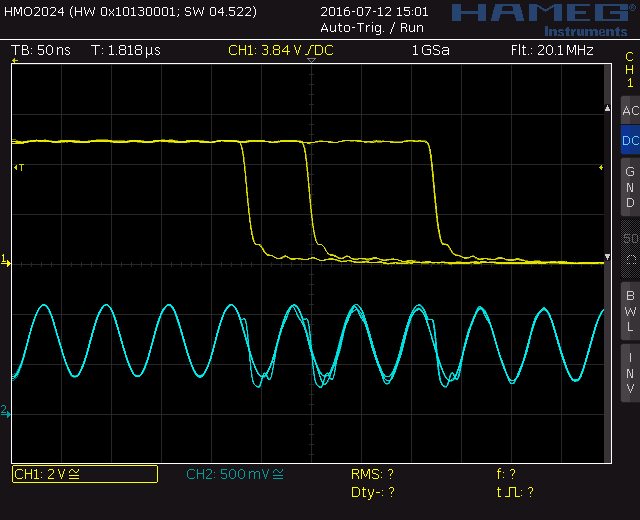
Auf einem ATmega mit 16 Mhz führe ich diese ISR aus:
1
ISR(ADC_vect)
2
{
3
PORTB |= (1<<PB0);
4
switch (ADMUX & 0x03) {
5
case 0: LED_R_PWM = pwm_value[ADCH];
6
ADMUX |= (1<<MUX0);
7
ADMUX &= ~(1<<MUX3); //test
8
break;
9
case 1: LED_G_PWM = pwm_value[ADCH];
10
ADMUX |= (1<<MUX1);
11
ADMUX &= ~(1<<MUX0);
12
break;
13
case 2: LED_B_PWM = pwm_value[ADCH];
14
ADMUX &= ~(1<<MUX1);
15
ADMUX &= ~(1<<MUX3); //test
16
break;
17
}
18
19
PORTB &= ~(1<<PB0);
20
}
Das setzen von PB0 für die Dauer die ISR dient nur dem Bestimmen der
Ausführungszeit von der ISR.
Mich verwundert aber ein Jitter, den in dabei messen kann.
In dem Oszi-Screenshot (Ch1 ist PB0, Ch2 der Takt) sieht man, dass die
Ausführungszeit um bis zu drei Takte schwankt, obwohl ich extra noch die
drei Cases angeglichen habe, indem ich für Case 0 und Case 2 noch
jeweils einen unnützen Befehl (mit //test kommentiert) eingefügt habe...
pwm_value[] ist ein Array für die Logarithmus-Korrektur, falls das von
Interesse ist.
Nicht dass der Jitter meinem Programm irgendeinen Abbruch tun würde,
aber es interessiert mich einfach mal, woher er kommt, da ich den Grund
nicht herausfinden konnte.
Julian S. schrieb:> ADMUX &= ~(1<<MUX1);> ADMUX &= ~(1<<MUX3); //test
Wird zu einer Aktion Optimiert un
Julian S. schrieb:> ADMUX |= (1<<MUX1);> ADMUX &= ~(1<<MUX0);
Hier müssen jedoch zwei unterschiedliche Aktionen gemacht werden, die
exakt 3 Takte dauern Read, Modify, Write.
Julian S. schrieb:> obwohl ich extra noch die drei Cases angeglichen habe, indem ich für> Case 0 und Case 2 noch jeweils einen unnützen Befehl (mit //test> kommentiert) eingefügt habe...
Ähm, dir ist klar, das nicht jede C-Zeile auf dem uC die selbe Laufzeit
hat? Nicht mal auf Assembler-Ebene ist das so...
BTW: Der "Idealfall" wäre sogar, wenn eine Zeile gar keine Laufzeit
hat und das Programm blitzschnell ausgeführt wird.
> da ich den Grund nicht herausfinden konnte.
Wie gesagt: wenns um einzelne Takte geht, dann ist das Assemblerlisting
der Anlaufpunkt...
Hallo,
die Wege eines C-Compilers sind manchmal etwas merkwürdig.
Richtig herausbekommen kann man das eigentlich nur, wenn man sich das
Disassembly bzw das *.lss file das Atmel Studio anlegt anschaut.
Mit welchen Optimierungseinstellungen kompilierst du? Manchmal kann es
sein, dass aufgrund "schlechter" Optimierung ein Stück nutzloser Code
oder sowas übrig bleibt, was dann einige Takte schluckt.
