Hallo,
klar heißt s wieder vom fall abhängig..aber wenn man einfach sachen
macht, also nicht Schwerpunktmässig die stärken der CPU (Xmega schnelles
Portschalten, ARM Flieskomma)
Wie ist dann der Takt vergleichbar..
Liege ich richtig, das ein 32MHZ XMEGA bei den meisten Sachen extwas
schneller als ein 70 oder 80MHz Arm ist?
Ab 120MHZ der Arm schneller ist?
Ab wieviel MHz bekommt das z.B. ein ARM hin?
https://www.youtube.com/watch?v=CXFOTpM2Jn4
oder sowas
https://www.youtube.com/watch?v=yK2MMMTw3SY
leider finde ich nirgend z.B. ein Vergleichsdemo
Man findet auch nur schwer vergleichbares..dashier ist unfair, weil der
controller vermutlich genug damit zu tun hat den VGA Anschluss zu
bedienen
https://www.youtube.com/watch?v=RY92VcNa1fI
Max Schauzer schrieb:> Liege ich richtig, das ein 32MHZ XMEGA bei den meisten Sachen extwas> schneller als ein 70 oder 80MHz Arm ist?> Ab 120MHZ der Arm schneller ist?
Da Xmega eine 8 bit RISC-CPU und ARM eine 32 bit RISC-CPU ist das sehr
unwahrscheinlich.
MfG,
Fpga Kuechle schrieb:> Da Xmega eine 8 bit RISC-CPU und ARM eine 32 bit RISC-CPU ist das sehr> unwahrscheinlich.
wenn für die Aufgabe 8bit reichen, spielt das keine rolle.
Peter II schrieb:> Fpga Kuechle schrieb:>> Da Xmega eine 8 bit RISC-CPU und ARM eine 32 bit RISC-CPU ist das sehr>> unwahrscheinlich.>> wenn für die Aufgabe 8bit reichen, spielt das keine rolle.
wenn du meinst das 32MHz Taktung eine mehr als doppelt so hohe Taktung
einer Machine mit vierfacher datenbusbreite kompensiert dann ist das
natürlich nicht von Belang ...
Max Schauzer schrieb:> klar heißt s wieder vom fall abhängig..aber wenn man einfach sachen> macht, also nicht Schwerpunktmässig die stärken der CPU (Xmega schnelles> Portschalten, ARM Flieskomma)
Anders ausgedrückt: Bei dem, was der AVR besser kann als der ARM, ist er
besser. Bei dem, was er schlechter kann, ist er schlechter. Jetzt muss
man nur noch wissen, aus welchen dieser beiden Alternativen das zu
betrachtende Problem überwiegend besteht. ;-)
Aber im Ernst: Es gibt neben Fliesskommarechnung auch weniger
offensichtliche Punkte, wo ein 8-Bitter wie AVR mit oder ohne X
schwächelt. Schon die Verarbeitung von nicht-statischen Adressen aller
Art macht ihm deutlich Arbeit. Ob Umgang mit Pointern (zu wenig
Adressregister) oder Array-Indizierung (16-Bit Rechnung mit Shift oder
Multiplikation).
Es gilt also das, was für Benchmarks generell gilt: Ein Vergleich zweier
Systeme liefert nur eine Aussage für die dabei eingesetzte Software.
Während bei PCs mittlerweile durch entsprechend grosse Benchmark-Suites
immerhin ziemlich viel Software integriert ist (dutzende z.T. sehr
grosse Programme) und sich das etwas ausmittelt, hat sich
verständlicherweise niemand die Mühe gemacht, entsprechend umfangreiche
Benchmark-Suites für Mikrocontroller zu entwickeln.
Bleibt also eigentlich nur der im Controller-Sektor recht verbreitete
Prozessor-Benchmark Dhrystone. da sollte sich auch was googeln lassen.
Dir muss nur klar sein, dass damit eben nur die Performance des
Dhrystones gemessen wird und die Performance deiner Anwendungen eine
Grössenordnung neben dieser Peilung liegen kann.
Fpga Kuechle schrieb:> Tatsächlich? sind nicht beide CPU's RISC-maschinen mit single cycle> Instructions?
Yep. Beide haben beispielsweise Shiftoperationen, die jeweils nur einen
Takt brauchen. Fairer Vergleich, oder? ;-)
laufen lassen...
ich muss glatt nochmal prüfen ob nich irgenwo eine Takteinstellung
falsch ist..aber hier kackt der ARm gerade deutlich!! ab..mit
120MHz..das hätte ich niemals so krass erwartet.
Habe hier von microe die beiden Micromedia Boards :-)
Der Grund ist weil ich natrülich auch überelge zu Arm zu wchseln wie so
viele..daher beschäftigt mich das gerade, was in der Hobbykiste
landet...ob ich einen Xmea für3€ kaufe oder eine vergleichbaren M3 mit
120 oder mehr für 7-12€ ist ein heftiger Unterschied wenn man sich ein
kleines Lager anlegen will
Max Schauzer schrieb:> so, hab es eben einfach mal getestet :-)> Oha...das überrascht mich jetzt doch..habe einfach mal auf einem> XMEGA128 und einem STM32F207>
>> laufen lassen...> ich muss glatt nochmal prüfen ob nich irgenwo eine Takteinstellung> falsch ist..aber hier kackt der ARm gerade deutlich!! ab..mit> 120MHz..das hätte ich niemals so krass erwartet.> Habe hier von microe die beiden Micromedia Boards :-)
Ja, schlechte Software lässt jede CPU abkacken. Aber laut thread-titel
willst du doch prozessoren vergleichen und nicht Software?
