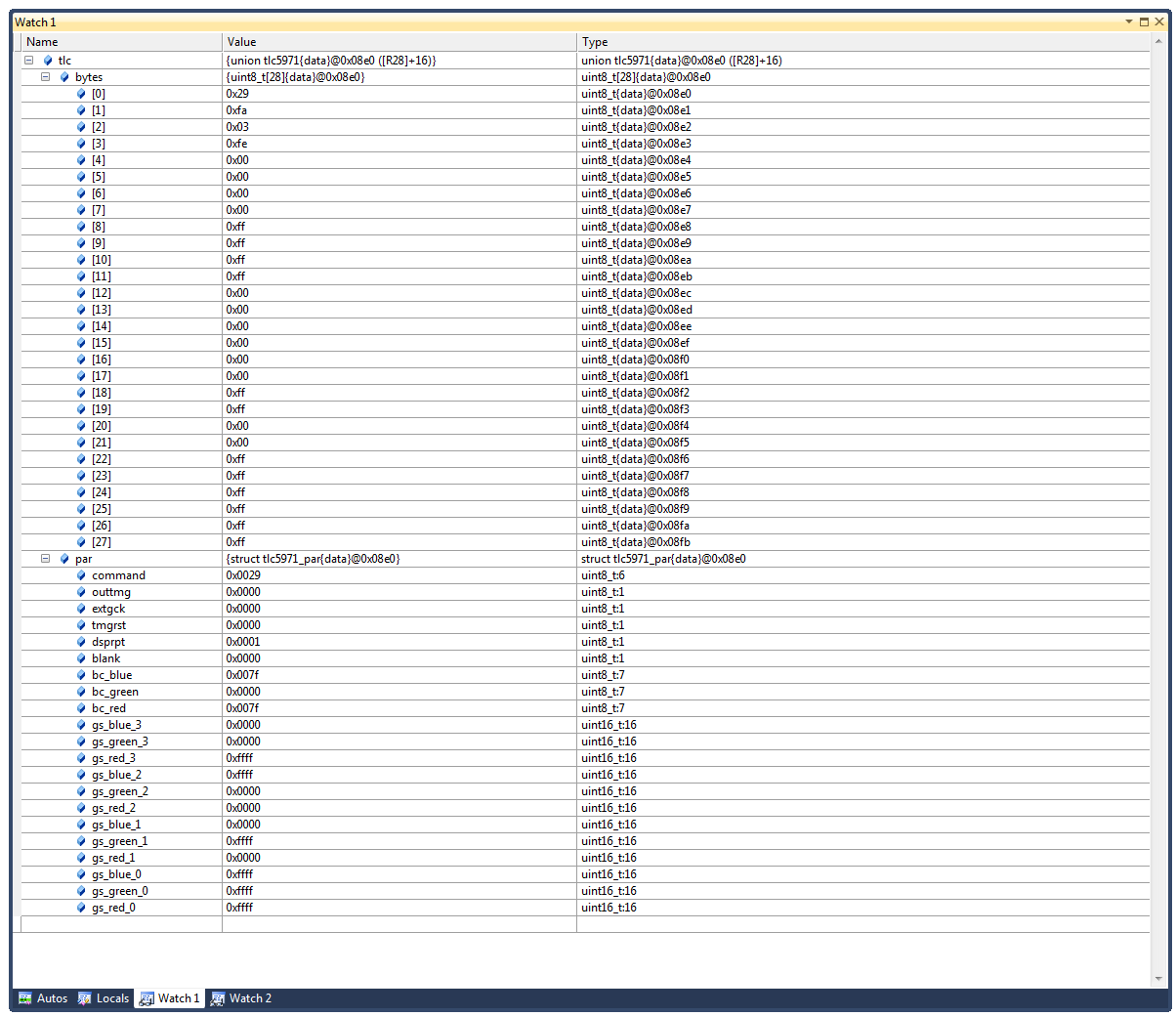
Hallo, um einen TLC5971 (LED Treiber) komfortabel anzusteuern habe ich ein struct mit den Parametern des Treibers erstellt und das Ganze anschließend in eine union gepackt um es dann byte-weise verschicken zu können. struct tlc5971_par { uint8_t command:6; uint8_t outtmg:1; uint8_t extgck:1; uint8_t tmgrst:1; uint8_t dsprpt:1; uint8_t blank:1; uint8_t bc_blue:7; uint8_t bc_green:7; uint8_t bc_red:7; uint16_t gs_blue_3:16; uint16_t gs_green_3:16; uint16_t gs_red_3:16; uint16_t gs_blue_2:16; uint16_t gs_green_2:16; uint16_t gs_red_2:16; uint16_t gs_blue_1:16; uint16_t gs_green_1:16; uint16_t gs_red_1:16; uint16_t gs_blue_0:16; uint16_t gs_green_0:16; uint16_t gs_red_0:16; }; union tlc5971 { uint8_t bytes[28]; struct tlc5971_par par; }; Ich habe mittlerweile auch gelesen, dass es Compilersache ist wie das Bitfeld später im Speicher liegt. Ich verwende AtmelStudio 6 und dort ist die Option -fpack-struct standardmäßig dabei. Die Optimierungen habe ich abgeschaltet und nun erhalte ich trotzdem die Daten wie sie im Bild dargestellt sind. Bereits das erste Byte ist also nicht korrekt. In bytes[0] müsste ja schon 0xA4 stehen. Hat jemand einen Tipp wie man es sauber lösen könnte? Viele Grüße
Angehängte Dateien:
-

watch.PNG
80 KB
@ Thomas (Gast) >um einen TLC5971 (LED Treiber) komfortabel anzusteuern habe ich ein >struct mit den Parametern des Treibers erstellt und das Ganze >anschließend in eine union gepackt um es dann byte-weise verschicken zu >können. Kann man machen, ist aber compilerabhängig. >Ich verwende AtmelStudio 6 und dort ist die Option -fpack-struct >standardmäßig dabei. Die Optimierungen habe ich abgeschaltet und nun >erhalte ich trotzdem die Daten wie sie im Bild dargestellt sind. >Bereits das erste Byte ist also nicht korrekt. In bytes[0] müsste ja >schon 0xA4 stehen. Nö. Bitfelder sind ne windige Sache und in der C-Praxis