Hallo zusammen, ich bin neulich über ein Codeschnipsel in einem großen
Programm gestolpert. Dort wird die Kreiszahl Pi in einer etwa 15 Zeilen
langen Funktion berechnet, obwohl in der selben Datei die <math.h>
eingebunden ist, und somit der Zugriff auf "M_PI" möglich wäre. Die
Funktion liefert als Rückgabetyp einen "long double". Genauer als 20
Stellen wird's ja deswegen auch nicht, oder? Was ist der Sinn der Sache,
dass der Programmierer Pi in einer Funktion berechnet, anstatt auf die
definierte Konstante mit 20 Nachkommastellen zuzugreifen? Ich bin nicht
dahintergekommen. Hat jemand eine Idee?
Christian W. schrieb:> Hat jemand eine Idee?
Er sah den Wald vor lauter Bäumen nicht und wusste daher
nicht das Pi schon vorkonserviert zur Verfügung steht.
Christian W. schrieb:> Hallo zusammen, ich bin neulich über ein Codeschnipsel in einem großen> Programm gestolpert. Dort wird die Kreiszahl Pi in einer etwa 15 Zeilen> langen Funktion berechnet, obwohl in der selben Datei die <math.h>> eingebunden ist, und somit der Zugriff auf "M_PI" möglich wäre. Die> Funktion liefert als Rückgabetyp einen "long double". Genauer als 20> Stellen wird's ja deswegen auch nicht, oder? Was ist der Sinn der Sache,> dass der Programmierer Pi in einer Funktion berechnet, anstatt auf die> definierte Konstante mit 20 Nachkommastellen zuzugreifen? Ich bin nicht> dahintergekommen. Hat jemand eine Idee?
ich schreibe immer "pi = (4 * arctan(-1))", sieht irgendwie viel cooler
aus als das benutzen einer Konstanten aus math.h :-)
Micha
Profilierung vor der Freundin?
Das kann man so nicht sagen.
Kommt drauf an, ob er mit einem long double die Auflösung und die
Genauigkeit überhaupt noch ausfahren kann. Ohne Analyse dessen, wie
damit gerechnet wird und wie die Fehlerfortpflanzung zuschlägt, ist dazu
wenig zu sagen.
Mal ganz davon abgesehen, dass es recht witzlos ist, das jedes mal neu
zu rechnen. Wenn schon, dann bestimmt man sich PI auf die Anzahl der
Stellen die man haben will oder lädt die sich aus dem Web runter. Noch
ein #define und gut ists.
Christian W. schrieb:> Dort wird die Kreiszahl Pi in einer etwa 15 Zeilen langen> Funktion berechnet, obwohl in der selben Datei die <math.h>> eingebunden ist, und somit der Zugriff auf "M_PI" möglich wäre.
M_PI wird in math.h auch nicht definiert. M_PI ist eine
GNU-Erweiterung, d.h. es kann verwendet werden und wird durch math.h
verfügbar wenn die Quelle in GNU-C steht. "Offiziell" ist M_PI aber
nicht.
> Die Funktion liefert als Rückgabetyp einen "long double".> Genauer als 20 Stellen wird's ja deswegen auch nicht, oder?> Was ist der Sinn der Sache, dass der Programmierer Pi in einer> Funktion berechnet, anstatt auf die definierte Konstante> mit 20 Nachkommastellen zuzugreifen?
Wenn man den Algorithmus nicht sorgsam auwählt, ist die Näherung
vermutlich deutlich schlechter als 20 Nachkommastellen und nicht besser
als 22/7 oder 355/113.
> Ich bin nicht dahintergekommen. Hat jemand eine Idee?
Vermutlich weil der Autor Spaß dran hat.
Micha S. schrieb:> ich schreibe immer "pi = (4 * arctan(-1))", sieht irgendwie viel> cooler aus als ...
Dafür auch viel falscher, nämlich um 2π daneben ;-)
Johann L. schrieb:> Micha S. schrieb:>> ich schreibe immer "pi = (4 * arctan(-1))", sieht irgendwie viel>> cooler aus als ...>> Dafür auch viel falscher, nämlich um 2π daneben ;-)
wer hat das -1 da hingemacht? Sauerei! :-)
Micha S. schrieb:> Johann L. schrieb:>>> Micha S. schrieb:>>> ich schreibe immer "pi = (4 * arctan(-1))", sieht irgendwie viel>>> cooler aus als ...>>>> Dafür auch viel falscher, nämlich um 2π daneben ;-)>> wer hat das -1 da hingemacht? Sauerei! :-)
alte Regel: immer eine gerade Anzahl an Vorzeichenfehlern machen!
