Heise Security beschreibt eine interessante Attacke (nicht nur) auf
Linux-Systeme: die Rowhammer-Attacke.
http://www.heise.de/security/meldung/Rowhammer-RAM-Manipulationen-mit-dem-Vorschlaghammer-2571835.html
Dazu werden Speicherzellen ausgelesen, die neben sicherheitsrelevanten
Zellen liegen. Durch das Auslesen sollen sich Bits in den Nachbarzellen
ändern können und so eine Rechte-Eskalation ermöglichen.
Alles ziemlich dubios... Aber eine Frage stellt sich: wie kann es
passieren, dass durch Auslesen einer RAM-Zelle Inhalte von Nachbarzellen
verändert werden?
Bis zum 1. April ist es doch noch eine Weile...
Nachtrag: Das ist ja fast so wüst, wie die Geschichte von den Rechnern
aus den 1960ern, deren Kernspeicher man braten konnte, indem man eine
unendliche Schleife der Bauart
1
jmp $
programmierte. Dabei rauchten die Speicherkerne ab, in denen der Befehl
gespeichert war.
Wie im Artikel schon steht - bei den sehr kleinen modernen Strukturen
liegen die Zellen sehr dicht beisammen und könnten sich beeinflussen.
Könnte dann sein, dass beim Auslesen da "übersprechen" auftritt.
Das sind ja nur winzige Kondensatoren... die auch noch regelmäßig
aufgefrischt werden wollen weil sonst die Daten verloren gehen.
Mit ECC Speicher klappt das nicht, weil der einzelne Bitfehler erkennen
und korrigieren kann.
Also Lösung: nächsten Rechner mit ECC Speicher bauen ;-)
Ich behaupte jetzt einfach mal, dass RAM-Bausteine, bei denen sowas
möglich ist, Ausschuss sind. Sowas sollte eigentlich mit kritischen
Zugriffsmustern beim Test auffallen - sofern überhaupt getestet wird und
nicht einfach Banana-Hardware verscherbelt wird.
Es dürfte relativ leicht sein heraus zu finden, auf welchen Adressen der
Kernel sensible Daten speichert. Dann muss ich aber wissen, welche Chips
verbaut sind um Zellen zu finden, die direkt daneben liegen und dann
muss ich die Speicherverwaltung überzeugen, mir die Seite zuzuweisen,
die genau diese Zellen enthält. Ich kann ja als User nur auf virtuelle
Adressen zugreifen und mir ist gerade keine Möglichkeit bekannt heraus
zu finden, welche physischen Adressen eigentlich dahinter liegen. (Ich
hatte allerdings auch noch nie einen Grund, das wissen zu wollen :-)
Vielleicht kann man ja auch durch das Einrammen von Pfählen vor einer
Bank das Gebäude so in Vibrationen versetzen, dass sich die Schlösser
einiger Tresore von allein öffnen. Ob das dann aber eine praktikabler
Weg für einen Bankraub wäre wage ich zu bezweifeln.
A. H. schrieb:> Ob das dann aber eine praktikabler Weg für einen Bankraub wäre wage> ich zu bezweifeln.
Die Möglichkeit, sowas zu einer Attacke auszunutzen beunruhigt mich
weniger, als die, dass aus derlei Verhalten des RAMs Systeminstabilität
resultiert.
gg schrieb:> Wie im Artikel schon steht - bei den sehr kleinen modernen Strukturen> liegen die Zellen sehr dicht beisammen und könnten sich beeinflussen.> Könnte dann sein, dass beim Auslesen da "übersprechen" auftritt.
Das passiert täglich auf Millionen von Rechnern ohne weiteres
böses Zutun.
Und was passiert also Folge davon? Nichts. Jedenfalls kein
"Übersprechen".
Toll mit was für Käse manche Menschen ihre Lebenszeit vergeuden.
Arduinoquäler schrieb:> Toll mit was für Käse manche Menschen ihre Lebenszeit vergeuden.
Mir wärs auch lieber, wenn sich weltweit niemand mit solchem Käse
befassen müsste...
"Den IT-Sicherheitsforschern Mark Seaborn, Matthew Dempsky und Thomas
Dullien ist es gelungen, durch permanente Speicherzugriffe ausgelöste
Bitflips auszunutzen, um aus einer Sandbox auszubrechen und auf einem
Linux-System Root zu werden." [Golem]
Details:
http://googleprojectzero.blogspot.de/2015/03/exploiting-dram-rowhammer-bug-to-gain.html
Wärs ein paar Wochen später würde ich das auch als Aprilscherz abtun.
Und ich hoffe immer noch inständig, dass da jemand auf dem Kalender
verrutscht ist. Aber es sieht doch ein bisserl zu ernsthaft aus.
A. K. schrieb:> Wärs ein paar Wochen später würde ich das auch als Aprilscherz abtun.
Genauso wie Schololadenweihnachtsmänner und -osterhasen lange vor den
entsprechenden Anlässen in den Regalen liegen, kommen auch die
Aprilscherze immer früher. Jeder Hoaxer will der Erste sein. Unbenommen
der Tatsache, daß es kein einziges System geben dürfte, daß länger als
ein paar Minuten stabil läuft, wenn benachbarte Zugriffe Bits kippen
ließen, scheitert eine solche Attacke auch daran, daß Speicherriegel in
unterschiedlichsten Organisationen verbaut vorkommen und somit gar nicht
gezielt nebeneinander liegende Zellen getroffen werden können. Und dann
gibt es noch den CPU-Cache...
A. K. schrieb:> Aber es sieht doch ein bisserl zu ernsthaft aus.
Der Funken Wahrheit (oder a bisserl mehr) mag ja drin stecken.
Aber für die volle Breite der PCs ist das ohne Belang.
Uhu Uhuhu schrieb:> Die Möglichkeit, sowas zu einer Attacke auszunutzen beunruhigt mich> weniger, als die, dass aus derlei Verhalten des RAMs Systeminstabilität> resultiert.
Das stimmt. Allerdings kann man die Welt nicht beliebig sicher machen.
Wir hatten mal einen Praktikanten, der sollte ein Rack aus dem
Rechenzentrum schieben, hatte aber dummerweise die Tür nicht getroffen
sondern fuhr rechts neben der Tür gegen die Wand. Dort war der
Not-Aus-Schalter. Für's ganze Rechenzentrum. Wir hatten viel Spaß den
Rest des Tages.
A. H. schrieb:> Allerdings kann man die Welt nicht beliebig sicher machen.
Darum gehts auch nicht. Sporadische Systemabstürze, deren Ursache nicht
feststellbar sind, sind so ziemlich das Schlimmste, was ich auf diesem
Sektor kenne.
Der Angriff macht Sinn.
Die FETs und die Wortleitung in der Speicherbank haben Kapazitäten -> es
fliest ein Strom.
Dadurch wird in die benachbarte Leitung eine Spannung eingestreut, die
Gates der benachbarten Leitung werden minimal leitfähig und ein teil der
Ladung geht auf die Wortleitung verloren.
>> daß es kein einziges System geben dürfte, daß länger als>> ein paar Minuten stabil läuft, wenn benachbarte Zugriffe Bits kippen>> ließen
Das liegt daran, dass der Ladungsverlust nur minimal ist. es braucht ca.
138.000* Zugriffe bis einzelne benachbarte Bit's fallen.
und die Zugriffe müssen auch noch zwischen 2 Auffrischungszyklen liegen
*Wenn ich mich richtig erinnere
A. K. schrieb:> Daran wurde selbstredend gedacht.
Dann fällt der Punkt halt weg, das ändert aber nichts am Hoax. Nicht
umsonst gibt es definierte Latenzzeiten für Speicherzugriffe. Ist ein
System spezifikationsgemäß konfiguriert, dann sorgt der
Refreshmechanismus zuverlässig dafür, daß sich ausgelesene Zellen wieder
so weit erholen, daß keine Kipper auftreten. Auch wenn sie bis zum
jüngsten Tag gelesen werden (falls die Hardware bis dahin überlebt).
Dennis R. schrieb:> und die Zugriffe müssen auch noch zwischen 2 Auffrischungszyklen liegen
Der Sinn der Latencys ist ja gerade, dies zu verhindern. Man müßte schon
das BIOS manipulieren, wozu mindestens Rootrechte notwendig sind. Wenn
man die schon hat, kann man sich die Attacke aber sparen.
Icke ®. schrieb:> Dann fällt der Punkt halt weg, das ändert aber nichts am Hoax.
Hoax? Nein, das ist ein prinzipielles Problem, das für kleine µC-Systeme
- ohne Cache - üble Folgen haben kann.
> Ist ein System spezifikationsgemäß konfiguriert, dann sorgt der> Refreshmechanismus zuverlässig dafür, daß sich ausgelesene Zellen wieder> so weit erholen, daß keine Kipper auftreten.
Wenn dennis_r93 mit den 138.000 Lesezugriffen richtig liegt, dann
müssten 64 ms Refresh viel zu viel sein - ob der Wert über den
Spezifikationen liegt? Kaum.
Icke ®. schrieb:> Wenn man die schon hat, kann man sich die Attacke aber sparen.
Die Attacke ist uninteressant. Interessant sind die Instabilitäten, die
evtl. ungewollt auftreten und auf das Problem zurück gehen.
Icke ®. schrieb:> Der Sinn der Latencys ist ja gerade, dies zu verhindern.
Das Refresh-Intervall einer Speicherzelle (d.h. einer Row) liegt im
Millisekundenbereich. Mir wärs schon lieber, wenn auf man deren
Nachbar-Rows nicht nur alle paar Millisekunden zugreifen dürfte, denn
dann hätten wir beim Trommel-Hauptspeicher der IBM 650 bleiben können.