Und wie es scheint testest du hier das Graphic-subsystem und nicht die
CPU.
Auch hier gilt eine miese Graka lässt jede CPU alt aussehen.
MfG,
Fpga Kuechle schrieb:> Ja, schlechte Software lässt jede CPU abkacken. Aber laut thread-titel> willst du doch prozessoren vergleichen und nicht Software?
wie willst du ohne Software eine CPU vergleichen? Wiegen?
Peter II schrieb:> Fpga Kuechle schrieb:>> Ja, schlechte Software lässt jede CPU abkacken. Aber laut thread-titel>> willst du doch prozessoren vergleichen und nicht Software?>> wie willst du ohne Software eine CPU vergleichen? Wiegen?
Technische Daten aus dem datenblatt.
eben und ich will nicht für jeden Controller den code erst optimieren
müssen..sondenr vergleiche so wie man üblich programmiert wenn man
schnell mal ein Projekt machen will...und daher habe ich ja ebe n diese
beiden Zeilen unverändert auf beiden Controllern laufen lassen..dauert
noch einen moment. erkennt gerade den Controller nicht am USB..blöde
VMWare
haha, Dui minst also Theoretische werte :-)
Mich interessieren aber eher wie gesagt die praktischen ;-) machen kann
man viel aber was ist bei allgemeiner Programmierung..
Hmpf..nun noch 131 Windowx XP updates :-(
Peter II schrieb:> wie willst du ohne Software eine CPU vergleichen? Wiegen?
Och, da gibts noch mehr Varianten die mehr Sinn ergeben als das Gewicht.
Gehäusetyp und Pindichte, Stromverbrauch und -Versorgungsoptionen,
In-Circuit-Programmierung und -Debugging, Entwicklungssystem, ...
Fpga Kuechle schrieb:> Technische Daten aus dem Datenblatt.
geht nicht sinnvoll, sonst würde Intel & Co nicht ihre vergleiche anhand
von Benchmarks machen.
Peter II schrieb:> geht nicht sinnvoll, sonst würde Intel & Co nicht ihre vergleiche anhand> von Benchmarks machen.
Fairerweise muss man sagen, dass man bei AvrX und Cortex M3 durch
Abzählen von Takten von Befehlen eines Programms der Realität wesentlich
näher kommt als bei Intel & Co. Bei den x86 von heute ist das ein völlig
hoffnungsloses Unterfangen.
Max Schauzer schrieb:> haha, Dui minst also Theoretische werte :-)> Mich interessieren aber eher wie gesagt die praktischen ;-) machen kann
Ja in Praxis kann man auch die schnellste CPU so suboptimal
programmieren
das 99% des Leistungspotentials verschwendet sind. Um zu wissen was in
Praxis optimal möglich muß man schon ins Datenblatt schauen.
MfG,
Sind die Displays identisch?
Sind sie identisch angeschlossen?
Werden die Displayschnittstellen mit dem gleichen Takt betrieben?
Sind die Bibliotheken identisch?
Mit Deinem Test testest Du höchstens die Displays und die Bibliotheken,
aber nicht den Prozessorkern.
Und die Codequalität des Mikroe-Zeugs ist natürlich auch ungewiss. Nimm
mal gcc, da weiß man wenigstens, dass da Profis am Werk waren.
fchk
Fpga Kuechle schrieb:> das 99% des Leistungspotentials verschwendet sind. Um zu wissen was in> Praxis optimal möglich muß man schon ins Datenblatt schauen.
Seit wann steht die realistische Performance direkt im Datasheet? Es ist
eine Wissenschaft für sich, aus Doku zu ISA und Implementierung die
Performance ganz grob einpeilen zu können.
Peter II schrieb:> Fpga Kuechle schrieb:>> Technische Daten aus dem Datenblatt.>> geht nicht sinnvoll, sonst würde Intel & Co nicht ihre vergleiche anhand> von Benchmarks machen.
Doch man kann sehr wohl aus dem Datenblatt abschätzen wieviel
Performance möglich ist und ob der Benchmark was taugt oder nicht.
MfG,
"ind die Displays identisch?
Sind sie identisch angeschlossen?
Werden die Displayschnittstellen mit dem gleichen Takt betrieben?
Sind die Bibliotheken identisch?
Mit Deinem Test testest Du höchstens die Displays und die Bibliotheken,
aber nicht den Prozessorkern."
ja, alles gelich, selbst das Platinenlayout sieht gleich aus :-)
Wie gesagt von Microe die micromedia board mit 320x240 Display, beide
mit dem Pascal Compiler und beide die gleichen Zeilen code
Fpga Kuechle schrieb:> Doch man kann sehr wohl aus dem Datenblatt abschätzen wieviel> Performance möglich ist und ob der Benchmark was taugt oder nicht.
Bei Intel&Co auch? ;-)
A. K. schrieb:> Fpga Kuechle schrieb:>> das 99% des Leistungspotentials verschwendet sind. Um zu wissen was in>> Praxis optimal möglich muß man schon ins Datenblatt schauen.>> Seit wann steht die realistische Performance direkt im Datasheet? Es ist> eine Wissenschaft für sich, aus Doku zu ISA und Implementierung die> Performance ganz grob einpeilen zu können.
Datenbus-frequenz rauslesen, cycles pro transfers rauslesen,
Datenbusbreite rauslesen -> Performance bestimmen
Das hat man mit ein paar jahren Erfahrung schnell drauf.