Ok, danke für die schnellen und zahlreichen Antworten.
Fassen wir mal zusammen.
Ich kann also generell am Anfang meiner C-Datei oder in meiner selbst
erstellten Headerdatei schreiben:
1
#define MY_PI 3.14159265358979323846
...und kann überall da, wo im Programm die Pi-Berechnungs-Funktion
aufgerufen wird, diese durch "MY_PI" ersetzen, ohne dass sich an der
Genauigkeit des Ergebnisses (3 Nachkommastellen sind gefordert) etwas
ändert. Richtig?
Vor allem bei Mikrocontroller-Anwendungen bei einem Takt von 1 MHz finde
ich generell ein #define besser als eine Berechnungsfunktion für Pi,
beispielsweise aus Zeitgründen...
Christian.
Christian W. schrieb:> Hallo zusammen, ich bin neulich über ein Codeschnipsel in einem großen> Programm gestolpert. Dort wird die Kreiszahl Pi in einer etwa 15 Zeilen> langen Funktion berechnet, obwohl in der selben Datei die <math.h>> eingebunden ist, und somit der Zugriff auf "M_PI" möglich wäre. Die> Funktion liefert als Rückgabetyp einen "long double". Genauer als 20> Stellen wird's ja deswegen auch nicht, oder?
Doch es könnte genauer werden.
Die Floating point units rechnen intern mit einer höheren Genauigkeit
als die "integer" Einheit. So definiert der Standard IEEE-754 eine 32
bit genauigkeit und eine extended 40 bit. Bei Datenaustausch muss
jeweils gerundet werden. Es könnte also sein das bei den define-pi das
schliesslich im assemblercode über die integer einheit in die floating
point einheit geladen wird nur 32 bit übergeben werden können, während
bei der Berechnungsroutine 40 bit genau ermittelt wird.
http://en.wikipedia.org/wiki/Extended_precision#IEEE_754_extended_precision_formatshttp://c-faq.com/fp/strangefp.html
Zitat:
" Beware that some machines have more precision available in
floating-point computation registers than in double values stored in
memory"
MfG,
Christian W. schrieb:> Fassen wir mal zusammen.>> Ich kann also generell am Anfang meiner C-Datei oder in meiner selbst> erstellten Headerdatei schreiben:>>
1
#define MY_PI 3.14159265358979323846
>> ...und kann überall da, wo im Programm die Pi-Berechnungs-Funktion> aufgerufen wird, diese durch "MY_PI" ersetzen, ohne dass sich an der> Genauigkeit des Ergebnisses (3 Nachkommastellen sind gefordert) etwas> ändert. Richtig?
Nein, siehe Antwort eins drüber.
Aha, langsam kommt Licht in's Dunkel.
Heißt das also, dass ein Präprozessor-Define immer nur 32-Bit-genau ist?
Die Frage ist jetzt nur, wenn ich zwar in einer Funktion Pi berechne,
dann aber den Wert über den Rückgabetyp long double zurückgebe und
irgendwo anders verrechne, ist die Genauigkeit dann nicht auch wieder
den Bach runter?
Christian
Heißt das also, dass ein Präprozessor-Define immer nur 32-Bit-genau ist?
nein der preprozessor macht nur eine testuelle ersetzung, das heist er
ersetzt jeden vorkommen von MY_PI durch 3.14159265358979323846. Die
umwandlung in float/double macht dann der compiler
Fpga Kuechle schrieb:> Doch es könnte genauer werden.> Die Floating point units rechnen intern mit einer höheren Genauigkeit> als die "integer" Einheit.
Mit Betonung auf könnte
Wenm Compiler für float / double erzeugen kommt es durchaus vor, daß ihm
die float-Register ausgehen und er float-Werte (temporär) in nicht-FPU
Registern oder auf dem Stack zwischenlagern muss.
Dann hängt die erreichte Genauigkeit von Faktoren ab wie
Optimierungsgrad oder vom umgebenden Code, der scheinbar nix mit der
eigentlichen Berechnung zu tun hat.
