Da es hier in einem anderen Thread gerade um KNNs ging, passt das irgendwie: http://googleresearch.blogspot.de/2015/06/inceptionism-going-deeper-into-neural.html Netter Artikel. Bekommt man direkt Lust das selbst mal auszuprobieren und damit rumzuspielen ;) Aufgefallen ist mir das ganze durch einen SPON und einen Heise Artikel: http://www.heise.de/newsticker/meldung/Bilderkennung-Wovon-traeumen-neuronale-Netze-2717736.html http://www.spiegel.de/netzwelt/gadgets/inceptionism-google-forscher-geben-netzwerken-lsd-a-1039965.html
Vlad Tepesch schrieb: > Bekommt man direkt Lust das selbst mal auszuprobieren und damit > rumzuspielen ;) Hast Du auch gelesen auf welcher Hardware die das gefahren haben ? Um mal einen Vergleich zu ziehen: http://www.heise.de/tr/artikel/Google-lernt-sehen-1769478.html Voraussetzung dafür ist allerdings, dass die Netze groß genug sind und mit genügend Trainingsdaten gefüttert werden. In ihrem Experiment hatten die Wissenschaftler ein KNN mit einer Milliarde künstlicher Synapsen verwendet und diesem zehn Millionen Bilder aus YouTube-Videos vorgesetzt. >16000 Prozessoren in 1000 Computern waren zehn Tage damit beschäftigt.
Michael Knoelke schrieb: >>16000 Prozessoren in 1000 Computern waren zehn Tage damit beschäftigt. Prima, da kann ich das ganze zweimal parallel machen. Aber im Ernst. Man kann ja auch mal klein anfangen und die Bildgröße auf 100x100 oder so beschränken. Michael Knoelke schrieb: > einer Milliarde künstlicher Synapsen kommt mir wenig vor. bei 1024x768 Pixeln hat man ja schon mal >0,75Mio Neuronen pro layer. Selbst wenn man nicht Alle Neuronen mit allen Neuronen des vorherigen Layers verbindet ist man bei 2-3 Layern ja schon drüber. Klar können die tieferen Schichten vielleicht auch weniger Neuronen haben, aber die Zahl kommt mir komisch vor. Vielleicht waren auch 1Mrd Neuronen gemeint.
Vlad Tepesch schrieb: > kommt mir wenig vor. > bei 1024x768 Pixeln hat man ja schon mal >0,75Mio Neuronen pro layer. Nur die Eingangsschicht braucht für jedes Pixel ein Neuron. Die tieferen Layer kommen i.d.R. mit weniger Neuronen aus. Michael Knoelke schrieb: > In ihrem Experiment hatten > die Wissenschaftler ein KNN mit einer Milliarde künstlicher Synapsen > verwendet Synapsen sind nicht Neuronen, sondern Verbindungen eines Neurons mit dem Axon eines Neurons der vorherigen Schicht. Ein Neuron kann (sinnvollerweise) maximal so viele Synapsen haben, wie Neuronen im vorherigen Layer vorhanden sind. Für R gibt es recht flotte Libs dafür.
Uhu Uhuhu schrieb: > Nur die Eingangsschicht braucht für jedes Pixel ein Neuron. Die tieferen > Layer kommen i.d.R. mit weniger Neuronen aus. wenn aber aus zwischenschichten Bilder generiert werden, heißt es für mich, dass ausreichend viele Neuronen da sein müssen. Deswegen hab ich das mit konservativen 1024xX abgeschätzt. Uhu Uhuhu schrieb: > Synapsen sind nicht Neuronen, sondern Verbindungen eines Neurons mit dem > Axon eines Neurons der vorherigen Schicht. Deswegen vermute ich hier einen Fehler. > Ein Neuron kann > (sinnvollerweise) maximal so viele Synapsen haben, wie Neuronen im > vorherigen Layer vorhanden sind. In der Regel ist bei einem Bild eher die Nachbarschaft interessant. vielleicht kann man so mit einer drei- oder vierstelligen Anzahl an Verbindungen pro Neuron auskommen. Oder man zieht Kreise und überspringt mit zunehmenen Abstand vom Pixel Ringe.
Vlad Tepesch schrieb: > In der Regel ist bei einem Bild eher die Nachbarschaft interessant. > vielleicht kann man so mit einer drei- oder vierstelligen Anzahl an > Verbindungen pro Neuron auskommen. Zu Beginn werden alle Neuronen mit allen Axonen des Vorgänger-Layers verbunden. Beim Training des Netzwerkes stellen sich die Synapsengewichte ein. Gewichte für Verbindungen ohne Relevanz für das Problem gehen gegen 0. Ob das Entfernen solcher 0-Synapsen effizienter ist, als die Berechnung mit dem Gewicht 0 ist, hängt natürlich davon ab, wie das Ganze implementiert ist.
Uhu Uhuhu schrieb: > Zu Beginn werden alle Neuronen mit allen Axonen des Vorgänger-Layers > verbunden. Beim Training des Netzwerkes stellen sich die > Synapsengewichte ein. Gewichte für Verbindungen ohne Relevanz für das > Problem gehen gegen 0. Ziel dieser Einschränkung wäre ja genau den Trainingsprozess einfacher zu gestalten und durch Voruntersuchungen festzustellen, welche der möglichen Verbindungen überhaupt sinnvoll wären. Bei 1024x768 = 786432 Neuronen pro Layer, wären das 393.216.000 (500/Neuron) versus 618.475.290.624 Synapsen (786432/Neuron) Allein der benötigte Speicher für die Gewichte pro Layer ist riesig. Man müsste nochmal genau recherchieren, wie diese Bilderkennungs-NN aufgebaut sind. die Zahlen werden doch sehr schnell sehr groß ;)
Vlad Tepesch schrieb: > Ziel dieser Einschränkung wäre ja genau den Trainingsprozess einfacher > zu gestalten und durch Voruntersuchungen festzustellen, welche der > möglichen Verbindungen überhaupt sinnvoll wären. > Bei 1024x768 = 786432 Neuronen pro Layer, wären das Leider nicht, denn dann müsste man Prämissen in den Lernalgorthmus stecken und würde damit zum Einen das Training stark verkomplizieren und zum Anderen den Vorteil der KNNs verschenken, dass sie auf beliebige Features trainierbar sind, so lange die Trainingsdaten widerspruchsfrei sind. (Wenn man dem Teil ein X für U vormacht, konvergiert das Training nicht.) In der Praxis werden die Gewichte der Synapsen mit Zufallsgewichten initialisiert und weil nicht jede Konstellation gleich gut funktioniert trainiert man i.d.R. mehrere Netze mit unterschiedlichen Initialisierungen und nimmt dann dasjenige, das die Aufgabe am besten erfüllt. Eines der R-Pakete trainiert standardmäßig 10 verschiedene Netze und vergleicht hinterher, wie gut sie sind - es können auch Netze entstehen, die schlichten Unsinn produzieren.