Der einzige Sinn von Latencies besteht ausserdem darin, so kurz wie
technisch möglich sein. ;-)
A. K. schrieb:> Das Refresh-Intervall einer Speicherzelle (d.h. einer Row) liegt im> Millisekundenbereich.
Gut, das stimmt. Trotzdem sind die Hardwaredesigner nicht dúmm. Es würde
mich schon sehr wundern, wenn wiederholte Zugriffe nicht eingeplant
wären, noch dazu bei der relativ läppischen Zahl von 138000. Außerdem
könnte man mit der Methode das Kippen nur in eine Richtung bewirken, was
das Erzeugen funktionierenden Codes nochmals erschwert.
Uhu Uhuhu schrieb:> Nein, das ist ein prinzipielles Problem, das für kleine µC-Systeme> - ohne Cache - üble Folgen haben kann.
Die "kleinen" µCs arbeiten i.d.R. mit SRAM, wären also gar nicht
betroffen. Aber vielleicht kann mal ein Cortex-Programmierer
Beispielcode für ein System mit externem DRAM schreiben, um die These zu
verifizieren.
Icke ®. schrieb:> Gut, das stimmt. Trotzdem sind die Hardwaredesigner nicht dúmm.
Die Entwickler von OpenSSL sich auch nicht dumm. Ich nehme an, dass
sogar die Entwickler von Adobe nicht dumm sind, auch wenn ich mich mit
dieser Annahme vielleicht unbeliebt mache. ;-)
Trotzdem gibts überall Probleme, wo immer du hinsiehst. Auch in
Hardware. PC/Server-Prozessoren haben eine ziemlich dicke Liste mit
Problemen, und da sind auch ein Haufen effektiv nichtdeterministische
Probleme drin. Intel musste in den Haswells nachträglich per BIOS-Update
genau jene Feature abschalten, die deren grosser struktureller Vorteil
gegenüber der Vorgängergeneration war (ok, anfangs nutzt die sowieso
fast niemand, eben weil zu neu).
Schon vor Jahren stellte man fest, dass man Verschlüsselungsprogramme
knacken kann, indem man das Zeitverhalten eines Fremdprozesses über
gezielte Nutzung des Verdrängungsverhaltens von Caches und TLBs
manipuliert, und so auf dessen Speicherzugriffe schliessen kann.
Nein, man kann nicht an alles denken. Aber man weiss nachher immer, dass
man vorher an diese dumme Sache eigentlich hätte denken sollen.
Icke ®. schrieb:> Trotzdem sind die Hardwaredesigner nicht dúmm.
Schau Dir mal die Erratas zu modernen Mikrocontrollern / SoCs an.
Das ist oft ein zweites "Datenblatt" von der Länge her...
(kommt von der ständig wachsenden Komplexität. Es soll aber trotzdem
alles immer schneller und billiger entwickelt werden - da bleibt wenig
Zeit zum Testen)
A. K. schrieb:> Die Entwickler von OpenSSL sich auch nicht dumm.
Nee, nur grob fahrlässig. Wenn man den Heartbleed-Bug betrachtet, muß
vielleicht sogar Vorsatz unterstellt werden.
> und da sind auch ein Haufen effektiv nichtdeterministische> Probleme drin.
Die theoretische (und praktische) Möglichkeit, daß ein Programm
wiederholt auf eine Speicherzelle zugreift, zählt m.E. zu den leicht
vorhersehbaren Problemen.
Wie auch immer, wir sprechen uns im April wieder...
Icke ®. schrieb:> Wie auch immer, wir sprechen uns im April wieder...
Ich hoffe es sehr. Nur wundert mich mittlerweile in dieser Beziehung
kaum noch etwas. Die Nach-Snowden Ära hat Verschwörungstheorien ja auch
eine gänzlich neue Bedeutung verpasst.
Refresh, klingt schon seltsam! Vor Äonen habe ich bei meinen 64KBit
DRAMs den Refresh abgeschaltet und andere Spielereien probiert. Manche
Bereiche hatten noch nach Sekunden die Daten frisch.
Was ich mir vorstellen könnte, wäre ein fehlerhaftes Design. Bei dem bei
zu häufigen Zugriffen in gleiche Bereiche die Refresh-Logik irgendwann
blockiert wird.
Auf dem Friedhof ist alle 20 Jahre Refresh ;-)
Abdul K. schrieb:> Refresh, klingt schon seltsam!
Die beschriebene Methode hat mit dem Refresh praktisch nichts zu tun.
Wenn über wiederholte Zugriffe die Ladung einer Nachbarzelle sukzessive
beeinflusst werden kann, dann muss das allerdings vor dem nächsten
Refresh (oder Lesezugriff) dieser Zelle zu Potte kommen, sonst war die
Mühe umsonst.
Ich kann mir da keine Allgemeingültigkeit vorstellen. Wenn, dann ist da
ein fehlerhaftes Design schuld. Was dann den Kreis der betroffenen
Systeme einschränkt. Gut, der Kreis kann groß sein bei der heutigen
Oligopolie der wenigen Hersteller.
Abdul K. schrieb:> Ich kann mir da keine Allgemeingültigkeit vorstellen.
Angesichts der Vielzahl real existierender Hersteller von DRAM-Chips
braucht man eine Allgemeingültigkeit wohl auch nicht. ;-)
Wieviel sind es denn? Samsung, Hynix, Micron ... fehlt wer? Wenn es
Samsung betreffen sollte, dann wäre doch schon der halbe Markt dabei.
Der Vollständigkeit halber, der etwas akademischer gehaltene
ursprüngliche Artikel:
http://users.ece.cmu.edu/~yoonguk/papers/kim-isca14.pdf
"We demonstrate this phenomenon on Intel and AMD systems using a
malicious program that generates many DRAM accesses. We induce errors in
most DRAM modules (110 out of 129) from three major DRAM manufacturers.
From this we conclude that many deployed systems are likely to be at
risk."
Florian H. schrieb:> Fefe muss wohl mit diesen Hoaxern unter einer Decke stecken
Möglicherweise ist die Kiste auch nur infolge Überhitzung durch die
stundenlange Dauerlast abgekackt.
Ich schrieb:> Der Vollständigkeit halber, der etwas akademischer gehaltene> ursprüngliche Artikel:> http://users.ece.cmu.edu/~yoonguk/papers/kim-isca14.pdf
Hab ich mir durchgelesen. Es läßt sich daraus schlußfolgern, daß
bestimmte Systeme in der Tat anfällig für Bitfehler durch intensive
Lesezugriffe sind. Es läßt sich aber NICHT schlußfolgern, daß mit der
Methode GEZIELTE Bitmanipulationen möglich sind. Wildes Hämmern
verursacht eher nur zufällig erwünschte Bitflips aber zusätzlich jede
Menge Kollateralschaden. Meiner Meinung nach ist daher die
Wahrscheinlichkeit, das System zum Absturz zu bringen, um
Größenordnungen höher als Rootrechte zu erlangen, und daraus noch Nutzen
zu ziehen.
Ich bin kein Systemprogrammierer, könnte mit aber durchaus wirksame
Gegenmaßnahmen auf OS-Ebene vorstellen. Zum einen nicht privilegierten
Prozessen den Lesezugriff auf sensible Bereiche verwehren. Zum anderen
diese Bereiche redundant an verschiedenen Stellen im Speicher halten und
zusätzlich mit Prüfsummen/CRC plausibilisieren. Also wie das z.B. bei
besseren Dateisystemen in ähnlicher Form auch gemacht wird. Desweiteren
gibt es auf Hardwareseite die Möglichkeit, Refresh- und Zugriffstimings
auf sichere Werte anzupassen, wenn auch mit einem gewissen
Performanceverlust. Auf jeden Fall sehe ich in der Holzhammermethode
keine besonders ernstzunehmende Gefahr.
> Es läßt sich aber NICHT schlußfolgern, daß mit der> Methode GEZIELTE Bitmanipulationen möglich sind.
Nachdem das ein analoger Effekt ist, könnte das mit dem Arbeiten von
zwei Seiten und bestimmten Bitpatterns her durchaus sein. Da kullern ja
nur einige 100 Elektronen auf die Leitung, die vom Leseverstärker als 0
oder 1 unterschieden werden müssen. Für bestimmte Speicherchiptypen wäre
mit etwas Aufwand&Kosten ala NSA da evtl. schon was zu finden sein.
Trotzdem ist immer noch das Problem, dass man wissen muss, was "nebenan"
eigentlich im Speicher liegt. Bei einem frisch gestarteten System wäre
das sogar deutlich einfacher, weil es da noch kaum Seitenfragmentierung
gibt. Da ist virtueller Speicher auch physikalisch hintereinander. Aber
ein paar mal den Webbrowser gestartet und alles ist permutiert (BTDT).
> Zum einen nicht privilegierten Prozessen den Lesezugriff auf sensible> Bereiche verwehren.
Du hast das Problem nicht ganz verstanden. Der Lesezugriff geht nur auf
für den Prozess ganz normal zugreifbaren Addressen. Durch die virtuelle
Speicherverwaltung können aber in 4k-Seiten "nebenan" OS-Teile liegen,
die dadurch beeinflusst werden.
> Desweiteren gibt es auf Hardwareseite die Möglichkeit, Refresh- und> Zugriffstimings auf sichere Werte anzupassen,
Die normalen Zugriffstimings sind hier nutzlos, weil es die nur extern
gibt. Intern läuft das Auslesen so schnell ab, wie es eben geht, es wird
dann nur von den Daten her synchronisiert... Der Refresh wäre dem Paper
nach wohl das einzige.