Johann L. schrieb:> Dann hängt die erreichte Genauigkeit von Faktoren ab wie> Optimierungsgrad oder vom umgebenden Code, der scheinbar nix mit der> eigentlichen Berechnung zu tun hat.
das ist sogar eine extra Option vom Compiler. Im Standard sollte es so
rechnen das das Ergebnis mit double nachvollziehbar ist. (also etwas
ungenauer als es sein könnte)
http://christian-seiler.de/projekte/fpmath/
Christian W. schrieb:> Aha, langsam kommt Licht in's Dunkel.>> Heißt das also, dass ein Präprozessor-Define immer nur 32-Bit-genau ist?
"immer" ist immer falsch ;-)
Also m.E. kann man die Fragen nach der besten Implementierung nur anhand
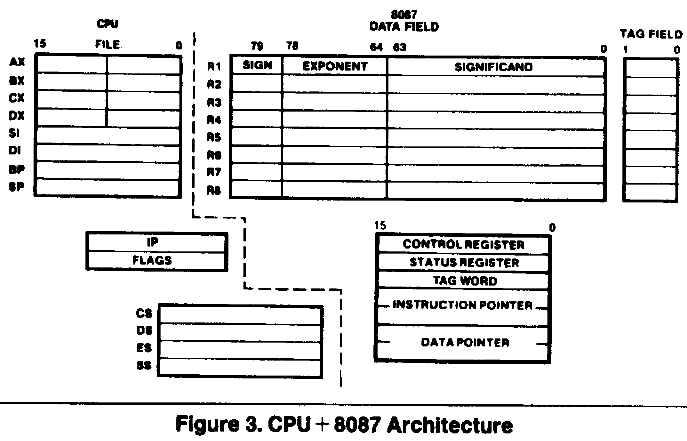
der Hardware klären. Deshalb zwei Schnipsel aus dem Datenblatt zu einem
der Urväter der Fliesskommaberechnung - der 8087 FPU.
Früher sah die Hardwarearchitektur mal so aus
RAM <-> CPU <-> FPU
Die FPU (80x87)rechnet intern mit 80 bit (Schnipsel 1)
die CPU kann aber nur 64 bit rüberreichen (Schnipsel 2, Op-code)
-> will man also die höchste Genauigkeit muss man Pi auf der FPU
berechnen und kann es nicht als Konstante rüberreichen. Das gestattet
der Befehlssatz (Assembler) der CPU nicht. Damit ist es egal ob man nun
in C, Pascal etc. rechnet - es geht nicht.
Das erklärt erstmal warum in dem von Dir erwähenten C-Code Pi berechnet
wird.
Schaut man sich die FPU-register genauer an fällt weiterauf, das die
nicht beliebig zugreiffbar sind, sondern als Stack orientiert sind. Man
kann also das berechnete PI nicht auf Dauer auf einer fixen Addresse
speichern.
Das würde erklären warum Pi immer neu berechnet wird.
Bei anderen Controllern wie bspw ARM-Cortex-M4 mit FPU-Option kann das
wieder anders aussehen. Beim angesprochenen ARM sind FPU-Register wie
"normale" Register 32 bit breit. Da bringt berechnen statt Konstante
kein Plus an Genauigkeit - ARM kann an dieser Stelle wohl nicht besser
als 32bit Fliesskomma.
Interessant finde ich dann wieder späterer intel FPU#s, die bringen
einen Befehl mit der PI mit der maximalen genauigkeit bereitstellt
(FLDPI).
Pi ist dabei:
S = 0.f * 2^2
mit:
f = C90FDAA2 2168C234 C
Wie man aber dem C-Compiler sagt, das er dieses Feature im Assemblercode
nutzt (wenn das Target das unterstützt) ist noch unklar. Aber
wahrscheinlich nicht in dem man ein define mit möglichst vielen Stellen
benutzt.
MfG,
*http://www.ece.usu.edu/ece_store/spec/8087.pdf - Datenblatt 8087
*http://home.agh.edu.pl/~amrozek/x87.pdf Datenblatt x87 bei IA32 S.23
Fpga Kuechle schrieb:> Wie man aber dem C-Compiler sagt, das er dieses Feature im Assemblercode> nutzt (wenn das Target das unterstützt) ist noch unklar.