Uhu Uhuhu schrieb: > Synapsen sind nicht Neuronen, sondern Verbindungen eines Neurons mit dem > Axon eines Neurons der vorherigen Schicht. Ein Neuron kann > (sinnvollerweise) maximal so viele Synapsen haben, wie Neuronen im > vorherigen Layer vorhanden sind. Ein Neuron (man bezeichnet die eher als Unit) kann sinnvollerweise maximal 1+Anzahl Units in allen Layern Synapsen haben. D.h. man kann zum einen einen Eingang mit dem Ausgang der Unit selber verknüpfen und zumdem von allen anderen Ausgängen aller Units des kompletten Netzwerkes Verknüpfungen aufbauen. Die Synapse als Feedback vom Ausgang zum Eingang des gleichen Neurons macht es erst möglich das ein Netzwerk auch sequentielle Muster erlernen kann, zb. beim Recurrenten Cascade Correlation Netzwerk. Erst durch solche Verbindungen kann ein Netzwerk ein "Gedächtnis" ausbilden. Das Netzwerk ist dann in der Lage beim Trainingsprozess eine Muster-Reihenfolge innerhalb sequentiell trainierter Muster zu erkennen. Beispiel: Morsecode. Ein Recurrentes Netzwerk ist in der Lage den Morsecode mit einem einzigen Eingangsneuron zu erlernen. Dieses Eingangsneuron bekommt den Morsecode also sequentiell gefüttert. Normalerweise heist dies: man arbeitet getaktet mit einer "Zeitbasis" und definiert das der Unterschied zwischen Punkt zu Strich nur darin besteht das der Punkt zwei Takte = zweimal in zwei Mustern als Punkt vorkommt. Die Ausgangsschicht besteht überlicherweise aus Neuronen die jeweils ein Buchstabe des Alphabeths und ein Fehlerausgang besteht. Ist das Netz trainiert wird es später live im Einsatz ohne Zeitverzögerung den Mosrecode dekodieren können. Habe ich selbst schon programmiert. Anderes Beispiel: ich habe dieses RCCs dazu benutzt zu beweisen das wir Menschen nicht in der Lage sind echt zufällige Entscheidungen zu treffen. Dazu wird ein Spiel gespielt bei dem der Mensch sich zwischen zwei Antworten entscheiden kann, also JA oder NEIN, bzw. grüner oder roter Taster. Das Netzwerk trifft verdeckt im Vorfeld die Entscheidung ob der Mensch sich für Rot/Grün entscheiden wird. Nachdem beide ihre Wahl getroffen haben wird überprüft ob die beiden Entscheidungen übereinstimmen. D.h. ob das Netz die Vorhersage der Auswahl des Menschens korrekt vorhergesagt hat. Wenn nicht bekommt der menschliche Spieler einen Punkt wenn korrekt das Netzwerk. Ausgehend von diesen Ergebnissen wird das Netzwerk nun im Hintergrund trainiert, also alle vergangenen Entscheidungen werden dabei berücksichtigt, und dies live während des Spieles! (das Netz ist am Anfang untrainiert). Das Netz soll also lernen in unserer "freien und zufälligen" Entscheidung ein Muster zu erkennen. Ergebnis: nach ca. 100-200 Spielrunden gewinnt das Netz in jedem Fall mit > 60% Wahrscheinlichkeit. Und das obwohl der menschliche Spieler sehr wohl das Feedback hat welche Entscheidung er trifft und getroffen hat und er auch erkennen kann wie sich das Netzwerk entschieden hat, es also ein Feedback für den Menschen gibt seine Spieltaktik ständig anpassen zu können, er verliert trotzdem. Nur wenn der Mensch einen Würfel zur Hand nimmt pegelt sich die Gewinnwahrscheinlichkeit auf 50% ein. Ein Neuron kann also viel mehr Synapseneingänge besitzen als die von dir angegebene Maximalanzahl.
Uhu Uhuhu schrieb: > Vlad Tepesch schrieb: >> Ziel dieser Einschränkung wäre ja genau den Trainingsprozess einfacher >> zu gestalten und durch Voruntersuchungen festzustellen, welche der >> möglichen Verbindungen überhaupt sinnvoll wären. >> Bei 1024x768 = 786432 Neuronen pro Layer, wären das > > Leider nicht, denn dann müsste man Prämissen in den Lernalgorthmus > stecken und würde damit zum Einen das Training stark verkomplizieren und > zum Anderen den Vorteil der KNNs verschenken, dass sie auf beliebige > Features trainierbar sind, so lange die Trainingsdaten widerspruchsfrei > sind. (Wenn man dem Teil ein X für U vormacht, konvergiert das Training > nicht.) Doch das geht. Man kombiniert innerhalb des Trainingsprozesses die Idee der neuronalen Netze mit genetischen Algortihmen. Am Anfang kann also ein Netz initialisiert werden das maximal verknüpft ist und nur wenige Neuronen besitzt. Während des Trainingsprozesses werden nun sogenannte Kandidatenneuronen dynamisch hinzugefügt und wiederum maximal verknüpft. Es gibt mehrere solcher Kandidaten die untereinander quasi konkurreren und durch gentische Algorithmen evolutoniert werden. Nach einer gewissen Trainingszeit (wiederum mit mathm. Verfahren in ihrer Entwicklungsgeschindigkeit bewertet) beendet man das Zwichentraining und wählt das Kandidatenneuron mit der besten Fitness aus und fügt es dauerhaft dem Netzwerk hinzu. Zum zweiten wird dies auch mit den Synapsen gemacht. Je mehr einfluß sie auf die korrekte Entscheidungen haben desto höher ihre Fitness = Überlebenschance. Verknüpfungen die also wenig Einfluß haben werden mit der Zeit aus dem Netz eleminiert. Am Ende hat man ein Netz trainiert bei dem man: - keine Layer mehr vorgeben muß - eine Lösung mit optimal geringer Anzahl an Neuronen für das Problem benötigt werden - die geringste Anzahl an Synapsen entstehen und somit die höchste Rechenperformance im späteren Einsatz erzielt werden kann Desweiteren gibt es verschiedene Aktivierungsfunktionen, zB. Gaussian/Sigmoid/Sin/Cos etc.pp. Auch diese werden als eine Eigenschaft der Neuronen genetisch evolutioniert. Der Mensch gibt nur noch die Trainigsdaten, die Ein/Ausgangsschicht und die Evolutionären Selektierungsfunktionen = Zielrichtung vor. Den Rest erlernt das Netz von selbst.
Neuronale Netze verpaart mit Genetischen Algorithmen - das wird erst richtig Rechenaufwendig... Wenn sich das allerdings irgendwann effizient in Hardware packen läßt, dann gilt die Menschheit zu 100% geistig behindert.