MfG,
A. K. schrieb:> Fpga Kuechle schrieb:>> Doch man kann sehr wohl aus dem Datenblatt abschätzen wieviel>> Performance möglich ist und ob der Benchmark was taugt oder nicht.>> Bei Intel&Co auch? ;-)
Steht intel im Thread-Titel oder ARM?
MfG,
Max Schauzer schrieb:> ja, alles gelich, selbst das Platinenlayout sieht gleich aus :-)
Display mit eigenem Controller? Wenn der Anhänger nur 60kmh darf, dann
sind Porsche und Trabbi gleich schnell. ;-)
Fpga Kuechle schrieb:> Das hat man mit ein paar jahren Erfahrung schnell drauf.
Beim Blocktransfer ja. Bisschen schwieriger wird aber die Abschätzung,
in wieviele Maschinenbefehle sich ein C Programm ungefähr übersetzt, und
sei es nur in Relation zueinander. Bei Maschinen gleicher Klasse, also
32-Bitter gegeneinander klappt das schon wesentlich leichter als wenn
völlig verschiedene 8- und 32-Bitter gegeneinander antreten.
Der Vergleich ist nicht so ganz einfach. Es dürften aber nur relativ
wenige spezielle Aufgaben sein, wo der AVR mit weniger Taktzyklen
auskommt als der ARM. Auch wenn keine Fließkommazahlen gebraucht werden,
wird der ARM eher mit weniger Zyklen auskommen - wie viel hängt halt von
der Aufgabe bzw. dem Programm ab.
Bei den ARMs hat man keine lineare Skalierung mit dem Takt. Flash und IO
Bus haben oft ein relativ niedriges Taktlimit. Mit 80 MHz ist der ARM
entsprechend da nicht mehr 4 mal so schnell wie mit 20 MHz. Da
unterscheiden sich wohl auch die Implementierungen. Code kann man ggf.