Seit C99 gibt es auch hexadezimale Gleitkommakonstanten. Der Sinn
ist dabei, dass man auf diese Weise eine Gleitkommazahl mit einem
definierten, 1:1 vergleichbaren Bitmuster festlegen kann.
Für irrationale Zahlen wird aber auch das nicht helfen, sie exakt
abzubilden. ;-)
Jörg Wunsch schrieb:> Seit C99 gibt es auch hexadezimale Gleitkommakonstanten. Der Sinn> ist dabei, dass man auf diese Weise eine Gleitkommazahl mit einem> definierten, 1:1 vergleichbaren Bitmuster festlegen kann.>> Für irrationale Zahlen wird aber auch das nicht helfen, sie /exakt/> abzubilden. ;-)
Nicht nur aus diesem Grund scheint mir die Variante Pi über Arkustangens
zu deklarien von Vorteil. Das wurde oben auch vorgeschlagen und bei
Recherchen zu Pi und C stößt man auch öfters auf diesen Vorschlag.
Darüber könnte man auch eine intrinsic function basteln anhand derer der
Compiler erkennt was er zu assemblieren hat, hier also den Befehl die
Konstante PI zu laden.
*http://de.wikipedia.org/wiki/Intrinsische_Funktion
MfG,
BTW: Da die FPU bei intel zu SSE mutiert ist, muß man hinsichtlich
optimalet float-programmierung heutzutage nach SSE suchen?
Fpga Kuechle schrieb:> Wie man aber dem C-Compiler sagt, das er dieses Feature im Assemblercode> nutzt (wenn das Target das unterstützt) ist noch unklar. Aber> wahrscheinlich nicht in dem man ein define mit möglichst vielen Stellen> benutzt.
Warum sollte es nicht?
Das ist doch eine ziemlich einfache Optimierung für den Compiler.
Fpga Kuechle schrieb:> Nicht nur aus diesem Grund scheint mir die Variante Pi über Arkustangens> zu deklarien von Vorteil.
und was lässt sich über die Genauigkeit des so errechneten PI sagen?
Dirk B. schrieb:> Fpga Kuechle schrieb:>> Wie man aber dem C-Compiler sagt, das er dieses Feature im Assemblercode>> nutzt (wenn das Target das unterstützt) ist noch unklar. Aber>> wahrscheinlich nicht in dem man ein define mit möglichst vielen Stellen>> benutzt.>> Warum sollte es nicht?> Das ist doch eine ziemlich einfache Optimierung für den Compiler.
Woran soll der Compiler erkennen das man hier Pi wie für die FPU meint
und nicht eine Näherung für Pi? Oder irgendeinen Skalierungsfaktor der
nur so aussieht wie PI.
also bspw bei
#define M_PI 3,141526536
den FPUbefehl
und bei
#define M_PI 3,14152653
oder
#define M_PI 3,1415265358
nicht?
abgesehen von anderen schreibweisen
wie 0,31415926536 * 10;
Exakt wäre eine Konstante wie oben genannt:
S = 0.f * 2^2
mit:
f = C90FDAA2 2168C234 C
Also für den Programmierer ist es sicher nicht einfacher wenn er erst Pi
auf 20+ Stellen nachschauen und exakt eintippern muß um damit den
gewünschten assembler-befehl zu erzeugen.
Ob eine einzelne Inline-Assembler Zeile das Problem lösen kann ist auch
zu bezweifeln, da es sich bei der hier beispielhaft verwandten FPU um
eine mit Registerstack handelt, wo übliche calling conventions versagen.
MfG,
Fpga Kuechle schrieb:> also bspw bei> #define M_PI 3,141526536
Nur zur Richtigstellung: Du meinst hier den Dezimalpunkt, nicht das
Komma.
P.S.
Wie wärs mit PI auf 800 Stellen?
Walter schrieb:> Fpga Kuechle schrieb:>> Nicht nur aus diesem Grund scheint mir die Variante Pi über Arkustangens>> zu deklarien von Vorteil.>> und was lässt sich über die Genauigkeit des so errechneten PI sagen?
Es soll nicht berechnet werden sondern als Konstante eingesetzt. Also
der Compiler erkennt das hier eine Konstante deklariert wird, berechnet
diese und setzt die dann ein.
also die deklaration
const T_floatType_with_best_presision C_PI = 4.0*atan(1.0);
wird nach compilieren durch das Laden des Registers/Stack mit der
optimalen Konstante ersetzt.