Naja, das ist wie jedes technische Problem für das es verschiedene mathematische Rechenwege gibt und dann feststellt das destöfteren der Algorithmus mit der besten Komplexität (Big O) eben auch aufwendigere Vorarbeiten benötigt und dann aber bei der eigentliche Problemlösung zur Laufzeit der schnellste ist. Ein großes Problem von neuronalen Netzen ist oft deren schlechte Parallelisierbarkeit. Bei genetischen Algorithmen wiederum gibt es für 90% der Berechnungen aber sehr gute Möglichkeiten der Parallelisierbarkeit im Vergleich zum immer notwendigem Speicheraufwand und deren Verwaltung der Datenmengen. Kann man nun beides geschickt kombinieren, so wie beim RCC Netzwerk, dann ist es möglich die Parallelisierbarkeit drastisch zu verbessern. Die Grundkomplexität des schon bestehenden Teils des Netzwerkes, der nicht mehr weiter trainiert wird! wächst nur linear. Die Kandidatenneuronen, die als einziges trainiert werden, können wiederum mit genetischen Verfahren, parallel evolutioniert werden. Faktische also ein Rechner pro Neuron. Die restlichen für das Training notwendigen Netzwerkstrukturen sind für all diese Recheneinheiten aber fix und eine gemeinsam genutzte ReadOnly Resource. Back to Topic: was mich eigentlich interessiert ist die Frage wie die ein Netzwerk aus meheren Layern dazu bewegen nun seine Arbeitsweise umzukehren und wie sie einen Layer mit Daten anregen. Auf alle Fälle fallen mir spontan unzählige interessante Anwendungen ein. Man stelle sich vor ein netzwerk das auf die Erkennung und Klassifizierung von Musik trainiert wurde. Also: das Netzwerk erkennt "Klassik/Pop/Rock, Orchester/Band/Chor, Musikinstumente, Taktbasis -> Beethoven -> die Neunte. Und nun lassen wir es umgedreht arbeiten und regen es so an das man sagt: "Hallo Netzwerk ich wünsche mir Beethovens Klassik + Queens Rock Ballade" und macht dann Musik. Oder male mir ein Bild -> "Abstrakt und Rubens Stil". Oder: "Netzwerk evolutioniere alle möglichen Entscheidungen deines erlernten Handlungsmodelles des dazugehörigen Menschen und berechne die wahrscheinlichste Reaktion wenn ich diesem Menschen in real dies oder das zum kaufen anbiete". Man trainiert also erstmal für einen realen Menschen an Hand aller gesammelten Bewegungsprofile ein Netzwerk. Quasi lebenslang läuft auf dem Server ein trainiertes Abbild eines Menschens mit. Und bei Bedarf dreht man dessen Funktion um und setzt es als Simulation verschiedenen Angeboten aus. Wie hoch ist dann die Wahrscheinlichkeit das der reale Mensch Produkt X kauft, welchen Preis ist er bereit zu zahlen und unter welchen Umständen kann ich den profit noch steigern (Zb. packe ne rote Schleife drum Sie steht drauf und kauft mehr). Und zusätzlich visualisiert mir dieses Menschen-Netzwerk-Abbild auch noch die Trigger-Zusammenhänge die mich zum kaufen bewegen oder es zeigt uns welche Fehlentscheidungen der Mensch trifft weil sein natürliches "Netzwerk" den gleichen Trainingsfehlern unterliegt wie das simmulierte. Bei perfekt gesammelten Bewegungsprofilen unterliegt ja das künstliche Netzwerk den fast gleichen "Trainingsdaten" wie dessen natürliches Original. Wahnsinn. An der Rechenpower wird sowas in Zukunft mit Sicherheit nicht scheitern, da bin ich mir sicher.
Geht man von den Gesetzmäßigkeiten der industriellen Massenproduktion aus so wird es einen Breakeven Point nach unten geben ab dem man den Profit durch Intensivierung der Massenproduktion nicht mehr steigern kann. Diesen Punkt haben wir heutzutage längst erreicht. Ein Ausweg ist dann die Konsumgeschwindigkeit zu erhöhen, auch das haben wir schon zB. mit der geplanten Obsoleszenz. Und auch hier wird es einen BreakEven Point nach unten geben der dann erreicht ist wenn die zB. ökologischen Schäden den zukünftigen Profit auffressen werden. Auch den Punkt haben wir fast erreicht. Nächster Ausweg ist die Entwicklungsgeschwindigkeit neuer Technologien zu erhöhen, sprich immer neuere Features immer neuere angeblich bessere Produkte. Auch hier gehts nur bis zu einem gewissen Punkt bis der Kunde sagt: ach ich bin mit Handy zufrieden ich brauche nicht mehr und fühle mich betrogen und gehetzt immer alle Trends mitmachen zu müssen. Was bleibt? Die Optimierung der individuellen Angebote. Statt "Fließband-Kunden" mit immer identischen Bedürfnissen und Eigenschaften also höchst individualisierte Angebote, quasi für jeden Kunden und Produkt und Zeitpunkt der Entscheidungsfindung individuelle Kaufverträge. Und da denke ich steuern wir gerade hin. Mit einem "Tool" das diesen Prozess optimal vorhersagen kann lässt sich enorm Geld verdienen. Ich denke Google wird das begriffen haben. Grundsätzlich keine schlechte Sache denke ich, es hängt vom gesellschaftlich akzeptierten und regulierten Kontext ab. Ich stell es mir schon praktisch vor wen mich mein "persönlicher Assistent", das mit meinen Bewegungsdaten trainierte Netzwerrk, an Hand seiner Simulationen der möglichen Zukünfte davon abrät mit meinem Herzschaden den Sprung von der Brücke am Gummiseil zu wagen. Oder umgedereht durch Abgleich mit dem "Assistenten" der hübschen Frau am anderen Tisch im Cafe andeutet das es sich lohnt mal ein Risiko einzugehen. Wenn die letztliche Entscheidung darüber transparent bei jedem persönlich liegt sehe ich da eher Vorteile, solange ich das System und dessen Funktion verstanden habe und vertraue.
Hagen Re schrieb: > An der Rechenpower wird sowas in Zukunft mit Sicherheit nicht scheitern, > da bin ich mir sicher. An Wahnsinn vermutlich auch nicht... Hagen Re schrieb: > Die Ausgangsschicht besteht überlicherweise aus Neuronen die > jeweils ein Buchstabe des Alphabeths und ein Fehlerausgang besteht. Wie trainiert man den Fehlerausgang?
Uhu: "Wie trainiert man den Fehlerausgang?" Der wird einfach per NAND mit einem idealen Menschenmodell verknüpft.
Hagen Re schrieb: > Auch hier gehts nur bis zu einem gewissen > Punkt bis der Kunde sagt: ach ich bin mit Handy zufrieden ich brauche > nicht mehr und fühle mich betrogen und gehetzt immer alle Trends > mitmachen zu müssen. Wundert mich, das nicht schon längst bei vielen dieser Punkt erreicht ist. Ich habe mir z.B. nie ein Smartphone angeschafft.