Wenn du das elf-File oder das lss-File hochlädst, kann ich mal schauen.
Spontan fällt mir als Grund nur ein, wie der switch-case implementiert
wird.
Auf dem AVR wird er als "if", also als Vergleich, implementiert. und je
nachdem in welchen Case du hineinspringst müssen davor unterschiedlich
viele vergleiche durchgeführt werden, was zu einer Laufzeitveränderung
führt.
Springt er beispielsweise in den dritten Case hat er davor schon zweimal
die ersten beiden abgeglichen. Dies muss er nicht tun, wenn der erste
Case bereits ein "Hit" ist.
@Ingo Less
Ahh, daran habe ich nicht gedacht. Ergibt natürlich Sinn.
@Lothar Miller
Theoretisch war mir das schon klar, ich kenne auch zum Großteil die
Ausführungszeiten der ASM-Befehle, aber ich bin schlicht nicht drauf
gekommen, dass die zwei gleichen Befehle zu einem Zusammengefasst werden
können.
Danke =)
Ingo L. schrieb:> Julian S. schrieb:>> ADMUX &= ~(1<<MUX1);>> ADMUX &= ~(1<<MUX3); //test> Wird zu einer Aktion Optimiert un>> Julian S. schrieb:>> ADMUX |= (1<<MUX1);>> ADMUX &= ~(1<<MUX0);> Hier müssen jedoch zwei unterschiedliche Aktionen gemacht werden, die> exakt 3 Takte dauern Read, Modify, Write.
Das sollte nicht passieren. Die Register sind als "volatile" deklariert.
Somit werden Zugriffe nicht vom Compiler gruppiert.
Ingo L. schrieb:> Außerdem, wenn du unnützen Kram einbaust, ist es die Aufgabe des> Optimizers diese Sache zu finden und weg zu optimieren, was er hier wohl> auch tut...
Der Compiler weiß aber nicht, was davon unnötig ist und was nicht :D
M. H. schrieb:> Der Compiler weiß aber nicht, was davon unnötig ist und was nicht :D
Wenn ich vorher etwas mit 3 maskiere kann es nicht größer als 3 sein,
das sollte jeder Compiler trotz volatile optimieren oder?
Hier z.B.:
Ingo L. schrieb:> Wenn ich vorher etwas mit 3 maskiere kann es nicht größer als 3 sein,> das sollte jeder Compiler trotz volatile optimieren oder?
Naja, nur weil mich für die Case-Bedingung nur die letzten beiden Bits
des Registers interessieren heißt das ja noch lange nicht, dass ich
nicht auch irgendwie ein höherwertigeres Bit setzen/zurücksetzen kann!
Ingo L. schrieb:> Ich habe gerade mal in einem meiner *.lss> nachgeschaut: Zwei Zugriffe (odernd) auf TCCR1B werden tatsächlich nicht> zusammengefasst.
Was mich an diesem Listing irgendwie wundert, ist dass der Compiler eine
indirekte Adressierung über den Z-Pointer baut.
Wäre nicht auch ein Zugriff mittels lds/sts und einer Konstanten in
diesem Fall möglich? Dass würde Takte sparen.
Julian S. schrieb:> Naja, nur weil mich für die Case-Bedingung nur die letzten beiden Bits> des Registers interessieren heißt das ja noch lange nicht, dass ich> nicht auch irgendwie ein höherwertigeres Bit setzen/zurücksetzen kann!
Ja, stimmt auch wieder...
Jedenfalls werden doppelte Zugriffe nicht zusammengefasst, das stimmt
schon.
M. H. schrieb:> Spontan fällt mir als Grund nur ein, wie der switch-case implementiert> wird.> Auf dem AVR wird er als "if", also als Vergleich, implementiert. und je> nachdem in welchen Case du hineinspringst müssen davor unterschiedlich> viele vergleiche durchgeführt werden, was zu einer Laufzeitveränderung> führt.
Daran wird es dann wohl liegen.
Ich hab mal den ASM-Code angehangen, aber dass spätere Cases mehr
Vergleiche "benötigen", erschließt sich mir schon.
Julian S. schrieb:> Ich hab mal den ASM-Code angehangen,
Ja. Die Vergleiche für die einzelnen Cases machen da nen Unterschied.
Aber was mich wundert ist, dass dein Compiler Registerzugriffe mit sts
implementiert wohingegen die Registerzugriffe aus dem Listing von Ingo
Less mit st implementiert sind.