Dort wird das für FORTRAN erklärt:
http://stackoverflow.com/questions/2157920/why-define-pi-4atan1
Wie das bei C genau gemacht wird ist mir unbekannt, es ist ein
Rklärungsversuch warum sich im Netz immer wieder vorgeschlagen wird Pi
über den arctan zu deklarieren -> weil das eben eine Möglichkeit ist
eine Zahl mit unendlich vielen Stellen mit einer endlichen Anzahl von
Tastaturanschlägen exakt einzutippen. Und auf einer Tastatur ohne
griechische Buchstaben ;-)
MfG,
Frank M. schrieb:> Fpga Kuechle schrieb:>> also bspw bei>> #define M_PI 3,141526536>> Nur zur Richtigstellung: Du meinst hier den Dezimalpunkt, nicht das> Komma.
Ja!
>> P.S.> Wie wärs mit PI auf 800 Stellen?>
Jörg Wunsch schrieb:> Für irrationale Zahlen wird aber auch das nicht helfen, sie /exakt/> abzubilden. ;-)
Immerhin ist es möglich, mit manchen irrationalen Zahlen exakt zu
rechnen bzw. rechnen zu lassen:
1) man begnügt sich mit +, -, *, / und Kompositionen davon.
2) und die Zahl(en) sind nicht transzendent wie beispielsweise
In Indiana wurde mal ein Gesetzesentwurf vorgelegt (und beinahe auch
beschlossen) dass Pi auf 3,2 festgelegt wird.
http://de.wikipedia.org/wiki/Indiana_Pi_Bill
Vielleicht hat er nicht gewußt dass PI nun doch auch 3.141.. bleibt.
Babbage schrieb:> In Indiana wurde mal ein Gesetzesentwurf vorgelegt (und beinahe auch> beschlossen) dass Pi auf 3,2 festgelegt wird.
Wenn man auf einem Gebirgspass lebt (wo die Erdoberfläche hyperbolische
Geometrie hat) ist das Verhältnis von Umfanng zu Durchmesser eines
Kreises größer als 3.1415.... Wahrscheinlich wuchs der legendäre Mr.
Goodwin auf einem Pass auf und hat einfach mal nachgemessen anstatt
theoriegläubig Kreisumfang / Durchmesser = 3.1415... nachzubeten :-)
Das Gesetz kam schlichweg deshalb nicht durch den Senat, weil die Herren
Senatoren
1) vom Schulsystem indoktrinierte Ignoranten waren, die Euklids
5. Postulat als gottgegeben ansahen
2) oder in Tälern oder auf Bergen wohnten (wo das Verhältnis von Umfang
zu Durchmesser eines Kreise aufgrund der dort herrschenden sphärischen
Geometrie) bekanntlich kleiner als 3.1415... ist;
3) oder in den Plains aufwuchsen wo Umfang zu Durchnesser eines Kreise
tatsächlich 3.1415... ist.
Oder alles zusammen.
Verfolgt man den Lauf der Geschichte jedoch weiter, so erkennt man, daß
Mr. Goodwin einfach nur seiner Zeit voraus war:
Noch keine 20 Jahre später revolutionierte ein gewisser Hr. Einstein das
mathematisch-physikalische Weltbild durch eine Gravitationstheorie in
Gestalt einer Geometrisierung von Raum und Zeit, nach welcher der Raum
außerhalb von Himmelskörpern tatsächlich eine hyperbolische Geometrie
aufweist.
Wer es nicht glaubt: Nachmessen!