nicht sehr häufig. Der Compiler darf die nahezu beliebig auf mehrere Bytes aufteilen, auch mit Leerbits. Wie das genau im C-Standard geregelt ist, weiß ich nicht, ist mir als Pragmatiker auch herzlich egal. >Hat jemand einen Tipp wie man es sauber lösen könnte? Nimm ein normales Feld und schreib dir eine handvoll Funktionen, welche die jeweileigen Bits per Bitmanipulation setzen. Das ist eindeutig und ggf. auch portabel.
Thomas schrieb: > Bereits das erste Byte ist also nicht korrekt. In bytes[0] müsste ja > schon 0xA4 stehen. versteh ich nicht. Warum soll da 0xA4 drinnen stehen. Du hast offenbar 0x29 ins command member geschrieben, die beiden oberen Bits in diesem Byte sind 0 und daher steht im Byte insgesamt auch 0x29 drinnen. Die Bits werden vom Compiler beginnend mit dem LSB, also Bit 0 allokiert! Also von unten nach oben und nicht von oben nach unten. > Hat jemand einen Tipp wie man es sauber lösen könnte? Man kann es mit einer struct und Bitfeld machen. Man muss aber nicht. IMHO bringt hier ein Bitfeld nicht viel, auch nicht an Klarheit. Denn die Bitpositionen sind sowieso fix und ändern sich nicht. Es kommt auch in den nächsten 100 Jahren kein Bit dazu oder weg. D.h. ganz klassisch mit Funktionen bzw Makros, die die jeweiligen Werte zurecht schieben und mit UND bzw. ODER Operationen in die Bytes einbauen. Was anderes kann auch der Compiler nicht machen. Schreibst du
1 | par.outtmg = 1; |
dann muss der Compiler das auch (konzeptionell) in
1 | par.bytes[0] = par.bytes[0] | 0x40; |
aufdröseln. Geschwindigkeitsmässig ist das ziemlich egal ob du daher das eine oder das andere schreibst. Nur: Mit der Schreibweise, in der du selber die Bits setzt, hast du alle nicht definierten Dinge von Bitfeldern erst mal aussen vor und alles funktioniert so, wie du das haben willst. Wenn die Syntax nicht gefällt ... verstecken in einer Funktion bzw. einem Makro kann man das immer noch.