Irgendwie verwirrt mich das gerade. War eigentlich der Meinung, dass der
AVR-GCC in 99% der Fälle recht zuverlässig arbeitet und ausgereift ist.
Aber bei der Implementierung mittels st dauert ein Schreibzugriff ja
doppelt so lang.
M. H. schrieb:> Wäre nicht auch ein Zugriff mittels lds/sts und einer Konstanten in> diesem Fall möglich? Dass würde Takte sparen.
Keine Ahnung was sich der Compiler da zusammenbaut... Is mit GCC 4.9.2
und -Os kompiliert.
Mit -O2 kommt das Selbe raus.
Da kann wohl nur Johann helfen!
Ingo L. schrieb:> M. H. schrieb:>> Der Compiler weiß aber nicht, was davon unnötig ist und was nicht :D> Wenn ich vorher etwas mit 3 maskiere kann es nicht größer als 3 sein,> das sollte jeder Compiler trotz volatile optimieren oder?
Nein, da der Compiler die Seiteneffekte dieser Anweisung nicht kennt.
Die Zuweisung könnte irgendwas auslösen oder zwischen den Zuweisungen
könnte der Wert bereits wieder von der Hardware verändert werden.
volatile-Variablen behandelt der Compiler wie angeknackste rohe Eier.
Ansonsten könnte er folgendes auch optimieren:
Julian S. schrieb:> Mich verwundert aber ein Jitter, den in dabei messen kann.
Das ist doch noch harmlos.
Sobald Du noch andere Interrupts benutzt, kann der Jitter leicht 50
CPU-Zyklen und mehr betragen.
Mit ISR_NOBLOCK kann man zwar manche Interrupts unterbrechbar machen und
den Zusatz-Jitter auf ~10 Zyklen verkürzen, aber z.B. bei der UART geht
das in die Hose (Stacküberlauf).
Hier nochmal ein (beim mir) reproduzierbares Compiler(-fehl)verhalten:
Beitrag "Compiler verhält sich seltsam"
welches die Codeproblematik nochmal aufgreift
Warum sind die 3 Case-Pfade unterschiedlich lang?
Weil der Compiler
1. diese nicht über eine Tabelle mit Zieladressen für 0,1,2 anspringt,
was in der Konstelation teurer wäre als Vergleiche und Sprünge
2. er um das jeweils nächste Case rumspringt zum return, was beim
letzten nicht notwendig ist.
3. C keine Garantie zu taktgenauen Ausführungszeiten macht.
Falls man letzteres wirklich braucht, ist Assembler angesagt. Allerdings
funktioniert der Trick dann auch nur auf den einfachen CPUs wie z.B.
AVR.
BTW, in der ISR ist noch etwas Luft, denn ADMUX ist (da HW-Register)
volatile deklariert, kann aber in einer (trickfreien) ISR als
nicht-volatile angesehen werden. Wenn man es also in eine lokale
Variable _ADMUX kopiert, diese in der ISR verwendet und am Ende wieder
zurückkopiert, dann wird der Compiler ADMUX in einem (CPU-)Register
"cachen". Wenn ich das .lss richtig überflogen hab, spart das 6x LDS
Rn,0x007C und 4x STS 0x007C,Rn. Die sind alle 2-Wort-Befehle. Wird
sicher auch ohne laufen, aber kurze ISRs sind besser, besonders, wenn
man nur normale Sprachmittel benutzt hat.
Ach je, was für eine Problematik ?
Der Compiler erzeugt funktionieren den Code in völlig ausreichender
Qualität. Wer zyklengenaue ISRs benötigt, muß diese in Assembler
programmieren. Bei dem Beispiel hier sinds ja, wie üblich, nur ein paar
wenige Zeilen.
Jittern wirds dann allerdings immer noch, selbst dann, wenn nur eine
einziger Interruption aktiv ist, weil die benötigen Zyklen zum Einsprung
in eine ISR nicht konstant sind.
Oliver
Oliver S. schrieb:> Wer zyklengenaue ISRs benötigt, muß diese in Assembler programmieren.
Es ist eher so, dass er sich mal genau überlegen muss, ob er sowas
tatsächlich braucht. Ich will i.A. nicht, dass eine ISR immer gleich
lang braucht, sondern viel eher, dass sie schnellstmöglich fertig ist...
Hier ging es ja auch nicht um die Jittervermeidung sondern um das Warum
es jittert. Dabei ist halt durch Zufall aufgefallen, dass der gcc
unserer laienhaften Meinung nach etwas umständlichen Code erzeugt.