Nun da das Netzwerk den Morsecode auf Grund seiner Kodierung nur sequentiell erlernt muß es Zwischenschritte geben. Diese entstehen dadurch das ein Strich in zwei aueianderfoldgenden Mustern als Punkt kodiert wird. Die "Abtastfrequenz" ist also doppelt so hoch, bzw. ein Punkt lang. Dies gilt für Punkt/Strich und die Pausen dazwischen. Dadurch kann es passieren das das Netzwerk aktuell im Morsecode Stream mitten innerhalb eines Striches oder Pause = Symboles ist. Um das anzuzeigen trainiert man den "Fehlerausgang". Dieser Ausgang zeigt also an wann die anderen Ausgänge der Symbole Gültigkeit haben. Dies ist sehr leicht zu trainieren und die Traingsdaten sind ebenfalls einfach zu erzeugen. Male dir SOS als Morsecode auf und taste dieses Signal mit Schrittweite "Punkt" ab. Wenn beim Abtasten ein gültiges Symbol abgetastet wurde geht der Fehlerausgang auf 0, ansonsten auf <> 0. Gleiches gilt für die Abtastung der Pausenlänge, man trainiert einen Ausgang auf die Pausenlänge um das Ende einer Kommunikation etc.pp. zu erkennen. Übrigens wenn ich mich recht errinnere hatte das finale Netzwerk 9 Neuronen und ansonsten nur die Neuronen für Ein/Ausgabe Schicht, Fehlerquote 0%, und bei jedem Training entstand nach Abstraktion immer das identische Minimal-Netzwerk, nur die Trainingsiterationen variierte. Interessant war aber für mich eher das alle Netzwerke mit unterschiedlichen Aktivierungsfunktionen -> Sigmoid/Gaussian/Sin/Cos identische Abstraktionen besitzen (maW. Aktivierungsfunktionen sind oft überschätzt) Diese Abtastung muß man so machen, da man die Ausgänge eines Neurons nach Möglichkeit nur auf ein Feature trainieren möchte. Man hätte die Ausgänge auch so trainieren können das sie nur dann ein Symbol anzeigen wenn es korrekt erkannt wurde. Dh. erst duch die Analyse aller Ausgänge und der Suche nach "alle sind 0" würde man erkennen können das man mitten im Symbol dekodiert hat. Das ist aber schlecht. Besser ist es wie ich es beschreibe denn so kann man selbst wenn der Fehlerausgang sagt "mitten im Symbol" denoch die Symbolausgänge analysieren und sagen "falls es korrekt wäre dann wäre es mit x% diesem Symbol ähnlich". Davon abgesehen: es ist doch wohl logisch das diese Auswertung auch ein Netzwerk für uns machen kann statt ein blöder MinMax Bewertungalgorithmus, das wäre ja profan ;) Vereinfacht ausgedrückt könnte man es auch so bauen: ein sequentiell lernfähiges Netzwerk konzentiert sich darauf wann ein gültiges Symbol erkannt wurde und ein zweites Netzwerk wird nur auf die Erkennung der Symbole trainiert. Aber! wie du oben schon selbst geschrieben hast ist das bei neuronalen Netzwerken eher ungünstig da man so von vornherein eventuell nicht sichtbare aber erlernbare Zusammenhänge ausschließt. Ich habe damals als erstes Experiment exakt dieses Problem programmiert da es von den Erfindern des RCCs selbst als Szenario beschrieben wurde. Ergebnis damals: RCCs erzeugten Netzwerke mit bis dato nie dagewesener Effizienz. Es gab damals mathematische Abhandlungen darüber welche Mindestkomplexität bis dahin bekannte Netzwerke haben müssen damit sie das Morsecode Problem sauber lösen können. Die bis dahin als bewiesene gültige Annahme wurde von RCcs widerlegt, es ging mit RCCs mit noch weniger Neuroen als bis dahin vermutet (exakt 1 Neuron weniger als die mathem. ermittelte Minimalkonfiguration). Ebenso wurde die Geschwindigkeit und Konvergenzgeschwindigkeit zur korrekten Lösung analysiert. Auch hier zeigte sich das RCCs das Problem deutlich schneller erlernen konnten. Das alles waren ja die Gründe, neben meinem Vorwissen in genetischen Algortihmen und Evolutionsstrategien, warum ich überhaupt die RCCs angegangen bin. Nun, das heist aber nicht das dieser RCC Netzwerktypus, der Weisheits letzter Schluß ist. Dieser Typ versagt jämmerlich bei vielen anderen Problemen (zb. Bilderkennung). Aber er ist eben in der Lage ein "Memoryeffekt" auszubilden und somit Mustersequenzen zu erlernen die sequentiell über Einzelmuster hinausgehen. Eigentlich logisch: Angenommen du hast ein normales Netzwerk mit 3 Neuronen in 3 Layer, also pro Layer ein Neuron. Der Ausgang des ersten Neurons dient als Eingang im ersten Neuron, Ausgang vom 2. geht zum 2. und 1., Ausgang 3. geht zum 3.,2.und 1. Eine "Entscheidung" die sequntiell durch das Netzwerk läuft wird also nach 1, 2 und 3 Mustern auch als Input für die Bewertung aktueller Muster herangezogen. Es entsteht ein Feedback innerhalb des Netzwerkes das es dem Netz ermöglicht seine eigenen vergangenen "Entscheidungen" für aktuelle Muster heranzuziehen. Es kann sich also an bis zu 3 vergangene Entscheidungen/Muster "erinnern", es hat ein Gedächtnis.
Stefan M. schrieb: > Hagen Re schrieb: >> Auch hier gehts nur bis zu einem gewissen >> Punkt bis der Kunde sagt: ach ich bin mit Handy zufrieden ich brauche >> nicht mehr und fühle mich betrogen und gehetzt immer alle Trends >> mitmachen zu müssen. > > Wundert mich, das nicht schon längst bei vielen dieser Punkt erreicht > ist. > Ich habe mir z.B. nie ein Smartphone angeschafft. Mich wundert eher der "Fakt" das wenn ich annehme das real dieser Punkt schon erreicht wurde die meisten Menschen nicht die Konsequenzen zu ziehen bereit sind, sondern eher versuchen mit noch mehr Konsum die entstehende innere Qual über die Sinnlosigkeit des Ganzen, ertragen zu wollen. Oder anders formuliert: Statt die realen Ursachen zu indentifizieren und zu beseitigen man lieber an den Symptomen rumdoktert.
Hagen Re schrieb: > Back to Topic: was mich eigentlich interessiert ist die Frage wie die > ein Netzwerk aus meheren Layern dazu bewegen nun seine Arbeitsweise > umzukehren und wie sie einen Layer mit Daten anregen. Ich schätze mal, das funktioniert so (wird im Artikel kurz erwähnt, aber nicht weiter erklärt): Auf der Ausgabe-Schicht werden die Neuronen auf ein bestimmtes Resultat eingestellt - z.B. wird das Bananen-Neuron auf 1 gesetzt, und die Neuronen für Apfel, Birnen, Kiwi, Erdbeeren usw. werden auf 0 gesetzt. Dann werden alle Kombinationen an Eingangs-Werten gesucht, die zu dieser Ausgabe führen. Natürlich sind das "unendlich" viele, und die meisten davon sehen nicht aus wie ein Bild. Nun sucht man sich eine Eingangs-Kombination, die von ihren Eigenschaften einem natürlichen Bild möglichst nahe kommt. Das trifft beispielsweise auf Kombinationen zu, wo benachbarte Pixel jeweils eine hohe Korrelation haben. Algorithmisch wird man das natürlich nicht so lösen, dass man zuerst "alle" Eingangskombinationen sucht und dann die bildhafteste auswählt, sondern man wird vermutlich ein Optimierungsproblem lösen, wo man gleichzeitig einen möglichst passenden Input für den gegebenen Output UND möglichst bildhafte Eigenschaften (hohe Korrelation von Nachbarpixeln) des Inputs sucht. Würde mich nicht wundern, wenn das in einem riesigen linearen Gleichungssystem endet ;-)
Welche Bibliothek würdest du empfehlen, wenn man Neuronale Netze in eigene Programme einbauen will? Ich habe bisher mit einer Ruby-Bibliothek erste Flugversuche mit ewig langen Testreihen gemacht, um etwas Gefühl für den Einfluss der Netzwerktopologie bei der Individuenerkennung von Wachtelkönigen zu bekommen - es war fast wurscht, wieviele Layer das Teil hatte und wie breit die waren, außer dem ersten und dem letzten natürlich. Nachteil war die äußerst schwache Recheneffizienz, aber das ist bei Ruby im Preis inbegriffen. Für "echte" Berechnungen hat sich das R-Paket ganz gut bewährt, das aus einem Ruby-Programm zur Merkmalsextraktion aufgerufen wird. Letztere war im Nachhinein betrachtet der aufwendigere Teil.
Für Deep Learning ist das Python-basierte Theano im Moment sehr beliebt (http://deeplearning.net/software/theano/). Für Standard-Netzwerkstrukturen gibt es dabei Wrapper die einem die Arbeit abnehmen alles von Hand zu schreiben (mit Keras, http://keras.io/, habe ich gute Erfahrungen gemacht). Auch sehr einfach und beliebt ist Torch (http://torch.ch/), das basiert auf Lua. Beide unterstützen GPUs. Die klassischen NN-Toolkits in MATLAB, R & Co. sind für Deep Learning weniger geeignet, da fehlen z.B. Knotentypen wie ReLU und Maxout und Techniken wie Pre-Training und Dropout Training.