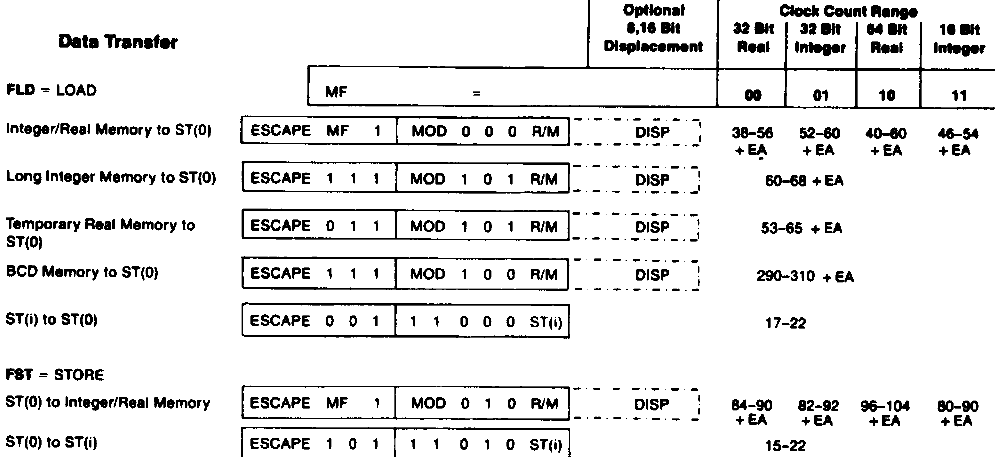
Fpga Kuechle schrieb:> Früher sah die Hardwarearchitektur mal so aus>> RAM <-> CPU <-> FPU>> Die FPU (80x87)rechnet intern mit 80 bit (Schnipsel 1)> die CPU kann aber nur 64 bit rüberreichen (Schnipsel 2, Op-code)
Stimmt nicht. Das Laden eines 80-Bit-Wertes ist das, was in dem von dir
verlinkten (etwas verwirrenden) Dokument als "Temporary Real Memory to
ST(0)" bezeichnet wird.
> -> will man also die höchste Genauigkeit muss man Pi auf der FPU> berechnen und kann es nicht als Konstante rüberreichen. Das gestattet> der Befehlssatz (Assembler) der CPU nicht.
Doch, tut er. Siehe z.B.
http://www2.deec.uc.pt/~jlobo/tc/opcode_f.html
1
FLD Floating point load
2
3
operand 8087 287 387 486 Pentium
4
reg 17-22 17-22 14 4 1 FX
5
mem32 (38-56)+EA 38-56 20 3 1 FX
6
mem64 (40-60)+EA 40-60 25 3 1 FX
7
mem80 (53-65)+EA 53-65 44 6 3 NP
Oder wenn's von Intel selbst kommen soll:
"The double extended-precision format is normally reserved for holding
intermediate results in the x87 FPU registers and constants. Its extra
length is designed to shield final results from the effects of rounding
and overflow/underflow in intermediate calculations. However, when an
application requires the maximum range and precision of the x87 FPU (for
data storage, computations, and results), values can be stored in memory
in double extended-precision format." (*)
Das 80-Bit-Format wird von gcc auch über den Typ long double
unterstützt.
(*) http://home.agh.edu.pl/~amrozek/x87.pdf Seite 8-17.
Fpga Kuechle schrieb:> Woran soll der Compiler erkennen das man hier Pi wie für die FPU meint> und nicht eine Näherung für Pi? Oder irgendeinen Skalierungsfaktor der> nur so aussieht wie PI.
Darum:
Fpga Kuechle schrieb:> in dem man ein define mit möglichstvielenStellen benutzt.
Rolf Magnus schrieb:> Fpga Kuechle schrieb:>> Früher sah die Hardwarearchitektur mal so aus>>>> RAM <-> CPU <-> FPU>>>> Die FPU (80x87)rechnet intern mit 80 bit (Schnipsel 1)>> die CPU kann aber nur 64 bit rüberreichen (Schnipsel 2, Op-code)>> Stimmt nicht. Das Laden eines 80-Bit-Wertes ist das, was in dem von dir> verlinkten (etwas verwirrenden) Dokument als "Temporary Real Memory to> ST(0)" bezeichnet wird.>>> -> will man also die höchste Genauigkeit muss man Pi auf der FPU>> berechnen und kann es nicht als Konstante rüberreichen. Das gestattet>> der Befehlssatz (Assembler) der CPU nicht.>> Doch, tut er. Siehe z.B.> http://www2.deec.uc.pt/~jlobo/tc/opcode_f.html>
1
> FLD Floating point load
2
>
3
> operand 8087 287 387 486 Pentium
4
> reg 17-22 17-22 14 4 1 FX
5
> mem32 (38-56)+EA 38-56 20 3 1 FX
6
> mem64 (40-60)+EA 40-60 25 3 1 FX
7
> mem80 (53-65)+EA 53-65 44 6 3 NP
8
>
Sicher? Also das intel-paper bezieht sich auf 80X87 der IA32
Architektur,
also 32bit processoren. Der 8087 ist der Co vom 8086 als 16bit. In dem
PNG-Schnipsel des Instructions set wird gezeigt das ganze zwei bit
benutzt werden um die Operandenbreite zu codieren (Bitfeld M)? und da
sind keine
80 bit vorgesehen. Und das PNG ist auch von intel. Ich stimme zu, das
ist verwirrend, ich bin mir da auch nicht 100% sicher, halte aber den
Auszug des Instructions-code für ein sehr starkes Argumenten gegen die
These das es bei diesem Co-Prozessor 80 bit Zugriffe auf die FPU gibt.
