist mindestens Faktor 3. Bei der Index-Variante muss
ja bei jeder Zuweisung zweimal die neue Adresse berechnet werden, was ja
die ALU beansprucht und das kostet Zeit. Den Zeiger einfach Hochzaehlen
passiert nebenbei, das ist viel schneller."
Ende der Vorgeschichte
So, diese Geschichte zum Geschwindigkeitsvorteil hat mir keine Ruhe
gelassen und ich hab es jetztmal getestet.
Umgebung:
Atmel Studio 6.2
AVR GCC 4.8.1
AVR Projekt (Mega 2560)
Compilerflags: -O0 -g3 -std=gnu99 -Wall -Wextra
Atmel Studio Simulator
So, bei meinem Code-Beispiel, verhaelt es sich jetzt aber genau
andersherum, als der Herr C++-Guru uns erzaehlt hat, zumindestens laut
dem Simulator des Atmel Studios. Bis zum Breakpoint braucht das
Programmm 4,445ms zu 4,570ms, immerhin mehr als 0,1ms unterschied.
So, jetzt die eigentlichen Fragen:
Stimmt das, was uns der werte Herr da zum Geschwindigkeitsvorteil
erzaehlt hat prinzipiel und das liegt hier jetzt einfach daran das ich
es mit dem AVR-Simulator getestet habe, oder ist das Grundsaetzlicher
bloedsinn was uns da erzaehlt wurde?
Ich hoffe Ihr koennt etwas Licht ins dunkel bringen :-)
Kaj schrieb:> Stimmt das, was uns der werte Herr da zum Geschwindigkeitsvorteil> erzaehlt hat prinzipiel und das liegt hier jetzt einfach daran das ich> es mit dem AVR-Simulator getestet habe, oder ist das Grundsaetzlicher> bloedsinn was uns da erzaehlt wurde?
weder noch.
Das ganze ist abhängig von dem Compiler. Je besser der Compiler desto
kleiner sind die unterschiede. Im Idealfall kommt sogar der gleiche Code
raus.
Seine Aussage könnte als durchaus auf einen Compiler zutreffen, pauschal
ist es aber falsch.
Kaj schrieb:> und hier die "richtige Loesung" der> Aufgabe:void copy(int* src, int* dst, int elements)> {> for(int i = 0; i < elements; i++)> *dst++ = *src++;> }
damit hätte man gleich Kontern können.
Denn es ist langsamer eine Variable von 0 bis irgendwas zu zählen als
andersrum.
1
copy(int*src,int*dst,intelements)
2
{
3
while(elements--)
4
*dst++=*src++;
5
}
und das spart sogar noch eine Variabel auf dem Stack.
(gilt alles nur ohne Optimierung vom Compiler)
Kaj schrieb:> void copy(int* src, int* dst, int elements)> {> for(int i = 0; i < elements; i++)> dst[i] = src[i];> }
Ich haette es so geschrieben:
memcpy(dst,src,elements * sizeof(int));
Ich dachte immer zwischen Pointern und Arrays gibt es keine
Unterschiede.
Das ist nur eine andere Schreibweise.
Zudem verbieten manche Standarts auch über Pointer zu iteriren.
Könnte mir jemand erklären warum das so ist?
Gruß
Peter II schrieb:> (gilt alles nur ohne Optimierung vom Compiler)
Dann brauchst du auch nicht über Geschwindigkeit zu reden.
Keiner würde sich einen Ferrari kaufen, um dann zu argumentieren,
dass der mit angezogener Handbremse langsamer ist als der Ford Fiesta.
... schrieb:> Ich dachte immer zwischen Pointern und Arrays gibt es keine> Unterschiede.> Könnte mir jemand erklären warum das so ist?
bei der 1.Version muss immer die Adresse neu berechnet werden, bei er
2.Version wird die Adresse immer nur um sizeof(int) erhöht.
schau dir beide Versionen in ASM-Code ohne Optimierung an.
> Stimmt das, was uns der werte Herr da zum Geschwindigkeitsvorteil> erzaehlt hat prinzipiel
Nein.
Bei gutem Compiler kommt derselbe Maschinecode bei raus.
Sein Beispiel ist auch kein C++, er hat offensihcltichlich von C++ nicht
die leiseste Ahnung und schreibt C Code und glaubt das wäre C++.
Bei C++ kopieren sich Elemente selbst.
Sein Array wäre ein Klasse. Um eine Klasse zu kopieren, braucht mal also
bloss
1
b=a
zu schreiben. Und das ist vom erzeugten Maschinencode her VIEL langsamer
als der entsprechende C Code, den du oben genannt hast. Denn je nach
dem, wie die Klasse intern die Integers speichert, möglichst basierend
auf einer dynamischen Datenstruktur mit Integers als serialisierbaren
KLassenelementen, werden dabei tausende von new's gemacht.
Daher sind C++ Programme auch meist grottenlangsam.
1. Das ganze mit C++ (gegenüber C) nichts zu tun.
2. Ein moderner Compiler mit eingeschalteter Optimierung dürfte da
wahrscheinlich keinen Unterschied produzieren.
3. Nach Jahrelanger Erfahrung mit Fortbildungen: Leider werden viel zu
viele Coaches Trainer Lehrer nachdem sie es im richtigen Berufsleben
zu nichts mehr bringen. Man lernt also viel zu häufig von Versagern,
häufig mit veraltetem Wissen. Es gibt natürlich Ausnahmen - aber die
sind selten und teuer.
MaWin schrieb:> zu schreiben. Und das ist vom erzeugten Maschinencode her VIEL langsamer> als der entsprechende C Code, den du oben genannt hast. Denn je nach> dem, wie die Klasse intern die Integers speichert, möglichst basierend> auf einer dynamischen Datenstruktur mit Integers als serialisierbaren> KLassenelementen, werden dabei tausende von new's gemacht.
Schwachsinn. Bei vernünftigen Implementationen, wie zB std::vector<int>,
wird 1x new und 1x memcpy gemacht, also exakt das gleiche wie in der
C-Variante.
Mir wurde mal glaubhaft beigebracht, dass bei der heutigen Komplexität
der Prozessoren ein guter Compiler deutlichen besseren Code erzeugt,
als händisches Optimieren.
Konkret ging es um einen TriCore, bei dem der Compiler z.B. die
Maschinenbefehle zur optimalen Auslastung der Pipeline umsortiert: Was
da an Assemblercode rauskam, war kaum noch nachzuvollziehen.
Unter dem Strich kam raus: Überlasst das Optimieren dem Compiler und
konzentriert Euch auf die Aufgabe!
Bronco schrieb:> Überlasst das Optimieren dem Compiler und> konzentriert Euch auf die Aufgabe!
muss sollte den Mittelweg finden. Man kann auch C/C++ so schlecht
schreiben das der Compiler es auch nicht mehr retten kann.
In der Theorie können das gute Compiler so optimieren, daß da kein
Unterschied ist.
In der Praxis kann das bei bestimmten Systemen viel ausmachen.
Aktuelles Beispiel hier bei uns in der Firma: Eine alte Sun mit einem
Gnu C++ Compiler. Standard copy ist bis zu Faktor 100! langsamer
gegenüber einem tricky Code. Problem da: Compiler optimiert nicht
ordentlich die Zugriffe auf ungerade Adressen, was bei dieser einen Sun
sich in extrem langsamen Speicherzugriffen auswirkt.
Aber portabel und lesbar ist anders.
Für gängige Systeme (PC, gängige µCs) sieht es deutlich besser aus, da
sind die Optimierungen normalerweise besser und kaum
Geschwindigkeitsunterschiede zu erzielen.
Punkt ist: Mach nur das schneller was wirklich zu langsam ist.
Bei modernen (großen) Anwendungen lassen sich in der Regel viel mehr
Zeit sparen indem man Schwachstellen in der Architektur findet, bessere
Parallelsierungen ermöglicht und bei Datenstrukturen (Hashtabellen,
clevere Bäume etc.) , File I/O und Datenbankzugriffen Grips investiert.
>> zu schreiben. Und das ist vom erzeugten Maschinencode her VIEL langsamer> als der entsprechende C Code, den du oben genannt hast. Denn je nach> dem, wie die Klasse intern die Integers speichert, möglichst basierend> auf einer dynamischen Datenstruktur mit Integers als serialisierbaren> KLassenelementen, werden dabei tausende von new's gemacht.>> Daher sind C++ Programme auch meist grottenlangsam.
Was natürlich kompletter Schwachsinn ist.
> Das Ergebnis war ziemlich ernuechtern.
Da muss ich dir zustimmen.
Leider glauben immer noch viel zu viele, durchaus auch Dozenten, dass
man Geschwindigkeit auf dieser unteren Ebene mit sogenannten
Mikrooptimierungen holen könne. Was die Leute geflissentlich ignorieren:
All diese Tricks kennen die COmpiler auch schon seit Jahrzehnten. Und
wahrscheinlich noch Dutzende andere, von denen der Dozent noch nie etwas
gehört hat.