Und sowas
1 | blue_0
|
2 | green_0
|
3 | red_0
|
4 | |
5 | blue_1
|
6 | green_1
|
7 | red_1
|
8 | |
9 | ...
|
wirst du eher verfluchen als das es dir nützt. Damit wird die Ansteuerung nämlich zur Qual. Wieviel simpler ist es in der Verwendung wenn du ganz einfach sagen kannst: Die 3. LED auf die und die RGB Werte setzen. Klar, mit einem switch-case ist das natürlich möglich. Aber es besteht ein ganz simpler Zusammenhang zwischen der LED-Nummer und dem Byte im Array, wo die Bits rein müssen. Dann geht das auch mal mit 200 LED an 48 Bausteinen problemlos ohne dass du erst mal 86 Fallunterscheidungen im Vorfeld brauchst. Wann immer du versucht bist, konzeptionell gleiche Variablennamen zur Unterscheidung durchzunummerieren, dann sollten deine Alarmglocken anfangen zu klingeln und du darüber nachdenken ob nicht eine Array-Sicht der Dinge samt Berechnung des Index die bessere Lösung wäre.
Falk Brunner schrieb: > Der Compiler darf die nahezu beliebig auf mehrere Bytes > aufteilen, auch mit Leerbits. Das ist im ABI (Application Binary Interface) beschrieben. Der Compiler übersetzte den Code nicht beliebig, sondern wie im ABI spezifiziert.
Naja, die 4 RGB Ausgänge könnte ich ja in meiner struct einfach wieder als struct einbinden, dann hätte ich auch mit der union Konstruktion die Möglichkeit die 200LEDs anzusteuern. Aber ich will den Aufbau so auch gar nicht verteidigen. Es gibt da sicher schönere Ansätze. Mir ging es hier halt um die Sache mit der union. Ich habe solche Konstrukte früher auch schon verwendet um zB einfacher lesbare Bitfelder in die 8Byte Palyload eines CAN Busses zu packen. Darum war ich ziemlich überrascht, dass hier nun so etwas rauskommt. Der eigentliche Fehler von mir war aber , dass ich die Bytes falschrum aufgebaut habe. Wenn man nun beachtet, dass jedes Byte quasi von hinten aufgefüllt wird, dann funktioniert es. Das macht das Ganze dann aber extrem hässlich, weil man die Bitfelder dann trennen muss, damit man die Bytegrenzen kontrollieren kann :( Vielen Dank!
Thomas schrieb: > Der eigentliche Fehler von mir war aber , dass ich die Bytes falschrum > aufgebaut habe. Wenn man nun beachtet, dass jedes Byte quasi von hinten > aufgefüllt wird, dann funktioniert es. Das macht das Ganze dann aber > extrem hässlich, weil man die Bitfelder dann trennen muss, damit man die > Bytegrenzen kontrollieren kann :( Oder beim SPI ganz einfach am anderen Ende anfangen (bzw. anfangen lassen) Anstatt MSB zuerst, LSB zuerst (bzw. umgekehrt) :-)
Von hinten anzufangen nützt mir aber an den Bytegrenzen doch auch nichts oder übersehe ich da gerade etwas? Wenn ich es nun wie folgt anordne stimmt mein erstes Byte: //Byte 0 uint8_t outtmg:1; uint8_t extgck:1; uint8_t command:6; Aber beim zweiten Byte bekomme ich dann die Probleme. Hier müsste zuerst die letzten drei Funktionsbits kommen und dann der bc_clue Block, der dann auf der Bytegrenze liegt. Durch die Schreibweise in der umgedrehten Reihenfolge wie bei Byte 0 passt es nun aber natürlich nicht in ein Byte und er packt nun nur tmgrst und bc_blue rein. Damit stimmt die Reihenfolge dann gar nicht mehr. //Byte 1 uint8_t bc_blue:7; uint8_t tmgrst:1; uint8_t dsprpt:1; uint8_t blank:1; Das ganze wird langsam zu einem eher akademischen Problem, aber ich finde es (auch wenn eine andere Lösung längst schöner wäre) sehr interessant. Das Problem ist ja das Vollwerden eines Bytes. Es wird ja quasi solange weiter nach "unten" geschaut in der struct bis das Byte voll wird und dann wird von oben bis nach oben reingekippt. Viele Grüße
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.