Andreas Schwarz schrieb: > Für Deep Learning ist das Python-basierte Theano im Moment sehr beliebt > (http://deeplearning.net/software/theano/). Kann ich auch empfehlen. Bin gerade berufsbedingt mit ANNs beschäftigt. Außerdem würde ich mir vorher das hier mal durchlesen (http://cs231n.stanford.edu/syllabus.html), damit bekommt man einen groben Überblick und Anwendungstipps (ich bin allerdings in der Bildverarbeitung unterwegs, dem entsprechend ist das schon recht spezifisch). Im Zusammenhang mit Theano wäre Lasagne vielleicht noch interessant (https://github.com/Lasagne/Lasagne). Gruß
P. M. schrieb: > Hagen Re schrieb: >> Back to Topic: was mich eigentlich interessiert ist die Frage wie die >> ein Netzwerk aus meheren Layern dazu bewegen nun seine Arbeitsweise >> umzukehren und wie sie einen Layer mit Daten anregen. > > Ich schätze mal, das funktioniert so (wird im Artikel kurz erwähnt, aber > nicht weiter erklärt): > > ....einem riesigen linearen Gleichungssystem endet ;-) Da bin ich mir nicht so sicher. Meine Vermutung geht da in eine andere Richtung, nämlich das die für die SPON/Bild/Heise Reporter eine weniger geschickte Vereinfachung gemacht haben und die Darstellung des NNs auf gewöhnliche NNs bezogen haben (also Grafik mit Neuronen etc.pp.) Solche NNs sind nämlich unidirektional in ihrem Verarbeitungpfad. Ich denke eher das die wie üblich bei Bildverarbeitungen mit SOM-Matrix/Hidden markov Modelle etc.pp. arbeiten die insich bidirektionale Verarbeitungspfade ermöglichen. D.h. schon das Training solcher Netzwerke wäre so möglich das es im Grunde irrelevant ist wo Ein- oder Ausgangsschicht sich befindet, ist reine Definition welche Schicht welche Funktion hat. Allerdings kenne ich solche NNs nur als Layerfreie Netze.
Uhu Uhuhu schrieb: > Welche Bibliothek würdest du empfehlen, wenn man Neuronale Netze in > eigene Programme einbauen will? Kann ich nicht. Meine Zeit mit NNs liegt im Bereich 1990-97.
Uhu Uhuhu schrieb: > Netzwerktopologie bei der Individuenerkennung von Wachtelkönigen zu > bekommen Damit meinst du deren "Stimme" eg. Singen ? Ich habe mich nachdem ich die Schrifterkennung so wie beim Palm das "One Stroke System" nachgebaut hatte auch an Sounderkennung versucht. Damit bin ich nur bedingt weiter gekommen, lag vielleicht am Ansatz. Auf alle Fälle denke ich nicht das man bei Stimmerkennung einfach den Saound in ein Netzwerk füttern kann und das dann auf ein Individuum trainieren kann. Ich hatte damals mit sehr schmalen 3D-FFTs = Wasserfalldiagrammen gearbeitet und schnell festgestellt das meine Kompetenz die Datenmengen auf diese Weise zu reduzieren nicht ausreichend ist, kurz gesagt: die nötige Rechenpower war für mich nicht algorithmisch in den Griff zu bekommen. Zudem konzentrierte ich mich in diesem Zeitraum eher auf Kryptoanalyse Mithilfe von NNs für spezialisierte Zwischenberechnungen, was auch dämlich war ;)
Hagen Re schrieb: > Wenn die letztliche Entscheidung darüber transparent bei > jedem persönlich liegt sehe ich da eher Vorteile, solange ich das System > und dessen Funktion verstanden habe und vertraue. Die Benutzeroberfläche dient nur dem Benutzen.
Hagen Re schrieb: > Damit meinst du deren "Stimme" eg. Singen ? Ja, das ist ein ziemlich simpler Ruf, der sich aus einer Anreihung von einzelnen Pulsen zusammensetzt. Er klingt so ähnlich, als würde man mit dem Finger die Zinken eines Kamms (mit gleich langen Zinken) anreißen. Zur Indiviuenerkennung reicht es aus, das NN auf die Zeitabstände der ersten 15 Pulse zu trainieren. Das ist ein extrem einfaches Beispiel. Bei anderen Arten ist die Merkmalsextraktion deutlich kniffliger.
und die Tiere selber unterscheiden dann nicht nur die Tonlage sondern auch die Abstände zwischen den einzelnen Pulsen? Also die Pulsabstände sind ebenfalls entscheidend? Wenn dem so wäre dann sind eben besonders solche recurrenten Netze von Interesse. Nimmt man herkömliche Netze für solche Probleme dann hat man oft zwangsläufig das Problem einer großen Inputschicht. Man fängt an diese Inputschicht künstlich zu verkleinern, aus der Not heraus, und wendet Vorfilterungen an. Eben zb. FFTs oder Wavlets oder sonstige Filterungen . Und handelt sich somit noch mehr Probleme ein. Zb. stellen wir uns mal vor es gibt 10-15 solcher Pulse. Die Pulse selber können nur in 3 varianten vorkommen. Normalerweise könnte man also sagen: lerne die 3 Grundarten von Pulsen und dann nur noch deren zeitlicher Kombination von beliebig aueinadnerfolgender Pulse. Recurrente Netze können genau das, sie differenzieren die 3 Pulsarten, deren sequentielle Kombination und Geschwindigkeit=Pausenzeiten. Alles als drei getrennte Feature und sequentiell jeden Puls als einzelnes Muster. Normal Netzwerke wo man den kompletten Ruf als ein Muster auf einmal der kompletten Inputschicht präsentieren muß haben damit Probleme. Aber der relevante Vorteil ergibt sich erst später. Bei zB. 15 Pulse a 3 Kombinationen ergibt sich eine große Kombinationsvielfalt. Normale Netze versuchen über alle Pulse hinweg quasi alle Kombinationen zu erlernen. Recurrente Netze dagegen können am Ende kompaktere Strukturen bilden weil sie über die drei Feutures "Pulsart", "sequentielle Kombination", "Pausendauer" für jede dieser Features quasi eine Komprimierung durchführen können und das abhängig über alle drei Feature hinweg. Sie erlernen also nicht alle Kombinationen sondern nur die die für eine Vorgelart von Relevanz sind. Hm, anders formuliert: wenn die ersten drei Pulse nur eine Gesamtanzahl an Kombinationen von zb. 7 haben dann erlernt dies das recurrente Netz sehr gut. Oder wenn sich dieses Muster bei allen Rufen später wiederholt im individuellen Ruf, auch Individuenübergreifend, kann es das abstrahieren und exakt die selben Neuronengruppen feuren dann. Das Netz bildet also diese Gruppe nur einmal aus und benutzt sie mehrfach für verschieden Positionen im Muster. Sowas können andere Netze uU. nicht, sie würden für ähnliche Teilmuster an unterschiedlichen Positionen auch eigene Neuronengruppen herausbilden. Wie weit bist du denn gekommen? Schribst oben "bedingt" erfolgreich.
Letzendlich ist die Idee dahinter ja recht simpel. Alles was eine gesuchte Information enthält zusammengesetzt aus zeitlich aufeinanderfolgenden Einzelinformationen wird mit recurrenten Netzen auch als sequentiell ablaufendes Muster erlernt. Statt also das WAV-File eines Sounds komplett der Inputschicht zu präsentieren wird hier Sample für Sample der Inputschicht präsentiert. Das reduziert natürlich die Breite der Inputschicht und überlässt zudem die sequentielle Analyse auch noch dem Netzwerk. Das Netz kann somit auch mit Komplettmustern umgehen deren Länge variabel ist. Das problem der Normierung der Eingangsdaten wird teilweise ausgelagert ins Netzwerk. Ich denke du wirst auch schnell erkennen das nun auch der "Fehler"-Ausgang "kompletten Ruf" bzw. "neuer Ruf beginnt" Sinn ergibt. Übrigens: intuitiv würde man meinen das es besser wäre die Inputschicht breit zu machen damit man einen Ruf quasi paralell erlernen kann. Bei genauerem Betrachten stellt man aber fest das dies eben nicht so ist.