Diesen sog. Guru hätt ich rausgeschmissen, gleich nachdem er die Aufgabe
eine Kopierfunktion zu schreiben gestellt hätte. Alleine die
Aufgabenstellung zeigt, dass er ein paar wesentliche Dinge nicht
begriffen hat, worauf es in der SW-Entwicklung ankommt.
Peter II schrieb:> Das ganze ist abhängig von dem Compiler. Je besser der Compiler desto> kleiner sind die unterschiede. Im Idealfall kommt sogar der gleiche Code> raus.
Dazu kommt noch, daß es auch von der Zielplattform abhängt. Schon
alleine auf Plattformen, die mehr als 8 Bit breit sind, bekommt man
Geschwindigkeitsvorteile daraus, wenn man nicht jedes Byte einzeln
kopiert. Dann gibt es außerdem noch Plattformen, bei denen es ganz
unterschiedliche Arten zum Kopieren gibt. Auf dem PC geht das bei
Programmen, die öfter Speicherblöcke schnell kopieren müssen, so weit,
daß sie beim Programmstart einen Performance-Test machen und dann später
die speziell auf diesem Rechner performanteste Variante benutzen.
... schrieb:> Ich dachte immer zwischen Pointern und Arrays gibt es keine> Unterschiede.> Das ist nur eine andere Schreibweise.
Ja, das ist richtig. p[i] ist zu 100% äquivalent zu *(p+i).
> Zudem verbieten manche Standarts auch über Pointer zu iteriren.> Könnte mir jemand erklären warum das so ist?
Bei der einen Variante wird der Pointer in jedem Schleifendurchlauf
inkrementiert, bei der anderen wird dagegen der Offset inkrementiert und
in jedem Schleifendurchlauf zum Pointer addiert. Das ist aber erstmal
nur die C-Ebene, die für die Performance völlig unerheblich ist. Wichtig
ist, was der Optimizer des Compilers daraus macht. Abgesehen davon gibt
es auf manchen Plattformen auch Instruktionen, denen man einfach direkt
den Pointer und den Offset übergeben kann und die dann nebenher ohne
zusätzlich Zeit zu verbrauchen, diese zusammenzählen können. Teilweise
kann dort das Inkrementieren eines speziellen Adressregisters auch
langsamer sein als das Inkrementieren eines allgemeinen Registers.
Also ist selbst ohne Optimizer und wenn der Compiler die C-Answeisungen
1:1 umsetzt keine sichere Aussage möglich, was schneller wäre.
Mit anderen Worten: Der Herr Guru erzählt Mist und sollte mal meditieren
gehen. Das kann er dann auf seinem Amiga tun, wo die Welt vielleicht
sogar noch so ist, wie er sie sich vorstellt.
Rolf Magnus schrieb:> p[i] ist zu 100% äquivalent zu *(p+i).
stimmt. Und da die Kommutativität der Addition gilt ist:
p[i] <==> *(p+i) <==> *(i+p) <==> i[p]
verwirrt aber eher den Leser.
> "Das ist viiieeeeel effektiver, der Geschwindigkeitsvorteil gegenueber> der Index-Variante ist mindestens Faktor 3. Bei der Index-Variante muss> ja bei jeder Zuweisung zweimal die neue Adresse berechnet werden, was ja> die ALU beansprucht und das kostet Zeit. Den Zeiger einfach Hochzaehlen> passiert nebenbei, das ist viel schneller."
Beim DSP mit extra Adressberechnungsunit (VLIW) hat er recht, da ist
pointer Inkrement besser als der Umweg über die ALU.
Halt eine Frage der CPU-Architektur, wahrscheinlich ist das schon bei
Harvard vers von Neumann unterschiedlich.
Bei so einem Waschmaschinencontroller wie dem AVR, der keine parallele
adressberechnung kennt (?) ist natürlich wurscht.
MfG,
Rolf Magnus schrieb:> ... schrieb:>> Ich dachte immer zwischen Pointern und Arrays gibt es keine>> Unterschiede.>> Das ist nur eine andere Schreibweise.>> Ja, das ist richtig. p[i] ist zu 100% äquivalent zu *(p+i).
Gilt dies den auch bei C++? Operatoren könnten ja überladen sein.
Nur mal ganz spitzfindig gefragt.
Oder?
Steffen Rose schrieb:> Rolf Magnus schrieb:>> ... schrieb:>>> Ich dachte immer zwischen Pointern und Arrays gibt es keine>>> Unterschiede.>>> Das ist nur eine andere Schreibweise.>>>> Ja, das ist richtig. p[i] ist zu 100% äquivalent zu *(p+i).>> Gilt dies den auch bei C++?
Bei Pointer: ja.
> Operatoren könnten ja überladen sein.> Nur mal ganz spitzfindig gefragt.
Du kannst aber nicht die [] Operation für Pointer oder int überladen.
D.h. beim gemeinsamen 'Subset' Pointeroperationen, ist das in C nicht
anders als in C++
Kaj schrieb:> Stimmt das, was uns der werte Herr da zum Geschwindigkeitsvorteil> erzaehlt hat prinzipiel
Ja, dem Prinzip nach, wenngleich nicht unbedingt vom Faktor her. Und
wenn man dazu in der Zeit zurück reist, so in die 80er Jahre oder davor,
als Compiler noch ungefähr das machten, was man hinschrieb.
Und auch dann hätte ich es nur akzeptiert, wenn er es so gemacht hätte:
1
voidcopy(int*src,int*dst,intelements)
2
{
3
for(int*limit=src+elements;src<limit;)
4
*dst++=*src++;
5
}
oder (manchmal) noch besser und stilistisch angepasst:
A. K. schrieb:> oder (manchmal) noch besser und stilistisch angepasst:
Ich bin mir jetzt gar nicht mal sicher, ob es in K&R C schon erlaubt
war, innerhalb von Blöcken neue Variablen zu definieren. Aus dem Bauch
raus würde ich sagen: Nein, die mussten alle am Anfang der Funktion
stehen.
Aber ansonsten fand ich die Formulierung "oder (manchmal) noch besser
und stilistisch angepasst" Klasse, um darauf hinzuweisen, dass das
eventuell mal so war, kurz nachdem wir von den Bäumen runter gekomen
sind :-)
Karl Heinz schrieb:> Ich bin mir jetzt gar nicht mal sicher, ob es in K&R C schon erlaubt> war, innerhalb von Blöcken neue Variablen zu definieren.
Ich meine schon. Das war beispielsweise nützlich, um in "switch"
Statements abschnittsweise verschiedene "register" Variablen nutzen zu
können. Die hätte ich eigentlich auch reinschreiben müssen. ;-)
Es ist aber ein anderer Fehler drin: "void".
Also:
Karl Heinz schrieb:> Ich bin mir jetzt gar nicht mal sicher, ob es in K&R C schon erlaubt> war, innerhalb von Blöcken neue Variablen zu definieren.
Ja. In meinem K&R steht zu mindest "nur am Anfang eines Blocks".
asdf schrieb:> Hat der Guru auch einen Namen? Ich kann gar nicht glauben, dass jemand> fuer C++ Performance auftritt und dann so einen Quatsch verzapft.
Die Geschichte ist bestimmt erfunden.
Mendax schrieb:> Die Geschichte ist bestimmt erfunden.
Glaube nicht. Eher noch untertrieben. Du ahnst ja gar nicht, wie viele
ausrangierte Möchtegerns sich als Lehrer oder Berater aufspielen.
Übrigens nicht nur in der IT...
Karl Heinz schrieb:> Ich bin mir jetzt gar nicht mal sicher, ob es in K&R C schon erlaubt> war, innerhalb von Blöcken neue Variablen zu definieren.
In der hier:
http://cm.bell-labs.com/cm/cs/who/dmr/cman.pdf
verlinkten Version der 6. Ausgabe von UNIX (1975) offenbar noch nicht,
später dann schon.
Jörg Wunsch schrieb:> verlinkten Version der 6. Ausgabe von UNIX (1975) offenbar noch nicht,> später dann schon.
Für Fans entsprechender Archäologie: In dieser Version gab es weder
"unsigned" noch "long", und es hiess a =+ 1 statt a += 1 (was bedeutet
"a=-1"? ;-). Dieser Sprachlevel steht im üblichen Verständnis noch vor
"K&R".
Kaj schrieb:> das ganze moeglichst effektiv
Ich hoffe mal das Ziel war es möglichst EFFIZIENT zu sein, effektiv ist
wohl jeder Ansatz der die Kopieroperation fehlerfrei durchführt ob es
jetzt 1ms oder 1 Jahr dauert...
Effizient & Effektiv ist dann die Verwendung von std::copy, zumindest
wenn man sich C++-"Guru" nennen will.