auch schneller aus dem RAM ausführen - allerdings ist da ggf. der Platz
knapp.
Warum ist verwendest du den internen Oszillator (HSI) und nicht den
Externen (HSE)? Gibt es überhaupt einen STM32 der mit dem Internen so
hoch takten kann?
so..wie ich das sehe kackt der ARm voll ab :-( Also bleibe ich wohl doch
beim Xmega..
Der Xmega ist ca. 40% schneller!
Anbei nochmal die einstellungen falls jemand noch einen Fehler
entdeckt..
ARM 120MHz gegen Xmega 32MHz!!
http://www.directupload.net/file/d/3997/ozjnkjc3_jpg.htmhttp://www.directupload.net/file/d/3997/rikqsnuc_jpg.htm
dann ist es also schon so wie ich es mir die ganze Zeit
dachte..schade..can wäre schön gewesen..aber dafür so viel mehr kohle
und mehr konfigurierei.neee
Dass der XMega 40% schneller ist, kann nicht sein. Da ist definitiv was
im Argen.
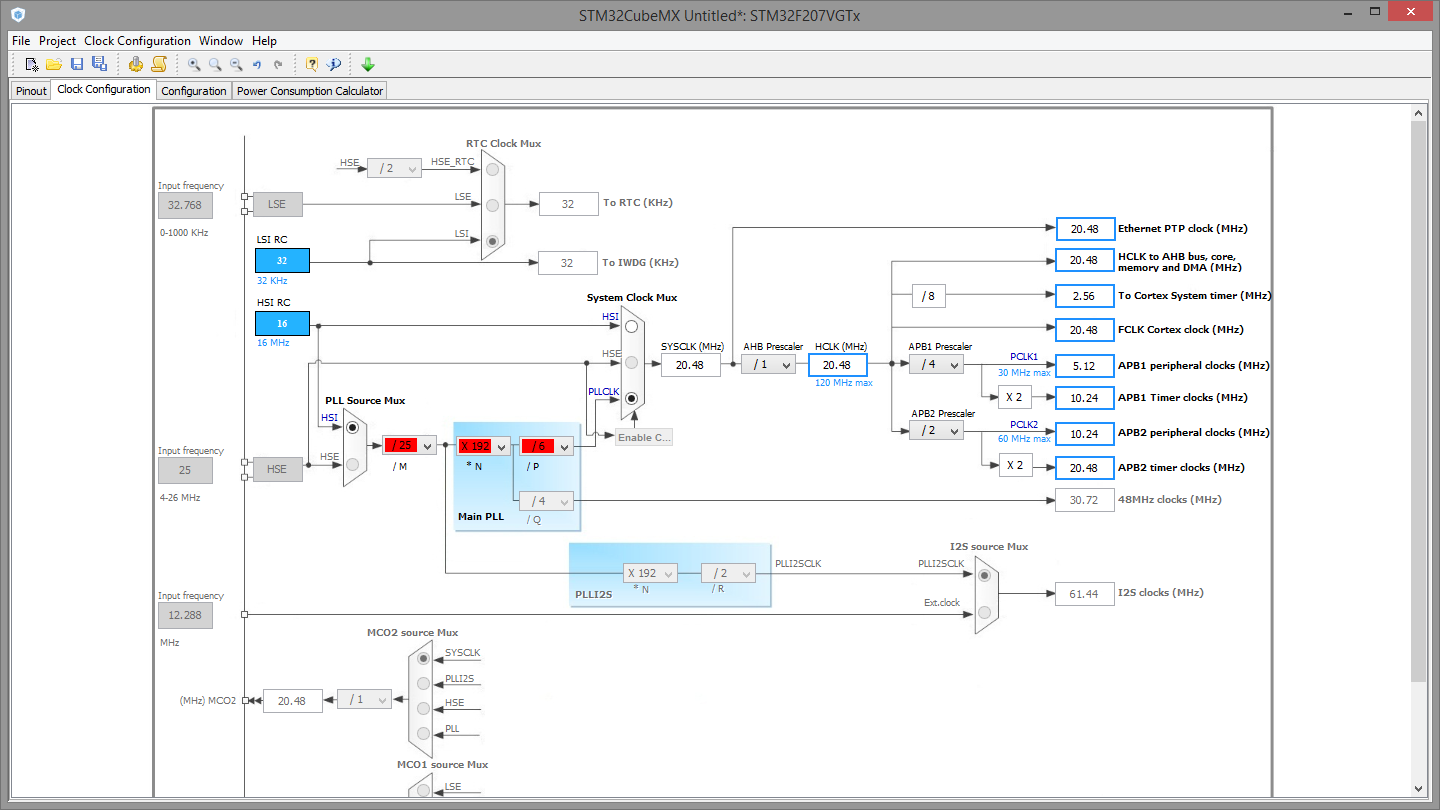
Habe deine Einstellungen mal in STM32CubeMx übertragen und nach dessen
Berechnung dürfte der ARM mit 20,48 MHz laufen (siehe Bild 1). Übernehme
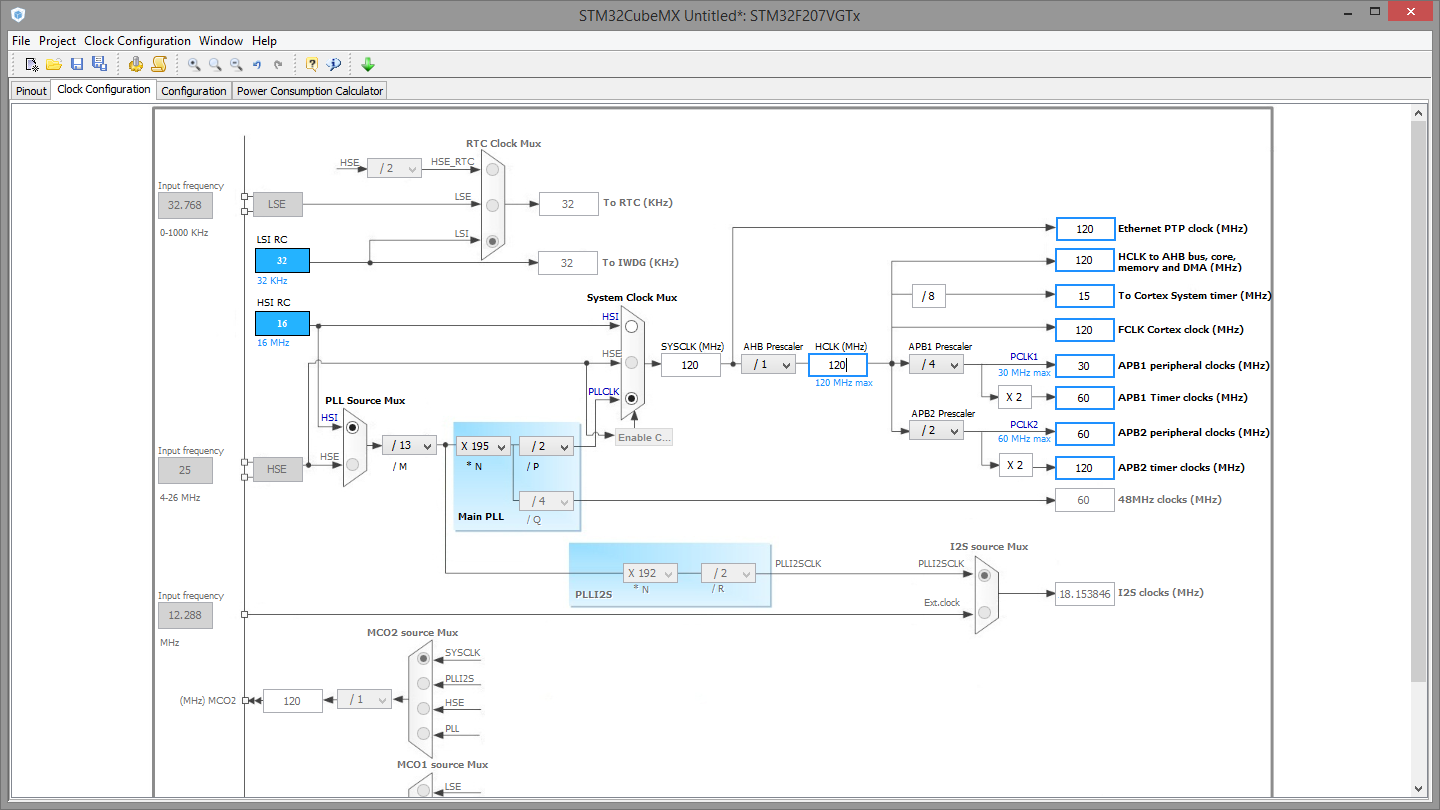
mal die Einstellung aus Bild 2.
ahh, super jetzt ist der ARM schneller, dennoch deutlich weniger als
erwartet..
Habe den PLLP jetzt mal auf 6 gestellt, also 40MHz, dann ist der ARM
tatsächlich etwas schneller als der Xmega mit 32MHz..Also scheinen noch
gut direkt mit dem Takt vergleichbar zu sein
Max Schauzer schrieb:> wieso? Das wir davon ausgehen das beides RISV ist haen wir ereits> geklärt...