Hagen Re schrieb: > und die Tiere selber unterscheiden dann nicht nur die Tonlage sondern > auch die Abstände zwischen den einzelnen Pulsen? Also die Pulsabstände > sind ebenfalls entscheidend? Das Muster der Pulsabstände allein reicht aus, um die Viecher zu unterscheiden, die Tonhöhe kann man außer Acht lassen. Zur Vorverarbeitung habe ich als erstes das Signal gleichgerichtet und dann durch einen zweistufigen digitalen Tiefpass geschickt. Anschließend einfach die Anzahl Samples zwischen den Maxima gezählt und dann mit diesen Werten als Feature-Vektor das NN mit 15 Eingängen gefüttert. > Wie weit bist du denn gekommen? 16 Individuen konnte ich damit unterscheiden, zweimal zwei Aufnahmen waren nicht zu unterscheiden, also vermutlich jeweils derselbe Vogel. Mich interessiert vor allem die Individuenerkennung, als nächstes möchte ich den Waldkauz näher unter die Lupe nehmen - von denen kann ich manche Individuen ohne Hilfsmittel am Ruf erkennen. Allerdings sind die Oszillogramme deutlich komplizierter, als bei den Wachtelkönigen. Hagen Re schrieb: > Das Netz kann somit auch mit Komplettmustern umgehen deren Länge > variabel ist. Das Problem kann man beim Wachtelkönig einfach dadurch umgehen, dass man nur die ersten 13-15 Pulse berücksichtigt Rufe mit weniger als 15 Pulsen gibt es zwar auch, aber Individuen, die das immer machen, dürften sehr selten sein, wenn es sie überhaupt gibt. Die kurzen Rufe dürften auf irgend welche äußeren Ereignisse zurückzuführen sein. > Ich denke du wirst auch schnell erkennen das nun auch der > "Fehler"-Ausgang "kompletten Ruf" bzw. "neuer Ruf beginnt" Sinn ergibt. Darüber habe ich lange nachgedacht... Letztlich lohnt sich der Aufwand nicht, weil zur Erkennung wenige Rufe ausreichen und die Aufnahmen auch noch allen möglichen anderen Dreck enthalten können, der die Rufe verstümmelt, auch Überlagerungen mehrerer Rufer. Das Einfachste ist, sich die Oszillogramme anzusehen und "schöne" Rufe herauszupicken und damit die Erkennung zu füttern. Der weit größere Aufwand ist, Aufnahmen mit ausreichender Qualität zu bekommen.
Uhu Uhuhu schrieb: > Der weit größere > Aufwand ist, Aufnahmen mit ausreichender Qualität zu bekommen. Gute Trainingsdaten, und damit meine ich nicht nur Daten zum Training sondern auch zur Einschätzung des Erfolges des Trainings, sind immer das Problem. Eigentlich sind das die nervigsten Arbeiten. Deswegen ist ja der verlinkte Beitrag so interessant. Ich hatte mir damals immer schon gewünscht ind die Arbeitsweise des Netzwerkes reinschauen zu können. Alleine der Aufwand beim Morsecode Experiment, die Abstraktion der verschiedenen Netzwerke, um sie auf vergleichbare Funktion zu überprüfen hat länger gedauert als der ganze Rest. Allerdings fällt mir auf das du sehr starkes Preprozessing betrieben und damit im Vorfeld schon eine starke Abstraktion durchgeführt hast. Meiner Erfahrung nach ist das oft ein Problem warum später die Netze nicht gut konvergieren. Ich bevorzuge es eher diesen Aufwand zu verringern und dem Netz die Entscheidungen zu überlassen. Das führt aber zu längeren Trainingszeiten die sich am Ende aber meistens lohnen, wenn man das Ziel hat möglichst kompakte Netze für die Laufzeit zu bekommen. Also: aufwendigers Training das offline erfolgen kann dafür bessere Netze zur Laufzeit die online rechnen können.
Uhu Uhuhu schrieb: > Das Muster der Pulsabstände allein reicht aus, um die Viecher zu > unterscheiden, die Tonhöhe kann man außer Acht lassen. Hm, d.h. die Tiere selber identifizieren den Absender an Hand der Puls/Pausen und der Inhalt der Nachricht dann über die anderen Eigenschaften? Ich hätte eher vermutet das es umgedreht ist, Tonlage als Stimme fürs Tier und Puls/Pausen für den Inhalt.
Hagen Re schrieb: > Allerdings fällt mir auf das du sehr starkes Preprozessing betrieben und > damit im Vorfeld schon eine starke Abstraktion durchgeführt hast. Auf diese Weise wurde das Problem überschaubar und die Rechenzeiten erträglich und vor allem konnte ich einen Einstig in diese doch ziemlich undurchsichtige Technik finden... > und der Inhalt der Nachricht dann über die anderen Eigenschaften? Ob man da von einem Inhalt reden kann, glaube ich weniger. Der ganze Ruf sagt wohl nur "ich bin hier" und an den Qualitäten des Rufes erkennt der Rivale oder ein Weibchen, wie fit der Rufer ist. Intelligenzbestien sind die Wachtelkönige nicht. An den Revierstrophen der Waldkäuze kann man auch als Mensch sehr deutliche Qualitätsunterschiede hören: das eine Männchen huddelt das Tremolo am Ende der Strophe nur so ganz flüchtig hin, andere bringen es sehr sauber und kräftig moduliert und bei manchen hört man, dass sie irgend eine Infektion, oder Luftröhrenwürmer haben, da kommt die Strophe dann mit Wackelkontakt oder die Stimme überschlägt sich. Das Rufrepertoire der Waldkäuze ist ziemlich reichhaltig, während der Wachtelkönig nur diesen einen Ruf zustande bringt. Ich denke, dass die rückgekoppelten NNs für Arterkennung geeigneter sind. Ob man aber einfach einen wav-File vorne reinschieben kann und hinten die Artenliste heraus bekomt, da habe ich doch so meine Zweifel, denn auf den Aufnahmen ist mit allem möglichen zu rechnen, das mit einer Mono- oder Stereoaufnahme nicht mehr sauber zu trennen geht. Wenn sich der Hörer selbst im Feld bewegen kann, kann er Informationen gewinnen, die auf einer Aufnahme nur zusamengematscht rüber kommen.
@Uhu Uhuhu Von oben läßt sich vor lauter Wald oft KEIN EINZIGER Baum erkennen.
@Hagen Re Aha, ein Mann ohne Gedächtnis ALSO!
Uhu Uhuhu schrieb: > Ob man aber einfach einen wav-File vorne reinschieben kann und > hinten die Artenliste heraus bekomt, da habe ich doch so meine Zweifel, > denn auf den Aufnahmen ist mit allem möglichen zu rechnen, das mit einer > Mono- oder Stereoaufnahme nicht mehr sauber zu trennen geht. Wenn sich > der Hörer selbst im Feld bewegen kann, kann er Informationen gewinnen, > die auf einer Aufnahme nur zusamengematscht rüber kommen. Ich kann deine Bedenken nachvollziehen, ging/geht mir auch so. Deshalb hatte ich ja mit 3D-FFTs die Waves prozessiert und dann auf ausgewählte Frequenzbereiche reduziert und diese als an separate Inputs geführt. Das reduziert aber nicht die Komplexität im Vergleich zu SampleBySample Technik, sondern im Gegenteil musste ich feststellen. Die Trennung von Störgeräuschen ist mit oder ohne Preprozessing immer die Aufgabe des Netzwerkes, das soll ja gerade die wesentlichen Merkmale erlernen. Es ist meiner Meinung nach eher eine Frage der Trainingsdaten. Und in deinem Fall musst du das Netzwerk auch mit FALSE-Daten trainieren bzw. verifizieren.