Und der 8087 ist hier nur beispielhaft gemeint. Das bis jetzt noch nicht
näher beschriebene Code-schnipsel des TO kann auch für eine andere
machine
gedacht sein (DSP, ibm360, space-ASIC) bei der die interne Darstellung
höhere Genauigkeit aufweist als mit dem Speicher austauschbar ist.
Vielleicht gibt es eine solche Maschine auch nicht aber der Code würde
die maximal verfügbare Genauigkeit ausnutzen.
MfG,
Dirk B. schrieb:> Fpga Kuechle schrieb:>> Woran soll der Compiler erkennen das man hier Pi wie für die FPU meint>> und nicht eine Näherung für Pi? Oder irgendeinen Skalierungsfaktor der>> nur so aussieht wie PI.>> Darum:> Fpga Kuechle schrieb:>> in dem man ein define mit möglichstvielenStellen benutzt.
?Also in der Spec für den compiler soll stehen"
"Wenn Sie möglichst viele Stellen für Pi im define verwenden wird die
FPU-interne Konstante genutzt, wenn mindestens eine stelle weniger als
möglichst dann diese." ?
Das ist dann aber scherzhaft gemeint, oder?
Und wenn man bei den beispielwhaft 200 Stellen sich an einer vertippt
...
Also da muss eine eindeutige Notation verwendet werden. So wie wenn man
ein Drittel möchte auch "ein Drittel" sagt/notiert oder "1/3" und nicht
0.33333333333333333... .
Wenn man Pi möchte dann sollte man auch pi verlangen und keine gekürzte
Variante.
MfG
Fpga Kuechle schrieb:> Sicher?
Ich hab's noch nicht selbst ausprobiert, aber ich hab extra noch eins
von meinen alten verstaubten x86-Assembler-Büchern aus dem Regal
gezogen, und da wird das bestätigt. Darin findet sich eine ähnliche
Tabelle mit Taktzyklen für die Instruktion ab 8087.
Ich kann mich auch noch aus dem Turbo Assembler an die Datentypen BYTE,
WORD, DWORD, QWORD und TBYTE erinnern. Letzterer war eben der
80-Bit-Datentyp.
> Also das intel-paper bezieht sich auf 80X87 der IA32 Architektur,> also 32bit processoren. Der 8087 ist der Co vom 8086 als 16bit. In dem> PNG-Schnipsel des Instructions set wird gezeigt das ganze zwei bit> benutzt werden um die Operandenbreite zu codieren (Bitfeld M)? und da> sind keine 80 bit vorgesehen.
Das gilt aber nur für die Variante "Integer/Real Memory to ST(0)". Die
80-Bit-Instruktion ist wie schon geschrieben die separate Variante
"Temporary Real Memory to ST(0)". Die hat auch den gleichen Opcode wie
der in meinem Buch angegebene 80-Bit-Speicherzugriff.
Ich vermute, daß das "Temporary" hier darauf anspielt, daß die
Instruktion wie in dem von mir verlinkten Dokument eher dafür gedacht
ist, um Zwischenergebnisse mit vollen 80 Bit auch in den Speicher
schreiben zu können.
> Und der 8087 ist hier nur beispielhaft gemeint. Das bis jetzt noch nicht> näher beschriebene Code-schnipsel des TO kann auch für eine andere> machine gedacht sein (DSP, ibm360, space-ASIC) bei der die interne> Darstellung höhere Genauigkeit aufweist als mit dem Speicher austauschbar> ist.