So inhaltlich klingt das ganz schon "technically sound", aber ein Hoax
könnte es immer noch sein ;)
Icke ®. schrieb:> Wildes Hämmern> verursacht eher nur zufällig erwünschte Bitflips aber zusätzlich jede> Menge Kollateralschaden. Meiner Meinung nach ist daher die> Wahrscheinlichkeit, das System zum Absturz zu bringen, um> Größenordnungen höher als Rootrechte zu erlangen, und daraus noch Nutzen> zu ziehen.
Ach, hast dus jetzt auch gemerkt?
> Ich bin kein Systemprogrammierer, könnte mit aber durchaus wirksame> Gegenmaßnahmen auf OS-Ebene vorstellen. Zum einen nicht privilegierten> Prozessen den Lesezugriff auf sensible Bereiche verwehren.
Dann doch lieber ECC-RAM.
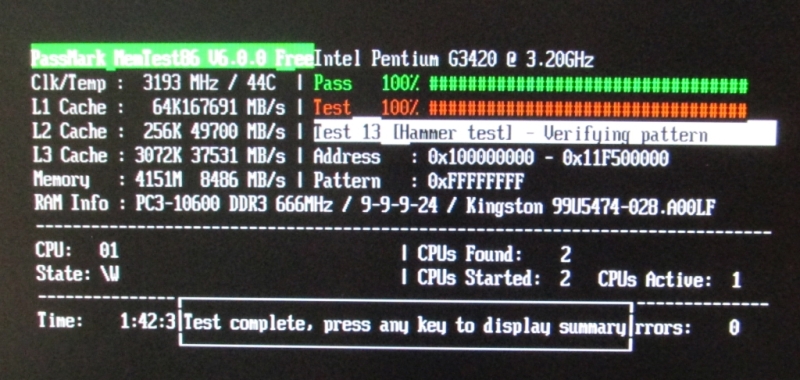
Memtest kann das mittlerweile auch ;-)
http://www.memtest86.com/support/ver_history.htm
New "Hammer Test" for detecting disturbance errors caused by charge
leakage when repeatedly accessing addresses in the same memory bank but
different rows in a short period of time.
Georg A. schrieb:> Du hast das Problem nicht ganz verstanden. Der Lesezugriff geht nur auf> für den Prozess ganz normal zugreifbaren Addressen. Durch die virtuelle> Speicherverwaltung können aber in 4k-Seiten "nebenan" OS-Teile liegen,> die dadurch beeinflusst werden.
Ich meine nicht den Zugriff zum Zwecke des Hämmerns, sondern in dieser
Beziehung:
> Trotzdem ist immer noch das Problem, dass man wissen muss, was "nebenan"> eigentlich im Speicher liegt.
Wozu benötigt ein Userprogramm bspw. Zugriff auf /proc/PID/pagemap und
wozu muß es im Falle NaCl das Codesegment der Sandbox lesen können? Wenn
das Userprog nur den ihm zugewiesenen Speicher lesen darf, kann es nicht
prüfen, welche Erfolge die Klopforgie gezeitigt hat und die Attacke kann
höchstens noch verwendnet werden, um den Rechner abzuschießen.
> Nachdem das ein analoger Effekt ist, könnte das mit dem Arbeiten von> zwei Seiten und bestimmten Bitpatterns her durchaus sein.
Die Experten im o.g. Bericht haben es jedenfalls nicht geschafft. Selbst
mehrere Durchläufe mit der gleichen Hardware brachten unterschiedliche
Ergebnisse.
> So inhaltlich klingt das ganz schon "technically sound", aber ein Hoax> könnte es immer noch sein ;)
Daß mit Rowhammer prinzipiell Bitflips erzeugt werden können, scheint zu
stimmen. Aber aus der Methode einen verwertbaren Exploit zu
konstruieren, dürfte ein Hoax sein.
Angriffe über Arbeitsspeicherfehler gibts schon lange. Da gab es auch
mal Leute die ein radioaktives Präparat neben den Arbeitsspeicher
gestellt haben um aus einer, damals als sicher geltenden, Java Sandbox
auszubrechen.
Also was lernen wir daraus:
ECC-Ram ist ein Sicherheitsfeature
Auf Sandkästen kann man sich nicht verlassen
Dufe schrieb:> Was soll ein OS an kaputten RAM ändern können?
Wenig bis nichts. Es kann aber dafür sorgen, daß die Fehler nicht für
Angriffe nutzbar sind, siehe oben.
Dufe schrieb:>> Oder ein sicheres Betriebssystem.>> Was soll ein OS an kaputten RAM ändern können?
Kaputt vermeiden.
Per Hintergrundprozess mit vollem Tempo der Reihe nach alle Rows
auslesen - ein Zugriff pro Row reicht. Ergibt einen Soft-Refresh mit
sehr viel kürzerem Intervall als der Hardware-Refresh.
A. K. schrieb:> Per Hintergrundprozess mit vollem Tempo der Reihe nach alle Rows> auslesen - ein Zugriff pro Row reicht. Ergibt einen Soft-Refresh mit> sehr viel kürzerem Intervall als der Hardware-Refresh.
Und warum nicht gleich die Refreshrate erhöhen?
Generell sind Versuche, Hardwaremacken per Software auszuwetzen nicht
effizient und tendieren dazu, ein Fass ohne Boden zu werden...
Uhu Uhuhu schrieb:> Und warum nicht gleich die Refreshrate erhöhen?
Oder das. Aber die Frage war nach dem Betriebssystem. ;-)
Ausserdem haben viele PCs noch haufenweise unausgelastete CPU-Kerne
rumliegen. Warum nicht einmal etwas findet, das die auslastet?
Uhu Uhuhu schrieb:> Generell sind Versuche, Hardwaremacken per Software auszuwetzen nicht> effizient und tendieren dazu, ein Fass ohne Boden zu werden...
Korrekt. Aber wie sonst will man den Leuten mit 8 CPU-Kernen einen neuen
Prozessor mit 16 verkaufen? ;-)
Uhu Uhuhu schrieb:> Generell sind Versuche, Hardwaremacken per Software auszuwetzen nicht> effizient und tendieren dazu, ein Fass ohne Boden zu werden...
Leider ist das heute gängige Praxis, bei der unreifen 'Bananenware'. Die
Hardware ist da oft genauso unreif, wie die Software. Software kann man
aber nachreichen, an schon verkaufter Hardware kann man nichts mehr
machen. Also versucht man, meist eher schlecht als recht, die Mängel per
Software zu flicken.
Mit freundlichen Grüßen - Martin
A. K. schrieb:> Ausserdem haben viele PCs noch haufenweise unausgelastete CPU-Kerne> rumliegen. Warum nicht einmal etwas findet, das die auslastet?
Weil die Attacke insbesondere Laptops betrifft die auch mal auf Akku
laufen sollen.
Icke ®. schrieb:> Es würde mich schon sehr wundern, wenn wiederholte Zugriffe nicht> eingeplant wären, noch dazu bei der relativ läppischen Zahl von 138000.
Das kommt so aber in der Praxis normalerweise nicht vor.
Icke ®. schrieb:> Die theoretische (und praktische) Möglichkeit, daß ein Programm> wiederholt auf eine Speicherzelle zugreift, zählt m.E. zu den leicht> vorhersehbaren Problemen.
Normalerweie laufen diese wiederholten Zugriffe aber komplett im Cache
ab, und der Hauptspeicher sieht davon gar nichts. Daß ein Programm nach
jedem einzelnen dieser Zugriffe auch gleich explizit angibt, daß der
Wert sofort in den Speicher weitergeschrieben werden soll, ist ganz und
gar nicht üblich. Schon gar nicht 138.000 mal in 65 ms. Wozu sollte das
in einem normalen Anwendungsszenario überhaupt benötigt werden?
A. K. schrieb:> Ich hoffe es sehr. Nur wundert mich mittlerweile in dieser Beziehung> kaum noch etwas. Die Nach-Snowden Ära hat Verschwörungstheorien ja auch> eine gänzlich neue Bedeutung verpasst.
Sie hat halt vor allem gezeigt, daß viele der Verschwörungstheorien ganz
und gar nicht nur Spinnereien von Alufolienhut-Trägern sind.
Rolf Magnus schrieb:> Daß ein Programm nach> jedem einzelnen dieser Zugriffe auch gleich explizit angibt, daß der> Wert sofort in den Speicher weitergeschrieben werden soll, ist ganz und> gar nicht üblich.
Wie auch alle anderen Arten von Fehlern in der Computerei nicht üblich
sind...
> Sie hat halt vor allem gezeigt, daß viele der Verschwörungstheorien ganz> und gar nicht nur Spinnereien von Alufolienhut-Trägern sind.
Inhaltsloser Schwachsinn.
Uhu Uhuhu schrieb:> Rolf Magnus schrieb:>> Daß ein Programm nach>> jedem einzelnen dieser Zugriffe auch gleich explizit angibt, daß der>> Wert sofort in den Speicher weitergeschrieben werden soll, ist ganz und>> gar nicht üblich.>> Wie auch alle anderen Arten von Fehlern in der Computerei nicht üblich> sind...
Und deshalb gibt es sie. Warum ist es bei diesem also so unglaublich,
dass es ihn gibt? Sollte eben nicht sein, ist aber so. Wenn man ein
Problem nicht versteht, heißt das nicht, daß es nicht da ist.
>> Sie hat halt vor allem gezeigt, daß viele der Verschwörungstheorien ganz>> und gar nicht nur Spinnereien von Alufolienhut-Trägern sind.>> Inhaltsloser Schwachsinn.