Und wenn std::copy zu langsam für einen speziellen Fall ist: einfach
eine neue Template-Specialization anlegen, notfalls mit Handgezimmertem
Inline-ASM.
C++-Antiguru schrieb:> notfalls mit Handgezimmertem Inline-ASM.
Handgezimmerter Assembler-Code für genau solche Aktionen ist mitunter
eher ineffizient, es sei denn man richtet sich nach dem Optimization
Guide des konkret verwendeten Prozessors in Abhängigkeit von der Grösse
der zu kopierenden Daten und hat das Glück, das es im Guide drinsteht
und dessen Inhalt zufällig auch stimmt. Optimal schneller Code dafür
kann nämlich bei Prozessoren jenseits der µC Klasse verteufelt
kompliziert sein.
Ich denke, das Beste wird sein, ihr kompiliert mal vor seinen Augen die
Beispiele und druckt den Code aus, damit ihr es schwarz auf weiß habt.
Interessant wird vor allem seine Reaktion sein.
Kannst ja mal posten, wie die Geschichte weiter ging. ;) Ist
wahrscheinlich auch unterhaltsamer als Compilerarchäologie.
Ich würds mit dem DMA Controller machen =;) und die CPU für was andres
benutzen da bin ich dann auch schneller.
Manche CPUs haben auch Lopp-Hardware drinn (Nen Loop Counter der
automatisch inkrementiert wird und nen Komparator) dadurch kann
gleichzeitig die Pipeline perfekt gefüllt werden bzw. Cache vorgeladen
da die Branch prediction Unit dann weiß wann wohin gesprungen wird(bei
manchen DSPs). Hängt also vom Compiler ab bzw. bei DMA usw. von den
Biblioteken die man benutzt und nicht vom C(++) Code.
uwe schrieb:> Ich würds mit dem DMA Controller machen =;)
DMA Controller sind nicht unbedingt für grosse Blocktransfers von
Speicher zu Speicher optimiert. Daher ist das oft der langsamste Weg.
Ganz besonders, wenn du versuchen solltest, das auch auf dem PC mit dem
DMA Controller zu erledigen. ;-)
> DMA Controller sind nicht unbedingt für grosse Blocktransfers von> Speicher zu Speicher optimiert.
Ist zwar etwas weg vom Thema aber...
Bei DSPs schon, die haben Dual ported RAMs bzw. Dual Access RAMs und
dann auch noch werschieden RAM bereiche (Blöcke) die einen jeweils
eigenen Adress und Datenbus und Adressberechnungeinheit(also Increment
und Offset und shifts werden von einer speziellen adressberechnung ALU
gemacht).
Die CPU kann also aus einem RAM lesen der automatisch inkrementiert wird
ohne die ALU der CPU zu benutzen gleichzeitig aus einem anderen RAM
lesen der automatisch dekrementiert wird, gleichzeitig verrechnen
gleichzeitig zurechshiften, gleichzeitig in einen anderen RAM schreiben
aus dem gleichzeitig der DMA Controller das Ergebnis ließt und irgendwo
hinschreibt, alles in einem Takt Die Daten die die CPU aus dem RAM
ausließt kommen natürlich von einem anderen Kanal des DMA Controllers.
Kaj schrieb:> und hier die "richtige Loesung" der> Aufgabe
... wenn man schon einen nicht optimierenden Compiler dazu bringen will,
optimierten Code zu erzeugen, darf man doch das Loop-Unrolling nicht
vergessen.
Ich hätte also mindestens was von diesem Kaliber erwartet:
@ A. K. (prx)
>> Ich würds mit dem DMA Controller machen =;)
Me too!
>DMA Controller sind nicht unbedingt für grosse Blocktransfers von>Speicher zu Speicher optimiert. Daher ist das oft der langsamste Weg.
Nanana, nimmst du den gurkisten DMA-Controller, denn du kennst als
Standard?
>Ganz besonders, wenn du versuchen solltest, das auch auf dem PC mit dem>DMA Controller zu erledigen. ;-)
Früher (tm), als es noch richtige Männer gab, die Mammuts mit der Keule
erlegten und Assembler programmierten, gab es mal einen coolen
Homecomputer namens Amiga. Der hatte u.a. einen Blitter (Block Image
Transferer). Der konnte rasend schnell Daten im RAM kopieren, deutlich
schneller als die CPU. Und wenn es sein sollte, nebenbei noch
Verschiebeoperationen und logische Verknüpfungen durchführen. Damit
wurden anno dazumal mordsmäßige Effekte erzeugt, die heute die meisten
GHz Maschinen in ihrem JAVA-Korsett nicht mal ANSATZWEISE hinkriegen! Es
ist sooo traurig. seufz Schön war die Zeit.
http://www.eevblog.com/2013/03/13/eevblog-438-amiga-500-retro-computer-teardown/
*Thumbs up!!!*
And last but not least läuft auch auf dem PC schon seit Ewigkeiten
DMA-Transfer, z.B. über den PCI-Bus!
Irgendwie bestätigt das mich in meinem Glauben, dass es auf der Welt
vielleicht 100 Leute gibt, die C++ wirklich können. Darum scharen sich
dann ein paar Tausend, die einen kleinen Teil von C++ brauchbar können,
und hunderttausende von Leuten die glauben sie seien die tollsten C++
Programmierer und in Wirklichkeit nichts können.
Christian Berger schrieb:> Irgendwie bestätigt das mich in meinem Glauben, dass es auf der Welt> vielleicht 100 Leute gibt, die C++ wirklich können. Darum scharen sich> dann ein paar Tausend, die einen kleinen Teil von C++ brauchbar können,> und hunderttausende von Leuten die glauben sie seien die tollsten C++> Programmierer und in Wirklichkeit nichts können.
Die wären mir noch soweit egal. Richtig schlimm wird es dann, wenn
einige dieser hunderttausend in die Lehre gehen (Uni, FH oder Schule)
oder Consulting betreiben. Diese Fälle sind nicht so selten, wie man
glauben könnte oder annehmen sollte.
Karl Heinz schrieb:> Die wären mir noch soweit egal. Richtig schlimm wird es dann, wenn> einige dieser hunderttausend in die Lehre gehen (Uni, FH oder Schule)> oder Consulting betreiben. Diese Fälle sind nicht so selten, wie man> glauben könnte oder annehmen sollte.
Ach, ich finde es schlimmer wenn die hunderttausend schlechten Code
produzieren. Ich bin ja für mich auf dem Standpunkt, dass ich zu blöd
bin C++ zu programmieren. Ich bin wohl keiner der paar Hundert Leute die
das können, und es ist nicht wahrscheinlich, dass ich innerhalb einiger
Jahre genügend Wissen und Erfahrung ansammeln kann, so weit zu kommen.
Somit ist das Thema C++ für mich persönlich beendet.
Christian Berger (casandro) schrieb:
> Ach, ich finde es schlimmer wenn die hunderttausend schlechten Code> produzieren. Ich bin ja für mich auf dem Standpunkt, dass ich zu blöd> bin C++ zu programmieren. Ich bin wohl keiner der paar Hundert Leute die> das können, und es ist nicht wahrscheinlich, dass ich innerhalb einiger> Jahre genügend Wissen und Erfahrung ansammeln kann, so weit zu kommen.> Somit ist das Thema C++ für mich persönlich beendet.
Und (wenn man fragen darf) wie lautet deine persönliche
Ausweichstrategie darauf, nun mit "ohne C++" auszukommen, in Bezug aufs
µC und PC programmieren?
Karl Heinz schrieb:> Richtig schlimm wird es dann, wenn> einige dieser hunderttausend in die Lehre gehen (Uni, FH oder Schule)> oder Consulting betreiben. Diese Fälle sind nicht so selten, wie man> glauben könnte oder annehmen sollte.
Das reicht doch vollkommen aus.
Ich war schon öfter auf Veranstaltungen, auf denen ich nahezu der
einzige war, den das interessiert hat. Der Rest war einfach auch mal mit
einem Lehrgang dran und hat von seiner Firma Arschbacken breitsitzen und
Spesen bezahlt bekommen.
Pech allerdings, wenn plötzlich alle was wissen und zu allem Überfluss
auch noch mehr wissen wollen und der Dozent völlig überfordert mit
dieser unbekannten Situation ist.
Aber davon wird der sich auch nicht entmutigen lassen.
mfg.
Optimal war (damals) der C-Compiler für die NS32000-Serie.
Das wurde dann direkt durch die CPU mit dem Befehl
MOVSi (Move String 1 to String 2)
gemacht und fertig.
Solche Op-Codes sind mir bis heute leider nicht mehr über den Weg
gelaufen.
War schon prima, was diese Prozessoren konnten.
NS32 schrieb:> War schon prima, was diese Prozessoren konnten.