Das sagt erst mal wenig aus. Denn da gibt es noch sowas wie
Registerbreite, Busbreite, Taktfrequenz, Cache, Anzahl der Kerne,
RAM-(Busbreite, Latenz, Größe), DMA, etc. .
Lass die beiden erst mal mit größeren Zahlen rechnen, da wird der XMega
kein Land sehen.
Max Schauzer schrieb:> wieso? Das wir davon ausgehen das beides RISV ist haen wir ereits> geklärt...
Vergleich mal
int shift(int x, int n) { return x >> n; }
für variables n. Klar, beide RISCs haben einen Shift-Befehl, der nur
einen Takt benötigt, aber...
Schau dir mal an, was bei
int a[10][10]; ... a[x][y] ...
rauskommt und zähl die Takte mit. Oder Codelänge.
Nur 2 Beispiele von vielen für stinknormalen Code.
Wenn Programme grösser als ein paar KB sind und der Overhead vom
Startup-Code nicht mehr dominiert, dann wirst du typischerweise auch
feststellen, dass CM3 Code kürzer als AVR Code ist.
Kleiner Spass am Rande: Vergleich mal den Code, der bei dieser völlig
harmlosen und im Grafik-Umfeld auch nicht exotischen Funktion rauskommt:
1
intshift(inta,intb,intn)
2
{
3
return(n>0)?a|(b>>n):a|(b<<n);
4
}
wobei hier ein kleiner Abstecher zum klassischen ARM Befehlsatz durchaus
lohnen kann, denn das ergibt:
cmp r2, #0
orrgt r0, r0, r1, asr r2
orrle r0, r0, r1, asl r2
CM3 kommt da nicht ganz ran:
cmp r2, #0
ite gt
asrgt r1, r1, r2
lslle r1, r1, r2
orr r0, r0, r1
CM0 erst recht nicht:
cmp r2, #0
ble .L2
asr r1, r1, r2
b .L4
.L2:
lsl r1, r1, r2
.L4:
orr r0, r1
von AVR ganz zu schweigen:
cp _zero_reg_,r20
cpc _zero_reg_,r21
brge .L2
rjmp 2f
1:
asr r23
ror r22
2:
dec r20
brpl 1b
rjmp .L4
.L2:
rjmp 2f
1:
lsl r22
rol r23
2:
dec r20
brpl 1b
.L4:
or r22,r24
or r23,r25
PS: Ok, das ist etwas "tuned for ARM" ;-)
TriHexagon schrieb:> Lass die beiden erst mal mit größeren Zahlen rechnen, da wird der XMega> kein Land sehen.
Richtig. Nur ist der springende Punkt ja gerade, daß man in kleineren
Steuerungsaufgaben fast nie mit großen Zahlen rechnen muß.
Wenn nur maximal 10 Bits reinkommen und nur maximal 10Bits wieder
rausgehen können, muß man bei allen üblichen Algorithmen halt maximal
mit 20..24 Bits rechnen. In dem meisten Fällen genügen aber auch 16 oder
noch weniger.
Ja, es gibt leider sehr viele Leute, die sind nur dazu in der Lage,
vorhanden Quelltext per C&P zu übernehmen.
Nur dieses KRASS UNFÄHIGE PACK braucht dann oft zwingend 32Bit oder gar
eine Double-fähige FPU noch dazu, und das nur, weil der raubkopierte
Quelltext halt eigentlich für Desktop-PCs geschrieben wurde...
Das ist aber nur bemitleidenswerter Programmiererabschaum. Nicht
wirklich Programmierer. Irrelavant, außer für BWLer, die solche Abschaum
natürlich gern einkaufen, weil er einfach mal billich ist.
c-hater schrieb:> Richtig. Nur ist der springende Punkt ja gerade, daß man in kleineren> Steuerungsaufgaben fast nie mit großen Zahlen rechnen muß.>> Wenn nur maximal 10 Bits reinkommen und nur maximal 10Bits wieder> rausgehen können, muß man bei allen üblichen Algorithmen halt maximal> mit 20..24 Bits rechnen. In dem meisten Fällen genügen aber auch 16 oder> noch weniger.
Dir ist schon klar, dass eine acht Bit CPU mehr Takte/Klimzüge braucht,
wenn Du zehn Bits oder mehr verarbeiten möchtest gegenüber einer
16-/32-Bit CPU... und gerade beim multiplizieren, sollte genug "Luft" an
Bitbreite für das Ergebnis vorhanden sein, oder man muss vorher Prüfen,
ob es keinen Überlauf gibt - zwei 16-Bit Zahlen zu multiplizieren mit
einer 32-Bit CPU dürfte schneller von statten gehen, als bei einer 8-Bit
CPU...
Max Schauzer schrieb:> so, hab es eben einfach mal getestet :-)> Oha...das überrascht mich jetzt doch..habe einfach mal auf einem> XMEGA128 und einem STM32F207 TFT_Set_Pen(CL_black, 2);> TFT_Set_Brush(1, CL_BLUE, 1, LEFT_TO_RIGHT, CL_BLUE, CL_BLUE);> For n:=1 TO 320 Do TFT_Rectangle(0, 0, n, 20);> TFT_Set_Brush(1, CL_yellow, 1, LEFT_TO_RIGHT, CL_BLUE, CL_yellow);> For n:=1 TO 320 Do TFT_Rectangle(0, 0, n, 20);
Eigentlich ist dieses Programm auch absolut unbrauchbar für den
Vergleich. Hier werden nur Daten verschoben und dafür brauch man keine
CPU. Da benutzt man einen DMA, dann geht die Belastung auf die CPU gegen
null. Und das auch nur weil DMA und CPU den gleichen Bus benutzen.