Angehängte Dateien:
-

crex.png
2,3 KB
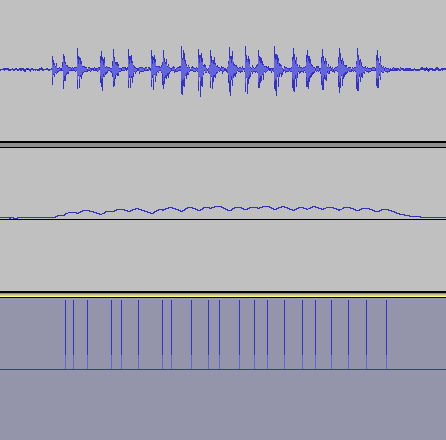
Hagen Re schrieb: > Und in deinem Fall musst du das Netzwerk auch mit FALSE-Daten trainieren > bzw. verifizieren. Das ist leicht gesagt, das Spektrum an Dreck, der in einer Aufnahme sein kann, ist kaum vorhersehbar. Was ich mir vorstellen könnte, wären Markierungen in den Trainingsdaten, die sagen, "hier kommt ein Ruf" und "hier endet er". Eventuell wäre es besser, den Job aufzuteilen: als erstes von einem eigenen NN die Rufe herauspicken lassen und von einem zweiten die Identifikation auf dem Output des ersten ausführen. Zum Anhang: das obere Oszillogramm ist ein (handverlesener) Originalruf, das mittlere ist das gleichgerichtete und tiefpassgefilterte Signal, das untere enthält für jedes Maximum im mittleren einen Peak. Das NN wird nur mit den Zeitabständen zwischen den Peaks gefüttert. Da der Feature-Vektor nur 15 Fließkommawerte enthält, kann man zumindest durch einfachen Vergleich grob prüfen, ob das NN was Plausibles augegeben hat. Meine Überprüfung bestand darin, dass ich aus den Aufnahmen jeweils ~20 Rufe extrahiert habe und dann mit der Hälfte davon das NN trainiert und mit der anderen Hälfte geprüft, ob das "richtige" Ergebnis heraus kommt. Das hat sehr gut geklappt. Sinn der Übung soll sein, die Wanderungen von max. 40-50 Vögeln in einem Feuchtgebiet nachzuvollziehen und das auch nur in der relativ kurzen Zeit, in der sie rufen. Evtl. auch noch die Wiedererkennung "alter Kunden" aus den Vorjahren - die zeitlichen Muster in den Rufen sind über lange Zeit stabil. Wie müsste man es anfangen, ein Netz zu konstruieren, das den Originalsound so einliest, wie er aus dem A/D-Wandler kommt und den "Namen" des Rufers ausspuckt? Das Netz müsste Dreck von Rufen unterscheiden können, überlagerte Rufe aussondern und dann die individuellen Feinheiten herausfinden. Wie müssten die Trainingsdaten aussehen? Für jede Aufnahme eine Taktspur, die PCM-Daten und an passender Stelle als dritte Spalte der "Name" des Rufers?
Hi Uhu dein Vorgehen mit der Analsys der Peaks ist verständlich. Wenn ich das auf RCCs erweitern wollte dann einfach indem ich das RCCs mit den Zeitlichen Abständen als Zahlenwerte sequentiell füttern würde. D.h. man ermittelt die Abstände als Integer Werte und das ist das sequentielle Muster das das Netzwerk erlernen soll. Die Traingsdaten bestehen erstmal aus den durch dich erkannten Rufen, sauber separiert und ohne "fehler". Dann erweiterst du dieses Muster während des Trainings live am Anfang und Ende mit zufälligen Teilstücken aus anderen Rufen und mutierst den sauberen Ruf noch mit zufälligen Zahlenwerten innerhalb des Musters. Mit anderen Worten: aus wenigen hochqualifizierten Rufen werden so viel mehr Testdaten erzeugt. So enstehen die Mustervektoren für das Training der des Inputs des RCCs, hat ja nur einen. Exakt synchron zum Eingabemuster erzeugtst du einen Stream für die gewünschte Antwort. Dieser ist mehrspürig und besteht aus jeweils einer Spur für jedes Individuum. Wenn du also 50 Vögel ausgewählt hast sio entstehen 50 Spuren + 1 Spur für "hier ist Ruf erkannt worden". Diese Daten werden wiederum live während des Trainigs erzeugt. Für die Spur des zu erkenndenen Vogels gilt: ab dem moment wo der Ruf beginnt bis er endet alles 1 ansonsten 0 für den Ausgang. Für alle Individuuen die vor/nach/während des Rufes dynamisch per Zufall hinzugefügt wurden gilt das gleiche. Für alle Individuuen die nicht vorhanden sind immer 0 am Ausgang. Für den Ausgang "Ruf erkannt" nur am Ende des Rufes. So erzeugst du dir deine Trainingsdaten quasi aus dem "Nichts". Einige wenige Rufe hebst du dir auf um sie später dem Netz vorzuführen. Soweit dazu wenn man dein Vorgehen erweitern würde. Zur Laufzeit und auch bei Tests kannst du nun verschiedene Rufe einfach vermischen und nochmal mit Netz testen. Das Netz muß in der Lage sein sich überlappende Rufe sauber zu erkennen. Aber ich würde es tatsächlich so manchen das man ohne Preprozessing arbeitet. Genauer gesagt, das Preprozessing beschänkt sich auf den Versuch mit möglichst schlechten Audiostreams zu trainieren. Also geringe Samplerate und Sampleauflösung und nur Integer. Letzteres ist absolut kein Problem, man benötigt keine große Dynamik oder Auflösung damit Netzwerke was erlernen können. Im idealfall liegen diese Parameter an der untersten Grenze wo ein netzwerk überhaupt noch was erlernen kann. Einfachste Vorgehensweise: reduziere die Audioqualität bis du selber nicht mehr sauber unterscheiden kannst. Das Netzwerk wird es besser können als du! so meine Erfahrung mit meinen Experimenten:) Ich habe mit der Analyse der fertigen Netze und der Frage "warum? kann das das Netz" Wochen verbracht. Der Rest, also die Frage wie man aus den qualitiv sauber separierten Rufen wieder Trainingsdaten generiert ist so wie oben, nur viel einfacher. Man mischt digital einfach die Rufe. Reizt mich ja schon die Sache, besonders weil ich wetten könnte das man damit sogar familiere Beziehungen aufdecken kann. Das würde ich sogar von Anfang an vorsehen. Man kann nämlich Netzwerke auch zusaätzlich so trainieren das deren Outputs die dicht nebeneinander in der eigentliche Netzwerkstruktur liegen, also deren programatische örtlichkeit, als Indiz der Ähnlichkeit zusätzlich heranzieht. In deinem Fall sortiert man die zu trainierenden Ausgangsmuster einfach nach Familienbezug. Shit: wenn ich nur mehr Zeit hät. Auf alle Fälle scheint deine Problemstellung noch schön überschaubar und eben sehr nützlich zu sein. Wenn du delphi/PASCAL verstehst kann ich dir meine Sourcen zum RCC mailen.