Aber nur, bis man auf die Taktzyklenzahl des Befehls geguckt hat. :-)
Irgendwann hat man dann mal bemerkt, dass es mehr Sinn hat, dem
Compiler die Optimierung zu überlassen, statt mehrere Dutzend
Spezialfälle im Microcode „vorzuoptimieren“.
NS32 schrieb:> War schon prima, was diese Prozessoren konnten.
CISC to the max, nur NEC hatte es beim Versuch, die DEC VAX auf der
falschen Spur zu überholen, mit V70/V80 noch weiter getrieben. Solche
Befehlssätze sind zwar phantastisch für den Assember-Programmierer. Mir
ging es zunächst nicht anders. Das war jene Ära, in der einerseits die
CISCs prächtige hoffnungslos überladene Blüten trieben, und andererseits
die ersten RISCs (MIPS, ARM(!)) diesem barocken Schwulst abschworen.
So war die Codierung der Displacements zwar wunderbar platzsparend. Aber
sobald du in der Lage sein willst, einen Befehl pro Takt zu dekodieren,
geschweige denn mehrere, ist das ein Schuss in Knie. Motorola lief bei
dem Schritt von 68000/10 zu 68020 in eine ähnliche Falle und hat den
später verflucht.
Letztlich bewies NS damit nur, dass dieser Weg in die falsche Richtung
führte und der Aufwand für die Verarbeitung der Befehle und den ganzen
Microcode anderweitig besser investiert worden wäre. Auch, weil solche
Komplexität zu einer hässlichen Anzahl in Silizium gegossener Bugs
führt.
Naja, jeder halbwegs gescheite Compiler nutzt doch wahrscheinlich
sinnvollerweise eine handoptimierte Assemblerversion für memcpy(),
Spezialprozessoren gern auch DMA & sonstige Features. Womit die
Diskussion über Pointer vs. Index überflüssig wird.
Falk Brunner schrieb:> Naja, jeder halbwegs gescheite Compiler nutzt doch wahrscheinlich> sinnvollerweise eine handoptimierte Assemblerversion für memcpy(),
Wenn man freilich genau reinschaut, weil sich in der Anwendung
Optimierung an diese Stelle wirklich lohnt, und es nicht bloss um ein
paar Strings geht, dann wird man vielleicht mit nicht zum
Basisbefehlssatz gehörenden Befehlen, Prefetch, Cache-Hints etc. an die
Grenze der konkreten Hardware gehen wollen. Denn das bieten
Compiler-Runtimes aufgrund ihrer Unabhängigkeit von der exakt
eingesetzten CPU nicht unbedingt.
Kaj schrieb:> "Das ist viiieeeeel effektiver, der Geschwindigkeitsvorteil gegenueber> der Index-Variante ist mindestens Faktor 3. Bei der Index-Variante muss> ja bei jeder Zuweisung zweimal die neue Adresse berechnet werden, was ja> die ALU beansprucht und das kostet Zeit. Den Zeiger einfach Hochzaehlen> passiert nebenbei, das ist viel schneller."
Im Prinzip richtig.
> So, diese Geschichte zum Geschwindigkeitsvorteil hat mir keine Ruhe> gelassen und ich hab es jetztmal getestet.
Gute Idee!
>> Umgebung:> Atmel Studio 6.2> AVR GCC 4.8.1> AVR Projekt (Mega 2560)
Schlechte Wahl, nicht vergleichbar.
> So, jetzt die eigentlichen Fragen:> Stimmt das, was uns der werte Herr da zum Geschwindigkeitsvorteil> erzaehlt hat prinzipiel und das liegt hier jetzt einfach daran das ich> es mit dem AVR-Simulator getestet habe, oder ist das Grundsaetzlicher> bloedsinn was uns da erzaehlt wurde?
Ja die Begründung des Guru ist korrekt. Vorausgesetzt das Target hat
parallel zur ALU noch Module für die Adressberechnung kann es
tatsächlich
3 Operatione (1xALU+2xAdressincrement) in einem Maschinenzyklus
ausführen.
Das ist bei DSP gängig , da es Skalarprodukte wie bei Digitalen Filtern
deutlich beschleunigt. Bspw. SHARC: siehe
http://en.wikipedia.org/wiki/Very_long_instruction_word#Design
Da der Atmel AVR solche parallelen inkrement-Blöcke nicht hat, sondern
jede Berechnung über die ALU geht braucht dieser mind. 3 Taktzyklen.
Deine Test vergleichen also Äpfel mit Birnen.
> 2. Ein moderner Compiler mit eingeschalteter Optimierung dürfte da> wahrscheinlich keinen Unterschied produzieren.
Das ist leider nur ein frommer Wunsch wie diese Tests
http://nadeausoftware.com/articles/2012/05/c_c_tip_how_copy_memory_quickly
von 2012 anschalich zeigen. Bei diesen wurde speicher auf verschiedenene
Weisen kopiert darunter pointer,index und memcpy.
Würden die Compiler wirklich optimieren können wäre die Durchlaufzeit
für jeden Code gleich. Wie die Graphen zeigen ist dem nicht so. Gerade
mal der intel-compiler schafft das fast perfekt, der gcc liefert bei
memcpy oft schlechtere Ergebnisse als mit pointern.
MfG,
NS32 schrieb:> Solche Op-Codes sind mir bis heute leider nicht mehr über den Weg> gelaufen.
Naja, LDIR kannte der Z80 aber auch schon.
Jörg Wunsch schrieb:> Aber nur, bis man auf die Taktzyklenzahl des Befehls geguckt hat. :-)
Hehehe, darüber musste man beim Z80 dann auch nachdenken.
A. K. (prx) schrieb:
Falk Brunner schrieb:
>> Naja, jeder halbwegs gescheite Compiler nutzt doch wahrscheinlich>> sinnvollerweise eine handoptimierte Assemblerversion für memcpy(),> Zumindest so lange, bis man wirklich man genau reinschaut, und bei> grösserer Speichermenge mit nicht zum Basisbefehlssatz gehörenden> Befehlen, Prefetch, Cache-Hints etc. an die Grenze der konkreten> Hardware geht. Denn das bieten Compiler-Runtimes aufgrund ihrer> Unabhängigkeit von der exakt eingesetzten CPU nicht unbedingt.
Mal ehrlich, solche allgemeinen Aussagen zur Effizienz von C++ - wie
oder was nun besonderen "Geschwindigkeitsvorteil" bringen soll - beruhen
doch schlicht größtenteils auf der Annahme, der gerade zur Verfügung
stehende Compiler möge gefälligst den denkbar bestmöglichen Code ins
Compilat einpflügen, nach dem Motto, "mein Compiler macht dat scho. Der
is ja soo schlau!". ;-)
Ob das im ausführenden Programm dann wirklich so ist und ob das dann
auch die bestmögliche Ausführungszeit erbringt, überprüfen doch die
Allerwenigsten. Deswegen kann so ein "Seminarguru" auch mal schnell
Behauptungen wie im Eingangsthread aufstellen und die Teilnehmer
abqualifizieren. Er selber bringt Null Beweise seiner Aussage. Er ist
schließlich der "Guru", die Teilnehmer sind aus seiner Sicht die
Dummchen. Warum stellen solche Leute nicht auch mal ein paar
Messergebnisse für ihre Aussagen zur Verfügung, dann könnte man ihnen
wenigstens Glauben schenken und selber mal Vergleiche anstellen.
Vielleicht gäbe es dann auch mal ein paar Überraschungen. Wer weiß!
Ein anderer Aspekt wäre zudem, ob solche Effizienzhascherei immer den
Königsweg darstellen, insbesondere dann, wenn dafür der Code schwieriger
zu schreiben und erst recht zu verstehen ist und somit auch
fehlerträchtiger wird. Ganz abgesehen vom horrenden Zeitaufwand der
betrieben werden muss, wenn die Dinge dann nicht so laufen, wie man es
erwartet.
Hier beißt sich doch die Mietzekatze in ihren Kringelschwanz. C++
Protagonisten verführen regelrecht gewollt oder ungewollt mit ihrem
fortwährenden Betonen ihrer "Überlegenheitskultur" gegenüber anderen
Programmiersprachen andere dazu, sich auch in C++ zu probieren. Der Ball
wird dann prompt gerne aufgenommen. Man will schließlich auch irgendwie
zur "C++ Elite" dazugehören. Dann aber stechen die Nebenwirkungen und
Begleiterscheinungen aus dem (C++)-Beipackzettel beim Probanden immer
mehr durch. Ergebnis: Dass gerade daraus dann vielleicht umso mehr
fehlerhafte und gar nicht immer so Effizient wie behauptet Programme
erwachsen, weil kaum einer dieses Thema richtig beherrscht, steht dem
ganzen schönen Thema C++ hässlich gegenüber, wird aber gerne unter den
Teppich gekehrt, weil die Wenigsten freiwillig und offen zugeben, dass
sie ihr C++ eben nicht so richtig oder bisweilen sogar gar nicht
beherrschen. REAL werden dann eher die gewohnten C-Programme
geschrieben, durch den C++ Compiler geschickt und heraus kommt sowas wie
.. C+.