Gut, nicht jeder hat aus der Snowden-Geschichte was gelernt.
Rolf Magnus schrieb:> Normalerweie laufen diese wiederholten Zugriffe aber komplett im Cache> ab, und der Hauptspeicher sieht davon gar nichts. Daß ein Programm nach> jedem einzelnen dieser Zugriffe auch gleich explizit angibt, daß der> Wert sofort in den Speicher weitergeschrieben werden soll, ist ganz und> gar nicht üblich.
Das ist richtig und deswegen kommt es in der Praxis nicht zum Tragen.
Aus Sicht eines Speicherdesigners müßte ich diesen Fall trotzdem
einplanen, auch wenn er nicht üblich ist.
X2 schrieb:> Memtest kann das mittlerweile auch
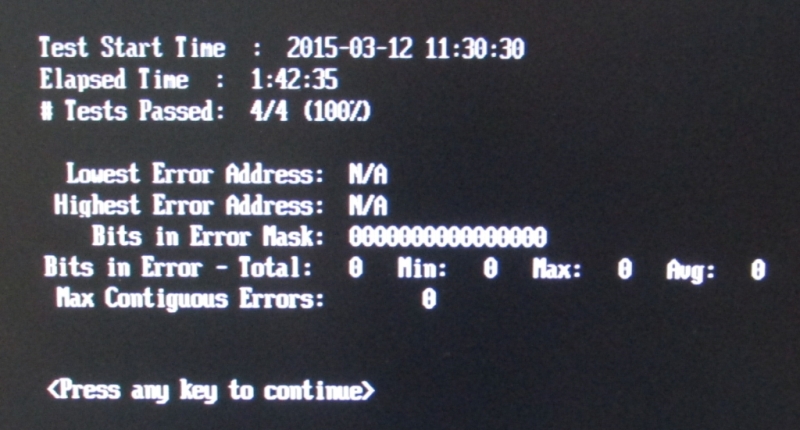
Getestet, siehe Bilder. Eindreiviertel Stunden den Schmied gespielt und
nix passiert. Zweiter Test läuft gerade mit anderem Riegel, nach 17
Minuten noch Null Errors.
Asko B. schrieb:> laut memtest2.jpg bist Du uns sowieso bereits> einen Tag vorraus. ;-)
Verflixt, die haben meine CMOS-Uhr zerhämmert!!
Btw, mit dem zweiten und auch dritten Modul ebenfalls keine Fehler.
Icke ®. schrieb:> Hab ich mir durchgelesen. Es läßt sich daraus schlußfolgern, daß> bestimmte Systeme in der Tat anfällig für Bitfehler durch intensive> Lesezugriffe sind. Es läßt sich aber NICHT schlußfolgern, daß mit der> Methode GEZIELTE Bitmanipulationen möglich sind.
Siehe Google-Seite unter Kernel privilege escalation bzw.
"There are two things that help ensure that the bit flip has a high
probability of being exploitable:
1. Rowhammer-induced bit flips tend to be repeatable...
2. We spray most of physical memory with page tables. This means that
when a PTE's physical page number changes, there's a high probability
that it will point to a page table for our process..."
> Ich bin kein Systemprogrammierer, könnte mit aber durchaus wirksame> Gegenmaßnahmen auf OS-Ebene vorstellen. Zum einen nicht privilegierten> Prozessen den Lesezugriff auf sensible Bereiche verwehren.
Das ist solchen Prozessen schon verwehrt...
> Zum anderen> diese Bereiche redundant an verschiedenen Stellen im Speicher halten und> zusätzlich mit Prüfsummen/CRC plausibilisieren.
Und wie oft soll das gemacht werden?
Die Google-Methode sucht mehr oder weniger gezielt nach Bit-Fehlern in
Page-Table-Einträgen. Davon gibt's eine ganze Menge insb. wenn mmap und
4 kiB-Seiten genutzt werden. Zudem "Huge pages cannot be swapped out
under memory pressure."
https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt> Auf jeden Fall sehe ich in der Holzhammermethode> keine besonders ernstzunehmende Gefahr.
Das kann man so sehen, muss man aber nicht...
Arc Net schrieb:> Das kann man so sehen, muss man aber nicht...
Er macht sich Sorgen ob des anstehenden Berufswechsels: ;-)
Icke ®. schrieb:> Ich auch, ansonsten fall ich vom Glauben ab, mach meinen IT-Laden zu und> laß mich zum Friedhofsgärtner umschulen...
A. K. schrieb:> Arc Net schrieb:>> Das kann man so sehen, muss man aber nicht...>> Er macht sich Sorgen ob des anstehenden Berufswechsels: ;-)>> Icke ®. schrieb:>> Ich auch, ansonsten fall ich vom Glauben ab, mach meinen IT-Laden zu und>> laß mich zum Friedhofsgärtner umschulen...
Ob das vor Row-Hammering schützt... Wer weiß, vielleicht ist die erste
App mit passendem Grabpflegeroboter gar schon in Entwicklung ;)
Arc Net schrieb:> 1. Rowhammer-induced bit flips tend to be repeatable.
Das heißt aber nicht, daß bestimmte Bits zuverlässig beeinflußt werden
können. Grundsätzlich sind nur geladene Zellen anfällig, ungeladene
können nicht aufgeladen werden. Die Orientierung der Zellen, d.h. ob sie
im geladenen Zustand eine 1 oder eine 0 repräsentieren, ist auch nicht
einheitlich. Die Speicherriegel bestehen intern sogar aus Mischungen
verschieden orientierter Zellen. Wenn ich nun ein bestimmtes Bit auf 0
kippen will, dieses aber in einer anti cell (aktiv 0) liegt, dann wirds
nix. Weiterhin besteht kein zwingender Zusammenhang zwischen logischer
und physischer Nachbarschaft von Zellen. Ein logisch benachbartes Bit
kann physisch ein paar Reihen weiter oder gar (durch Remapping bedingt)
sonstwo liegen. Und letztendlich ist sowieso nur ein Bruchteil der
Zellen eines Riegels überhaupt anfällig für Bitflips. Den RAM komplett
auf anfällige Zellen zu analysieren, kann laut Kim et al Tage dauern:
"This implies that
an exhaustive search for every possible victim cell would re-
quire a large number of iterations, necessitating several days
(or more) of continuous testing."
Die Chance, eine ganz bestimmte Zelle kippen zu können. ist also gar
nicht sehr groß.
In den Blogs wird es teilweise so dargestellt, als ob die Googletruppe
schon den Weg zum Rootrecht freigemacht hätte. In Wirklichkeit bedarf es
einer ganzen Kette von Glücksumständen, um mit den Bitflips etwas
sinnvolles anstellen zu können. Von einem echten Exploit noch weit
entfernt.
> Das ist solchen Prozessen schon verwehrt.
Offensichtlich nicht, sonst wäre das Problem nicht existent.
> Die Google-Methode sucht mehr oder weniger gezielt nach Bit-Fehlern in> Page-Table-Einträgen. Davon gibt's eine ganze Menge
Würde es nicht helfen, die page tables selbst redundant anzulegen und
zyklisch die Konsistenz zu prüfen, sodaß Manipulationen auffallen?
Icke ®. schrieb:> Würde es nicht helfen, die page tables selbst redundant anzulegen und> zyklisch die Konsistenz zu prüfen, sodaß Manipulationen auffallen?
Jeder Prozess hat seine eigene Page Table... Wieviele Prozessorkerne
wist du für den Quatsch spendieren und wieviel Strom?
Hardwarefehler - nichts anderes ist das - per Software reparieren zu
wollen, ist eine Schnapsidee.
Icke ®. schrieb:> Und letztendlich ist sowieso nur ein Bruchteil der> Zellen eines Riegels überhaupt anfällig für Bitflips. Den RAM komplett> auf anfällige Zellen zu analysieren, kann laut Kim et al Tage dauern:
Daher auch das Spraying, welches vergleichbar auch bei anderen Exploits
benutzt wird.
Der Exploit hier sprayed erst mal den Speicher mit Page-Table-Einträgen
voll, versucht dann in irgendeinem dieser Einträge einen Bitfehler zu
erzeugen, der dazu führt, dass danach ein anderer Page-Table-Eintrag im
beschreibbaren Adressraum des Angreifers liegt (was er vorher nicht
tat).
Ist ein solcher Eintrag erzeugt worden, bedeutet dies nichts anderes als
uneingeschränkten Zugriff auf den gesamten Speicher...
> In den Blogs wird es teilweise so dargestellt, als ob die Googletruppe> schon den Weg zum Rootrecht freigemacht hätte. In Wirklichkeit bedarf es> einer ganzen Kette von Glücksumständen, um mit den Bitflips etwas> sinnvolles anstellen zu können. Von einem echten Exploit noch weit> entfernt.
Den Proof-of-Concept-Exploit kann man hier
http://www.exploit-db.com/exploits/36310/ im Quelltext bekommen
http://www.exploit-db.com/sploits/36310.tar.gz
Arc Net schrieb:> Daher auch das Spraying, welches vergleichbar auch bei anderen Exploits> benutzt wird.
Meine letzten praktischen Kontakte mit systemnaher Programmierung liegen
ein wenig zurück, sprich letztes Jahrtausend. Ich mußte mich zunächst
einlesen, habe das Prinzip der Attacke über die page tables aber nunmehr
verstanden. Gut, sie funktioniert grundsätzlich. Das ändert aber nichts
an meiner Ansicht, daß sie keine nenneswerte Bedrohung darstellt. Eher
bestärkt es mich darin, weil für das Erreichen des letztendlichen
Zieles, das Kompromittieren des Systems, ein hohes Maß an
Voraussetzungen und auch "Glück" erforderlich sind. Basierend auf den
Berichten und Zahlen von Kim et al und der Zero-Gruppe wären das u.a.:
1. Die Hardwareplattform muß grundsätzlich verwundbar sein. Mit ECC-RAM
bestückte und/oder vor 2010 hergestellte Systeme sind so gut wie nicht
betroffen.