Ich fand's erstaunlich, jetzt zu lesen, daß man mit Absicht intern mit
größerer Bitbreite rechnet als man nachher extern üblicherweise
verwendet, damit Zwischenergebnisse genauer sind. In C will man das
nicht unbedingt immer, weil das Verhalten dann nicht der Spezifikation
entspricht. Man spricht in so einem Fall von "excess presicion". Deshalb
gibt es die oben schon mal von jemandem erwähne Möglichkeit, den
Compiler zu zwingen, jedes Zwischenergebnis erst in den Speicher zu
schreiben und wieder von da zu lesen, um die Größe auf diese Weise auf
32 oder 64 Bit zu reduzieren. Das macht die Sache zwar tierisch lahm,
aber sorgt dafür, dass das Verhalten dann der Vorgabe von ISO-C
entspricht.
Seit dem 14. März 1988 feiern Mathematik-Freunde in aller Welt den Tag
der Kreiszahl. Aufgrund der amerikanischen Datumsschreibweise 3-14-15
gerät er in diesem Jahr zum Super-Pi-Tag.
Heise...
Rolf Magnus schrieb:> Fpga Kuechle schrieb:>> Sicher?>> Ich hab's noch nicht selbst ausprobiert, aber ich hab extra noch eins> von meinen alten verstaubten x86-Assembler-Büchern aus dem Regal> gezogen, und da wird das bestätigt.
OK, da habe ich mich geirrt, "80 bit laden" ist wohl möglich. Ich hab
mal aus meinen Regal auch mal des vergilbteste Lehrbuch gezogen -
"Einführung in die 16bit-Mikrorechentechnik mit dem K1860 WM 86"
Militärverlag 1988. Der K1810WM86 ist ein "Sowjetischer" kompatibler
Nachbau zum intel 8086, WM87 der zum 8087. Das 80 bit Format heisst dort
"Gleitkomma nicht normalisiert (temporäres Format)" und es gibt 3
Ladebefehle für float:
FLD GK kurz 11011001
FLD GK lang 11011101
FLD GK temporar 11011011 //den hab ich übersehen
Und es werden auch Konstantenladebefehle erwähnt, aber nicht welche
Genauigkeit damit realisiert wird:
FLDZ Null
FLD1 Eins
FLDPI Pi
FLDL2T Log2 10
> Ich fand's erstaunlich, jetzt zu lesen, daß man mit Absicht intern mit> größerer Bitbreite rechnet als man nachher extern üblicherweise> verwendet, damit Zwischenergebnisse genauer sind.
Das hat mich wiederum nicht überrascht. Meine antrainierte
Erwartungshaltung bei Hand- und Maschinenrechnung ist das immer die
gültigen Stellen angegeben werden - sind weniger Stellen gültig gibt man
(bei Handrechnung) die ungültigen nicht an (Beisp Einkaufspreis, 5.99 €
und nicht 5.9900000€. Hat man nun eine fixe Stellenanzahl die immer
ausgegeben werden muß bspw. Mantisse 52 bit dann müssen die oberen 51
Stellen genau sein, die letzte gerundet. Deshalb genauere
Zwischenergebnisse.
> In C will man das> nicht unbedingt immer, weil das Verhalten dann nicht der Spezifikation> entspricht.
OK, das ist mir Bitzähler neu, ich bin da eher auf der Seite derer die
eine garantierte Genauigkeit wollen. Dazu gibt es recht interessante
Abhandlungen von William Kahn - der mathematiker der intel bei floating
point beraten hat:
http://en.wikipedia.org/wiki/Rounding#The_table-maker.27s_dilemma
MfG,
Damit kein falscher Eindruck entsteht sei noch daran erinnert, dass die
Anzahl Bits, mit der auf PCs mit Fliesskommawerten bei Zwischenwerten
durchschnittlich gerechnet wird, mittlerweile immer geringer wird, also
die Ergebnisse im Gesamtmittel immer ungenauer werden.
In 16- und 32-Bit Zeiten rechnete man, wie hier ausgiebig beschrieben,
bei Zwischenwerten meist im 80 Bit Format des 8087 Koprozessors und
dessen internen Nachfahren.
Seit zunehmend 64-Bit Programme eingesetzt werden entfällt dieses 80-Bit
Zwischenformat. Denn das 64-Bit Programmiermodell der üblichen
Betriebssysteme sieht an Stelle des x87 Befehlssatzes SSE vor. Und da
steht auch für Zwischenwerte nur das 64-Bit Format zur Verfügung.