;)
Fpga Kuechle schrieb:>> ja bei jeder Zuweisung zweimal die neue Adresse berechnet werden, was ja>> die ALU beansprucht und das kostet Zeit. Den Zeiger einfach Hochzaehlen>> passiert nebenbei, das ist viel schneller.">> Im Prinzip richtig.
Wenn man die Umsetzung C in Assembler genau so versteht, wie es da
steht, dann landen wir x86 Befehlen bei
pointer_loop:
load (src)
increment src
store (dst)
increment dst
increment count
compare count to limit
if ok then goto pointer_loop
und
index_loop:
load (src+index*n)
store (dst+index*n)
increment index
compare index to limit
if ok then goto index_loop
Das sind zunächst 7 Befehle gegenüber 5 zu Lasten der Pointer-Version,
entsprechend auch internen Befehlen des x86 OOO Cores - evtl. werden die
beiden letzten gemerged, aber das gilt für beide Versionen.
Zwar ist die Berechnung (src) auf dem Papier weit einfacher als
(src+index*n), aber dafür kannst du dir nichts kaufen, denn den real
existierenden x86 ist das egal.
Aber selbst wenn die Index-Rechnung mehr Zeit brauchen würde, wäre es in
den Cores der Oberklasse seit einiger Zeit egal. Denn die sequentiellen
Abhängigkeiten bei der Adressrechnung aufeinander folgender Iterationen
betragen jeweils nur einen Takt und sind damit weit kürzer als der
Transport bei L1 Hit dauert (IIRC 8 Takte aktuell). Weshalb die Adressen
des Transports auch dann schon lange vor dem Transport selbst zur
Verfügung stehen, wenn die Adressrechnung einige Takte benötigt.
Soll heissen: Die in internen Operationen kürzere Version gewinnt, oder
landet beim gleichen durch den Transport durch die jeweiligen Cache
Levels entstehenden Limit.
Demgegenüber gewinnt derjenige, der die Breite der Datenpfade auch
ausnutzt, und das ist Stand heute nicht mit "int" zu machen, sondern
setzt SSE Befehle voraus. Wenn man dann bei grösseren Datenmengen auch
noch darauf verzichtet, Cache Lines, die sowieso komplett überschrieben
werden, überhaupt erst in den Cache zu laden, dann kommt man dem Ziel
schon näher.
Apropos AVR: Der werte Herr kommt wie berichtet aus dem Bereich Server
und hochgradiger Parallelisierung. Eine wilde Horde parallel arbeitender
ATmegas wird er damit nicht gemeint haben. ;-)
Ret schrieb:> Mal ehrlich, solche allgemeinen Aussagen zur Effizienz von C++ - wie> oder was nun besonderen "Geschwindigkeitsvorteil" bringen soll - beruhen> doch schlicht größtenteils auf der Annahme, der gerade zur Verfügung> stehende Compiler möge gefälligst den denkbar bestmöglichen Code ins> Compilat einpflügen, nach dem Motto, "mein Compiler macht dat scho. Der> is ja soo schlau!". ;-)
Wenn man in dieser Form auf C Ebene optimiert, also den C Code dem
anpasst, was der jeweilige Compiler für die jeweilige Maschine an Code
erzeugt, dann muss man sich mit jedem signifikant neuen Compiler und
jeder ansdersartigen Maschine neue Gedanken machen, wie man dem Compiler
in C (oder C++) beibringt, die grad richtigen Befehle zu erzeugen.
Das freilich ist fast immer der falsche Ansatz. Wie grad beschrieben
kann die Index-Variante allein aufgrund der niedrigeren Anzahl
Inkrementierungen im Vorteil sein. Auf Maschinen mit Inkrementierung als
Teil des Befehls löst sich der Unterschied zwar auf, aber dann greift
bei ausreichend komplexem Core das, was ich grad geschrieben habe.
Ich sehe einfach keinen Sinn mehr darin, auf C/C++ Ebene solchen
Feinheiten hinterher zu rennen. In den 80ern habe ich das gemacht. Heute
ist das sinnarm geworden. Wie ich schon schrieb findet eine echte
Optimierung von Speichertransports im High-Performence Bereich heute
dort statt, wo der Compiler nicht hinkommt und was eine einfache für
memcpy Implementierung für Queerbeet-x86/(-64) nicht leisten wird.
Daher spricht für mich nichts dagegen, die simple aber leicht
verstndliche Index-Version zu verwenden, so lange es nicht wirklich
kritisch ist. Und wenn es wirklich kritisch ist, dann kommt man mit
generischem C/C++ sowieso nicht weiter.
> Hier beißt sich doch die Mietzekatze in ihren Kringelschwanz. C++> Protagonisten verführen regelrecht gewollt oder ungewollt mit ihrem> fortwährenden Betonen ihrer "Überlegenheitskultur" gegenüber anderen> Programmiersprachen andere dazu, sich auch in C++ zu probieren.
Die Laufzeit bei C v. C++ hier ins Spiel zu bringen finde ich sowieso
etwas schräg. Da mag es Optimierungsmöglichkeiten geben. Aber der
Kernunterschied liegt nicht in irgendwelchen Optimierungen, sondern in
der Mächtigkeit des Ausdrucks. Und 99% des entstehenden Codes werden
weniger von der Performance der Laufzeit begrenzt, sondern von der
Performance des Programmierers, ihn zu schreiben.
Programmierung und Wartbarkeit von Programmen sind näherungsweise
abhängig von der Anzahl Quellcodezeilen. Da die Mächtigkeit von C++ sehr
viel grösser ist als die von C, können entstehende Programme letztlich
in Quellcodezeilen deutlich kompakter ausfallen, vorausgesetzt der
Programmierer beherrscht es wirklich.
NB: Ich finde C++ eine ziemlich grässliche Konstruktion - übrigens von
Anfang an seit der Lektüre des ersten Stroustrup. Kann nicht anders
sein, da schon C schaurig geraten ist und nie für die Dimension gedacht
war, in der es heute eingesetzt wird. Aber das ist Philosophie auf der
Wiese. Das Zeug ist nun einmal da.
Das ist doch alles Kindergarten hier ;-)
Schaut doch erst mal in eine konkrete Implementierung von memcpy, hier
z.B. in der Newlib für ARM 7a:
https://sourceware.org/viewvc/src/newlib/libc/machine/arm/memcpy-armv7a.S?revision=1.2&view=markup
Ich bezweifle dass da irgendeine der o.g. kiki-Schleifen auch nur
ansatzweise mitkommt — ok, zum Besteck zeitgemäßer Compiler gehören zwar
auch Auto-Vectorizer, aber das Hand-optimierte Asm dürfte dennoch besser
aussehen.
In der Newlib für ARM zählt man insgesamt 5 Asm-Implementierungen von
memcpy für unterschiedliche Derivate, die je nach Derivat, für das
gelinkt wird, ausgewählt werden.
Davon ab ist die vom OP gegebene Frage bzl. Optimalität total Banane;
wurde ja auch schon geschrieben. Ohne zu wissen für welchen Compiler,
welche Architektur, welche LibC-Implementierung, etc. ist die Frage kaum
zu beantworden.
Und übrigens haben auch Compiler eine Vorstellung von memcpy, d.h. auf
einer C-Implementierung mit sizeof(int) = sizeof(float) erzeugt sowas
wie
1
unsignedtype_pun_float(floatf)
2
{
3
unsignedu;
4
memcpy(&u,&f,sizeof(int));
5
returnu;
6
}
schon überhaupt keine Kopier-Befehle mehr (z.B. gcc -O2), außer
natürlich das Kopieren vom Parameter-Register zum Return-Register falls
diese nicht identisch sind.
Johann L. schrieb:> Das ist doch alles Kindergarten hier ;-)
Allerdings. Das ist eine Gespensterdebatte auf dem Stand der frühen
80er. Völlig missachtend, was sich seither bei Compilern und Prozessoren
getan hat.
Wenn dann Beispiele aus der AVR Welt ins Spiel gebracht werden, dann
sollte man beachten, dass Mikroarchitektur und Befehlsabläufe dieser
AVRs technisch auch nicht weiter sind als ebendiese frühen 80er.
Zwischen diesen und den PC- und Smartphone-Prozessoren liegen Welten,
und zwar nicht bloss in MHz.
Johann L. schrieb:> In der Newlib für ARM...A. K. schrieb:> Wenn dann Beispiele aus der AVR Welt...
Wer lesen kann:-)
-
Wenn man sich in der x86 Welt mal ansieht welche Unterschiede zwischen
dem gcc und dem icc möglich sind. Da könnte einem schon der Verdacht
kommen das beim Thema Optimierung zumindest beim gcc noch einiges an
Luft für Verbesserungen vorhanden ist.