2. Die RAM-Riegel müssen anfällig sein, es sind ~85% der getesteten.
3. Nur eine von 1700 Speicherzellen (0,06%) neigt zu Bitflips, eher
weniger.
4. Die Zufallsanalyse mittels page table spraying erfordert große Mengen
freien RAMs, um effizient und schnell arbeiten zu können.
5. Während des Hämmerns darf kein Refresh oder Zugriff durch andere
Prozesse in die Quere kommen.
6. Eine page table aus dem Adressraum des angreifenden Prozesses muß
durch Bitflips betroffen sein.
7. Die "Mutation" dieser page table(s) muß für weiteres Vorgehen nutzbar
sein.
8. Das Betriebssystem muß gegen diese Art von Attacke anfällig sein.
9. Virtualisierung erschwert die Attacke oder verhindert sie ganz.
10. Kollateralschäden durch nicht beabsichtigte Bitflips können
unvorhersehbare Auswirkungen haben, bis hin zum Absturz des Systems.
Man könnte nun die Wahrscheinlichkeit des Erfolges berechnen, wenn
weitere statistische Daten wie Marktanteile der Systeme, mittlere
Auslastungen usw. bekannt wären. Aber auch ohne Rechnung dürfte die
Erfolgsquote nicht sonderlich hoch einzuschätzen sein.
Die für Hacker lohnenswertesten Ziele, nämlich Server, fallen aufgrund
der Punkte 1 und 9 schon mal größtenteils weg. Von den anderen Systemen
ist nur ein Teil anfällig. Außerdem existieren aufgrund von
Sicherheitslücken in OS und Anwendungen jede Menge wesentlich einfachere
Möglichkeiten, um das System zu infiltrieren. Also warum so umständlich?
Icke ®. schrieb:> 8. Das Betriebssystem muß gegen diese Art von Attacke anfällig sein.
Alle Betriebssyteme sind dafür anfällig. Einen wirksamen Schutz dagegen
gibt es nicht.
> 9. Virtualisierung erschwert die Attacke oder verhindert sie ganz.
Wer sagt das? Auch virtualisierte Systeme haben Page Tables.
> 10. Kollateralschäden durch nicht beabsichtigte Bitflips können> unvorhersehbare Auswirkungen haben, bis hin zum Absturz des Systems.
Das ist das eigentliche Problem. Die Bedrohungsszenarien sind so
wacklig, dass damit bestensfalls Zufallstreffer zu erzielen sind.
Uhu Uhuhu schrieb:> Hardwarefehler - nichts anderes ist das - per Software reparieren zu> wollen, ist eine Schnapsidee.
Besser als sie gar nicht zu reparieren. Und es ist auch ein sehr
gängiger Weg, da sich Software in der Regel viel leichter und
kostengünstiger tauschen läßt als die dazugehörige Hardware.
Oder sollen jetzt alle weltweit ihren Speicher (oder wenn der nicht
ausbaubar ist, das ganze Gerät) wegwerfen und neu kaufen, wenn ein
Betriebssystem-Update es auch täte?
Icke ®. schrieb:> Getestet, siehe Bilder. Eindreiviertel Stunden den Schmied gespielt und> nix passiert. Zweiter Test läuft gerade mit anderem Riegel, nach 17> Minuten noch Null Errors.
Grund für die Auswirkungen der Leseoperationen auf Nachbarzellen sind
doch die kleineren Strukturbreiten. Da sind wir jetzt bei 25 nanometer
(DDR3 80-25nm) und waren vor einigen Jahren bei DDR2 noch bei 100 - 60
nm.
https://www.thomas-krenn.com/de/wiki/DDR-SDRAM
Dann ist doch davon auszugehen das ältere Riegel weniger bis garnicht
"verletzlich" sind. Gibt es dazu eine Statistik?
Solche Crosstalk/Leckstrom-Probleme im IC sind für Hardwareentwickler
nix neues, da gibt es einige bewehrte Gegenmaßnahmen. Eine ist die
Flanken der Impulse nur so steil zu gestalten wie nötig.
Mitverantwortlich für die Flankensteilheit ist die Bufferung der
Betriebsspannung, die Kondensatoren zwischen Vcc und Masse. Gibt es da
Erfahrung wie sich bspw das ESR der C auf das interne crosstalk
auswirkt? Also Speicherriegel mit identsichen Speicher-IC aber anderen
Modulhersteller mit anderen Kondensatoren.
MfG,
Bei modernen Chips sind oft Abblockkondensatoren (1. Stufe) und
Spannungsregler mit auf dem Chip integriert. Vermutlich oft als
parasitäre Strukturen.
Wer sich schon immer wunderte, warum manche CPLDs so viel Leistung
verheizen, weiß es jetzt ;-) Es gibt z.B. ein Patent, da ist der
Spannungsregler als äußerste Struktur am Rand des Chips rundherum
verteilt angelegt.
Uhu Uhuhu schrieb:> Hardwarefehler - nichts anderes ist das - per Software reparieren zu> wollen, ist eine Schnapsidee.
Ne das ist gängige Praxis. Beispielsweise das wear-leveling bei
Solidstatedisks und flash generell. Die billigen hochkapazitiven
Multilevel Flash heute vertragen nur noch einige hundert Speicherzyklen.
Also baut man die SSD mit super intelligenten Controllern und
filesystemen bei denen keine Zelle überstrapaziert wird.
Alternativ könnte man natürlcich robustere Flash-Speicher verwenden
(single-level, geringere Speicherdichte)
MfG,
Icke ®. schrieb:> Würde es nicht helfen, die page tables selbst redundant anzulegen und> zyklisch die Konsistenz zu prüfen, sodaß Manipulationen auffallen?
Gibt es schon, nennt sich ECC-Speicher.
Das gute an dem Bug wird wohl sein das Systeme mit ECC stärker im Markt
nachgefragt werden. Leider ist das Angebot an günstigen Systemen mit ECC
stark rückläufig.
Dirk schrieb:> Leider ist das Angebot an günstigen Systemen mit ECC stark rückläufig.
Die Prozessoren können es und für passenden ECC-Speicher brauchts nur
1-2 DRAM-Chips mehr auf dem Modul. Fehlt möglicherweise der BIOS
Support, aber auch das steckt da im Grunde schon drin, ist nur mangels
Bedarf mitunter abgeschaltet. Wenn also aufgrund RowHammer der Bedarf
kommen sollte kann darauf recht schnell reagiert werden.
Sollte das BIOS kein Scrubbing vorsehen (regelmässiges Kontrolllesen um
kumulierende Bitfehler zu vermeiden): Das lässt sich per Software
harmlos nachrüsten.
Uhu Uhuhu schrieb:> Einen wirksamen Schutz dagegen gibt es nicht.
Theoretisch schon, wenn auch zu Lasten der Performance. Das OS muß
eigentlich nur in so kurzen Abständen auf die page tables zugreifen, daß
die Attacke keine Chance hat, die Zellentladung zu vollenden. Oder die
page tables spiegeln. Ja, das ist nicht optimal, wäre aber eine
Möglichkeit.
> Auch virtualisierte Systeme haben Page Tables.
Der Hypervisor muß lediglich die Ausführung der CLFLUSH Instruktion
durch Gäste unterbinden und schon läuft die Attacke ins Leere (bzw. den
CPU-Cache).
> Wer sagt das?
Die Zero-Truppe. Die haben nämlich genau dieses Feature in der NaCL
Sandbox nachgerüstet. Steht in dem Blog.
Fpga Kuechle schrieb:> Dann ist doch davon auszugehen das ältere Riegel weniger bis garnicht> "verletzlich" sind. Gibt es dazu eine Statistik?
Aus dem Paper von Kim et al läßt sich entnehmen, daß Systeme vor 2010
kaum bis gar nicht betroffen sind und daß die Verwundbarkeit bei ganz
neuen Systemen wieder zurückgeht. Siehe PDF-Seite 6, Figure 3.
Auch wenn es schon vom Ansatz her naheliegt halte ich angesichts der
doch relativ geringen Anzahl der Module pro Zeitpunkt und der
drastischen Streuung der Ergebnisse eine statistische Aussage der
Entwicklung über die Jahre für mutig, insbesondere für 2014 mit nur 4
Modulen insgesamt und davon 3 von einem Hersteller.
Rolf Magnus schrieb:> Besser als sie gar nicht zu reparieren. Und es ist auch ein sehr> gängiger Weg, da sich Software in der Regel viel leichter und> kostengünstiger tauschen läßt als die dazugehörige Hardware.
Sowas kann man per Software gar nicht zuverlässig reparieren und
irgendwelche Hacks kosten jede Menge CPU-Leistung, bringen aber keine
sichere Lösung.
Fpga Kuechle schrieb:> Ne das ist gängige Praxis. Beispielsweise das wear-leveling bei> Solidstatedisks und flash generell.
Das ist doch was völlig anderes, als RAMs, die auf kritische
Zugriffmuster mit Informationsverlust reagieren.
Ausgelutschte Flash-Zellen sind kaputt, das ist Verschleiß; durch das
Geschehen auf den Zugriffsleitungen kippende RAM-Zellen sind nicht
kaputt - das ganze Design ist kaputt. Diese Art Fehler ist nur durch
Hardware - also z.B. ECC - reparierbar.