Ich hatte mal privat die Taktzyklen eines AVR gemessen, die für die
Durchführung einer 64 Bit Ganzzahldivision benötigt werden.
Dann hatte ich aus beruflichen Gründen den "Trace" einer 64Bit
Ganzzahldivision auf einem ARM Cortex-A9 vorliegen. Das Ergebnis:
Anzahl der Taktzyklen auf einem AVR * 4 = Anzahl der Assembler Befehle
auf einem Cortex-A9.
Das sagt leider nichts darüber aus, wie schnell der ARM jetzt ist, da
die Taktzyklen dort nicht gezählt wurden. Der Faktor *4 würde natürlich
passen, da erstere 8Bit und letztere in 32Bit rechnet, unter der (zu
optimistischen) Annahme dass der AVR jeden Befehl in einem Takt
ausführt.
Wie schnell nun der ARM pro Takt im Verhältnis zum AVR ist, hängt auch
wieder von der ARM Architektur ab. Der Cortex A8 hat zwei
Ausführungseinheiten und kann somit im günstigsten Fall zwei Befehle
gleichzeitig ausführen.
Im wesentlichen kann man sich das so vorstellen, dass der zweite Befehl
angefangen wird, bevor der erste fertig berechnet wurde. Das klappt
(vereinfacht gesagt), solange der zweite Befehl keine Register
verwendet, die auch im ersten Befehl verwendet werden. Die erreichbare
Geschwindigkeit hängt somit davon ab, wie geschickt der Compiler dabei
ist die einzelnen Befehle so zu verschachteln, dass möglichst viel
anderer Code zwischen zwei Befehlen liegt, der das gleiche Register
verwendet.
1
ldr r0, =123456
2
ldr r1, =234567
3
add r2, r1, r0
4
mov r4, #0
dürfte langsamer sein als
1
ldr r0, =123456
2
ldr r1, =234567
3
mov r4, #0
4
add r2, r1, r0
Beim Cortex A9 ist dies ebenfalls so, dafür kann der Out-of-Order
ausführen, also die Reihnfolge der Befehle selbstständig ändern.
"Eigentlich ist dieses Programm auch absolut unbrauchbar für den
Vergleich. Hier werden nur Daten verschoben und dafür brauch man keine
CPU. Da benutzt man einen DMA, dann geht die Belastung auf die CPU gegen
null. Und das auch nur weil DMA und CPU den gleichen Bus benutzen.§
mir völlig wurscht..das ist das was die meistn hier mit den Controllern
machen, fenster Zecihnen, Button anlegen für touch etc...das ist daher
für 90% ein brauchbarer Test.
MPEg kodieren, mit Fliesskoma rechnen im großen Stiel, Spracherkennung
udn Mondfahrzeuge bauen hier die wenigsten..daher interessieren mit die
theoretichen Diskussionen hier..0
Max Schauzer schrieb:> ..daher interessieren mit die theoretichen Diskussionen hier..0
Wenn dich Antworten nicht interessieren, weshalb fragst du dann?
Den wohl einzigen verbreiteten Benchmark im Embedded-Bereich hatte ich
anfangs bereits genannt. Es ist auch nicht schwer, danach zu Suchen und
Zahlen zu gewinnen. Das fand ich zumutbar.
Der 8-Bitter kackt doch schon bei einfachen Arrayzugriffen gnadenlos ab:
- lade 2 Register mit Base
- lade 2 Register mit Offset
- addiere 2 mal
- lese 2 mal vom SRAM (für int16)
Er braucht jedesmal die doppelte Anzahl an Befehlen.
Peter Dannegger schrieb:> Er braucht jedesmal die doppelte Anzahl an Befehlen.
Eine ggf. skalierte Addition ist beim ARM Teil des Ladebefehls.
ldr r0, [r0, r1, lsl #2]
v.
lsl r22
rol r23
add r22,r24
adc r23,r25
movw r30,r22
ld r24,Z
ldd r25,Z+1
für
Peter Dannegger schrieb:> Der 8-Bitter kackt doch schon bei einfachen Arrayzugriffen gnadenlos ab:
nicht jedes Programm braucht das.
ARM ist auch nicht gut bei Video-Codierung.
Peter II schrieb:> ARM ist auch nicht gut bei Video-Codierung.
Würde ich so allgemein nicht unterschreiben. Kommt etwas drauf an
welcherARM. Die Bandbreite dessen, was unter dieser Flagge segelt,
ist recht hoch.
Aber klar, nix taugt für alles. Wenn AVR reicht, warum wechseln? Aber
der Thread bezieht sich letztlich auf die Frage, was bei einer
strategischen entweder-oder Entscheidung flexibler ist, AVR oder ARM.
Und das ist mittlerweile ARM.
Max Schauzer schrieb:> "Eigentlich ist dieses Programm auch absolut unbrauchbar für den> Vergleich. Hier werden nur Daten verschoben und dafür brauch man keine> CPU. Da benutzt man einen DMA, dann geht die Belastung auf die CPU gegen> null. Und das auch nur weil DMA und CPU den gleichen Bus benutzen.§>> mir völlig wurscht..das ist das was die meistn hier mit den Controllern> machen, fenster Zecihnen, Button anlegen für touch etc...das ist daher> für 90% ein brauchbarer Test.> MPEg kodieren, mit Fliesskoma rechnen im großen Stiel, Spracherkennung> udn Mondfahrzeuge bauen hier die wenigsten..daher interessieren mit die> theoretichen Diskussionen hier..0
Füllst du dich jetzt etwa beleidigt? Mein Beitrag war in keiner Weise
beleidigend oder böse gemeint.