Irgendwer schrieb:> kommen das beim Thema Optimierung zumindest beim gcc noch einiges an> Luft für Verbesserungen vorhanden ist.
Sicher. Ich würde mich aber doch etwas wundern, wenn der ICC bei der
Optimierung des anfänglichen Codes automatisch etwas rund um den MOVNTDQ
Befehl auswirft. Denn in die Richtung läuft der Hase, wenn es um
grössere Speichertransfers geht.
Ret schrieb:> Und (wenn man fragen darf) wie lautet deine persönliche> Ausweichstrategie darauf, nun mit "ohne C++" auszukommen, in Bezug aufs> µC und PC programmieren?
Also mir wäre noch nie ein Fall untergekommen, wo man einen µC in C++
programmiert hätte, und in meinem derzeitigen Job arbeite ich als
"Softwareentwickler und Netzwerkmanager NGN" und da gibts auch kein C++.
Ich hab auch schon in vorherigen Jobs GUI-Anwendungen gemacht. Die hab
ich in Lazarus, einem freien Delphi Klon erstellt. Das hat den Vorteil,
dass das schnell und plattformunabhängig ist, und dass man kein
Framework installieren muss.
Und selbst wenn ich, aus welchen Gründen auch immer, Die Art von
Objektorientiertheit von C++ brauche, so kann ich die auch einfach in C
nachprogrammieren. Das hab ich zugegeben sogar schon mal gesehen. Und
wenn man das selber macht kann man sogar die üblichen Merkwürdigkeiten
von C++ umschiffen. (implizite Objektkopien? WTF!)
Woah, rege beteiligung, das freut mich :-)
Zu erstmal scheint es das ein oder andere missverstaendnis zu geben, was
freilich mein fehler ist! :-/
Es geht nicht speziel um die AVR oder sonstige Mikrocontroller,
lediglich mein Beispiel hat sich auf einen AVR bezogen. Dass das sehr
unklug war, ist mir mittlerweile auch aufgefallen, und dafur
entschuldige ich mich auch. Die Aufgabe des "Dozenten" war mehr
allgemeiner Natur, ich habe es halt im AVR umfeld getestet, was durch
aus legitim ist, finde ich.
Das aendert aber, meiner meinung nach, nichts daran, das aussagen wie
"Variante B ist schneller als Variante A, weil..." keine allgemeine
gueltigkeit besitzen koennen, da keine Randbedingungen genannt wurden.
Und genau das ist passiert, und da hat natuerlich zu dem Zeitpunkt auch
keiner von uns dran gedacht nach zu fragen unter welchen umstaenden denn
dieser geschwindigkeitsvorteil greifen soll.
Das ist so, als wenn ich sage:
1
Nachts sind alle Katzen grau
und dabei die Randbedingung, dass das nur Nachts gilt, weglasse.
Fpga Kuechle schrieb:>> Umgebung:>> Atmel Studio 6.2>> AVR GCC 4.8.1>> AVR Projekt (Mega 2560)>> Schlechte Wahl, nicht vergleichbar.
Dachte ich mir schon. :-/
Deswegen fragte ich ja auch, ob es an meinem Test liegt.
Kaj schrieb:> liegt hier jetzt einfach daran das ich> es mit dem AVR-Simulator getestet habe, oder ist das Grundsaetzlicher> bloedsinn was uns da erzaehlt wurde?Fpga Kuechle schrieb:>> So, diese Geschichte zum Geschwindigkeitsvorteil hat mir keine Ruhe>> gelassen und ich hab es jetztmal getestet.>> Gute Idee!
Danke :-)
A. K. schrieb:> Apropos AVR: Der werte Herr kommt wie berichtet aus dem Bereich Server> und hochgradiger Parallelisierung. Eine wilde Horde parallel arbeitender> ATmegas wird er damit nicht gemeint haben. ;-)
Ja, stimmt schon. Wie geschrieben, Ich hab es halt mit AVR getestet.
Deswegen schrieb ich ja auch:
Kaj schrieb:> Stimmt das, was uns der werte Herr da zum Geschwindigkeitsvorteil> erzaehlt hat prinzipiel und das liegt hier jetzt einfach daran das ich> es mit dem AVR-Simulator getestet habe, oder ist das Grundsaetzlicher> bloedsinn was uns da erzaehlt wurde?
Apropos: Was ist eigentlich an einer wilden Horde parallel arbeitender
ATmegas auszusetzen? :-P
Peter II schrieb:> Denn es ist langsamer eine Variable von 0 bis irgendwas zu zählen als> andersrum.
Warum ist das eigentlich so? Denn soweit ich weiss, betrifft das ja
nicht nur Mikrocontroller, sondern auch "normale" Prozessoren. Ist das
mal wieder so ein Historisch-Gewachsenes-Ding, oder gibt es da irgendwo
eine handfeste Begruendung, weshalb das so umgesetzt wurde das runter
schneller ist als rauf? Ich meine, wenn man es so umsetzten kann, dann
haette man es ja auch andersrum umsetzten koennen, also das rauf
schneller ist als runter.
uwe schrieb:>> Stichwort:>>>>Loop unrolling> Ja schon, aber nicht selber sondern die Compileroption aktivieren
Dafuer gibt es eine Compileroption? o_0
Bronco schrieb:> Überlasst das Optimieren dem Compiler und> konzentriert Euch auf die Aufgabe!
Da stimme ich dir zu. Trotzdem kann man sich doch bemuehen, von
vornerein, wenigstens halbwegs guten Code zu schreiben, oder nicht? (Ob
gut nun schnell oder speichersparend ist, haengt wieder von der
situation ab.)
Karl Heinz schrieb:> Diesen sog. Guru hätt ich rausgeschmissen
Sagen wir es mal so:
Er war danach nicht mehr sehr lange im Haus, und wir waren nicht weit
davon entfernt den Mann mit brennenden Fackeln und Mistgabeln vom
Firmengelaende zu "begleiten" :D
Läubi .. schrieb:> Ich hoffe mal das Ziel war es möglichst EFFIZIENT zu sein
Aehem...*hust*.. ja meinte effizient. Mein Fehler :-/
A. K. schrieb:> Irgendwer schrieb:>> A. K. schrieb:>>> Wenn dann Beispiele aus der AVR Welt...>>>> Wer lesen kann:-)>> Rohrkrepierer. Denn so ging der ganze Spass überhaupt erst los:>> Kaj schrieb:>> AVR GCC 4.8.1
Wie schon geschrieben: Mein Fehler. :( Lediglich mein Test-Setup
basiert darauf.
Im grossen und ganzen kann ich dieser Diskussion entnehmen, das Herr
mehr oder minder Recht hat, abhaengig von Compiler, Zielplatform usw.
Ich danke euch aufjedenfall fuer diese erleuchtung und die rege
teilnahme :-)
Kaj schrieb:>> Denn es ist langsamer eine Variable von 0 bis irgendwas zu zählen als>> andersrum.> Warum ist das eigentlich so?
Bis 0 runterzählen kann bedeuten, dass man sich den Vergleich mit der
Endbedingung ersparen kann, weil die Dekrementierung das Zero-Flag
setzt. Vorausgesetzt freilich, es gibt überhaupt Flags, was keineswegs
immer der Fall ist.
> Wie schon geschrieben: Mein Fehler. :( Lediglich mein Test-Setup> basiert darauf.
Das war nicht aggressiv gemeint, nur als Information. Ok, der
"Rohrkrepierer" an die Adresse von "Irgendwer", der mir Leseschwäche
vorwarf, der war es. ;-)
> Im grossen und ganzen kann ich dieser Diskussion entnehmen, das Herr> mehr oder minder Recht hat, abhaengig von Compiler, Zielplatform usw.
Nein, denn mit ...
> "Das ist viiieeeeel effektiver, der Geschwindigkeitsvorteil gegenueber> der Index-Variante ist mindestens Faktor 3."
... liegt er immer und überall dramatisch daneben, sofern es überhaupt
einen Unterschied macht und er nicht andersrum ausgeht.
Und er kämpft mit Optimierung auf dieser Ebene mit Gespenstern aus den
80er Jahren. Das ist einfach nur sinnlos.
> Er war danach nicht mehr sehr lange im Haus, und wir waren nicht weit> davon entfernt den Mann mit brennenden Fackeln und Mistgabeln vom> Firmengelaende zu "begleiten" :D
Recht getan. ;-)
Christian Berger schrieb:> Und selbst wenn ich, aus welchen Gründen auch immer, Die Art von> Objektorientiertheit von C++ brauche, so kann ich die auch einfach in C> nachprogrammieren.Das ist dann vielleicht erst 'ne Krücke. Vereinigung der Nachteile
von allem.