Software geht davon aus, dass die Hardware genau das tut, was
spezifiziert ist. Alles andere ist ganz einfach nicht praktikabel.
Icke ®. schrieb:> Theoretisch schon, wenn auch zu Lasten der Performance. Das OS muß> eigentlich nur in so kurzen Abständen auf die page tables zugreifen, daß> die Attacke keine Chance hat, die Zellentladung zu vollenden. Oder die> page tables spiegeln. Ja, das ist nicht optimal, wäre aber eine> Möglichkeit.
Alle 100.000 Speicherzyklen alle Page Tables durchnudeln? Was bleib da
von der Speicherbandbreite übrig?
Und das erschwert nur Attacken auf die Page Tables. Provozierte
Systemabstürze sind damit nich aus der Welt.
Uhu Uhuhu schrieb:> Fpga Kuechle schrieb:>> Ne das ist gängige Praxis. Beispielsweise das wear-leveling bei>> Solidstatedisks und flash generell.>> Das ist doch was völlig anderes, als RAMs, die auf kritische> Zugriffmuster mit Informationsverlust reagieren.
Ja, es ist noch viel schlimmer, da sie auf kritische Zugriffsmuster
sogar mit Defekt reagieren, und in diesem Fall sogar auf Zugriffsmuster,
die auch in ganz normalen Standardsituationen vorkommen und nicht nur
auf welche, die explizit provoziert werden müssen.
> Ausgelutschte Flash-Zellen sind kaputt, das ist Verschleiß;
Ja. Sie verschleißen aufgrund der eingesetzen Technologie so schnell,
daß das für Standardanwendungen untragbar ist. Deshalb muß man außenrum
irgendwelche ausgeklügelten Verfahren basteln, damit man sie trotzdem
noch vernünftig nutzen kann.
> Software geht davon aus, dass die Hardware genau das tut, was> spezifiziert ist. Alles andere ist ganz einfach nicht praktikabel.
Hardware geht dagegen immer öfter nicht mehr davon aus,daß die Software
genau das tut, was spezifiziert ist. Das war früher mal so, aber da es
zu oft vorkam, daß durch Fehler in der Software die Hardware zerstört
wurde, werden heute entsprechende Sicherheitsvorkehrungen eingebaut.
Rolf Magnus schrieb:> Hardware geht dagegen immer öfter nicht mehr davon aus,daß die Software> genau das tut, was spezifiziert ist.
Das würde ich anders formulieren:
Hardware wird im Idealfall so konzipiert, dass jede beliebige Software
darauf keine bleibenden Schäden anrichten kann - vergleichbar mit der
Eigensicherheit im Maschinenbau.
Es handelt sich nicht um ein Feature zur Bändigung "bösartiger"
Software, sondern um eine Sicherung der Hardware vor sich selbst: sie
wird vor Selbstbeschädigung geschützt. (Immerhin ist ja denkbar, dass
dieser "bösartige" Code durch irgend welches schräges Verhalten der
Hardware in den Speicher kommt und dann Rauchwölkchen auslöst...)
Die Bedeutung von Codebits ergibt sich aus der Hardware - aus sich
selbst sind sie bedeutungslos.
Arc Net schrieb:> Nur ein paar unterstützen ECC...
50 aktuelle Prozessoren für den Desktop-Bereich (von 202):
http://ark.intel.com/de/search/advanced?s=t&FilterCurrentProducts=true&MarketSegment=DT&ECCMemory=true
Letztlich ist das Intels Spiel mit den Features und der schier
unendlichen Palette von Prozessoren. Technisch sind das nur relativ
wenige wirklich verschiedene Dies, die sich in der Kennung und den
freigeschalteten Features unterscheiden.
Daher sind praktisch alle Dies, die sowohl im Server- als auch im
Desktop-Bereich eingesetzt werden, prinzipiell zu ECC fähig. Und so
kommt man dann eben zu einem Celeron mit ECC, weil der gleiche Haswell
drin steckt wie in einem irgendeinem Xeon E3.
> Und dann müssen die Mainboards ECC auch unterstützen...
Verdrahtung der Datenbits, und BIOS.
Arc Net schrieb:> Bei AMD können zwar z.B. die FX alle ECC, aber die APUs afaik nur in der> eingelöteten Notebook-Variante.
Yup. AMD ist eine andere Baustelle, weil die mittlerweile den
Server-Markt praktisch nicht mehr bedienen.
Übrigens, ECC löst, anders wie der heise Artikel suggeriert, das Problem
nicht wirklich.
ECC wie heute bei den ECC-Speicherriegeln eingesetzt korregiert nur wenn
ein einziges bit im Wort kippt. Schon bei zwei bit im Wort gedreht ist
der Fehler auch mit ECC nur durch reboot sicher korigierbar, bei drei
bit ist es ganz schlimm, das wird nichtmal erkannt.
Und laut der Orginalquelle (danke für den link) S.8 Tab. 5 gab es am
bspw für einen Riegel 9,8 Mio einbitfehler (korigierbar); 182 Tsd
zweibitfehler (geordneter reboot); 2,3 Tsd drei-und 4bitfehlerfehler
(nicht erkennbar) .
Wofür ECC heute eingesetzt wird und was es kann kann man aus dieser
Meldung ablesen:
http://www.heise.de/newsticker/meldung/Hauptspeicherfehler-sehr-viel-haeufiger-als-bisher-angenommen-828883.html
Dagegen hilft nur Speicher mit größerer Strukturbreite, also vielleicht
etwa von vor 2011 gefertigt.
Vielleicht zeigt der Row-hammer ja auf das die Zeiten des immer mehr
Speichers durch immer kleineren Strukturen vorbei ist - mal wieder Zeit
nachzudenken Systen zu bauen/programmieren die auch mit weniger Speicher
(ein paar Gigabyte) pro Core effizient arbeiten.
Wahrscheinlich genügt es auch schon wenn der Cache nicht deaktiviert
oder von jedem entleert werden kann. Dann dürfte es für die Software
nicht möglich sein in kürzester Zeit hunderttausend Mal hintereinander
eine nicht geänderte Speicherzelle im Arbeitsspeicher auszulesen. Das
deutet ja der heise Artikel so an.
MfG,
Fpga Kuechle schrieb:> Dagegen hilft nur Speicher mit größerer Strukturbreite, also vielleicht> etwa von vor 2011 gefertigt.
Na ein Glück das meine Kiste von 2008 mit 8GByte DDR2 noch schnell genug
für alles was ich so mache ist ;-) ;-P
Fpga Kuechle schrieb:> Übrigens, ECC löst, anders wie der heise Artikel suggeriert, das Problem> nicht wirklich.>> ECC wie heute bei den ECC-Speicherriegeln eingesetzt korregiert nur wenn> ein einziges bit im Wort kippt. Schon bei zwei bit im Wort gedreht ist> der Fehler auch mit ECC nur durch reboot sicher korigierbar, bei drei> bit ist es ganz schlimm, das wird nichtmal erkannt.>> Und laut der Orginalquelle (danke für den link) S.8 Tab. 5 gab es am> bspw für einen Riegel 9,8 Mio einbitfehler (korigierbar); 182 Tsd> zweibitfehler (geordneter reboot); 2,3 Tsd drei-und 4bitfehlerfehler> (nicht erkennbar) .>
Ist doch usus z.B. in der Raumfahrt einfach im Hintergrund den Speicher
systematisch durchzulaufen und damit Einzelbitfehler vor dem möglichen
Erscheinen eines zweiten Bitfehlers zu korrigieren. Dann reicht eine ECC
1-Bit Korrekturmöglichkeit.
>> Dagegen hilft nur Speicher mit größerer Strukturbreite, also vielleicht> etwa von vor 2011 gefertigt.>
Warte einfach den Hype ab. Die sehen darin alle die NSA.
Hach, wie gerne ich sowas lese:
"
> Vielleicht zeigt der Row-hammer ja auf das die Zeiten des immer mehr> Speichers durch immer kleineren Strukturen vorbei ist - mal wieder Zeit> nachzudenken Systen zu bauen/programmieren die auch mit weniger Speicher> (ein paar Gigabyte) pro Core effizient arbeiten.
"
Wirklich, schnelle und sparsame Programme?? YMMD
Fpga Kuechle schrieb:> ECC wie heute bei den ECC-Speicherriegeln eingesetzt korregiert nur wenn> ein einziges bit im Wort kippt.
Zumindest in der häufigsten SECDED Implementierung. Bei Servern findet
man allerdings mittlerweise öfter auch RAM-Mirroring als Option.
Eine andere Variante ist ein Speichersystem, bei dem der Totalausfall
eines DRAM-Chips toleriert werden kann (bei IBM als "Chipkill"
bezeichnet). Je nach Implementierung sind dabei deutlich mehr Bitfehler
korrigierbar, oder ein Speicherwort wird so auf Module und RAM-Chips
verteilt, dass kein Chip mehr als 1 Bit des Wortes enthält (was in
diesem Zusammenhang die Wahrscheinlichkeit von Mehrbit-Fehlern
reduziert).
> Schon bei zwei bit im Wort gedreht ist> der Fehler auch mit ECC nur durch reboot sicher korigierbar,
Ein entscheidender Punkt ist aber, dass sowohl 1- wie 2-Bit-Fehler
erkannt und protokolliert werden können. Da ein RowHammer Angriff jede
Menge Fehler produziert stehen die Chancen recht gut, dass man einen
entsprechenden Angriff schnell bemerkt. Und zwar mit ziemlich klarer
Aussage, nicht bloss mit mysteriösen Crashes.