Hm, ich würde neben dem Ausgang "Ruf erkannt" auch noch die Ausgänge "Ruf beginnt" und "Ruf endet" einbauen. Diese werden aber so trainiert das sie NICHT Individuuen-spezifisch sind. Also auch bei den Störungen dürch Teilstücke andere Rufe aktiviert werden. Im Grunde erzeugst du separate Ausgänge für jedes einzelne Feature das dich interessiert. Von der Zerlegung des Netzwerkes in hierarisch auf Aufgaben bezogenen Einzelnetze halte ich grundsätzlich nichts. Der Aufwand der sich daraus ergibt frist die Vorteile auf.
Nochwas ist wichtig. Die Spezialausgänge wie "Ruf erkannt" sind kausal problematisch. Zb. "Ruf beginnt" geht schon auf 1 noch bevor das Netzwerk überhaupt genügend Informationen über den eigentlichen Ruf zu sehen bekommt. Interessanter Weise also ein Problem für das Netzwerk das es im Grunde nicht 100%'tig erlernen kann. Denoch wird es seine Fehlerquote reduzieren wenn genügend Infos vorhanden sind wenn sein "Lernziel" tatsächlich erreichbar ist. Damit meine ich: man muß sich von seinen eigenen "intuitiv logischen" Vorstellungen verabschiedenen beim Design aber mit Hilfe dieser Logik im Nachhinhei sich erklären können das das Netz nichts erlernen kann. Schon im Vorfeld diese Logik walten zu lassen und somit die Daten wie du enorm zu reduzieren ist kontraproduktiv. Nur den Ausgang "Ruf erkannt" würde ich gesondert behandeln. Dieser geht erst par Samples nach dem Ruf auf 1, am besten soviel später wie die zeitliche Tiefe des RCCs ist, was aber im Vorfeld nicht exakt verhersehbar ist. Zudem geht dieser Ausgang auch nicht nur für 1 Samplezeitpunkt auf 1 sondern sollte in den Traingsdaten auf zb. 5 Samples verlängert werden, so wie eine Impulsverlängerung. Das ist einfacher da du ja weist was so durchschnittlich die zeitspanne zwischen zwei Pulsen ist, in Sampleanzahl gerechnet.
Hagen Re schrieb: > Interessanter Weise also ein Problem für das Netzwerk das > es im Grunde nicht 100%'tig erlernen kann. Denoch wird es seine > Fehlerquote reduzieren wenn genügend Infos vorhanden sind wenn sein > "Lernziel" tatsächlich erreichbar ist. Erst diese Denkweise bringt dich dann später weiter. Oft stellt man dann bei der Analyse fest das über alle Individuuen hinweg nur die ersten par Pulse/Pieper real entscheidend sind. Exakt solche Erkenntnisse sind es die mich so verdutzt haben bei der späteren Analyse.
Uhu Uhuhu schrieb: > Wie müssten die Trainingsdaten aussehen? Für jede Aufnahme eine > Taktspur, die PCM-Daten und an passender Stelle als dritte Spalte der > "Name" des Rufers? Die qualifizierten Rufe: PCM-WAVE Datei + Infos als Datensatz zum Individuum, am einfachsten ist der Dateiname = Name des Individuums. Ich würde aber wenn es geht noch weiter klassifizieren nach Alter/Geschlecht etc.pp. Ich denke diese Daten sammelst du ja eh schon. Die Trainingsdaten werden dann daraus dynamisch erzeugt. So lang wie der sich dann ergebende Input-PCM-Stream ist ist der Stream für jeden der gewünschten Outputs. Dh. Inputschicht sehr klein, Outputschicht groß. Datenmenge Input ist klein, Outputs groß aber dynamisch schnell erzeugbar. Für jedes Individuum ein eigener Output. Die Ouput-Trainingsstreams sind also auch PCM und synchron zum Input-PCM-Stream. Das netzwerk wird trainiert Sample by Sample. Einen Takt als solche gibt es nicht, die Samplerate ist immer gleich und damit ist das die enthaltene Taktbasis. Die Implementierung eines RCCs enthält sowieso noch zusätzliche "Steuereingänge" die dem Netzwerk mitteilen das ein neuer Musterstream beginnt, diese sind eh schon vorhanden auf Grund der Funktionsweise des RCCs. Stelle es dir so vor: du schaust dir in deinem WAVE Editor den Ruf an. Nun fügst du parallel dazu noch mehrere Tonspuren hinzu in denen nur die Werte 0 oder 1 als Samples vorkommen. Dieses Tonspuren sind die Outputs die du von "Hand" nach Zielsetzung auf 0 oder 1 definierst. Das ganze bekommt das Netzwerk zu sehen, als Input und Output-Muster. Simpel. Diese Kodierung erscheint auf den ersten Blick sehr aufgebläht, ist es aber nicht aus Sicht des Recurrenten Netzwerkes. Angenommen ein Output geht über die gesamte Länge von zb. 1000 Samples nur einmalig für 100 Samples auf 1 ansonsten 0. Ein Recurrentes Netzwerk wird nun nur vom x'ten neuron zum y'ten neuron eine Verküpfung aufbauen. Quasi wie ein zwei Taps in einem FIR-Buffer die abgegriffen werden und einem Gatter zugeführt werden. Das RCC ist in der Lage exakt solche Start-Stop Sequenzen mit minimalem Neuronen Aufwand zu detektieren.
Hagen Re schrieb: > besonders weil ich wetten könnte das man damit sogar familiere > Beziehungen aufdecken kann. Das wäre natürlich super. Nur gibt es ein paar kleine Probleme dabei: die Vögel sind wild und um die familiären Beziehungen festzustellen um die Ergebnisse verifizieren zu können, müsste man sie fangen und Blutproben entnehmen, um dann per DNA-Fingerprinting die Verwandschaftsbeziehungen heraus zu bekommen. Und wie das so üblich ist bei den meisten Vögeln, singen nur die Männchen. Außerdem ist die Population offen und die Piepmätze sind Langstreckenzieher, beide Geschlechter leben in sukzessiver Polygamie und können sich in einer Brutsaison mehrfach verpaaren. Das würde wohl aus rein praktischen und Artenschutzgründen zumindest sehr schwierig. https://de.wikipedia.org/wiki/Wachtelk%C3%B6nig - dort ist auch eine Tonaufnahme. > Auf alle Fälle scheint deine Problemstellung noch schön überschaubar und > eben sehr nützlich zu sein. In der Tat. Wenn man die Rufe hört, glaubt man erst mal nicht, dass der Piepmatz geradezu ein Lehrbeispiel für solche Dinge ist. > Wenn du delphi/PASCAL verstehst kann ich dir meine Sourcen zum RCC > mailen. Das wäre super. Ich schreib dir eine PM. Mein Lieblingsvogel ist der Waldkauz - bei dem sieht die Sache völlig anders aus: sie leben in Dauerbeziehung in festen Revieren, haben eine ganze Reihe verschiedene Lautäußerungen, die z.T. geschlechtsspezifisch sind. Die Jungvögel rufen völlig anders, als adᥙlte. Eine zuverlässige Individuenerkennung wäre schon toll, aber wenn man auch noch die Verwandschaftsbeziehungen zwischen Revierinhabern feststellen könnte, wäre das ein Riesenfortschritt. Nur das Verifikationsproblem ist nicht viel kleiner. Der Waldkauz ist die häufigste einheimische Eule, allerdings nicht ganz einfach zu beobachten, weil sehr überwiegend nachtaktiv. Das Ganze geht in Richtung minimalinvasive Untersuchnung der Populationsdynamik.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.