Weißt du überhaupt was ein DMA ist? Was daran jetzt theoretisch sein
soll, verstehe ich auch nicht. Du verfeuerst hier unnötig Rechenleistung
für simples Kopieren von Daten. Aber gut wenn du meinst, das macht jeder
so und das soll so bleiben, wünsche ich dir noch viel Spaß. Kannst dich
ja wieder melden, wenn du einen Benchmark STM32F207 vs Rasperry Pi
machst ;) .
Peter II schrieb:> Peter Dannegger schrieb:>> Der 8-Bitter kackt doch schon bei einfachen Arrayzugriffen gnadenlos ab:>> nicht jedes Programm braucht das.
Also bei mir kommt kein einziges Programm ohne Pointer aus, ob Strings,
Buffer, Lookup-Tables, switch/case, command-parser usw. usw.
Und oftmals sind sogar Pointer auf Pointer nötig, d.h. mehrfache
Indirektion.
Allerdings habe ich keinerlei Zeitprobleme, daher reicht der AVR mir aus
und läuft oft mit Werkseinstellung 8MHz/8.
Ist aber schön zu wissen, falls man dochmal eilige Anwendungen hat, daß
der ARM sowas in einem Befehl kann, statt in 7 beim AVR.
A. K. schrieb:> Peter II schrieb:>> ARM ist auch nicht gut bei Video-Codierung.>> Würde ich so allgemein nicht unterschreiben. Kommt etwas drauf an> welcherARM. Die Bandbreite dessen, was unter dieser Flagge segelt,> ist recht hoch.ARM Systeme sind sehr wohl für Video/Graphic geeignet, das hat schon der
Ur-ARM im Archimedes Acorn bewiesen dessen Graphic-leistung Ende der
Achtziger einen Commodore Amiga oder Mac CE alt ausehen ließ:
http://en.wikipedia.org/wiki/Acorn_Archimedeshttps://www.youtube.com/watch?v=h6a8FMak-Pk (bspw. ab 2:00)
Heute überzeugt die Videoausgabe auf Smartphones oder in HDMI Sticks -
ARM von Cortex M0 32 MHz bis multicores im GHz bereich bei Cortex-A12?.
Und ARM selber ist nur der Core, bezüglich der "Chip-ausgabe" über
Peripherals wie GPIO's, HDMI etc. ist der Lizennehmer verantwortlich.
Und da gibt recht ordentliche Exemplare wo jeder Vergleich mit einem 8
bit Waschmaschinencontroller lächerlich ist.
Bspw Chromecast:
https://tomkanok.wordpress.com/2013/07/25/chromecast-device-cpu-detailed-specifications/
MfG,
Hat Moby eigentlich Ferien? Ich denke, er könnte abschließende Klarheit
über die Leistungfähigkeit von AVRs bringen.
Max Schauzer schrieb:> mir völlig wurscht..das ist das was die meistn hier mit den Controllern> machen, fenster Zecihnen, Button anlegen für touch etc...das ist daher> für 90% ein brauchbarer Test.> MPEg kodieren, mit Fliesskoma rechnen im großen Stiel, Spracherkennung> udn Mondfahrzeuge bauen hier die wenigsten..daher interessieren mit die> theoretichen Diskussionen hier..0
Nimm den AVR! Das ist der beste µC der Welt. ARM taugt absolut nichts,
da viel zu langsam.
Vielleicht kennt jemand noch einen guten Prozessor nicht zum Fenster
zeichnen, sondern zum Fenster putzen - auch von außen?
m.n. schrieb:> Vielleicht kennt jemand noch einen guten Prozessor nicht zum Fenster> zeichnen, sondern zum Fenster putzen - auch von außen?
Kein Problem. Sind aber nur als Einzelstücke mit subtil
unterschiedlichen und nicht immer vorher bekannten Eigenschaften
verfügbar. Und die wirklich günstigen Typen sind nur sehr eingeschränkt
versendefähig, weil der Zoll sie abgreift und zurückschickt oder
einlagert, da hilft auch kein CE Zeichen (wenn sie nicht sowieso schon
unterwegs absaufen). Gelegentlich wird auch von Problemen mit der
Programmiersprache berichtete, eine Einhaltung von hiesigen Standards
ist nicht garantiert.
A. K. schrieb:> Peter II schrieb:>> geht nicht sinnvoll, sonst würde Intel & Co nicht ihre vergleiche anhand>> von Benchmarks machen.>> Fairerweise muss man sagen, dass man bei AvrX und Cortex M3 durch> Abzählen von Takten von Befehlen eines Programms der Realität wesentlich> näher kommt als bei Intel & Co. Bei den x86 von heute ist das ein völlig> hoffnungsloses Unterfangen.