C++ auf Controllern kann durchaus schön sein (gibt ja gerade einen
Nachbarthread, der die Möglichkeiten aufzeigt) und ist gewiss nichts,
was man gleich verteufeln muss.
Nur die Mikro-Optimierungen des „Gurus“ sind einfach Unfug.
Also meine Erfahrung mit dem AVR-GCC ist, daß ihm die Schreibweise, ob
Index oder Pointer, meistens völlig wurscht ist. Er erzeugt den gleichen
Code (-Os).
Versucht man was zu optimieren, wehrt er sich hartnäckig dagegen.
Man kann also ruhig der besseren Lesbarkeit den Vorzug geben und
Mikrooptimierungen dem Compiler überlassen.
Was ich mich aber frage, was hat das ganze mit C++ am Hut?
Pointer sind doch schnödes plain C.
Kaj schrieb:> Peter II schrieb:>> Denn es ist langsamer eine Variable von 0 bis irgendwas zu zählen als>> andersrum.> Warum ist das eigentlich so? Denn soweit ich weiss, betrifft das ja> nicht nur Mikrocontroller, sondern auch "normale" Prozessoren. Ist das> mal wieder so ein Historisch-Gewachsenes-Ding, oder gibt es da irgendwo> eine handfeste Begruendung, weshalb das so umgesetzt wurde das runter> schneller ist als rauf? Ich meine, wenn man es so umsetzten kann, dann> haette man es ja auch andersrum umsetzten koennen, also das rauf> schneller ist als runter.
Das ist weniger eine Frage des rauf oder runter sondern ob der Vergleich
auf 0 oder auf eine Nicht-Null Konstante gemacht wird.
Ein Vergleich auf = macht so eine CPU nebenher, jedes mal wenn eine Null
als Ergebnis in der ALU steht wird das zero-Flag gesetzt. Das verlassen
der Schleife ist uber einen Springbefehl realisiert der diese Flag
testet.
Also gleich nach dem Decrement des Index und damit ohne weiteren befehl
kann die CPU entscheiden ob sie die Schleife verlässt oder nicht. Für
einige CPU's ist das sogar auf einen einzigen Befehl zusammengefasst:
DECBRNZ - Dekrementiere, Branch wenn nicht Zero
Zähl man dagegen aufwärts muss auf bspw 10 vergleichen werden. Dazu muss
ein extra Befehl eingefügt werden:
INC --Inkrementiere
CMP --Vergleiche
BRNZ --Branch wenn nicht Zero
bei dem Compare kann es noch weitere Verzögerungen geben wenn der
schleifenindex nicht im Register steht sondern auf dem Stack oder im
externen Speicher.
MfG,
A. K. schrieb:>> "Das ist viiieeeeel effektiver, der Geschwindigkeitsvorteil gegenueber>> der Index-Variante ist mindestens Faktor 3.">> ... liegt er immer und überall dramatisch daneben, sofern es überhaupt> einen Unterschied macht und er nicht andersrum ausgeht.
Doch es macht genau den Faktor 3 aus ob ich 3 mal auf die ALU zugreife
um Index, src und dest pointer zu inkrementieren, oder nur 1mal die ALU
benutze und die Pointerarithmetik den data fetch Units überlasse.
> Und er kämpft mit Optimierung auf dieser Ebene mit Gespenstern aus den> 80er Jahren. Das ist einfach nur sinnlos.
Nope das sind nicht 80 iger Jahre sondern aktuelle
Architekturoptimierungen wie sie beispielsweise beim Blackfin von Analog
devices (produziert seit 2008) eingesetzt werden.
Manche sind einfach nur Thread- resp. Beratungsresistent.
MfG,
Hardware Kenner schrieb:> Doch es macht genau den Faktor 3 aus ob ich 3 mal auf die ALU zugreife> um Index, src und dest pointer zu inkrementieren, oder nur 1mal die ALU> benutze und die Pointerarithmetik den data fetch Units überlasse.
Nur dass der Guru es genau anders herum ausdrückte, d.h. er sah in der
Index-Variante die 3fach teurere, weil jedesmal die Adresse berechnet
werden muss. Was auch wieder stimmen könnte, weil ein IA64 Prozessor
keine implizte Adressrechnung beherrscht, dafür aber implizite
Inkrementierungen (allerdings vorher), und wenn der Compiler so blöd
wäre, den C Code ohne nachzudenken 1:1 umzusetzen.
Ausserdem muss man den Faktor auf die Iteration beziehen und dann ist es
selbst mit 1:1 Umsetzung des C Codes in Assembler-Code kein Faktor 3
mehr.
Hatten wir ausserdem nicht längst geklärt, dass es keinen direkten und
verlässlichen Bezug mehr zwischen dem gibt, was du in C hinschreibst,
und dem, was der Compiler erzeugt?
Ich bin aber auch der Ansicht, dass man per Default locker die
Index-Variante verwenden kann, weil Compiler darauf getrimmt sind,
solche Klassiker zu erkennen und passend zu den Fähigkeiten der
Zielmaschine zu optimieren. Wer wirklich optimalen Code will muss
ohnehin in jedem Einzelfall auf den erzeugten Code hin kontrollieren und
weiter optimieren, weil sich nicht alle Möglichkeiten dem Compiler
erschliessen.
> Manche sind einfach nur Thread- resp. Beratungsresistent.
Du wirst immer Compiler und Plattformen finden, in denen irgendwelche
solchen Spitzfindigkeiten mal in der einen und mal in der anderen
Variante besser sind. Aber ich halte es i.d.R. für völlig sinnlos, in
normalen Programmen auf normalen Plattformen dem hier gezeigten
Kleinkram hinterher zu rennen. Wenn Grenzoptimierung gefragt ist, dann
ist oft genug weder die eine noch die andere Variante optimal.
Daher kann ich mich nur deiner ad hominem Argumentation anschliessen.
Die Resistenz findet sich auch dort, wo du sie nicht vermutetest.
Peter Dannegger schrieb:> Was ich mich aber frage, was hat das ganze mit C++ am Hut?> Pointer sind doch schnödes plain C.
Weil C++ da mit "std::copy" & co ein schönes Framework für Optimierungen
bietet.
Du schreibst im Applikations-Code immer denselben "std::copy"-Call.
Wenn auf meiner Ziel-Plattform z.B. das Kopieren von "doubles" über die
FPU besonders schnell ist, dann schreibt man(*) einmal eine
spezialisierte Copy-Variante für doubles und schon wird überall der
neue, verbesserte Code eingebunden.
Bei Plain-C muss man per Suchen&Ersetzen alle memcpy finden und
herausfinden, welche davon "doubles" kopieren wollen...
*) man == jemand der sich mit C++ und der Zielplattform besser auskennt
als ich :)
Wobei das Optimieren von Kopier-Operationen eh seltenst wirklich nötig
ist...
Bei mir das letzte mal auf einem '51er Klon, der einen speziellen
Selbst-Inkrementierenden Autoptr für schnelle XMEM-Kopieraktionen hatte.
A. K. schrieb:> Ich bin aber auch der Ansicht, dass man per Default locker die> Index-Variante verwenden kann, weil Compiler darauf getrimmt sind,> solche Klassiker zu erkennen und passend zu den Fähigkeiten der> Zielmaschine zu optimieren.
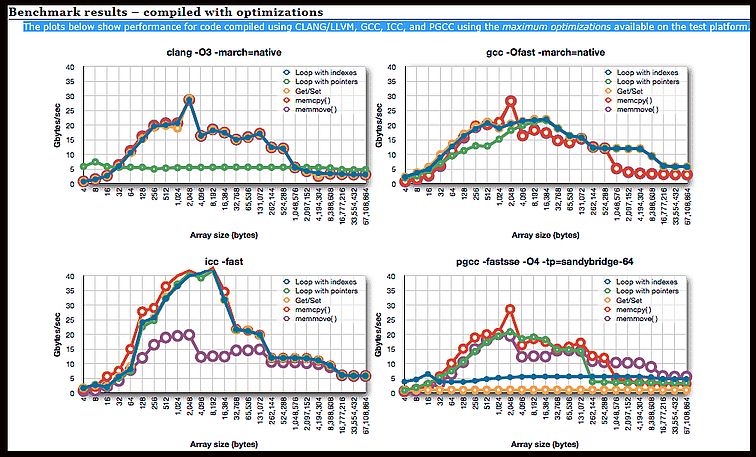
Eben nicht, auch heutige C-Compiler sind recht eigenwillig was die
Erkennung von "Code der anders aussieht, aber dasselbe tut". Im Anhang
ein Benchmark vom "Speicherbereich kopieren" mit 5 verschiedenen
Algorithmen in C beschrieben (darunter die pointer und die
index-Variante) für 4 verschiedenene Compiler ausgemessen. Dargestellt
wird die Transferrate abhängig von der Blockgröße.