Da 2-Bit-Fehler zum automatischen Stop/Restart von Systemen mit ECC
führen sollten, ist die Chance, mit einem Angriff mehr zu erreichen als
einen DOS, ausgesprochen gering.
> Wahrscheinlich genügt es auch schon wenn der Cache nicht deaktiviert> oder von jedem entleert werden kann.
Dazu sind ausserhalb virtualisierter Umgebung neue Prozessoren nötig,
denn der entsprechende Befehl ist nicht privilegiert.
Abdul K. schrieb:> Ist doch usus z.B. in der Raumfahrt einfach im Hintergrund den Speicher> systematisch durchzulaufen und damit Einzelbitfehler vor dem möglichen> Erscheinen eines zweiten Bitfehlers zu korrigieren.
Ist nicht bloss in der Raumfahrt üblich, sondern dürfte in jedem ernst
zu nehmenden Server implementiert sein (memory scrubbing).
A. K. schrieb:>> Wahrscheinlich genügt es auch schon wenn der Cache nicht deaktiviert>> oder von jedem entleert werden kann.>> Dazu sind ausserhalb virtualisierter Umgebung neue Prozessoren nötig,> denn der entsprechende Befehl ist nicht privilegiert.
Hm gibt es diese neuen Prozessoren in Form des Cortex-R schon? Da
scheint zumindest das Verhalten des Daten-Caches nur von Privilierten
änderbar:
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0363e/Bgbdbdjc.html
Der prefetch-cache ist jetz nur für Instructions ?
MfG,
Fpga Kuechle schrieb:> Hm gibt es diese neuen Prozessoren in Form des Cortex-R schon?
Da das RowHammer Thema sich im Code bisher ausschiesslich auf die
PC-Welt bezog, tat ich das auch. Man könnte sich auch auf alte
Prozessoren zurückbesinnen, die den CLFLUSH Befehl noch nicht kennen.
Icke ®. schrieb:> scheitert eine solche Attacke auch daran, daß Speicherriegel in> unterschiedlichsten Organisationen verbaut vorkommen und somit gar nicht> gezielt nebeneinander liegende Zellen getroffen werden können
Sie es mal anders.
Wieviele Socken muss man maximal aus einem Wäschekorb herausfischen, um
ein Paar in den Händen zu halten, wenn man weiß, dass zehn Paare im Korb
sind.
Oder anders ausgedrückt, wieviele Speicherorganisationen gibt es und wie
viele Rechner muss man dann statistisch betrachte angreifen, um einen
mit einer zum Angriffsmuster passenden Organisation zu erwischen?
A. K. schrieb:> Fpga Kuechle schrieb:>> Hm gibt es diese neuen Prozessoren in Form des Cortex-R schon?>> Da das RowHammer Thema sich im Code bisher ausschiesslich auf die> PC-Welt bezog, tat ich das auch. Man könnte sich auch auf alte> Prozessoren zurückbesinnen, die den CLFLUSH Befehl noch nicht kennen.
Meines Erachtens ist eine Lehre aus der Geschichte das der Datencache
kein nice-to-have feature mehr ist sondern wegen der hier beschriebenen
effekte aus Gründen der System-stabilität bei hochintegrierten SDRAM
unverzichtbar geworden ist.
Sicher ist einem Ingenieur das problem beim Stress-Lesen aufgefallen und
er hat gleich die Produktentwicklungen in Alarmzustand versetzt. Dann
setzen sich alle an den Tisch und meist das managment spricht schon mal
von völlig unrealistischen benchmarks die im Feld-Einsatz nie auftreten.
Damit haben diese ja auch nicht völlig Unrecht. Also einigt man sich
drauf die Spec respective Qualifikations-benschmarks dahin gehend zu
ändern das nur noch Einsatzrelevante Szenarien durchgespielt werden -
also der Cache aktiviert bleibt.
Auch wäre zu fragen ob Alltagsanwendungen ohne cache den Effekt auslösen
können. Ohne jetzt nachgerechnet zu haben, scheint es für den bitflip
nötig den selben unveränderten Speicherbereich aller 10-100 (?) Takte
erneut auszulesen und das hunderte Mal hintereinander. Womöglich noch
ohne die Daten weiter prozessieren. Welche Algorithmus braucht so ein
"Xtreme fast and long memory polling" ?
MfG,
Me2 schrieb:> Oder anders ausgedrückt, wieviele Speicherorganisationen gibt es und wie> viele Rechner muss man dann statistisch betrachte angreifen, um einen> mit einer zum Angriffsmuster passenden Organisation zu erwischen?
Bei RowHammer sehe ich zwei Angriffsszenarien.
(1) DoS = Denial of Service. Alle PCs effektiv lahmlegen. Das kannst du
überall mindestens ausprobieren.
(2) Der Versuch, ein System zu übernehmen/manipulieren. Das wäre dann
wohl eher eine hochspezifische Attacke auf bekannte Systeme, nicht so
sehr ein Fischzug querbeet. Sofern überhaupt realistisch möglich, ohne
Horden schlafender Hunde zu wecken.
Fpga Kuechle schrieb:> Welche Algorithmus braucht so ein> "Xtreme fast and long memory polling" ?
Auch ohne CLFLUSH ist der Aufwand, Caching zu überwinden, überschaubar.
Da geht mit etwas Anlauf jeder Zugriff am L1 Cache vorbei:
for i=0 to infinity
Zugriff auf Adresse BASE+i*4K
Beim Pentium Pro war bereits ab dem dritten Zugriff der L1-Cache
nutzlos.
Abhängig von exakter Implementierung, Anzahl Cache-Levels und
Assoziativität wird das etwas aufwändiger und der Anlauf variiert, aber
das Prinzip bleibt ähnlich.
Das muss letztlich auch nicht langsamer sein als die CLFLUSH Variante.
Dieser Befehl ist nämlich schweinelangsam.
Fpga Kuechle schrieb:> Dagegen hilft nur Speicher mit größerer Strukturbreite, also vielleicht> etwa von vor 2011 gefertigt.
Oder ein ECC-Verfahren mit höherer Redundanz und besseren
Korrekturfähigkeiten.
Me2 schrieb:> Oder anders ausgedrückt, wieviele Speicherorganisationen gibt es und wie> viele Rechner muss man dann statistisch betrachte angreifen, um einen> mit einer zum Angriffsmuster passenden Organisation zu erwischen?
Das ist gar nicht notwendig. Ich muß zugeben, die Problematik anfangs
etwas zu oberflächlich betarchtet zu haben. Mir ist jetzt aber klar, daß
man bei dem "Bruteforce" Angriff auf die page tables die
Speicherorganisation gar nicht kennen muß.
Uhu Uhuhu schrieb:> Fpga Kuechle schrieb:>> Dagegen hilft nur Speicher mit größerer Strukturbreite, also vielleicht>> etwa von vor 2011 gefertigt.>> Oder ein ECC-Verfahren mit höherer Redundanz und besseren> Korrekturfähigkeiten.
Nein, der verhindert nicht grundsätzlich das das Problem auftritt, er
verbessert nur die Kompensation auf Kosten der Speichereffizienz und
Leistungsaufnahme.
Und wenn die Wahl ist zwischen bspw. 2 Riegel "alter" Speicher a 4 GByte
gegen einem Riegel 8 Gbyte neuer Speicher + 2Gbyte Parity ECC plus
steuerlogic + vorbereites Motherboard dann fällt die Entscheidung sicher
für den Speicher mit 0.000% Probleme statt zu dem mit ECC mit 0,0001%
Problem.
MfG,
>> Der Mann mit dem Hammer ist zurück. Die Wände werden immer dünner:
Gibt es überhaupt ein nachprüfbares Szenario? Mit anderen Worten: Wo
kann ich die Sau zu sehen, die angeblich seit sechs durchs Dorf
getrieben wird?
Die Strukturen sind so klein, das hier bereits Strahlung einige Fehler
verursachen kann. Es gibt daher ein Patent, diese Fehler zu zählen und
als Strahlungsdetektor zu verwenden. Im Betrieb sieht der Nutzer davon
nichts, da mit dem Refresh-Zyklus permanent parallel über Prüfbits eine
Korrektur durchgeführt wird. Über Assemblercode und Bus, kommt man
vielleicht an diese Daten heran. Denke mal RAM-Tests, ohne diese Werte
auszulesen, sind daher für die Tonne. D.h. alle Tests zu neuen
Speicherriegeln in allen deutschprachigen Fachzeitschriften sind daher
eigentlich auch für die Tonne.
> wie bekomme ich denn von aussen ein Programm auf> einen Linux-Rechner, den man attackieren möchte?
Wie bei jeder Windows-Krücke auch - per eMail/Download als Trojaner oder
via infiziertem USB-Stick...
Das Thema an sich wirkt auf mich wie "technische Prostitution".Was
glaubt ihr wie oft man einen Datenträger überschreiben muss ehe er nur
noch unbrauchbares von sich gibt? 23 x oder 1x? Ich denke ,nach einmal
ist der Kaas gebissen. Klar im Internet auf diversen Seiten wird von
entsprechenden Firmen viel versprochen. Nur...wer garantiert mir
zb.,dass ich eine eingesendete Festplatte tatsächlich wieder bekomme?
Dubiose kriminelle Firmen gibt es zuhauf.
Solche Meldung wie auf Heise dienen nur der Unterhaltung und nebenbei
läuft das Hauptgeschäft , die Werbung.
Haben wir keine anderen Probleme die uns gefährlicher sind zu lösen?
herbert schrieb:> Ich denke ,nach einmal> ist der Kaas gebissen.
Du denkst falsch, bzw. hast keine Ahnung => mach dich erst mal schlau.