Selbst bei den ARM ist das schon ein schwieriges unterfangen weil auch
diese bereits pipelining/prefetch/branch speculation usw. beherrschen.
http://de.wikipedia.org/wiki/Pipeline_(Prozessor)
Cortex-M0+: 2-stufige Pipeline
Cortex-M0 : 3-stufige Pipeline
Cortex-M3 : 3-stufige Pipeline mit Sprungvorhersage
Cortex-M4 : 3-stufige Pipeline mit Sprungvorhersage
Cortex-M7 : 6-stufige Dual-Issue-Pipeline mit Sprungvorhersage
Ein einfaches aufsummieren der Befehle aus dem Handbuch gibt allenfalls
einen theoretischen Worstcase aber für eine realistischen Wert müsste
man genau betrachten in welcher Reihenfolge die verschiedenen Compiler
die befehle anordnen (und ggf. auch bezüglich Piplining hin optimieren),
wie sich diverse Waitstats im Flash/RAM der verschiednen Modelle
auswirken (bzw. in wie weit diese z.B. durch Prefetch neutralisiert
werden) und dann noch wie gut die sprungverhersage für den genauen Fall
ist usw.
Ist insgesamt nicht wirklich viel einfacher aus bei einem der früheren
x86.
@ Fpga Kuechle (fpgakuechle) Benutzerseite
>ARM Systeme sind sehr wohl für Video/Graphic geeignet, das hat schon der>Ur-ARM im Archimedes Acorn bewiesen dessen Graphic-leistung Ende der>Achtziger einen Commodore Amiga oder Mac CE alt ausehen ließ:>http://en.wikipedia.org/wiki/Acorn_Archimedes>Youtube-Video "DustyShows - Acorn Archimedes Xperience Szenedemo" (bspw. >ab
2:00)
Das ist von 1994. Auserdem war die Graphikleistung der 16 Bit System der
80er in erster Linie von den Customchips abhängig, die CPU hat da weit
weniger eine Rolle gespielt.
Das Video/Demo ist Klasse, aber auch der Amiga konnte sowas.
>Heute überzeugt die Videoausgabe auf Smartphones oder in HDMI Sticks -
Wirklich? Die Standardsachen ala MP3/Videoplayer sind OK, weil wirrklich
optimiert. Aber massig Apps und einfache Games sind einfach nur grausam!
Da ruckelt und zuckelt es, trotz GPU und GHz CPU!
>ARM von Cortex M0 32 MHz bis multicores im GHz bereich bei Cortex-A12?.
Dito heute. Die Graphik macht die GPU, nur selten die CPU.
Irgendwer schrieb:> A. K. schrieb:>> Fairerweise muss man sagen, dass man bei AvrX und Cortex M3 durch>> Abzählen von Takten von Befehlen eines Programms der Realität wesentlich>> näher kommt als bei Intel & Co.>> Selbst bei den ARM ist das schon ein schwieriges unterfangen weil auch> diese bereits pipelining/prefetch/branch speculation usw. beherrschen.>> http://de.wikipedia.org/wiki/Pipeline_(Prozessor)> Cortex-M0+: 2-stufige Pipeline> Cortex-M0 : 3-stufige Pipeline> Cortex-M3 : 3-stufige Pipeline mit Sprungvorhersage> Cortex-M4 : 3-stufige Pipeline mit Sprungvorhersage> Cortex-M7 : 6-stufige Dual-Issue-Pipeline mit Sprungvorhersage
Allerdings beherrscht der ARM bedingte Befehlsausführung was die Anzahl
der bedingten Sprünge und damit der pipeline stalls bei falsch
vorhergesagten Sprüngen deutlich minimiert.
Und kennt man die pipelinetiefe, kann man die zyclenzahl für eine
schleife immer noch genau bestimmen. Auch ein Einberechnung der pipeline
flush Kosten ist nun wirklich kein Hexenwerk (bei sprung anzahl clock
cycles laut datenblatt drauf).
Kritischer ist IMHO die Abschätzung des Einflußes der Caches
insbesonders bei nicht voll assoziativen Caches und Multi-Task systemen.
Cache ist allerdings nur bei langsamen (externen) Speicherinterfaces
sinnvoll,
so braucht der Cortex-M3 keinen Cache.
MfG,
irgendwie verstehen hier offenbar einige oder die meisten! gar nicht
worum es geht...obwohl der Threatstarter sogar Beispiele gebracht
hat.r.affen es einige immer noch nicht..
Es geht nicht darum ob ein ARM generell besser ist, es geht darum ob es
für umsteiger eine Überlegung ist, die eigentlich das übliche machen was
90% der Leute hier amchen..nämlich LED Blinken, Button Zeichen auf
Displays und einfach TExtausgabe bzw Balken...
Die Frage war ob ein ARM hierbei wirklich so viel schneller ist als ein
mit 32MHZ getakteter XMEGA z.B.
Stattdessen kommen hier Beispiele mit Videocodierung und so ein
tinnef...
UM es noch mal zu sagen..das FAZIT!! war ein mit 32MHz getakteter ARM
ist für sowas genauso schnell..oder nahezu...wie ein 32MHz XMega..
Also ist ein mit 72MHz getakteter ARM auch tatsächlich bei solchen
Aufgaben schon erheblich schneller und mit 120MHz noch mehr...
Eigentlich war die Frage gar einfach..aber 90% hier schon damit
überfordert...
haha, da fallen mir so geiel Beispiele zu diesem Forum hier ein :-)
Wenn hier eienr fragt wie man eine Glühlampe am besten wehchselt, weil
er sich damit nicht auskennt..werden daraus 45 Antworten doer
mehr..sowas wie..warum nimmst Du nicht gleich LED, abbauen und T8 nehmen
etc pp LOL
Dann kommen die üblichen Sicherheitsdiskussionen das er das besser sein
lassen solle und jemand holen soll, andere erklähren den Wirkungsgrad
von LED und LAmpen vs T8.
Dann kommen welche die sagen das das Thema geschlossen werden könne,
weile s sicher nur ein Troll ist hahah, ich schmeiß mich weg