Eigentlich müssten alle 5 Kurven übereinander liegen - dem ist aber
nicht so. Besonders der GCC scheint seinen Benutzer mit stark
differierenten Code überraschen zu müssen. Vielleicht will er auch nur
davon ablenken das der Intel-Compiler zuweilen doppelt so schnelle
Compilate erzeugt.
Details dort:
http://nadeausoftware.com/articles/2012/05/c_c_tip_how_copy_memory_quickly
Da wundert es nicht das Gott Linus persönlich vor ein paar Wochen den
gcc als völligen Mist bezeichnete "Because it damn well is
some seriously crazy shit"):
http://www.heise.de/developer/meldung/Linus-Torvalds-wettert-gegen-Compiler-Collection-GCC-4-9-2268920.html
MfG,
PS.:
Für jeden der sich etwas in Compilerbau auskennt sei der
Orginalkommentar empfohlen:
http://lkml.iu.edu/hypermail/linux/kernel/1407.3/00650.html
Hinweis:
"gcc is stupid in spilling a constant" meint das der Compiler Konstanten
auf den stack (in den Speicher) kopiert (statt sie als immediate Operand
beim filling zu verwenden)
Hardware Kenner schrieb:> Besonders der GCC scheint seinen Benutzer mit stark> differierenten Code überraschen zu müssen.
Der GCC formt gleich funktionierenden Code immer in die gleiche Form um.
Daß im Quellcode ein Index verwendet wird, heißt für ihn noch lange
nicht, daß er ihn auch verwenden muß.
Daher erzeugt er für verschiedene Schreibweisen den gleichen Assembler.
Hier mal für die beiden obigen Routinen (AVR-GCC):
Irgendwer schrieb:> Johann L. schrieb:>> In der Newlib für ARM...>> A. K. schrieb:>> Wenn dann Beispiele aus der AVR Welt...>> Wer lesen kann:-)
Für avr-gcc gilt ähnliches. Zwar nicht für die Newlib, aber für die
AVR-LibC, die wohl von mindestens 99% der Anwender eingesetzt wird.
AVR-LibC enthält Assembler-Optimierte Algorithmen. Nicht nur für
Bytegeschiebe sondern z.B. auch für float-Arithmetik oder int <-> String
Konvertierungen etc etc.
"Optimalität" bei AVR-Anwendungen ist i.d.R. Codegröße; da einen 4x
größeren Code zu haben und ein, zwei grottige Ticks einzusparen ist da
nicht angezeigt.
> Wenn man sich in der x86 Welt mal ansieht welche Unterschiede zwischen> dem gcc und dem icc möglich sind. Da könnte einem schon der Verdacht> kommen das beim Thema Optimierung zumindest beim gcc noch einiges an> Luft für Verbesserungen vorhanden ist.
Besser geht immer. Bei manchen Optimierungen steht sich GCC selbst im
Weg... Und ICC hat den Vorteil, daß er nur für eine einzige
Architektur(familie) zu erzeugen brauch. Und selbst da liegt
Intel-harware vorne und nicht-Intel hinken in Codegüte hinterher.
uwe schrieb:> Ich würds mit dem DMA Controller machen =;)
Ende der 80er habe ich auf 3B-Unix-Rechnern von AT&T gearbeitet. Die
3B-Prozessoren waren auf die Sprache C optimiert. Sie kannten z.B.
memcpy() und auch strcpy() als Opcode. Besser gehts nicht :-)
Kaj schrieb:> Der gute Mann hat erstmal einen auf ganz dicke Hose gemacht, und was> fuer ein toller super Typ er doch sei, er sei ja seit Jahren> C++-Entwickler fuer Serverprogramme und hoch parallelisierte Prozesse> bla bla.
Will nur kurz noch auf das eingehen: Die Kopierfunktion von oben schreit
nach einem Buffer-Overflow und ist auf jeden Fall ein
Sicherheitsrisiko... so ein Code hat in sicherheitsrelevanten Bereichen
wie z.B. Serversoftware nichts zu suchen.
remy schrieb:> Die Kopierfunktion von oben schreit> nach einem Buffer-Overflow
wie das? Die Anzahl der kopierten Elemente ist ja durch "elements"
begrenzt.
remy schrieb:> so ein Code hat in sicherheitsrelevanten Bereichen> wie z.B. Serversoftware nichts zu suchen.
Naja, sowas wie ein E-Mail oder HTTP-Server ist nach üblichem
Verständnis nicht sicherheitsrelevant. Darunter fallen eher Dinge wie
ESP-Steuerung im Auto...
Und wie stellst du dir eine "sichere" Kopier-Operation vor? Das normale
memcpy oder der Kopier-Operator von std::vector hat doch exakt das
gleiche "Problem".
Dr. Sommer schrieb:> wie das? Die Anzahl der kopierten Elemente ist ja durch "elements"> begrenzt.
Jein. Das wäre nur eine geeignete Sicherheitsstrategie mit einem
entsprechendem Reviewprozess und statischer Codeanalyse. Und selbst dann
kann man nicht vollständig ausschließen, dass auch mal ein falsches
"elements" übergeben wird.
Und zusätzlich sollte man "-fstack-protector" als Compilerflag setzen.
Viele Fehler kann man auch mit valgrind entdecken.
Dr. Sommer schrieb:> Naja, sowas wie ein E-Mail oder HTTP-Server ist nach üblichem> Verständnis nicht sicherheitsrelevant. Darunter fallen eher Dinge wie> ESP-Steuerung im Auto...> Und wie stellst du dir eine "sichere" Kopier-Operation vor? Das normale> memcpy oder der Kopier-Operator von std::vector hat doch exakt das> gleiche "Problem".
Naja, wenn ich dank eines Buffer Overflow Zugriff auf einen Server
deiner Firma habe und dort interne Daten absaugen kann, ist das durchaus
sicherheitsrelevant...
Wenn man zwei std:vector kopiert, ist das, aufgrund der Codebase der STL
"secure". Ganz im Gegensatz dazu, wenn man seine eigene Kopierfunktion
verwendet (da sind wir wieder wie oben angesprochen, bei einem
Reviewprozess).
remy schrieb:> Wenn man zwei std:vector kopiert, ist das, aufgrund der Codebase der STL> "secure".
Und wer reviewt die?
remy schrieb:> Ganz im Gegensatz dazu, wenn man seine eigene Kopierfunktion verwendet
Wenn du so eine triviale Funktion schon als review-pflichtig ansiehst,
ist das garantiert der gesamte Code des Programms. Also kein besonderer
Nachteil dieser Funktion.
Und wie man eine nicht-review-pflichtige "sichere" Kopierfunktion
implementiert hast du immer noch nicht verraten.
PS: in richtig sicherheitskritischen Bereichen (wie Automotive
Steuerungen) wird natürlich alles reviewed. Aber auch da ist memcpy (mit
Längen-Argument) erlaubt.
Tom schrieb:> Und wer reviewt printf? Oder malloc?
Der Anbieter der zertifizierten C Library. Da diese Funktionen aber
offenbar review-bedürftig (von wem auch immer) sind, sind sie auch nicht
besser als die Funktion vom OP. Damit ist immer noch nicht klar was sich
remy unter einer sicheren memcpy (artigen) Funktion vorstellt, die auch
bei falschem Längenargument noch sicher ist...
Dr. Sommer schrieb:> Damit ist immer noch nicht klar was sich> remy unter einer sicheren memcpy (artigen) Funktion vorstellt, die auch> bei falschem Längenargument noch sicher ist...
void * memcpy (void * dest, const void * src, size_t n)
{
return (NULL);
}
micha schrieb:> Kaj schrieb:>> Compilerflags: -O0 -g3 -std=gnu99 -Wall -Wextra>> Schalt mal die Optimierung ein und vergleich den Code.
Und teste mal mit
-Ofast -march=native -flto -funroll-loops -Wall -fbounds-check
und mal mit
-Os -march=native -Wall -fbounds-check
Wie schon erwähnt wurde nimmt man zum Kopieren vom Speicherbereichen
üblicherweise memcpy und keine zusammengefrickelten Schleifen, denn in
der Realität spielt auch die Wartbarkeit und Portabilität eine Rolle -
auch das betrifft die Effizienz.
Zudem ist der Weg an einer Stelle etwas rumzubasteln nicht selten
ineffektiv, denn man kann sowas auch parallelisieren mit mehreren
CPUs/GPUs oder einem Cluster/einer Cloud.
Das int elements kann ja auf einer 64-Bit-Plattform ziemlich groß sein
und ohne ein paar Tausend/Millionen Kernen kann es dann ziemlich lange
dauern.
Also kurz gesagt ist die richtige Antwort auf die Frage "kommt drauf
an", denn unterschiedliche Lösungen skalieren unterschiedlich.
Daher ist die Frage von dem Guru so sinnvoll wie "ist es nachts kälter
als draußen?".