Mit entsprechendem Equipment kannst du die Daten auch nach
dem Löschen auslesen.
Bei Festplatten bleibt eine Restmagnetisierung, und bei SSD eine
Restladung übrig.
Beim Löschen sowie auch beim Lesen und Schreiben
ändert sich auch der Zustand benachbarter Zellen
(Ladung im Falle von SDRAM und SSD, bzw. Magnetische Remanenz).
Die Daten werden immer als "Block" oder "Row" geschrieben.
Da kommt es noch zu einer Reihe von unerwarteten Effekten.
● Des I. schrieb:> wie bekomme ich denn von aussen ein Programm auf einen Linux-Rechner,> den man attackieren möchte?
Auf Hosting-Systemen teilen sich viele Kunden einen Server, ähnlich
sieht's bei VMs (Marketing-Slang: "Cloud-Server") aus.
Ansonsten ist sowas als nächster Schritt interessant, wenn man z.B. eine
Lücke in einer Serveranwendung ausgenutzt hat, aber noch ohne
root-Rechte auf dem Server ist.
Wie praktikabel Rowhammer-Attacken sind, sei mal dahingestellt, in
Servern wird ja immerhin ECC-RAM verbaut.
udok schrieb:> Mit entsprechendem Equipment kannst du die Daten auch nach> dem Löschen auslesen.
Wenn man nur mit Nullen überschreibt, ja, bei zufälligen Daten ist das
deutlich schwieriger. Ich glaube, MIL-Vorgabe ist dreimaliges
Überschreiben mit Zufallsdaten.
Problematischer ist da das Thema Reservesektoren.
Hmmm schrieb:> Wie praktikabel Rowhammer-Attacken sind, sei mal dahingestellt,
Für Quantenspeicher dürfte das interessant werden. In dem Falle sind die
Spitzbuben der Zeit bereits meilenweit voraus.
Hmmm schrieb:>> Mit entsprechendem Equipment kannst du die Daten auch nach>> dem Löschen auslesen.>> Wenn man nur mit Nullen überschreibt, ja, bei zufälligen Daten ist das> deutlich schwieriger. Ich glaube, MIL-Vorgabe ist dreimaliges> Überschreiben mit Zufallsdaten.>> Problematischer ist da das Thema Reservesektoren.
Ich schätze mal, dass die Spitzbuben mit dem Equipment auch
wissen, wie Zufallszahlen generiert werden.
Vor allem, wenn mit der Löschsoftware auch grosse bekannte Files
gelöscht werden, ist das ein einfach lösbares Problem.
Otto-Normalverbraucher von uC.net ist davon eher nicht betroffen,
der verwendet doch sicher Bitlocker?
udok schrieb:> Du denkst falsch, bzw. hast keine Ahnung => mach dich erst mal schlau.> Mit entsprechendem Equipment kannst du die Daten auch nach> dem Löschen auslesen.
Peter Gutmann, 1996 hat er den Käse veröffentlicht, allerdings ohne nur
eine einzige belastbare Referenz.
Und bis heute ist er der einzige geblieben, der das behauptet. Es gibt
keinerlei wissenschaftliche Veröffentlichung dazu, dass erfolgreich
Daten wiederhergestellt werden konnten.
Und bei heutigen Festplatten, die schon massiv Fehlerkorrektur-Techniken
einsetzen, und das Lesen von Daten nur noch eine statisches Berechnung
ist, ist es vollkommen abwegig, zu glauben, man könne überschriebene
Daten wieder herstellen.
Aber dieser Mythos wird wohl nie wieder aus dem Internet zu tilgen sein,
und er wird ja auch schon für Flash-Speicher mit QLC-Technik behauptet.
Ist halt so schön einfach, irgendeinen Quatsch, den man mal irgendwo
gehört hat, nachzuplappern.
Arduinoquäler schrieb:> Und was passiert also Folge davon? Nichts. Jedenfalls kein> "Übersprechen".>> Toll mit was für Käse manche Menschen ihre Lebenszeit vergeuden.
Bei SSDs lebst wahrscheinlich auch du davon, dass Menschen einen Teil
ihrer Lebenszeit damit zubringen, dieses Übersprechen vor den Nutzern zu
verbergen.
udok schrieb:> Vor allem, wenn mit der Löschsoftware auch grosse bekannte Files> gelöscht werden, ist das ein einfach lösbares Problem.
Warum sind dann solche Firmen die versprechen Daten zu retten so
furchtbar teuer?
Ich stelle mir folgendes Szenario vor: Ich schicke so einer Firma meine
Festplatte und bekomme danach einen Kostenvoranschlag der mich vom
Sockel haut. Ich verzichte und lasse mir die Platte zurücksenden.
Kriminelle Firmen könnten davon aber eine Kopie angefertigt haben die
bei ihnen verbleibt.Was die damit machen ????
Allein schon die Vorstellung beunruhigt mich sehr... Kontrolle gibt es
ja keine.
Erstens ist bei einer sicheren Festplattenverschlüsselung die
Vernichtung des Schlüssels genau so sicher wie eine Vernichtung der
Daten.
Zweitens, wenn die Daten auf einer Platte ganz sicher zerstört werden
sollen, so daß sie auch niemand wiederherstellen kann, kommt die Platte
in den Schredder.
herbert schrieb:> Warum sind dann solche Firmen die versprechen Daten zu retten so> furchtbar teuer?
Weil es je nach Menge mühsam ist. Bei der Masse der anfallenden
Festplatten wir die Firma wohl keine Zeit haben, jeden Text zu lesen.
Ein paar Schlagwörter könnte man aber schon suchen, wennnnnn sie lesbar
sein sollten. Snowden.txt?
Experte schrieb:> Aber dieser Mythos wird wohl nie wieder aus dem Internet zu tilgen sein,> und er wird ja auch schon für Flash-Speicher mit QLC-Technik behauptet.
Ganz so unmöglich dürfte das nicht sein noch Inhalte der vorherigen
Zellinhalte zu ermitteln. Der Versuch ein GB auszulesen würde aber erst
mal einige Terrabyte-Festplatten mit Daten füllen, nach vier Jahre wären
die Rohdaten gesammelt. Ausgewertet würden pro 512-Byte-Block immer noch
einige Bits falsch sein. Bei unkomprimierten unverschlüsselten
ASCII-Text ließe sich noch etwas herauslesen.
herbert schrieb:> Ich verzichte und lasse mir die Platte zurücksenden.> Kriminelle Firmen könnten davon aber eine Kopie angefertigt haben die> bei ihnen verbleibt.Was die damit machen ????> Allein schon die Vorstellung beunruhigt mich sehr... Kontrolle gibt es> ja keine.
so funktioniert das aber nicht. Die Platte bekommst du in keinem Fall
zurück. Die ist in aller Regel zerstört. Schau dir mal die Bedingungen
von Ontrack an. Wenn du soviel Angst vor Misbrauch hast darfst du solche
Dienste halt nicht nutzen.
Die großen Firmen wie Kroll Ontrack werden die Daten auf jeden Fall
vertraulich behandeln. Denen ist ihr Brot- und Butter-Geschäft weit
mehr wert, als Deine persönlichen Geheimnisse. Wenn da nämlich
nachweisbar durchsickert, daß sie Kundendaten veruntreuen, können sie
den Laden dichtmachen. Da würden sie so viele sehr gut zahlende Kunden
verlieren... das wollen die nicht.
Irgendwelche "Gelegenheits-Bastler" oder Billiganbieter für den
vermeintlichen Massenmarkt sind natürlich weniger vertrauenswürdig, da
muß man dann abwiegen was wichtiger ist - die Sicherheit der Daten oder
deren Wiederbeschaffung mit möglicher Kompromittierung - zusammen mit
der Frage wieviel die Daten überhaupt wert sind.
Dazu kommt, die Kunden sind auch nicht immer zuverlässig. Bei so einem
Typen ging vor etlichen Jahren sein heiß geliebter USB-Stick mit
irgendwelchen unwiderbringlichen Uni-Arbeiten und Bildern kaputt und der
Chef einer befreundeten Firma hat gefragt ob ich den reparieren könne,
der Typ würde 200 Euro dafür bezahlen. Hm, sounds like a challenge,
probieren kann man es ja mal. Ergebnis war ein defekter Quarz, habe
einen aus der Restekiste drangefrickelt und konnte den gesamten Inhalt
des Sticks retten. Daten (ungesichtet) übergeben, der Typ superglücklich
und bekommen hab ich 50 Euro. Super. Das sind so Fehler, die macht man
ein Mal - beim nächsten Mal sagt man komm leck mich, was interessieren
mich deren Probleme...
Thomas Z. schrieb:> so funktioniert das aber nicht. Die Platte bekommst du in keinem Fall> zurück.
Das hängt vom Anbieter ab.
Bei einem anderen grossen Anbieter, mit dem ich mal zu tun hatte, wird
bei erfolgloser Recovery die Platte zurückgeschickt, im Erfolgsfall
behalten sie die, sofern man nicht explizit eine Rücksendung will.
Thomas Z. schrieb:> Wenn du soviel Angst vor Misbrauch hast darfst du solche Dienste halt> nicht nutzen.
Genau. Ich habe mir seinerzeit bestätigen lassen, dass Platten und Daten
nicht die EU verlassen.
Christoph Z. schrieb:> ● Des I. schrieb:>> wie bekomme ich denn von aussen ein Programm auf einen Linux-Rechner,>> den man attackieren möchte?>> Wie wärs ganz einfach per Browser :-)
tchaaah... was ist denn nun mit der Propaganda,
dass Linux so sicher sei?